
前言
讲XGboost的代码案例并结合Kaggle上的Titanic数据总结一点数据预处理的技巧。
案例1
简单使用xgboost做分类,了解一些特性。
import xgboost as xgb
import numpy as np
def log_reg(y_hat, y):
p = 1.0 / (1.0 + np.exp(-y_hat))
g = p - y.get_label()
h = p * (1.0-p)
return g, h
def error_rate(y_hat, y):
return 'error', float(sum(y.get_label() != (y_hat > 0.5))) / len(y_hat)
if __name__ == "__main__":
data_train = xgb.DMatrix('agaricus_train.txt')
data_test = xgb.DMatrix('agaricus_test.txt')
print (data_train)
print (type(data_train))
param = {'max_depth': 3, 'eta': 1, 'silent': 1, 'objective': 'binary:logistic'}
watchlist = [(data_test, 'eval'), (data_train, 'train')]
n_round = 7
bst = xgb.train(param, data_train, num_boost_round=n_round, evals=watchlist, obj=log_reg, feval=error_rate)
y_hat = bst.predict(data_test)
y = data_test.get_label()
print(y_hat)
print(y)
error = sum(y != (y_hat > 0.5))
error_rate = float(error) / len(y_hat)
print('样本总数:\t', len(y_hat))
print('错误数目:\t%4d' % error)
print('错误率:\t%.5f%%' % (100*error_rate))
DMatrix不能直接打印出来

XGboost中可以设置参数 watchlist 来显示添加每一刻树时的误差变化
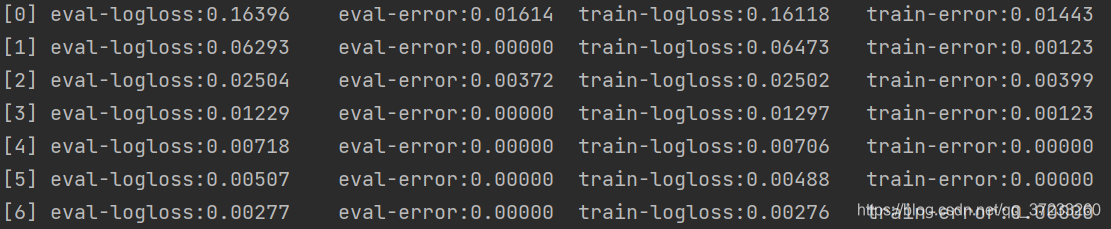
案例2
这是对Titanic数据的处理案例,原数据格式如下:
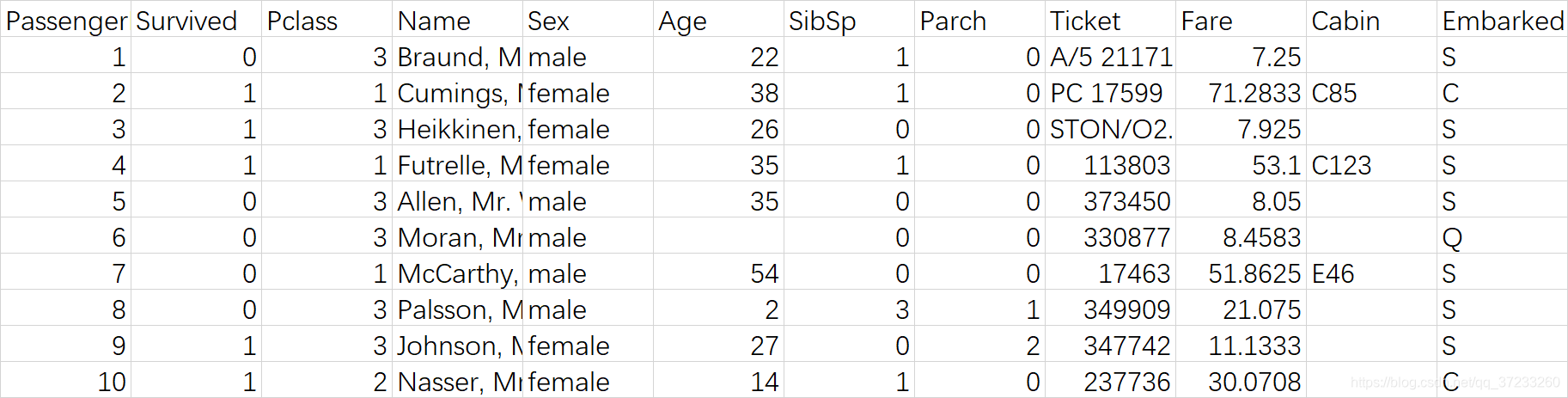
您可以看到,一些缺失的值需要补齐,一些功能需要重新标记。
[En]
You can see that some of the missing values need to be made up, and some features need to be re-tagged.
可以使用describe()方法来统计数据的一些信息:
data = pd.read_csv(file_name)
pd.set_option('display.width',200)
print ('data.describe() = \n', data.describe())
结果:
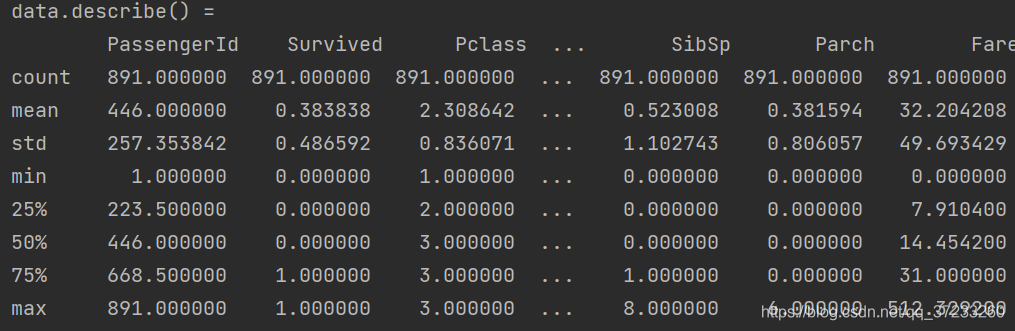
使用map()将性别中的值映射为数值:
data['Sex'] = data['Sex'].map({'female': 0, 'male': 1}).astype(int)
print('data.describe() = \n', data.describe())
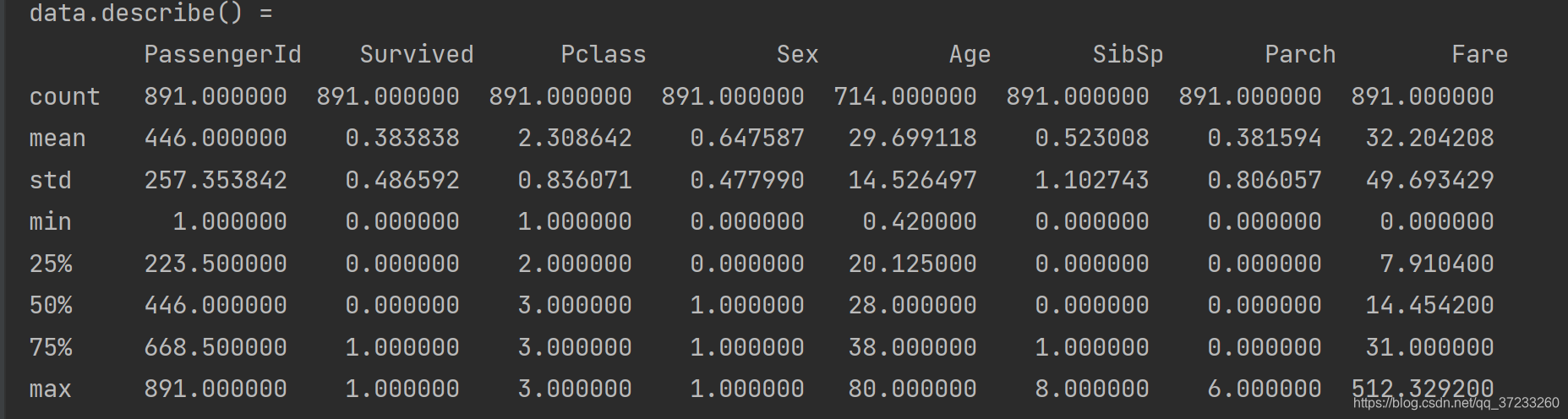
非数值型数据不显示在describe()中。
可以使用仓位来补齐船票价格缺失值:
if len(data.Fare[data.Fare == 0]) > 0:
fare = np.zeros(3)
for f in range(0, 3):
fare[f] = data[data.Pclass == f + 1]['Fare'].dropna().median()
for f in range(0, 3):
data.loc[(data.Fare.isnull()) & (data.Pclass == f + 1), 'Fare'] = fare[f]
这里是使用某类仓位的船票的中位数来补。
也可以将缺失值当作测试集,使用其他分类算法来补:
if is_train:
print ('随机森林预测缺失年龄:--start--')
data_for_age = data[['Age', 'Survived', 'Fare', 'Parch', 'SibSp', 'Pclass']]
age_exist = data_for_age.loc[(data.Age.notnull())]
age_null = data_for_age.loc[(data.Age.isnull())]
x = age_exist.values[:, 1:]
y = age_exist.values[:, 0]
rfr = RandomForestRegressor(n_estimators=1000)
rfr.fit(x, y)
age_hat = rfr.predict(age_null.values[:, 1:])
data.loc[(data.Age.isnull()), 'Age'] = age_hat
print ('随机森林预测缺失年龄:--over--')
else:
print ('随机森林预测缺失年龄2:--start--')
data_for_age = data[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
age_exist = data_for_age.loc[(data.Age.notnull())]
age_null = data_for_age.loc[(data.Age.isnull())]
x = age_exist.values[:, 1:]
y = age_exist.values[:, 0]
rfr = RandomForestRegressor(n_estimators=1000)
rfr.fit(x, y)
age_hat = rfr.predict(age_null.values[:, 1:])
data.loc[(data.Age.isnull()), 'Age'] = age_hat
print ('随机森林预测缺失年龄2:--over--')
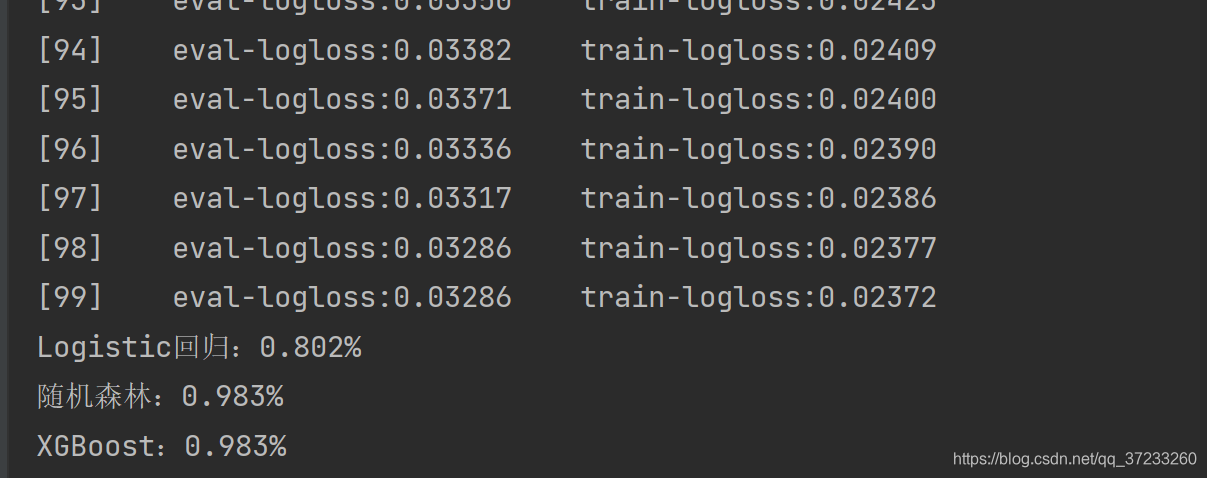
最终的分类结果如下:
案例的所有代码:
import xgboost as xgb
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import csv
def show_accuracy(a, b, tip):
acc = a.ravel() == b.ravel()
acc_rate = 100 * float(acc.sum()) / a.size
print ('%s正确率:%.3f%%' % (tip, acc_rate))
return acc_rate
def load_data(file_name, is_train):
data = pd.read_csv(file_name)
pd.set_option('display.width',200)
print ('data.describe() = \n', data.describe())
data['Sex'] = data['Sex'].map({'female': 0, 'male': 1}).astype(int)
pd.set_option('display.max_columns', None)
print('data.describe() = \n', data.describe())
if len(data.Fare[data.Fare == 0]) > 0:
fare = np.zeros(3)
for f in range(0, 3):
fare[f] = data[data.Pclass == f + 1]['Fare'].dropna().median()
for f in range(0, 3):
data.loc[(data.Fare.isnull()) & (data.Pclass == f + 1), 'Fare'] = fare[f]
if is_train:
print ('随机森林预测缺失年龄:--start--')
data_for_age = data[['Age', 'Survived', 'Fare', 'Parch', 'SibSp', 'Pclass']]
age_exist = data_for_age.loc[(data.Age.notnull())]
age_null = data_for_age.loc[(data.Age.isnull())]
x = age_exist.values[:, 1:]
y = age_exist.values[:, 0]
rfr = RandomForestRegressor(n_estimators=1000)
rfr.fit(x, y)
age_hat = rfr.predict(age_null.values[:, 1:])
data.loc[(data.Age.isnull()), 'Age'] = age_hat
print ('随机森林预测缺失年龄:--over--')
else:
print ('随机森林预测缺失年龄2:--start--')
data_for_age = data[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
age_exist = data_for_age.loc[(data.Age.notnull())]
age_null = data_for_age.loc[(data.Age.isnull())]
x = age_exist.values[:, 1:]
y = age_exist.values[:, 0]
rfr = RandomForestRegressor(n_estimators=1000)
rfr.fit(x, y)
age_hat = rfr.predict(age_null.values[:, 1:])
data.loc[(data.Age.isnull()), 'Age'] = age_hat
print ('随机森林预测缺失年龄2:--over--')
data.loc[(data.Embarked.isnull()), 'Embarked'] = 'S'
embarked_data = pd.get_dummies(data.Embarked)
print (embarked_data)
embarked_data = embarked_data.rename(columns=lambda x: 'Embarked_' + str(x))
data = pd.concat([data, embarked_data], axis=1)
print (data.describe())
data.to_csv('New_Data.csv')
x = data[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked_C', 'Embarked_Q', 'Embarked_S']]
y = None
if 'Survived' in data:
y = data['Survived']
x = np.array(x)
y = np.array(y)
x = np.tile(x, (5, 1))
y = np.tile(y, (5, ))
if is_train:
return x, y
return x, data['PassengerId']
def write_result(c, c_type):
file_name = 'Titanic.test.csv'
x, passenger_id = load_data(file_name, False)
if type == 3:
x = xgb.DMatrix(x)
y = c.predict(x)
y[y > 0.5] = 1
y[~(y > 0.5)] = 0
predictions_file = open("Prediction_%d.csv" % c_type, "wb")
open_file_object = csv.writer(predictions_file)
open_file_object.writerow(["PassengerId", "Survived"])
open_file_object.writerows(zip(passenger_id, y))
predictions_file.close()
if __name__ == "__main__":
x, y = load_data('Titanic.train.csv', True)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=1)
lr = LogisticRegression(penalty='l2')
lr.fit(x_train, y_train)
y_hat = lr.predict(x_test)
lr_acc = accuracy_score(y_test, y_hat)
rfc = RandomForestClassifier(n_estimators=100)
rfc.fit(x_train, y_train)
y_hat = rfc.predict(x_test)
rfc_acc = accuracy_score(y_test, y_hat)
data_train = xgb.DMatrix(x_train, label=y_train)
data_test = xgb.DMatrix(x_test, label=y_test)
watch_list = [(data_test, 'eval'), (data_train, 'train')]
param = {'max_depth': 6, 'eta': 0.8, 'silent': 1, 'objective': 'binary:logistic'}
bst = xgb.train(param, data_train, num_boost_round=100, evals=watch_list)
y_hat = bst.predict(data_test)
y_hat[y_hat > 0.5] = 1
y_hat[~(y_hat > 0.5)] = 0
xgb_acc = accuracy_score(y_test, y_hat)
print ('Logistic回归:%.3f%%' % lr_acc)
print ('随机森林:%.3f%%' % rfc_acc)
print ('XGBoost:%.3f%%' % xgb_acc)
Original: https://blog.csdn.net/qq_37233260/article/details/118712430
Author: Y_蒋林志
Title: 机器学习进阶(8):XGboost代码案例(DMatrix)和一些数据预处理的技巧
相关阅读
Title: Win10 下安装 CUDA Toolkit
目录
- CUDA是什么
- 1.确认适合自己的版本
- 2. 安装 CUDA Toolkit 10.1
- 3.下载并安装与 CUDA 10.1 版本兼容的 cuDNN
- 4. pip 安装 pytorch
- 5. 测试能否可用
CUDA是什么
可以利用CUDA和GPU的并行处理能力来加速深度学习和其他计算密集型应用程序。CUDA是Nvidia开发的一种并行计算平台和编程模型,用于在其自己的GPU(图形处理单元)上进行常规计算。 CUDA使开发人员能够利用GPU的能力来实现计算的可并行化部分,从而加快计算密集型应用程序的速度。
1.确认适合自己的版本
安装 CUDA Toolkit (工具包)之前,注意不是按照的CUDA的版本越高越好,需要考虑安装的开发工具是否和自己的CUDA驱动版本兼容,如果基于 Python 开发,则需根据所采用的深度学习框架(如 Pytorch、TensorFlow)支持的 CUDA 版本,选择可支持的最新版本安装。
1. 首先查看自己本机的CUDA驱动版本:
点开桌面,右键,选择里边的 "NVIDIA 控制面板"。打开后,单击 左下角的 "系统信息" 。如下图所示:
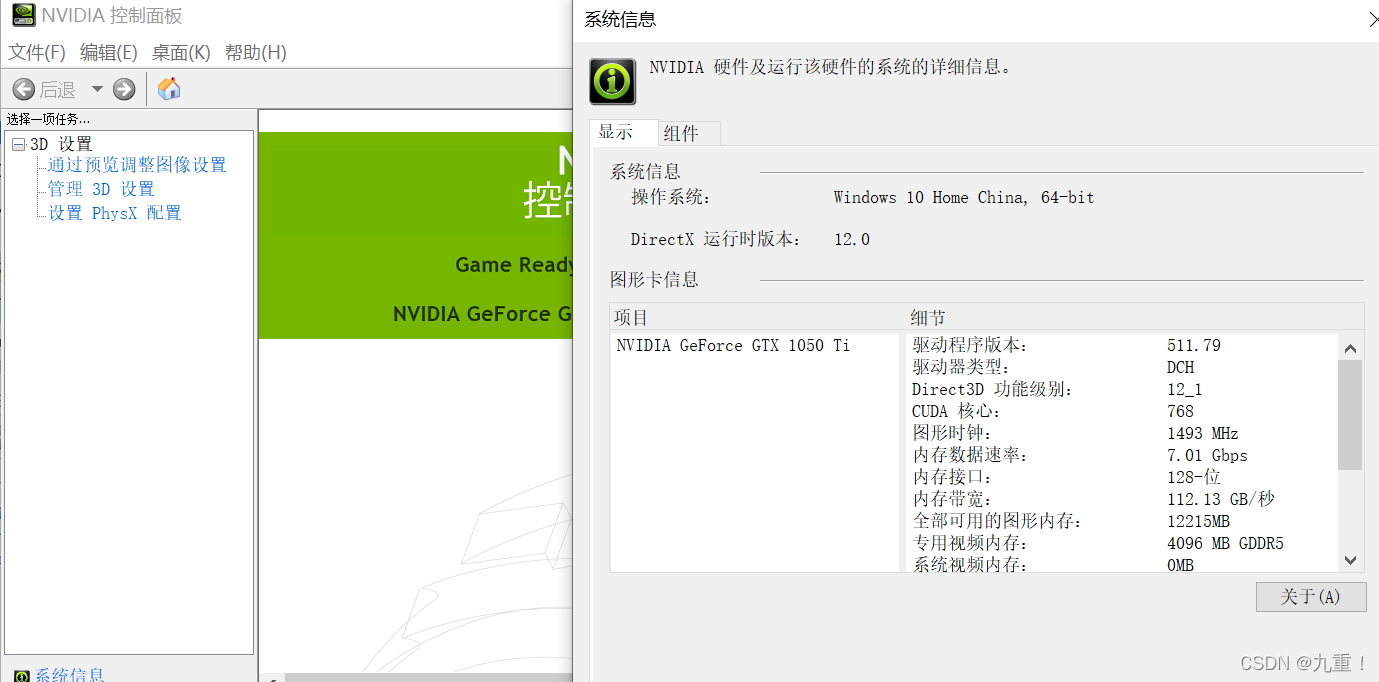
然后查看文档 NVIDIA CUDA Toolkit Release Notes
根据文档的版本,确定否与当前最新的 CUDA Toolkit 版本兼容
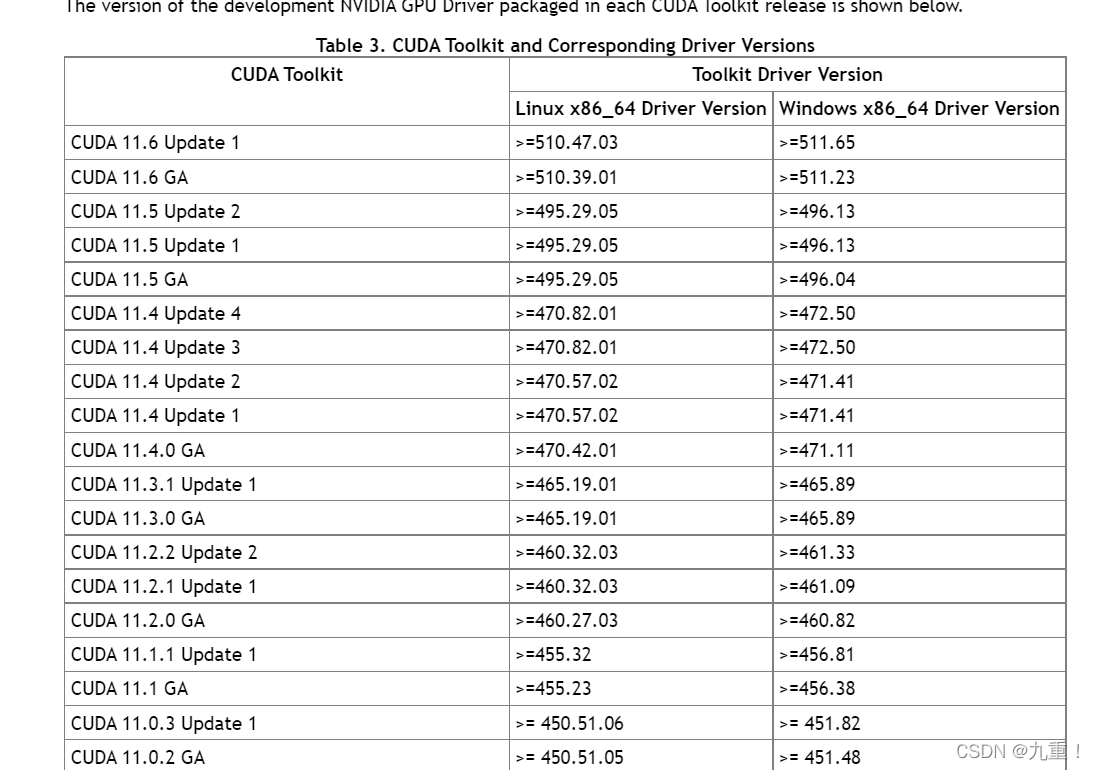

例如,本台电脑511.79,因为是之前更新过的,再这之前我是418.96那个,然后根据上边的表格,选择的应该是 CUDA Toolkit 10.1 这个
点击下载:
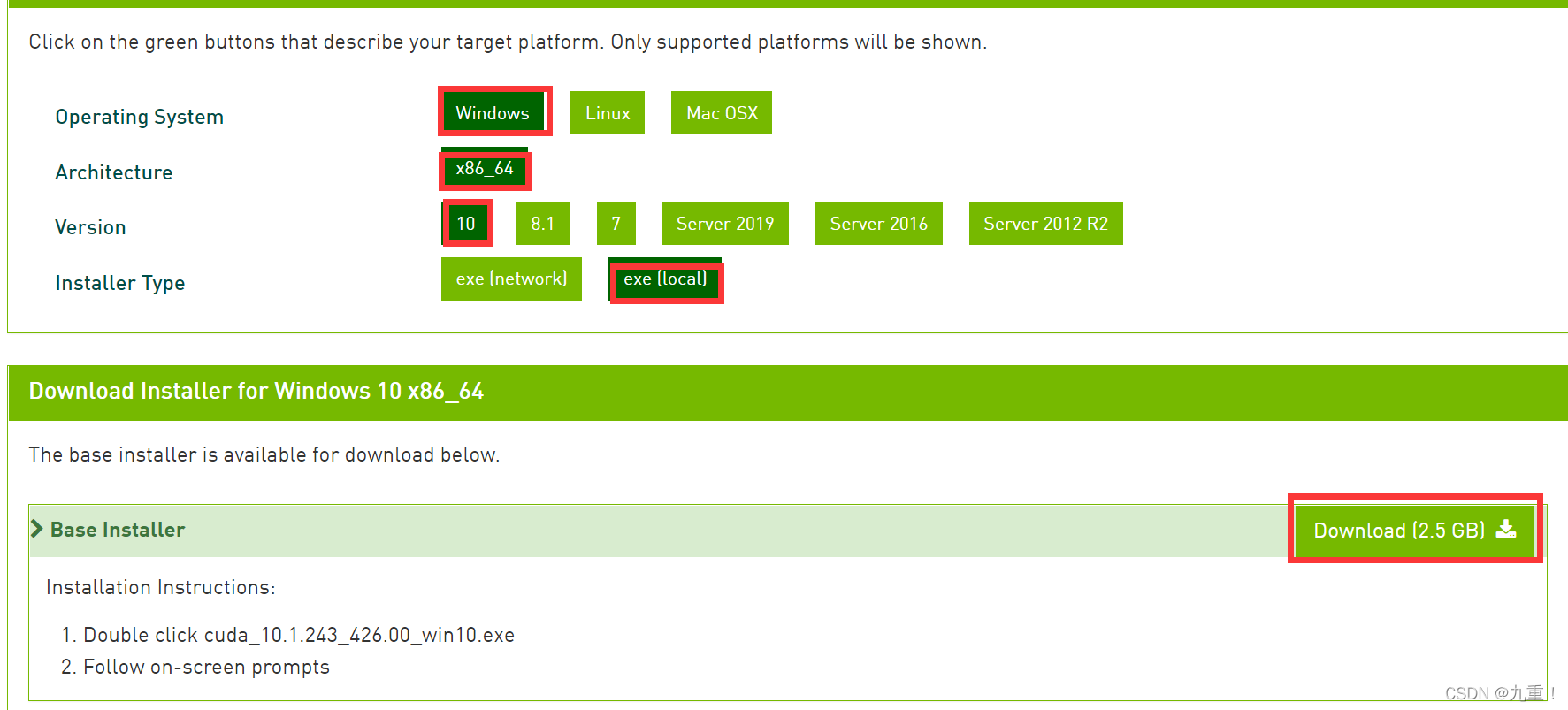
; 2. 安装 CUDA Toolkit 10.1
下载好后,双击运行,可更改路径,点击ok,就开始安装了:
进度条完成后:

等待系统兼容性检测:
同意协议后,选择自定义
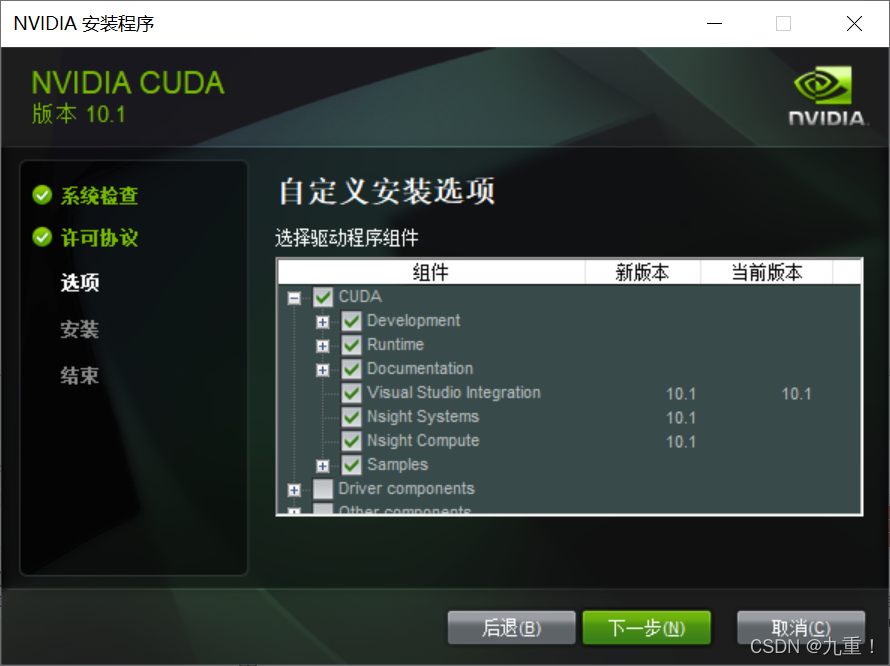
单击 "下一步(N)" 进行安装。
如下图所示,我们只需选择CUDA下面这4项就够了(默认是全选的。。。),visual studio integration这一项没有勾选是因为我并没有使用VS环境。这一步之后,会询问这些组件的安装路径,可以直接使用C盘的默认位置,当然我自定义了一下(请记住这些安装路径,后面配置环境变量需要用到)。
默认安装目录为 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0,示例程序安装目录为 C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0。安装完成后,在命令行窗口(cmd)中,输入 nvcc -V 命令进行测试
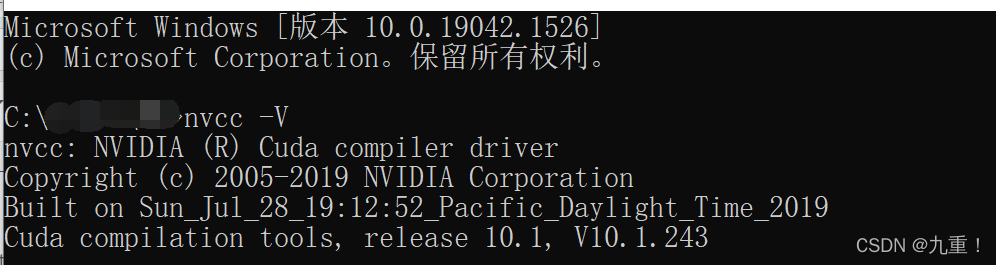
3.下载并安装与 CUDA 10.1 版本兼容的 cuDNN
cuDNN 的全称为 NVIDIA CUDA® Deep Neural Network library,是 NVIDIA 专门针对深度神经网络(Deep Neural Networks)中的基础操作而设计的基于 GPU 的加速库。下载 cuDNN 需要注册,官网下载地址为] https://developer.nvidia.com/cudnn 。本人下载的 cuDNN 版本为
【PS:好像记得这个下载 前要注册、填问卷、加入开发者计划什么的】

同意,选择查看之前的版本,
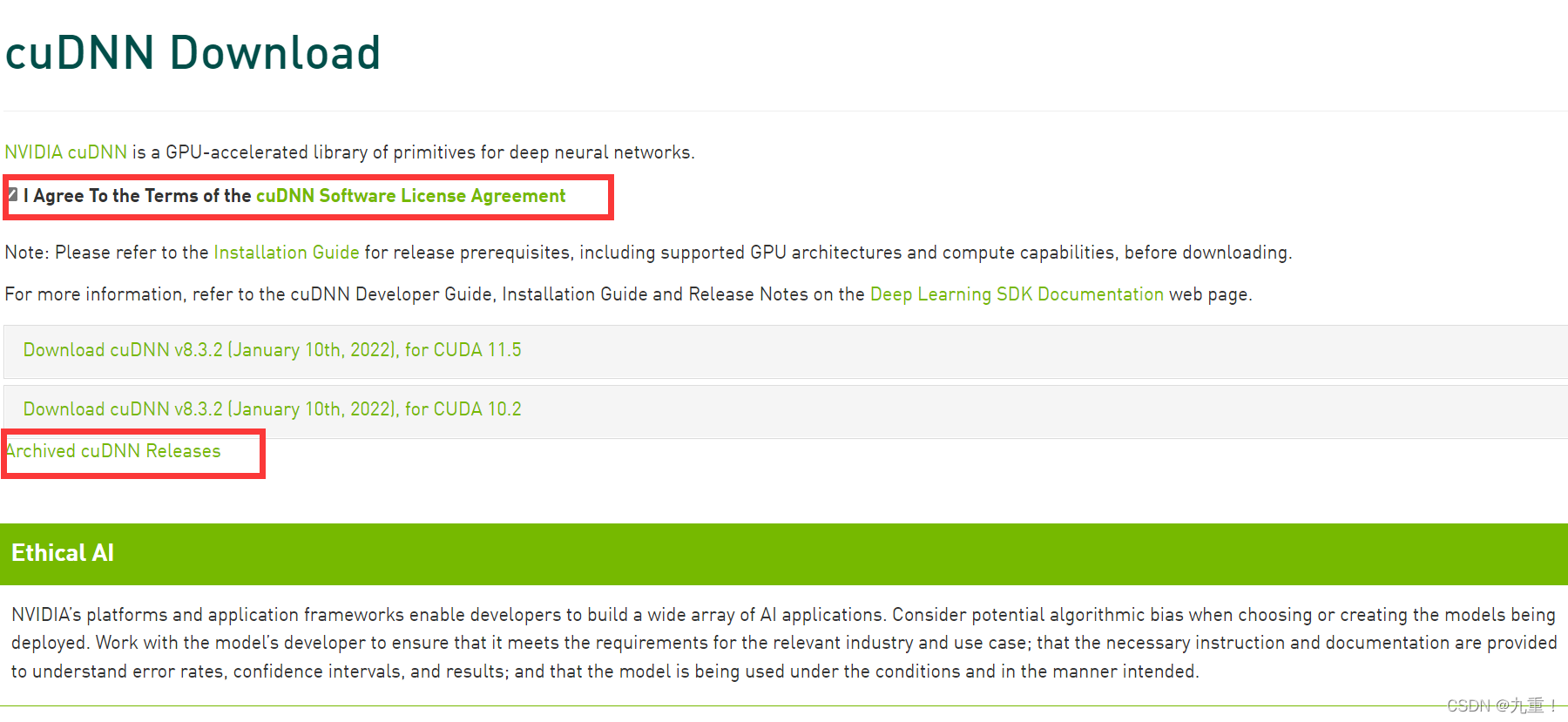
选择正常的版本的进行下载:
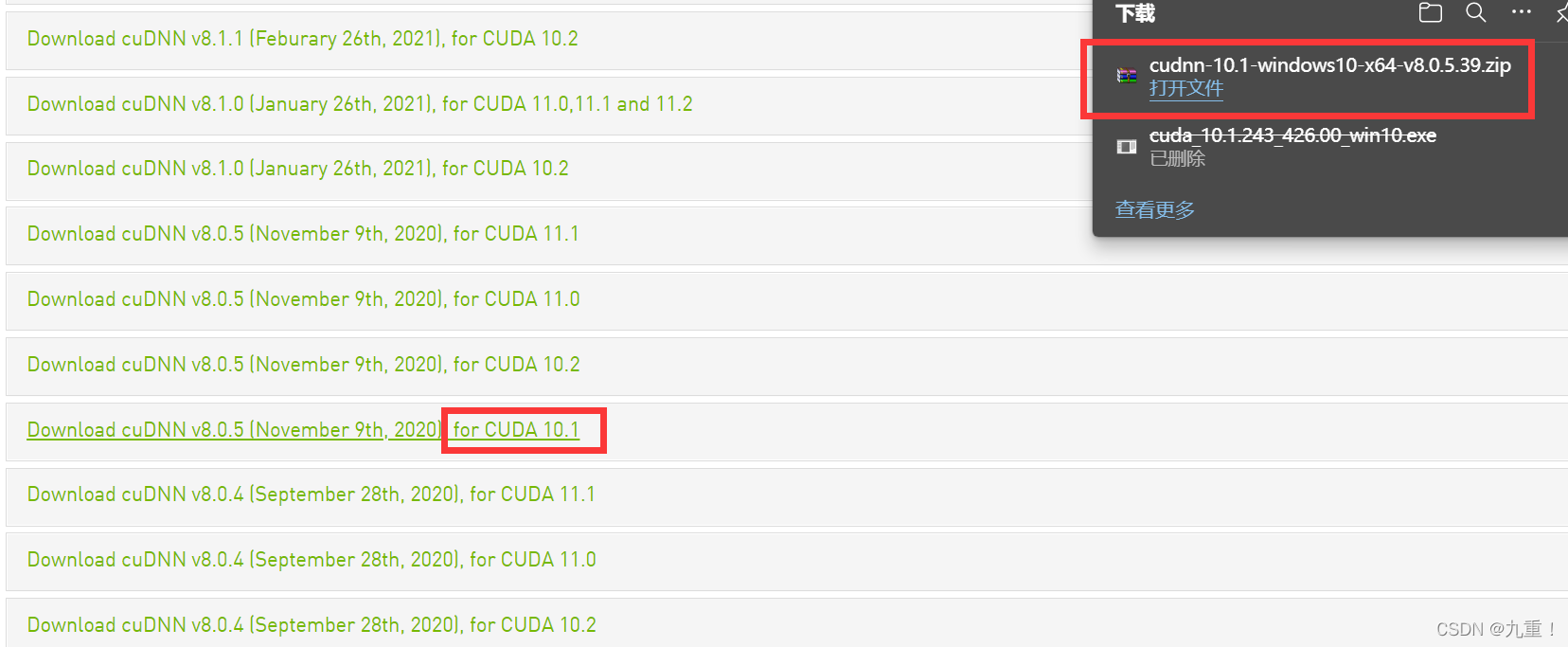
下载好后,解压文件:如下:
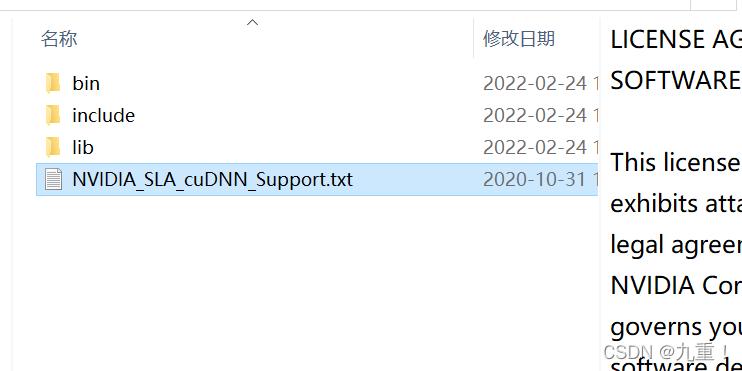
然后,将所有内容复制到 cuda 10.1 安装目录,即可完成 cuDNN 的安装,如下图所示
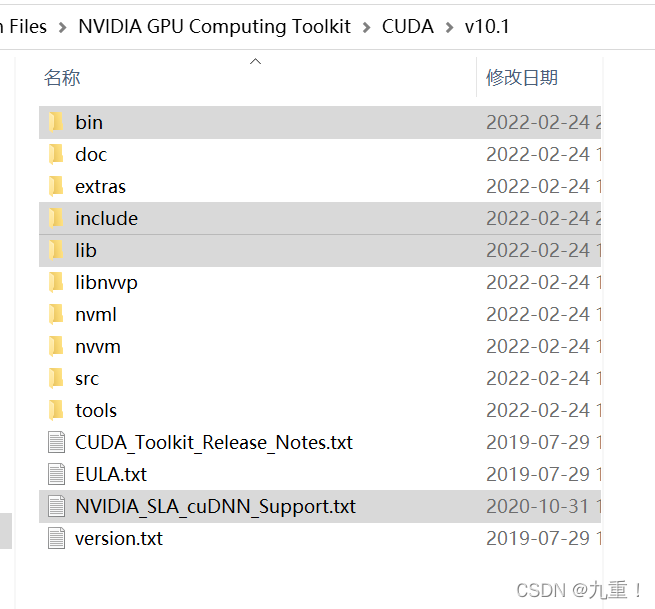
; 4. pip 安装 pytorch
pip install torch==1.8.1+cu101 torchvision==0.9.1+cu101 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
PyTorch先前版本部分截图如下:

cmd 输入命令:

; 5. 测试能否可用
import torch
print(torch.cuda.is_available())

Original: https://blog.csdn.net/weixin_43798572/article/details/123122477
Author: 九重!
Title: Win10 下安装 CUDA Toolkit