
python爬取百度图片总体来说是比较简单的。爬虫一个网站,爬取百度图片的思路也是很有迹可循的。思路分为两大部分。第一部分(对百度图片的网页分析):百度图片是一个动态网页,怎么判断一个网页是动态网页或者说是个静态网页。也比较简单,网络上的资源也很多。简单说:如果你想爬取的内容,在页面源代码中很少(不全or没有),网址带有标志性的?。基本上就是动态网页。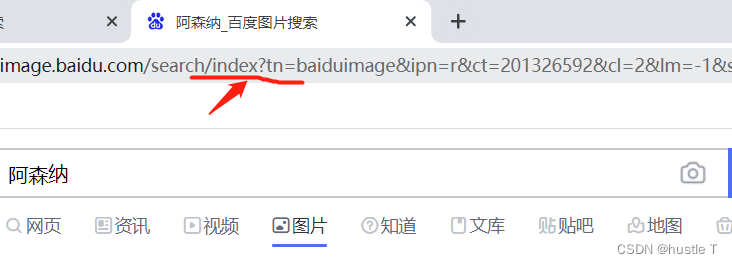
因此,基本判断百度图片的页面为动态网页。这种动态网页不断地与数据库交互。我们无法在页面源代码中获取照片地址,或者可能有20张图片(在一些网站上)。静态网页基本上就是我们在页面源代码中可以找到的所有内容。因此,完成了第一部分的思路分析,即我们抓取动态网页。
[En]
Therefore, it is basically judged that the page of Baidu pictures is a dynamic web page. This kind of dynamic web page constantly interacts with the database. We can't get the photo address in the page source code, or there may be 20 pictures (on some websites). The static web page is basically all the content we can find in the page source code. So the first part of the train of thought analysis is completed, that is, we crawl dynamic web pages.
思路第二部分(代码实现爬取图片):首先打开浏览器的开发者工具(F12),然后锁定network(网络),再锁定fetch/xhr后。json中,就藏着一个个图像的相关信息。上图吧!
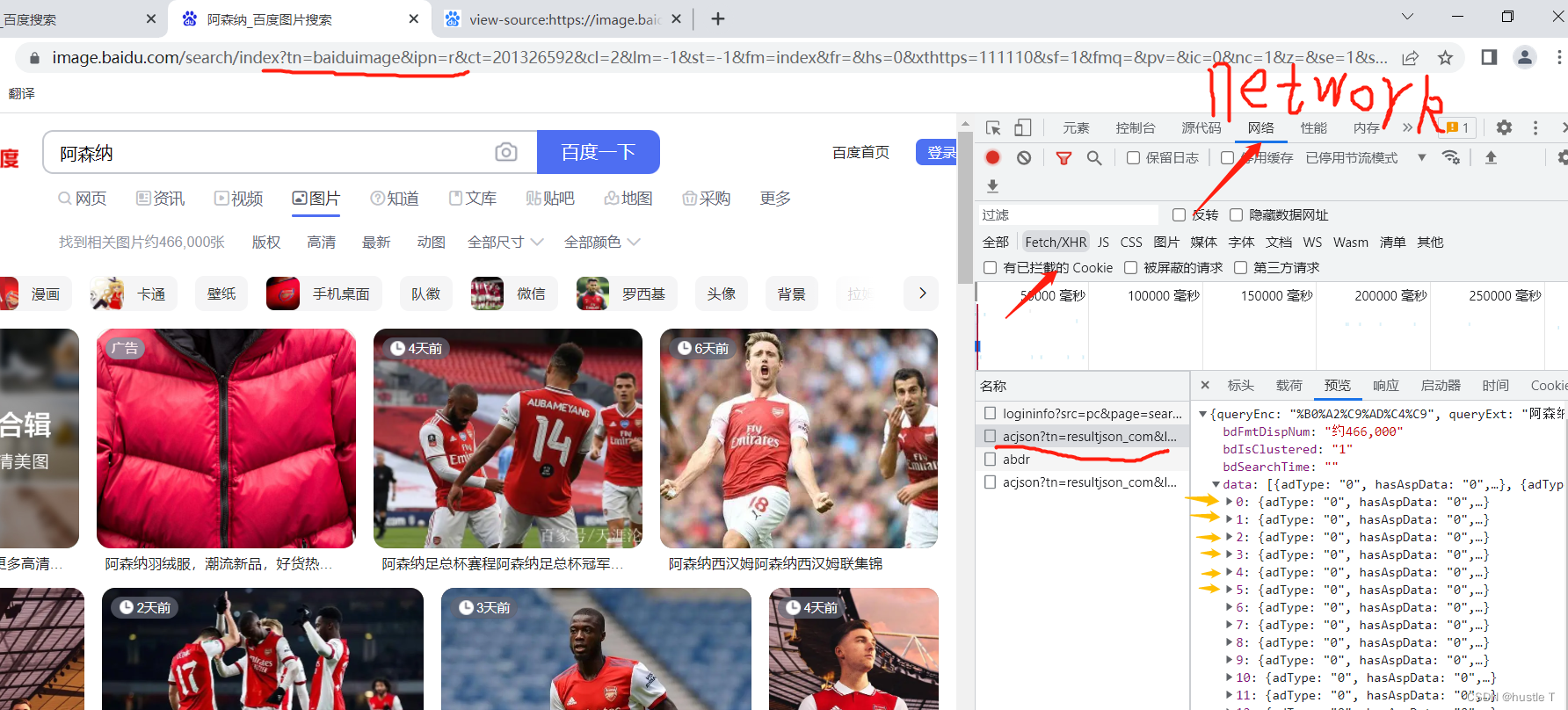
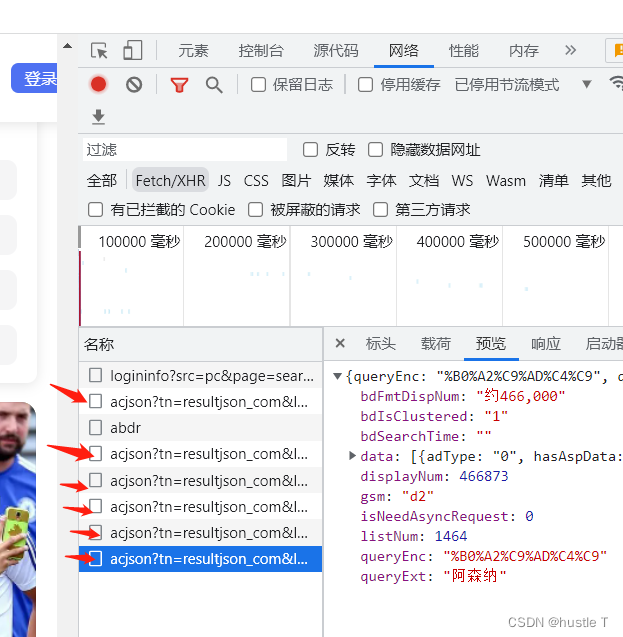
每当你访问你继续访问更多的照片,那么它又会传入一个新的以acjson开头的文件,,这就能很形象的感觉到动态了。而再这些以acjson开头的文件中,其页面源代码包含了其新的照片的访问地址,你只需要让程序去访问acjson的网页里面的源代码,就可以利用正则表达式去匹配出每个照片的地址,最后访问图片,下载到你的电脑上。或者其他的地方。思路就是如此。所以找到这些acjson文件的规律:每个里面的data数有三十个对应三十张照片,其acjson的url地址pn每次以三十为等差数列。那么其规律就出来了。我们其实嵌套两个循环就可以完成这个demo了,第一层访问acjson开头的文件的源代码,第二层就是每张照片的url,最后写入到电脑中。完成!!!
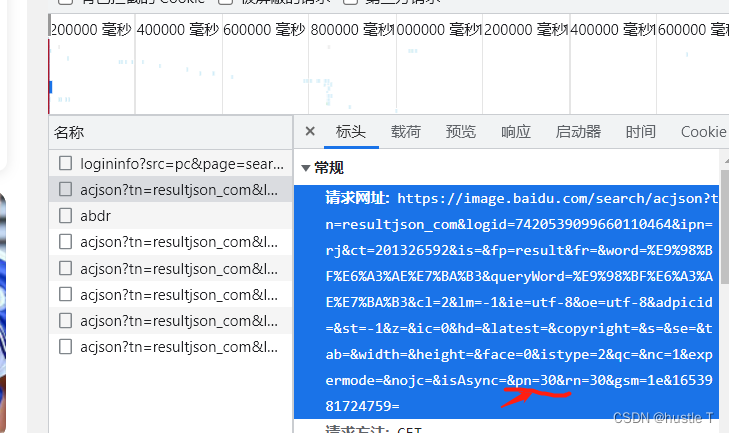
acjson的url地址在标头中,其规律pn的变化(后面的其他参数不用管的)
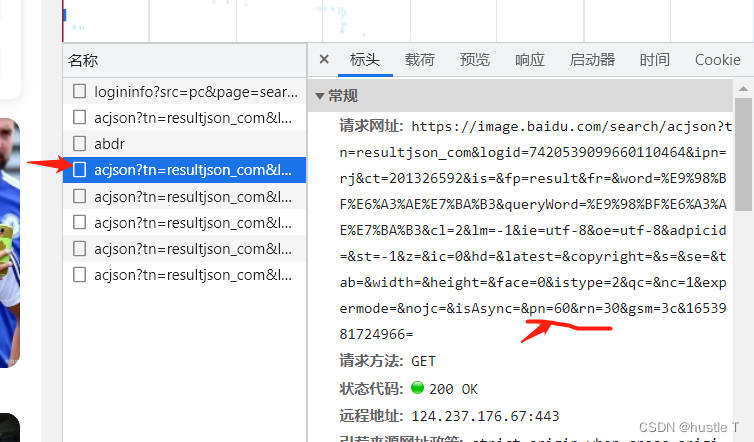
那么思路懂了,代码如下。还有一点是爬虫访问百度图片,很可能会遇到百度验证和被发现,弹出forbidden spider 。要去伪装自己是一个浏览器的样子。在你的请求标头中,复制下来浏览器的各种参数就行了!
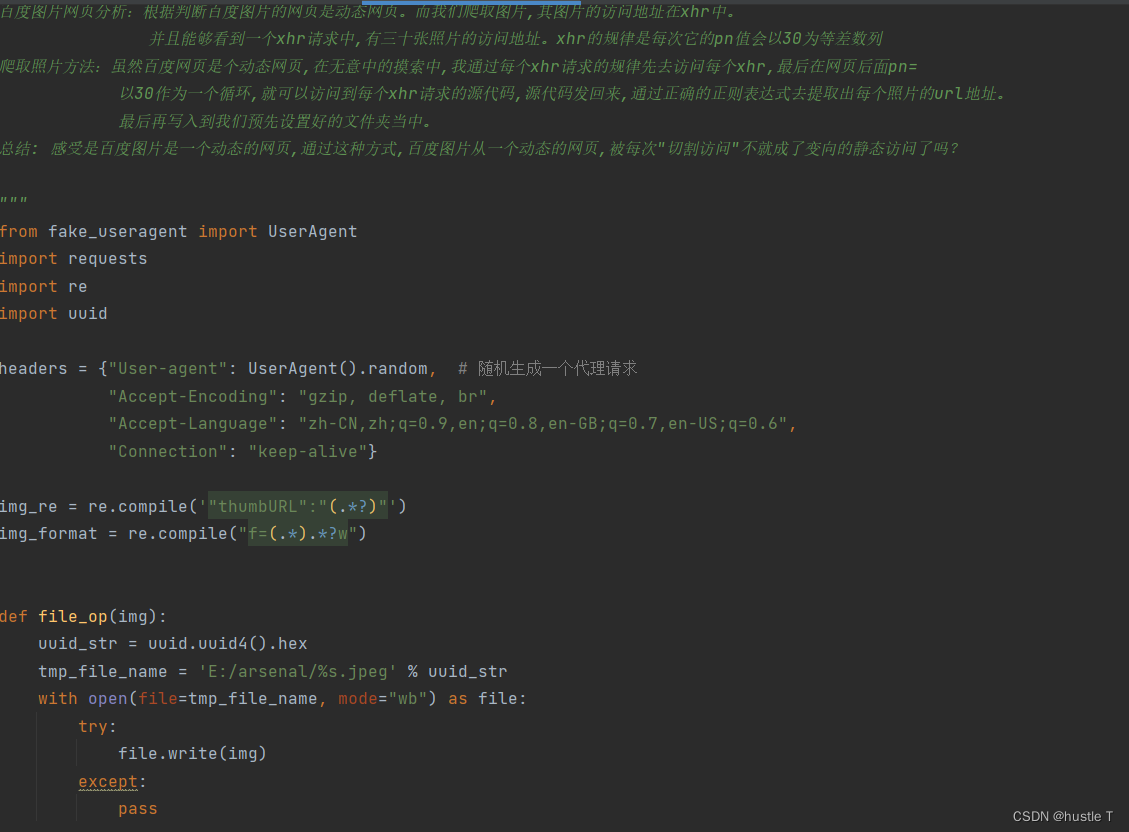
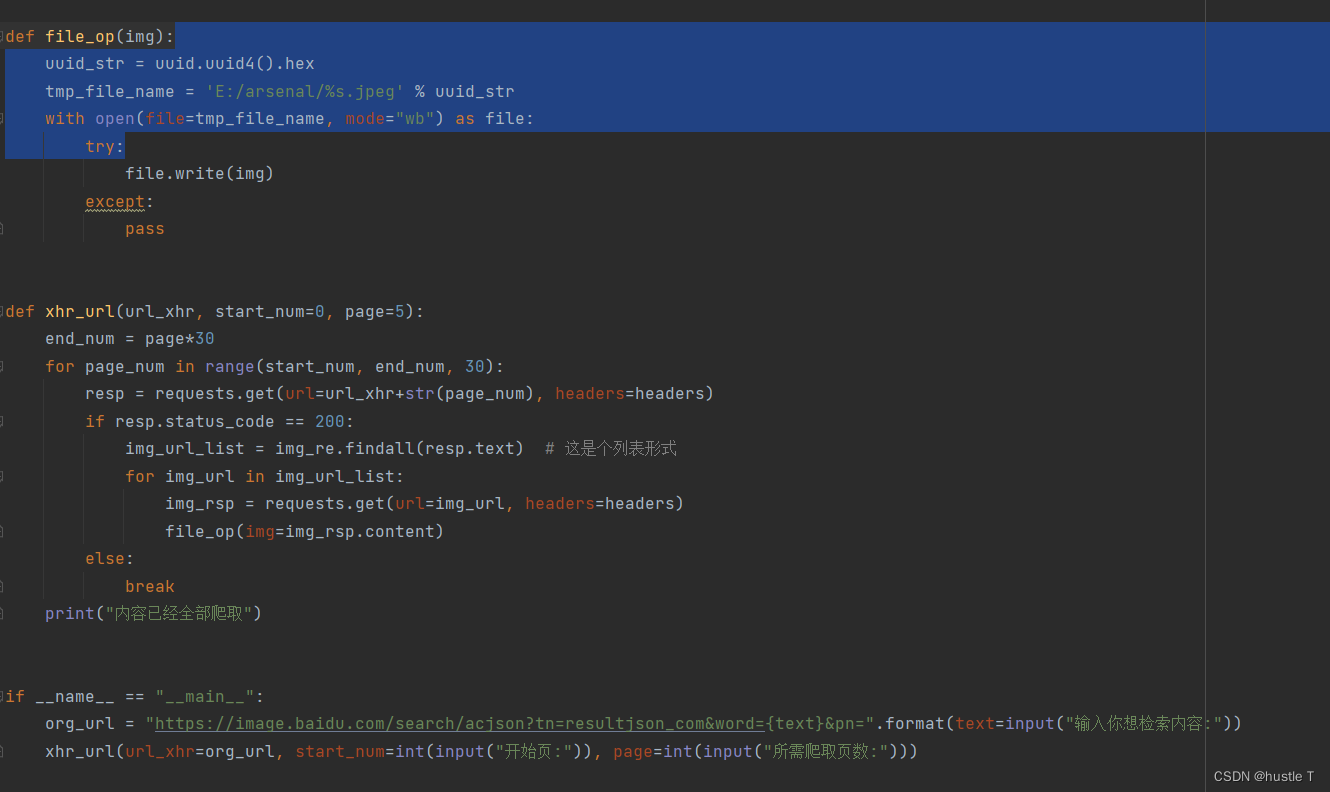
```