
记录几篇Transformer的超分辨率重建论文。
1 Learning Texture Transformer Network for Image Super-Resolution(TTSR, CVPR2020)
本文引用已经有200多了。 原文链接
1.1 摘要
文章做的是RefSR工作,主要观点是将Transformer作为一个attention,这样可以更好地将参考图像(Ref)的纹理信息转移到高质图像(HR)中。做法还是比较有意思的,如下图所示,将上采样的LR图像、依次向下/上采样的Ref图像、原始Ref图像中提取的纹理特征分别作为Q、K、V。纹理Transformer包含了4个结构:1)DNN实现的可学习的纹理提取器(learnable texture extractor)2)相关性嵌入模块( relevance embedding)3)用于纹理转换的硬注意力模块(hard-attention)4)用于纹理合成的软注意力模块(soft-attention)。此外整个纹理Transformer模块可以跨尺度的方式进一步堆叠,这使得能够从不同尺度(例如,从1x倍到4x倍放大率)恢复纹理

; 1.2 网络结构
鉴于该论文蛮多讲解的,我简单复述一下,最后会贴其他的论文讲解。
1.2.1网络的整体架构
如下图所示,将多个纹理Transformer(即上图)堆叠、上采下采融合来实现超分。
 其中RBS为多个残差Block,CSFI为跨尺度特征集成模块(ross-scale feature integration )
其中RBS为多个残差Block,CSFI为跨尺度特征集成模块(ross-scale feature integration )
1.2.2纹理Transformer
即图1,介绍一下他的四个组件。
1)DNN实现的可学习的纹理提取器。就是将图像送入DNN,然后DNN可以训练
2)相关性嵌入模块。使用归一化内积计算Q、K之间的相关性。获得矩阵r i , j r_{i,j}r i ,j ,i,j分别为Q,K的patch数目。
3)硬注意力。通过h i = a r g m a x ( r i , j ) h_{i}=argmax(r_{i,j})h i =a r g m a x (r i ,j )获得对每个LR块,最相似的Ref块的索引。然后从V中获得该特征块组成T。举个例子,比如查询第i=3 LR图像块时,发现在K中,第j=7个图像块跟它最相似,那h 3 = 7 h_3=7 h 3 =7,在构建T时,T的第3个图像块就由V的第7个图像块构成。
4)软注意力。获得软注意力图s i = a r g m a x ( r i , j ) s_{i}=argmax(r_{i,j})s i =a r g m a x (r i ,j ),然后利用下式获得输出。
再分析一下这个公式,当S大的时候,说明当前块和T的相关性大,所以用更多的T的特征,如果S小,则使用更少的参考帧特征。
1.3 损失函数
L1 loss + GAN loss + Percepture Loss
其他参考讲解
1)https://cloud.tencent.com/developer/article/1646490
2)https://zhuanlan.zhihu.com/p/320236856
2 SwinIR: Image Restoration Using Swin Transformer(ICCV2021)
2.1 摘要
该文准确来说实现包括SR、denoise、JPEG compression artifact reduction等三项low level image Restoration任务。transformer在high level中效果不错,但没有使用到low level中。因此作者用Swin Transformer实现可一个baseline。
2.2 网络结构
虽说很多大佬,但其实没啥要讲的,网络结构看图就好,还是常见的主体结构学习残差,然后与LR图像相加后上采。
 1)Shallow Feature Extraction 为一层3x3卷积。
1)Shallow Feature Extraction 为一层3x3卷积。
2)HQ Image Reconstruction在SR任务中采用sub-pixel Conv,就是unpixelShuffle。denoise和JPEG去伪影用一层卷积。
3)对STL,就是Transformer的Encoder结构。将输入划分为M ∗ M M*M M ∗M个块X,然后每个X映射为QKV,通过多头attention后将输出concat。MLP通过两层FC实现。作者还进行了划窗来避免图像块之间的信息不融合问题。步长为M / 2 M/2 M /2
; 2.3 Loss
简单的仿真图像SR只使用L1 loss
真实图像SR使用L1 + GAN loss
denoise和JPEG去伪影 使用Cb loss
3 Video Super-Resolution Transformer
论文 代码
transformer用于VSR,被引22。论文还有很多公式,代码也很标准,都可以互相参考着看看。
3.1 摘要
作者觉得transformer本来就是用于处理序列数据的,那VSR正好是视频帧的序列数据。但是传统Transformer包含FC的自注意力层和基于token的前向层(Feed Forward,FF)。这导致以下两个问题:
1)全连接的自注意层由于依赖FC来计算注意图而忽略了对局部信息的利用。
这个是Transformer用于low level经常会谈到的问题,意思是说Tranformer是全局attention的,但是low level任务一般需要局部attention。
2)由于词前馈层独立的处理每个输入,导致其缺乏特征对齐的能力。
这个是说,vsr一般需要帧间特征的对齐,但是transformer的FF层只处理一个token,因此无法做到对齐。
针对以上两个问题,作者分别提出了时空自注意力层(spatial-temporal convolutional self-attention)和基于双向光流的前馈层(bidirectional optical flow-based feed-forward)
3.2 网络结构
整体架构如下:
 1)特征提取器,由一堆ResBlock构成。
1)特征提取器,由一堆ResBlock构成。
2)重建模块,文中没说,代码将残差通过两次unpixelshuffle上采4x,然后与双线性插值后的原图相加得到输出结果。
3)位置编码。空间和时序的3D信息
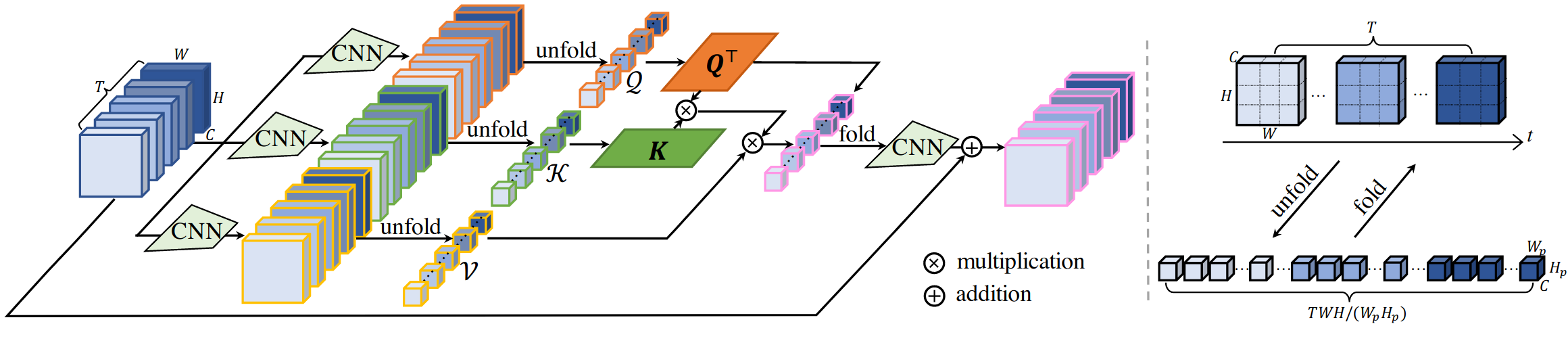
3.2.1 VSRT
1)时空自注意力层。通过CNN提取特征,然后通过unfold和reshape操作获得Q T Q^T Q T和K K K,将这两个向量计算attention矩阵。但有个问题是,我感觉Q T Q^T Q T连接到紫色输出的线是错的,因为公式和代码都没有这个相乘。
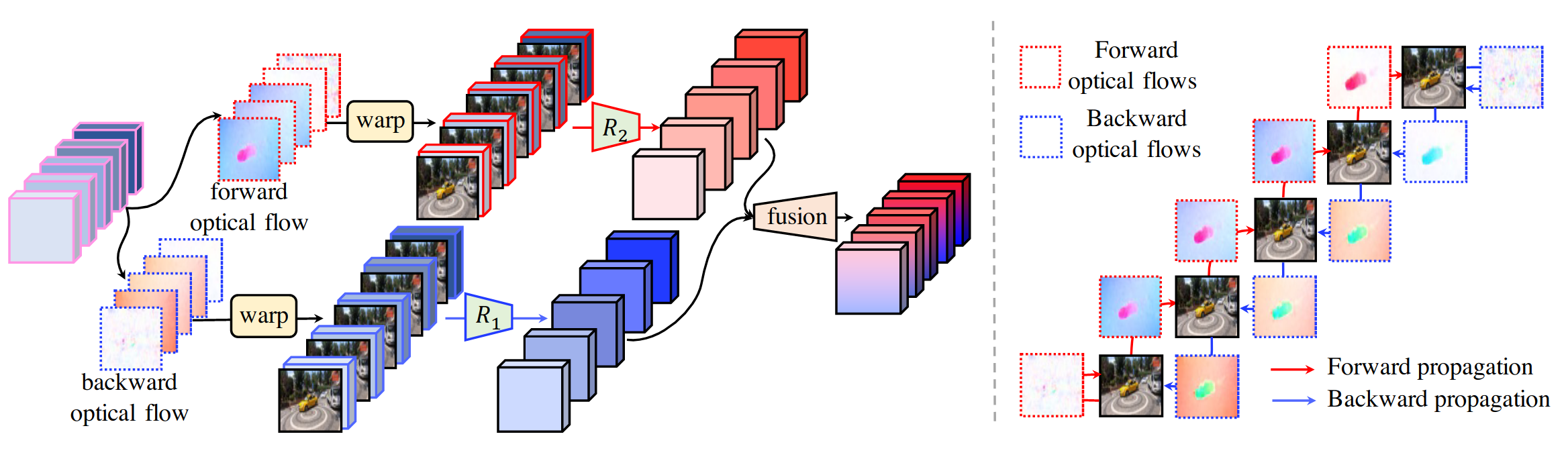
2)基于双向光流的前馈层
即通过前向和后向光流,然后融合输出。
其他参考讲解
- https://cloud.tencent.com/developer/article/1846290
; 4 Efficient Transformer for Single Image Super-Resolution
论文挂在arxiv上,有7个索引
其实结构连得超级复杂(摘要里竟然还吐槽其他论文堆积结构参数提升性能 ),有一点是提出了Efficient Multi-Head Attention (EMHA)实现Transformer的轻量化,这点可以稍微讲讲。
4.1 EMHA
 主要是在获得QKV之后,将QKV特征分为s组,每组分别进行attention获得输出O,然后将输出Concat,这样可以将大矩阵相乘拆分为多个小矩阵相乘。这也是Transformer常见的减少参数操作。
主要是在获得QKV之后,将QKV特征分为s组,每组分别进行attention获得输出O,然后将输出Concat,这样可以将大矩阵相乘拆分为多个小矩阵相乘。这也是Transformer常见的减少参数操作。
; 4.2 HFM
此外作者还用了一个High-frequencyFiltering Module (HFM)提取高频信息,结构如下,仅供参考。
 其他内容可以看讲解
其他内容可以看讲解
5 Microsoft Bing Turing ISR(T-ISR)
Introducing Turing Image Super Resolution: AI powered image enhancements for Microsoft Edge and Bing Maps
这篇不算论文,是微软介绍自家用于Microsoft Edge和Bing Maps上ISR的技术博客。但是效果非常Amazing啊,但缺点是有些地方没有仔细介绍。
5.1 设计原则
1)人类视觉为基准(Human eyes as the north star)
广泛使用的指标如PSNR,SSIM并不总是和人眼视觉的直观感受匹配的,同时也需要GT图。我们构建了一个并行评估工具匹配人眼判断,并将这个工具作为north star metric来引导模型训练。(可是作者没介绍这个工具是啥55555)
2)噪声建模(Noise modeling)
开始作者也是将HR图像降质然后构建HR-LR图相对训练。但这样有些case效果好,但是对真实的LR图像不鲁棒。因此随机对输入图像用blurring, compression 和 gaussian noise进行破坏可以恢复细节。
3)Perceptual and GAN loss
仅pixel loss不够,要引入感知和GAN loss,并用权重结合。
4)Transformers for vision
CNN和Transformer各有优缺点,因此未利用他们各自优点,将网络分为Enhance和Zoom,前者使用Transformer,后者使用CNN。(其实这段也没详细介绍各自优缺点是什么。整体四准则很对我胃口啊,果然英雄所见略同hhhh)
5.2 DeepEnhance – Cleaning and Enhancing Images
在处理高度压缩和从远程卫星拍摄的航拍照片等very noise图像时,Transformer清理噪声做的很好。如人脸的噪声和处理包含很多纹理的森林的特征就很不同。这是因为大数据集和Transformer卓越的远程记忆能力。我们先使用了一个稀疏Transformer,将其放大以支持非常大的序列长度来"Enhance"图像,产生干净的,crisper(脆?)和更具吸引力,尺寸相同的图像。有些场景不需要放大图像,那到这里就可以停止了。
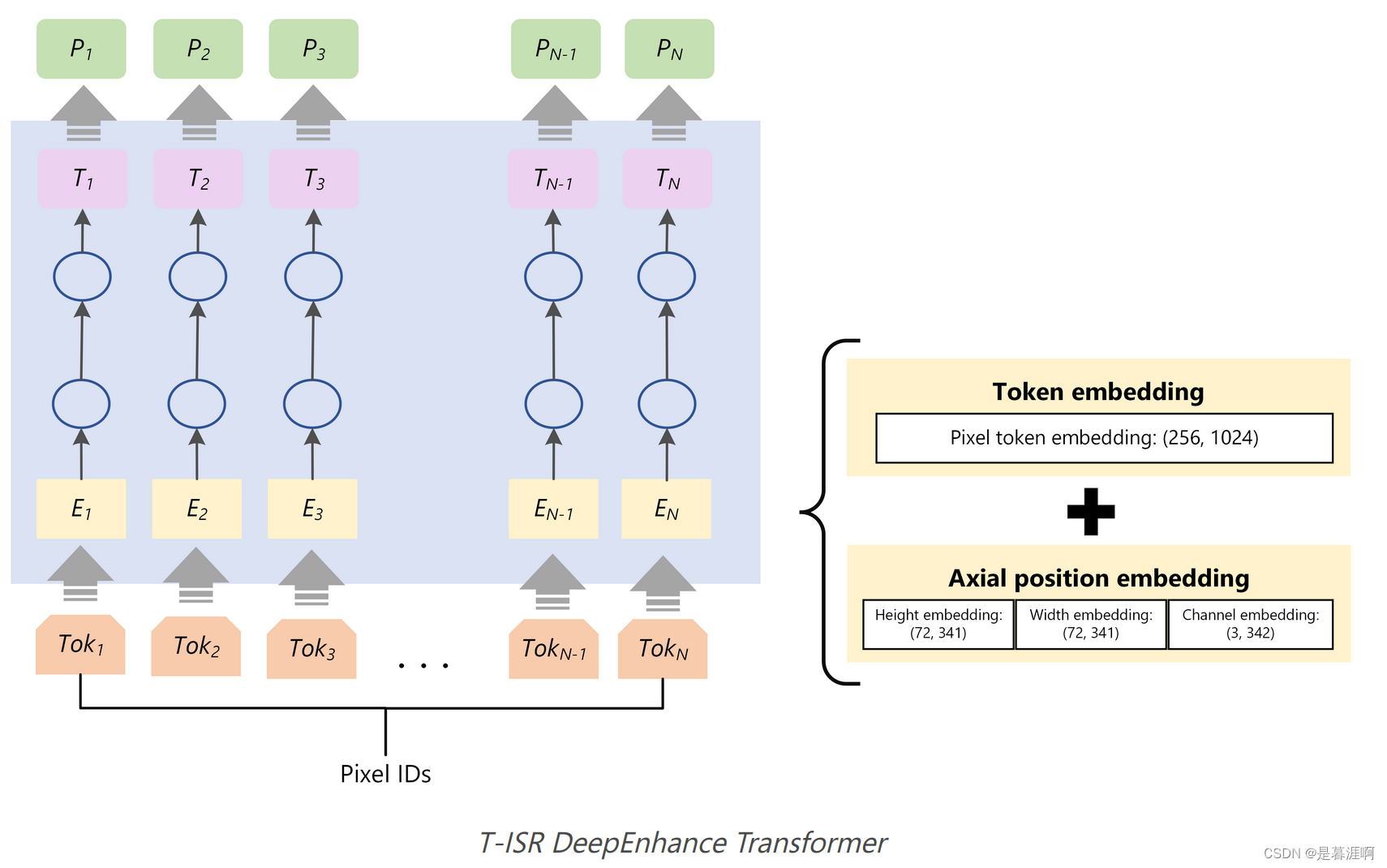 非常难受的是这个结构作者没有详细介绍。
非常难受的是这个结构作者没有详细介绍。
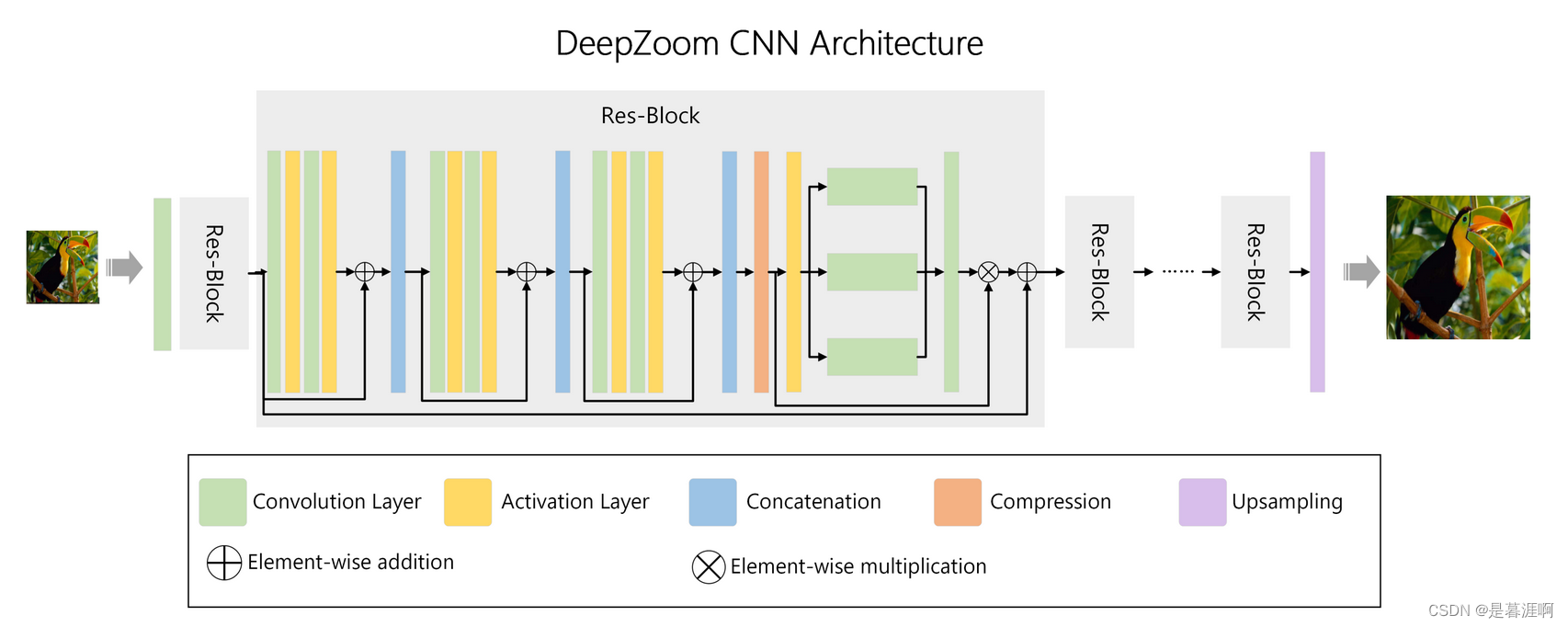
; 5.3 DeepZoom – Scaling up Images
作者认为双线性和双立方插值都会导致图像信息丢失,因此采用200层的CNN恢复pixel细节
5.4 泛化能力Generalization Ability
T-ISR在几个不同任务的海量多样的数据上进行训练。所以相同的模型可以应用到Bing Maps, Microsoft Edge和其他可能的场景。域的多样性提升了网络的性能。如为处理卫星图中森林做的训练recipe同样提升了自然图像(如人,动物,建筑)的效果。
Original: https://blog.csdn.net/longshaonihaoa/article/details/123871899
Author: 是暮涯啊
Title: Transformer用于超分辨率重建