
一、背景介绍:
自2017年Google提出的Transformer结构以来,迅速引发一波热潮,最初《Attention is all you need》这篇论文的提出是针对于NLP领域的,通过自注意力机制代替传统处理序列数据时采用的循环神经网络结构,不仅实现了并行训练,提升了训练的效率,同时也在应用中取得很好的结果。之后的一段时间中,各种基于Transformer改进的网络结构涌现出来,在不同领域中都达到SOTA的效果。
2020年Google又提出了《AN IMAGE IS WORTH 16X16 WORDS : TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》这篇论文,该文章已经被收录于ICLR 2021。首次提出Vision Transformer(ViT)将Transformer结构应用在了CV领域图像分类中,论文中表明,与当前效果最好的卷积神经网络结构相比,ViT仍然取得很好的成绩,同时需要更少的计算资源。
本次实验内容是复现ViT模型,并将该模型应用在CIFAR10数据集上进行实验,与原论文中的实验结果做比较和分析。
二、基本思想:
2.1 整体结构:
借鉴于2017年Google提出Transformer的思想,ViT的作者希望能够把最纯净的Transformer结构应用在图像分类中,但是Transformer最初提出是针对NLP领域中的机器翻译任务,所以作者对Transformer结构做了一些细小的改动,让它完成图像分类任务。
改动的地方有:
(1)传统Transformer结构是由Encoder-Decoder框架组成,而对于ViT来说,只使用了Encoder部分。
(2)标准Transformer的输入是一维序列数据,所以需要将图像转换为序列数据,论文作者提出的思路就是将一张图片无重叠切分成固定大小的patches,然后将每一个patch通过拉伸操作转换为一维向量,最后通过一个线性变换层将输入的patches转换为一个固定长度的向量,称为patch_embedding。
(3)因为对于分类任务,最后的输出应该是一个标签,所以作者对Transformer Encoder的输入做了调整, 在输入序列的最开始位置添加了一个CLS Token。
整体网络结构如下图所示:
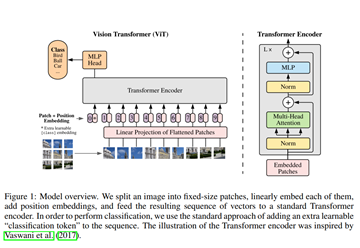
; 2.2 模块分析:

2.2.1 Patch Embedding:
Transformer在NLP领域应用时,处理的都是词向量序列,所以在处理二维图像时,我们需要对图像做一些特殊处理,在原论文中,作者提出的方式是将一张图片切分成大小相同的图像块,比如1616,并将每一个patch映射到固定维度的向量embed_dim=768,该向量的维度在整个计算过程中保持不变。这一块的操作是通过一个二维的卷积来完成的,卷积核大小设置为1616 ,步长为16。
将图片进行切分之后,我们还需要对每个patches添加不同的位置信息Pos Embedding,这里的位置信息如何获得,在《Attention is all you need》这篇论文中,作者采用sin cos的方式计算得来。
将Patch Embedding和Pos Embedding进行相加就可以得到了最终可以送入Transformer结构的输入信息,也就是把数据传给了多头自注意力层。
通过jupyter notebook对patch Embedding的操作进行模拟,查看张量在处理过程中的维度变化:
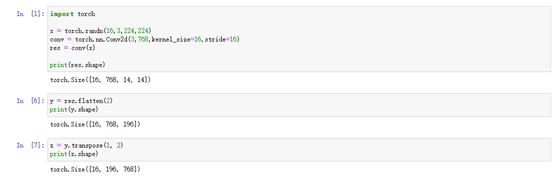
; 2.2.2 Multi-Head Attention:
关于注意力机制这一模块,论文中采用与《Attention is all you need》中完全一样的结构。需要注意的是,在ViT中不同规模的模型,它们在网络结构设计上存在着一些微小的差别,比如对于本次实验采用的vit_base_patch16_224预训练模型来说,它的整个网络结构堆叠了12层,并且多头注意力的head数设置为12。其他模型如下图所示:
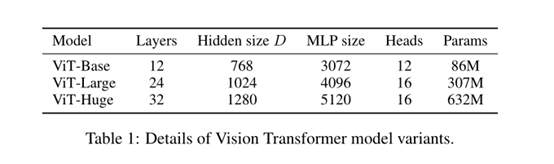
在这一个模块中,计算过程与Self-Attention中的计算过程一样,对于输入的数据,我们得到QKV三个矩阵,然后通过scaled Dot-Product和softmax计算出不同序列(这里也就是不同patch)之间的相关性得分,最后得到输出序列,输出序列与输入保持同一个维度,由于这里的layers设置为12,所以 输入序列数据需要经过12个Attention之后才会得到输出结果。
2.2.3: MLP:
在Transformer Encoder层中,MLP是包含一个隐藏层的全连接网络,隐藏层的节点数由参数mlp_ratio来控制。而MLP的输出和输入的维度保持一致,均为768。同时在Encoder层中的MLP采用的激活函数是GELU。
在整个网络的最后还有一个MLP Head模块,该模块是用来实现分类的,这个分类头在预训练阶段是带有一个隐藏层的MLP,在微调阶段改为由单个线性层实现。由于对于数据集CIFAR10来说,类别数是10,所以这里MLP Head的作用就是完成维度由768到10的线性变换,实现分类,注意这里计算时采用了log_softmax。
三、实验过程:
3.1. 实验说明:
论文中指出,在中小规模的数据集上训练时,Transformer的表现并没有预期的好,因为相比于卷积神经网络来说,Transformer并没有体现出局部性和平移不变性,所以在数据量不足的情况下很难有很好的泛化能力。
基于上述问题,作者在论文中将ViT模型分别在ImageNet、ImageNet-21k和未开源的Google内部的数据集JFT-300M 这三个大型数据集上做了预训练之后,ViT模型已经接近或者超过许多图像识别的基准水平了。
本次实验是采用的vit_base_patch16_224预训练模型,然后在CIFAR10数据集上进行微调。实验过程中参考了以下两个开源实现库:
a) Google官方公布的代码:、
b) 第三方开源实现:
3.2. 实验环境:
CUDA: 11.3、cudnn: 8.2、Miniconda 3、python: 3.9.5、pytorch: 1.8.1
GPU: NVIDIA Quadro RTX 4000
3.3. 实验步骤:
3.3.1 网络结构实现:
论文中的模型共包含以下几个结构模块:
- Patch_Embeding: 实现将图片转换为1D token (dim = 768)
- Attention: 注意力机制模块
- MLP:多层感知器模块
- MLP Head:分类
由于论文官方公布的代码是基于TensorFlow实现的,而且需要安装Jax库,但是在windows下对Jax的支持不太友好,所以本次实验采用的是pytorch实现的,关于各个模块的实现参考了timm开源库的代码实现。
3.3.2 数据集预处理:
CIFAR10 数据集下载地址:https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
由于下载的数据集是二进制文件,一共包含了五个训练数据文件和一个验证数据文件,如下图所示:
所以需要手动对数据集进行解压,转换为32*32标准像素的图片,并且分别存储为train和val文件夹中,以备使用。数据集共包含50000张训练图片,10000张测试图片,共10个类别。解压后的图片如下:
这里的文件名由类别和文件标号组成,由下划线分割,在加载数据集的时候也是通过文件名来获取到图片的标签信息。
; 3.3.3 预训练模型加载:
本次实验使用的预训练模型为ViT-B_Patch16_224,该模型指定patch size为16,输入的图片大小为226*224,并且在ImageNet上完成了模型的预训练过程。在实验中,是通过timm库提供的预训练模型加载接口实现了模型的加载:
model = timm.create_model('vit_base_patch16_224', pretrained=True)
3.3.4 训练过程:
Timm库提供了通用的训练示例代码,但是对于ViT的训练来说,无法直接使用,还需要对其中的部分过程进行修改,以满足ViT的需求,所以本次实验的训练过程,是通过修改Timm库提供的训练代码完成对ViT模型的微调过程。整个训练的代码实现包含以下几个方面:
- 通过配置文件或者命令行的方式定义各种超参数。
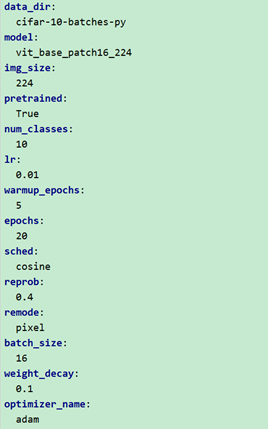
经过对Timm库的源码的阅读,发现Timm库对于超参数的解析提供了便捷的、完备的配置入口,所以对于本次实验的需要定义的超参数,基于了Timm的提供的参数解析方法,通过一个config.yml文件统一配置了模型需要的一些超参数。如下图所示:
(比如,一些基本的配置:数据集地址,预训练模型、分类任务的类别数,学习率等等)。
- 加载数据集:
关于数据集的加载,一开始采用Timm库提供的data_loader接口并未发现问题,但是在训练完一个epoch后,发现验证数据集的Top1准确率竟然达到了100%,完全超出了论文中的最好效果,带着怀疑的态度阅读了data_loader的具体实现源码,并且调试了加载数据集的过程才发现它并不能支持本次实验的数据集正常加载,读取到的标签均为同一个类别。
所以在实验过程中,对data_loader进行了修改,弃用原有的标签读取方式,重写提取标签的过程,通过文件名来获取标签信息,并且和对应的图片绑定起来。
- 加载模型:
由于Timm库本身对ViT的各种预训练模型都进行了收集和封装,所以模型的加载可以直接通过不同的模型名称,调用不同的url地址即可加载到本地。
- 定义优化器和损失函数:
优化器基于pytorch提供的SGD优化器,按原论文中提出的参数设置为0.9。
对于损失函数来说,在训练集上的采用的是标签平滑交叉熵损失函数,在验证集上的损失函数采用的是交叉熵损失函数。
; 四、实验结果及分析:
GPU:NVIDIA Quadro RTX 4000,显存8G
在自己的电脑上训练一个epoch大概需要25分钟,并且batch_size最大可设置为16。
4.1 结果展示:
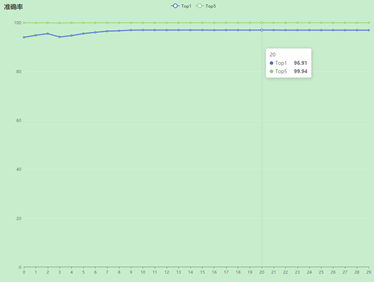
(1)首先看一下经过30个epoch的训练以后得到的实验结果:

可视化结果如下:
(2)添加clip_grad参数,将并将学习率设置为0.03,不做warmup
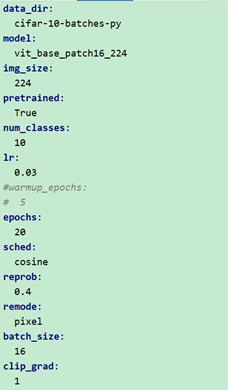
经过30个epoch后,得到的结果如下:
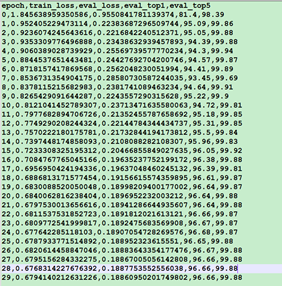
原论文的实验结果:
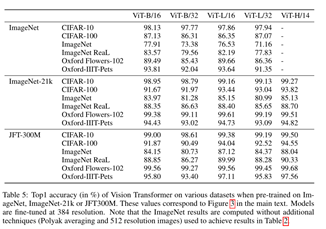
实际验证效果:

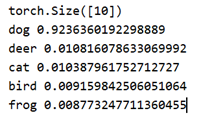

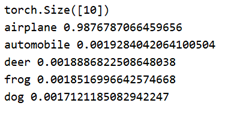

; 4.2 结果分析:
从原论文的实验结果的说明来看, 作者分别在ImageNet、ImageNet-21k、JFT-300M三个数据集上对不同规模的模型进行了预训练,然后再将这些模型应用在CIFAR10、CIFAR100等数据集上做验证得到的Top1准确率的统计结果。比如,对于ViT-B/16来说,在ImageNet数据集上做预训练,然后在CIFAR10上做微调最终得到的Top1准确率为98.13%。而在自己的实验中得到的准确率在96.9%左右。
对于原论文中指出的一些超参数的设置:论文中作者指出,在 训练过程中使用Adam优化器,平滑参数设置为(0.9,0.999),权重衰减率设置为0.1,batch_size=4096。这些参数有比较好的表现。在 微调阶段采用SGD优化器,momentum设为0.9,batch_size=512.

按照原论文512的batch_size来说,这一点由于本地资源有限无法完全和原论文保持一致,在本地的环境下batch_size 最大可以设置为16。还有关于学习率的设置和衰减方案在原论文中提到好几种,有提到采用余弦衰减、也有采用分段常数衰减的方式,本次实验采用的是余弦衰减,初始值设置为0.03。
Original: https://blog.csdn.net/Yore_/article/details/123847838
Author: Yore_
Title: ViT网络模型
相关阅读
Title: [Python实验 ] tensorflow
问题及解决
1、※ModuleNotFoundError: No module named 'cv2' 解决方案√
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python
2、ModuleNotFoundError: No module named 'luminoth' 解决方案=>
ERROR: Cannot uninstall 'PyYAML'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall. 解决方案 =>
pip install --ignore-installed luminoth
Luminoth requires a TensorFlow >= 1.5 installation. Depending on your use case, you should install either tensorflow or tensorflow-gpu packages manually or via PyPI. 装tensorflow =>
ModuleNotFoundError: No module named 'keras' 解决方案 =>
python -m pip install keras
ImportError: cannot import name 'get_config' from 'tensorflow.python.eager.context' 问题
tensorflow和keras版本不对应 =>tensorflow版本、 、二者版本对应1|对应2、
pip install 包名称==版本号 => tensorflow.python.framework.errors_impl.AlreadyExistsError: Another metric with the same name already exists. pip install 包名称==版本号 还是二者版本不对应问题
注意:interpreter 中有version和latest version,自己实际安装的版本是version所显示的
pip install tensorflow==2.6.0
pip install keras==2.6.0
tf1和tf2有区别、累了 毁灭吧 安装python3.6吧 ↓ 有效
3、Unresolved reference 'read_image' 、Unresolved reference 'vis_objects'、Unresolved reference 'Detector'
4、尴尬现状:2.6.0出现tf中无contrib、1.14.0出现checkpoint问题
tf2.0砍了contrib、keras解决×、contrib解决思路、、、
知识
从Pipenv到Luminoth,2017十大ML-Python库:Pipenv、PyTorch、Caffe2、Pendulum、Dash、PyFlux、Fire、imbalanced-learn、FlashText、Luminoth || PyVips、Requestium 、skorch等。
Luminoth 是用于计算机视觉的开源 Python 工具包,它使用 TensorFlow 和 Sonnet 构建,且目前支持 Faster R-CNN 等目标检测方法。此外,Luminoth 不仅仅是一个特定模型的实现,它的构建基于模块化和可扩展,因此我们可以直接定制现有的部分或使用新的模型来扩展它而处理不同的问题,即尽可能对代码进行复用。
TensorFlow:入门详解/教程、是什么:在TensorFlow所有的数据都是一个n维的数组,只是我们给它起了个名字叫做张量(Tensor)、
深度学习中train/val/test:说明val是validation的简称,training dataset 和 validation dataset都是在训练的时候起作用。因为validation数据集和training没有交集,所以这部分数据对最终训练出的模型没有贡献。 validation的主要作用是来验证是否过拟合、以及用来调节训练参数等。|| 交叉验证★:尝试利用不同的训练集/验证集划分来对模型做多组不同的训练/验证,来应对单独测试结果过于片面以及训练数据不足的问题(就像通过多次考试,才通知哪些学生是比较牛的) 。做法就是将数据集粗略地分为比较均等不相交的k份,然后取其中的一份进行测试,另外的k-1份进行训练,然后求得error的平均值作为最终的评价。通常建议K=10 ||

Original: https://blog.csdn.net/sinat_40759442/article/details/122869263
Author: 우 유
Title: [Python实验 ] tensorflow