
文章目录
- 1 针孔相机模型
- 2.双目相机模型
- 3.立体校正(共面行对准、极线校正)
* - 3.1极线约束
- 3.2Bouguet算法
- 3.3OpenCV API 介绍
- 4. 立体匹配与视差图
- 5.深度图
* - 5.1 基础介绍
- 5.2OpenCV API
- 6.双目测距精度分析
- 7.总结
1 针孔相机模型
如基本相机模型及参数中介绍的,首先回忆一下针孔相机模型,

如上图,空间中的一点到图像平面的变换为:
Z M [ x m y m 1 ] = [ f 0 0 0 f 0 0 0 1 ] [ Z M Y M Z M ] Z_M\begin{bmatrix} x_m \ y_m\ 1 \end{bmatrix} = \begin{bmatrix} f & 0 & 0\ 0 & f& 0\ 0 & 0 & 1 \end{bmatrix}\begin{bmatrix} Z_M \ Y_M\ Z_M\end{bmatrix}Z M ⎣⎡x m y m 1 ⎦⎤=⎣⎡f 0 0 0 f 0 0 0 1 ⎦⎤⎣⎡Z M Y M Z M ⎦⎤,而图像平面到像素平面的关系可表示为:
[ μ v 1 ] = [ d x 0 μ 0 0 d y v 0 0 0 1 ] [ x m y m 1 ] \begin{bmatrix} \mu\ v\ 1 \end{bmatrix}=\begin{bmatrix} d_x & 0 &\mu_0 \ 0 & d_y& v_0\ 0 & 0 & 1 \end{bmatrix}\begin{bmatrix} x_m\ y_m\ 1 \end{bmatrix}⎣⎡μv 1 ⎦⎤=⎣⎡d x 0 0 0 d y 0 μ0 v 0 1 ⎦⎤⎣⎡x m y m 1 ⎦⎤
由以上可知相机坐标系下空间中的点到像素坐标系的变换关系为,
Z M [ μ v 1 ] = [ f d x 0 μ 0 0 f d y v 0 0 0 1 ] [ X M Y M Z M ] = K [ X M Y M Z M ] Z_M\begin{bmatrix} \mu\ v\ 1 \end{bmatrix}=\begin{bmatrix} fd_x & 0&\mu_0 \ 0& fd_y& v_0\ 0& 0 &1 \end{bmatrix}\begin{bmatrix} X_M\ Y_M\ Z_M \end{bmatrix}=K\begin{bmatrix} X_M\ Y_M\ Z_M \end{bmatrix}Z M ⎣⎡μv 1 ⎦⎤=⎣⎡f d x 0 0 0 f d y 0 μ0 v 0 1 ⎦⎤⎣⎡X M Y M Z M ⎦⎤=K ⎣⎡X M Y M Z M ⎦⎤
K即相机的内参矩阵。
考虑畸变,常用的畸变模型有五个参数,分别是( k 1 , k 2 , p 1 , p 2 , k 3 ) (k_1,k_2,p_1,p_2,k_3)(k 1 ,k 2 ,p 1 ,p 2 ,k 3 ) <br>其中k 1 , k 2 , k 3 k_1,k_2,k_3 k 1 ,k 2 ,k 3 表示的是径向畸变,取的是畸变原点周围的泰勒展开式的前三项,常用描述公式为
{ x d i s t o r t e d = x ( 1 + k 1 r 2 + k 2 r 4 + k 3 r 6 ) y d i s t o r t e d = y ( 1 + k 1 r 2 + k 2 r 4 + k 3 r 6 ) \begin{cases} x_{distorted} = x(1+k_1r^2+k_2r^4+k_3r^6)\ y_{distorted} = y(1+k_1r^2+k_2r^4+k_3r^6) \end{cases}{x d i s t o r t e d =x (1 +k 1 r 2 +k 2 r 4 +k 3 r 6 )y d i s t o r t e d =y (1 +k 1 r 2 +k 2 r 4 +k 3 r 6 )
( x , y ) (x,y)(x ,y )是校正后的像素点,( x d i s t o r t e d , y d i s t o r t e d ) (x_distorted,y_distorted)(x d i s t o r t e d ,y d i s t o r t e d )是原图上的像素点,r = x 2 + y 2 r=\sqrt{x^2+y^2}r =x 2 +y 2 是像素点到图像中心的距离。
其中p 1 , p 2 p_1,p_2 p 1 ,p 2 表示的是切向畸变,是由于安装时导致的镜头不平行镜头平面而产生的安装误差,其描述公式为:
{ x d i s t o r t e d = x + 2 p 1 x y + p 2 ( r 2 + 2 x 2 ) y d i s t o r t e d = y + 2 p 2 x y + p 1 ( r 2 + 2 y 2 ) \begin{cases} x_{distorted} = x + 2p_1xy + p_2(r^2+2x^2) \ y_{distorted} = y + 2p_2xy + p_1(r^2+2y^2) \end{cases}{x d i s t o r t e d =x +2 p 1 x y +p 2 (r 2 +2 x 2 )y d i s t o r t e d =y +2 p 2 x y +p 1 (r 2 +2 y 2 )
; 2.双目相机模型

上图所示是最理想的双目相机模型,图中,C 1 , C 2 C_1,C_2 C 1 ,C 2 分别表示的左右相机的坐标系原点,空间中一点P P P在左右相机的图像平面中的点如图p 1 p_1 p 1 和p 2 p_2 p 2 所示,相机C 1 C_1 C 1 和C 2 C_2 C 2 焦距相同的都为f f f且两相机在同一平面上,图像平面在同一平面上,两个相机成像的图像像素宽度都为W W W,则p 1 p1 p 1在左图中横轴上的像素坐标为x 1 x_1 x 1 ,p 2 p_2 p 2 在右图中的横轴上的像素坐标为x 2 x_2 x 2 ,两个相机之间的距离为b b b,点P P P到相机平面的距离即深度为L L L,像平面到相机平面的距离为f f f。
上图中△ P p 1 p 2 ∼ △ P C 1 C 2 \triangle Pp_1p_2\sim\triangle PC_1C_2 △P p 1 p 2 ∼△P C 1 C 2 ,因此有如下关系:
b − ( x 1 − W / 2 ) − ( W / 2 − x 2 ) b = L − f L \frac{b-(x_1-W/2) - (W/2-x_2)}{b}=\frac{L-f}{L}b b −(x 1 −W /2 )−(W /2 −x 2 )=L L −f 由上式可以求得L = f b x 1 − x 2 L=\frac{fb}{x_1-x_2}L =x 1 −x 2 f b ,其中x 1 − x 2 x_1-x_2 x 1 −x 2 表示的是点P在左右相机中的像素点的横坐标之差,也被称为视差。如何在左右图像中匹配到点P的像素点p 1 p_1 p 1 、p 2 p_2 p 2 是双目测距中的关键,由上述公式可以看出,深度与视差成反比关系,距离越远视差越小,距离越近,视差越小。
实际的双目相机往往无法满足上述理想的条件,这里提出几个问题,
- 如何找到两个图像中相同的像素点的位置?
- 两个相机不在同个平面
- 两个相机的焦距不同怎么样
- 两个相机的图像有多少的是重合的
- 当点距离相机过近时,盲区如何计算
- 两个相机的基线是如何求出来的
- 两个相机获取图像如何同步
3.立体校正(共面行对准、极线校正)
3.1极线约束
1.2中假设两个相机的像平面和基线都是平行的,但实际情况往往并非如此,因此需要将两个视图进行投影变换,使两个成像平面平行于基线,且同一个点在左右两幅图像中位于同一行,以应用上图介绍的三角原理,简称共面行对准。
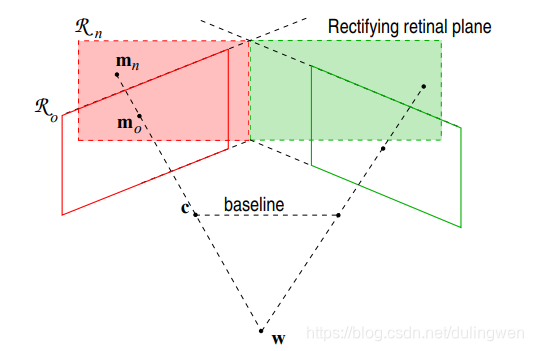
根据对极几何的原理,如下图所示,
图片来自于《视觉SLAM十四讲》

点P是空间中的一点,O 1 O_1 O 1 和O 2 O_2 O 2 分别是左右相机的中心,平面P O 1 O 2 PO_1O_2 P O 1 O 2 称为极平面(epipolar plane),O 1 , O 2 O_1,O_2 O 1 ,O 2 连线与像平面I 1 , I 2 I_1,I_2 I 1 ,I 2 的交点分别为e 1 e_1 e 1 和e 2 e_2 e 2 称为极点(epipoles),如前所述O 1 O 2 O_1O_2 O 1 O 2 称为基线,极平面与图像平面I 1 , I 2 I_1,I_2 I 1 ,I 2 的交线称为极线, 极线约束是指给定图像上一点,其在另一幅图像上的匹配点一定在对应的极线上。
可以通过对极约束来求左右相机之间的旋转和平移关系。上图中P ( X , Y , Z ) P(X,Y,Z)P (X ,Y ,Z )左右相机的两个像素点p 1 , p 2 p_1,p_2 p 1 ,p 2 的像素位置由相机的成像原理可知为:
s 1 p 1 = K P 和 s 2 p 2 = K ( R P + t ) s_1p_1=KP和s_2p_2=K(RP+t)s 1 p 1 =K P 和s 2 p 2 =K (R P +t )
这里P的坐标是在左相机的相机坐标系下,R R R和t t t分别表示左相机坐标系到右相机坐标系下的旋转和平移向量,K是相机的内参矩阵。当使用齐次坐标系(即增加1维为1),一个向量表示为( x , y , z , 1 ) T (x,y,z,1)^T (x ,y ,z ,1 )T,对其乘以任意的常数后,依然为其自身(需保持最后一维为1)。因此如s 1 p 1 s_1p_1 s 1 p 1 与p 1 p_1 p 1 在齐次坐标系下意义相同。这种相等关系为尺度意义下相等,表示为s p ≃ p sp\simeq p s p ≃p,则:
p 1 ≃ K P , p 2 ≃ K ( R P + t ) x 1 = K − 1 p 1 , x 2 = K − 1 p 2 p_1 \simeq KP,p_2 \simeq K(RP+t)\x_1=K^{-1}p_1,x_2=K^{-1}p_2 p 1 ≃K P ,p 2 ≃K (R P +t )x 1 =K −1 p 1 ,x 2 =K −1 p 2
这里x 1 , x 2 x_1,x_2 x 1 ,x 2 表示归一化平面上的坐标,归一化平面的表示如下图:
图片引用自 https://www.cnblogs.com/yutian-blogs/p/13543481.html

代入上式,
x 2 ≃ R x 1 + t x_2\simeq Rx_1+t x 2 ≃R x 1 +t
两边同时左乘向量t t t的反对称矩阵t ∧ t^{\wedge}t ∧,相当于与向量t t t做外积
t ∧ x 2 ≃ t ∧ R x 1 t^{\wedge} x_2\simeq t^{\wedge}Rx_1 t ∧x 2 ≃t ∧R x 1
两侧同时左乘x 2 T x_2^T x 2 T 得:
x 2 T t ∧ x 2 ≃ x 2 T t ∧ R x 1 x_2^Tt^\wedge x_2\simeq x_2^Tt^\wedge Rx_1 x 2 T t ∧x 2 ≃x 2 T t ∧R x 1
上式中由向量的外积和内积的性质可知,左侧恒为零,因此上式可写为:
x 2 T t ∧ R x 1 = 0 x_2^Tt^\wedge Rx_1 = 0 x 2 T t ∧R x 1 =0
重新代入p 1 , p 2 p_1,p_2 p 1 ,p 2 可以得到:
p 2 T K − T t ∧ R K − 1 p 1 = 0 p_2^TK^{-T}t^\wedge RK^{-1}p_1=0 p 2 T K −T t ∧R K −1 p 1 =0
这个公式称为 对极约束,它的几何意义是O 1 , O 2 , P O_1,O_2,P O 1 ,O 2 ,P三点共面。把上式中间部分记作两个矩阵, 基础矩阵(Fundamental Matrix)和 本质矩阵(Essential Matrix),上式可简化为:
E = t ∧ R , F = K − T E K − 1 , x 2 T E x 1 = p 2 T F p 1 = 0 E=t^\wedge R, F=K^{-T}EK^{-1},x_2^TEx_1=p_2^TFp_1=0 E =t ∧R ,F =K −T E K −1 ,x 2 T E x 1 =p 2 T F p 1 =0
因此求处矩阵E或F就能求出R和t,就能求出左右相机之间的关系,就能求出相机的基线长度。
我们做立体校正的目的,正是为了得到如双目相机模型中描述的那样,使两条极线共线,以进行高效的立体匹配,因此立体匹配也称为极线校正,立体校正所做的事情就是 根据摄像头定标后获得的单目内参数据(焦距、成像原点、畸变系数)和双目相对位置关系(旋转矩阵和平移向量),分别对左右视图进行消除畸变和行对准,使得左右视图的成像原点坐标一致、两摄像头光轴平行、左右成像平面共面、对极线行对齐。
; 3.2Bouguet算法
以Bouguet算法为例说明立体校正的过程。
假设右目到左目的旋转矩阵和平移矩阵分别为R和T,如下图:
引用自:
https://blog.csdn.net/Txianshengfantexi/article/details/119454616

空间中的点P P P在左右相机坐标系的坐标的关系为:
P l = R P r + T P_l = RP_r+T P l =R P r +T
Bouguet双目立体校正,
- 首先
- 左相机坐标系沿旋转向量R的正方向旋转一半的R(向量),记该旋转为R h 1 R_{h1}R h 1 ;
- 右相机坐标系沿旋转向量R的反方向旋转一半的R(向量),记该旋转为R h 2 R_{h2}R h 2
- 如下图所示:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q4diPmox-1647592312229)(imgs/2_h12.jpg)]
结果为 经过左右相机一半的旋转后,左相机坐标系和右相机坐标系平行但不共面,此时,左右相机的x轴、y轴和z轴分别平行,但是左右相机的xoy平面不共面,满足关系P l = P r + R h 2 ∗ T P_l=P_r+R_{h2}T P l =P r +R h 2 ∗T记t = R h 2 ∗ T t = R_{h2}T t =R h 2 ∗T
经过左右相机一半的旋转后,左相机坐标系和右相机坐标系平行但不共面,此时,左右相机的x轴、y轴和z轴分别平行,但是左右相机的xoy平面不共面,满足关系P l = P r + R h 2 ∗ T P_l=P_r+R_{h2}T P l =P r +R h 2 ∗T记t = R h 2 ∗ T t = R_{h2}T t =R h 2 ∗T - 然后,将平行但不共面的左右相机坐标系旋转R r e c t R_{rect}R r e c t 至与矫正坐标系O r e c t − X r e c t Y r e c t Z r e c t O_{rect}-X_{rect} Y_{rect} Z_{rect}O r e c t −X r e c t Y r e c t Z r e c t 平行,使左右相机坐标系平行且共面:
 矫正后满足:
矫正后满足: - 矫正坐标系的O r e c t X r e c t O_{rect}X_{rect}O r e c t X r e c t 轴 与 左右相机坐标系 原点连线O L O R O_LO_R O L O R 平行,其正方向由O L O_L O L 指向O R O_R O R ;
- 矫正坐标系的X r e c t O r e c t Z r e c t X_{rect}O_{rect}Z_{rect}X r e c t O r e c t Z r e c t 平面与平面Z L O L O R Z R Z_LO_LO_RZ_R Z L O L O R Z R 平行,矫正坐标系的O r e c t Y r e c t O_{rect}Y_{rect}O r e c t Y r e c t 轴垂直该平面。
- 矫正矩阵R r e c t R_{rect}R r e c t 的每一列分别对应相机坐标系基轴(单位向量)在矫正坐标系中的投影;而矫正矩阵R r e c t R_{rect}R r e c t 的每一行分别对应矫正坐标系基轴(单位向量)在相机坐标系中的投影。
- 旋转矩阵R r e c t R_{rect}R r e c t 的构造方法构是通过右相机相对于左相机的偏移矩阵T完成的,使得基线与成像平面平行,推导参考6。
- 最终得到左右相机的旋转矩阵为:
{ R l = R r e c t ∗ R h 1 R r = R r e c t ∗ R h 2 \left{\begin{matrix} R_l = R_{rect}R_{h1}\ R_r = R_{rect}R_{h2} \end{matrix}\right.{R l =R r e c t ∗R h 1 R r =R r e c t ∗R h 2 这正是OpenCV函数StereoRectify函数返回的R 1 R_1 R 1 和R 2 R_2 R 2
得到左右相机的旋转矩阵之后,即可进行立体校正,步骤:
- 分别将两个图像的像素坐标系通过共同的内参矩阵转换到相机坐标系;
- 分别对两个相机坐标系进行旋转得到新的相机坐标系,通过左乘旋转矩阵R l R_l R l 逆和R r R_r R r 逆;(极线约束)
- 针对新的相机坐标分别进行左、右相机的去畸变操作;
- 去畸变操作结束后,分别用左、右相机的内参矩阵将左、右两个相机坐标系重新转换到左、右图像像素坐标系;
- 并分别用左、右源图像的像素值对新左、右图像的像素点进行插值
; 3.3OpenCV API 介绍
void cv::stereoRectify (
InputArray cameraMatrix1,
InputArray distCoeffs1,
InputArray cameraMatrix2,
InputArray distCoeffs2,
Size imageSize,
InputArray R,
InputArray T,
OutputArray R1,
OutputArray R2,
OutputArray P1,
OutputArray P2,
OutputArray Q,
int flags = CALIB_ZERO_DISPARITY,
double alpha = -1,
Size newImageSize = Size(),
Rect* validPixROI1 = 0,
Rect* validPixROI2 = 0
)
- R R R第一个相机坐标系到第二个相机坐标系下的旋转矩阵
- T T T第一个相机坐标到第二个相机坐标下的平移向量
- R 1 R_1 R 1 第一个相机的修正变换3 × 3 3\times 3 3 ×3 矩阵,将第一个相机坐标系中的点变换到第一个相机对应的修正坐标系下
- P 1 P_1 P 1 第一个相机在第一个相机的修正坐标系下的3 × 4 3\times 4 3 ×4投影矩阵。将第一个相机修正坐标系下的点投影到第一个相机修正图像上
- Q Q Q,4 × 4 4\times 4 4 ×4的视差到深度的映射矩阵,结合
reprojectImageTo3D函数,将视差图转为深度图。 - f l a g s flags f l a g s,值为0或
CALIB_ZERO_DISPARITY,如果设置此参数,则每个相机的主点在修正后的图像中是不变的。
R R R、T T T可通过 stereoCalibrate函数获得。对于水平双目,左右目相机在修正后的相机中主要是X轴方向的偏移,相应的左右目的极线是水平的,y轴相同,P 1 P_1 P 1 和P 2 P_2 P 2 形如:
P1 = [ f 0 c x 1 0 0 f c y 0 0 0 1 0 ] P2 = [ f 0 c x 2 T x ∗ f 0 f c y 0 0 0 1 0 ] \texttt{P1} = \begin{bmatrix} f & 0 & cx_1 & 0 \ 0 & f & cy & 0 \ 0 & 0 & 1 & 0 \end{bmatrix} \ \texttt{P2} = \begin{bmatrix} f & 0 & cx_2 & T_x*f \ 0 & f & cy & 0 \ 0 & 0 & 1 & 0 \end{bmatrix}P1 =⎣⎡f 0 0 0 f 0 c x 1 c y 1 0 0 0 ⎦⎤P2 =⎣⎡f 0 0 0 f 0 c x 2 c y 1 T x ∗f 0 0 ⎦⎤
其中T x T_x T x 是两个相机的水平偏移。另外,如果设置 flags=CALIB_ZERO_DISPARITY,则c x 1 = = c x 2 cx_1==cx_2 c x 1 ==c x 2 。可见P 1 P_1 P 1 ,P 2 P_2 P 2 等效于修正后的相机的参数矩阵,因此P 1 P_1 P 1 、P 2 P_2 P 2 、R 1 R_1 R 1 、R 2 R_2 R 2 可以作为 initUndistortRectifyMap函数的参数,得到左右目到修正后的图像坐标系下的映射。
4. 立体匹配与视差图
结合前述双目相机模型的介绍可知,双目深度的估计依赖于视差图的计算,为了计算视差,需要找到左右图像上相同的像素点,这正是立体匹配要做的事。
引用自https://blog.csdn.net/guyuealian/article/details/121301896#t9
大部分立体匹配算法的计算过程可以分成以下几个阶段:匹配代价计算、代价聚合、视差优化、视差细化。立体匹配是立体视觉中一个很难的部分,主要困难在于:
- 1)图像中可能存在重复纹理和弱纹理,这些区域很难匹配正确;
- 2)由于左右相机的拍摄位置不同,图像中几乎必然存在遮挡区域,在遮挡区域,左图中有一些像素点在右图中并没有对应的点,反之亦然;
- 3)左右相机所接收的光照情况不同;
- 4)过度曝光区域难以匹配;
- 5)倾斜表面、弯曲表面、非朗伯体表面;
- 6)图像噪声等。
常用的立体匹配方法基本上可以分为两类: 局部方法,例如BM、SGM、ELAS、Patch Match等, 非局部的,即全局方法,例如Dynamic Programming、Graph Cut、Belief Propagation等,局部方法计算量小,匹配质量相对较低,全局方法省略了代价聚合而采用了优化能量函数的方法,匹配质量较高,但是计算量也比较大。
目前OpenCV中已经实现的方法有BM、binaryBM、SGBM、binarySGBM、BM(cuda)、Bellief Propogation(cuda)、Constant Space Bellief Propogation(cuda)这几种方法。比较好用的是SGBM算法,
在立体匹配生成视差图之后,还可以对视差图进行滤波后处理,例如Guided Filter、Fast Global Smooth Filter(一种快速WLS滤波方法)、Bilatera Filter、TDSR、RBS等。 视差图滤波能够将稀疏视差转变为稠密视差,并在一定程度上降低视差图噪声,改善视差图的视觉效果,但是比较依赖初始视差图的质量。
以 OpenCV中实现的 StereoSGBM算法为例: <br>
cv::Ptr<cv::StereoSGBM> sgbm = cv::StereoSGBM::create(
0, 96, 9, 8*9*9, 32*9*9, 1, 63, 10, 100, 32
);
sgbm->compute(left, right, disparity)
5.深度图
5.1 基础介绍
得到视差图后,需将其转换为深度图,由中的介绍可知,深度L = f b x 1 − x 2 L=\frac{fb}{x_1-x_2}L =x 1 −x 2 f b ,其中x 1 − x 2 x_1-x_2 x 1 −x 2 表示的是点P(X,Y,Z)在左右相机中的像素点的横坐标之差,即视差。L即点P在空间中的Z轴坐标,由
[ μ v 1 ] = [ f x 0 c x 0 f y c y 0 0 1 ] [ X Z Y Z 1 ] \begin{bmatrix} \mu \ v\ 1 \end{bmatrix}=\begin{bmatrix} f_x &0 &cx \ 0 & f_y & cy\ 0 & 0 &1 \end{bmatrix}\begin{bmatrix} \frac{X}{Z}\ \frac{Y}{Z}\ 1 \end{bmatrix}⎣⎡μv 1 ⎦⎤=⎣⎡f x 0 0 0 f y 0 c x c y 1 ⎦⎤⎣⎡Z X Z Y 1 ⎦⎤可得:
{ X = Z ( μ − c x ) f x Y = Z ( μ − c y ) f y Z = L \left{\begin{matrix} X=\frac{Z(\mu-c_x) }{f_x}\ Y=\frac{Z(\mu-c_y) }{f_y}\ Z=L \end{matrix}\right.⎩⎪⎨⎪⎧X =f x Z (μ−c x )Y =f y Z (μ−c y )Z =L
代码示例:
vector<Eigen::Vector4d, Eigen::aligned_allocator<Eigen::Vector4d>> points;
for(int v=0; v<left.rows; v++)
for(int u=0; u<left.cols; u++) {
if(disparity.at<float>(v,u) 0.0 || disparity.at<float>(v,u) >= 96.0) continue;
Eigen::Vector4d point(0, 0, 0, left.at<uchar>(v,u)/255.);
double x = (u - cx) / fx;
double y = (v - cy) / fy;
double d = fx * b / (disparity.at<float>(v, u));
point[0] = x * d;
point[1] = y * d;
point[2] = d;
points.push_back(point);
}
5.2OpenCV API
视差图转深度图在 OpenCV中可用reprojectImageTo3D函数来实现
void cv::reprojectImageTo3D (
InputArray disparity,
OutputArray _3dImage,
InputArray Q,
bool handleMissingValues = false,
int ddepth = -1
)
disparity是前述立体匹配得到的视差图_3dImage函数的输出,是size同输入disparity的3通道浮点型矩阵,_3dImage[i][j]表示第i行第j列的点的空间坐标( x , y , z ) (x,y,z)(x ,y ,z ),若函数的输入Q矩阵是通过stereoRectify函数计算得来的,那么坐标( x , y , z ) (x,y,z)(x ,y ,z )是相对于第一个相机的修正坐标系的。Q是4 × 4 4\times 4 4 ×4的透视变换矩阵,可通过stereoRectify函数获得。
6.双目测距精度分析
https://blog.csdn.net/xuyuhua1985/article/details/50151269
根据深度L = f b x 1 − x 2 L=\frac{fb}{x_1-x_2}L =x 1 −x 2 f b 可以看出,某点像素的深度精度取决于该点处估计的视差d的精度。假设视差d的误差恒定,当测量距离越远,得到的深度精度则越差,因此使用双目相机不适宜测量太远的目标。
如果想要对与较远的目标能够得到较为可靠的深度,一方面需要提高相机的基线距离,但是基线距离越大,左右视图的重叠区域就会变小,内容差异变大,从而提高立体匹配的难度,另一方面可以选择更大焦距的相机,然而焦距越大,相机的视域则越小,导致离相机较近的物体的距离难以估计。
理论上,深度方向的测量误差与测量距离的平方成正比,而X/Y方向的误差与距离成正比;而距离很近时,由于存在死角,会导致难以匹配的问题;想象一下,如果你眼前放置一块物体,那你左眼只能看到物体左侧表面,右眼同理只能看到物体右侧表面,这时由于配准失败,导致视差计算失败;这个问题在基线越长,问题就越严重
7.总结

REFERENCE
1.https://blog.csdn.net/lx_ros/article/details/121000802
2.https://aijishu.com/a/1060000000139727
3.https://blog.csdn.net/qq_42722197/article/details/118663803
4.https://blog.csdn.net/guyuealian/article/details/121301896#t9
5.https://www.cnblogs.com/zyly/p/9373991.html
6.https://blog.csdn.net/Txianshengfantexi/article/details/119454616
Original: https://blog.csdn.net/lx_ros/article/details/123578462
Author: 恒友成
Title: (一) 双目立体视觉介绍
相关阅读
Title: 简洁优美的深度学习包-bert4keras
在鹅厂实习阶段,follow苏神(科学空间)的博客,启发了idea,成功改进了线上的一款模型。想法产出和实验进展很大一部分得益于苏神设计的bert4keras,清晰轻量、基于keras,可以很简洁的实现bert,同时附上了很多易读的example,对nlp新手及其友好!本文推荐几篇基于bert4keras的项目,均来自苏神,对新手入门bert比较合适~
- tokenizer:分词器,主要方法:encode,decode。
- build_transformer_model:建立bert模型,建议看源码,可以加载多种权重和模型结构(如unilm)。
import numpy as np
from bert4keras.models import build_transformer_model
from bert4keras.tokenizers import Tokenizer
from bert4keras.snippets import to_array
config_path = '/root/kg/bert/chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path = '/root/kg/bert/chinese_L-12_H-768_A-12/bert_model.ckpt'
dict_path = '/root/kg/bert/chinese_L-12_H-768_A-12/vocab.txt'
tokenizer = Tokenizer(dict_path, do_lower_case=True)
model = build_transformer_model(
config_path=config_path, checkpoint_path=checkpoint_path, with_mlm=True
)
token_ids, segment_ids = tokenizer.encode(u'科学技术是第一生产力')
token_ids[3] = token_ids[4] = tokenizer._token_mask_id
token_ids, segment_ids = to_array([token_ids], [segment_ids])
probas = model.predict([token_ids, segment_ids])[0]
print(tokenizer.decode(probas[3:5].argmax(axis=1)))
- 句子1和句子2拼接在一起输入bert。
- bert模型的pooler输出经dropout和mlp投影到2维空间,做分类问题。
- 最终整个模型是一个标准的keras model。
class data_generator(DataGenerator):
"""数据生成器
"""
def __iter__(self, random=False):
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
for is_end, (text1, text2, label) in self.sample(random):
token_ids, segment_ids = tokenizer.encode(
text1, text2, maxlen=maxlen
)
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
batch_labels.append([label])
if len(batch_token_ids) == self.batch_size or is_end:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = sequence_padding(batch_segment_ids)
batch_labels = sequence_padding(batch_labels)
yield [batch_token_ids, batch_segment_ids], batch_labels
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
bert = build_transformer_model(
config_path=config_path,
checkpoint_path=checkpoint_path,
with_pool=True,
return_keras_model=False,
)
output = Dropout(rate=0.1)(bert.model.output)
output = Dense(
units=2, activation='softmax', kernel_initializer=bert.initializer
)(output)
model = keras.models.Model(bert.model.input, output)
model = build_transformer_model(
config_path,
checkpoint_path,
application='unilm',
keep_tokens=keep_tokens,
)
NLG任务的loss是交叉熵,示例中的实现很美观:
- CrossEntropy类继承Loss类,重写compute_loss。
- 将参与计算loss的变量过一遍CrossEntropy,这个过程中loss会被计算,具体阅读Loss类源码。
- 最终整个模型是一个标准的keras model。
class CrossEntropy(Loss):
"""交叉熵作为loss,并mask掉输入部分
"""
def compute_loss(self, inputs, mask=None):
y_true, y_mask, y_pred = inputs
y_true = y_true[:, 1:]
y_mask = y_mask[:, 1:]
y_pred = y_pred[:, :-1]
loss = K.sparse_categorical_crossentropy(y_true, y_pred)
loss = K.sum(loss * y_mask) / K.sum(y_mask)
return loss
model = build_transformer_model(
config_path,
checkpoint_path,
application='unilm',
keep_tokens=keep_tokens,
)
output = CrossEntropy(2)(model.inputs + model.outputs)
model = Model(model.inputs, output)
model.compile(optimizer=Adam(1e-5))
model.summary()
预测阶段自回归解码,继承AutoRegressiveDecoder类可以很容易实现beam_search。
项目地址:SimBert
融合了unilm和对比学习,data generator和loss类的设计很巧妙,值得仔细阅读,建议看不懂的地方打开jupyter对着一行一行print来理解。
bert4keras项目的优点:
- build_transformer_model一句代码构建bert模型,一个参数即可切换为unilm结构。
- 继承Loss类,重写compute_loss方法,很容易计算loss。
- 深度基于keras,训练、保存和keras一致。
- 丰富的example!苏神的前沿算法研究也会附上bert4keras实现。
Original: https://blog.csdn.net/weixin_44597588/article/details/123910248
Author: 一只用R的浣熊
Title: 简洁优美的深度学习包-bert4keras