
前面一篇文章对联邦学习的代码进行了详细的解读,这篇文章主要是通过调试,更深入地了解一下联邦学习代码是如何运行的,促进后续我们对于其他和联邦学习的相关文章的阅读,以及在本代码基础之上进行修改。
首先回顾一下伪代码:

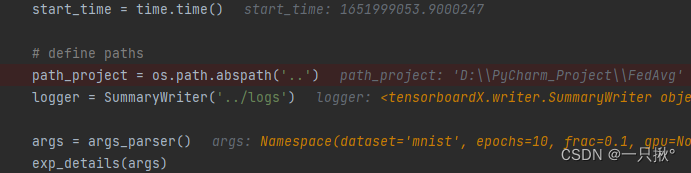
这些都不用再说明了,就是一些基本设置。那args已经在 options.py进行设置了。运行这几段代码之后,会展示出一些联邦学习设置的重要细节(如下图所示),这些细节都可以通过命令行参数来改变。
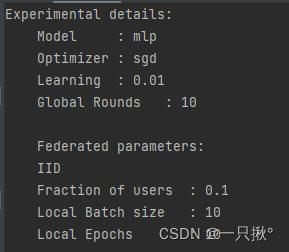
实验的重要细节:
模型:'mlp'
优化器:'sgd'
学习率:0.01
全局回合数:10
联邦学习参数:
数据集采集:IID(独立同分布)
用户选取比例C:0.1
本地批量大小B:10
本地回合数E:10
; 获取数据集

这行代码主要是为了获取训练集和测试机、用户组。
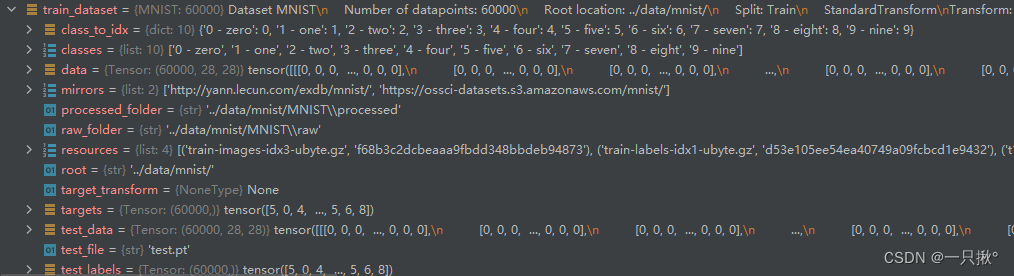
我们获取的训练集如下图所示:
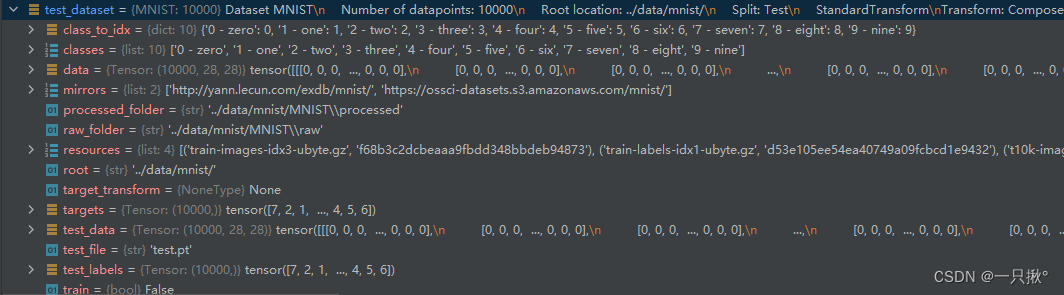
我们获取的测试数据集如图所示:
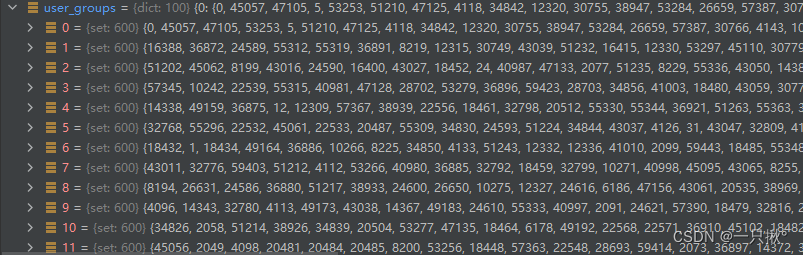
获取的用户组如图所示,是随机从训练集中选取的IID或者non-IID的数据,图中的每个用户组数据是图片的索引值。
开始训练
我们训练的模型是'mlp'所以直接进入这个条件判断后的语句
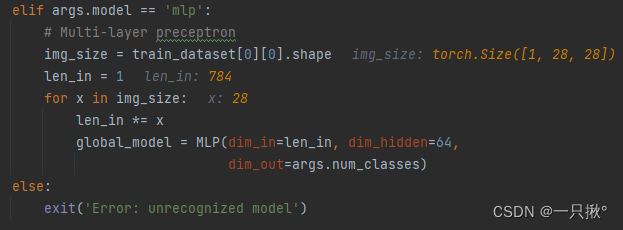
运行到最后一步的时候 len_in=784,为什么要像这样进行MLP模型的训练我暂时还不明白,或许后面还得仔细看看论文的实验设置。

原论文说明了多层感知器是有两个隐藏层以及200个单元的,每个单元都是用ReLu激活函数,我们将其视为MNIST 2NN。但是代码中设置的隐藏层是有64层的???另外输入为什么需要设置一个循环进行不同的设置,是因为单纯要计算最后的 len_in吗???
; 初始化参数:
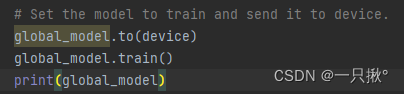
上述代码设置模型进行训练,并将模型发给设备(cpu),打印出模型的信息。
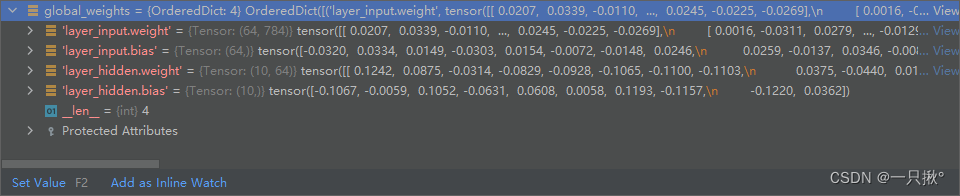
global_model.train()这行代码作用是什么?为什么这里就开始训练了?下面一张图的模型的每层的参数是如何得到的???
答:model.train()怎么用?在使用 pytorch 构建神经网络的时候,训练过程中会在程序上方添加一句 model.train(),作用是 启用 batch normalization 和 dropout 。
如果模型中有BN层(Batch Normalization)和 Dropout ,需要在 训练时 添加 model.train()。
model.train() 是保证 BN 层能够用到 每一批数据 的均值和方差。对于 Dropout, model.train() 是 随机取一部分 网络连接来训练更新参数。
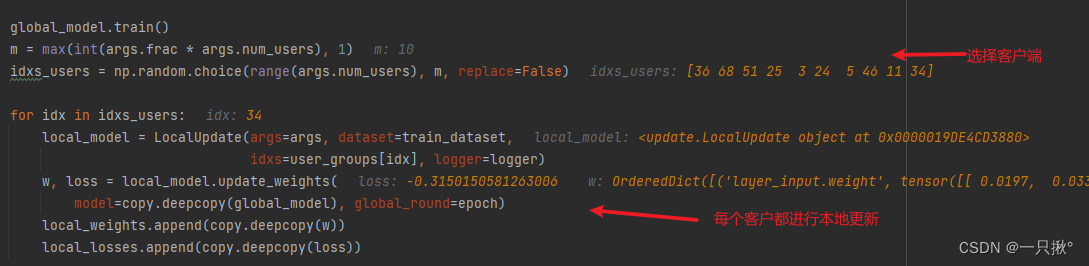
; 本地更新
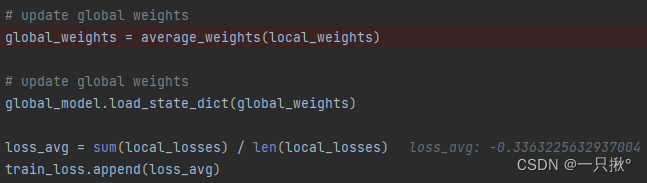
全局更新
- 进行全局的参数更新,取本地更新权重的平均值
- 训练损失值也进行更新
- 计算所有用户在每个全局回合当中的训练精度,根据这个回合算出的平均参数。
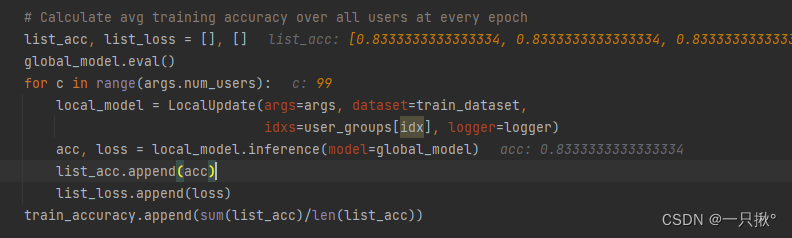
- 每个全局回合结束后,将打印输出这轮的训练损失值和训练精度

根据这样的步骤,循环执行,直至所有的全局回合结束。
; 测试精度和损失值

打印输出测试结果

测试结果如下:

Original: https://blog.csdn.net/weixin_42098322/article/details/124650776
Author: 一只揪°
Title: 联邦学习代码调试