
公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
本文主要是记录Pandas中单层索引的一些基本操作。

; 10种索引
下面简单回顾下之前学习创建的10种索引:
pd.Index
In [1]:
import pandas as pd
import numpy as np
In [2]:
# 指定类型和名称
s1 = pd.Index([1,2,3,4,5,6,7],
dtype="int",
name="Peter")
s1
Out[2]:
Int64Index([1, 2, 3, 4, 5, 6, 7], dtype='int64', name='Peter')
pd.RangeIndex
指定整数范围内的不可变索引
In [3]:
s2 = pd.RangeIndex(0,20,2)
s2
Out[3]:
RangeIndex(start=0, stop=20, step=2)
pd.Int64Index
64位整数型索引
In [4]:
s3 = pd.Int64Index([1,2,3,4,5,6,7,8],name="Peter")
s3
Out[4]:
Int64Index([1, 2, 3, 4, 5, 6, 7, 8], dtype='int64', name='Peter')
pd.UInt64Index
无符号整数索引
In [5]:
s4 = pd.UInt64Index([1, 2.0, 3, 4],name="Tom")
s4
Out[5]:
UInt64Index([1, 2, 3, 4], dtype='uint64', name='Tom')
pd.Float64Index
64位浮点型的索引
In [6]:
s5 = pd.Float64Index([1.5, 2.4, 3.7, 4.9],name="peter")
s5
Out[6]:
Float64Index([1.5, 2.4, 3.7, 4.9], dtype='float64', name='peter')
pd.IntervalIndex
新的间隔索引 IntervalIndex 通常使用 interval_range()函数来进行构造,它使用的是数据或者数值区间,基本用法:
In [7]:
s6 = pd.interval_range(start=0, end=6, closed="left")
s6
Out[7]:
IntervalIndex([[0, 1), [1, 2), [2, 3), [3, 4), [4, 5), [5, 6)],
closed='left',
dtype='interval[int64]')
pd.CategoricalIndex
In [8]:
s7 = pd.CategoricalIndex(
# 待排序的数据
["S","M","L","XS","M","L","S","M","L","XL"],
# 指定分类顺序
categories=["XS","S","M","L","XL"],
# 排需
ordered=True,
# 索引名字
name="category"
)
s7
Out[8]:
CategoricalIndex(['S', 'M', 'L', 'XS', 'M', 'L', 'S', 'M', 'L', 'XL'],
categories=['XS', 'S', 'M', 'L', 'XL'],
ordered=True,
name='category',
dtype='category')
pd.DatetimeIndex
以时间和日期作为索引,通过date_range函数来生成,具体例子为:
In [9]:
# 日期作为索引,D代表天
s8 = pd.date_range("2022-01-01",periods=6, freq="D")
s8
Out[9]:
DatetimeIndex(['2022-01-01', '2022-01-02', '2022-01-03',
'2022-01-04','2022-01-05', '2022-01-06'],
dtype='datetime64[ns]', freq='D')
pd.PeriodIndex
pd.PeriodIndex是一个专门针对周期性数据的索引,方便针对具有一定周期的数据进行处理,具体用法如下:
In [10]:
s9 = pd.PeriodIndex(['2022-01-01', '2022-01-02',
'2022-01-03', '2022-01-04'],
freq = '2H')
s9
Out[10]:
PeriodIndex(['2022-01-01 00:00', '2022-01-02 00:00',
'2022-01-03 00:00', '2022-01-04 00:00'],
dtype='period[2H]', freq='2H')
pd.TimedeltaIndex
In [11]:
data = pd.timedelta_range(start='1 day', end='3 days', freq='6H')
data
Out[11]:
TimedeltaIndex(['1 days 00:00:00', '1 days 06:00:00', '1 days 12:00:00',
'1 days 18:00:00', '2 days 00:00:00', '2 days 06:00:00',
'2 days 12:00:00', '2 days 18:00:00', '3 days 00:00:00'],
dtype='timedelta64[ns]', freq='6H')
In [12]:
s10 = pd.TimedeltaIndex(data)
s10
Out[12]:
TimedeltaIndex(['1 days 00:00:00', '1 days 06:00:00', '1 days 12:00:00',
'1 days 18:00:00', '2 days 00:00:00', '2 days 06:00:00',
'2 days 12:00:00', '2 days 18:00:00', '3 days 00:00:00'],
dtype='timedelta64[ns]', freq='6H')
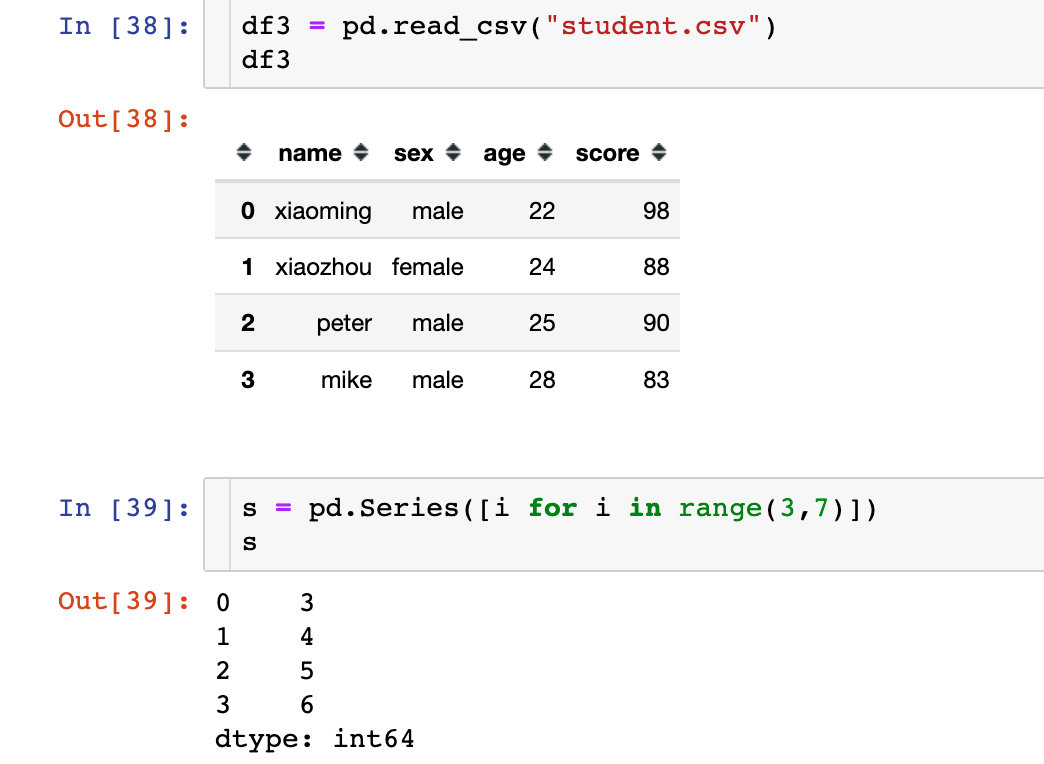
操作1:读取文件时自动生成索引
默认情况下,pandas以0到 len(df)-1 的自然数为索引
In [13]:
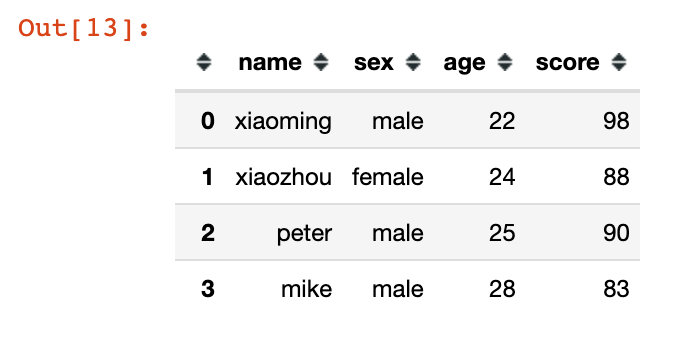
df = pd.read_csv("student.csv")
df
df.index
RangeIndex(start=0, stop=4, step=1)
我们可以指定某个字段作为索引:
操作2:读取数据时指定索引
在读取文件的时候可以指定一个或者多个字段作为索引:
In [15]:
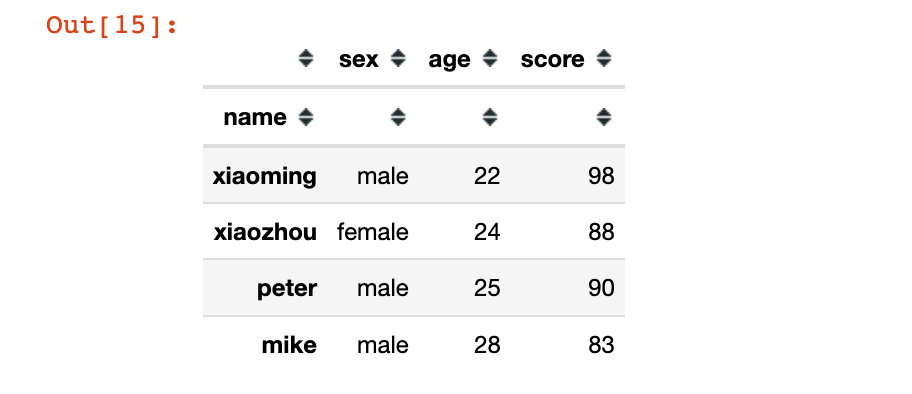
df1 = pd.read_csv("student.csv", index_col="name")
df1
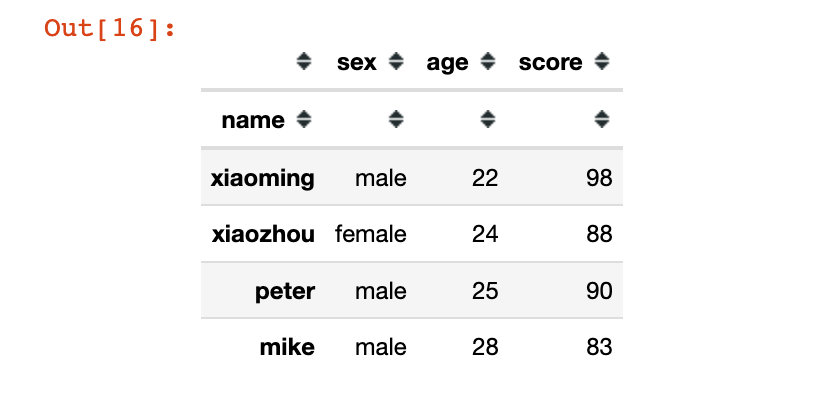
pd.read_csv("student.csv", index_col=0)
我们查看具体的索引:
In [17]:
df1.index
Out[17]:
Index(['xiaoming', 'xiaozhou', 'peter', 'mike'], dtype='object', name='name')
同时指定多个字段作为索引:
In [18]:
df2 = pd.read_csv("student.csv", index_col=["name","sex"])
df2
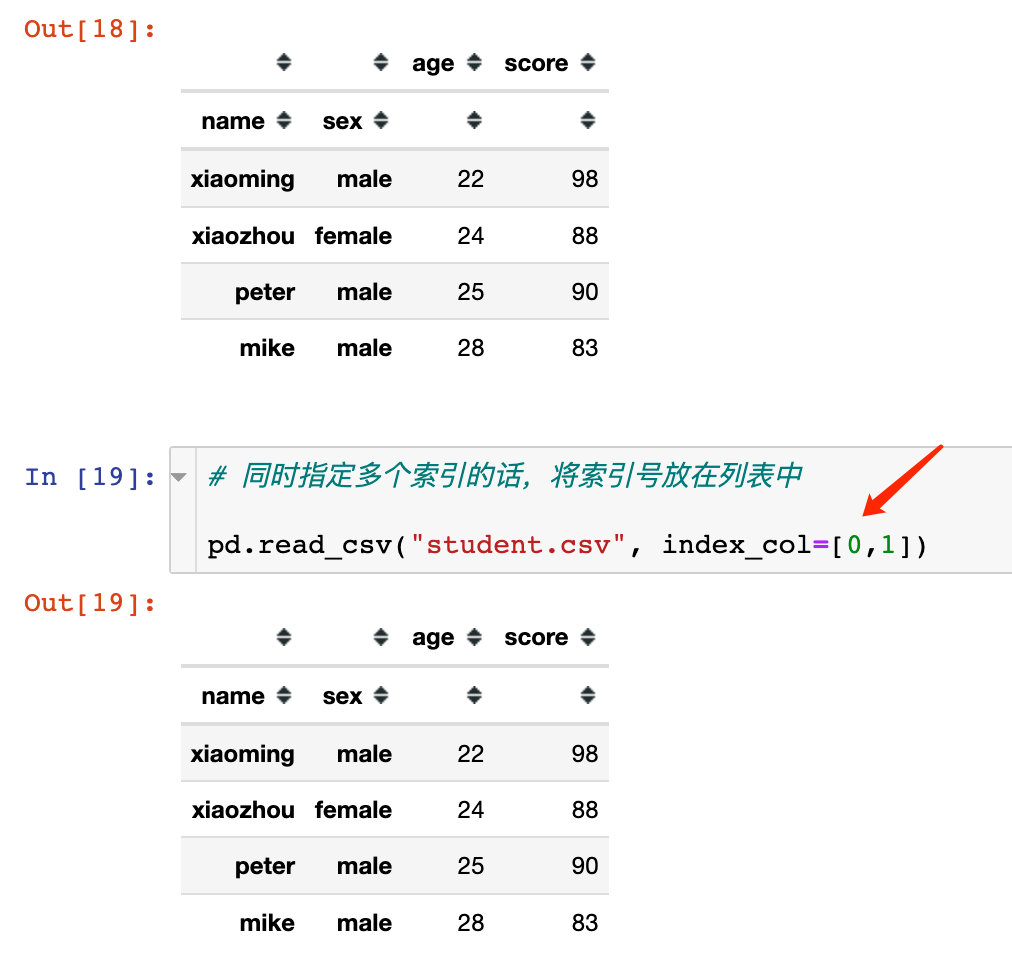
我们发现此时数据框df2的索引是一个多层索引MultiIndex
In [20]:
df2.index
Out[20]:
MultiIndex([('xiaoming', 'male'),
('xiaozhou', 'female'),
( 'peter', 'male'),
( 'mike', 'male')],
names=['name', 'sex'])
操作3:指定索引set_index
在读取之后可以指定字段作为索引
指定单个索引
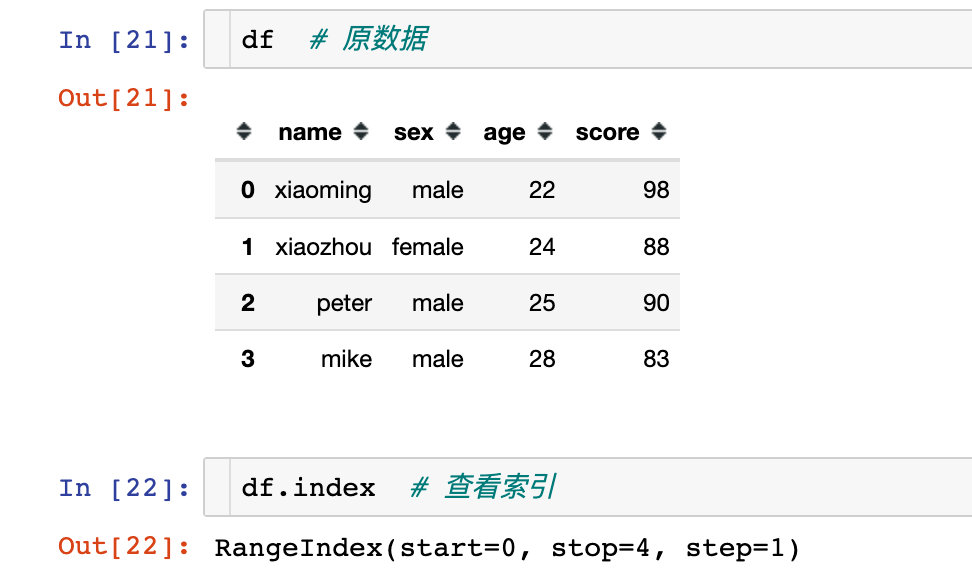
比如,我们把name字段作为索引:使用的是set_index函数
In [23]:
df.set_index("name")
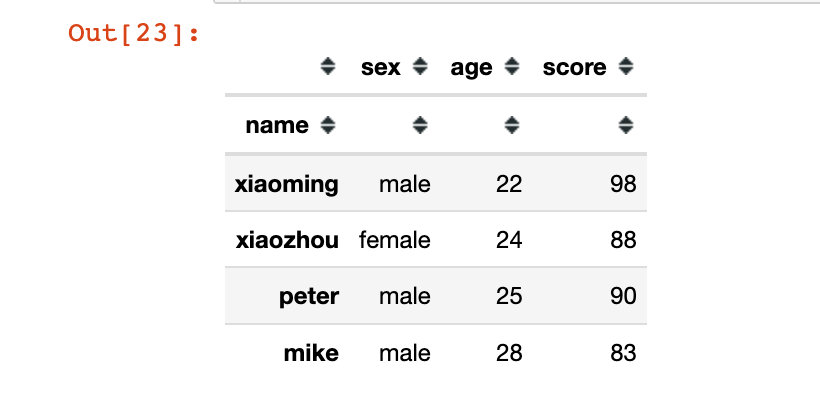
我们发现原始的df是没有变化的:
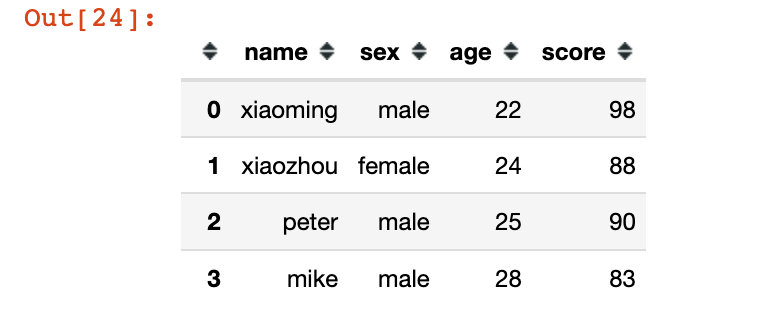
如果想直接改变df,有两种方法:
1、赋值法
通过对比赋值前后df的id,我们发现它们是不同的:
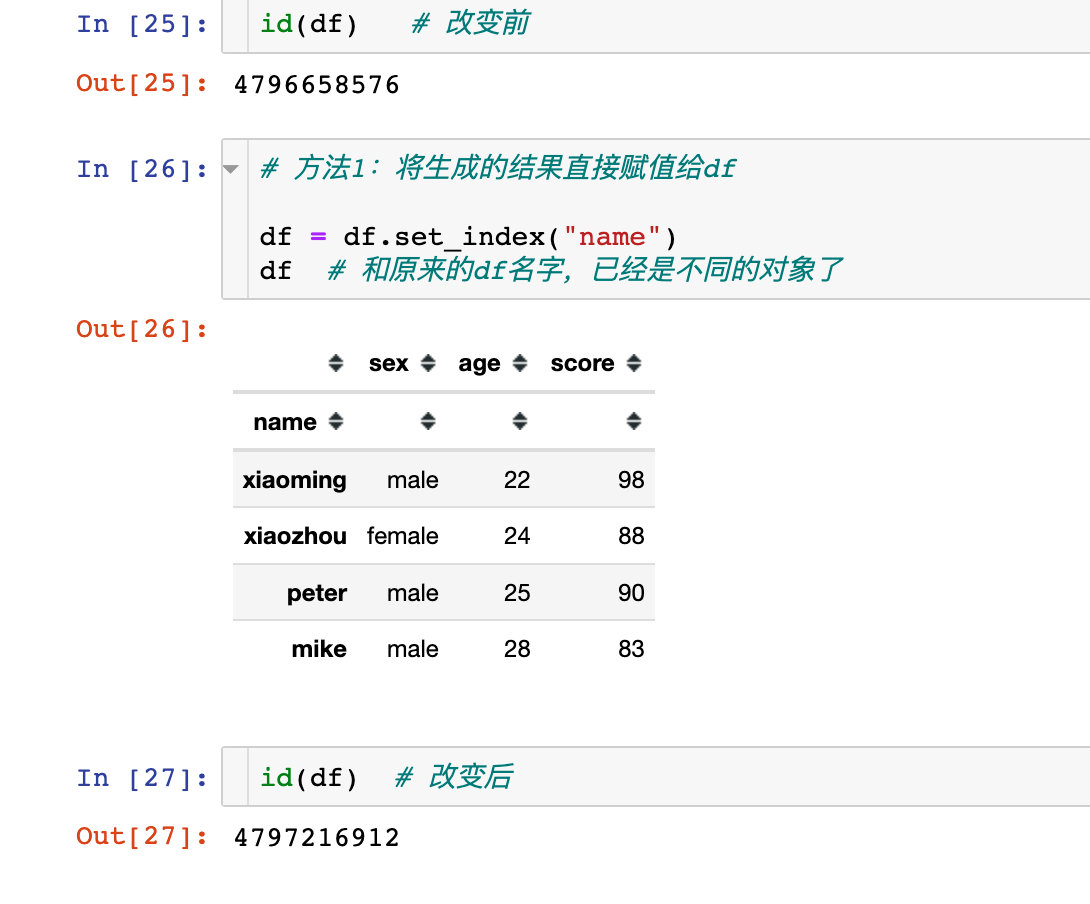
在Python内部其实创建了两个不同的对象,开辟了不同的内存地址,只不过对象的刚好都是df而已
2、原地修改
第二种方法是通过set_index的inplace参数,原地修改df:
In [28]:
id(df) # 改变前
Out[28]:
4633094992
In [29]:
df.set_index("name",inplace=True) # 原地修改
In [30]:
id(df) # 改变后
Out[30]:
4633094992
我们发现:修改后df和原来是一样的
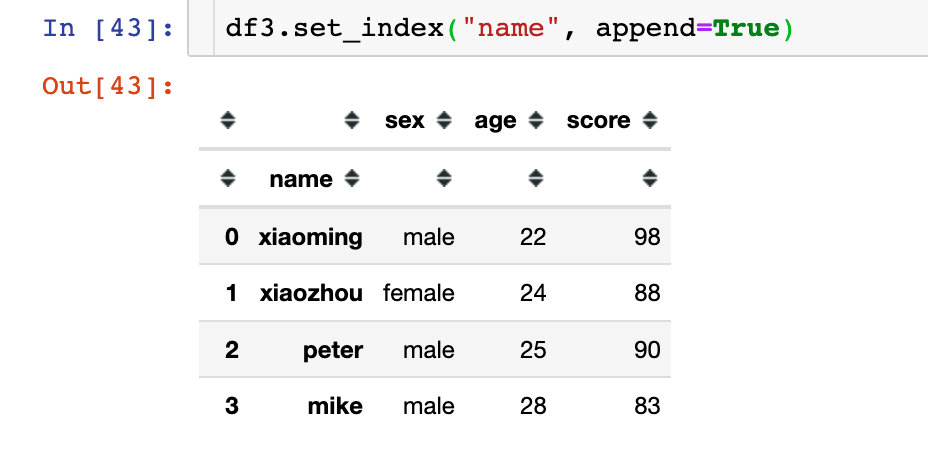
指定多个索引
1、赋值改变
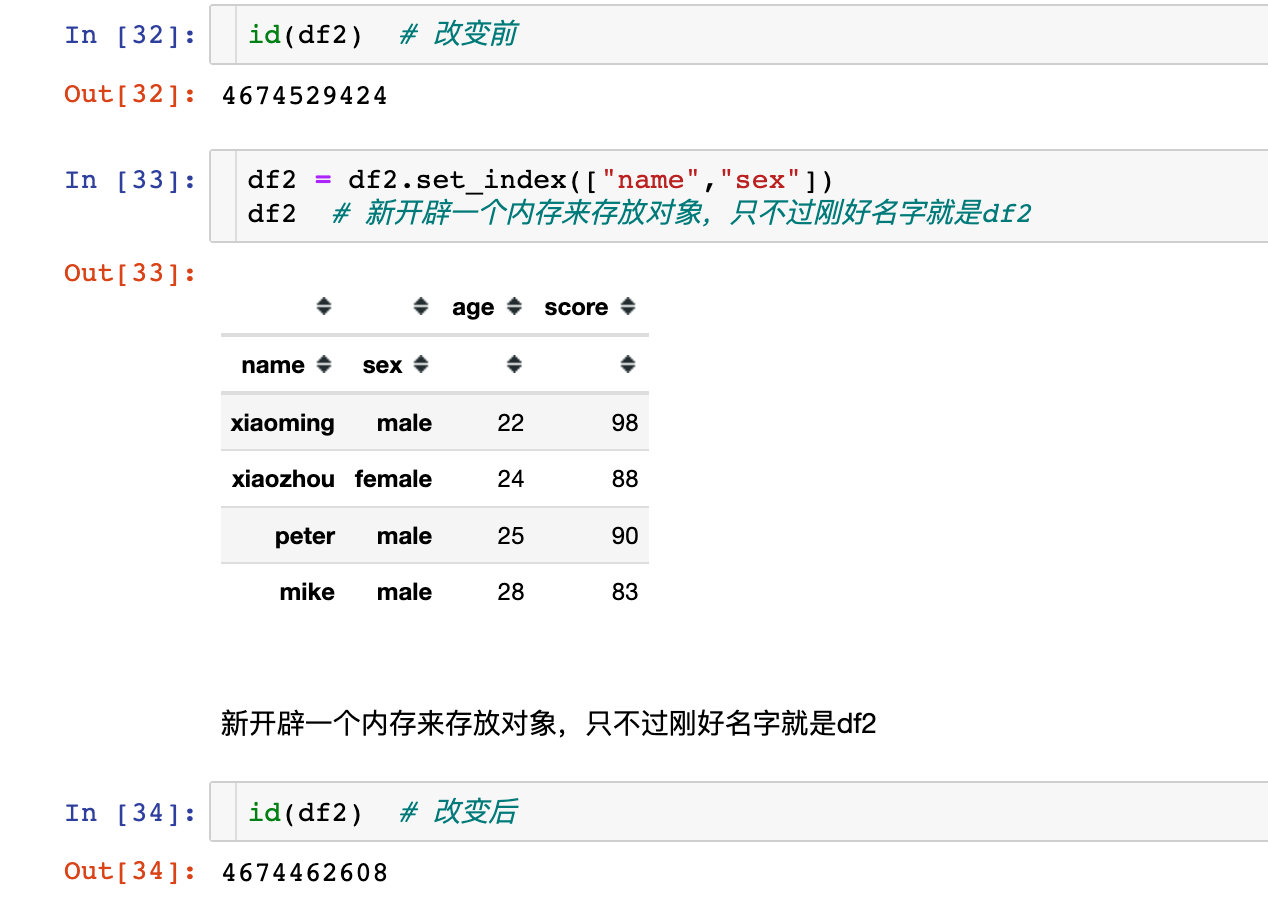
2、原地修改

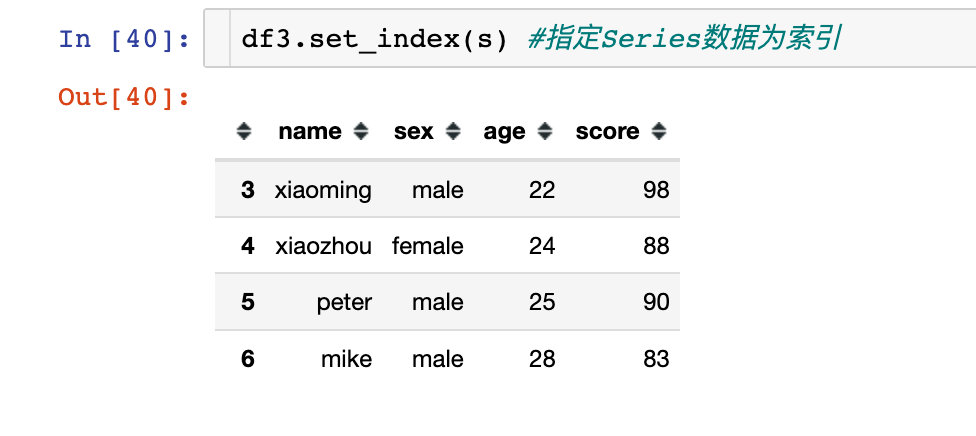
; 指定Series数据为索引
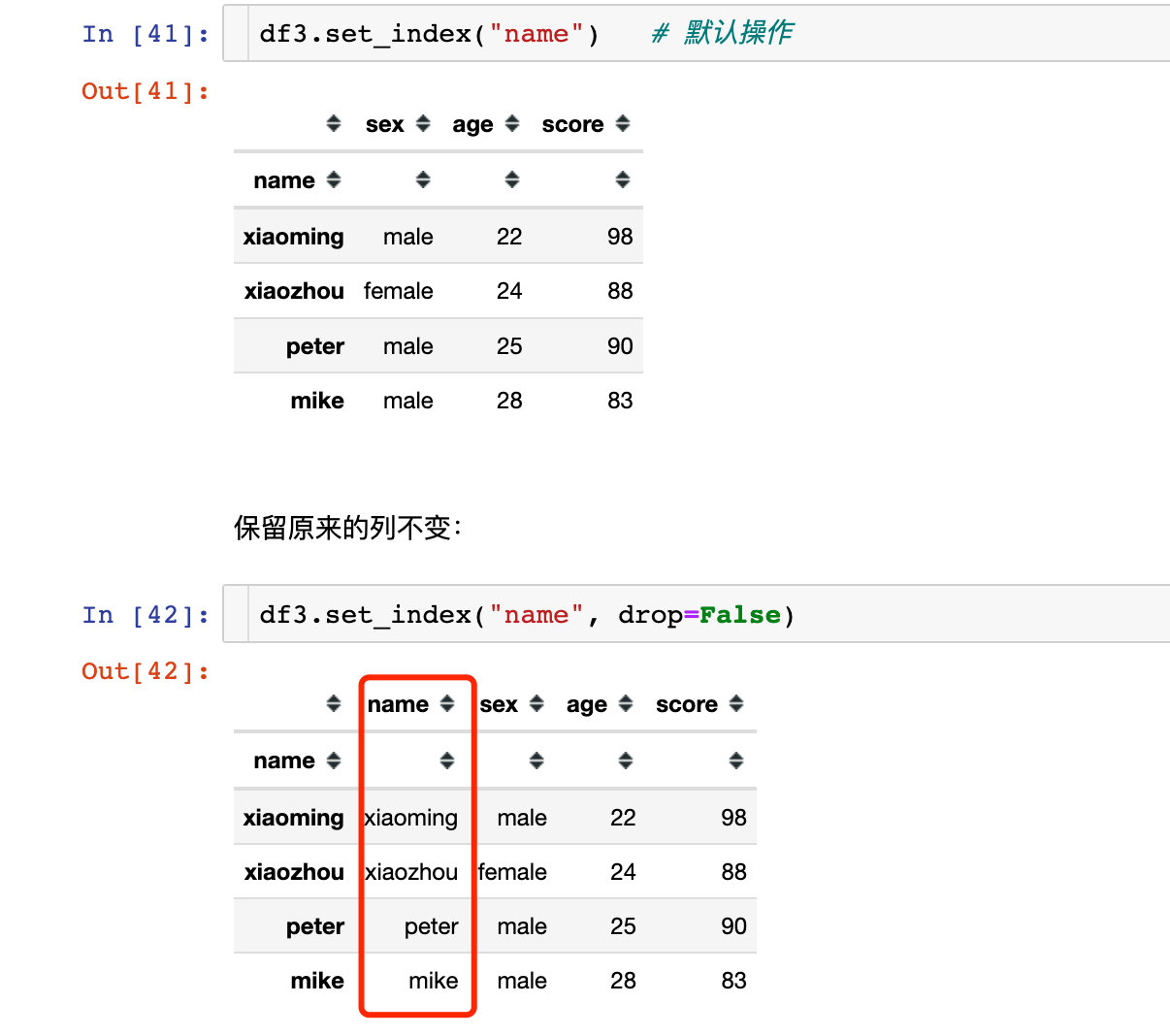
其他操作
原来的列字段仍然保存:
原来的索引仍然保留:
Original: https://blog.csdn.net/qq_25443541/article/details/124185158
Author: 尤尔小屋的猫
Title: Pandas索引基本操作
相关阅读
Title: Ubuntu安装TensorFlow详细过程
Title: Ubuntu安装TensorFlow详细过程
一、准备工作
虚拟机:Vmware Workstation 16 Pro(至少需要Windows10才能支持)
操作系统:Ubuntu-20.04.2.0
二、安装Anaconda
可以来到清华大学的镜像源找到自己喜欢的版本下载
下载地址:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
我是在Ubuntu上面的Firefox浏览器下载的,下载的版本是这个:
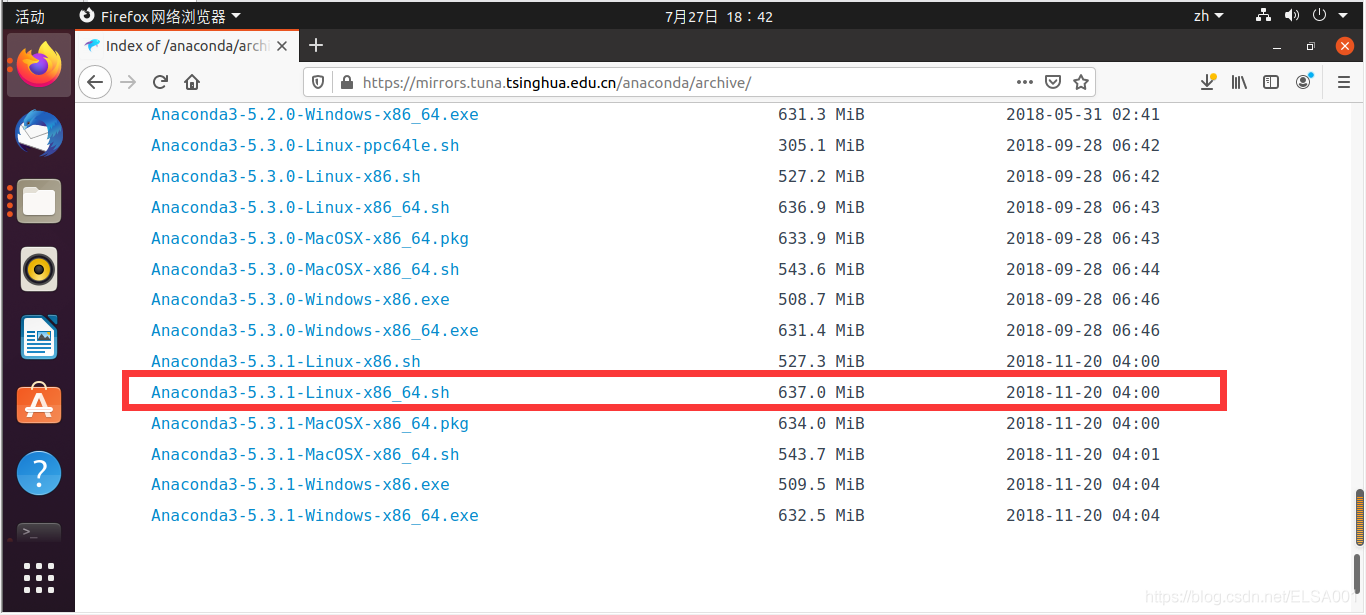
虽然下载好了,但是下载的很慢很慢,老是断网,然后再重新点一下才可以下载,花了很长时间。不过好像可以在自己的Windows上面先下载,然后在拖到虚拟机上面,具体我也不知道应该怎么弄。
下载好以后把它丢到download文件夹(其他文件夹也行)里然后执行安装脚本,按照提示一路yes或者回车就可以。
bash Anaconda3-5.3.1-Linux-x86_64.sh
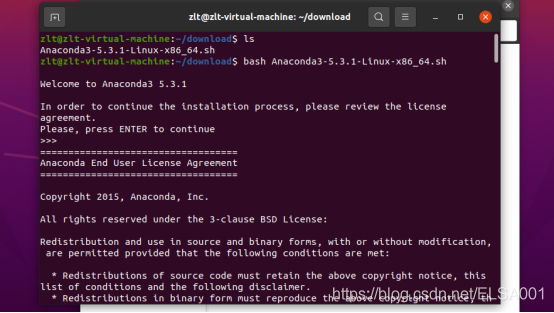
注意:在安装的过程中,有安装路径提示,请记住这个安装路径的提示,之后配置Anaconda环境需要用上。
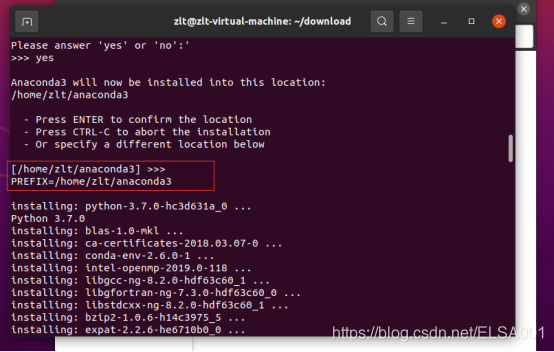
这样,Anaconda就装上了:
但是还需要配置一下环境变量
sudo gedit ~/.bashrc

在最后一行中加入自己安装的anaconda下bin的路径:
export PATH="/home/zlt/anaconda3/bin:$PATH"
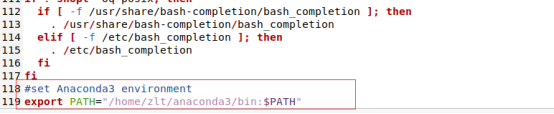
保存关闭文件后,使其生效:
source ~/.bashrc

看到这一步就大功告成啦~

三、安装Tensorflow
这里装的是CPU版的不是GPU版的哈哈哈。
为了利用Python的虚拟环境来进行更好地管理,先用conda新建一个python版本为3.6的虚拟环境。
conda create -n tensorflow python=3.6

激活虚拟环境
source activate tensorflow

安装tensorflow,找到了豆瓣源
pip install -i https://pypi.doubanio.com/simple/ tensorflow==1.3.0

四、验证Tensorflow是否安装成功
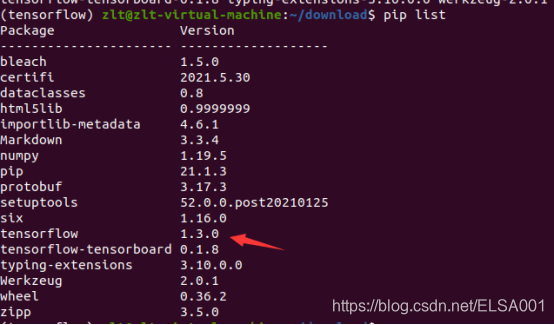
先看看自己的tensorflow版本,可以看到我安装版本的是1.3.0
pip list
导入一个tensorflow的模块来试试就可以了,记得一定还是要在虚拟环境下:
source activate tensorflow

每个版本的模块有不同的特点,报错不一定是安装出错,有可能是tensorflow版本不一致模块的用法不一样。
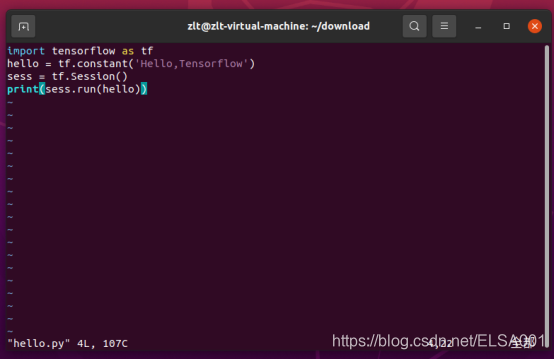
新建一个hello.py文件,输入以下代码保存,使用python来运行:
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print(sess.run(hello))
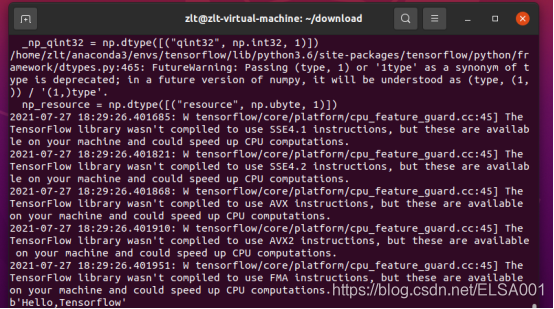
这样就没问题了,这一大串是在说numpy包版本有问题啥的。
五、总结
今天花了很多时间安装这个TensorFlow,遇到了很多问题,比如我之前下载的操作系统是Ubuntu16 ,我发现很多预安装在系统上面的软件都是版本很低的,比如Python只有2点几的版本,直接导致pip命令没办法使用,需要更新,更新了也有问题,还是用不了,于是我果断下载了Ubuntu20,很多命令就可以正常使用了。之前我的Linux操作系统这门课没有怎么好好学,现在又回来学这个,感觉还是力不从心,之后还得多练练才行。
Original: https://blog.csdn.net/ELSA001/article/details/119150775
Author: 钟良堂
Title: Ubuntu安装TensorFlow详细过程Original: https://blog.csdn.net/ELSA001/article/details/119150775
Author: 钟良堂
Title: Ubuntu安装TensorFlow详细过程