
Pandas 是核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,本文主要总结数据分析中pandas的常用方法
python 版本:python3.7 pandas版本:'2.7.0'
1.引入模块
import pandas as pd
import numpy as np
2.数据生成
2.1Series
Series是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。轴标签统称为 索引。
调用 pd.Series 函数即可创建 Series:
s = pd.Series(data, index=index)
上述代码中, data 支持以下数据类型:
- Python 字典
        Series 按字典的插入顺序排序索引(python3.7)
data = {'a': 3, 'b': 1, 'c': 2}
s = pd.Series(data)
s

- 多维数组
data 是多维数组时, index 长度必须与 data 长度一致。没有指定 index 参数时,创建数值型索引,即 [0, ..., len(data) - 1]。
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
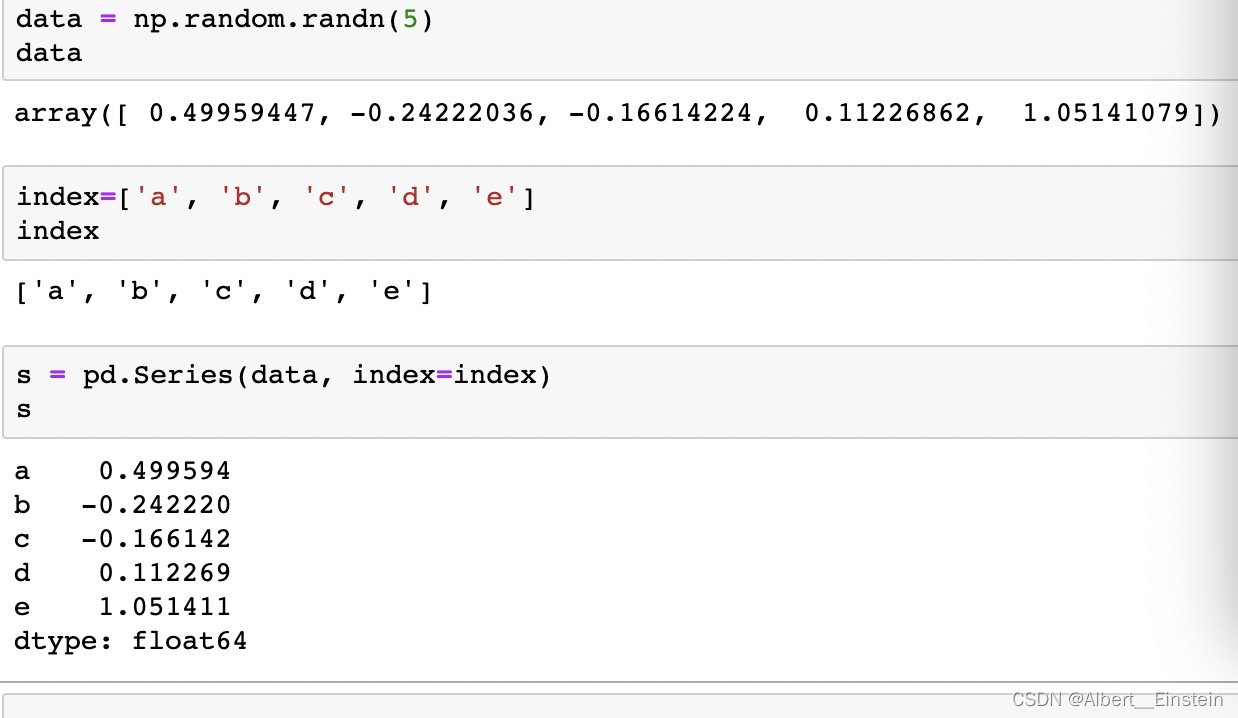
- 标量值(如,5)
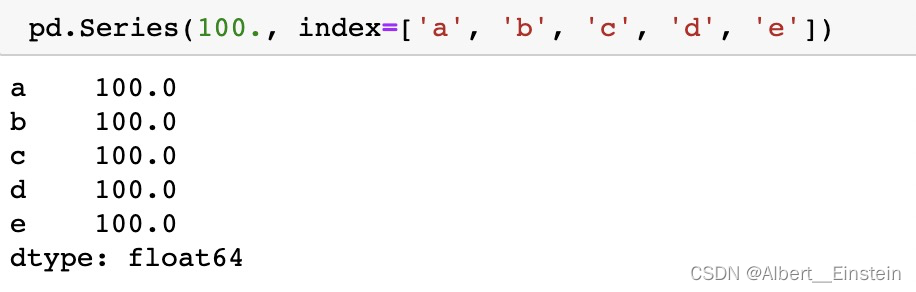
data 是标量值时,必须提供索引。 Series 按 索引长度重复该标量值。
pd.Series(100., index=['a', 'b', 'c', 'd', 'e'])
2.2DataFrame
DataFrame 是由多种类型的列构成的二维标签数据结构,类似于 Excel 、SQL 表,或 Series 对象构成的字典。DataFrame 是最常用的 Pandas 对象,与 Series 一样,DataFrame 支持多种类型的输入数据:
- 一维 ndarray、列表、字典、Series 字典
用多维数组字典、列表字典生成 DataFrame
多维数组的长度必须相同。如果传递了索引参数, index 的长度必须与数组一致。如果没有传递索引参数,生成的结果是 range(n), n 为数组长度。
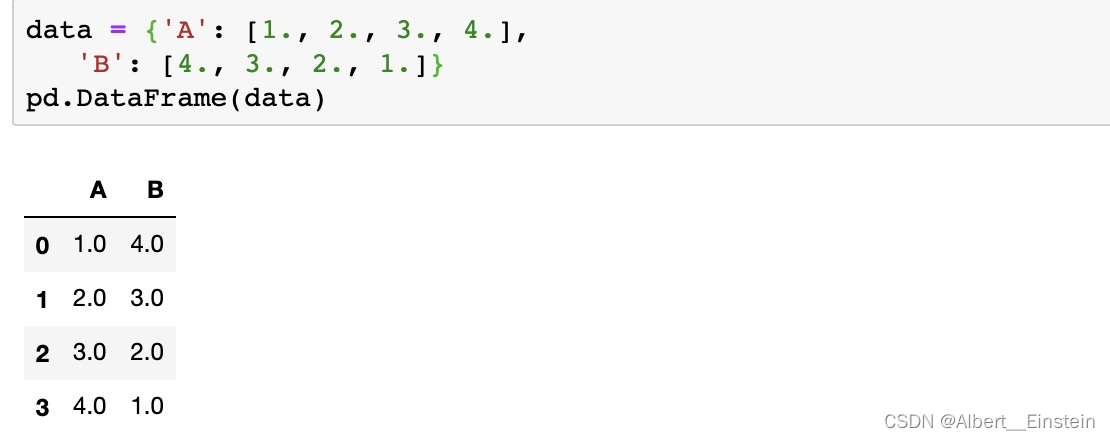
data = {'A': [1., 2., 3., 4.],
'B': [4., 3., 2., 1.]}
pd.DataFrame(data)
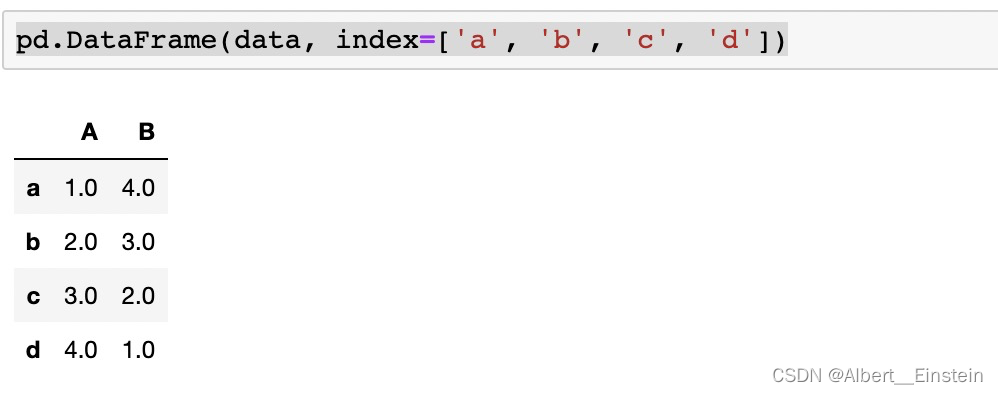
pd.DataFrame(data, index=['a', 'b', 'c', 'd'])
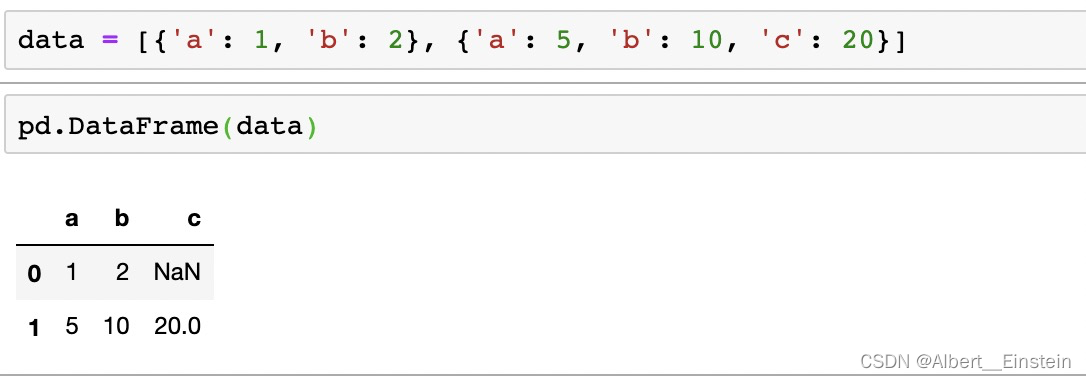
用列表字典生成 DataFrame (自动生成range索引)
data = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
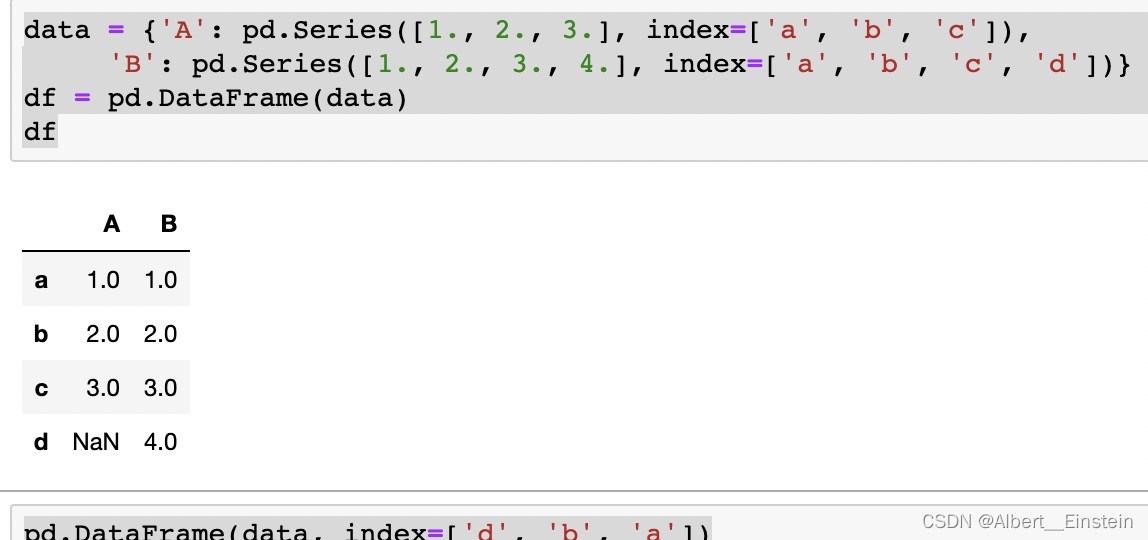
用 Series 字典或字典生成 DataFrame
生成的 索引是每个 Series 索引的并集。先把嵌套字典转换为 Series。如果没有指定列,DataFrame 的列就是字典键的有序列表。
data = {'A': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'B': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(data)
df
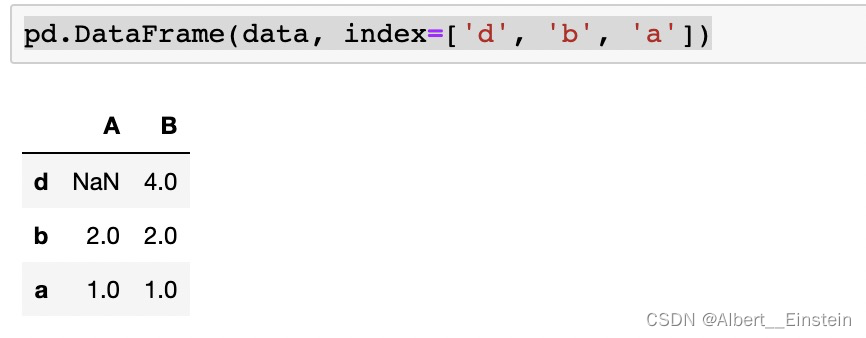
pd.DataFrame(data, index=['d', 'b', 'a'])
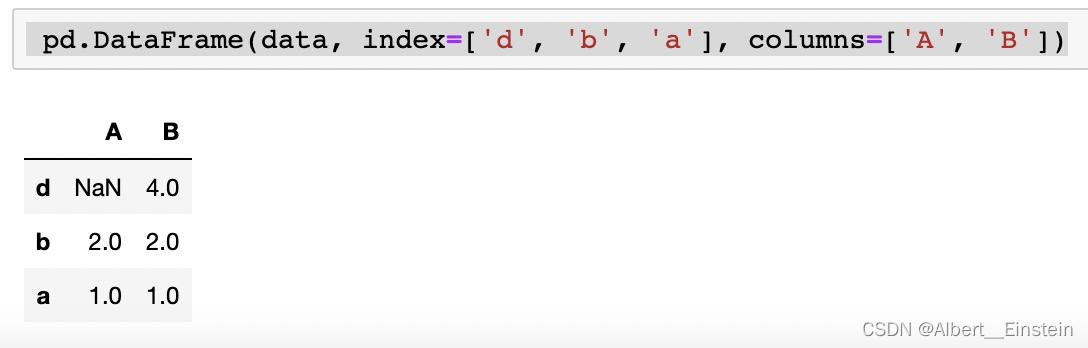
pd.DataFrame(data, index=['d', 'b', 'a'], columns=['A', 'B'])
用元组字典生成 DataFrame
元组字典可以自动创建多层索引 DataFrame。
pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2},
('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4},
('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6},
('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8},
('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}})
 二维 numpy.ndarray
二维 numpy.ndarray
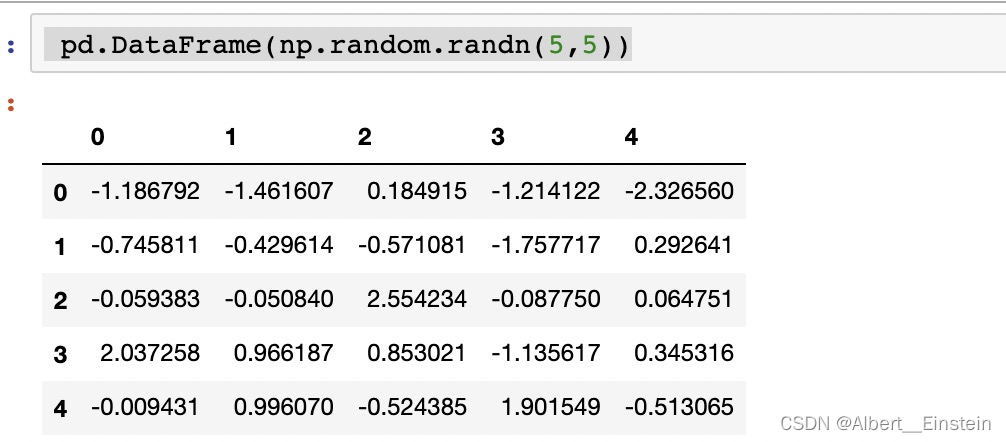
pd.DataFrame(np.random.randn(5,5))
3.数据读取
3.1pandas读取excel
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None,
usecols=None, squeeze=False,dtype=None, engine=None,
converters=None, true_values=None, false_values=None,
skiprows=None, nrows=None, na_values=None, parse_dates=False,
date_parser=None, thousands=None, comment=None, skipfooter=0,
convert_float=True, **kwds)
1、io,文件存储路径
io = /home/work/xxxx.xlsx
2、sheet_name,sheet名称
可以是 整型数字、列表名或SheetN,也可以是上述三种组成的 列表。
整型数字:目标sheet所在的位置, 以0为起始,比如sheet_name = 1代表第2个工作表。
3、header, 用哪一行作列名
4、names, 自定义最终的列名
5、index_col, 用作索引的列
6、usecols,需要读取哪些列
7、squeeze,当数据仅包含一列
8、converters ,强制规定列数据类型
9、skiprows,跳过特定行
10、nrows ,需要读取的行数
11、skipfooter , 跳过末尾n行
3.2pandas读取csv
pd.read_csv(filepath_or_buffer: Union[str, pathlib.Path, IO[~AnyStr]],
sep=',', delimiter=None, header='infer', names=None, index_col=None,
usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True,
dtype=None, engine=None, converters=None, true_values=None,
false_values=None, skipinitialspace=False, skiprows=None,
skipfooter=0, nrows=None, na_values=None, keep_default_na=True,
na_filter=True, verbose=False, skip_blank_lines=True,
parse_dates=False, infer_datetime_format=False,
keep_date_col=False, date_parser=None, dayfirst=False,
cache_dates=True, iterator=False, chunksize=None,
compression='infer', thousands=None, decimal: str = '.',
lineterminator=None, quotechar='"', quoting=0,
doublequote=True, escapechar=None, comment=None,
encoding=None, dialect=None, error_bad_lines=True,
warn_bad_lines=True, delim_whitespace=False,
low_memory=True, memory_map=False, float_precision=None)
filepath_or_buffer为第一个参数,没有默认值,也不能为空,根据Python的语法,第一个参数传参时可以不写参数名。可以传文件路径:
3.3pandas连接mysql,并读取数据
要实现 pandas 对 mysql 的读写需要三个库
- pandas
- sqlalchemy
- pymysql
1、read_sql_query 读取 mysql
read_sql_query 或 read_sql 方法传入参数均为 sql 语句,读取数据库后,返回内容是 dateframe 对象。
import pandas
from sqlalchemy import create_engine
class mysqlconn:
def __init__(self):
mysql_username = 'root'
mysql_password = '123456'
# 填写真实数库ip
mysql_ip = 'x.x.x.x'
port = 3306
db = 'work'
# 初始化数据库连接,使用pymysql库
self.engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}'.format(mysql_username, mysql_password, mysql_ip, port,db))
# 查询mysql数据库
def query(self,sql):
df = pandas.read_sql_query(sql,self.engine)
# df = pandas.read_sql(sql,self.engine) 这种读取方式也可以
# 返回dateframe格式
return df
if __name__ =='__main__':
# 查询的 sql 语句
SQL = '''select * from working_time order by id desc '''
# 调用 mysqlconn 类的 query() 方法
df_data = mysqlconn().query(sql=SQL)
2、to_sql 写入数据库
使用 to_sql 方法写入数据库之前,先把数据转化成 dateframe 。
import pandas
from sqlalchemy import create_engine
class mysqlconn:
def __init__(self):
mysql_username = 'root'
mysql_password = '123456'
# 填写真实数库ip
mysql_ip = 'mysql.mall.svc.test.local'
port = 3306
db = 'work'
# 初始化数据库连接,使用pymysql库
self.engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}'.format(mysql_username, mysql_password, mysql_ip, port,db))
# 查询mysql数据库
def query(self,sql):
df = pandas.read_sql_query(sql,self.engine)
# df = pandas.read_sql(sql,self.engine)
# 返回dateframe格式
return df
# 写入mysql数据库
def to_sql(self,table,df):
# 第一个参数是表名
# if_exists:有三个值 fail、replace、append
# 1.fail:如果表存在,啥也不做
# 2.replace:如果表存在,删了表,再建立一个新表,把数据插入
# 3.append:如果表存在,把数据插入,如果表不存在创建一个表!!
# index 是否储存index列
df.to_sql(table, con=self.engine, if_exists='append', index=False)
if __name__ =='__main__':
# 创建 dateframe 对象
df = pandas.DataFrame([{'name':'小米','price':'3999','colour':'白色'},{'name':'华为','price':'4999','colour':'黑色'}])
# 调用 mysqlconn 类的 to_sql() 方法
mysqlconn().to_sql('phonetest',df)
3.4pandasl连接oracle,并去读数据
1、登录oracle
首先先导入sqlalchemy库的create_engine,
通过 engine = create_engine("dialect+driver://username:password@host:port/database")初始化连接
参数说明:
dialect,是数据库类型包括:sqlite, mysql, postgresql, oracle, mssql等
driver,指定连接数据库的API,如:`psycopg2,pyodbc,cx_oracle``等,为可选关键字。
username,用户名
password,密码
host,网络地址,可以用ip,域名,计算机名,当然是你能访问到的。
port,数据库端口。
database,数据库名称。
from sqlalchemy import create_engine
engine = create_engine("oracle://scott:tiger@hostname/dbname",encoding='utf-8', echo=True)
2、 read_sql
pd.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
参数说明:
sql,执行的sql,可为查询、删除、创建、更新等等的sql,在此可直接指定表名称,默认就是select * from tablename
con,指定的数据库连接,即con=engine,也就是我们刚才初始化的数据库连接engine
index_col,查询时,指定那一列为DataFrame的index,也可以是多列['a','b'],此时就生成了Multindex
coerce_float,boolean,默认为True,尝试转换float的值,用于设置sql查询的结果
params,list, tuple or dict, 可选关键字, 默认为:None,要传递给执行方法的参数列表。不太懂这个关键字,一般情况用不到
parse_dates, list or dict, 默认为 None,要解析为日期时间的字段
columns,查询时指定选择那些列,即select * from 中的*,默认全部列
chunksize,int,默认为None,如果指定数值,则返回一个迭代器,指定的数值为迭代器内数据的行数
3、 to_sql
DataFrame.to_sql(self, name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)
关键参数说明:
name,数据库表名
con,指定的数据库连接,即con=engine,也就是我们刚才初始化的数据库连接engine
schema,指定样式,不明白有什么用处
if_exists,{'fail', 'replace', 'append'}, 默认为'fail',即指定当数据库表存在时的处理方式,默认为fail,挂起一个错误
* fail: 挂起一个错误
* replace: drop掉原来的表,重新创建
* append: 在原来表基础上插入数据
index,boolean,默认为True,指定DataFrame的index是否一同写入数据库
index_label,在index关键字为True时,指定写入的index的字段名称,默认为None时,字段名称为index
chunksize,int,默认为None,如果指定数值,则返回一个迭代器,指定的数值为迭代器内数据的行数。当写入的数据量较大时,最好指定此关键字的数值
dtype,dict, 可选关键字,默认为None,即指定写入的字段字符类型,注意做好指定字符类型,因默认写入的数据类型数是colb,若没有指定数据类型,估计会报错。
4.数据查看
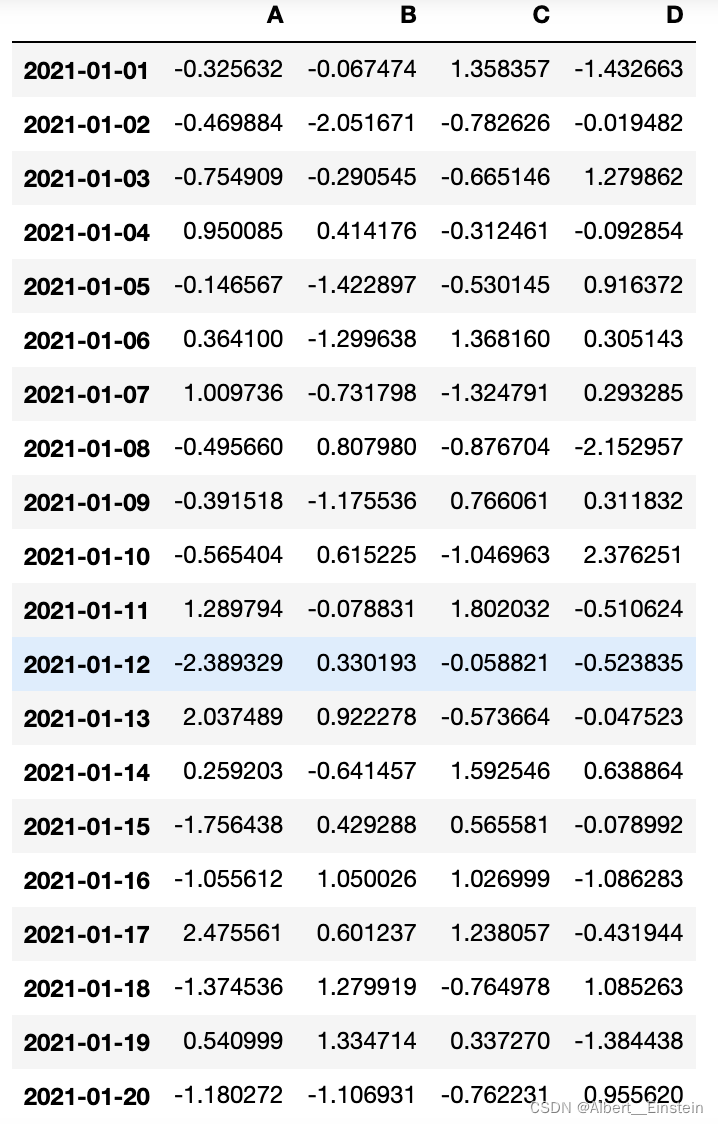
dates = pd.date_range('20210101', periods=20)
df = pd.DataFrame(np.random.randn(20, 4), index=dates, columns=list('ABCD'))
4.0显示设置
pd.set_option('display.max_rows',500)#设置展示最高行数
pd.set_option('display.max_columns',1000)#设置展示最高列数
pd.set_option('display.unicode.east_asian_width',True)#设置列名对齐
————————————————
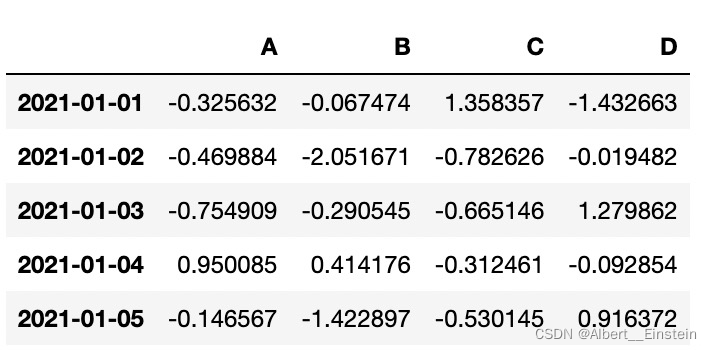
4.1查看前几行数据
df.head()
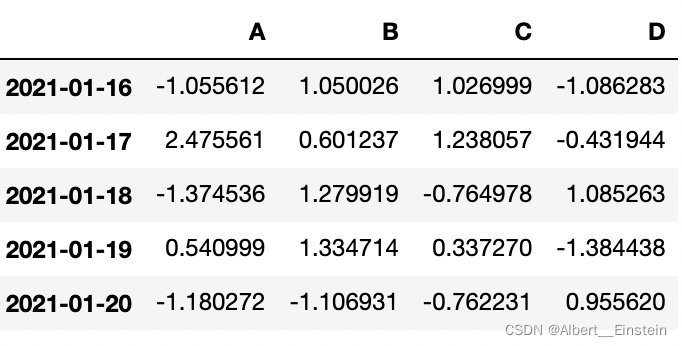
4.2查看前几行数据
df.tail()
4.3查看dataframe的形状
df.shape
(20, 4)
4.4数据表基本信息(维度、列名称、数据格式、所占空间等)
df.info()
DatetimeIndex: 20 entries, 2021-01-01 to 2021-01-20
Freq: D
Data columns (total 4 columns):
# Column Non-Null Count Dtype
> Original: https://blog.csdn.net/Albert__Einstein/article/details/121665036
> Author: Albert__Einstein
> Title: 数据分析--pandas常用操作
---
---
## **相关阅读**
## Title: 用Anaconda安装TensorFlow(Windows10)
## 用Anaconda安装TensorFlow
**本部分分为方法一和方法二,方法一是从清华镜像官网下载速度较快,<br> 方法二是从GitHub下载,速度较慢(有梯子的建议使用)**
**1.打开Anaconda Prompt**
**2.输入下面两行命令,打开清华镜像官网**
```js
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes

3.输入下面命令,利用Anaconda创建一个python3.9的环境,环境名称为tensorflow(这里python版本根据自己的情况如下图)
conda create -n tensorflow python=3.9
如图所示:
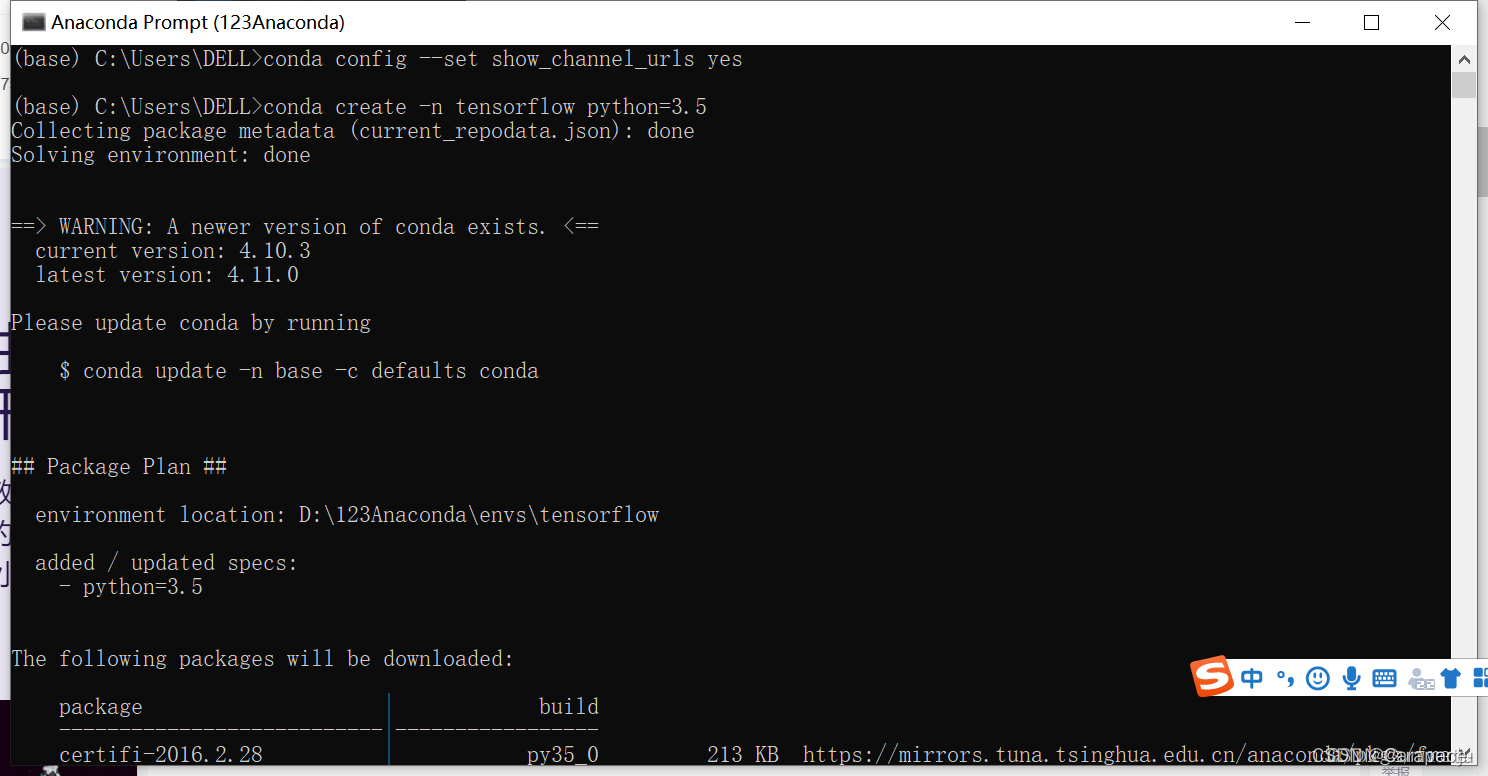
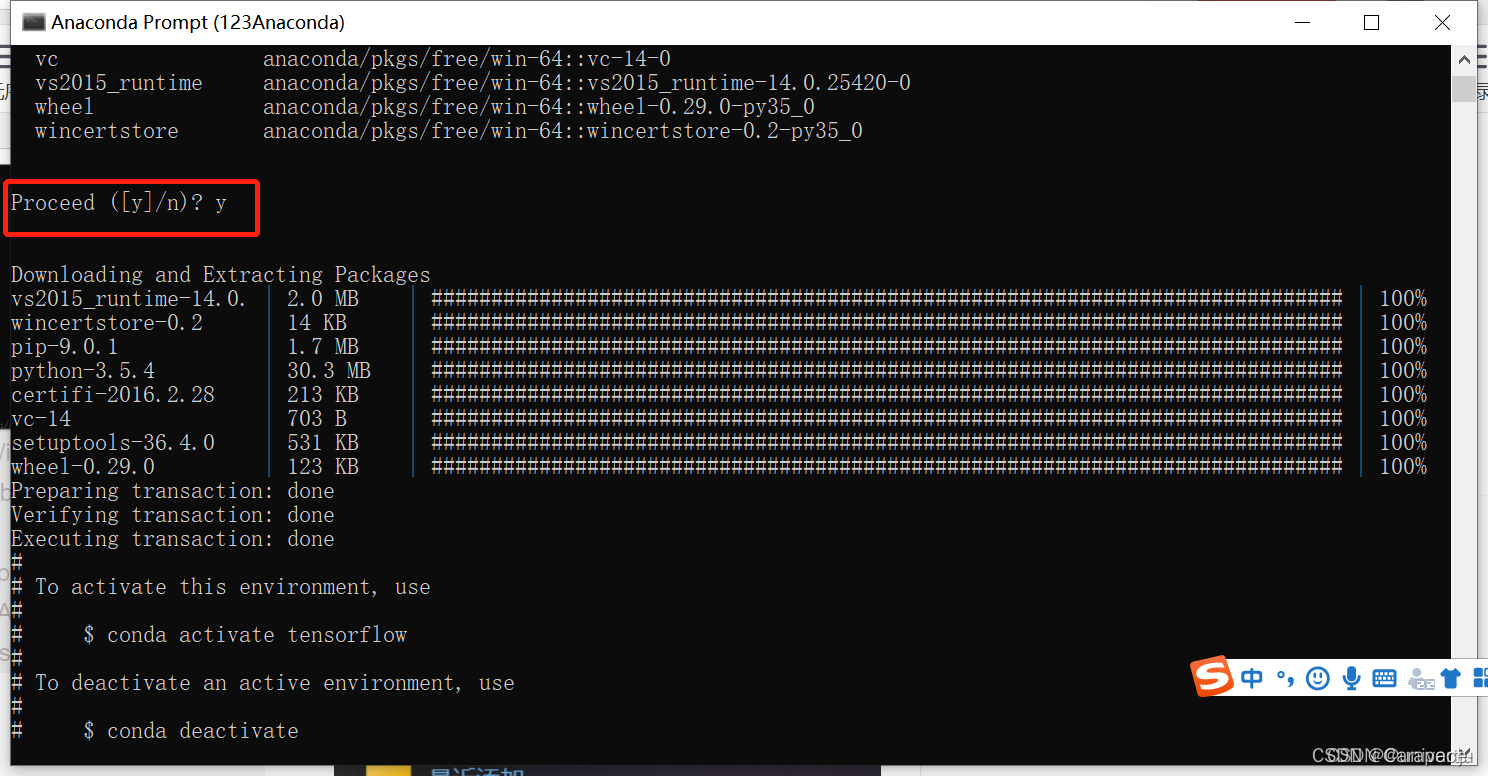
4.输入y
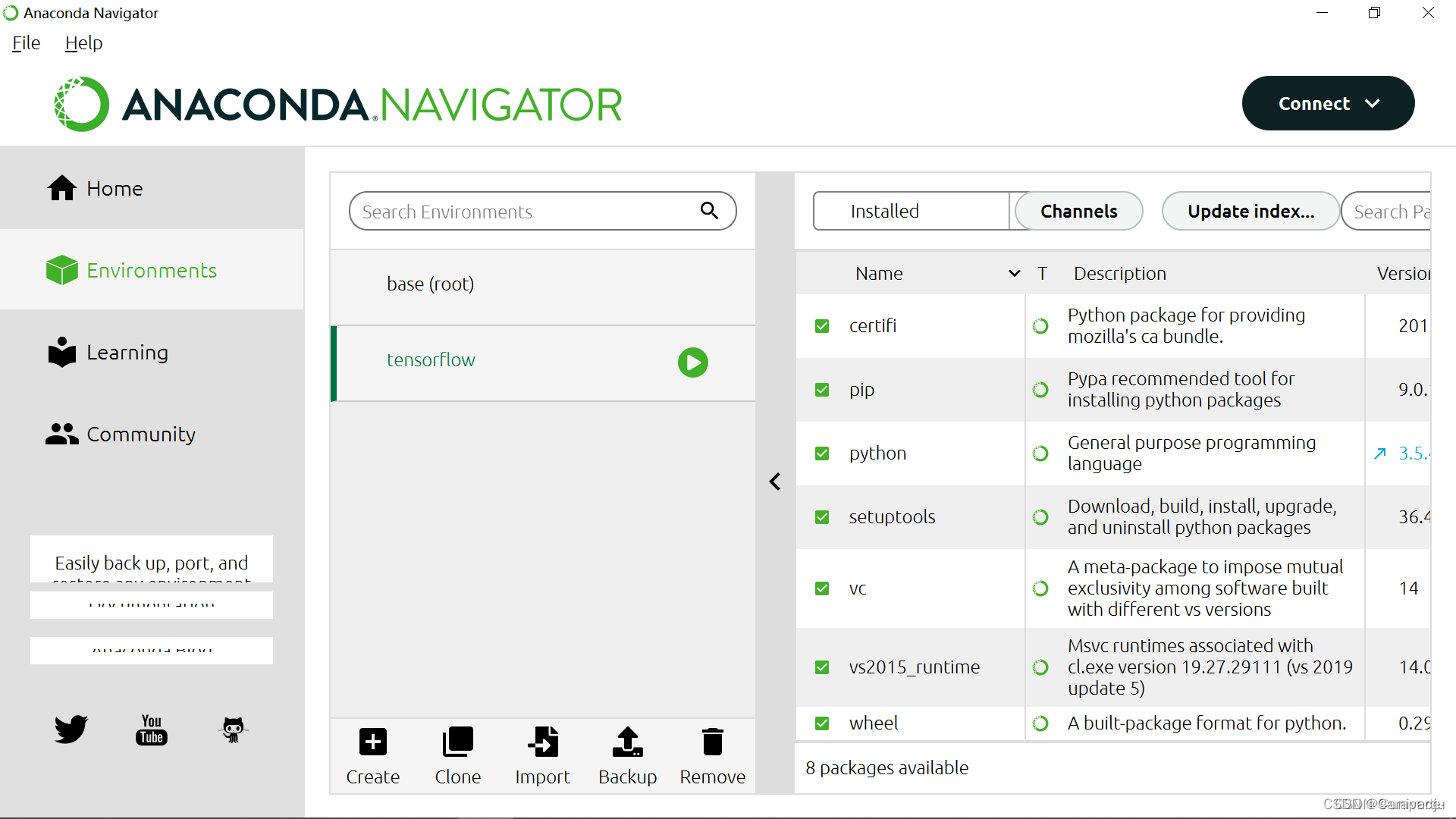
5.打开Anaconda Navigator,点击Environments,可以看到名称为tensorflow的环境已经创建好
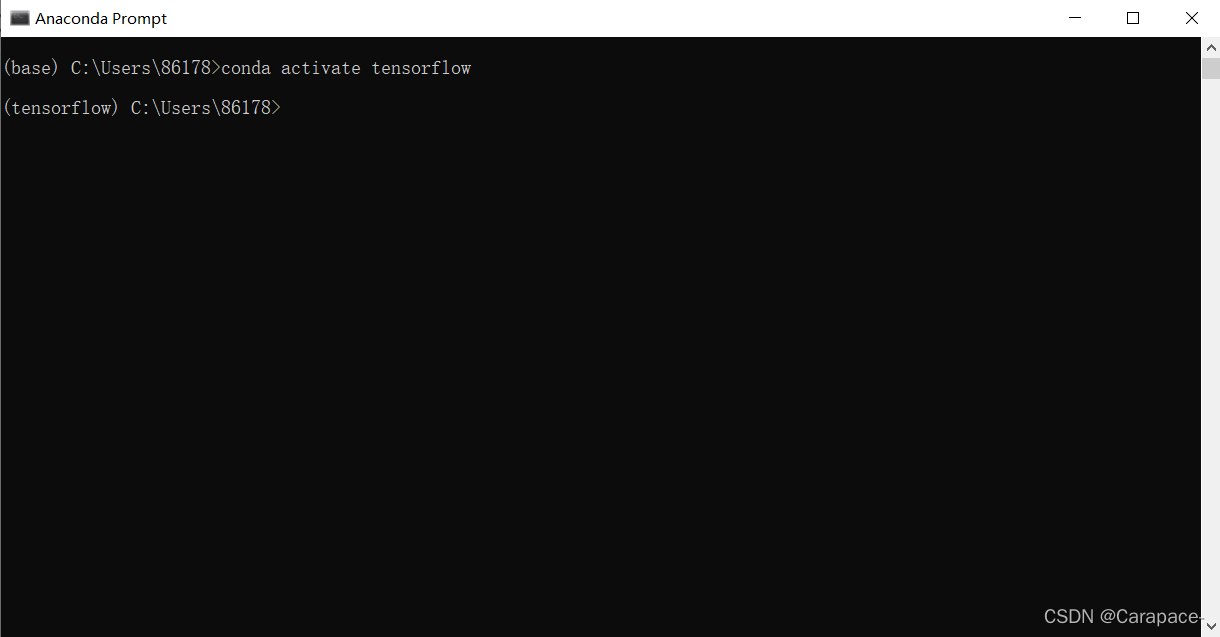
6.上一步最后我们可以看到,启动Tensorflow,使用下面的命令行:
conda activate tensorflow
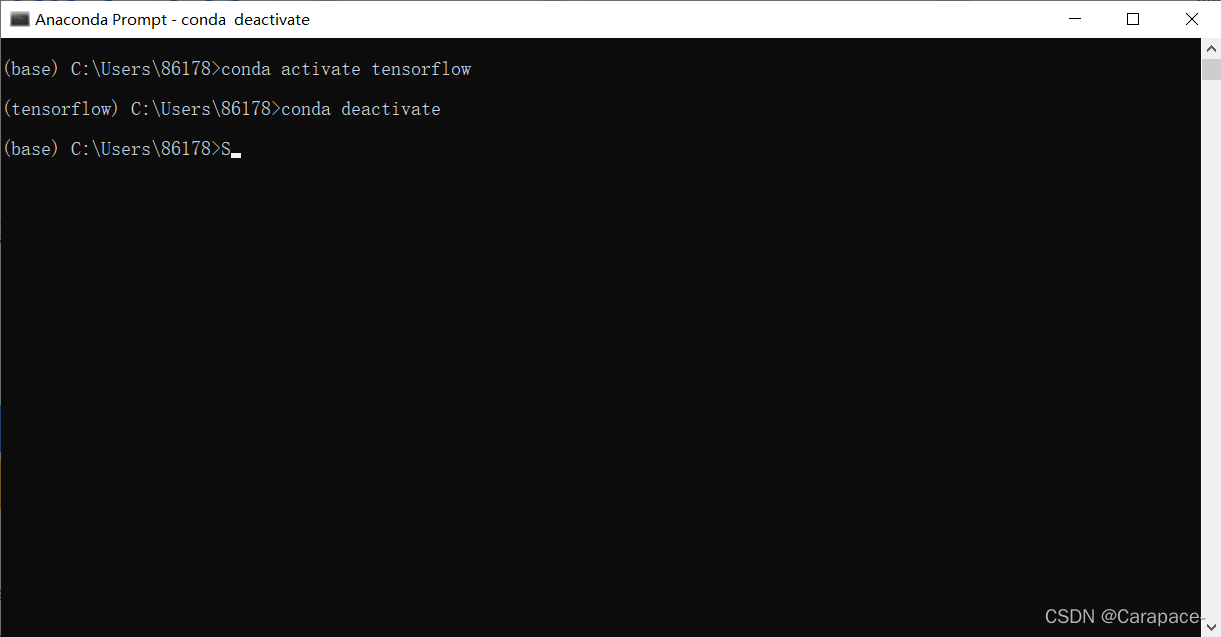
关闭tensorflow环境,使用下面的命令行:
7.我们在这里输入下面的命令,进入tensorflow环境
conda activate tensorflow
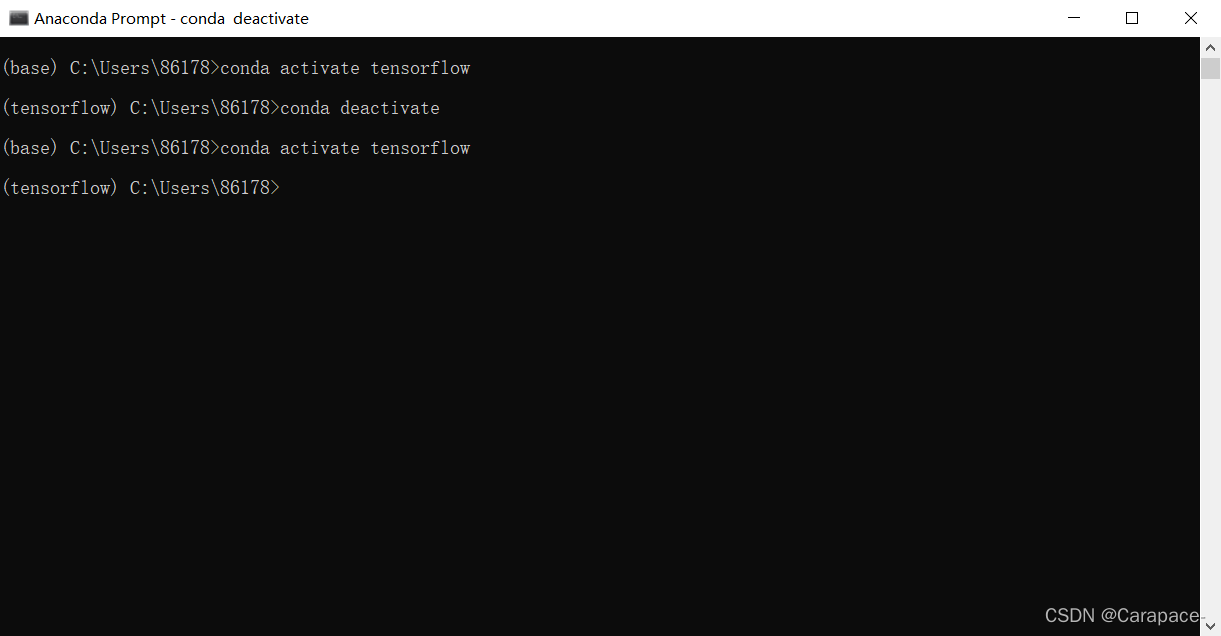
8.输入下面的命令行,安装cpu版本的tensorflow
conda install tensorflow
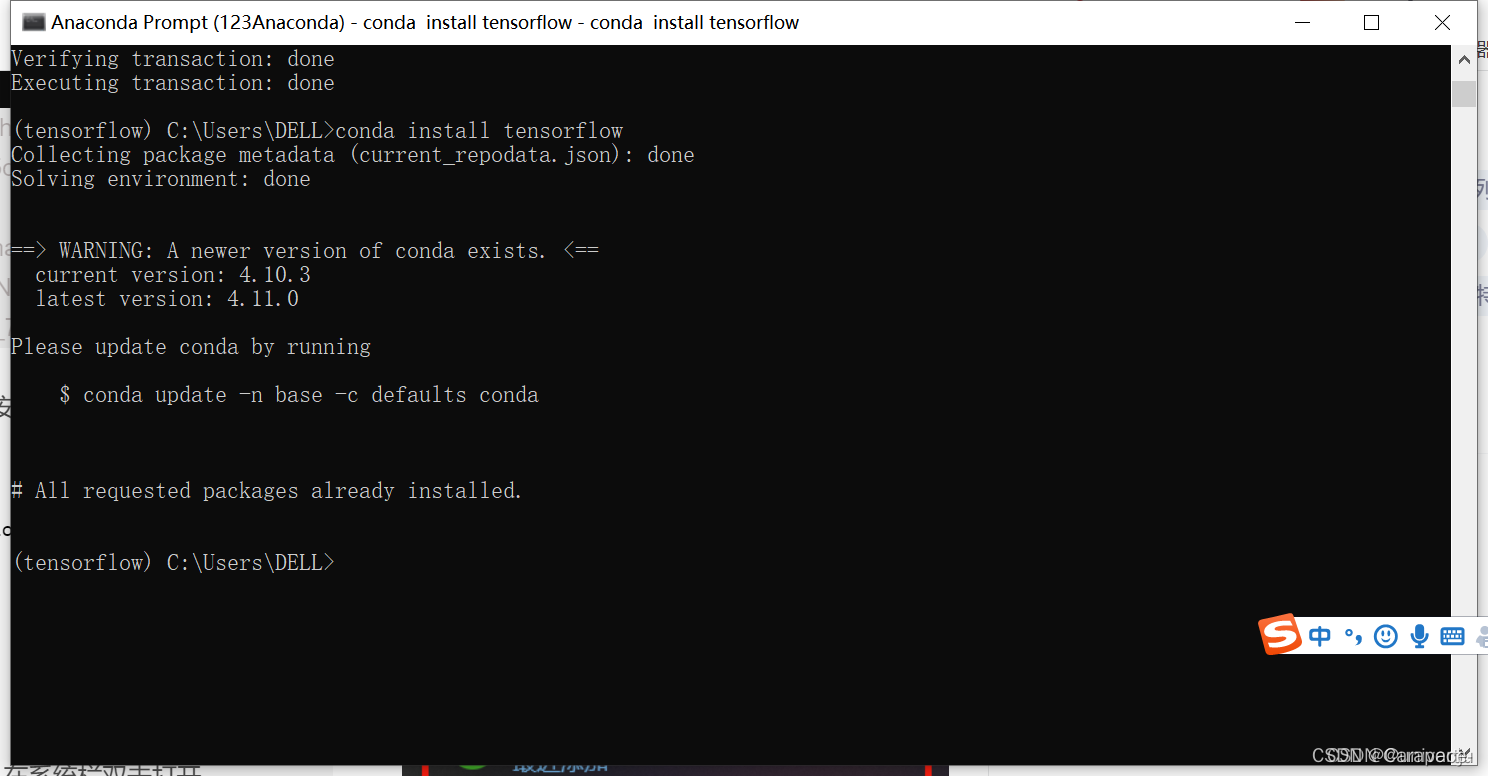
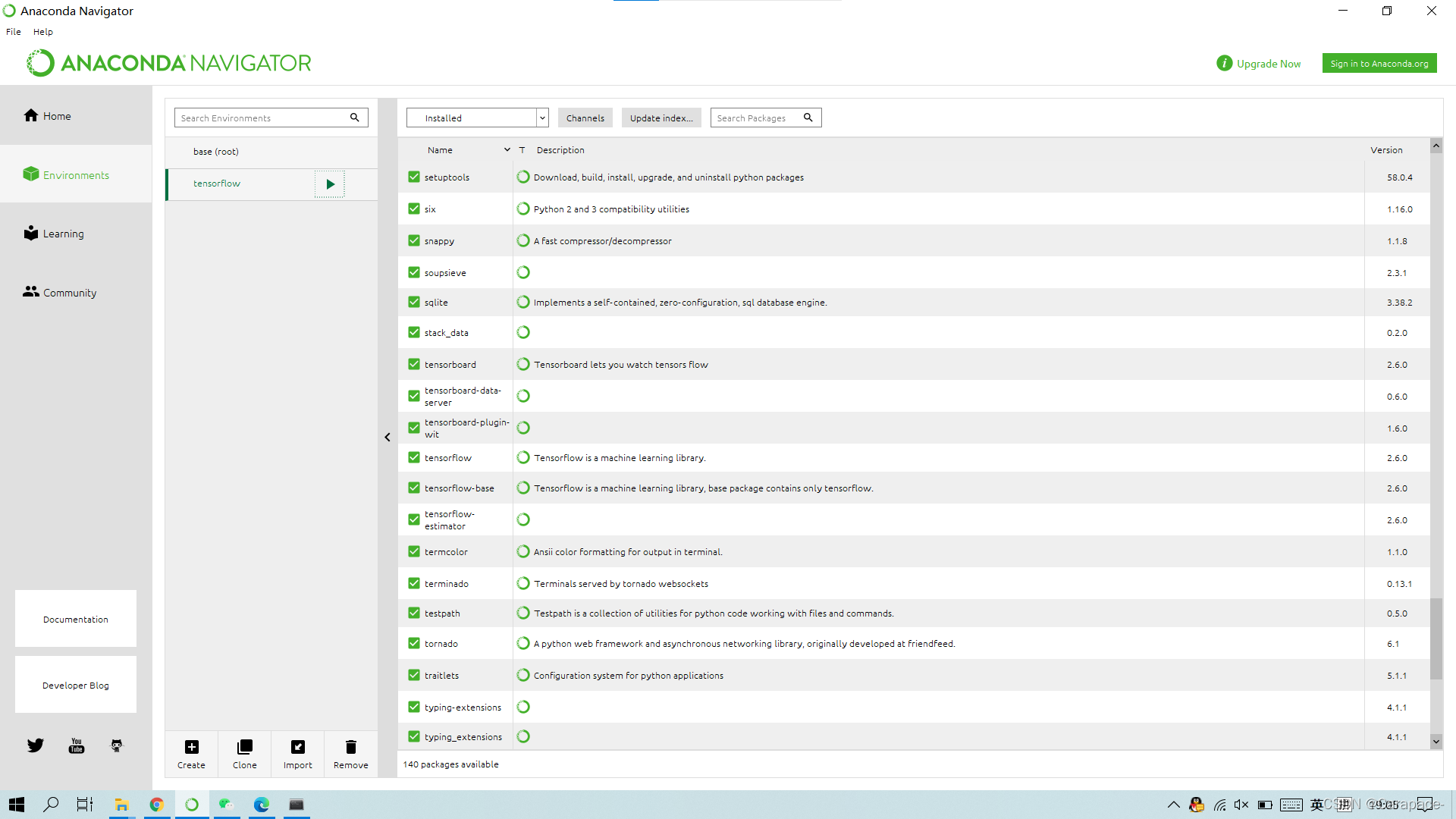
此时我们再次查看Anaconda Navigator中的Environments,可以发现tensorflow已经安装好了
第8步注意!!!
如果出现下图情况或者是从GitHub上下载速度极慢,说明清华镜像网址没有切换成功
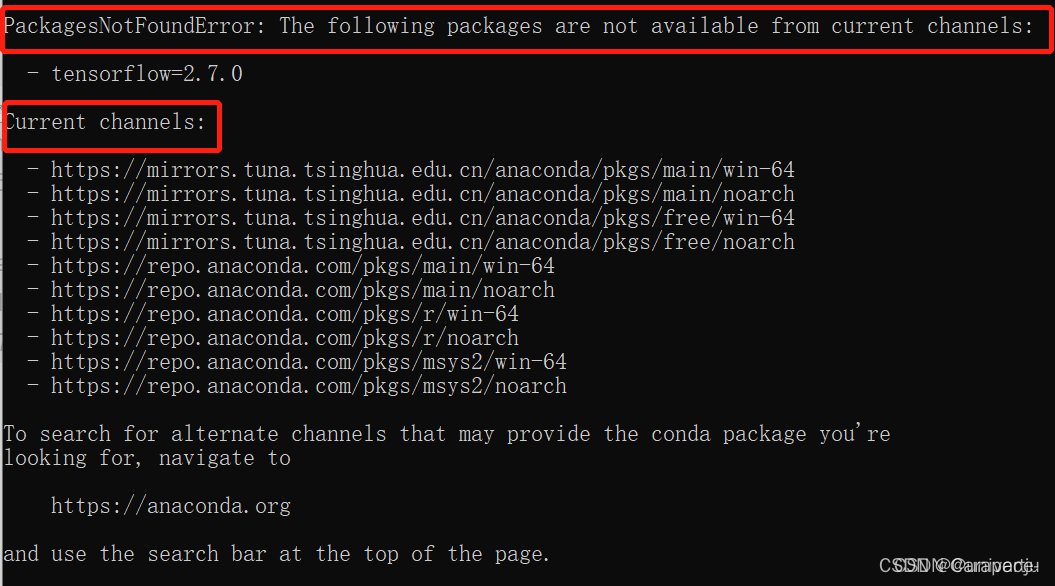
重新执行步骤二即可
TensorFlow安装方法方法二
方法二速度特别特别慢 (如果有梯子的话建议使用)
1.安装好Anaconda后,在系统栏双击打开Anaconda Navigator
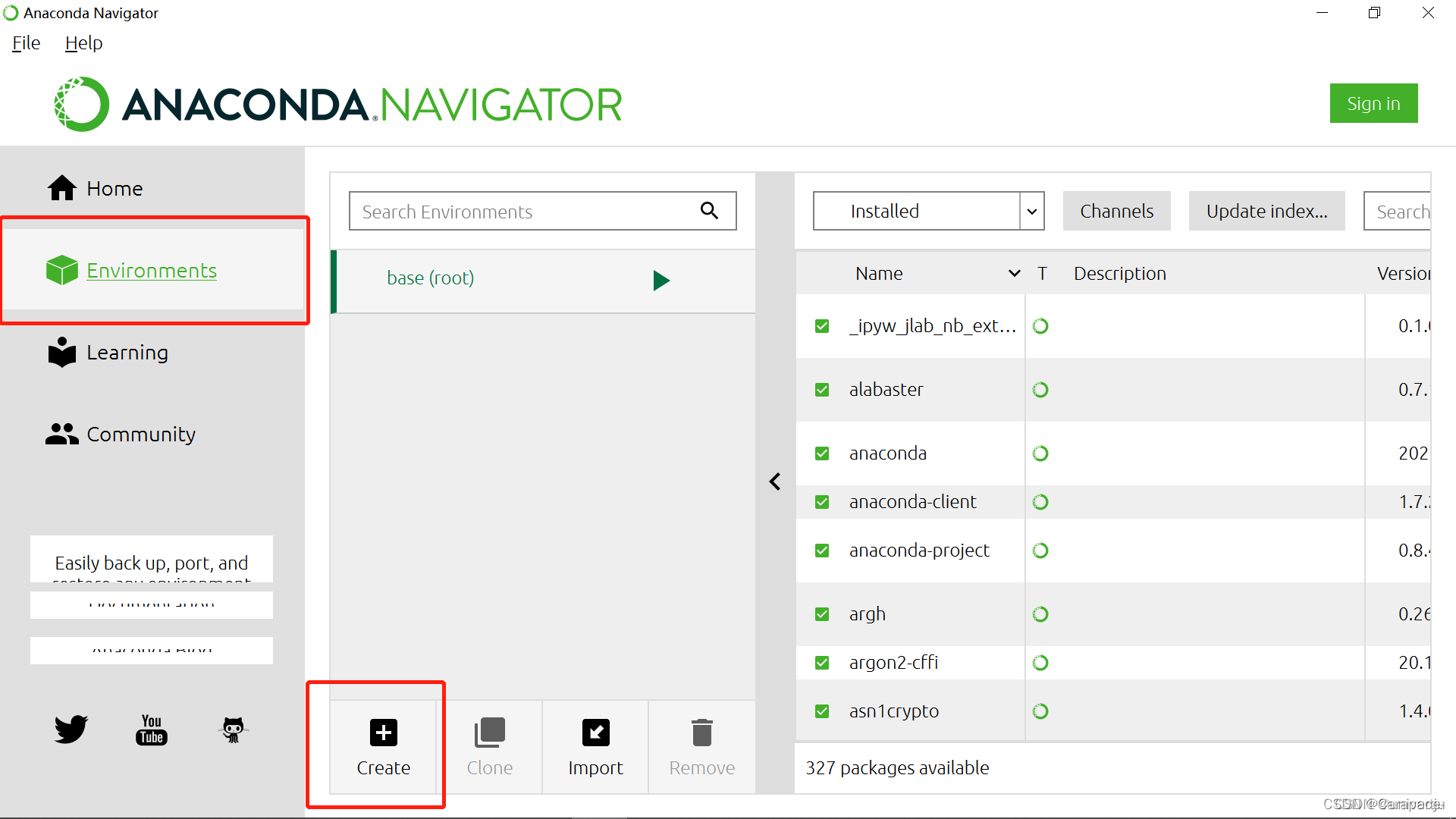
2.点击Environment,Create
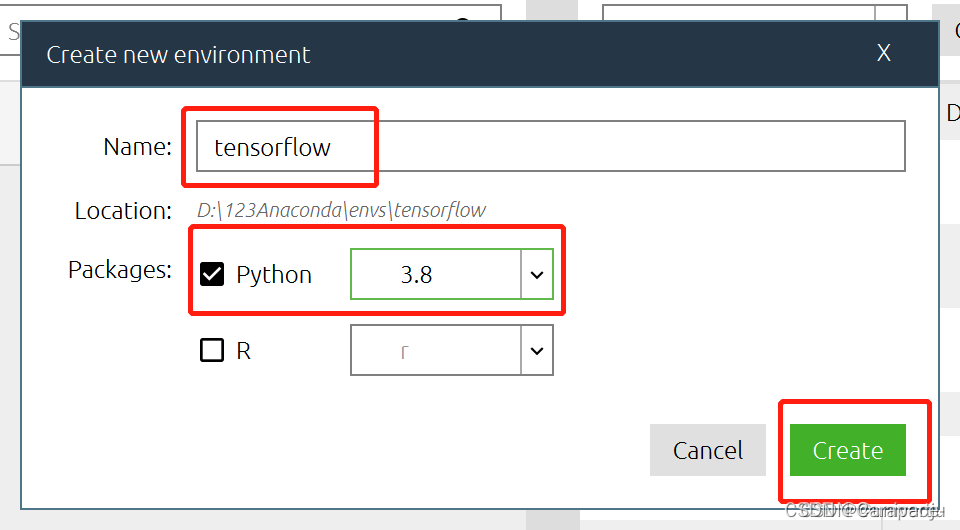
3.创建一个tensorflow的新环境,python在这里可以自行选择(根据Anaconda中安装的python版本,我这里是python3.8),然后点击Create
4.右边搜索栏输入tensorflow,选择后点击Apply
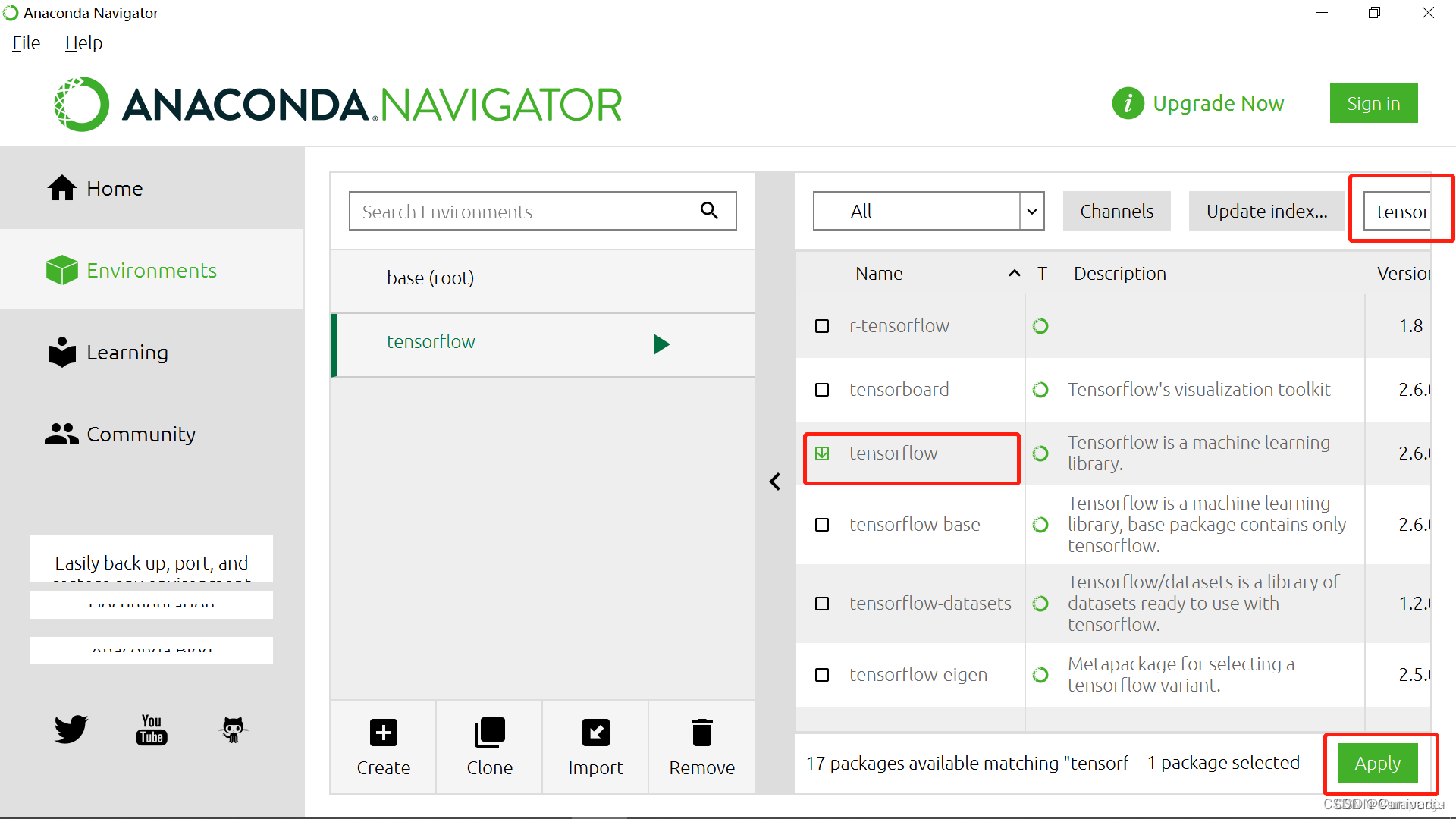
5.点击Apply
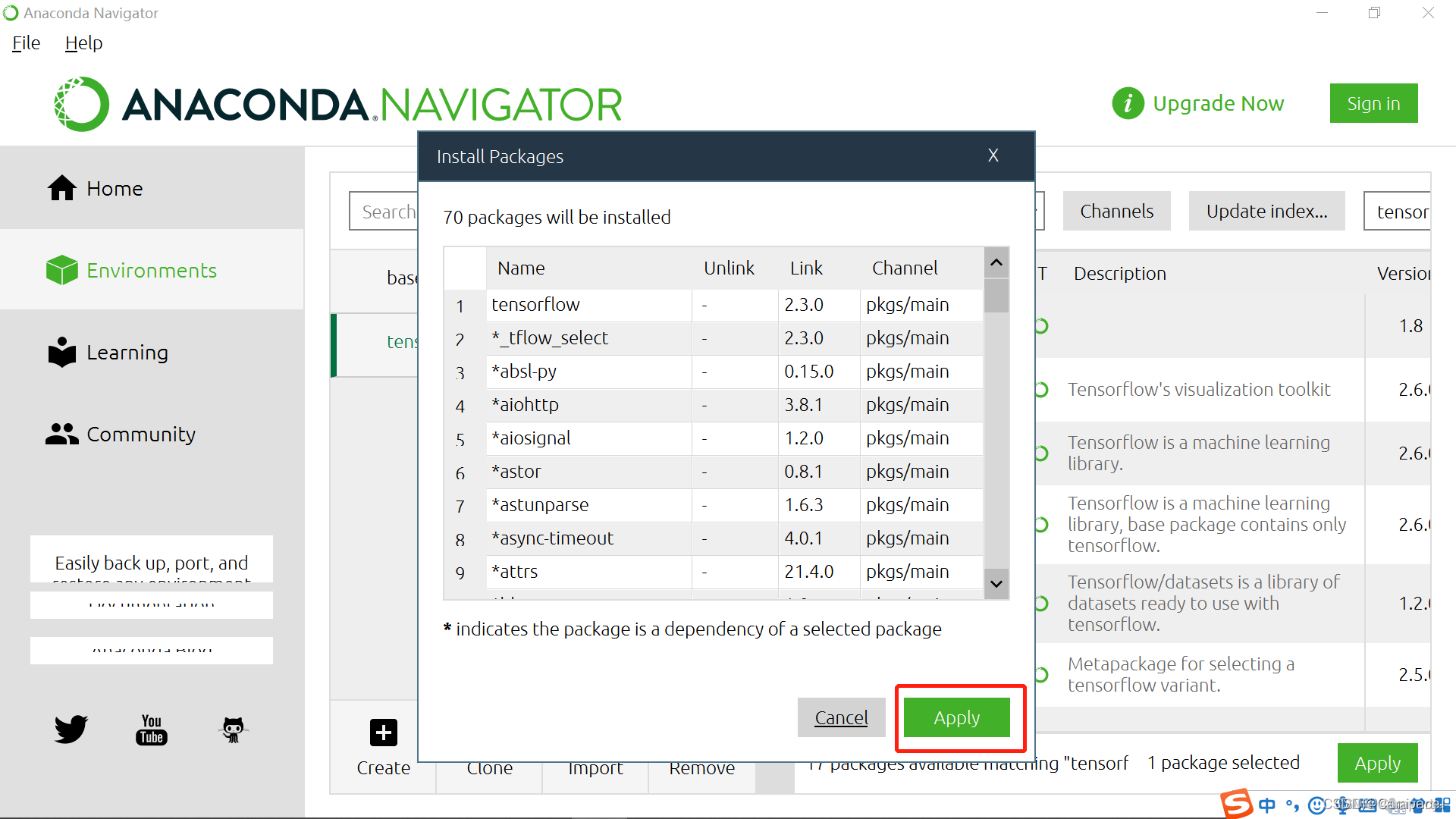
等待安装完成即可
Original: https://blog.csdn.net/m0_46299185/article/details/124280787
Author: bEstow--
Title: 用Anaconda安装TensorFlow(Windows10)