
Ribbon负载均衡策略源码解析
*
- RandomRule
- RoundRobinRule
- BestAvailableRule
- RetryRule
RandomRule
我们先来看一下这个随机策略的源码:
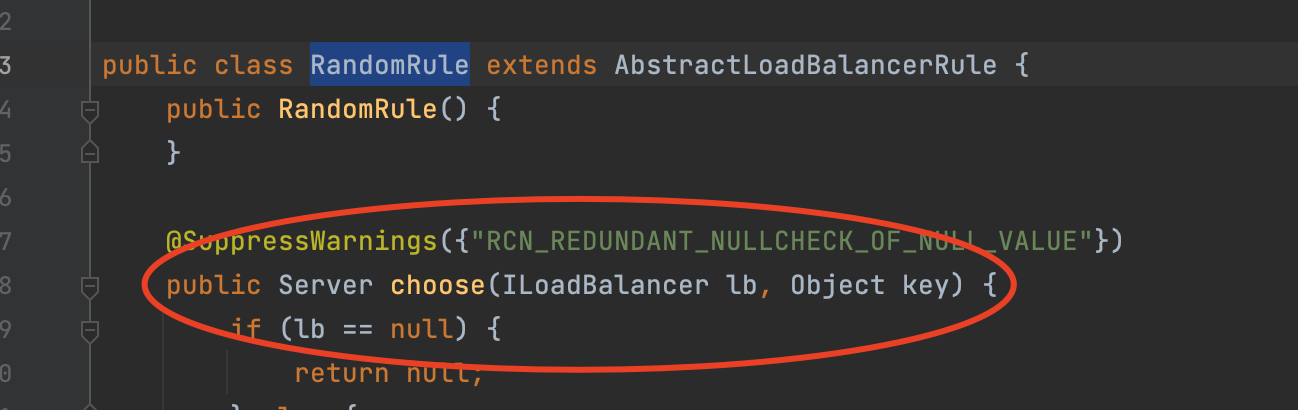
这个choose是它的核心方法。
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
} else {
Server server = null;
while(server == null) {
if (Thread.interrupted()) {
return null;
}
List<Server> upList = lb.getReachableServers();
List<Server> allList = lb.getAllServers();
int serverCount = allList.size();
if (serverCount == 0) {
return null;
}
int index = this.chooseRandomInt(serverCount);
server = (Server)upList.get(index);
if (server == null) {
Thread.yield();
continue;
} else {
if (server.isAlive()) {
return server;
}
server = null;
Thread.yield();
}
}
return server;
}
}
在choose方法里,我们可以看到它通过了一个 chooseRandomInt方法拿到了一个index下标。
我们看下这个方法:

它这里使用了一个 ThreadLocalRandom 然后在当前的thread中通过nextInt传入了一个serverCount,然后就会返回0到serverCount中的任意一个值。
既然这里提到了random,就给大家拓展一个小知识点吧,其实我们不管是使用Random类还是ThreadLocalRandom,在Java中的随机其实都并不是 真随机数,也就是说在所有输入都一定的情况下,不管你把什么样的种子数据插入进去,不论是当前时间,或者当前时间的后几位,他都是可以预测结果的。
那什么是真随机数呢?真随机数他会往往参杂一些你不可预测的东西来作为一个种子生成数据,比如说你当前CPU的温度,它就是你不可预测的,所以真随机数它往往会通过一些硬件来生成,而这些硬件有一些感应器或者是温度感受器,或者噪声感受器,他会采集你当前环境中的某些属性来作为随机数的种子来产生真随机数。
RoundRobinRule
其实RandomRule的代码读起来还是比较简单的。
我们再来看一下下一个负载均衡策略,RoundRobinRule:
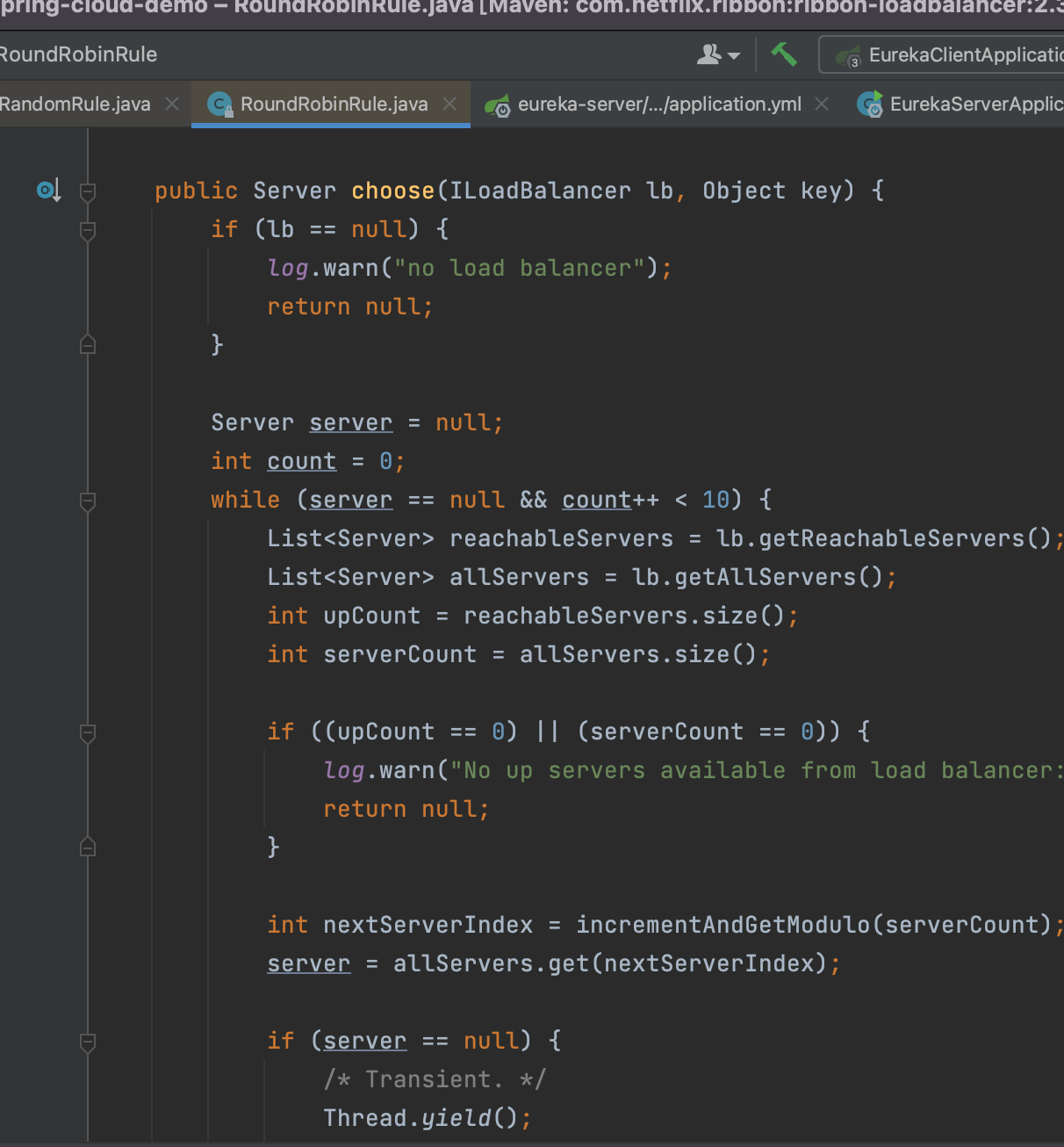
我们可以看到,这个choose和RandomRule的代码看着基本都是差不多的。
但是它这里利用了一个计数器,限制了一下循环的次数,如果10次还没有找到可用服务,就会打印一行日志:

代码逻辑基本和Random差不多,关键的是这个方法:

我们进去这个方法看一下,它是怎么获取下标的:
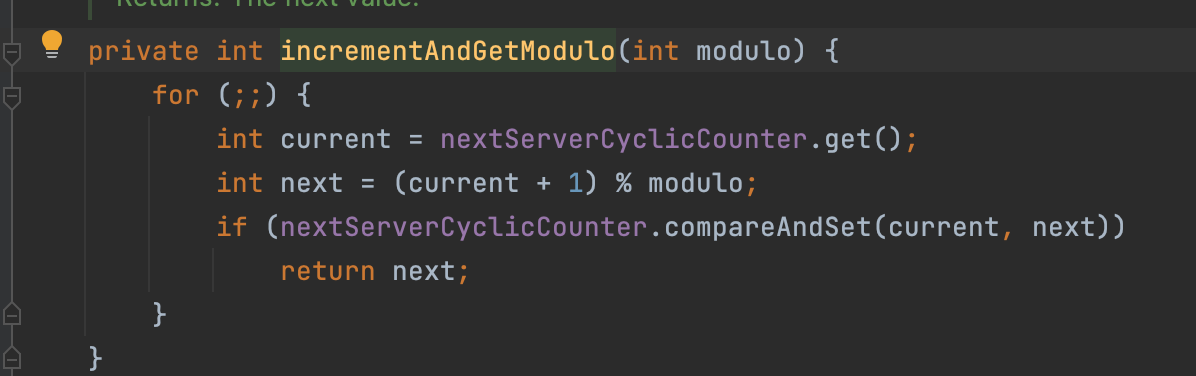
我们可以看到这里是采用了一个自旋锁的方式,这里的current就是获取的上一次访问的机器。
然后用上次访问的机器+1 与传入进来的modulo做了一个取模操作,得到了当前的下标。
这里的modulo就是外面的serverCount,比如说一共有100个server,上一次已经轮训到了第90台,那么这里就是第90台+1,然后取模100,最后得到的就是91,大家想这里为什么不直接用current+1直接返回呢?
其实是因为这个server的集合考虑到大小会发生变化,有可能你上次访问到的是第100台,这次进来第100台突然挂掉了,就会从server的List中移除了,所以我们不能单纯的进行+1,而要进行一个取模的操作。
然后下面通过CAS比对当前替换的值是否为current的值,如果是的话就替换成next了,如果不是就继续循环。
这种自旋和通过compareAndSet是一种非常常见的消耗资源很少的同步方案。
; BestAvailableRule
我们来看一下BestAvailableRule里的choose方法,
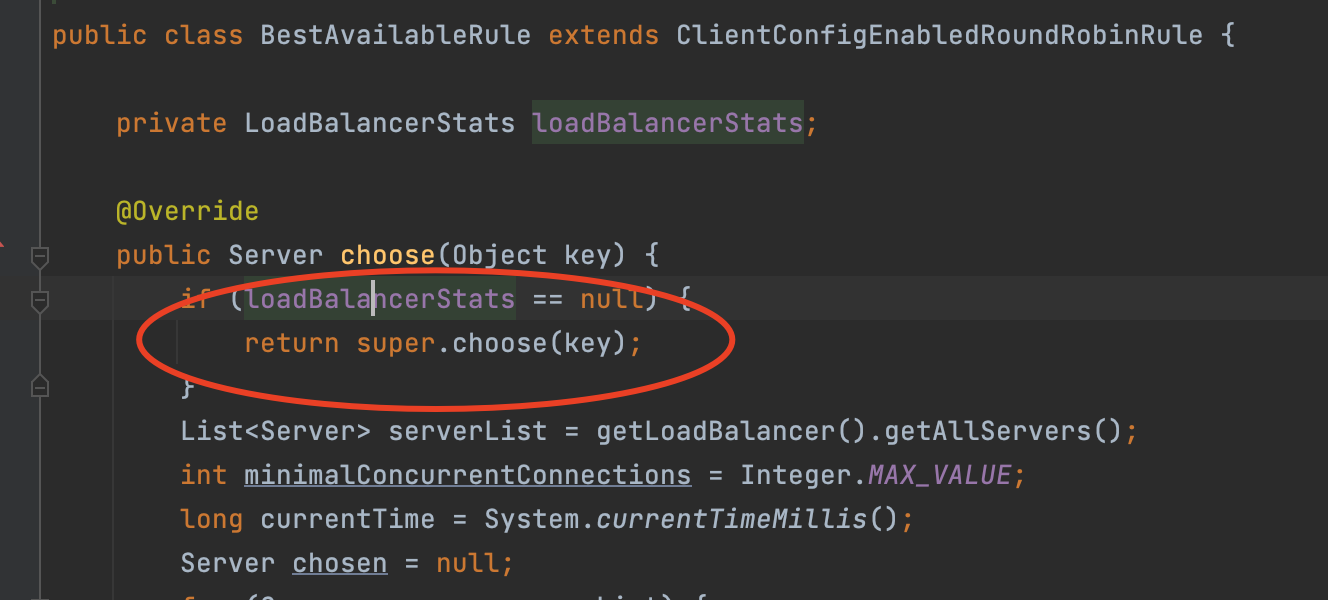
我们看这里有一个判断,如果loadBalancerStats为null的话就会调用父类的choose,进行返回。
我们看一下它的父类:
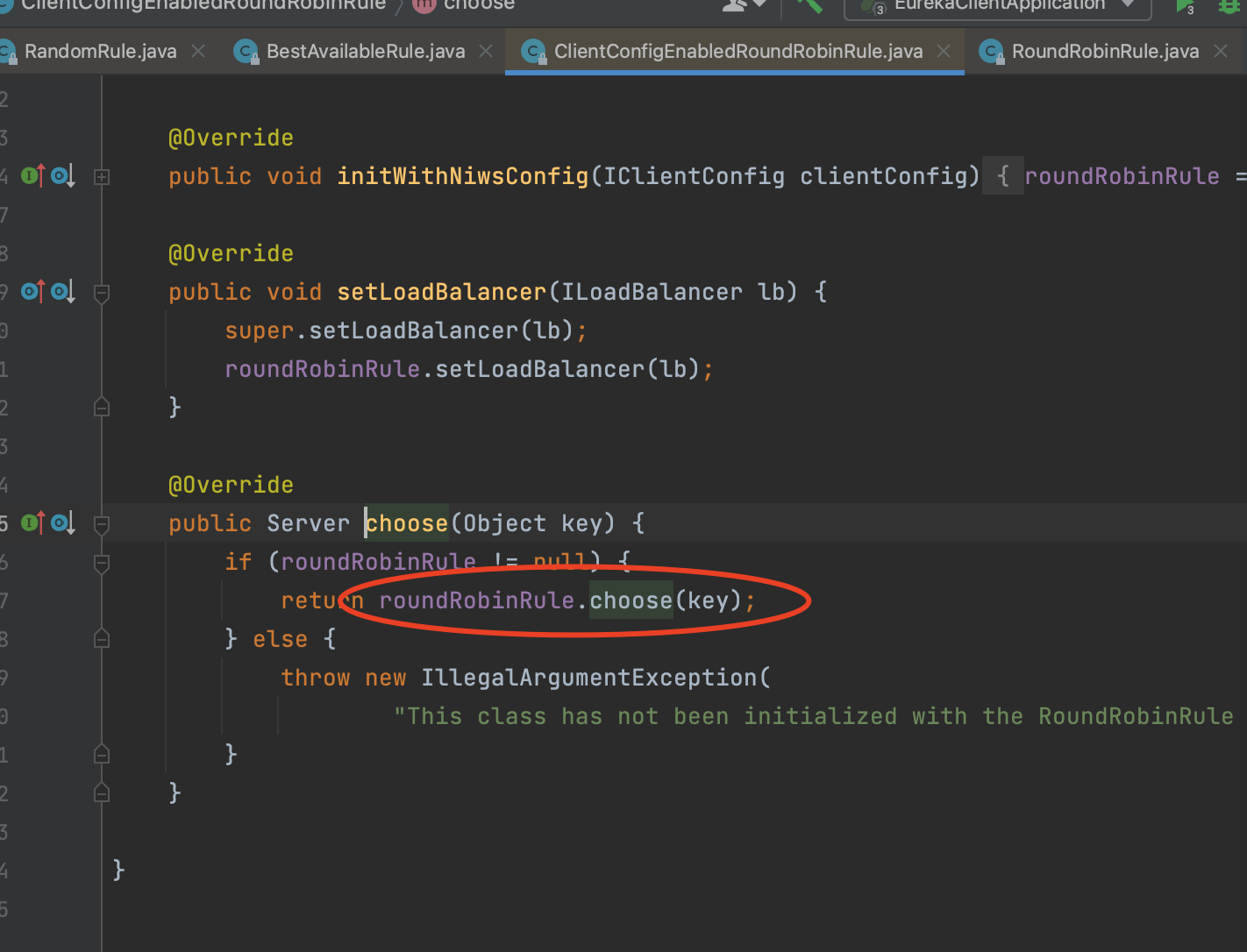
可以看到,其实这里还和RoundRobinRule有着一定的关系:

如果roundRobinRule不为空,直接调用了roundRobinRule的choose方法。
我们再回到BestAvailableRule:
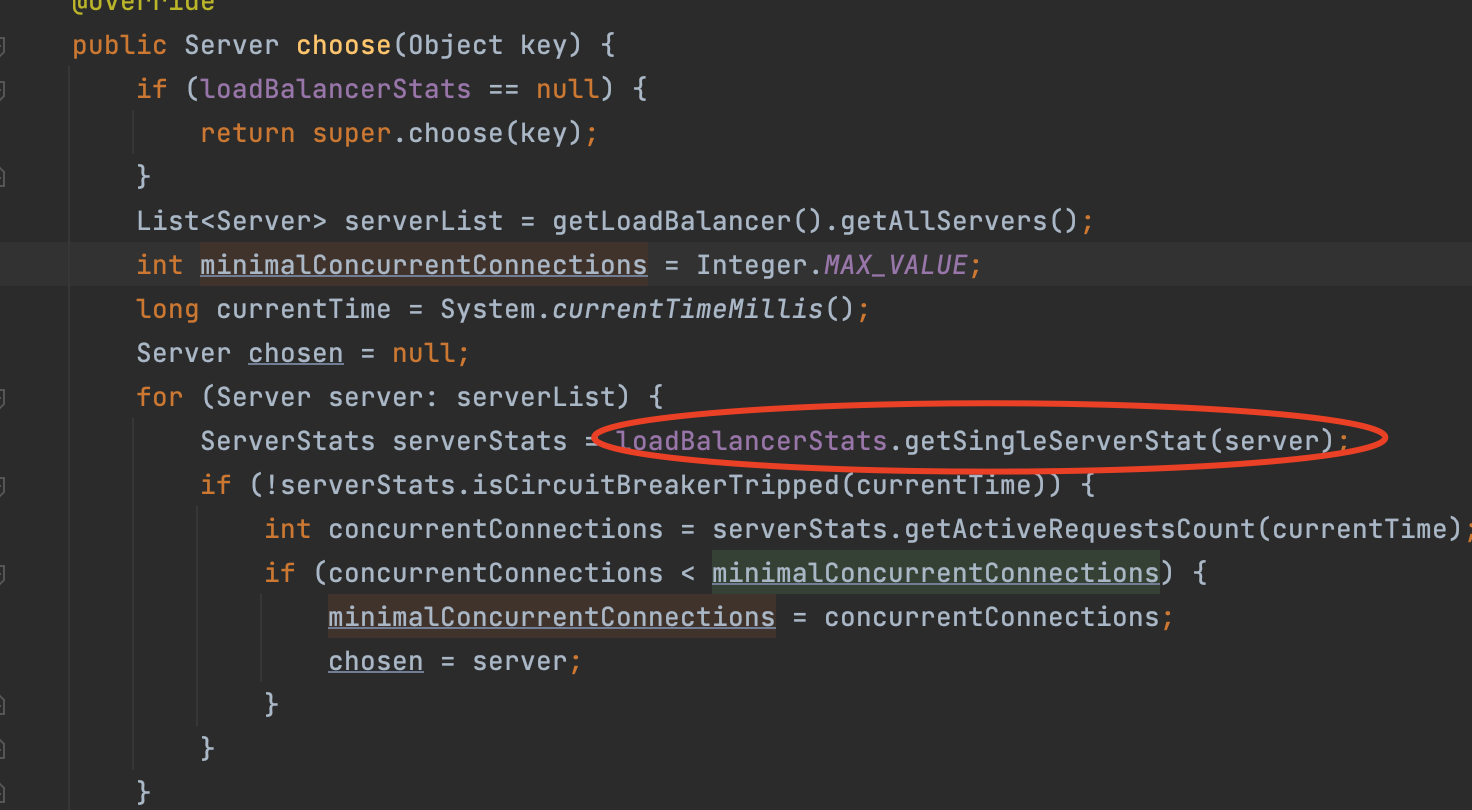
我们可以看到,在这个循环里,通过了一个loadBalancerStats获取当前服务的状态,我们点进去看看:

我们再进到getServerStats里:
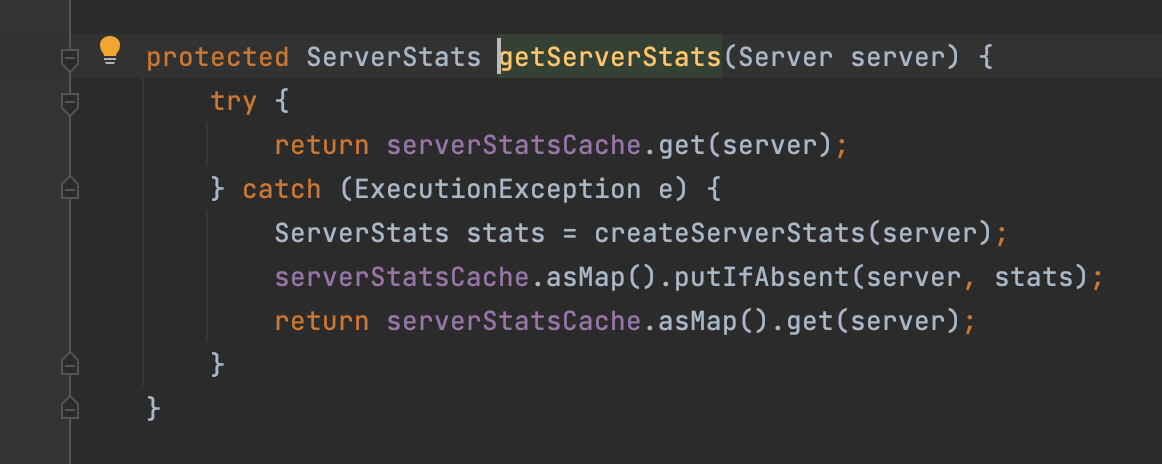
我们可以看到,它先在缓存里获取了一个serverStats,并且catch下面还有一段容错的逻辑:
就是说如果获取不到的话,就是创建一个默认的ServerStats然后放到缓存里,最后再从缓存获取一次进行返回。
最后,我们看到在这里有一个判断,当前状态是否处于熔断状态。
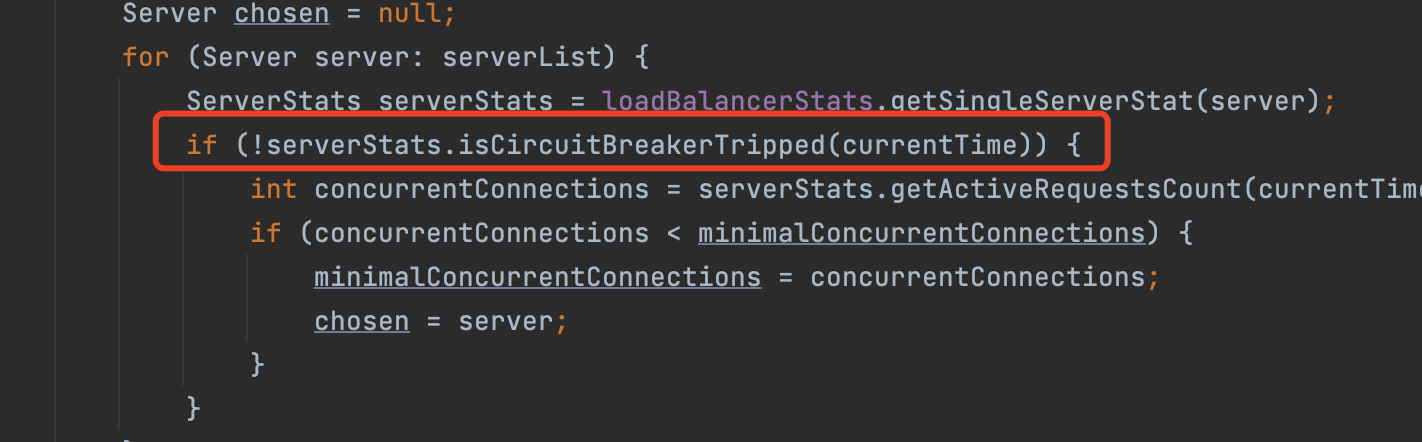
它会把当前的时间传入进去,我们跟进去看看它是什么样的判断逻辑:
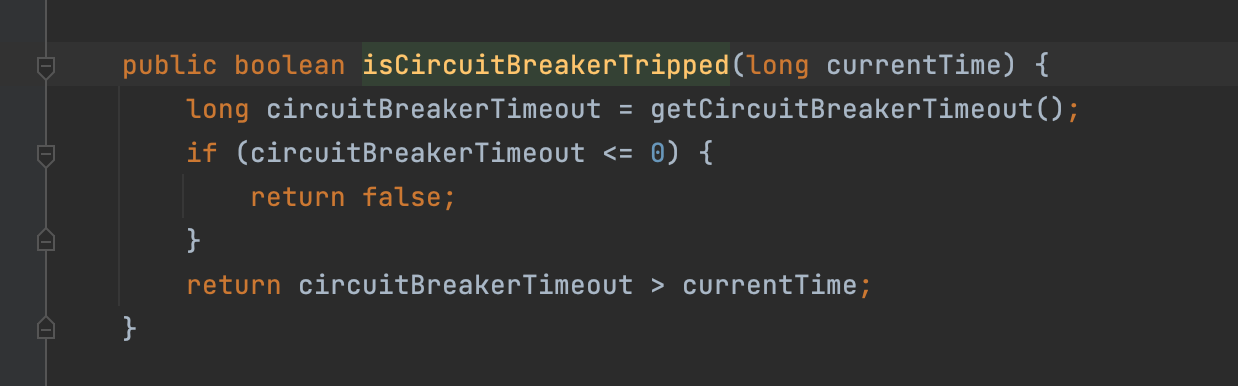
首先,它会先获取熔断的Timeout,如果小于等于0,则直接返回false,如果大于当前时间,则返回true,所谓熔断就是服务不可用,我们接触Hystrix后就会知道它的含义了。
我们看一下这个timeout是怎么计算出来的:
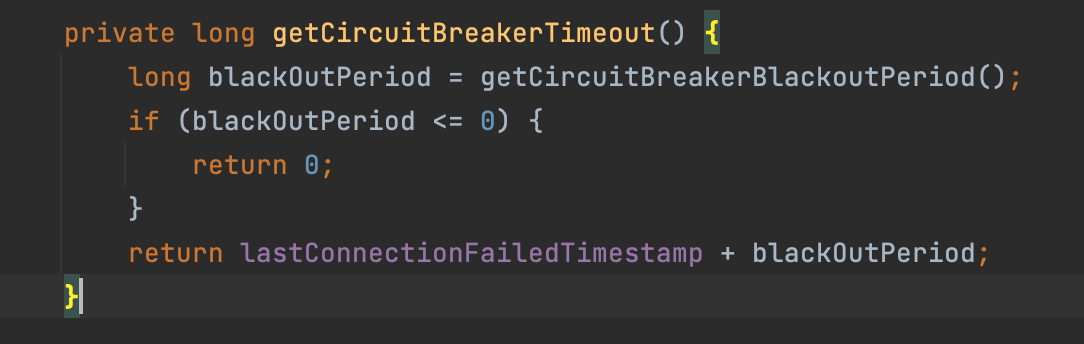
我们看到,这个有一个blackOutPeriod,我们看一下它是怎么获取的:
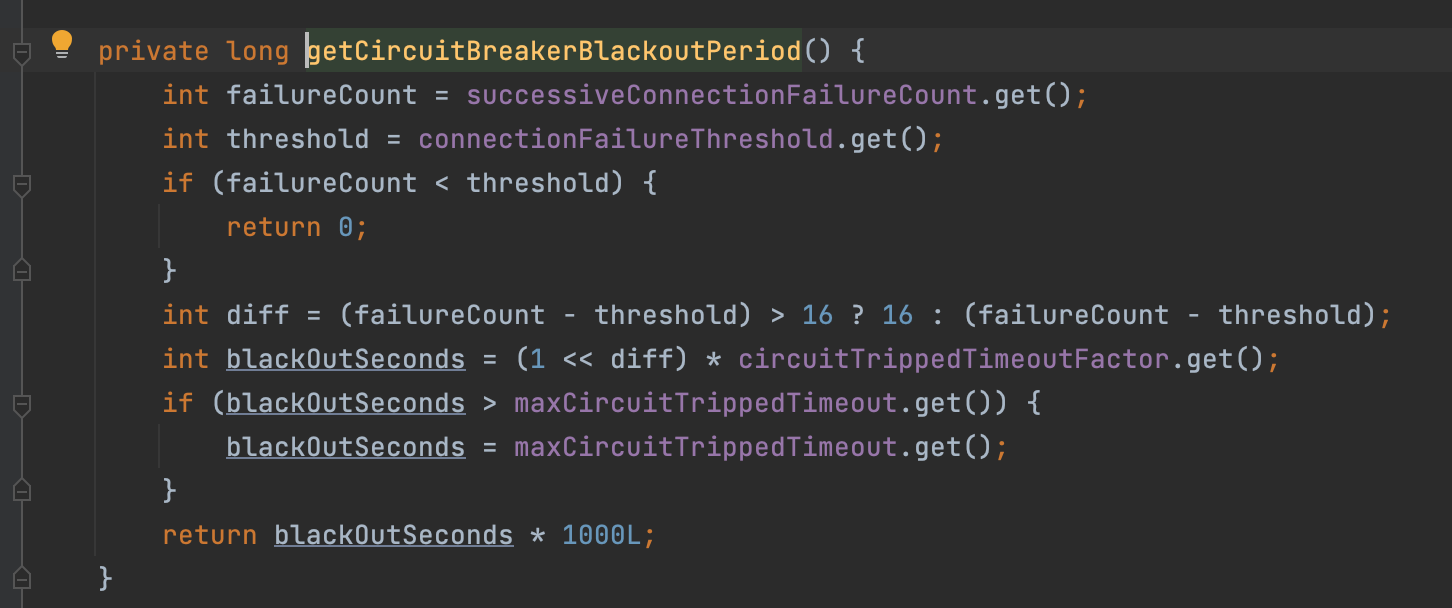
首先,它会从计数器中获取一个失败的个数,然后从一个缓存的属性中获取了一个threshold 阈值。然后判断当前失败个数是否小于阈值,如果小于则直接返回0,说明当前状态还不属于熔断。
否则,通过两者计算出一个差值,然后通过这个diff和缓存中的一些属性,计算出blackOutSecounds,然后用这个秒数乘以1000就是这个毫秒数。
拿到这个时间后:
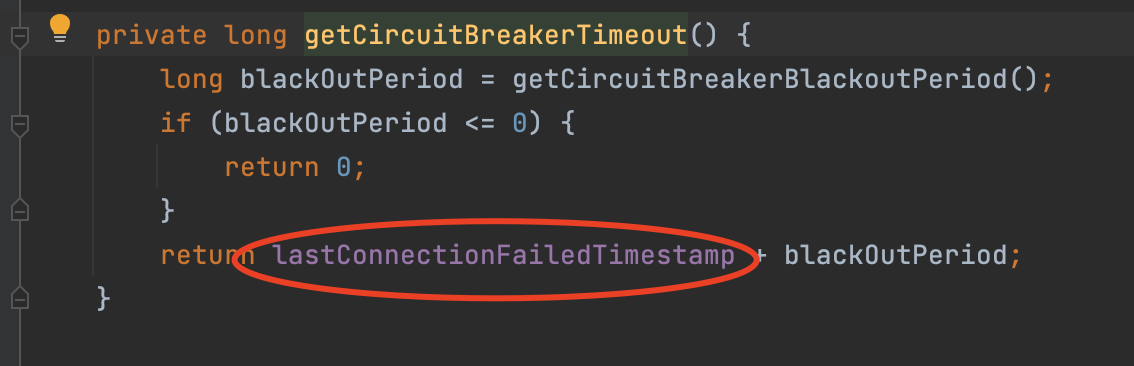
这里通过上次连接失败的时间加上这个blackOutPeriod,也就是说在上次失败后,再加上这段缓冲的时间内,它都认为是失败,也就是给了一段时间的缓冲。
最后我们再回到choose方法里:
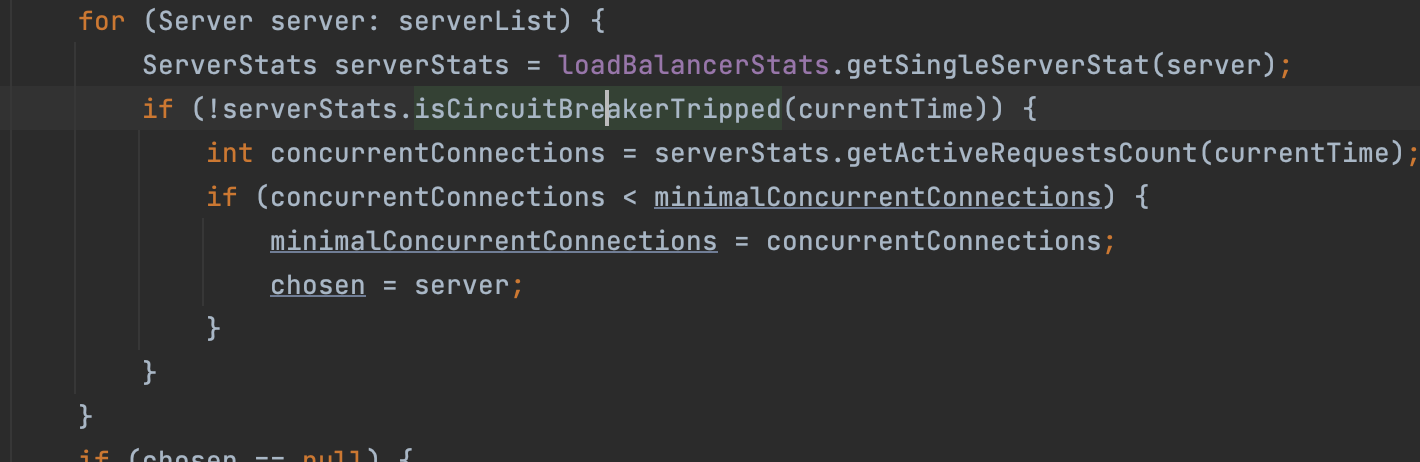
如果不是熔断状态,就会进到if里面的流程,concurrentConnections是获取到在当前时间连接到当前服务器的连接数。
获取到当前连接个数后,它会和minimalConcurrentConnections进行比较,如果当前服务器concurrentConnections小于minimalConcurrentConnections就会把concurrentConnections赋值给minimalConcurrentConnections。
最后把要选择的服务器替换成当前服务器。
我们可以看到这个for循环里没有中断条件,也就是说要遍历所有节点,直到获取到最小连接数的节点。
最后:

如果没有找到,则直接交给RoundRobinRule。
RetryRule
下面我们再来看一下这个RetryRule:
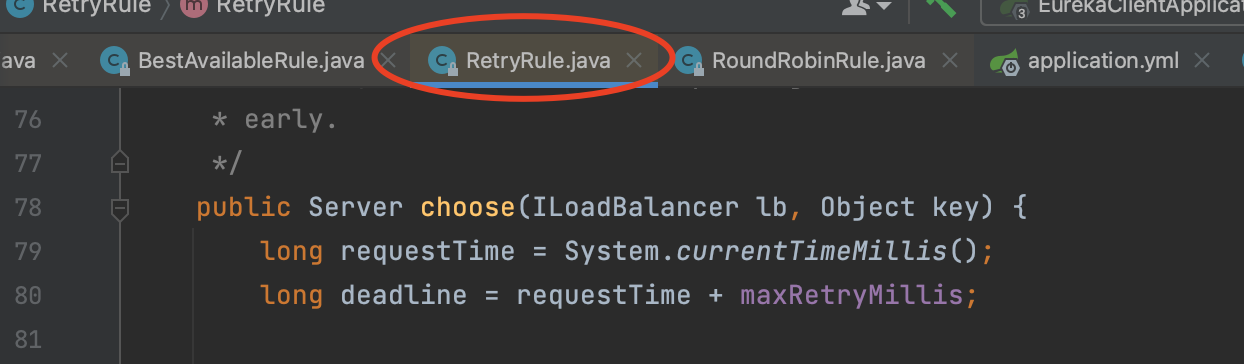
首先在它的choose方法里,先获取了当前时间,然后用当前时间加上maxRetryMillis,也就是说超过了这个时间就要停止重试。
再往下看:
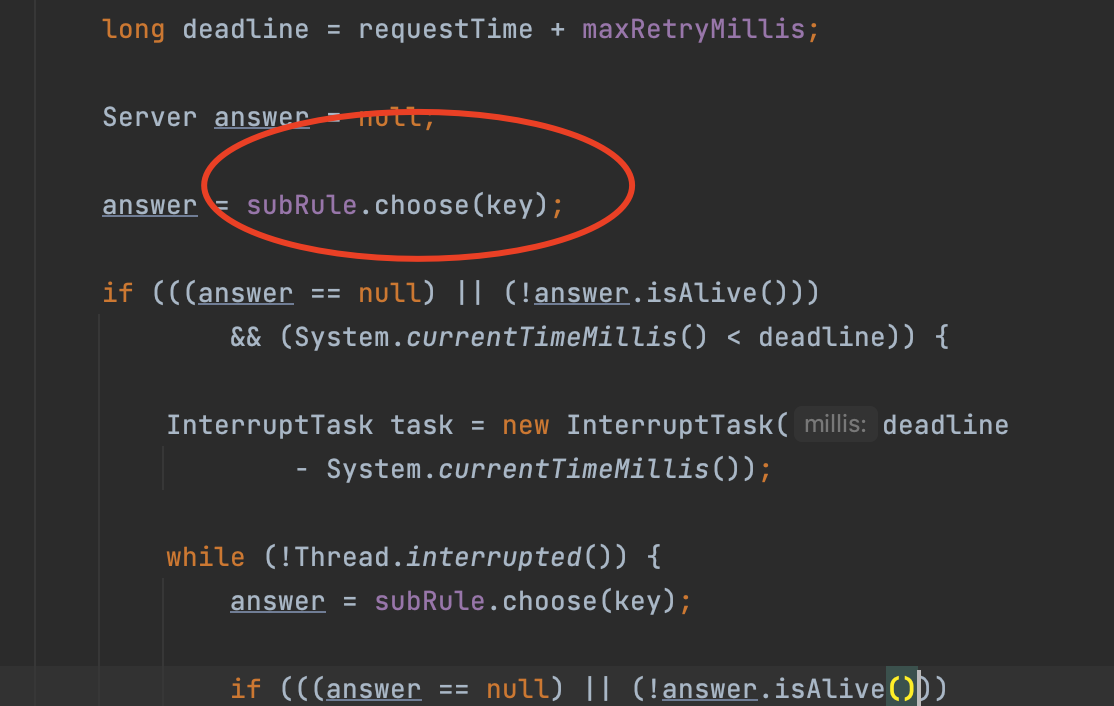
这里调用了subRule的choose方法:

可以看到,这里的subRule就是RoundRobinRule,当然这里的这个subRule是可以通过构造方法指定的。
我们继续看:
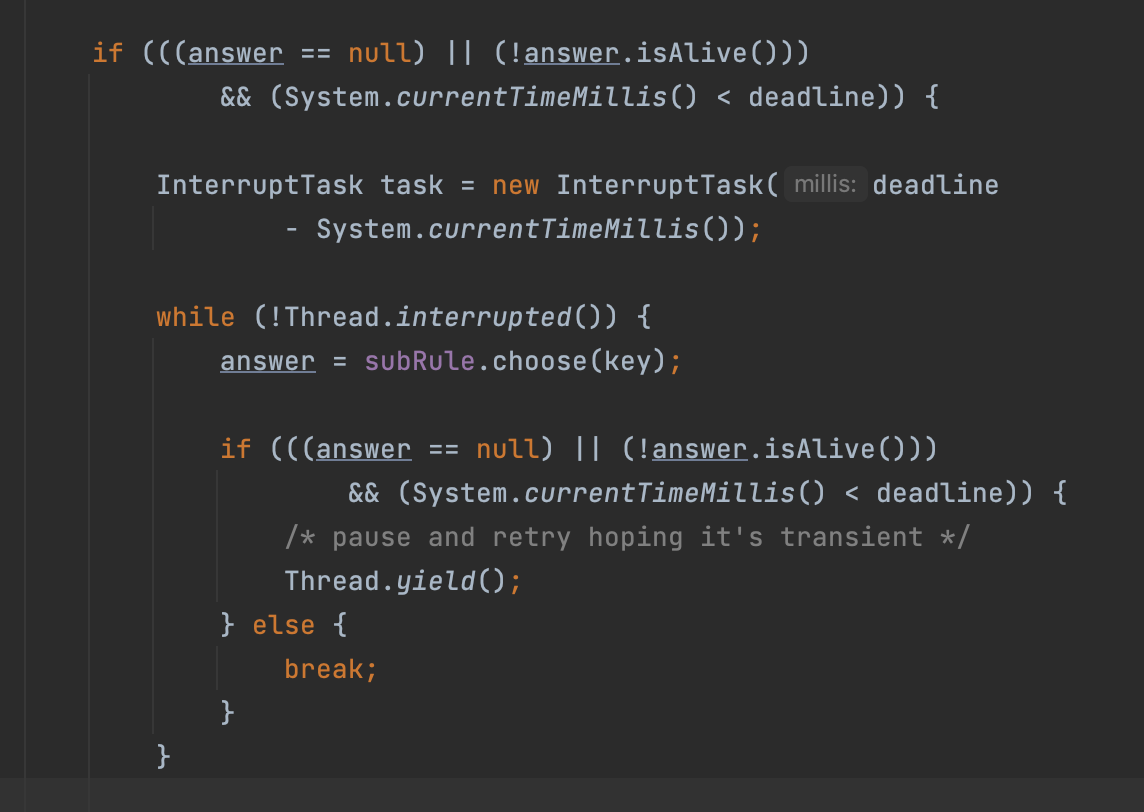
可以看到,这里的answer如果为空,或者当前时间小于最大重试时间,则可以继续重试,这个重试它依赖于while循环,首先判断线程如果被中断则中断重试,如果没有中断,则继续调用subRule,然后在循环里继续获取answer,如果又获取到了空,或者已经宕机,并且当前时间小于最大重试时间,则会把当前线程进行让步,下次循环时再判断一把。
最后:
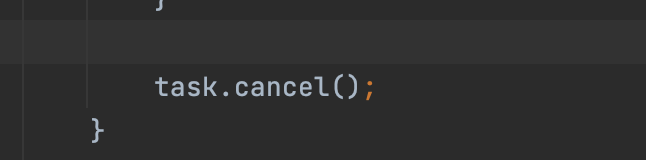
我们先看下这个task:

它这里用最大重试时间减去了当前时间,传到了InterruptTask,我们点进去看看:
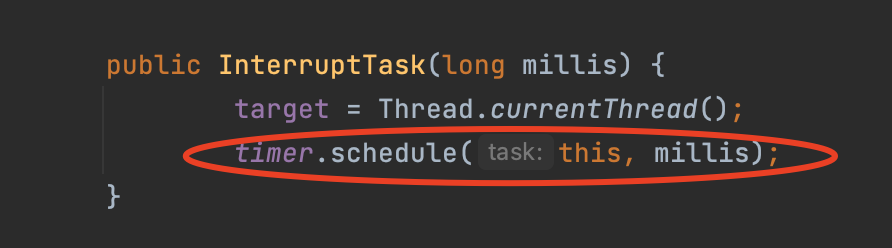
我们可以看到,这里用到了一个timer开启了一个后台任务,也就是说,过了重试时间后,通过后台任务的方式中断整个重试的流程。
所以完成这个流程后,就会关闭这个定时器。
通过阅读源码,我们不难发现RetryRule的实现还是比较简单,他比较依赖于底层具体负载均衡策略,其实它就是套了一层retry的逻辑。
Original: https://blog.csdn.net/qq_45455361/article/details/121389320
Author: 怎能止步于此
Title: 彻底搞懂Ribbon——负载均衡策略源码探究