
【人工智能项目】U-Net实战ISBI细胞分割
一、 实验配置及其参数
本实验采用的软硬件实验环境如表所示:

在Ubuntu操作系统下,采用基于Tensorflow的Keras的深度学习框架,对ISBI细胞分割数据集进行训练和测试。
采用keras的深度学习框架,keras是一个专为简单的神经网络组装而设计的Python库,具有大量预先包装的网络类型,包括二维和三维风格的卷积网络、短期和长期的网络以及更广泛的一般网络。使用keras构建网络是直接的,keras在其Api设计中使用的语义是面向层次的,网络组建相对直观,所以本次选用Keras人工智能框架,其专注于用户友好,模块化和可扩展性。
; 二、 数据集
本次数据集来自ISBI挑战的数据集http://brainiac2.mit.edu/isbi_challenge/。
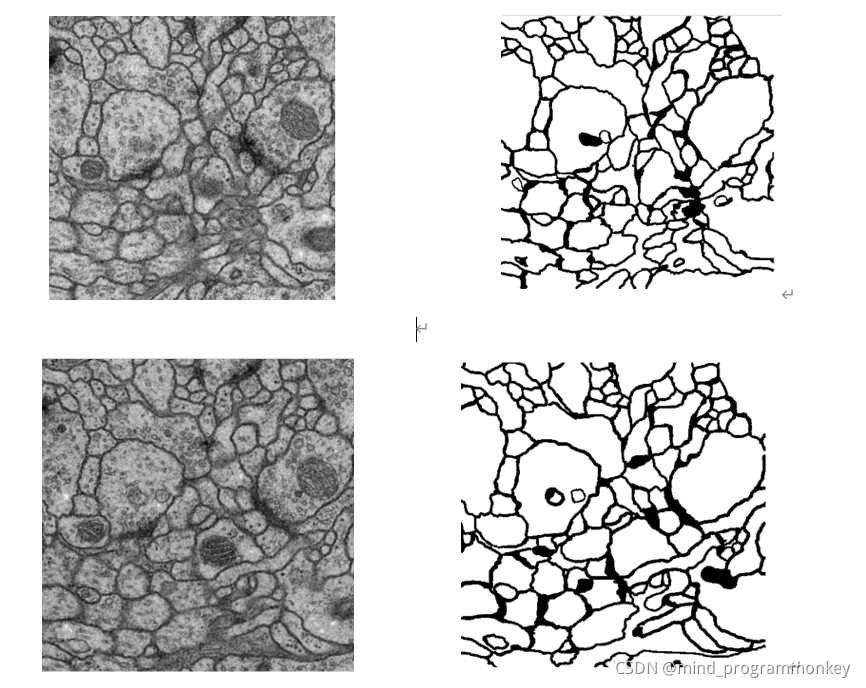
数据集为30张训练图,30张对应的标签。30张测试图片,图片均为.tif格式文件。其具体效果如下所示:
三、 源码架构
Unet
- data
- membrane
- train:包含训练集的图片以及标签
- test:包含测试集的图片以及标签
- logs:日志信息,用于tensorboard可视化展示
- trainUnet.ipynb:训练以及测试过程
- data.py:读取数据封装的函数
- model.py:unet网络函数
- unet.membrane.hdf5:训练得到的权重信息
UNet介绍
本次使用U-Net作为医疗影像分割的模型。下面主要介绍一下U-Net作为图像分割算法的优势。
U-Net架构包括一个捕获上下文信息的收缩路径和一个支持精确本地化的对称扩展路径。U-Net证明了这样一个网络使用非常小的图像可以进行端到端的训练,并在生物分割挑战赛中取得了比以前最好的方法。
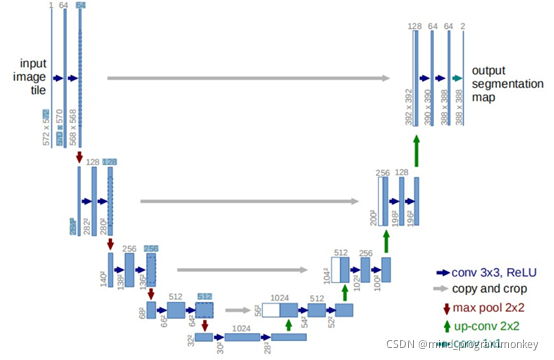
(1)收缩路径由2个3 * 3的卷积组成,每个卷积后面跟的是RELU激活函数和一个进行下采样的2 * 2较大池化运算。
(2)扩张阶段包括一个特征通道的上采样。后面跟得上是2 * 2的转置卷积,它能够将特征通道数目减半,同时加大特征图。
(3)最后一层是1 * 1卷积,用这种卷积来组成的特征向量映射到需要的类别数量上。
具体而言来讲:
- a.U-Net建立在FCN的网络架构上,作者修改并扩大了这个网络框架,使其能够使用很少的训练图像就能得到很精确的分割结果。
- b.添加上采样阶段,并且添加了很多的特征通道,允许更多的原图像纹理的信息在高分辨率的layers中进行传播
-
c.U-Net没有FC层,且全程使用valid来进行卷积,这样的话可以保证分割的结果都是基于没有缺失的上下文特征得到的,因此输入输出的图像尺寸不太一样(但在keras上代码做的都是same convolution),对于图像很大的输入,可以使用overlap-strategy来进行无缝的图像输出.
-
d.为了预测输入图像的边缘部分,通过镜像输入图像来外推丢失的上下文,实则输入大图像也是可以的,但是这个侧率基于GPU内存不够的情况下所提出的。
- e.细胞分割的另外一个难点在于将相同类别且互相接触的细胞分开,因此提出weighted loss,也就是赋予相互接触的两个细胞之间的background标签更高的权重。
其创新点总结为:
- 1.U-Net简单地将编码器的特征图拼接至每个阶段解码器对的上采样特征图,从而形成一个梯形结构。
- 2.通过跳跃拼接连接的架构,在每个阶段都允许解码器学习在编码器中丢失的相关特征。
- 3.上采样采用转置卷积
; data.py
负责读取数据
from __future__ import print_function
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
import os
import glob
import skimage.io as io
import skimage.transform as trans
Sky = [128,128,128]
Building = [128,0,0]
Pole = [192,192,128]
Road = [128,64,128]
Pavement = [60,40,222]
Tree = [128,128,0]
SignSymbol = [192,128,128]
Fence = [64,64,128]
Car = [64,0,128]
Pedestrian = [64,64,0]
Bicyclist = [0,128,192]
Unlabelled = [0,0,0]
COLOR_DICT = np.array([Sky, Building, Pole, Road, Pavement,
Tree, SignSymbol, Fence, Car, Pedestrian, Bicyclist, Unlabelled])
def adjustData(img,mask,flag_multi_class,num_class):
if(flag_multi_class):
img = img / 255
mask = mask[:,:,:,0] if(len(mask.shape) == 4) else mask[:,:,0]
new_mask = np.zeros(mask.shape + (num_class,))
for i in range(num_class):
new_mask[mask == i,i] = 1
new_mask = np.reshape(new_mask,(new_mask.shape[0],new_mask.shape[1]*new_mask.shape[2],new_mask.shape[3])) if flag_multi_class else np.reshape(new_mask,(new_mask.shape[0]*new_mask.shape[1],new_mask.shape[2]))
mask = new_mask
elif(np.max(img) > 1):
img = img / 255
mask = mask /255
mask[mask > 0.5] = 1
mask[mask 0.5] = 0
return (img,mask)
def trainGenerator(batch_size,train_path,image_folder,mask_folder,aug_dict,image_color_mode = "grayscale",
mask_color_mode = "grayscale",image_save_prefix = "image",mask_save_prefix = "mask",
flag_multi_class = False,num_class = 2,save_to_dir = None,target_size = (256,256),seed = 1):
'''
can generate image and mask at the same time
use the same seed for image_datagen and mask_datagen to ensure the transformation for image and mask is the same
if you want to visualize the results of generator, set save_to_dir = "your path"
'''
image_datagen = ImageDataGenerator(**aug_dict)
mask_datagen = ImageDataGenerator(**aug_dict)
image_generator = image_datagen.flow_from_directory(
train_path,
classes = [image_folder],
class_mode = None,
color_mode = image_color_mode,
target_size = target_size,
batch_size = batch_size,
save_to_dir = save_to_dir,
save_prefix = image_save_prefix,
seed = seed)
mask_generator = mask_datagen.flow_from_directory(
train_path,
classes = [mask_folder],
class_mode = None,
color_mode = mask_color_mode,
target_size = target_size,
batch_size = batch_size,
save_to_dir = save_to_dir,
save_prefix = mask_save_prefix,
seed = seed)
train_generator = zip(image_generator, mask_generator)
for (img,mask) in train_generator:
img,mask = adjustData(img,mask,flag_multi_class,num_class)
yield (img,mask)
def testGenerator(test_path,num_image = 30,target_size = (256,256),flag_multi_class = False,as_gray = True):
for i in range(num_image):
img = io.imread(os.path.join(test_path,"%d.png"%i),as_gray = as_gray)
img = img / 255
img = trans.resize(img,target_size)
img = np.reshape(img,img.shape+(1,)) if (not flag_multi_class) else img
img = np.reshape(img,(1,)+img.shape)
yield img
def geneTrainNpy(image_path,mask_path,flag_multi_class = False,num_class = 2,image_prefix = "image",mask_prefix = "mask",image_as_gray = True,mask_as_gray = True):
image_name_arr = glob.glob(os.path.join(image_path,"%s*.png"%image_prefix))
image_arr = []
mask_arr = []
for index,item in enumerate(image_name_arr):
img = io.imread(item,as_gray = image_as_gray)
img = np.reshape(img,img.shape + (1,)) if image_as_gray else img
mask = io.imread(item.replace(image_path,mask_path).replace(image_prefix,mask_prefix),as_gray = mask_as_gray)
mask = np.reshape(mask,mask.shape + (1,)) if mask_as_gray else mask
img,mask = adjustData(img,mask,flag_multi_class,num_class)
image_arr.append(img)
mask_arr.append(mask)
image_arr = np.array(image_arr)
mask_arr = np.array(mask_arr)
return image_arr,mask_arr
def labelVisualize(num_class,color_dict,img):
img = img[:,:,0] if len(img.shape) == 3 else img
img_out = np.zeros(img.shape + (3,))
for i in range(num_class):
img_out = color_dict[i]
return img_out / 255
def saveResult(save_path,npyfile,flag_multi_class = False,num_class = 2):
for i,item in enumerate(npyfile):
img = labelVisualize(num_class,COLOR_DICT,item) if flag_multi_class else item[:,:,0]
io.imsave(os.path.join(save_path,"%d_predict.png"%i),img)
model.py
定义模型架构
import numpy as np
import os
import skimage.io as io
import skimage.transform as trans
import numpy as np
from keras.models import *
from keras.layers import *
from keras.optimizers import *
from keras.callbacks import ModelCheckpoint, LearningRateScheduler
from keras import backend as keras
def unet(pretrained_weights = None,input_size = (256,256,1)):
inputs = Input(input_size)
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(inputs)
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv1)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool1)
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv2)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool2)
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv3)
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv4)
drop4 = Dropout(0.5)(conv4)
pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv5)
drop5 = Dropout(0.5)(conv5)
up6 = Conv2D(512, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(drop5))
merge6 = concatenate([drop4,up6], axis = 3)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge6)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv6)
up7 = Conv2D(256, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv6))
merge7 = concatenate([conv3,up7], axis = 3)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge7)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv7)
up8 = Conv2D(128, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv7))
merge8 = concatenate([conv2,up8], axis = 3)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge8)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv8)
up9 = Conv2D(64, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv8))
merge9 = concatenate([conv1,up9], axis = 3)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge9)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)
conv9 = Conv2D(2, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)
conv10 = Conv2D(1, 1, activation = 'sigmoid')(conv9)
model = Model(input = inputs, output = conv10)
model.compile(optimizer = Adam(lr = 1e-4), loss = 'binary_crossentropy', metrics = ['accuracy'])
if(pretrained_weights):
model.load_weights(pretrained_weights)
return model
trainUNet
from keras.callbacks import EarlyStopping
from keras.callbacks import ModelCheckpoint
from keras.callbacks import ReduceLROnPlateau
from keras.callbacks import TensorBoard
data_gen_args = dict(rotation_range=0.2,
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=0.05,
zoom_range=0.05,
horizontal_flip=True,
fill_mode='nearest')
myGene = trainGenerator(2,'data/membrane/train','image','label',data_gen_args,save_to_dir = None)
model = unet()
model_checkpoint = ModelCheckpoint('unet_membrane.hdf5', monitor='loss',verbose=1, save_best_only=True)
early_stopping = EarlyStopping(monitor="val_loss",
patience=5,
verbose=1,
mode="min")
reduce_lr = ReduceLROnPlateau(monitor="val_loss",
factor=0.5,
patience=2,
verbose=1,
mode="min")
tbCallBack = TensorBoard(log_dir="./logs")
history = model.fit_generator(myGene,steps_per_epoch=2000,epochs=20,callbacks=[model_checkpoint,early_stopping,reduce_lr,tbCallBack])
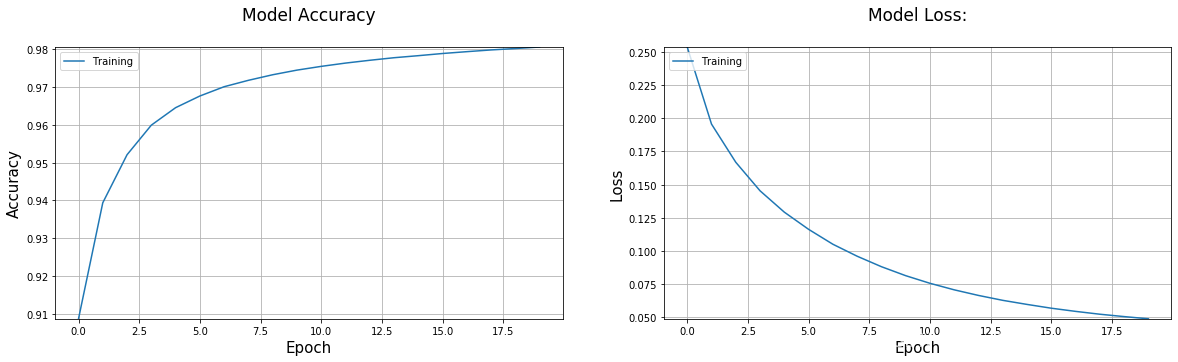
训练过程的曲线图
import matplotlib.pyplot as plt
%matplotlib inline
def plot_performance(history=None,figure_directory=None,ylim_pad=[0,0]):
xlabel="Epoch"
legends=["Training"]
plt.figure(figsize=(20,5))
y1=history.history["acc"]
min_y=min(min(y1),min(y1))-ylim_pad[0]
max_y=max(max(y1),max(y1))+ylim_pad[0]
plt.subplot(121)
plt.plot(y1)
plt.title("Model Accuracy\n",fontsize=17)
plt.xlabel(xlabel,fontsize=15)
plt.ylabel("Accuracy",fontsize=15)
plt.ylim(min_y,max_y)
plt.legend(legends,loc="upper left")
plt.grid()
y1=history.history["loss"]
min_y=min(min(y1),min(y1))-ylim_pad[1]
max_y=max(max(y1),max(y1))+ylim_pad[1]
plt.subplot(122)
plt.plot(y1)
plt.title("Model Loss:\n",fontsize=17)
plt.xlabel(xlabel,fontsize=15)
plt.ylabel("Loss",fontsize=15)
plt.ylim(min_y,max_y)
plt.legend(legends,loc="upper left")
plt.grid()
plt.show()
plot_performance(history)
Tensorbaord可视化模型
四、测试过程
testGene = testGenerator("data/membrane/test")
model = unet()
model.load_weights("unet_membrane.hdf5")
results = model.predict_generator(testGene,30,verbose=1)
saveResult("data/membrane/test",results)
测试结果展示

小结
本次在Ubuntu操作系统下,采用基于Tensorflow的Keras的深度学习框架,对ISBI细胞分割数据集进行训练和测试。
在模型训练过程中,用到U-Net的深度卷积神经网络结构,设定好模型的参数,进行20轮的训练,并用到了keras框架中的一些trick,如modelcheckpoint,early_stropping,reduce_lr,tensorboard_callback等。这些tricks使得模型更易于收敛,且将最好的权重信息保存了出来。
为了验证U-NET模型的鲁棒性,并在测试集上进行了测试,生成了预测的标签图片。
总之,本次通过对u-net医学图像分割的研究流程分析,提出了一套完整的
卷积神经网络医学图像分割流程。其次,本文构建的模型具有普适性,可以稍加改进应用于不同的数据集。此外,本次构建模型考虑了计算资源和时间成本,所以选择了U-Net这个模型。综合以上几点,本次实验使我对医学图像分割有了一定程度的了解。
最后,大家点赞收藏评论走起来呀!!!
Original: https://blog.csdn.net/Mind_programmonkey/article/details/121120025
Author: mind_programmonkey
Title: 【人工智能项目】U-Net实战ISBI细胞分割
相关阅读
Title: Tensorflow声纹识别说话人识别
前言
本章介绍如何使用Tensorflow实现简单的声纹识别模型,首先你需要熟悉音频分类,我们训练一个声纹识别模型,通过这个模型我们可以识别说话的人是谁,可以应用在一些需要音频验证的项目。不同的是本项目使用了ArcFace Loss,ArcFace loss:Additive Angular Margin Loss(加性角度间隔损失函数),对特征向量和权重归一化,对θ加上角度间隔m,角度间隔比余弦间隔在对角度的影响更加直接。
使用环境:
- Python 3.7
- Tensorflow 2.3.0
import json
import os
from pydub import AudioSegment
from tqdm import tqdm
from utils.reader import load_audio
# 生成数据列表
def get_data_list(infodata_path, list_path, zhvoice_path):
with open(infodata_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
f_train = open(os.path.join(list_path, 'train_list.txt'), 'w')
f_test = open(os.path.join(list_path, 'test_list.txt'), 'w')
sound_sum = 0
speakers = []
speakers_dict = {}
for line in tqdm(lines):
line = json.loads(line.replace('\n', ''))
duration_ms = line['duration_ms']
if duration_ms < 1300:
continue
speaker = line['speaker']
if speaker not in speakers:
speakers_dict[speaker] = len(speakers)
speakers.append(speaker)
label = speakers_dict[speaker]
sound_path = os.path.join(zhvoice_path, line['index'])
save_path = "%s.wav" % sound_path[:-4]
if not os.path.exists(save_path):
try:
wav = AudioSegment.from_mp3(sound_path)
wav.export(save_path, format="wav")
os.remove(sound_path)
except Exception as e:
print('数据出错:%s, 信息:%s' % (sound_path, e))
continue
if sound_sum % 200 == 0:
f_test.write('%s\t%d\n' % (save_path.replace('\\', '/'), label))
else:
f_train.write('%s\t%d\n' % (save_path.replace('\\', '/'), label))
sound_sum += 1
f_test.close()
f_train.close()
# 删除错误音频
def remove_error_audio(data_list_path):
with open(data_list_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
lines1 = []
for line in tqdm(lines):
audio_path, _ = line.split('\t')
try:
spec_mag = load_audio(audio_path)
lines1.append(line)
except Exception as e:
print(audio_path)
print(e)
with open(data_list_path, 'w', encoding='utf-8') as f:
for line in lines1:
f.write(line)
if __name__ == '__main__':
get_data_list('dataset/zhvoice/text/infodata.json', 'dataset', 'dataset/zhvoice')
remove_error_audio('dataset/train_list.txt')
remove_error_audio('dataset/test_list.txt')
输出类似如下:
Model: "functional_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resnet50v2_input (InputLayer [(None, 257, 257, 1)] 0
_________________________________________________________________
resnet50v2 (Functional) (None, 2048) 23558528
_________________________________________________________________
batch_normalization (BatchNo (None, 2048) 8192
=================================================================
Total params: 23,566,720
Trainable params: 23,517,184
Non-trainable params: 49,536
_________________________________________________________________
Loaded 李达康 audio.
Loaded 沙瑞金 audio.
请选择功能,0为注册音频到声纹库,1为执行声纹识别:0
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
请输入该音频用户的名称:夜雨飘零
请选择功能,0为注册音频到声纹库,1为执行声纹识别:1
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
识别说话的为:夜雨飘零,相似度为:0.920434

下载链接:
https://download.csdn.net/download/babyai996/85090063
Original: https://blog.csdn.net/babyai996/article/details/124022410
Author: babyai996
Title: Tensorflow声纹识别说话人识别