
图数据库是基于图论实现的一种NoSQL数据库,其数据存储结构和数据查询方式都是以图论为基础的。
图数据库擅长处理具有大量连接的数据。
neo4j由节点、属性、关系、标签、数据浏览器组成。
一个节点或关系可以包含多个标签。
CQL是一种声明性的模式匹配语言。
CREATE创建节点、关系和属性MATCH检索有关节点、关系和属性RETURN返回查询结果WHERE提供条件过滤DELETE删除节点和关系REMOVE删除节点和关系的属性ORDER BY排序检索SET添加或更新标签DISTINCT对返回结果进行去重COUNT返回个数EXISTS是否存在ALL/ANY/NONE/SINGLE检查集合元素
LOAD CSV
LOAD CSV WITH HEADERS FROM 'file:///station_name_res.csv' AS line
CREATE (:Station {name:line.name, englishname:line.english, stationid:line.id})
有了节点之后导入对应关系。
LOAD CSV WITH HEADERS FROM 'file:///route_name_res.csv' AS line
MATCH (from:Station{name:line.name1}),(to:Station{name:line.name2})
MERGE(from)-[r:NEAR{name:line.routeName,routeNumber:line.routeNumber,direction:line.direction,type:line.type}]->(to)
LOAD CSV WITH HEADERS FROM "file:///route_name_res.csv" AS line
MATCH (a:Station) where a.name=line.name1
MATCH (b:Station) where b.name=line.name2
WITH a, b, line
CALL apoc.create.relationship(a, line.routeName, {type:p.type}, b) YIELD rel
RETURN rel;
注:想要动态导入关系,除了使用AOPC插件,还可以将关系也作为一个节点集导入。
然后通过MATCH匹配创建关系如:
CREATE (:Star {name:line.name})
...
CREATE (:StarRelation {from:line.from, to:line.to, relation:line.relation})
...
MATCH (n:Star),(m:StarRelation),(s:Star) WHERE m.from=n.name AND m.to=s.name
CREATE (n)-[r:关系{relation:m.relation}]->(s)
RETURN n.name,m.relation,s.name
CREATE
创建多个标签为Person的节点,具有两个属性name、title。
CREATE (n:Person {name: 'Andy', title: 'Developer'}), (m:Person)
创建名为RELTYPE的关系且有一个name属性。
MATCH
(a:Person),
(b:Person)
WHERE a.name = 'A' AND b.name = 'B'
CREATE (a)-[r:RELTYPE {name: a.name + '' + b.name}]->(b)
RETURN type(r), r.name
创建三个节点和其之间的关系:
CREATE p = (andy {name:'Andy'})-[:WORKS_AT]->(neo)<-[:WORKS_AT]-(michael {name: 'Michael'})
RETURN p
MATCH
MATCH用来搜寻符合要求的模式,通过RETURN查看结果(有点类似SELECT)。
查找label为Movie的所有节点:
MATCH (movie:Movie)
RETURN movie.title
neo4j也支持一些比较复杂的用法:
MATCH (n:student) WHERE n.name IS NOT NULL RETURN n
MATCH (n:student) WHERE n.name IN["Mike","Jake"] RETURN n
MATCH (:Person {name: 'Oliver Stone'})--(movie:Movie)
RETURN movie.title
MATCH (:Person {name: 'Oliver Stone'})-->(movie)
RETURN movie.title
MATCH (:Person {name: 'Oliver Stone'})-[r]->(movie)
RETURN type(r)
MATCH (wallstreet:Movie {title: 'Wall Street'})<-[:ACTED_IN]-(actor)
RETURN actor.name
MATCH (wallstreet {title: 'Wall Street'})<-[:ACTED_IN|:DIRECTED]-(person)
RETURN person.name
可以通过MATCH匹配创建一些较复杂的关系:
MATCH (n:person {name:'Mike'}),(m:relationSet),(s:person)
WHERE m.from = 'Mike' AND s.name = m.to
CREATE (n)-[:iniRelation {relation:m.relation}] ->(s)
RETURN id(n), m.relation,id(s)
注意:id属性是neo4j自带的,因此通过函数 id()取而不是 n.id。
MERGE
MERGE可以看成MATCH + CREATE。如果MERGE命令找不到对应的数据则创建一个符合要求的数据。
找不到属性则创建:
MERGE (charlie {name: 'Charlie Sheen', age: 10})
RETURN charlie
可以设置时间戳标签来维护:
MERGE (n:Person { id: 'argan' })
ON CREATE SET n.created = timestamp()
ON MATCH SET n.lastAccessed = timestamp()
RETURN n.name, n.created, n.lastAccessed
MERGE很好的实现了这一功能,让原节点n += 新的数据,MERGE会自动覆盖掉被更新的数据,并保留新数据里没有但原数据里有的属性。
MERGE (n:Node {id: 'argan'})
SET n += {id: 'argan', age: 30, sex: 'male', email: 'arganzheng@gmail.com'}
RETURN n
CALL apoc.merge.node(['Label'], {id:uniqueValue}, {prop:value,...}) YIELD node;
CALL apoc.merge.relationship(startNode, 'RELTYPE', {[id:uniqueValue]}, {prop:value}, endNode) YIELD rel;
DELETE
注意:这种删除方法必须该节点不存在关系,否则删不掉。
MATCH (n:Person {name: 'UNKNOWN'})
DELETE n
如果要把这个节点的关系也删除(这只是一种方法,用下面的方法也可以):
MATCH (n {name: 'Andy'})
DETACH DELETE n
MATCH (n {name: 'Andy'})-[r:KNOWS]->()
DELETE r
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
DELETE n,r
REMOVE
与DELETE相比,REMOVE主要是删除属性和标签。
MATCH (a {name: 'Andy'})
REMOVE a.age
RETURN a.name, a.age
MATCH (n {name: 'Peter'})
REMOVE n:German
RETURN n.name, labels(n)
MATCH (n {name: 'Peter'})
REMOVE n:German:Swedish
RETURN n.name, labels(n)
SET
SET命令用于向现有节点或关系添加新属性或修改属性值。
MATCH (n {name: 'Andy'})
SET (CASE WHEN n.age = 36 THEN n END).worksIn = 'Malmo'
RETURN n.name, n.worksIn
可以将属性值设置为 null来达到remove的目的。
MATCH (n {name: 'Andy'})
SET n.age = toString(n.age)
RETURN n.name, n.age ORDER BY n.age DESC
可以同时修改多个属性:
MATCH (p {name: 'Peter'})
SET p = {name: 'Peter Smith', position: 'Entrepreneur'}
RETURN p.name, p.age, p.position
MATCH (n {name: 'Stefan'})
SET n:German
RETURN n.name, labels(n) AS labels
MATCH (n {name: 'George'})
SET n:Swedish:Bossman
RETURN n.name, labels(n) AS labels
INDEX
可以加上索引来加快查找速度。
将标签集Station中的name作为索引。
CREATE INDEX ON :Station (name)
DROP INDEX ON :Station (name)
UNIQUE
在需要限定为唯一值的地方加上约束,保证数据唯一性。
CREATE CONSTRAINT ON (n:Station) ASSERT n.name IS UNIQUE
DROP CONSTRAINT ON (n:Station) ASSERT n.name IS UNIQUE
EXISTS
如果指定的模式存在于图中,或者特定的属性存在于节点、关系或Map中,那么函数返回True。
MATCH (n)
WHERE exists(n.name)
RETURN n.name AS name, exists((n)-[:MARRIED]->()) AS is_married
ALL/ANY/NONE/SINGLE
ALL示例:
MATCH p =(a)-[*1..3]->(b)
WHERE a.name = 'Alice' AND b.name = 'Daniel' AND ALL (x IN nodes(p) WHERE x.age > 30)
RETURN p
ANY示例:
MATCH (a)
WHERE a.name = 'Eskil' AND ANY (x IN a.array WHERE x = 'one')
RETURN a.name, a.array
NONE示例:
MATCH p =(n)-[*1..3]->(b)
WHERE n.name = 'Alice' AND NONE (x IN nodes(p) WHERE x.age = 25)
RETURN p
SINGLE示例:
MATCH p =(n)-->(b)
WHERE n.name = 'Alice' AND SINGLE (var IN nodes(p) WHERE var.eyes = 'blue')
RETURN p
常用函数
neo4j的字符串下标从0开始。
UPPER转化为大写字母LOWER转化为小写字母SUBSTRING(str, begin, len)获取子字符串REPLACE替换CONTAINS是否包含STARTS WITH匹配开头ENDS WITH匹配结尾SPLIT将字符串分成List
关系函数用于了解关系的细节。
STARTNODE关系的开始节点ENDNODE关系的结束节点ID关系IDTYPE用字符串表示的一个关系的TYPE
通过 shortestpath函数来计算最短路径。
MATCH (p1:Station {name: "南府街"}), (p2:Station {name: "通顺小区"}),
path = shortestpath((p1)-[*]-(p2))
RETURN path
MATCH
(martin:Person {name: 'Martin Sheen'}),
(oliver:Person {name: 'Oliver Stone'}),
p = shortestPath((martin)-[*..15]-(oliver))
RETURN p
还可以对最短路径加一些限制:
本实例寻找'Charlie Sheen'和'Martin Sheen'之间的最短路径,且不考虑FATHER关系参与的最短路。
MATCH
(charlie:Person {name: 'Charlie Sheen'}),
(martin:Person {name: 'Martin Sheen'}),
p = shortestPath((charlie)-[*]-(martin))
WHERE none(r IN relationships(p) WHERE type(r) = 'FATHER')
RETURN p
Original: https://blog.csdn.net/DwenKing/article/details/120929936
Author: Dwenking
Title: Neo4j CQL基础
相关阅读
Title: r包安装固定版本r包 安装某个版本r包 安装特定版本的R包
r安装固定版本 安装某个版本 安装特定版本的R包
1采用大家普遍使用的指定R包版本的方法安装
require(devtools)
install_version("ggplot2", version = "3.2.1",
repos = "http://cran.us.r-project.org")
继续采用第二种指导R包版本的方法,就是在官网下载对应版本的R包原始代码文件
install.packages(("E:/ggplot2_3.2.1.tar.gz"))
3.如何查找旧版本的R包并且下载
https://blog.csdn.net/weixin_45865390/article/details/108219671
查找旧版本
网上给的都是如何下载某个旧版本的R包,在你已知版本的情况下。那我又不知道到底有什么版本。
so,先找到有什么版本的包
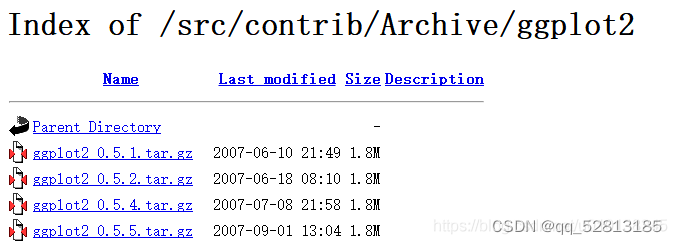
网址(https://cran.r-project.org/src/contrib/Archive/)
这个网址里面就是个各种各样的包的历史,随便打开一个看看
————————————————
这里是引用如果想特定搜索某个包(以TensorFlow为例)可以在上述第一个页面搜索,按字母顺序,也可以在网址后面直接输入这个包。例如:
我要找tensorflow的历史版本。直接输入tensorflow就可以了
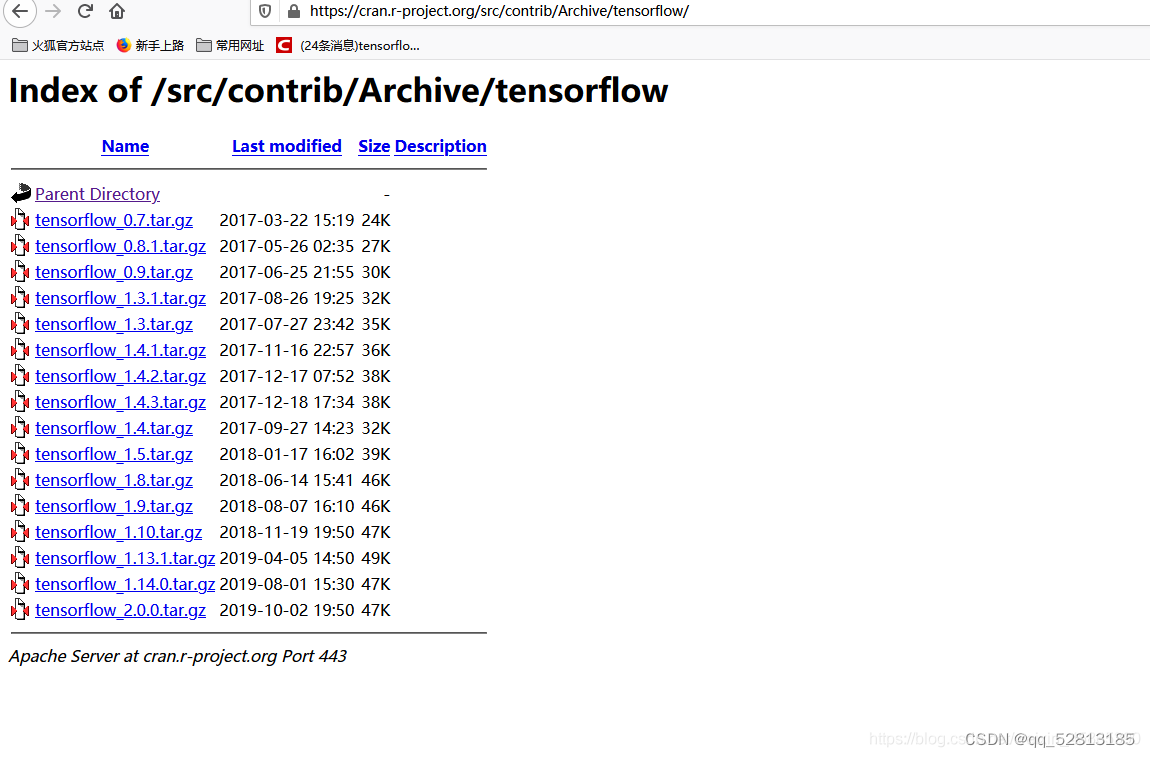
下载特定版本
packageurl "http://cran.r-project.org/src/contrib/Archive/tensorflow/tensorflow_1.14.0.tar.gz"
install.packages(packageurl, repos=NULL, type="source")
**
下载特定的r r-base版本
**
r安装固定版本r-base 安装某个版本r-base 安装特定版本的r-base
对于window系统看这个链接:
https://cran.r-project.org/bin/windows/base/old/
**
安装低版本的R语言、和自行下载安装各个版本的R语言包、以及多环境运行R
**
- 下载并安装最新的R版本软件,以国内的清华的镜像为例(国内镜像速度快)
https://mirrors.tuna.tsinghua.edu.cn/CRAN/
- 官网上如何下载老版本或低版本(旧版本)的R语言(同时下载多个版本的R,功能运行更加丰富)
https://cran.r-project.org/bin/windows/base/old/
- 官网上如何去自行下载安装各个版本的R语言包(当运行install.packages()不行时)
https://cran.r-project.org/bin/windows/contrib/
- 如何在Rstudio多个版本R语言环境进行选择(当要运行低版本R的包时)
打开RStudio —> 点击Tools —> Global Options —> General —> R version —> Change 具体如下
————————————————
版权声明:本文为CSDN博主「卧新实验室」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ChenQihome9/article/details/81949965
Original: https://blog.csdn.net/qq_52813185/article/details/124973065
Author: YoungLeeyou
Title: r包安装固定版本r包 安装某个版本r包 安装特定版本的R包