
目录
0 引言
前段时间,朋友让我帮忙剪十段音频,每段音频为约十分钟的包含男女生对话的录音,要求从中分离出男声的语音,男女声声音重叠部分可丢弃,刚开始本以为工作量没多大,遂打开了音频剪辑软件,剪了一段后发现这个事情还是挺麻烦的,于是决定写个matlab程序来自动分离,然后伴以一定的人工校正,从而大大提高剪辑效率。
1 思路
预处理:将原始音频分割成2s一段的音频文件(时间间隔可调);
正式处理:
依次读取已分割为2s一段的音频文件,并从以下两个方面考虑:
(1)男女生基音频率的差异,计算该段语音中基音频率;
(2)声音幅值的差异(录音时男生离录音笔更近),计算语音幅值;
从上述两个方面对该音频文件进行识别分类,考虑到会存在一定的误判,故将识别类别设定为三类:男声、女声、需人工识别,并将判定后的语音存入对应类别的文件中,以便后期人工校正。
2 代码
(1)主函数
%================================================
%作者:Uestc-Sl
%创建日期:2021.04.19
%维护日期:2021.04.19
%功能描述:将剪切声音与判断男女声功能相结合,实现剪切、识别、分类存储一系列功能
%调用函数:judge.m
%使用流程:点击运行--->选择原始音频文件--->选择剪切及识别分类后的文件输出目录---->剪切音频
% ----->读取剪辑的音频并识别---->根据识别结果将该语音存入对应分类文件,以便人工校对---->结束
%输出结果文件夹及目录结构 指定路径----> interval_2_0?-1 ---> 剪切好的音频
% --->男声
% --->女声
% --->需人工识别
%备注:
%其他:可考虑引入神经网络,构建更高维度的向量,提高基于判断幅值和基音频率判断的准确性
%================================================
clear;
clc;
[file1,PathName,FilterIndex] = uigetfile('.wav','Select the M-file');
file=strcat(PathName,file1);
outfilePath=uigetdir;
%======================创建输出结果文件=========================
new_folder0 = strcat(outfilePath,'\','interval_2_',file1(1:4)); % 创建一个加前缀的同名文件夹,保存处理后的数据
mkdir(new_folder0);
new_folder1 = strcat(new_folder0,'\','剪切好的音频');
mkdir(new_folder1);
new_folder2 = strcat(new_folder0,'\','男声');
mkdir(new_folder2);
new_folder3 = strcat(new_folder0,'\','女声');
mkdir(new_folder3);
new_folder4 = strcat(new_folder0,'\','需人工识别');
mkdir(new_folder4);
%=============================================================
[x,fs]=audioread(file); % 读入声音文件
data=x(:,1); % 取单声道
len=length(data); % 获取序列长度和深度
timeInterval=2; % 提取的时间间隔(s)
for i=1:ceil(len/fs)
start_time = timeInterval*(i-1);
end_time =timeInterval*i;
if end_time*fs <=len y_new="x((fs*start_time+1):fs*end_time,1);" outfilename="strcat(new_folder1,'\',num2str(i),'.wav')" audiowrite(outfilename,y_new,fs); %将分割好的音频存入指定文件 [ansnum]="judge(OutFileName);" if ansnum="=0" %男声 outfilename2="strcat(new_folder2,'\',num2str(i),'.wav');" audiowrite(outfilename2,y_new,fs); end %女声 outfilename3="strcat(new_folder3,'\',num2str(i),'.wav');" audiowrite(outfilename3,y_new,fs); %需人工识别 outfilename4="strcat(new_folder4,'\',num2str(i),'.wav');" audiowrite(outfilename4,y_new,fs); < code></=len>
(2)子函数judge.m
%返回值 0 男声
% 1 女声
% 2 需人工识别
function [ansnum]=judge(filename)
[x1,fs1]=audioread(filename); % 读入声音文件
data1=x1(:,1); %取单声道
%======基音频率提取======
N=length(data1);
[~,index]=max(data1); % 返回最大值 最大值索引
timewin=floor(0.015*fs1);
%避免溢出
[a,ind] = sort(data1);
count=1;
while index+timewin>N
a(end)=[];
count=count+1;
[~,index]=max(a);
end
temp=index-timewin;
if temp<0 temp="1;" end xwin="data1(temp:index+timewin);" [y,~]="xcov(xwin);" ylen="length(y);" halflen="(ylen+1)/2" +30; yy="y(halflen:" ylen); [~,maxindex]="max(yy);" fmax="fs1/(maxindex+30);" disp([filename,'基音频率为 ', num2str(fmax), ' hz']) %="===============考虑幅值信息======" mean="0;" for i="1:N" if data1(i)>0
mean=mean+data1(i);%只计算正值范围内的平均幅值
end
end
mean=mean/N
%======通过基音频率、幅值大小判断男女声======
if mean>=0.001 && fmax<160 disp([filename,' 是男声文件']); ansnum="0;" else if fmax<160 && fmax>100 ;
disp([filename,' 需人工识别']);
ansnum=2;
else
disp([filename,' 是女声文件']);
ansnum=1;
end;
end;
</160></0>
3 代码运行结果
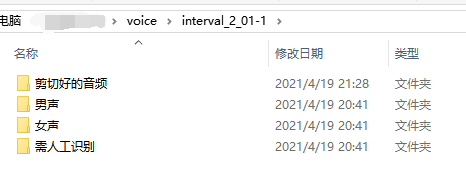
图3.1 输出结果文件夹

图3.2 判定为"男声"音频文件夹

图3.3 判定为"女声"音频文件夹
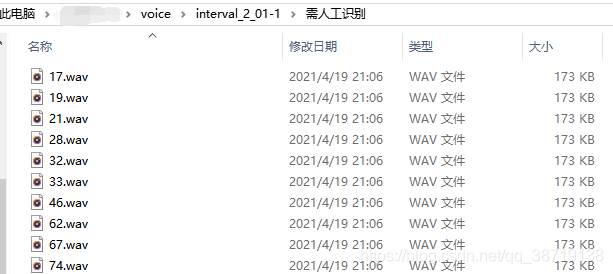
图3.4 判定为"需人工识别"音频文件夹
每次处理输入的语音时,首先会创建一个文件夹用于存处理完成后的数据,文件夹命名为"interval_2_"+输入文件名的前四个字符,并在该文件夹下创建四个文件夹:剪切好的音频、男声、女声、需人工识别。随后会自动分割录音音频为2s一段的音频,并存入"剪切好的音频"文件夹,然后对剪切好的语音进行识别并存入对应文件夹。
4 结论
根据本人人工校对后发现,"男声"的查准率近乎100%,查全率约80%(正常情况下),达到了预期的效果。在这些已分类后的语音基础上再进行人工进行校对分类,大大提高了音频剪切效率,故分享给大家,希望能给用得上的朋友带来帮助。
5 参考资料
【1】http://www.voidcn.com/article/p-hsevylyj-nx.html
【3】https://blog.csdn.net/weixin_29813667/article/details/113902853
【4】https://ww2.mathworks.cn/help/matlab/ref/mkdir.html
Original: https://blog.csdn.net/qq_38719138/article/details/116207726
Author: automan2019
Title: 语音识别之男女声分类(从一段对话中分离男声)