
文章目录
- 1、数据集
* - 1.1 可用数据集
- 1.2 scikit-learn数据集
- - 1.3 数据集的划分
- - 2.特征工程
* - 2.1特征工程包含内容
- 3.特征提取
* - 3.1字典特征提取
- 3.2 文本特征提取
- 3.3中文文本特征提取
- 3.4 Tf-idf文本特征提取
- - 4.特征预处理
* - 4.1 归一化
- 4.2 标准化
- 5. 特征降维
* - 5.1 特征选择
- - 6. 主成分分析
- 总结
1、数据集
1.1 可用数据集
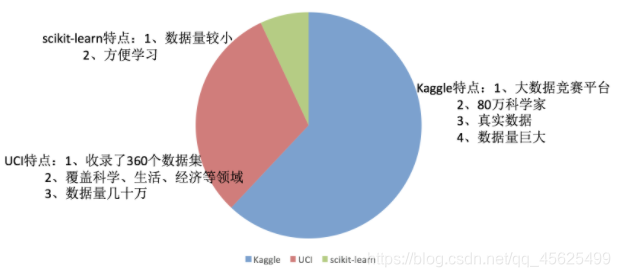
Kaggle网址:https://www.kaggle.com/datasets
UCI数据集网址: http://archive.ics.uci.edu/ml/
scikit-learn网址:https://scikit-learn.org/stable/
; 1.2 scikit-learn数据集
- load_* 获取小规模数据集,数据包含在datasets里
- fetch_* 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
sklearn小数据集
def datasets_demo():
"""
sklearn数据集使用
:return:
"""
iris = load_iris()
print("鸢尾花数据集:\n", iris)
print("查看数据集描述:\n", iris["DESCR"])
print('鸢尾花的目标值:\n', iris.target)
print("查看特征值的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("查看特征值:\n", iris.data, iris.data.shape)
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("训练集的特征值:\n", x_train, x_train.shape)
return None
sklearn大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset='train')
- subset:'train'或者'test','all',可选,选择要加载的数据集。
- 训练集的"训练",测试集的"测试",两者的"全部"
1.3 数据集的划分
- 训练数据:用于训练, 构建模型
- 测试数据:在模型检验时使用,用于 评估模型是否有效,测试集一般在20%~30%
数据集划分API
sklearn.model_selection.train_test_split(arrays, *options)
- x 数据集的特征值
- y 数据集的标签值
- test_size 测试集的大小,一般为float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return 测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("训练集的特征值:\n", x_train, x_train.shape)
2.特征工程
特征工程是使用 专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
- 意义:会直接影响机器学习的效果
2.1特征工程包含内容
- 特征抽取
- 特征预处理
- 特征降维
3.特征提取
特征提取是将任意数据(如文本或图像)转换为可用于机器学习的数字特征。
[En]
Feature extraction is the conversion of arbitrary data (such as text or images) into digital features that can be used in machine learning.
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(深度学习将介绍)
特征提取API: sklearn.feature_extraction
3.1字典特征提取
def dict_demo():
"""
字典特征提取
:return:
"""
data = [{'city': '北京', 'temperature': 100},
{'city': '上海', 'temperature': 60},
{'city': '深圳', 'temperature': 30}]
transfer = DictVectorizer(sparse=False)
data_new = transfer.fit_transform(data)
print('data_new\n', data_new)
print("特征名字: \n", transfer.get_feature_names())
return None
3.2 文本特征提取
def count_demo():
"""
文本特征抽取:CountVecotrizer
:return:
"""
data = ["Life is short, i like like python", "life is too long, i dislike python"]
transfer = CountVectorizer(stop_words=['is', 'too'])
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
3.3中文文本特征提取
def cut_word(text):
"""
进行中文分词:"我爱北京天安门" --->"我 爱 北京 天安门"
:param text:
:return:
"""
text = " ".join(list(jieba.cut(text)))
return text
def count_chinese_demo2():
"""
中文文本特征抽取,自动分词
:return:
"""
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
transfer = CountVectorizer(stop_words=['一种', '因为'])
data_final = transfer.fit_transform(data_new)
print("data_new:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
3.4 Tf-idf文本特征提取
- TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
- TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
公式
- 词频(term frequency,tf)指的是某一个给定的词语在该文件中出现的频率
- 逆向文档频率(inverse document frequency,idf)是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
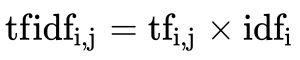
def tfidf_demo():
"""
用tfidf的方法进行文本特征提取
:return:
"""
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
transfer = TfidfVectorizer(stop_words=["一种", '因为'])
data_final = transfer.fit_transform(data_new)
print("data_new:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
4.特征预处理
通过一些 转换函数将特征数据 转换成更加适合算法模型的特征数据过程
原因:一个特征的单位或大小变化很大,或者一个特征的方差比其他特征的方差大几个数量级,这容易影响(支配)目标的结果,以至于一些算法无法学习其他特征。
[En]
Reason: the unit or size of a feature varies greatly, or the variance of one feature is several orders of magnitude larger than that of other features, which is easy to affect (dominate) the target result, so that some algorithms can not learn other features.
数值型数据的无量纲化:
- 归一化
- 标准化
API:sklearn.preprocessing
4.1 归一化
通过对原始数据进行变换把数据映射到(默认为[0,1])之间
def minmax_demo():
"""
归一化
:return:
"""
data = pd.read_csv('dating.txt')
data = data.iloc[:, :3]
transfer = MinMaxScaler()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None
注意:最大值和最小值是可变的,另外,最大值和最小值非常容易受到离群值的影响,所以这种方法健壮性较差,只适用于传统的精准小数据场景。
[En]
Note: the maximum and minimum values are variable, in addition, the maximum and minimum values are very easily affected by outliers, so this method is less robust and is only suitable for traditional accurate small data scenarios.
4.2 标准化
通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
- 对于归一化:如果存在影响最大值和最小值的离群值,则结果将明显改变
[En]
for normalization: if there are outliers that affect the maximum and minimum values, then the results will obviously change*
- 对于标准化:如果有异常值,由于一定的数据量,少数异常值对平均值影响不大,所以方差变化不大。
[En]
for standardization: if there are outliers, due to a certain amount of data, a small number of outliers have little impact on the average, so the variance changes little.*
def stand_demo():
"""
标准化
:return:
"""
data = pd.read_csv('dating.txt')
data = data.iloc[:, :3]
print('data:\n', data)
transfer = StandardScaler()
data_new = transfer.fit_transform(data)
print('data_new:\n', data_new)
return None
在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
5. 特征降维
降维是指在某些限定条件下, 降低随机变量(特征)个数,得到一组" 不相关"主变量的过程
降维的两种方式
- 特征选择
- 主成分分析(可以理解一种特征提取的方式)
5.1 特征选择
数据中包含 冗余或无关变量(或称特征、属性、指标等),旨在从 原有特征中找出主要特征。
方法:
- Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
方差选择法:低方差特征过滤
相关系数 - Embedded (嵌入式):算法自动选择特征(特征与目标值之间的关联)
决策树:信息熵、信息增益
正则化:L1、L2
深度学习:卷积等
API:sklearn.feature_selection
5.1.1 低方差特征过滤
去掉一些低方差的特征。我在前面谈到了差异的含义。结合方差的大小来考虑这种方式的角度。
[En]
Remove some of the features of low variance. I talked about the meaning of variance earlier. Combined with the size of the variance to consider the angle of this way.
- 特征方差小:某个特征大多样本的值比较相近
- 特征方差大:某个特征很多样本的值都有差别
def variance_demo():
"""
过滤低方差特征
:return:
"""
data = pd.read_csv('factor_returns.csv')
data = data.iloc[:, 1:-2]
print('data:\n', data)
transfer = VarianceThreshold(threshold=10)
data_new = transfer.fit_transform(data)
print('data_new:\n', data_new, data_new.shape)
return None
5.1.2 相关系数
皮尔逊相关系数(Pearson Correlation Coefficient)
- 反映变量之间相关关系密切程度的统计指标
def pearsonr_demo():
"""
相关系数计算
:return: None
"""
data = pd.read_csv("factor_returns.csv")
data = data.iloc[:, 1:-2]
r1 = pearsonr(data['pe_ratio'], data['pb_ratio'])
print('pe_ratio与pb_ratio相关系数:\n', r1)
r2 = pearsonr(data['revenue'], data['total_expense'])
print('revenue与total_expense相关系数:\n', r2)
return None
6. 主成分分析
- 定义:将高维数据转换为低维数据的过程,在这个过程中,可能会丢弃原始数据,并创建新的变量
[En]
definition: the process of converting high-dimensional data into low-dimensional data, in which the original data may be abandoned and new variables created*
- 功能:数据维度压缩,尽可能降低原始数据的维度(复杂性),并丢失少量信息。
[En]
function: data dimension compression, reducing the dimension (complexity) of the original data as much as possible, and losing a small amount of information.*
- 应用:回归分析或者聚类分析当中
def pca_demo():
"""
PCA降维
:return:
"""
data = [[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]]
transfer = PCA(n_components=2)
data_new = transfer.fit_transform(data)
print('data_new:\n', data_new)
return None
总结
关于本节所有代码及数据集相关文件参考如下链接:
https://download.csdn.net/download/qq_45625499/21048609?spm=1001.2014.3001.5501
Original: https://blog.csdn.net/qq_45625499/article/details/119652294
Author: 万里守约
Title: Python机器学习—特征工程
相关阅读
Title: 深度理解感受野(一)什么是感受野?
Title: 深度理解感受野(一)什么是感受野?
Introduction
经典目标检测和最新目标跟踪都用到了RPN(region proposal network),锚框(anchor)是RPN的基础,感受野(receptive field, RF)是anchor的基础。本文介绍感受野及其计算方法,和有效感受野概念
什么是感受野?
感受野与视觉
- 感受野(receptive field)这一概念来自于生物神经科学,是指感觉系统中的任一神经元,其所受到的感受器神经元的支配范围。感受器神经元就是指接收感觉信号的最初级神经元
- 视觉来自于光在个体感受器上的投射,它将客观世界的物理信息转化为人们可以感知的神经脉冲信号。
[En]
Vision comes from the projection of light on individual receptors, which converts the physical information of the objective world into nerve pulse signals that people can perceive.*
感受野的定义
One of the basic concepts in deep CNNs is the receptive field, or field of view, of a unit in a certain layer in the network. Unlike in fully connected networks, where the value of each unit depends on the entire input to the network, a unit in convolutional networks only depends on a region of the input.
This region in the input is the receptive field for that unit.
- 在卷积神经网络中,感受野(receptive field)不像输出由整个网络输入所决定的全连接网络那样,它是可以存在于网络中任意某层,输出仅由输入部分决定
- 就是指输出feature map上某个元素受输入图像上影响的区域
![En]
! [] (https://img-blog.csdnimg.cn/20210525205712705.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDc1NjAwMA==,size_16,color_FFFFFF,t_70)
如图所示,共有3个feature map输出。该图说明了2个33的conv可以代替1个55的conv层
- Layer1中方格可看作是一个元素,33的绿色方格则是一个33的卷积核
- Layer2由一个33的卷积核经过卷积运算输出,输出尺寸是33(假设stride=1,padding=0)显而易见,layer2中的绿色方格是由layer1中3*3的绿色方格所决定的。那么这一位置的感受野就是layer1中的绿色方格区域
- Layer3由layer2经过3*3的conv层输出,只有一个
; 理论感受野
https://distill.pub/2019/computing-receptive-fields/
如何计算?
卷积层的理论感受野可以由递推公式计算出来。首先定义下参数意义,r r r代表感受野l l l代表层数k k k代表卷积核大小s s s代表步长
r l = r l − 1 + ( k l − 1 ) ∗ ∏ i = 0 l − 1 s i r_l = r_{l-1}+(k_l - 1)*\prod_{i=0}^{l-1}{s_i}r l =r l −1 +(k l −1 )∗i =0 ∏l −1 s i
最大池化层的理论感受野
r l = r l − 1 + ( k l − 1 ) r_l = r_{l-1}+(k_l - 1)r l =r l −1 +(k l −1 )
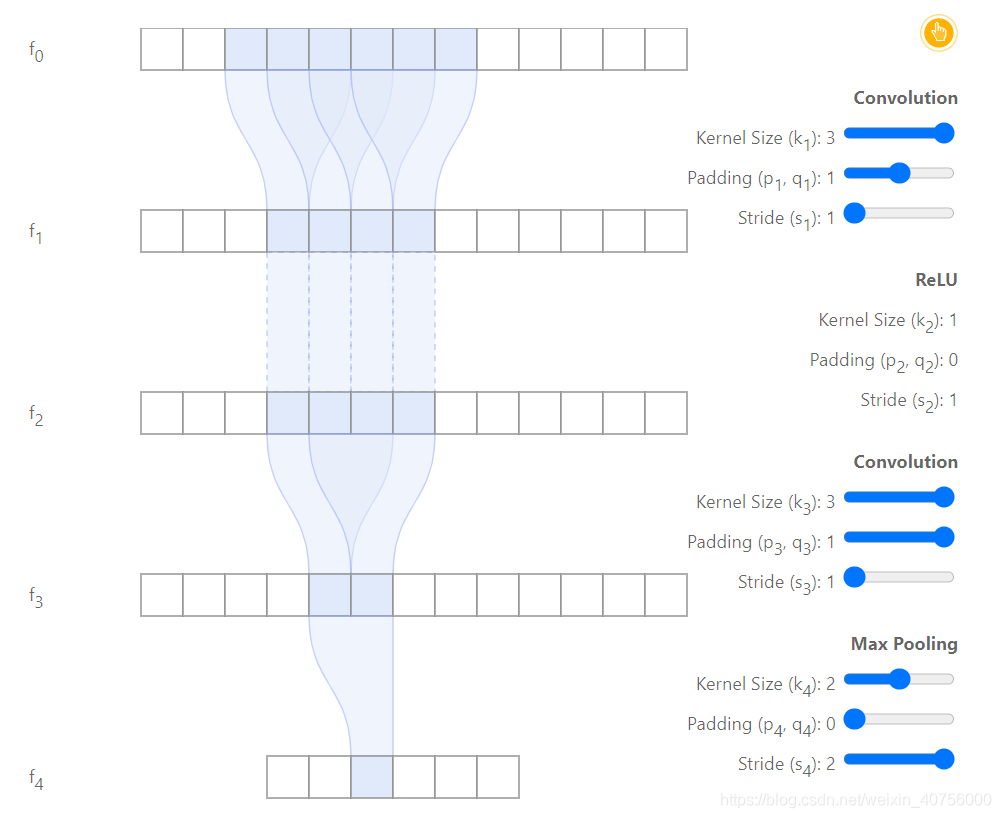
图中,由1个conv33(stride=1,pad=1),1个ReLu层,1个22MaxPooling层(k=2,s=2,p=0)组成。f 0 f_0 f 0 为输入层,f 4 f_4 f 4 层 为输出层。很明显能够发现,f 4 f_4 f 4 层的感受野为6。推导过程如下
- f 1 f_1 f 1 默认感受野为1,即r 0 = 1 r_0=1 r 0 =1
- f 2 f_2 f 2 层为33conv层,r 1 = r 0 + ( k 1 − 1 ) ∗ ∏ i = 0 0 s 0 r_1=r_0+(k_1-1)\prod_{i=0}^{0}{s_0}r 1 =r 0 +(k 1 −1 )∗∏i =0 0 s 0 即r 1 = 1 + ( 3 − 1 ) ∗ 1 = 3 r_1=1+(3-1)*1=3 r 1 =1 +(3 −1 )∗1 =3
- f 3 f_3 f 3 层为激活函数层ReLu,不改变理论感受野大小(也不是没作用,有效感受野里面会提到它的作用)r 2 = 3 r_2=3 r 2 =3
- f 4 f_4 f 4 层为33conv层,和上一个conv层一样,r 3 = 3 + ( 3 − 1 ) ∗ 1 = 5 r_3=3+(3-1)1=5 r 3 =3 +(3 −1 )∗1 =5
- f 5 f_5 f 5 层为22maxpooling层,r 4 = 5 + ( 2 − 1 ) ∗ 1 = 6 r_4=5+(2-1)1=6 r 4 =5 +(2 −1 )∗1 =6
按照上述方法可以计算出主流的backbone理论感受野大小,如下图所示。 数据来自https://distill.pub/2019/computing-receptive-fields/
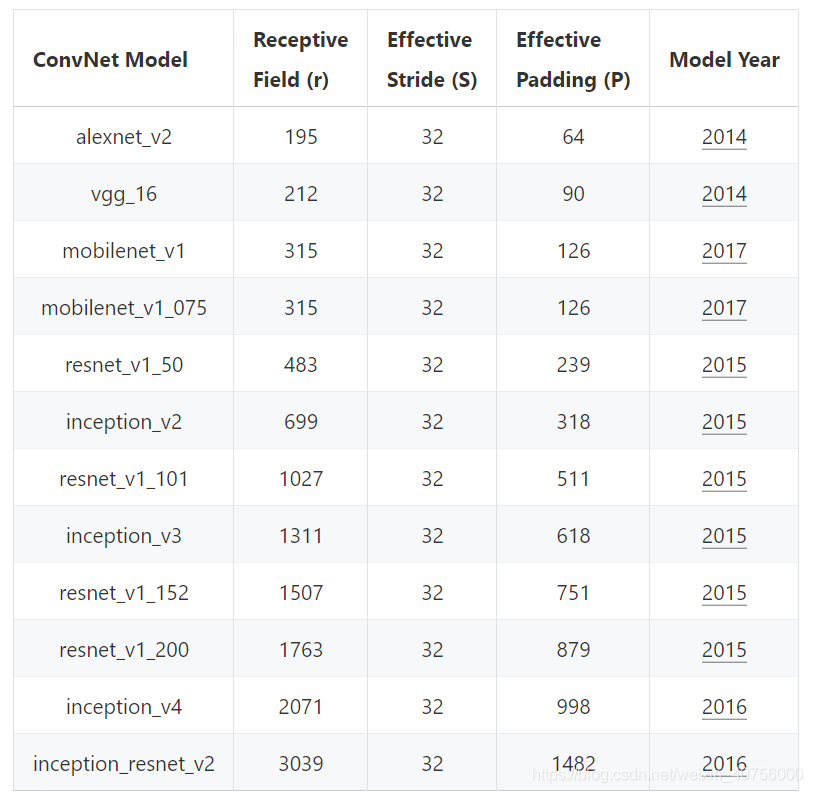
从感受野的计算公式很明显能够看出, stride kernel_size rf_size都会对其产生影响,其中 srtide对感受野大小起决定性作用。
; 有效感受野
有效感受野是在NIPS2016中的Understanding the Effective Receptive Field in Deep Convolutional Neural Networks提出的。
- 有效感受野是一种超参数, 无法像理论感受野那样被精确计算。但是文献[2]中采用求偏导数的方法对每个图像上的像素点,计算出他们对输出特征图的贡献值,并可视化。
- 有限感受野往往比理论感受野要小一些,关系大概是 anchor
- 有效感受野呈 高斯分布,并不是所有像素点的贡献都相同。直观的来说, *感受野中间的像素对于输出会有更大的影响
以下内容整理自:https://blog.csdn.net/DD_PP_JJ/article/details/104448825

采用不同初始化权重的方法和添加ReLU作为激活函数进行实验。Uniform初始化方法使卷积核的权重都为1,没有非线性性质。引入ReLU之后,网络中增加了非线性性,分布变得 a bit less Gaussian


不同的激活函数对ERF的分布也有影响,这说明ERF的分布也取决于 input。ReLU的高斯分布没有另外两个平滑,生成了一个较少的高斯分布,ReLU导致很大一部分梯度归零。上采样和空洞卷积可以增大感受野
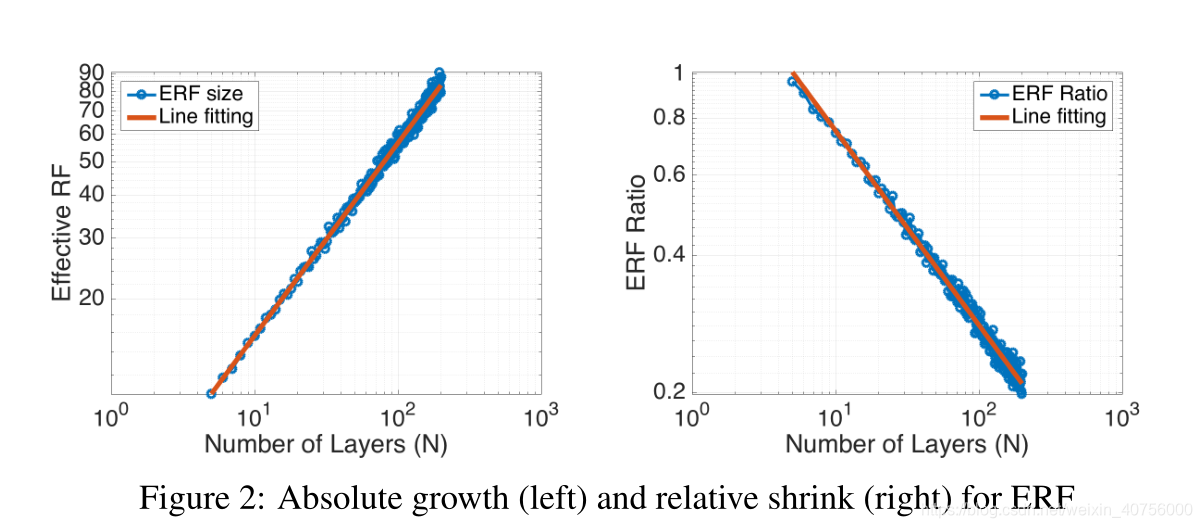
文章中也给出了答案,见上图,随着网络层数的加深,实际有效的感受野是程n \sqrt{n}n 级别增长。而右图展示了随着网络层数的加深,有效感受野占理论感受野的比例是按照1 n \frac{1}{\sqrt{n}}n 1 级别进行缩减的。其中需要注意的是实际感受野的计算方式:若像素值大于(1-96.45%)的中心像素值,就认为该像素处于实际感受野中
哪些操作可以改变感受野?
- Convolution
- DeConvolution
- Pooling
- Residential connection
- Concatenation
参考文献
[1] A guide to convolution arithmetic for deep learning
[2] Understanding the Effective Receptive Field in Deep Convolutional Neural Networks
Original: https://blog.csdn.net/weixin_40756000/article/details/117264194
Author: 黑夜里游荡
Title: 深度理解感受野(一)什么是感受野?Original: https://blog.csdn.net/weixin_40756000/article/details/117264194
Author: 黑夜里游荡
Title: 深度理解感受野(一)什么是感受野?