
背景
6月1日至6月3日,由北京智源人工智能研究院主办的2021北京智源大会在北京中关村国家自主创新示范区会议中心成功召开,来自近80个国家数万名人工智能领域专业人士参会。

本次大会共持续三天,设置了13场主旨报告/重磅对话,29场由各领域领军学者主导的专题论坛,4场讲习班。 2018年图灵奖得主Yoshua Bengio,2017年图灵奖得主David Patterson,马克斯·普朗克生物控制论研究所所长Peter Dayan等业内权威人士作为大会嘉宾发表演讲,与大家共同探索人工智能的创新应用。

大会期间,火山翻译推出的产品 「火山同传」 为会议现场和线上直播提供 「低延时、高质量」 的同传字幕,助力大会顺利召开。要想实现高质量同传, 精准快速的语音识别能力和准确流畅的翻译能力是关键因素——听对听懂,是成功还原原文的基础;学得更多反应更快,才能给观众带来更优的翻译体验。这种「所听即所得」的美妙体验是如何在技术上实现的呢?字节跳动的工程师们为我们揭开了同传技术的神秘面纱。

字节跳动自研端到端语音识别系统
打造优质的同传效果,需要精准的语音识别结果作为基础。传统的语音识别系统将语音识别分解成多个子模块分别建模(包括发音字典,声学模型和语言模型等),各模块的构建需要较强的语音、语言学知识作为指导;而端到端的语音识别系统将上述各子模块融为一体,直接根据训练数据来学习语音到文字的映射关系, 整个建模过程不需要语音、语言学知识的介入,在大数据上表现出了显著的性能提升。
Recurrent Neural Network Transducer (RNN-T) 模型是目前在语音识别领域应用最广泛的端到端模型之一。我们可以将该模型看作是Connectionist Temperal Classification (CTC)模型的一个拓展。由于它去除了CTC每帧语音概率条件独立性的假设,通过引入额外的自回归网络,将每帧语音的概率和之前的输入输出关联起来,因此对数据建模能力更强。 字节跳动AI-LAB智能语音团队对RNN-T模型做了较多尝试和探索,通过数据的不断积累、算法的持续优化,基于RNN-T模型的自研端到端语音识别系统获得了显著优于CTC模型的性能,被应用到了会议转录、同传等多个业务中,都取得了较好的反馈。团队针对具体业务场景和需求对模型进行多项改进和优化,使得模型具有很强的泛化能力。
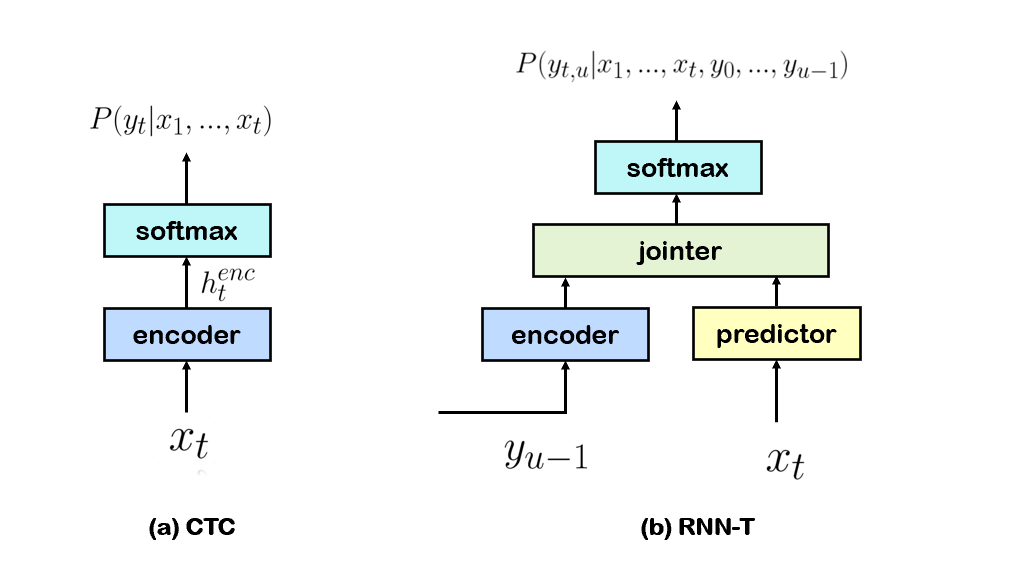
图1 CTC和RNN-T的对比
模型鲁棒性
RNN-T模型对口音和复杂场景具有很强的鲁棒性。一场会议的参会人员通常都来自全国各地,口音多种多样,大家使用的麦克风设备、所处的环境也各不相同。在这种复杂场景中要准确识别出每个人的语音极具挑战性。团队在模型训练中,采集了数十万小时数据,涵盖不同地域、不同年龄的说话人,包含远场、噪声、口音等丰富场景。在此基础上,团队结合了数据仿真算法,来进一步提升数据的多样性,如加混响,加噪等方法,在梅尔谱特征上采用了SpecAug的数据增强方法;团队针对RNN-T模型特点设计了多级训练流程,从而更高效地挖掘和吸收数据中的知识以加强模型泛化能力。最终模型在各种场景下都取得了优异的识别效果。
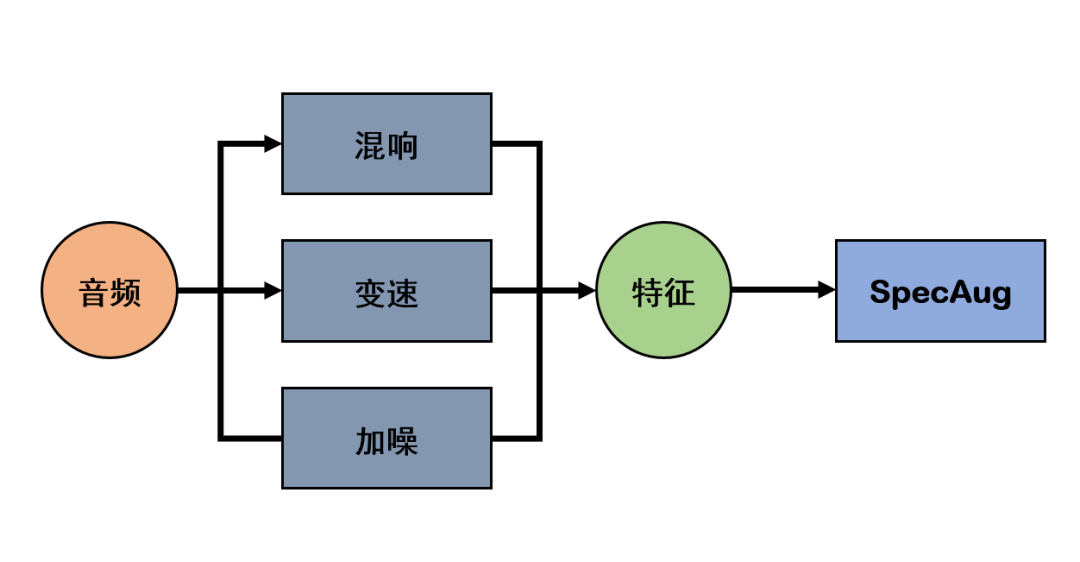
图2 多种数据增强方法
中英文混合说
RNN-T模型支持中英混合说,即单个语音识别模型可以判断出用户使用的语言类别并识别出对应内容。如今,作为大多数国人的第一外语,英语很自然地被穿插在日常的交流和对话当中。理解这种混合语言的表达对于人类来说相对容易,但对机器来说却不简单。要想准确地识别中英混场景,模型需同时具有语种识别和语音识别的能力。因此,针对该场景团队做了特定的数据筛选,并通过语音合成的方式来扩充中英混合训练数据;此外,在模型层面团队对两种语言构建了不同的建模单元,使得一个模型同时具备中英语种分类和语音识别的能力。最终仅使用一个模型便能够支持中英混合说的场景,该模型在中/英单语言场景下和单语言语音识别系统效果相当。
热词增强
RNN-T模型对特定词语(热词)识别加强。一个通用的语音识别系统难免会存在badcase,即对某些特定词汇容易识别出错。比如参与会议的人名、公司名、产品名等等。这些词语的识别错误不仅影响用户阅读体验,且会影响到后续机器翻译等下游任务效果。针对该场景,团队研发了一套高效的热词解决方案,该方案仅基于热词文本数据,通过在解码过程中对热词相关建模单元概率做干预,使得系统可以准确识别出参会人名、公司名、产品名等等。此外,该方案的效率很高,在毫秒级即可生效,对用户使用不会产生任何影响。
推理加速
RNN-T系统提供了更低的时延与更高的吞吐。相较于传统CTC模型,RNN-T模型巧妙的将语言模型与声学模型整合在一起,同时进行联合优化,是一种理论上更加完美的模型结构。但是由于网络参数量的暴增与更复杂的解码策略,给RNN-T模型带来了比CTC更大的延迟与更小的吞吐。针对RNN-T的这些特点,团队使用了自研的高性能推理框架Panther,通过极致优化且定制化的算子实现,使得网络推理速度获得了2~3倍的提升;同时,团队研发了一套高效的RNN-T解码方案,通过减少时间复杂度和增大并行度的方法让解码速度获得了数十倍的提升且效果基本相当。
基于Transformer的神经网络机器翻译技术
准确流畅的翻译是实现高质量同传的另一个关键因素。如今,基于Transformer的神经网络机器翻译技术已广泛应用于各大商业机器翻译系统当中,它不同于传统的统计机器翻译模型需要很多子模块来构建不同特征进行翻译(如调序模型、语言模型等),而是一个统一的端到端模型,接收源语言文本的输入,直接翻译输出译文。 火山翻译团队自研了一套神经机器翻译框架,并对机器翻译技术进行了大量探索和改进。
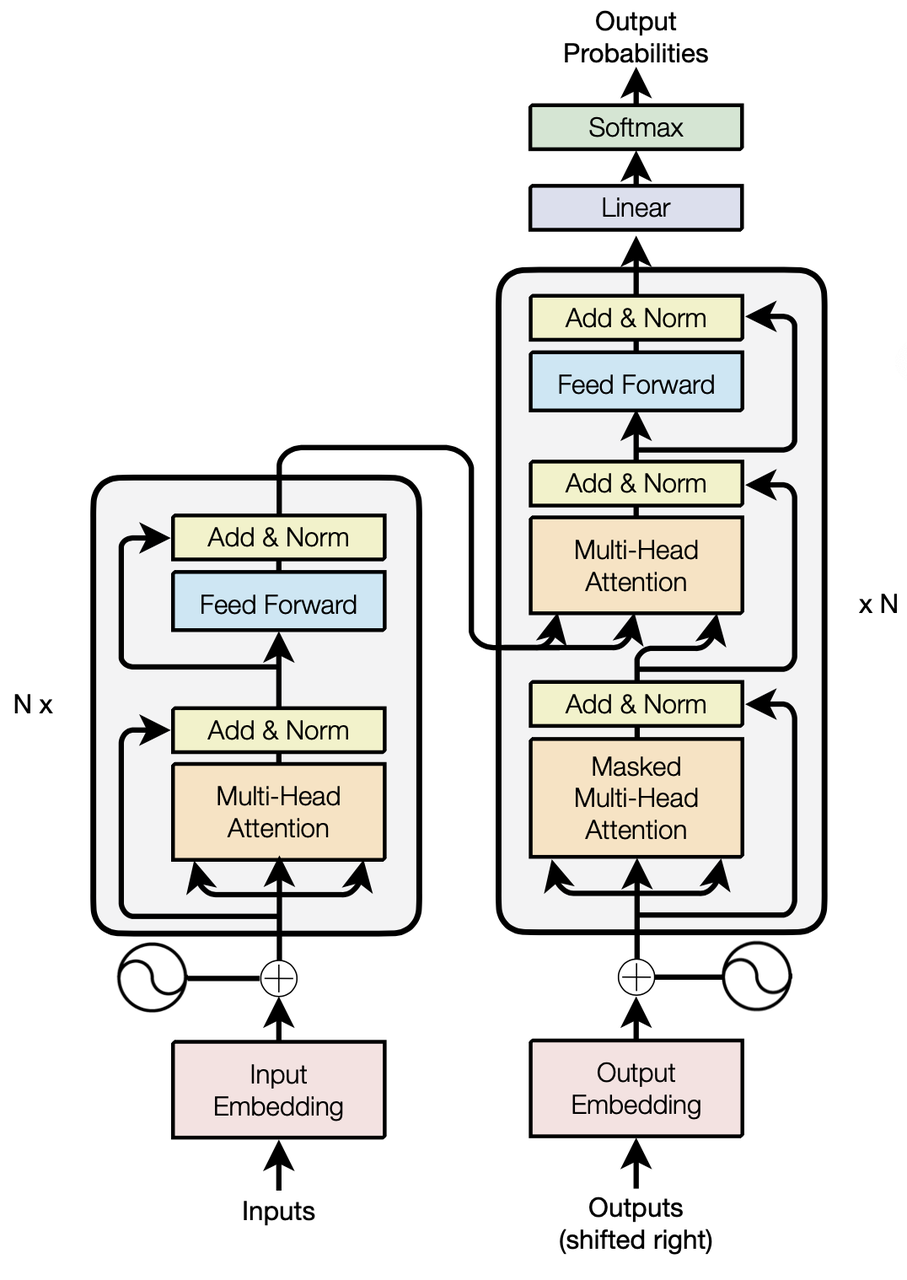
图3 Transformer模型
海量数据挖掘和领域适应
神经网络模型的训练依赖极大规模的双语语料。为了提升学习效率,火山翻译实现了一套语料清洗和挖掘系统,集成语言识别、词语对齐、跨语言预训练的语义匹配度模型等,可以从海量的互联网数据中筛选出数亿高质量的双语语料,最终训练得到的模型在日常聊天、新闻时政、财经、体育等领域均取得了业内领先的水平。 同时,在2020年国际机器翻译大赛(WMT2020)的语料清洗和翻译评测任务中,火山翻译团队研发的系统也取得了七项第一的成绩。
此外,本次智源大会涉及领域广泛、用语要求精准、参会人员语言各异,这些都加大了机器翻译的难度。为了在本次智源大会AI方向的主题上获得更好的同传翻译效果,火山翻译团队利用跨语言文本检索技术,更加精细化地从语料库中筛选出与本次大会主题最为接近的句对,进而对模型进行领域适应优化。除了行业通用的领域模型微调方法之外,火山翻译 首次在线上系统中使用了翻译记忆模块:机器翻译模型在翻译的过程中,会实时、动态决定是否参考翻译记忆库中相似的句子、词组,最终通过融合得到更为准确的译文。如此一来,我们可以不用频繁地更新模型,而是通过更新翻译记忆从而实现更高效、便捷的领域定制。
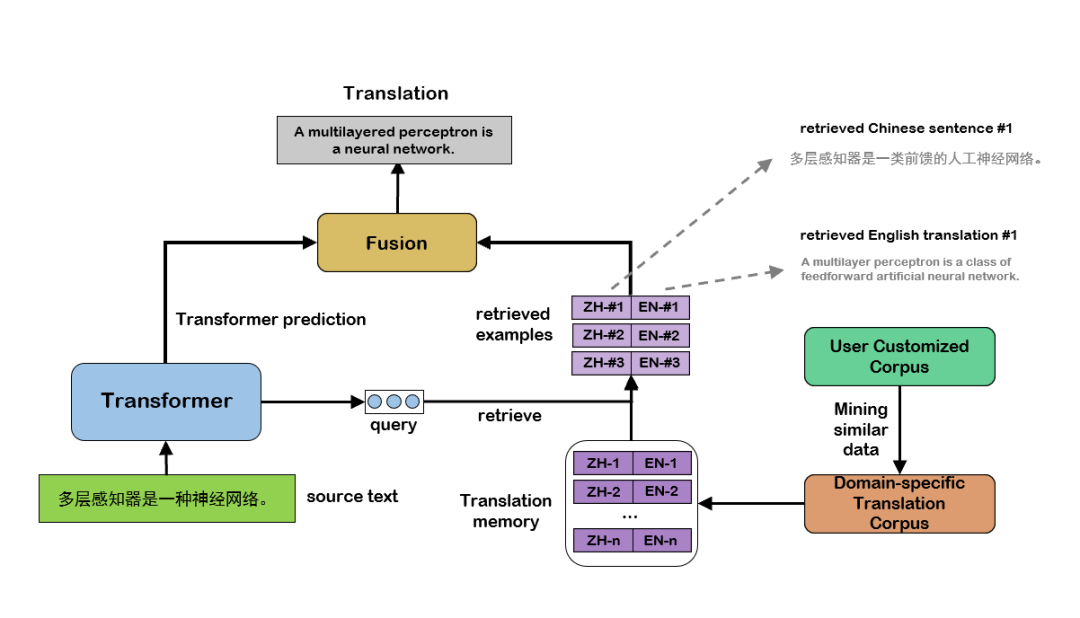
图4 融合翻译记忆模块的神经机器翻译系统示意图
深层模型和预训练
深层神经网络模型可以学习到更好的模型表达能力,目前标准的Transformer模型仅有6层。对此,火山翻译团队加深加宽了Transformer模型,用以从大规模语料库中学习更好的翻译能力。同时,团队引入了 BERT和GPT等基于更大规模单语语料库预训练的模型用以初始化,如此一来,既缓解了深层大模型的训练压力,加速收敛,又能将单语数据中学到的理解能力和生成能力输送给翻译模型,进而提升翻译质量。
Lightseq推理加速
深层模型带来了更好的表达能力,但会大大增加翻译的延迟;不仅如此,火山翻译还需要支持字节跳动众多产品和业务,这就要求了团队线上推理引擎能够快速响应并且支持高并发。为了满足需求, 火山翻译推出自研的高性能序列推理引擎LightSeq,通过极致优化的CUDA算子融合和层级式解码,让推理速度达到行业领先水平,相比同类竞品提速1.4倍左右,相比基于TensorFlow serving的方式更是提速10倍以上。此外,通过动态显存复用技术, LightSeq可以在一张T4显卡上同时部署最多8个推理模型,大大提升了低频或错峰业务场景下显卡的利用率。
总结
火山翻译旗下的智能同传产品 「火山同传」 的不俗表现,离不开强大的自研端到端语音识别系统和业界领先的神经网络机器翻译技术。此外,各种研发成果,如高性能序列推理引擎LightSeq等技术的加成也让火山同传能够更好地为不同领域和级别的活动服务。
目前,火山同传已经赋能过多场线上线下的大型活动,如:村上隆首场中国直播、CTDC第四届首席技术官领袖峰会暨年度技术颁奖盛典、第四届MTPE大赛开幕式等,为观众带来优质的翻译体验。其背后的团队火山翻译拥有包括 火山同传、火山翻译API、火山翻译Studio、VolctransGlass AR智能翻译眼镜、浏览器翻译助手等在内的一系列矩阵产品,应用于办公、娱乐、新闻等各类场景中,每天为来自全球的过亿用户提供优质的翻译服务。
随着越来越多自研产品的诞生与投用,火山翻译将会在更多领域进行技术深耕,希望能帮助更多用户进行跨语言交流,继续为行业乃至整个社会发展贡献一份力量。
Original: https://blog.csdn.net/ByteDanceTech/article/details/117575854
Author: 字节跳动技术团队
Title: 亮相智源大会,字节跳动自研同传系统的技术实现