
文章目录
前言
把由放大缩小的引起的导致分辨率低的图像,转换成为 分辨率高的图像。更加关注的是重构图片过程中,填充新的像素。SRCNN 呢也是将深度学习用于图像重建的鼻祖,网络结构非常简单,于是我决定来复现一下它。
代码链接:https://github.com/jiantenggei/SRCNN-Keras (包含所有资源)
一、SRCNN
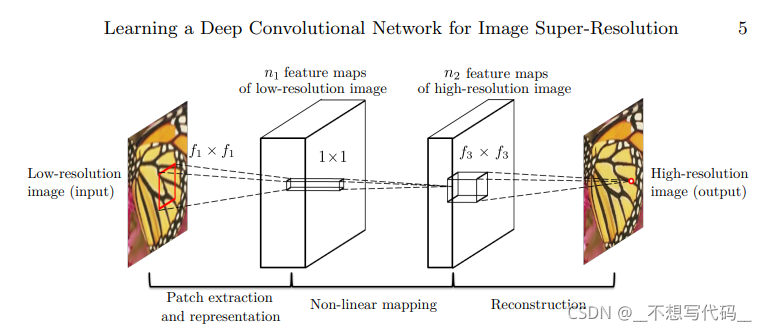
SRCNN 的网络结构特别简单,首先将一张低分辨率的图像作为输入,通过两个卷积后,还原成为高质量的图片。网络卷积运算时,保持特征图的大小和重构图片大小一致。且网络中没有线性连接。也就只有三层卷积~。
; 二、SRCNN 实现
首先在这里简述一下SRCNN 网络的训练和测试流程:
1.先将图片缩小后,再放大,制作不清晰的图片作为训练数据
2.将未处理过的原图片作为训练时的标签。
3.将图片和标签放到网络中训练。
4.测试模型时,将一张不清晰的图片输入到训练好的网络,生成的图片与清晰的原图片计算峰值信噪比。
1.模型的搭建
代码如下:
from keras.models import Sequential, model_from_json
from keras.layers.convolutional import Conv2D
from keras.layers.core import Activation
def built_model(input_shape=(33, 33, 1)):
model = Sequential()
model.add(Conv2D(filters=64, kernel_size=9,
padding='same', input_shape=input_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, 1, padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(input_shape[2], 5, padding='same'))
return model
if __name__ == '__main__':
model = built_model()
model.summary()
最后一层把图片从多通道特征图,还原成和输入通道一致。
2.生成训练数据
1.先将图片缩小后,再放大,制作不清晰的图片作为训练数据
2.将未处理过的原图片作为训练时的标签。
代码如下:
def load_train(image_size=33, stride=33, scale=3,dirname=r'dataset\train'):
dir_list = os.listdir(dirname)
images = [cv2.cvtColor(cv2.imread(os.path.join(dirname,img)),cv2.COLOR_BGR2GRAY) for img in dir_list]
images = -np.remainder(img.shape[0],scale),0:img.shape[1]-np.remainder(img.shape[1],scale)] for img in images]
trains = images.copy()
labels = images.copy()
trains = [cv2.resize(img, None, fx=1/scale, fy=1/scale, interpolation=cv2.INTER_CUBIC) for img in trains]
trains = [cv2.resize(img, None, fx=scale/1, fy=scale/1, interpolation=cv2.INTER_CUBIC) for img in trains]
sub_trains = []
sub_labels = []
for train, label in zip(trains, labels):
v, h = train.shape
print(train.shape)
for x in range(0,v-image_size+1,stride):
for y in range(0,h-image_size+1,stride):
sub_train = train[x:x+image_size,y:y+image_size]
sub_label = label[x:x+image_size,y:y+image_size]
sub_train = sub_train.reshape(image_size,image_size,1)
sub_label = sub_label.reshape(image_size,image_size,1)
sub_trains.append(sub_train)
sub_labels.append(sub_label)
sub_trains = np.array(sub_trains)
sub_labels = np.array(sub_labels)
return sub_trains, sub_labels
def load_test(scale=3,dirname=r'dataset\test'):
dir_list = os.listdir(dirname)
images = [cv2.cvtColor(cv2.imread(os.path.join(dirname,img)),cv2.COLOR_BGR2GRAY) for img in dir_list]
images = -np.remainder(img.shape[0],scale),0:img.shape[1]-np.remainder(img.shape[1],scale)] for img in images]
tests = images.copy()
labels = images.copy()
pre_tests = [cv2.resize(img, None, fx=1/scale, fy=1/scale, interpolation=cv2.INTER_CUBIC) for img in tests]
tests = [cv2.resize(img, None, fx=scale/1, fy=scale/1, interpolation=cv2.INTER_CUBIC) for img in pre_tests]
pre_tests = ,img.shape[1],1) for img in pre_tests]
tests = ,img.shape[1],1) for img in tests]
labels = ,img.shape[1],1) for img in labels]
return pre_tests, tests, labels
注意:代码中采样过程(三个for 训练处) 是将一张图片,截取一个个小的区域,这样一张图片就可以产生成多个数据,弥补训练样本不足的问题。
3.训练过程:
代码如下:
from tensorflow.python.keras.saving.model_config import model_from_config
from model import built_model
from utils import load_train
from keras.optimizers import Adam
def train():
input_shape = (33, 33, 1)
stride = 14
batch_size = 64
epochs=100
learning_rate=0.001
srcnn_model = built_model(input_shape=input_shape)
srcnn_model.load_weights(r'model\srcnn_weight.hdf5')
srcnn_model.summary()
X_train, Y_train = load_train(image_size=input_shape[0], stride=stride)
print(X_train.shape, Y_train.shape)
optimizer = Adam(lr=learning_rate)
srcnn_model.compile(optimizer=optimizer, loss='mean_squared_error', metrics=['accuracy'])
srcnn_model.fit(X_train,Y_train,epochs=epochs,batch_size=batch_size)
srcnn_model.save(r'model/srcnn.h5')
if __name__ == '__main__':
train()
这里计算损失用均方差,因为输入和输出都是大小一致的图片~ 只是分辨率不同。
4.测试过程
代码如下:
from model import built_model
import os
from utils import load_test,psnr
import cv2
def test():
input_shape = (None, None, 1)
scale = 3
srcnn_model = built_model(input_shape=input_shape)
srcnn_model.load_weights(r'model\srcnn_weight.hdf5')
X_pre_test, X_test, Y_test = load_test(scale=scale)
predicted_list = []
for img in X_test:
img = img.reshape(1,img.shape[0],img.shape[1],1)
predicted=srcnn_model.predict(img)
predicted_list.append(predicted.reshape(predicted.shape[1],predicted.shape[2],1))
n_img = len(predicted_list)
dirname = './result'
for i in range(n_img):
imgname = 'image{:02}'.format(i)
cv2.imwrite(os.path.join(dirname,imgname+'_original.bmp'), X_pre_test[i])
cv2.imwrite(os.path.join(dirname,imgname+'_input.bmp'), X_test[i])
cv2.imwrite(os.path.join(dirname,imgname+'_answer.bmp'), Y_test[i])
cv2.imwrite(os.path.join(dirname,imgname+'_predicted.bmp'), predicted_list[i])
answer = psnr(Y_test[i],predicted_list[i])
print(imgname+"_psnr:",answer)
if __name__ == '__main__':
test()
X_test 存放的是不清晰的图片,用于和预测结果计算计算峰值信噪比。
总结
各种网络各种功能,喂数据的方式不同,计算损失的方式不同罢了~
Original: https://blog.csdn.net/qq_38676487/article/details/120595718
Author: 不想写代码
Title: SRCNN 图像超分辨率重建(tf2)
相关阅读
Title: TensorFlow2-基础(五):Tensor的维度变换【改变:reshape(view级别)、transpose(content级别)】【增加(expand_dims)、删除(squeeze)】
tensorFlow维度变换可分为两个级别,一个是view级,一个是content级。
- view级维度变换:不改变数据的存储关系,比如[3,28,28,3]变换维度为[3,784,3]之后,数据本身并没有改变,属于哪一行哪一列的元素还是可以确定,可以原模原样的恢复为[3,28,28,3]。
- content级维度变换:会改变数据的存储关系。content有"目录"的意思,即索引关系,通过[3,28,28,3]这样的索引号能够找到一个元素。当content被改变时,意味着元素之间的索引关系变了。例如[3,28,28,3]变换为[3,3,28,28]后,相当于把最后面的维度数据整个提到了前面。
基本的维度变换包含了改变视图 reshape,插入新维度 expand_dims,删除维 squeeze,交换维度 transpose,复制数据 tile 等。
一、张量的存储和视图(View)概念
张量的视图就是我们理解张量的方式,比如shape 为[2,4,4,3]的张量A,我们从逻辑上可以理解为2 张图片,每张图片4 行4 列,每个位置有RGB 3 个通道的数据;
张量的存储体现在张量在内存上保存为一段连续的内存区域,对于同样的存储,我们可以有不同的理解方式,比如上述A,我们可以在不改变张量的存储下,将张量A 理解为2 个样本,每个样本的特征为长度48 的向量。
这就是存储与视图的关系。
在存储数据时,内存并不支持这个维度层级概念,只能以平铺方式按序写入内存,因此这种层级关系需要人为管理,也就是说,每个张量的存储顺序需要人为跟踪。
为了方便表达,我们把张量shape 中相对靠左侧的维度叫做大维度,shape 中相对靠右侧的维度叫做小维度,比如[2,4,4,3]的张量中,图片数量维度与通道数量相比,图片数量叫做大维度,通道数叫做小维度。
例如:在优先写入小维度的设定下,张量 [2,4,4,3] 的内存布局为

为了能够正确恢复出数据,必须保证张量的存储顺序与新视图的维度顺序一致,
例如根据图片数量-行-列-通道初始视图保存的张量,按照图片数量-行-列-通道(𝑏 − ℎ −w − 𝑐)的顺序可以获得合法数据。
如果按着图片数量-像素-通道(b − h ∗ w − c)的方式恢复视图,也能得到合法的数据。但是如果按着图片数量-通道-像素( − c − h ∗ w)的方式恢复数据,由于内存布局是按着图片数量-行-列-通道的顺序,视图维度与存储维度顺序相悖,提取的数据将是错乱的。
; 二、Reshape 操作
改变视图是神经网络中非常常见的操作,可以通过串联多个Reshape 操作来实现复杂
逻辑,
但是在通过Reshape 改变视图时,必须始终记住张量的存储顺序,新视图的维度顺序不能与存储顺序相悖,否则需要通过交换维度操作将存储顺序同步过来。
举个例子,对于shape 为[4,32,32,3]的图片数据,通过Reshape 操作将shape 调整为[4,1024,3],此时视图的维度顺序为 𝑏 − 𝑝𝑖𝑥𝑒𝑙 − 𝑐,张量的存储顺序为 [𝑏, ℎ, w, 𝑐]。
在 TensorFlow 中,可以通过张量的ndim 和shape 成员属性获得张量的维度数和形
状:

通过 tf.reshape(x,new_shape),可以将张量的视图任意的合法改变

当不知道填入什么数字合适时,可以选用 -1 来替代,由python通过其他值进行推算得知具体值
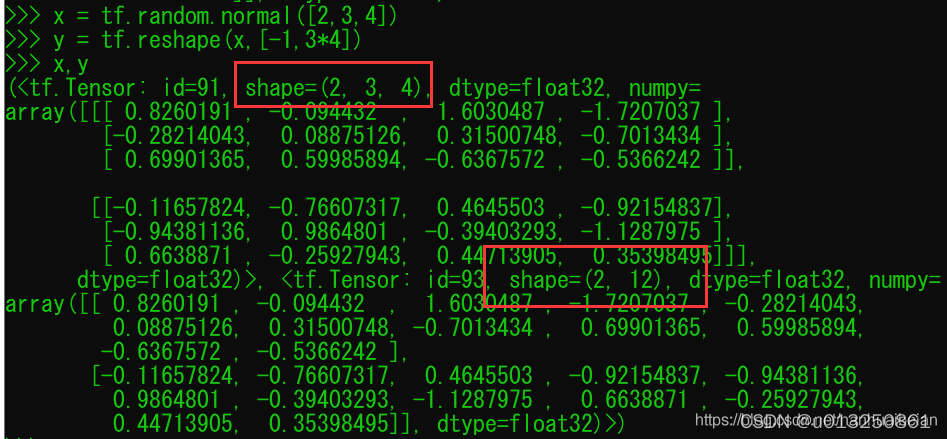
例如将shape为 [b,3,4]的输入数据转为 shape为 [b,3*4] 的数据:
三、增删维度
1、增加维度
增加一个长度为1 的维度相当于给原有的数据增加一个新维度的概念,维度长度为1,故数据并不需要改变,仅仅是改变数据的理解方式,因此它其实可以理解为改变视图的一种特殊方式
比如:,一张28x28 灰度图片的数据保存为 shape 为[28,28]的张量,在末尾给张量增加一新维度,定义为通道数维度,此时张量的shape 变为[28,28,1]:
通过tf.expand_dims(x, axis)可在指定的axis 轴前可以插入一个新的维度:
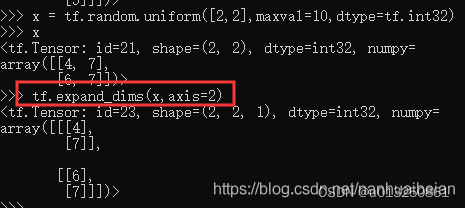
可以看到插入一个新维度后,数据的存储顺序并没有改变,仅仅改变了数据的视图。

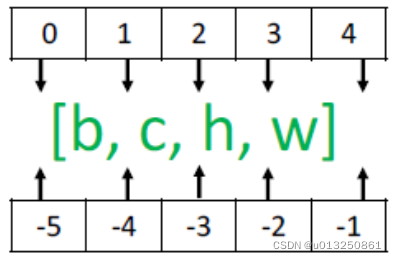
需要注意的是,tf.expand_dims 的axis 为正时,表示在当前维度之前插入一个新维度;为负时,表示当前维度之后插入一个新的维度。以[𝑏, ℎ, w, 𝑐]张量为例,不同axis 参数的实际插入位置如图所示:
; 2、删除维度
是增加维度的逆操作,与增加维度一样,删除维度只能删除长度为1 的维度,也不会改变张量的存储。
可以通过tf.squeeze(x, axis)函数,axis 参数为待删除的维度的索引号
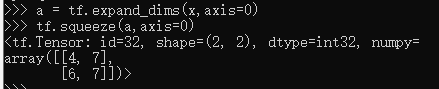
如果不指定维度参数 axis,即 tf.squeeze(x),那么他会默认删除所有长度为1的维度
四、交换维度
在实现算法逻辑时,在保持维度顺序不变的条件下,仅仅改变张量的理解方式是不够的,有时需要直接调整的存储顺序,即交换维度(Transpose)。通过交换维度,改变了张量的存储顺序,同时也改变了张量的视图。
我们以[𝑏, ℎ, w, 𝑐]转换到[𝑏, 𝑐, ℎ, w]为例,介绍如何使用tf.transpose(x, perm)函数完成维度交换操作,其中 perm 表示新维度的顺序 List。
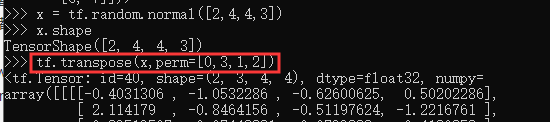
通过tf.transpose完成维度交换后,张量的存储顺序已经改变,视图也随之改变,后续的所有操作必须基于新的存续顺序进行
; 五、数据复制
tf.tile(x, multiples)函数完成数据在指定维度上的复制操作,multiples 分别指定了每个维度上面的复制倍数,对应位置为1 表明不复制,为2 表明新长度为原来的长度的2 倍,即数据复制一份,以此类推。

参考资料:
TensorFlow:维度变换
TensorFlow基础(7.维度变换)
【tensorFlow】维度变换
tensorflow(八):维度变换
Original: https://blog.csdn.net/u013250861/article/details/124222288
Author: u013250861
Title: TensorFlow2-基础(五):Tensor的维度变换【改变:reshape(view级别)、transpose(content级别)】【增加(expand_dims)、删除(squeeze)】