
统计表中常常以本年累计、上年同期(累计)、当期(例如当月)完成、上月完成为统计数据,并进行同比、环比分析。如下月报统计表所示样例,本文将使用Python Pandas工具进行统计。
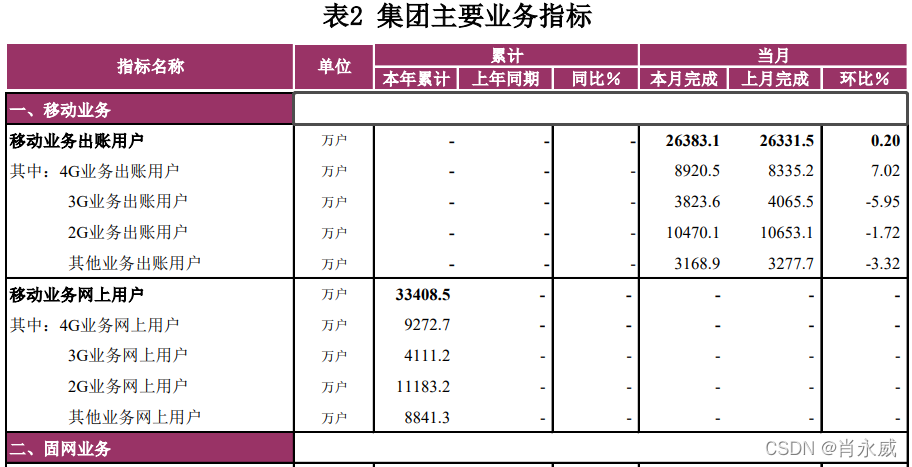
其中:
- (本年)累计:是指本年1月到截止月份的合计数
- (上年)同期(累计):是指去年1月到与本年累计所对应截止月份的合计数
- 同比(增长率)=(本期数-同期数)/同期数*100%
- 环比(增长率)=(本期数-上期数)/上期数*100%
注:这里的本期是指本月完成或当月完成,上期数是指上月完成。
示例数据:
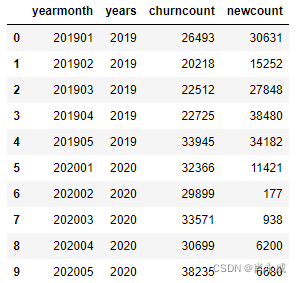
注:为了演示方便,本案例数据源仅使用2年,且每年5个月的数据。
; 1. (本年)累计
在统计分析的发展中,按年和按月积累一些统计数据是相当常见的。对于数据,就是按规则逐行累计数据。
[En]
In the development of statistical analysis, it is quite common to accumulate some statistical data on an annual and monthly basis. For data, it is to accumulate data row by row according to the rules.
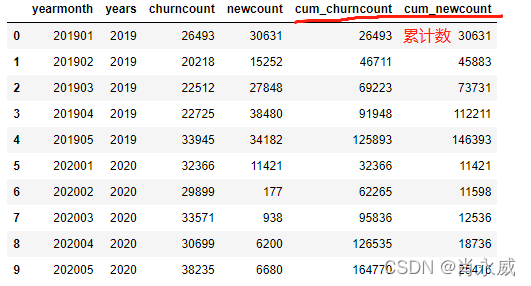
Pandas中的cumsum()函数可以实现按某时间维度累计需求。
import pandas as pd
df = pd.read_csv('data2021.csv')
cum_columns_name = ['cum_churncount','cum_newcount']
df[cum_columns_name] = df[['years','churncount','newcount']].groupby(['years']).cumsum()
注:其中分组'years'是指年度时间维度累计。
计算结果如下:
2. (上年)同期累计
对于(上年)同期累计,将直接取上一年度累计值的同月份数据。pandas DataFrame.shift()函数可以把数据移动指定的行数。
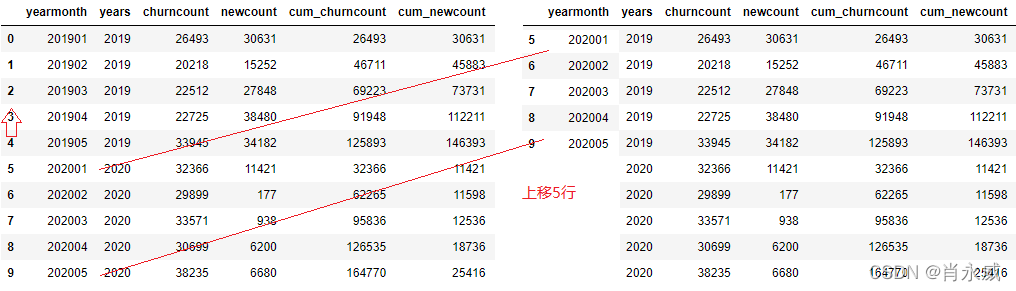
接续上列,读取同期数据。首先是把'yearmonth'上移五行,如上图所示得到新的DataFrame,通过'yearmonth'进行两表数据关联(左关联:左侧为原表,右侧为移动后的新表),实现去同期数据效果。
cum_columns_dict = {'cum_churncount':'cum_same_period_churncount',
'cum_newcount':'cum_same_period_newcount'}
df_cum_same_period = df[['cum_churncount','cum_newcount','yearmonth']].copy()
df_cum_same_period = df_cum_same_period.rename(columns=cum_columns_dict)
df_cum_same_period.loc[:,'yearmonth'] = df_cum_same_period['yearmonth'].shift(-5)
df = pd.merge(left=df,right=df_cum_same_period,on='yearmonth',how='left')
3. 上月(完成)
取上月的数据,使用pandas DataFrame.shift()函数把数据移动指定的行数。
接续上列,读取上期数据。(与取同期原理一样,略)
last_mnoth_columns_dict = {'churncount':'last_month_churncount',
'newcount':'last_month_newcount'}
df_last_month = df[['churncount','newcount','yearmonth']].copy()
df_last_month = df_last_month.rename(columns=last_mnoth_columns_dict)
df_last_month.loc[:,'yearmonth'] = df_last_month['yearmonth'].shift(-1)
df = pd.merge(left=df,right=df_last_month,on='yearmonth',how='left')
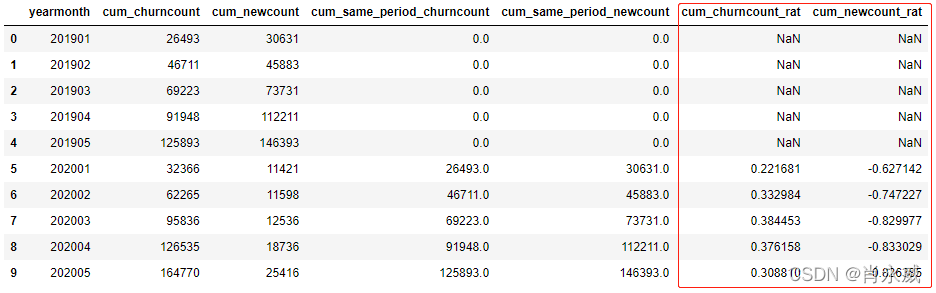
4. 同比(增长率)
计算同比涉及到除法,需要剔除除数为零的数据。
df.fillna(0,inplace=True)
df.loc[df['cum_same_period_churncount']!=0,'cum_churncount_rat'] = (df['cum_churncount']-df['cum_same_period_churncount'])/df['cum_same_period_churncount']
df.loc[df['cum_same_period_newcount']!=0,'cum_newcount_rat'] = (df['cum_newcount']-df['cum_same_period_newcount'])/df['cum_same_period_newcount']
df[['yearmonth','cum_churncount','cum_newcount','cum_same_period_churncount','cum_same_period_newcount','cum_churncount_rat','cum_newcount_rat']]
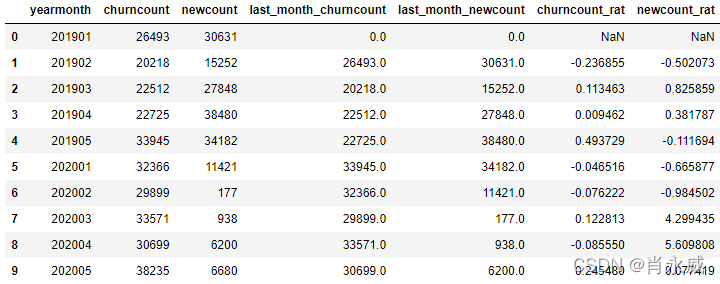
5. 环比(增长率)
df.loc[df['last_month_churncount']!=0,'churncount_rat'] = (df['churncount']-df['last_month_churncount'])/df['last_month_churncount']
df.loc[df['last_month_newcount']!=0,'newcount_rat'] = (df['newcount']-df['last_month_newcount'])/df['last_month_newcount']
df[['yearmonth','churncount','newcount','last_month_churncount','last_month_newcount','churncount_rat','newcount_rat']]
6. 总结
pandas做统计计算功能方法比较多,这里总结用到的技术有累计cumsum()函数、移动数据shift()函数、表合并关联merge()函数,以及通过loc条件修改数据。
Original: https://blog.csdn.net/xiaoyw/article/details/122979421
Author: 肖永威
Title: Pandas常用累计、同比、环比等统计方法实践案例