
参考书目:知识图谱:方法、实践与应用
知识工程导论、知识表示、知识推理、知识构建、知识存储、知识管理、知识工程应用
第1章 知识工程导论
1.1 知识工程简史
1.1.1 知识工程主要成就
1969图灵奖 Minsky感知机,框架知识表示
1971图灵奖 McCathy LISP语言
1975图灵奖 Newell&Simon形式化语言,通用问题求解
1994图灵奖 Feigenbaum知识工程提出者
2011图灵奖 Judea Pearl 概率图模型之父
2016图灵奖 Berners-Lee语义网
1.1.2 专家系统
其中,以Newell和 Simon为代表人物的符号主义学派,最先取得丰硕成果,最著名的代表为逻辑机LT。符号主义最核心的思想是什么呢?符号主义认为人工智能源于数理逻辑,认为智能的本质就是符号的操作和运算。(数学家的天下)
后来我们也知道,早期对于人工智能过高的期望和算力不足造成了接二连三的项目失败。在人工智能领域经历挫折之后,研究者们不得不冷静下来,重新审视、思考未来的道路。这时候,西蒙的学生,爱德华·费根鲍姆(Edward A. Feigenbaum)站了出来。他分析传统的人工智能忽略了具体的知识,人工智能必须引进知识。
Feigenbaum是专家系统之父,知识工程的奠基人。Knowledge is the power in AI。专家系统一般由两部分组成:知识库与推理引擎。它根据一个或者多个专家提供的知识和经验,通过模拟专家的思维过程,进行主动推理和判断,解决问题。第一个成功的专家系统DENDRAL化学分子式分析系统于1968年问世(面向垂域(特定领域、垂直领域)的专家系统)。1977年,费根鲍姆将其正式命名为知识工程。
把知识融合在机器中,让机器能够利用我们人类知识、专家知识解决问题,这就是知识工程要做的事。
不幸的是,随着日本五代机的幻灭,专家系统在经历了十年的黄金期后,终因无法克服人工构建成本太高,知识获取困难等弊端,逐渐没落。
1.1.3 知识工程与互联网
1998年随着万维网的出现,为知识的获取提供了极大的方便。万维网之父蒂姆·伯纳斯·李再次提出语义网sematic network/web。它的核心是:语义网可以 直接向机器提供能用于程序处理的知识。通过将万维网上的文档转化为计算机所能理解的语义,使互联网成为信息交换媒介。这需要自顶向下的优质设计框架,必须在一开始就对分类想的非常清楚,从而对数据进行表示处理。
由于自顶向下的设计落地困难,学者们将目光转移到数据本身上来,提出了连接数据的概念。连接数据希望数据不仅仅发布于语义网中,更需要建立起自身数据之间的链接从而形成一张巨大的链接数据网。其中, DBpedia项目是目前已知的第一个大规模 开放域链接数据。类似的还有 Wikipedia、 Yago等都属于这一类结构化知识的知识库。
1.1.4 知识图谱的出现
谷歌搜索是谷歌公司的核心产品服务,这类互联网的应用,主要有以下特点:
- 大规模开放性应用,永远不知道用户下一次搜索关键词是什么;
- 精度要求不高;大部分搜索理解与回答只需要实现简单的推理,复杂推理为极少数。
在这样的诉求下,谷歌推出了自己的知识图谱,使用与语义检索,从多种来收集信息,以提高搜索质量。而知识图谱的推出,基本上宣告了知识工程进入了一个新的时代,我们称之为大数据时代的知识工程阶段。谷歌利用一个全新名称表达与传统知识表示其毅然决裂的态度。
知识图谱即为一种大规模语义网络。这样的一个知识规模上的量变带来了知识效用的质变。
我们有海量的数据、强大计算能力、群智计算以及层出不穷的模型。在这些的外力的支持下,解决了传统知识工程的一个瓶颈性问题—— 知识获取。我们可以利用算法实现数据驱动的大规模自动化知识获取。
和传统知识获取不同,以前是通过专家自上而下的获取知识,而现在是利用数据 自下而上,从数据里面去挖掘知识、抽取知识。另外, 众包与群智成为大规模知识获取的一条新路径。高质量的UGC内容,为自动挖掘知识提供了高质量数据源。
1.1.5 知识图谱的应用前景
大数据知识这个词是BigKE,它将会显著提升机器认知智能水平。我们正在经历感知智能到认知智能的过渡阶段,未来最重要到技术即是实现认知智能。知识图谱使可解释人工智能成为可能。在人工智能发展的任何阶段,我们都需要事物的可解释性,现在的深度学习也常因为缺少可解释性受人诟病。而知识图谱中包含的概念、属性、关系是天然可拿来做解释的。
通过知识图谱等先验的知识去赋能机器学习,来降低机器学习对于样本的依赖,增强机器学习的能力。知识将显著增强机器学习能力。传统的机器学习都是通过大量的样本习得知识,在大数据红利渐渐消失的情况下,逐渐遇到发展瓶颈。而通过知识图谱等先验的知识去赋能机器学习,来降低机器学习对于样本的依赖,增强机器学习的能力,或许是连接主义和符号主义在新时代下的共生发展。
1.2 知识工程的主要问题
1.2.1 知识获取
隐性知识、过程知识等难以表达。比如如何表达老中医看病用了哪些知识;不同专家可能存在主观性,例如,我国有明确治疗规范的疾病占比非常小,大部分依赖医生的主观性。
1.2.2 知识表达
逻辑学规定了一套数理逻辑符号可供参考,然而现实生活中有太多复杂的知识形态。
1.2.3 知识应用
很多的应用,尤其是很多开放性的应用很容易超出预先设定的知识边界;还有很多应用需要常识的支撑,而整个人工智能最怕的恰恰就是常识。为什么?因为常识它难以定义、难以表达、难以表征;知识更新困难,太依赖领域专家,还有很多异常或难以处理的情况。
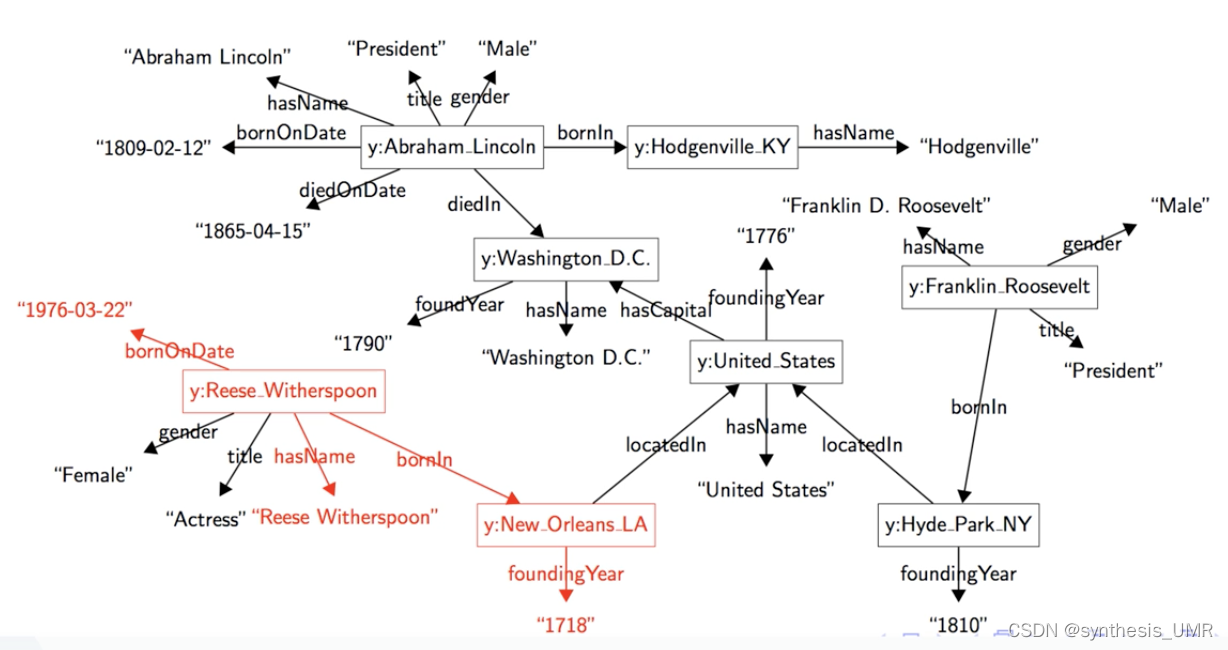
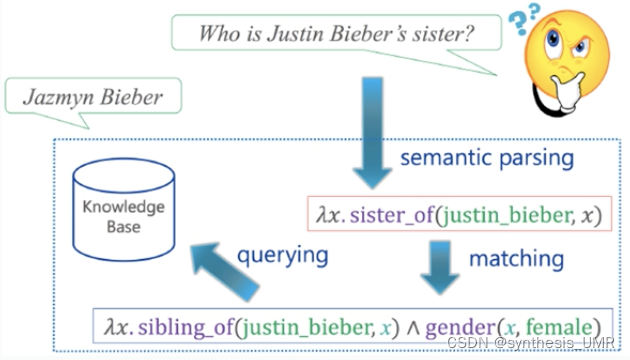
1.3 什么是知识图谱
感谢Google命名。Google知识图谱是它的一个知识库,使用语义检索从多种来源收集信息,以提高Google搜索的质量。是一种表示现实以及认知世界中各种对象之间关联关系的语义网络,可以对现实世界的事物及其相互关系进行形式化描述。(多源异构的知识来源)
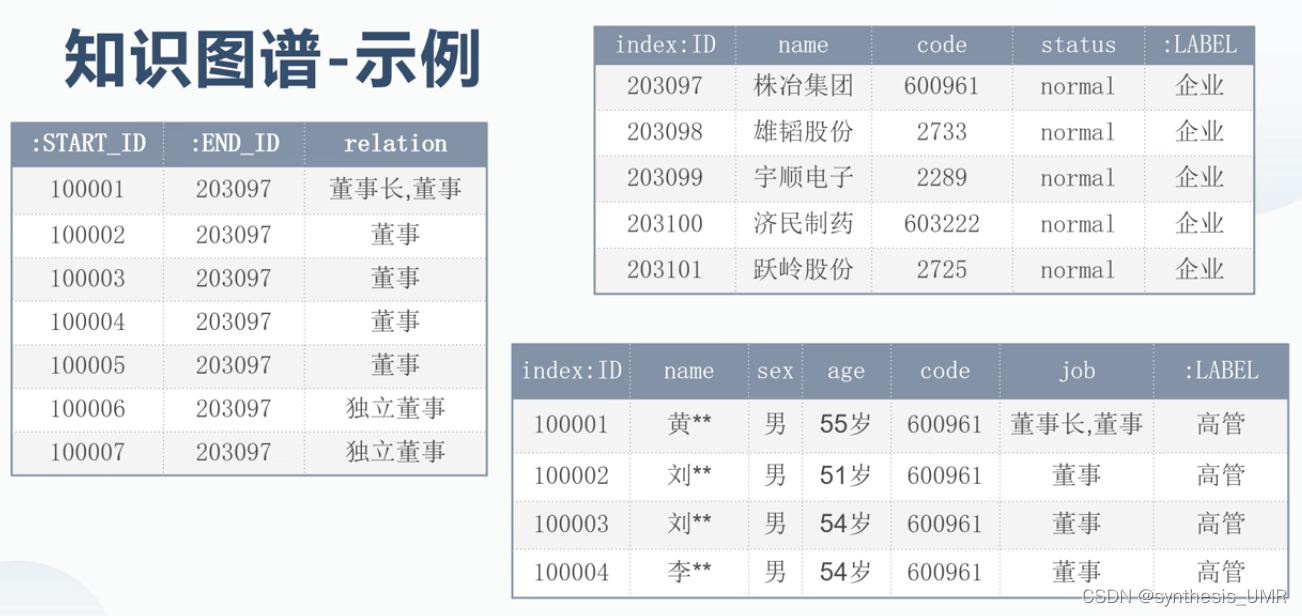
底层的知识图谱就是三元组,两端是实体,中间是关系。工业界认为知识图谱是语义网络,学术界不这样认为。语义网络是符号主义的产物,需要符号描述,知识图谱好像没有。
可以认可的是: 知识图谱是一种用图模型 来描述知识和建模世界万物之间的关联关系的技术方法。由节点和边组成。节点既可以是具体的事物也可以是抽象的概念,边可以用于描述节点的属性,也可以描述节点与节点之间的关系。
知识图谱:结构化存储人类知识的数据库。
基本组成:实体-关系-实体
将具象的事物和抽象的概念表现为实体、实体间的关系,构建成巨大的知识网络。
1.4 知识图谱的价值
人工智能的三要素:计算力(GPU CPU FPGA etc)、算法(深度学习、机器学习、专业领域传统算法)、数据(结构化、标定、数据量、分布均匀、特定应用场景)
深度学习算法:以人工神经网络ANN为代表的深度学习算法成为了人工智能应用落地的核心引擎。
深度学习的缺陷:深度学习可以模仿人类的视觉等感知能力,但想要真正实现类人智能,机器需要掌握大量常识性知识,用人的思维模式和知识结构来进行语言理解、视觉场景解析和决策分析。
需要引入人工智能时代的机器智脑:知识图谱。
现有的应用:基于知识图谱的语义检索系统
传统检索基于关键词的搜索返回网页,基于知识图谱的搜索引擎根据结构化的实体知识,给用户提供更有条理的信息,探索更完善的知识体系。(搜索居里夫人,关联展示同时代的其他物理学家化学家)
1.5 小结
知识就是一种精炼的数据,精炼的数据获取后通过知识引擎表示。底层是神经网络和表示学习。可以来进行智能搜索、推荐、语言理解、大数据分析、机器推理等。
本节重点:
1、发展历史
2、知识图谱概念
3、知识图谱应用
4、知识图谱项目
5、知识图谱相关技术
第二章 知识表示
2.1 什么是知识表示
知识是合理的,真实的,被人相信的
知识表示使知识便于用机器处理。他有三种用途:作为编程语言,表示信息及拟人推理,表达信息及拟人行为
2.1.1 作为编程语言
知识表示语言SQL语句啊这类的
2.1.2 表达信息及拟人推理
智能是显性(人可以读的)信息(符号人工智能)上的推理(与人类似的思考过程)
这个主要是通过符号进行的,而下一个主要是从连接主义
我们看下面这个例子,左边是非结构化语言,右边是结构化语言描述
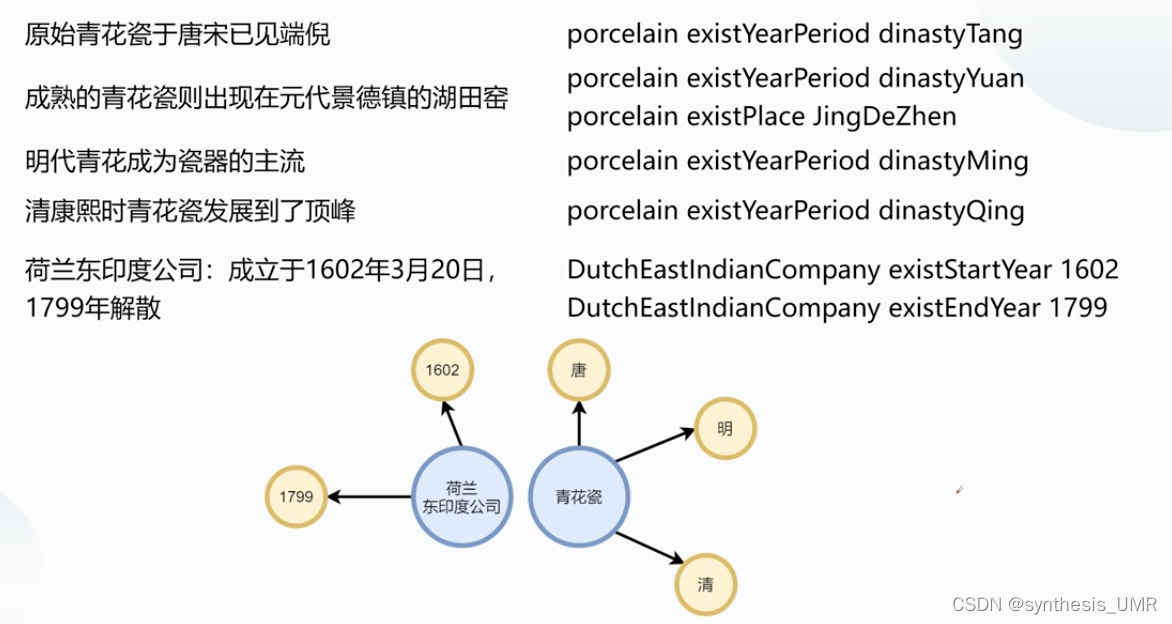

2.1.3 表达信息及拟人行为
对于信息编码并适合计算出期望结果的编码形式。
我们来看一个地形图的分类问题:

CNN多层卷积后pooling一下然后softmax一下就可以得出结果啦。 人工特征在发展的过程中有闪光的时候,但是深度框架一出来效果太好了以至于整个人工特征就没啥用了。
理性走到了符号主义,经验走到了连接主义。
比如人是怎么样表达知识的?我们举一个高考的例子:

我们适合把常识的已经固定了的知识(历史之类的,像沉船这个事件不适合放入知识图谱)放入知识图谱,然后进行拼接相似度分析,最后通过一个分类任务得出结果。对比上一种那个是集合运算,这种方法是AI算法的特点:不确定优化分析。
接下来看一个比较常见的知识表示形式:机器通过三元组的形式组织知识,使用图论模型,将知识符号化从而让机器理解知识。而另外一种就是向量表示,具体的到2.3 2.4看一下
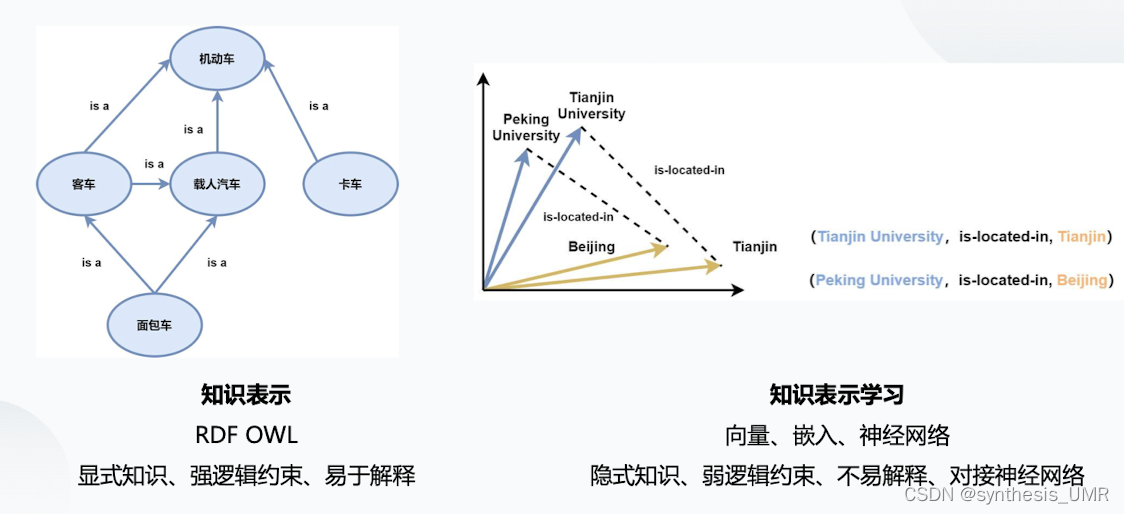
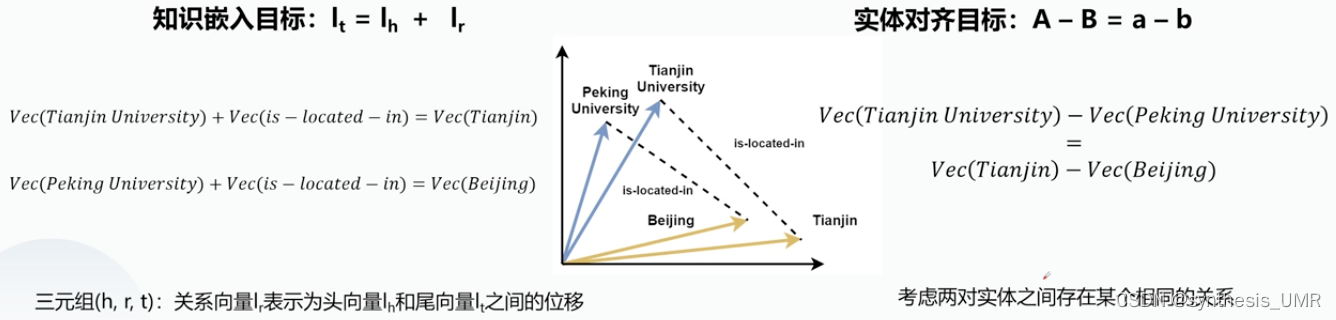
向量表示:头实体,尾实体,关系R。如果关系R是一样的,那么向量之间相减的结果是一样的。在图中的位置并不表示大小关系而是空间映射。
2.2 知识表示方法简介——传统方法
常用的知识表示方式有:
一阶谓词逻辑,产生式规则,框架,语义网络,逻辑程序,缺省逻辑。
2.2.1 一阶逻辑谓词
接近NL,容易接受,逻辑严密,容易实现;但是表达能力有限(如果以某种概率存在的知识无法表示),组合爆炸,效率低。
hasdog(x,y)->haspet(x,y)
可以通过并交补的布尔计算进行操作,霍恩逻辑是一阶逻辑微词的子集
所以:适合人的逻辑表示,不适合计算机
2.2.2 产生式规则
if x then y,cf=[0,1] x前提,y结论or操作,cf置信度
直观自然易于推理,易于模块化,能表示各种知识(确定性,不确定,启发,过程),格式固定高度一致;但是效率不高,组合爆炸,不能表示结构性知识,因此常与框架表示、语义网络结合。
2.2.3 框架系统
人在认识现实的事物中,通过框架模板形式存储信息,根据实际情况修改模板细节,得到对于事物的认识。
一个框架包含若干个槽及其约束条件,每个槽可以包含不同侧面。
槽:描述对象某一属性
侧面:描述槽的某一方面属性
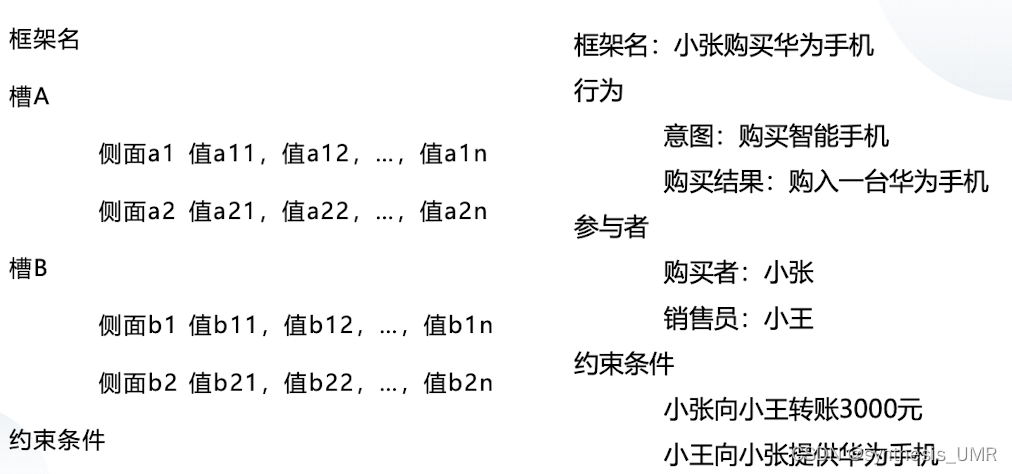
对于知识描述全面完整,知识库质量高,允许数值计算;但是成本很高,对于知识库质量要求非常高,表达不灵活。
2.2.4 语义网络
带标识的有向图,能够表达语义和支持推理,由节点和连接线组成。
节点:带有若干属性,表示事物的状态、概念。
弧:表达节点间的关系、动作等。
语义网络是通过三元组形式组合的:节点1,弧,节点2
接过话的表示事物属性和事物间的语义联系,是根据人类联想记忆模型提出的,直观自然;但是不严格没有公认的表示体系,不能保证正确性及非二义性,处理上复杂度高检索复杂。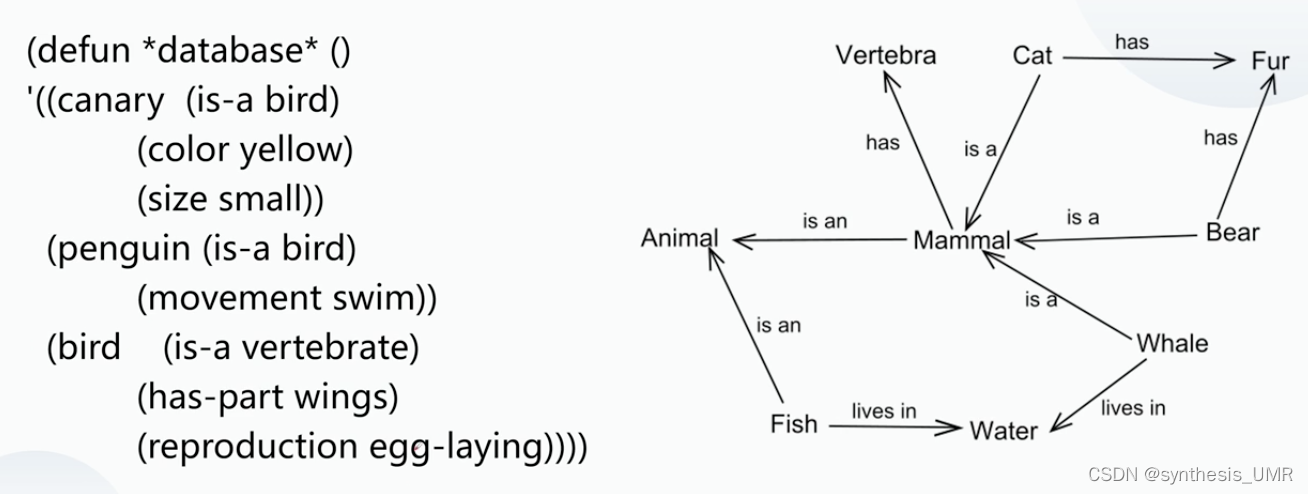
描述很简单但是不够严谨导致一些问题。 要和其他的知识表示方式组合在一起。
2.2.5 小结
传统知识表示以符号表示方法为主,符号表示方法显示表示知识,但来源主要靠专家和人工,所以是非常繁琐的。
2.3 知识图谱的表示方法-符号表示
知识方法:知识图谱
表示方式:RDF、OWL等方法,符号化表示
2.3.1 RDF Resource description framework
RDF:三元组形式主谓宾

这些信息是以一种自底而上的方法进行组织和描述的。
RDFS,包括class subClassOf type Property subPropertyOf Domain Range
早期来说这个对于机器和人都比较友好
使用xml的描述形式,描述一张CD的信息。 使用简单语义框架的rdfs定义类与子类,但是不区分数据属性和对象属性。
rdfs只有浅层的语义信息,我们想要获取深层的语义信息还需要继续改进。这时候我们引入OWL。
2.3.2 OWL Web Ontology Language
OWL:因为RDF和RDFS表达能力非常有限,所以局限在二元常谓词。RDFS局限于子类分层和属性分层,以及属性的定义域和值域限定。OWL可以继续使用RDFS中类和属性的含义,并增加建模原语提供更强大的表达能力。
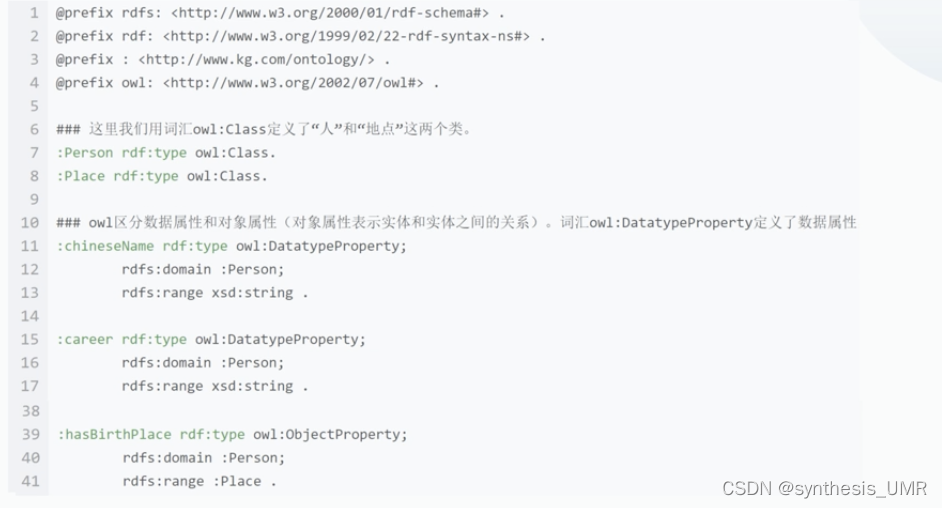
我们看最后这个person和place,OWL可以定义这个Place是Person的出生地,但是RDFs不可以。
表达构件(还是基于符号化的表示形式)这部分了解一下就行:



其实从RDF到RDFs到OWL时从弱语义到强语义的尝试,RDF一开始是没有语义框架的元数据框架,因为推理的需要所以加上了语义,为了和OWL统一,两个语言采用了复杂的模型语义以支持推理。但实际使用中他太复杂了,堆栈技术太大了,所以现在只变成了一种数据描述语言。
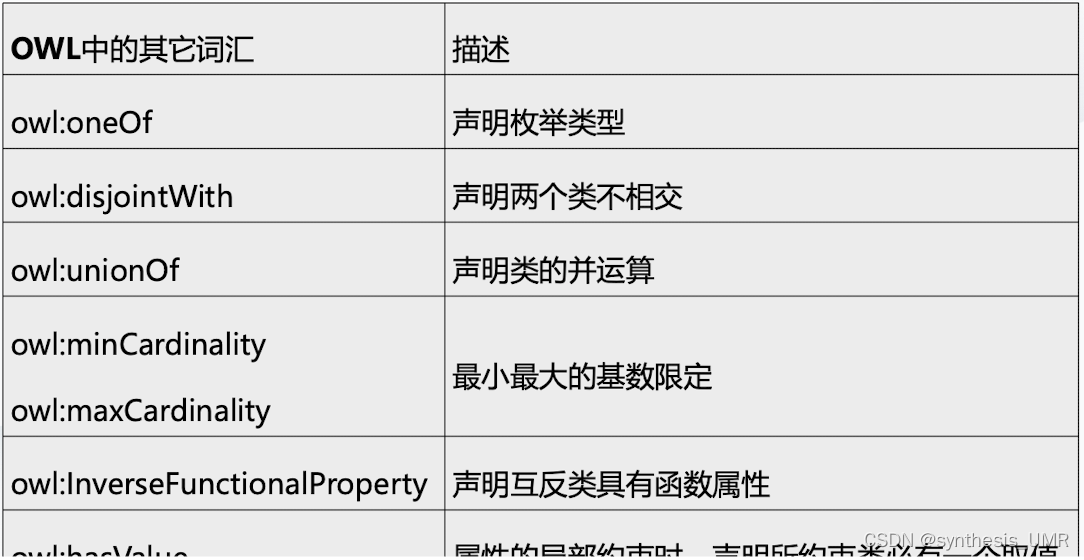
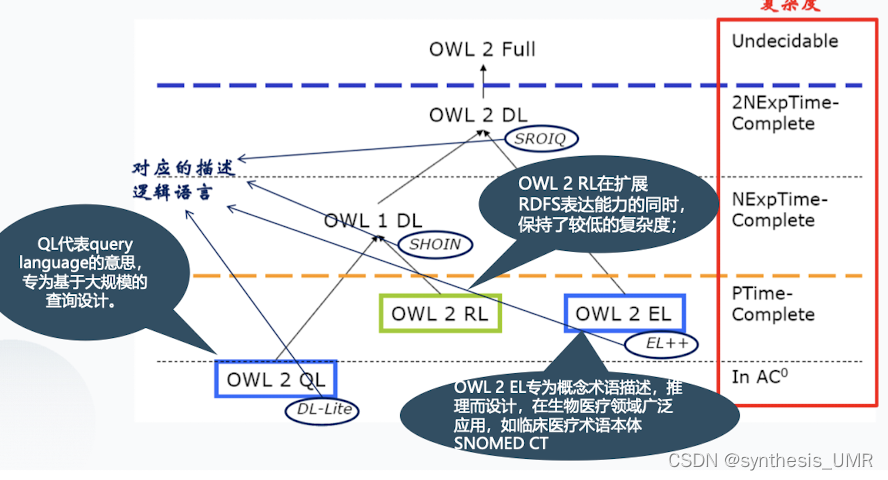
OWL语言族复杂度分析(了解)
OWL每个子语言是前述语义表达构件的一类集合,并有相应的复杂度分析方式
2.4 知识图谱的表示方法-向量表示(重点)
符号表示的问题:难以应用于大规模知识库,无法进行语义计算,扩展困难
引入向量表示,有利于刻画隐含的不明确的知识;有较好的鲁棒性和泛化性。
要表示一个人必须放在各种环境要素中进行表示,所以可以进行分布式的表示方式。
有了这个数据就可以做链路预测任务了。
2.4.1 词的向量表示
词向量表示有两种经典表示法:
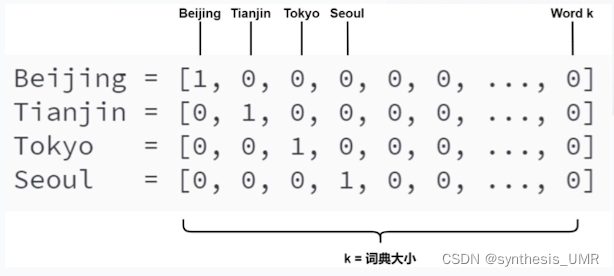
1、One-hot Endcoding(用来给NN做初始向量)
没有语义层的编码,非常稀疏,向量维度=词表大小
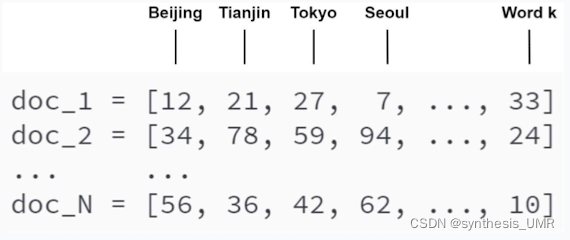
2、Bag-of-word(统计自然语言处理里面常用)
不考虑上下文关系,不关心词出现的顺序,语义信息缺失
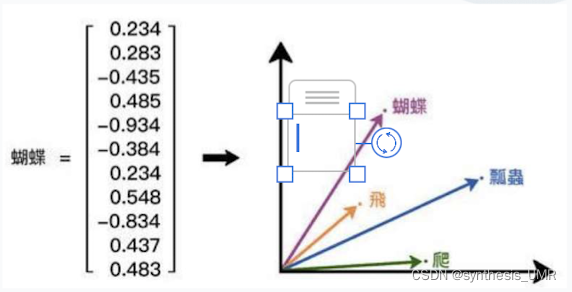
词向量的分布式表示
考虑上下文语义信息,表示语义层面词的相似程度,称为词向量or词嵌入
CBoW模型和Skip-gram模型是常用的Word2Vec模型
2.4.2 知识图谱-向量表示
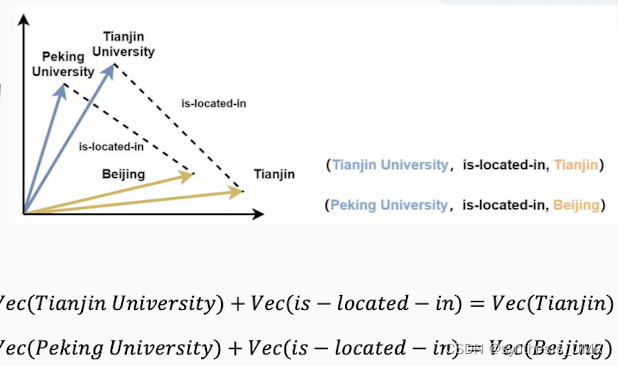
受到了词向量的启发, 将实体和关系映射到连续的向量空间(本质)。包含语义层面的信息;便于机器理解、计算。
称为:知识图谱嵌入、知识图谱的表示学习、知识表示学习等。
上面这种描述关系很宽松,语义关系也不强。如果需要做推理还需要其他的软件支撑
知识表示的学习模型(非常经典):
TranE模型通过机器学习对模型学习(基于翻译的模型)
对于每个事实(head relation tail)将relation看做从head到tail的翻译操作。
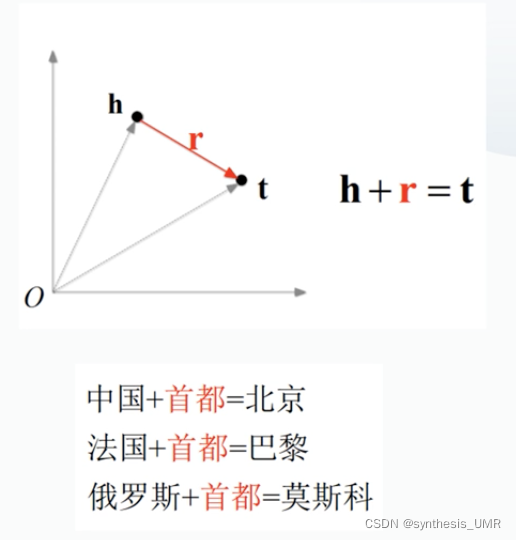

如果三元组(hrt)当hr约等于t时,我们认为三元组成立。d函数是衡量两个向量之间的距离函数。优化的是hlt的向量表示方法。
此外还有线性模型,张量分解模型,距离模型(KL散度啊之类的)等。
2.5 总结
1、知识表示的角色
2、知识图谱的符号表示
RDF RDFs OWL
3、知识图谱的分布式表示
经典算法TranE,了解基于DL的词的表示方式,基于网络表示的node2vector,基于大规模预训练的Berch??
第3章 知识获取
3.1 知识获取导论
3.1.1 知识无处不在
工业飞机制造,人体生理学,建筑设计结构,污水处理,食品药学,软件开发,医学balabala
结构化的知识让知识图谱来表述是非常容易的。
垂直领域的知识图谱构建是非常困难的,需要各种领域专家,还得融合在一起。MINS(info management system)系统的构造因为知识图谱技术变得较容易,成本变得更低。实验级一般是千万级,到了工业界就是亿级的,冷启动也是非常重要的问题。
软件开发的知识:
3.1.2 什么是知识获取
知识获取是人工智能和知识工程系统中,机器如何获取知识的问题。
狭义知识获取:人工移植将知识存储到机器中。系统设计、程序编制、人机交互。
广义知识获取:机器自动or半自动获取知识,直接通过感知从外部环境获取。
3.1.3 知识获取技术体系
知识构建(KA基于IA之上基于数据库进一步处理),信息抽取(命名实体识别,文本模态),数据挖掘(爬虫etc),本体工程。他的交叉领域有NLP IP(image process) DM ML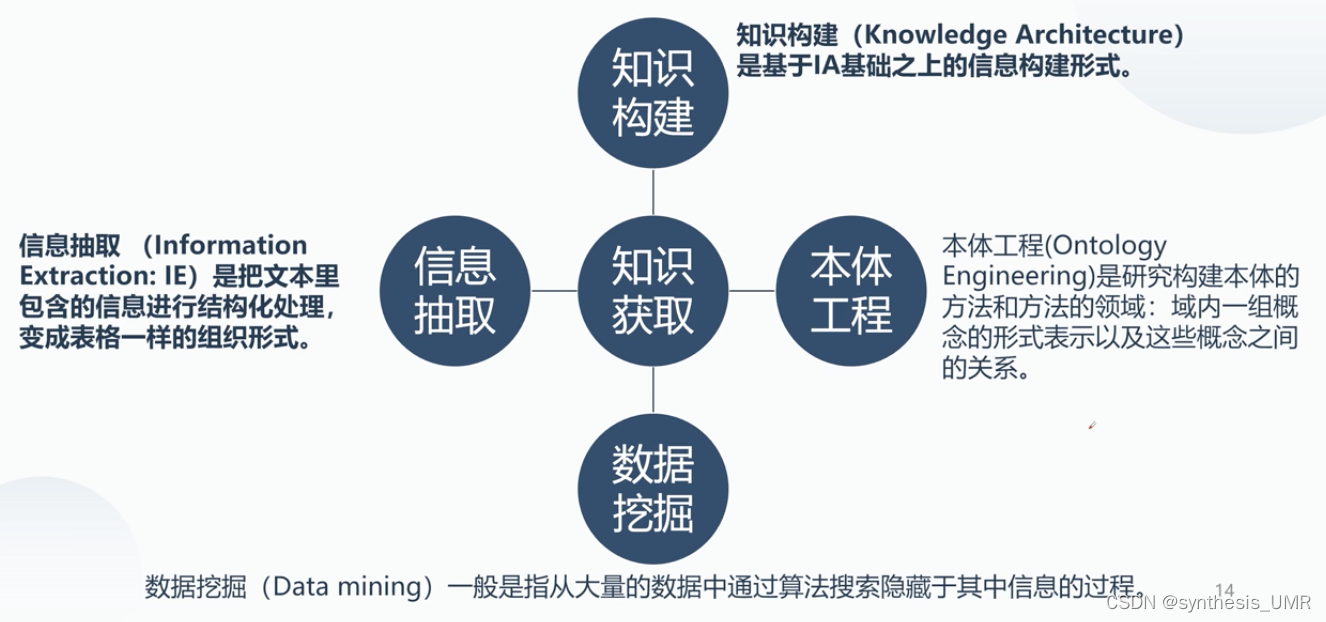
学者型专家一般去做Ontology比较多,实践性(日本武士型??)非常善于实践,只管数据有什么然后构建知识图谱。
3.1.4 知识获取与专家系统

有知识工程师共同把领域内的知识通过知识工程存储到知识库中,和综合数据库一起输入推理机,然后传给人机交互界面把推理的结果传送给用户。
Dendral系统:判定某待定物质的分子结构的专家系统。输入数据,输出物质化学结构。
整个系统功能分为三部分:1、利用专家知识对分子结构进行约束 2、生成结构图 3、利用化学家对于数据的知识,给出第二部分的结果排队。4、最后给出分子结构图
MYCIN系统
控制结构上:1、以病史,化验,症状微数据找出可能导致感染的细菌,并给出每种细菌的可能。
2、给出针对这些细菌的药方。
RIXCON系统
运用计算机系统配置知识根据用户订货选择最合适的系统部件
国内相关的专家系统有中医诊治、小麦施肥、渔场预报等
目前的现代的知识获取一般指 自主学习专家系统(IBM Watson)认知计算,信息分析,NLP机器学习。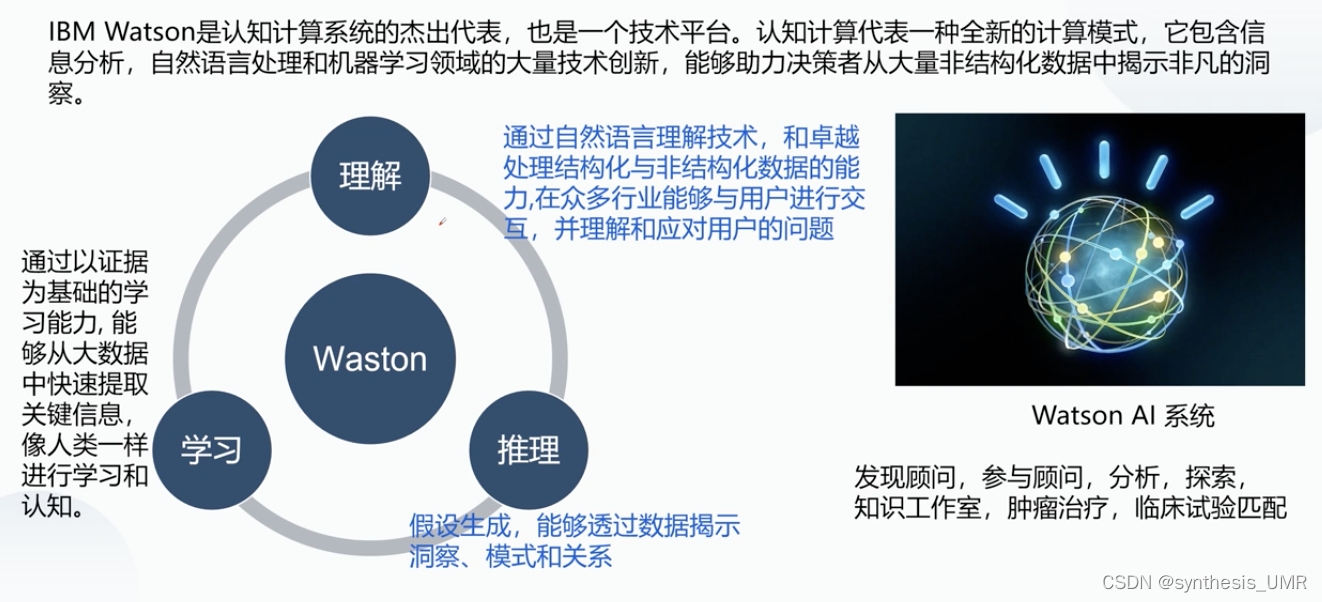
学习能力:通过证据为基础的学习能力,从大数据中快速提取关键信息。
推理能力:假设生成,透过数据解释洞察、模式和关系。
理解能力:NLP处理结构化和非结构化能力
3.1.5 知识获取的基本任务
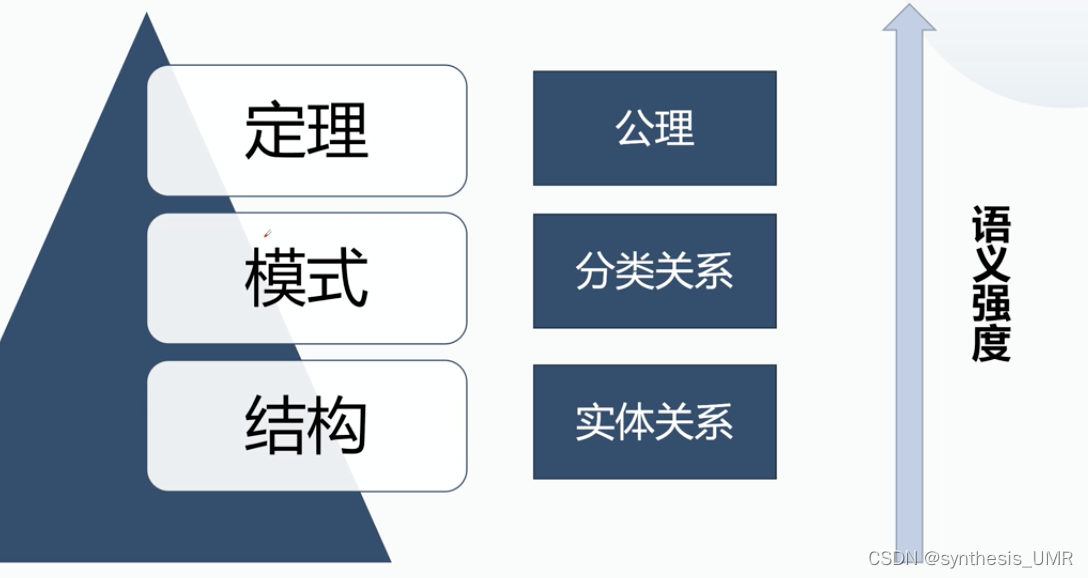
知识获取就是语义提取,把非结构化的知识转化成分层的结构关系。
定理、模式、结构 它们三者的语义强度从弱到强
知识获取的途径:
人工(人工智能系统设计师,知识工程师,专家,用户)移植:分为静态移植or动态移植
静态移植:人工进行知识的编码or编排输入到计算机中,是系统获得先验知识。
动态移植:通过常规人工输入的方法对知识库进行人工改进,使系统获得动态知识。

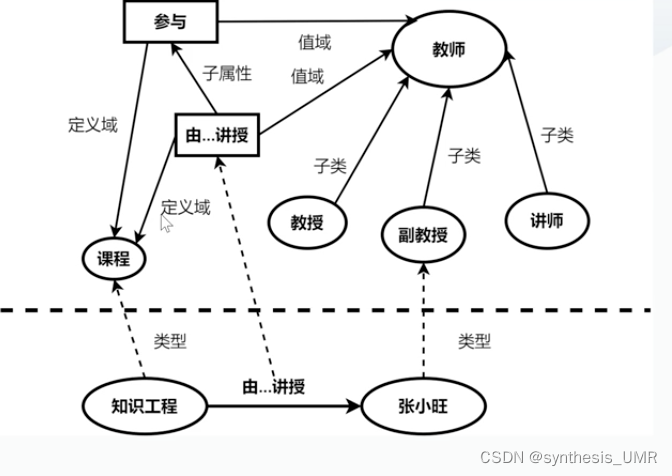
比如说上面这个半结构化的知识,授课教师;课程名称,序号这些都是结构化的知识。课程安排这个信息是半结构化的知识,稍微处理一下就可以转换为结构化的信息。
知识图谱交互式的平台比如protege.stanford.edu/schema.org可以把概念之间的层级描述清楚。cnschema是开放的中文知识图谱schema。
3.2 命名实体识别
现在大量的知识还是通过自然语言描述的,所以需要NER(named entity recognition)
使用NLP算法,对非结构的信息,进行结构化
目的:抽取文本中的原子信息元素(人名,组织,时间,地理etc)
实体抽取实质:实体检测和分类
实体识别的常用方法:
1、基于模板和规则的方法
2、基于序列标注的机器学习方法
3、基于深度学习方法
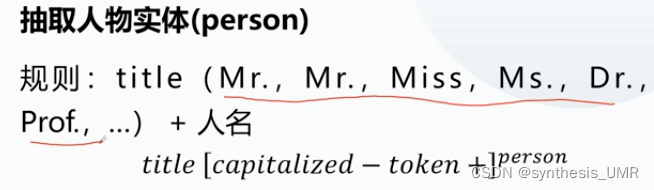
3.2.1 基于模板和规则的方法
本质:人工编写规则模板,处理语料,根据规则线索识别实体。比如下面这两个例子:

3.2.2 基于序列标注的机器学习方法
利用统计机器学习算法,对训练语料标注,结合人工选取特征,进行模型训练。
1、语料标注
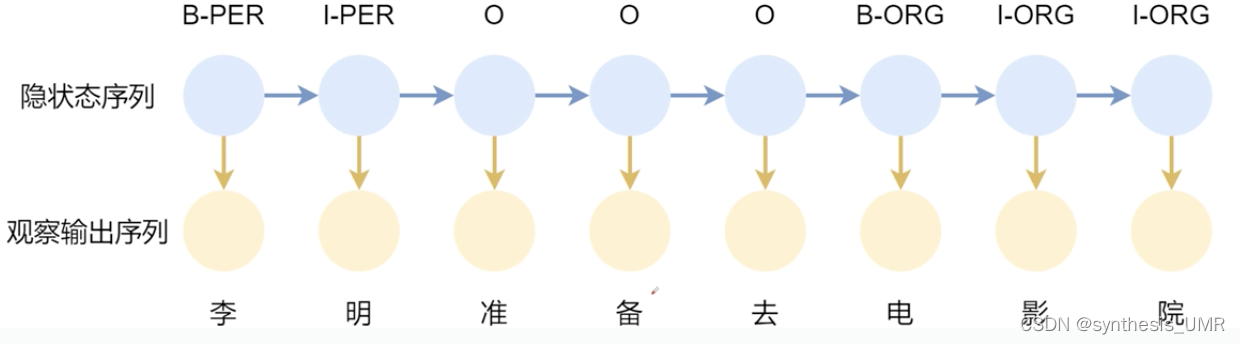
这个标签的策略一般叫做BIO标签策略:


现在BIOEs比较常见,这样可以来标注语料。
2、特征定义
需要人工选取每个词的一组特征作为模型输入,可以包括:1、单词级(是否大写,是否后面.,是否有数字)2、词典级(外部词典预定义的词表、地名,把很晦涩的词比如甲基苯丙胺定义成词典进行检索,或者行政地名这类的,这样处理地名时正确率就大大提高)3、文档级(基于整个语料计算词频,同现词TD/IDF)

3、模型训练
统计学习方法通过序列标注进行实体抽取,常用模型:隐马尔科夫HMM,条件随机场CRF。模型通过解决概率计算,模型参数学习,序列预测三个问题对输入的NL标注。
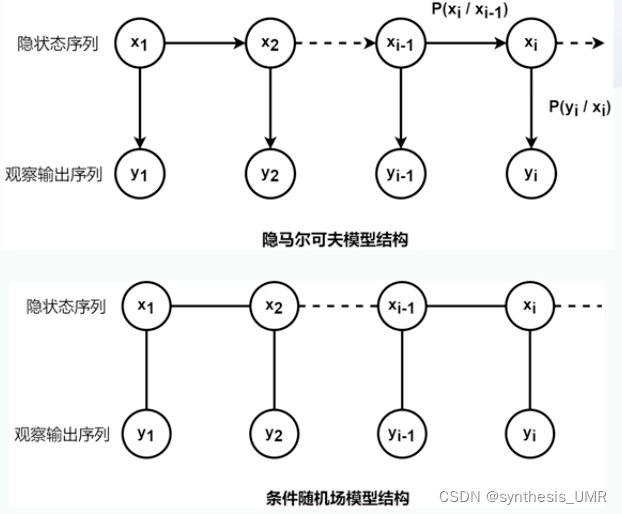
HMM隐马尔科夫模型(见ML大作业)
有向图,动态贝叶斯网络。假设特征间独立性。
两个假设:齐次马尔科夫链假设(t依赖于t-1),观测独立性假设(t时刻观测仅依赖于t时刻隐状态)
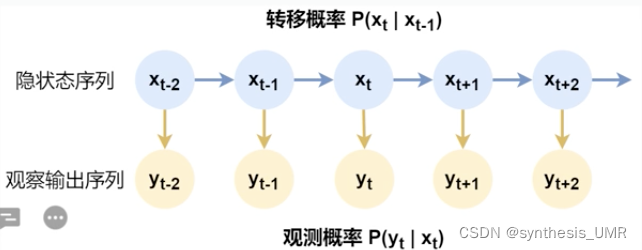
CRF条件随机场模型
随机场是由若干个位置组成的整体,给每一个位置中按照某种分布赋值,全体叫做随机场。
马尔科夫随机场是随机场特例,他假设随机场中某一个未知的赋值之和相邻的位置赋值有关。
条件随机场是马尔科夫随机场的特例,他假设马尔科夫随机场中只有XY两种变量,X是给定的,Y是在给定X条件下的输出。
例如:实体识别任务要求对一句话中的十个词做试题类型标记,这十个词可以从可能实体类型标签中选择,这就形成了一个随机场。若假设某个词的标签只和其相邻的词的标签有关,就形成了马尔科夫随机场。同时由于这个随机场只有两种变量,令 X是词,Y是实体类型标签,那么就形成了一个条件随机场。

那么通过定义特征函数和权重系数转化为一个机器学习问题
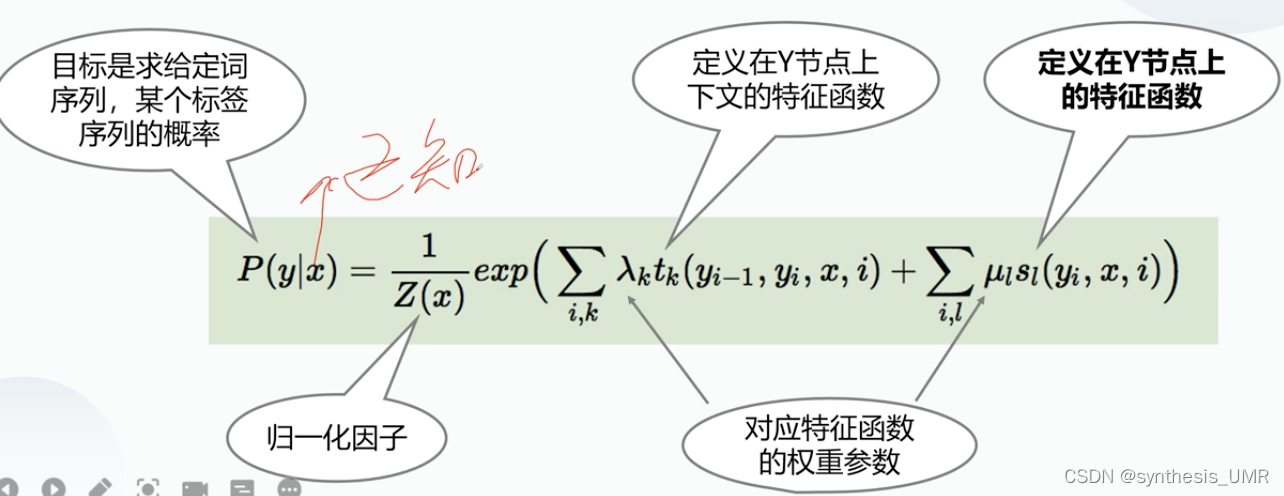
求某个词下标签的概率。
CRF的训练:最大似然函数和SGD就可以了
3.2.3 基于深度学习的方法
双向LSTM-CRF 非常推荐,sequence2sequnence的框架。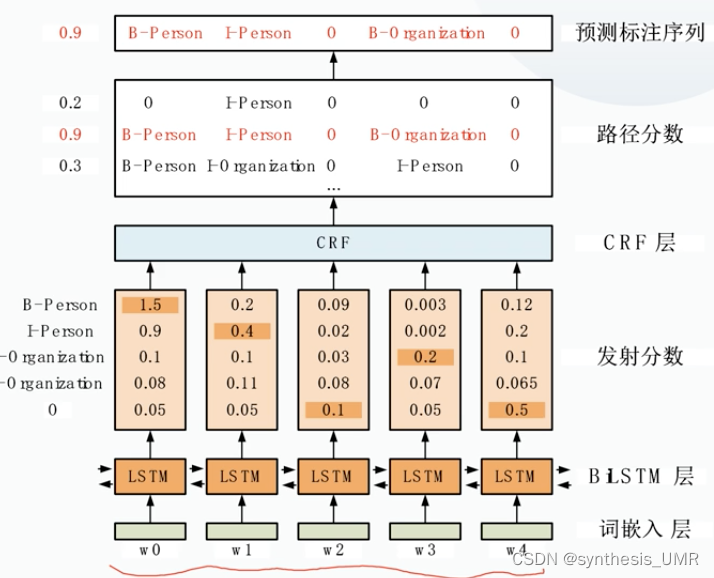
词嵌入层:用词向量表示句子。
发射分数这个啊,看着是概率,但其实不是概率(??老师如此说道,这不就是概率吗)主要是直接用这个概率预测效果不好,甚至还赶不上一个单个CRF,所以再输入CRF后诶嘿,比两个都好。学到了路径上的转移概率(路径分数)
BiLSTM:计算每个单词对应各个预测标签的概率。
CRF层:完成句子中命名实体的序列标注。
最近几年,基于预训练的框架也很多了。基于bert表示上下文的过程中非常强大。bert+任意分类器和bert+crf得出的效果差异不大。
3.3 关系抽取
就是在文本中识别并判定实体之间存在的特定关系

信息抽取是个基本任务,人们更想知道的是eg:比尔盖茨是哪个公司的?他老婆是谁?
三种方法:跟信息抽取一样的3种
3.3.1 基于模板、规则的方法(这个现在还在用)
触发词(位于,坐落于,地处)

模板:依存句法分析(来自统计自然语言处理)生成一个句法树(以动词为起点构建规则,对节点上的词性和边上的依存关系进行限定)
eg:2018年7月26日,华为创始人任正非向5G极化码(Polar码)之父埃尔达尔教授举行颁奖仪式,表彰其对于通信领域做出的贡献。
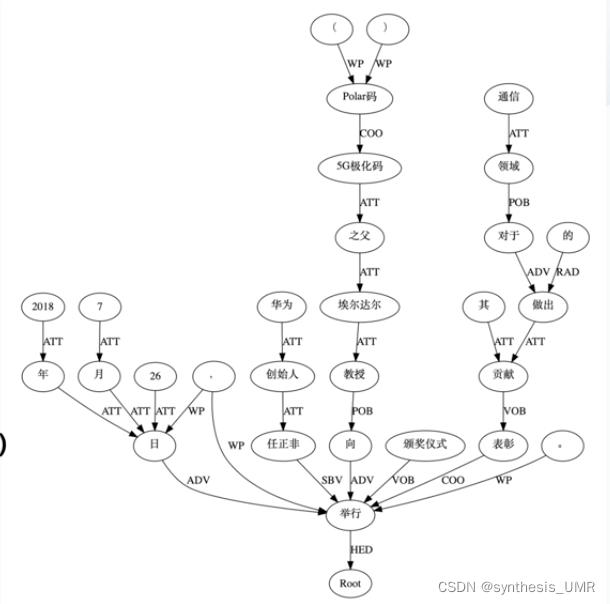
这个方法比较硬性,比如大连中心医院和大连市中心医院,两个抽取出来是不一样的。直接从原文抽取不能变化。
下面我们看一下有什么常用的关系:(SBV和VOB最为常用)
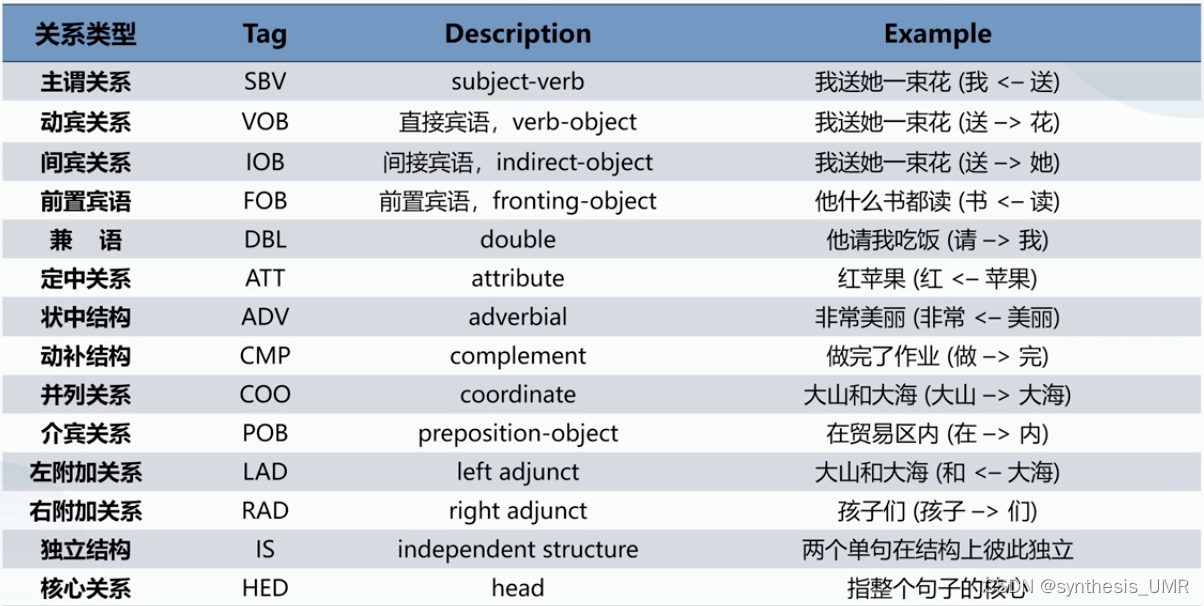
比如I eat apple,前两个词之间eat->I SBV,后两个词eat->apple VOB
总结:

依存分析结果:
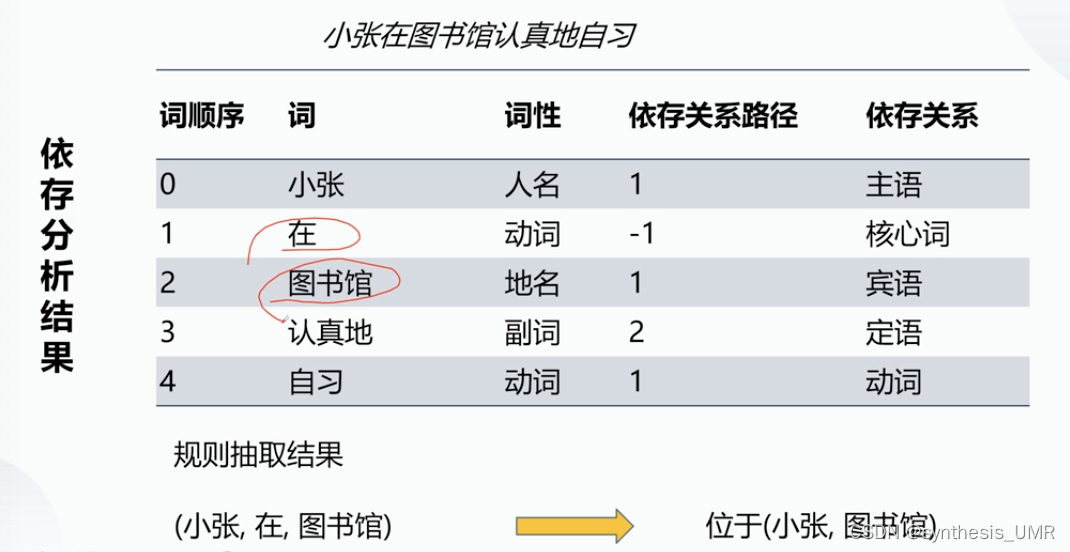
优点:从这个例子看好像效果不错,其实在小规模数据集上是很容易实现的,构建也简单。但是:
缺点:特定领域的模板需要专家,难以维护,可移植性差,规则集合小的时候recall率很低(主要是因为太硬性了,比如"经本院查明"和"经审查"和"经查",你在上海能用的模板放在辽宁,贵州就不行了)
3.3.2 基于传统机器学习的方法(不常用了)
学习过程:
通过SVM等对有量数据的训练语料库进行训练,得到分类模型
预测过程:
实体对送入训练好的关系抽取模型中对于这些候选模型的分类。
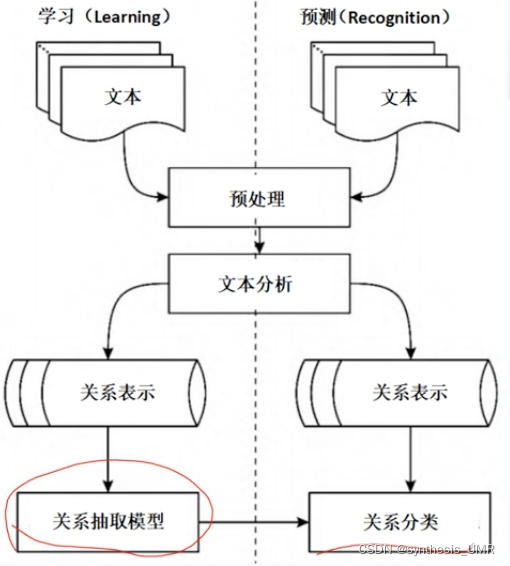
关系表示成向量,然后送入关系抽取模型进行处理。NLP还是很苦难的,主要是因为特征太少信息被压缩的比较厉害。但是也有很多,比如词频啊同化词啊依存关系之类的。
一般我们都是基于特征工程进行关系抽取。
1、基于特征提取的关系抽取方法
核心思想:通过从句子上下文中提取句法和语法等特征信息去构造特征向量,从而利用特征向量的相似度训练实体关系识别模型,比如最大熵ME。
关键:如何获取各种有效的词法、句法、语义特征,并把它们集成起来,不同的特征对于最终系统的性能有不同的影响。
优点:可解释性好
缺点:需要经验和直觉,特征项组合是有限的,无法表示指定的语义关系
2、基于核函数的关系抽取方法
核心思想:将输入空间的数据嵌入到合适的高维特征空间,利用线性分类器在新的特征空间中抽取。
关键:设计出计算两个关系实例相似度的核函数。
特征提取出来都是数值化的表示方式,组合成向量后要做的最多的操作就是计算向量内积。我们通过映射处理可以在高维空间通过线性分类器将他们分开。
优点:处理高维特征空间问题计算代价低,求解凸优化问题,核矩阵展现输入在空间中的相对位置
缺点:组合复杂,处理速度慢
3.3.3 基于深度学习的方法
基于特征的方法需要人工设计,这类方法适用于标注数量少,精度高,人工能胜任的情况。
基于核函数的方法能够从字符串或句法树中自动抽取大量特征,始终是在两段文本在子串or子树上比较相似度,没有进行语义比较。
两种方法都要做词性标注和句法分析,用于特征抽取或核函数计算,典型的pipeline。会把POS和句法分析的 错误传递到后续任务中并不断放大。
深度学习端到端的抽取方式可以大幅减少特征工程,并减少对于词性标注等预处理模块的依赖,称为当前关系抽取技术的主流路线。
一般而言大家认为可用的阈值是80%,传统的ML做得好的一般80-90,但是DL非常好。
1、基于CNN的方法
主要三层:词表示层,特征提取层,输出层
主要关注特征提取层:
词汇级别特征:实体本身的语义特征
句子级别特征:通过 CNN网络挖掘句子级别的文本特征,不需要人工设计特征。
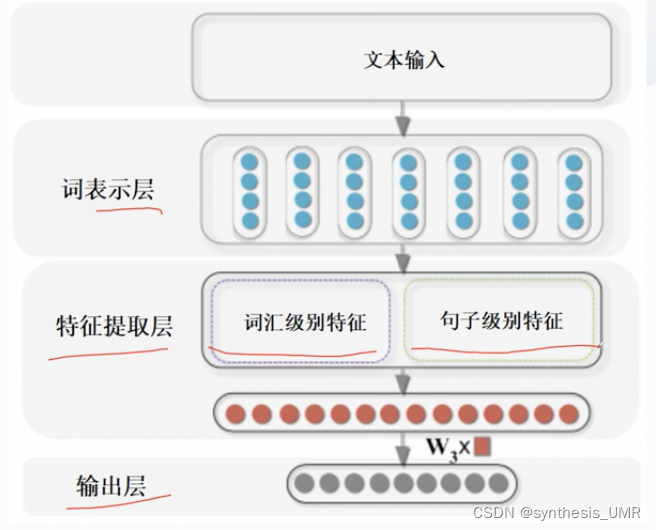
1.1 词汇级别的特征:利用词向量信息作为词汇级特征 ,早期Word2Vec,one-hot后来bert啊这些。

比如说上面这个例子里面我们需要判断haft和axe这两个entity之间的关系,所以首先我们需要研究两者的词向量表示(one-hot ,词带都可以,也可以用WordNet(??)上位词特征指出e1和e2同属于哪一个上位名词 狗-动物/宠物)
1.2 句子级别特征
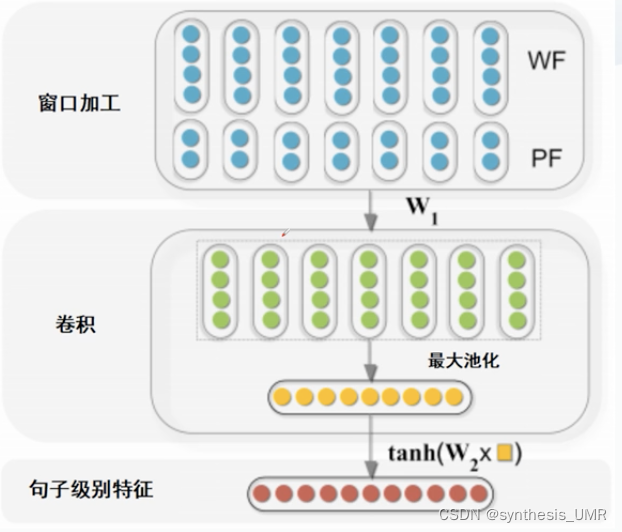
WF:word features,使用滑动窗口来捕获某一词语的局部上下文信息。一般为1-3
PF:position feature,当前词相对于两个标记名词的距离
2、基于RNN的关系抽取方法
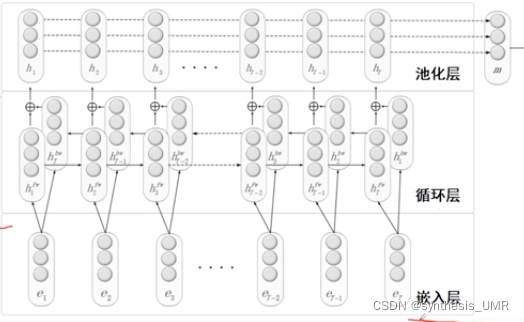
可以用LSTM双向LSTM替代
3、基于图神经网络GNN的关系抽取方法
GCN图卷积神经网络是现在常见的做法
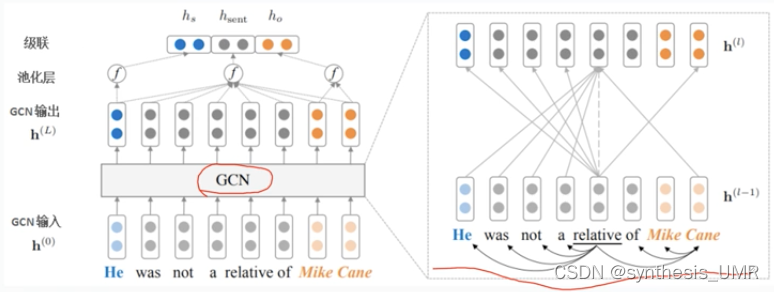
3.3.4 关系抽取小结
早期关系抽取方法主要是基于规则的模式匹配,对于跨领域的可移植性差,人工标注成本高,召回率低,需要专家设计特征。
后来研究者专项ML,可以分为有监督,半监督,无监督,面向开放域,远程监督(利用外部资源)。
发展示意图如下:
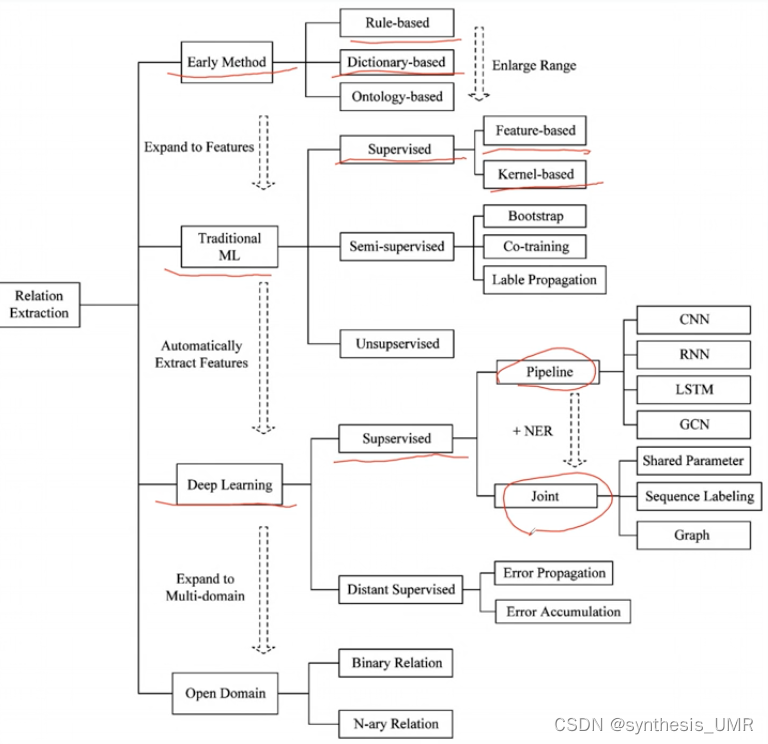
早期:基于规则词典
传统ML:有监督用的最多,基于特征、核函数;半监督(了解);无监督
深度学习:刚开始需要海量的标注样本,可解释性也差。早期Pipeline+NER,现在用Joint更好,提取实体关系三元组。远程监督利用了Web资源(Web知识库)。还有个self supervision自监督没写上来。
基于开放域:二元关系(有、无关系),多元关系
比如我们现在要构建一个大连理工大学的知识图谱,我们要什么?考虑一下。(结构化的信息在数据库中最多,半结构化的信息在Web中很多)
3.4 知识融合
来自于不同知识源的多元异构的知识,有些是冗余的。因为很多数据集包含相似或者相同的本体或者事实。(三元组)
3.4.1 知识图谱异构
我们说很多知识图谱的信息都是异构的,表现在以下方面:
语言异构:
语法(json xml rdf owl)
逻辑(a not b, b not a, disjointWith)
表达能力(owl:Thing)
模型异构:
概念化不匹配(动物划分为哺乳动物or鸟;划分为食肉食草)
解释不匹配
所以知识融合的目标:合并多个知识图谱,将来自多个数据集的关于同一实体or概念的描述信息融合。它包含了两个层次:
本体层匹配:等价类,子类;等价属性,子属性
实例层匹配:实例等价(把概念具象化了以后就是实例)

比如上图:高等院校、学校就是本体层级,校徽和校门就是实例匹配。
3.4.2 知识融合方法
1、本体匹配(Ontology Matching)
发现等价类、相似类、属性或者关系(都是在抽象的概念层级的)
2、实体对齐(Entity Alignment)
发现指向相同真实对象的不同实例
基本技术流程:
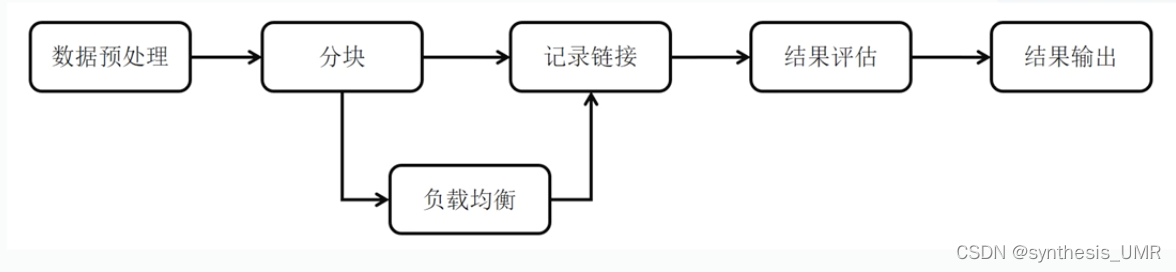
数据预处理:尤其是文本有很多方法,词频啊分词啊之类的。解决数据的准确性,一致性问题
分块:把潜在可能会匹配的记录作为候选项,然后进行匹配。
记录连接: 对应实体连接,实体连接是实体对齐的结果。记录连接是实体对齐的核心,连接两个对齐实体。
负载均衡是在海量数据处理的时候使用的分布式数据处理框架MapReduce。
结果评估:使用随机采样的方式,因为数据量太多了。还可以看下游任务处理情况。
3.4.3 本体匹配OM
定义本体:一个概念体系的显式的形式化规范
一个本体形式化刻画了一个领域,一个典型的本体由有限个术语及其他们之间的关系组成。
术语:给定论域(对应领域)中重要的概念(对象的类)
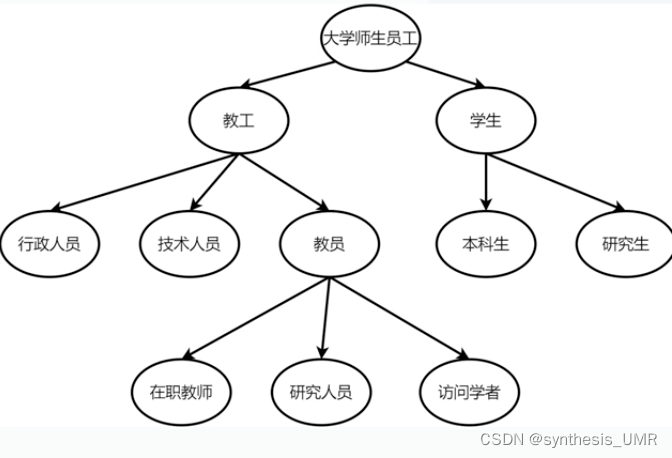
例如上面这个,以一个大学为论域,教工、学生、课程和教室等是一系列重要概念。
定义有了,然后我们在概念层进行融合,我们通过数学语言表述一下本体匹配这个问题 :

通过s相似度的度量来衡量源本体和目标本体之间概念的相似度。
然后我们要决定如何计算这个属性相似度:
编辑距离:Levenstein Distance, Wagner and Fisher Distance, Edit Distance with Affine Gaps
集合相似度计算:Jaccard相似系数,Dice系数

基于向量的相似度计算:Cosine相似度!TF-IDF相似度
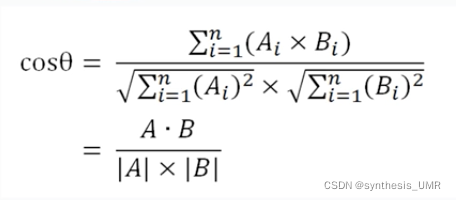
这些属性相似度在实际运用中其实效果一般 ,我们还有一种结构相似性计算的手段可以用
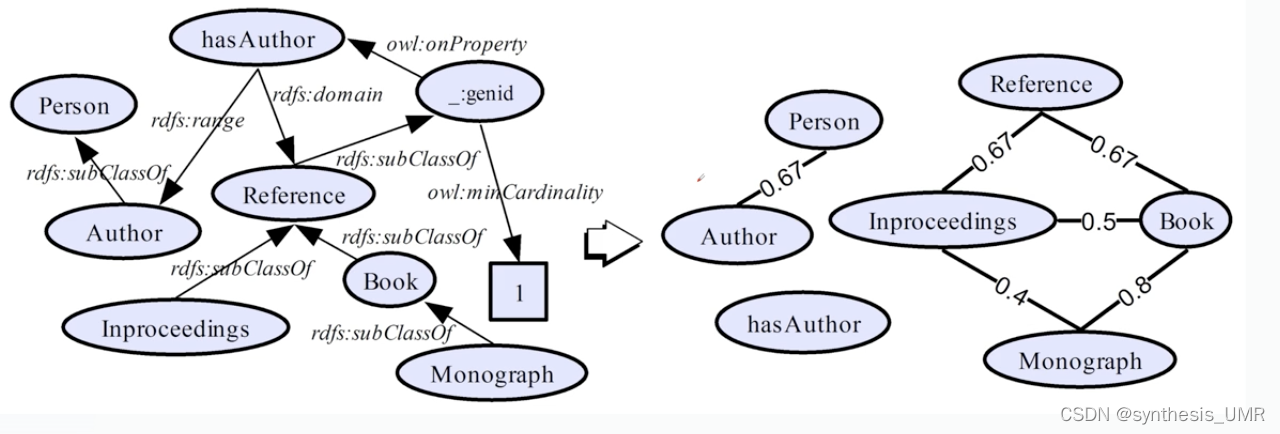
我们说类彼此之间有着层次关系,我们说如果是图or树的方式组织,那么在这个结构上每个节点是否有公共父类?邻居?子类?路径是否有相似性?子类是否有相似性?
比如这个book monograph和proceeding是reference的子类,计算出来book和monograph的相似度最高0.8。
那么以现在有没有现成的本体匹配的工具呢?Falcon-AO就是。
Falcon-AO是一个自动的本体匹配系统,已经成为RDFs和OWK所表达的Web本体匹配的一种流行选择,Java写的。
现在人们更常用的还是实体对齐的方法
3.4.4 实体对齐(实例层融合)EA
目标:融合指称相同现实对象的不同实例
知识工程领域:实例(知识处理角度)
数据库:记录(知识存储角度)
自然语言处理:实体(技术角度)
上面这三种叫法其实是同一种东西
有了定义我们还是要进行相似度计算的方式:
1、聚类算法
层次聚类,相关性聚类,Canopy+K-means算法(速度是不错的,效果想好还是得有监督)

2、表示学习
复习知识嵌入: 将知识图谱中的实体和关系都映射低维稠密的空间向量。直接用数学表达式计算各个实体之间相似度。这类方法不依赖任何文本信息,获取到的都是数据深度特征。
比如:我吃不上饭了 我吃不下饭了 这两句话相似度很高,词频也一致,但是语义完全不同。这时候考虑特征的话就要考虑更多语境的信息。现在大家都很喜欢大规模预训练模型。
实体对齐的定义和目标我们都了解了,下面介绍一下实体对齐的工具:Dedupe
Dedupe是一个使用ML对结构化数据快速执行模糊匹配,重复数据删除和实体对齐的Python库。
优点:主动学习训练正负样本,降低用户标注量
缺点L要求输入数据集中记录的属性(实体间的关系)数量很少,10-20个
还有一个Silk系统
Silk是一个用于集成异构数据源的开源框架,可以生成不同源相关数据项间连接;可以使用SIlk将RDF连接从数据源上设置为Web其他的数据。还可以将数据转化应用于结构化数据源。
他有Silk-LSL语言和图形化界面Silk Workbench给用户使用。
3.4.5 小结
专家系统发展简史
命名实体识别NER常用方法
关系抽取RE的常用方法
知识融合的方式,方法,常见工具
第四章 知识存储导论
前面几张都是算法相关的,这一章讲存储(知识存进磁盘中,以某种数据结构模式)
主要分为集中式存储和分布式存储。
集中式知识存储
数据集中在中心节点,所有功能交给中心节点处理。增删改查操作。人才培养成本高,昂贵,单点问题严重。
分布式知识存储
数据分散在不同设备上,关系对等。易于扩展,可靠性高,分担存储负荷。它具有以下性质
一致性:服务器越多,出错概率越高
可用性:需要多台服务器同时工作
分区容错性:通过网络连接,额外增加通讯成本
4.1 RDF语法
URIs(U):统一资源标识符
Literal(L):文字
Blank nodes(B):空点(变量)
RDF三元组:

spo是主谓宾,或者主 属性 值,id是使用uri的形式表述的
Turtle规范:Terse简要 RDF Triple Language
实体or关系URIs,文字(值)"Literals",三元组spo主谓宾

上图里面有三个三元组,都是通过uri记录的。这个有点儿长,还有简写形式

用prefix规定一下前缀,其实就是起别名define。我们进一步可以发现,有两个主语是一样的,那可以进一步进行主语分组简写

注意上面使用了分号来表示共享,这个部分要注意。
因为这种描述方式是为了描述网络信息,所以叫做Linked-Data
RDF还有XML语法格式

并没有实质上的数据变化,只是增加了结束符而已。
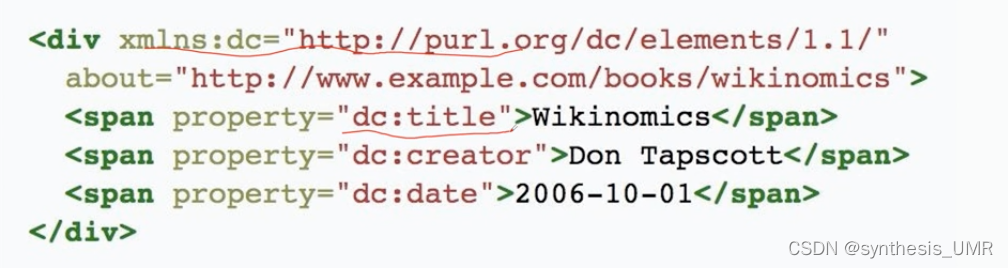
RDFa:RDF in Attributes
我们可以把RDF嵌入到html中,也可以用来描述三元组

JSON-LD: Javascript Object Notation for LinkedData
使用名称和值对的集合,值的有序列表

4.2 关系型数据库简介
我们可以使用各种方式来描述知识,但是想要快速高效滴调用数据,就必须使用数据库系统。
4.2.1 概念模型
用途:数据库设计人员和用户之间交流的语言。他需要有较强的语义表达能力,能清晰方便地表示知识,便于理解。
那么接下来我们就来学习这种语言,首先明确几个基本概念
信息世界中的基本概念:实体entity(人事物概念)属性attribute(一个实体可以有多个属性)码key(唯一标识实体的属性集)域domain(属性的取值范围)
实体型(实体+属性的集合刻画同类实体)实体集(同一类型实体的集合)联系(反映实体内部的联系和实体间联系)
联系可以进一步细分:
实体内部联系通常指实体和各个属性之间的联系
实体之间联系指不同实体集之间的联系
实体之间的联系还有其他的关系:1对1 1对n m对n
一对一联系:一个班级中只有一个班长 一个班长只对应一个班级
一对多的联系:一个班级有多个学生,一个学生只能在一个班中
多对多:一个学生学多门课程,一门课程有多个学生选修
我们说两个以上的实体型之间也有这样的联系(简单来说就是动词下面对应不同的实体分支)
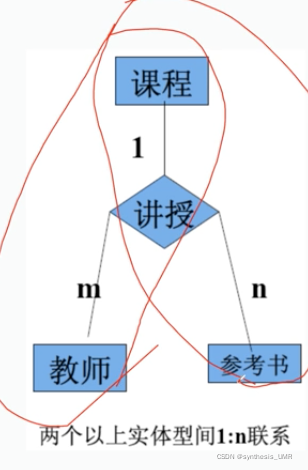
1、课程、教师、参考书三个实体型的1:n关系:
一门课程可以有若干个教师讲授,使用若干本参考书
每一个教师只讲授一门课程
每一本参考书只供一门课程使用
2、多个实体型之间的一对一关系(这个比较简单)
3、两个以上实体型间的多对多联系
供应商、项目、零件三个实体型:
一个供应商可以给多个项目供给多个零件
每个项目可以使用不同供应商的零件
每个零件可以由不同供应商供给
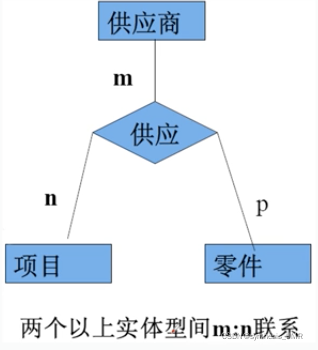
关系我们现在已经掌握了,接下来我们学习使用图模型表示概念模型 E-R图
实体型:矩形表示
属性:椭圆表示,使用无向边和实体连接
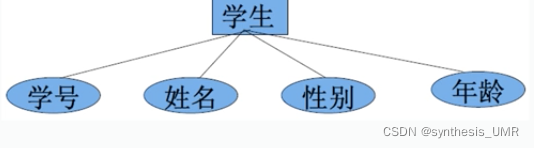
联系:使用菱形表示,里面写上联系名,并标注上1对1还是另外两种
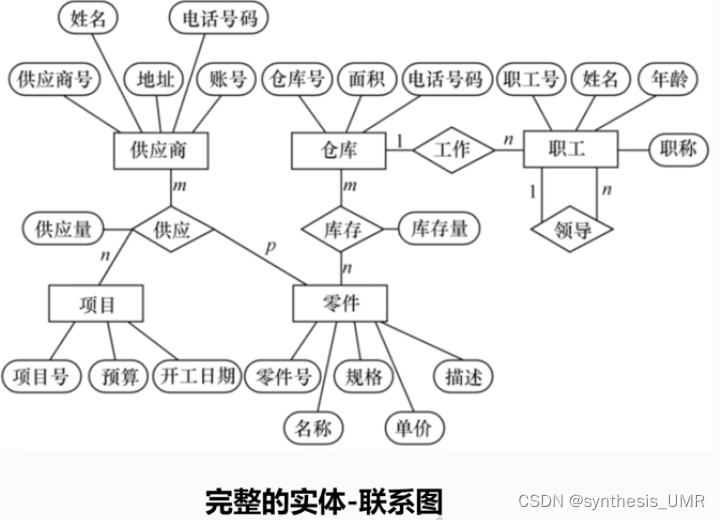
我们刚才忽略了一个重要的问题:联系本身也是一种实体型,也可以有属性。我们可以使用无向边将两者联系起来。

最后我们用E-R图来表示某个工厂物资管理的概念模型,自己尝试一下能不能画出来吧~


4.2.2 关系模型
关系数据库系统采用关系模型作为数据的组织方式
从用户角度,使用二维图数据结构来描述这种关系。

关系relation :对应通常说的一张表Table
元组tuple:表中一行就是一个元组
属性Attribute:一列就是一个属性,每个属性起一个名称就是属性名
主码Key:表中某个属性组,可以为已确定一个元组(非常重要,就是学号啦)
域Domain:值域
分量:元组中一个属性值
关系模式:对于关系的表述


我们要注意关系之间的联系:比如说学生和系之间通过系号进行沟通
4.2.3 关系的完整性
1、关系的三类完整性约束
包括实体、参照、用户定义三类
实体和参照完整性必须满足完整性约束条件,称为关系的两个不变性,应该由关系系统自动支持。
用户定义的完整性体现了具体领域中的语义约束。
2、实体完整性
如果属性A是基本关系R的主属性,那么A不能取空值。
SAP(Supervisior,Speciality,Postgraduate)Postgraduate是主码不能取空值。
现实世界中的实体具有某种唯一性的标识,所以关系模型中以主码作为唯一性标识。
3、参照完整性
关系间引用,其实就是一定要规定上面说到过的学生实体和专业实体的沟通桥梁(专业号)

学生关系引用了专业关系的主码"专业号",这个是一对多关系,还有关系间的多对多关系:

学号、课程号两个主码来规定。
关系内也会有一对多关系,比如下面这个例子:
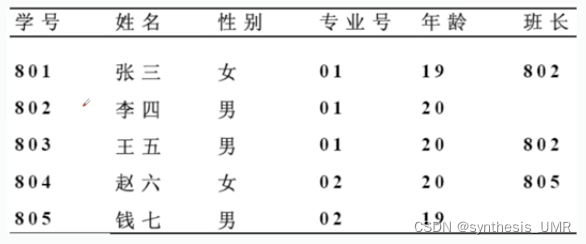
学号是主码,班长是外码,它引用了本关系的学号。这样维护起来更容易,而不是在旁边标注班长的名字(如果名字写错了不需要全改)
这里我们引入了外码,(F是大关系的属性,是小关系的码,则称F是大关系的外码)。外码R叫参照关系,S是被参照关系or目标关系。
我们规定这个参照值必须是有具体指向的,这个叫做参照完整性规则。比如说这个专业号,他只能取空值(表示该学生还没有分配专业)或者实际存在的值01or02
4、用户定义的完整性

比如这个学分,就是用户自定义的约束。
4.3 RDF关系存储
(这一部分需要4.2的知识,请优先阅读4.2)
我们查询不同的关系需要涉及到不同的表,这是一个典型的多表联合查询问题。
用关系型数据库存放RDF三元组就是三列,对应主谓宾。多跳查询时会产生自连接操作
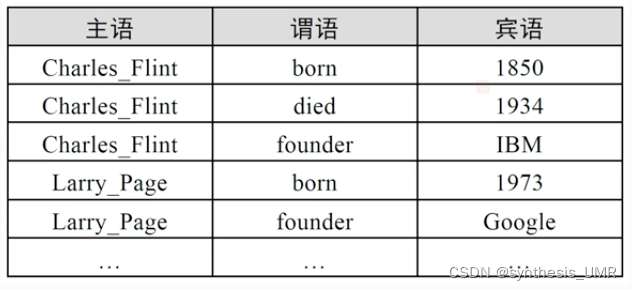
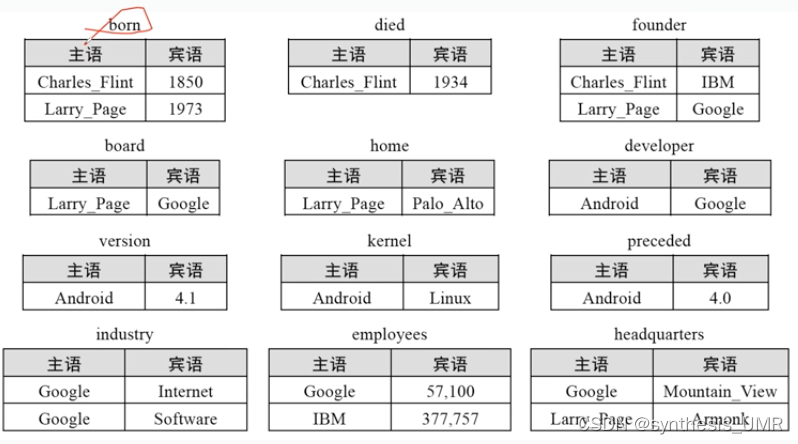
eg:查找一个生于1850年死于1934年且创建过公司的人 
from t as t1这段语句是一种虚拟映射关系,映射成了3个表。现在我们把上面这个表撑开:

以entity为中心,表格列是谓语,属性值是宾语,这样就是以person为主体的。再举两个例子:以操作系统为中心的和以公司为中心的:
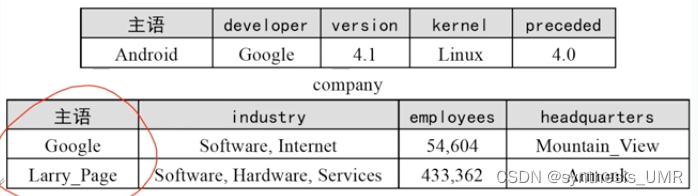
这种组织形式更直观但是很容易出现空值,这种划分方式叫做水平划分:
4.3.1 水平划分
水平划分方法使用N+1列数据表存储RDF数据集(N是数据集中不同谓词的数目)基于主语对RDF数据集划分,每行记录存储知识图谱的一个主语的所有谓语和宾语,不存在对应宾语时用空值。
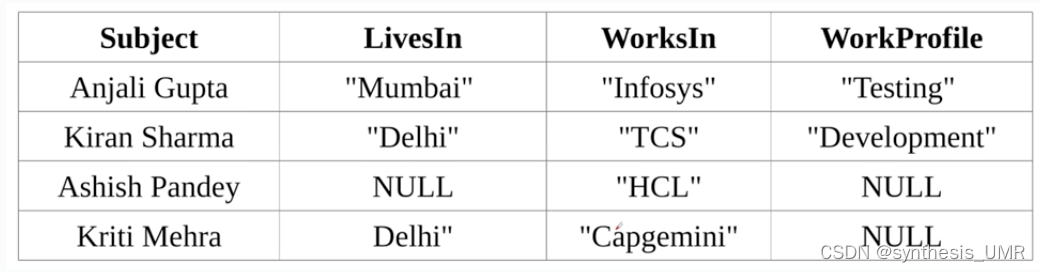
Sempala系统是水平划分方法的典型代表,对于有多值属性的主语则在紧接着下一行列出,从而简化了SPARQL到SQL的转换过程。
优势:有利于星型SAPRQL查询处理;Join减少了可重用RDBMS功能
局限:数据表中可能存在大量空值,存储和查询额外空值的开销。列数等于RDF数据集中不同谓语数量,可能超过列数目上限。
对应水平划分也会有垂直划分,它是通过谓语来进行划分的,有多少个谓语就会有多少个2列表。多个谓语查询会导致多表链接问题。
4.3.2 垂直划分
垂直划分虽然解决了空值问题,但是会导致表超多,对于某个主语进行查询涉及到多个谓语需要查找多个表。
他的代表系统是S2RDF系统,提出了扩展垂直划分,通过左连接形式进行一种《半链接计算》从而在Join执行时减少不必要的输入。其实是一种空间换时间的方式。
优点:解决空值,多值问题(存储为连续的行),主语列排序可以使用归并排序连接快速join
缺点:数量大难维护,对于n个表,需要n-1次join
4.4 RDF的图存储
关系型数据库的局限性:
虽然可以存储吧,但是语义关系没有显性表达带来的关联查询与计算的复杂性。知识图谱需要更加丰富的语义表达和关系推理能力。而且关系型数据库通过join,非常慢。图非常快。
关系模型用接近自然语言模式描述世界原则,让概念化,高度关联的世界模型和数据的物理存储间出现失调。
图模型优点:
自然表达,便于扩展,关联查询高效,多跳优化(查询性能好)。

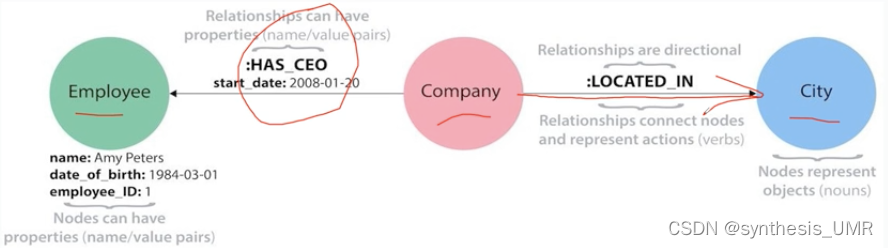
我们主要介绍:属性图。
由边和顶点组成,节点具有一组属性,每个属性是一个键值对,边有一个Type和方向。边同样也可以具有属性。
属性图数据库:Neo4J 一种声明式语言
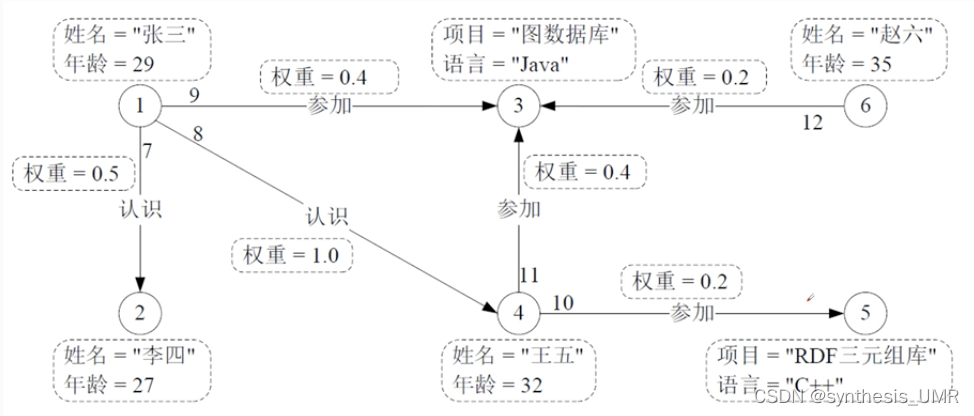
比如:我们要在上图中查找节点id是1认识年龄大于30的人所参加的项目。

第五章 知识管理
5.1 SQL语言
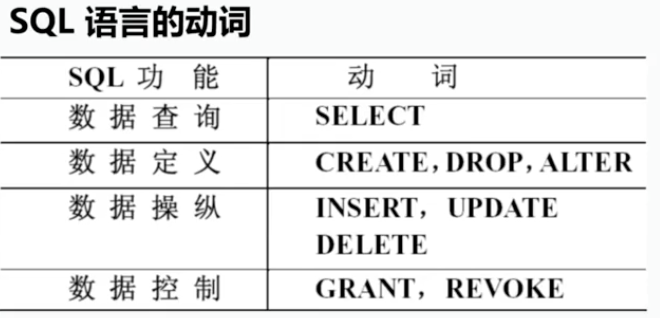
对于关系型数据库组常见SQL语言,对于图关系数据库使用Sparkle语言。
5.1.1 SQL概述
SQL结构化查询语言,是关系数据库的标准语言。是通用的功能极强的关系数据库语言。
5.1.2 举例:学生-课程数据库

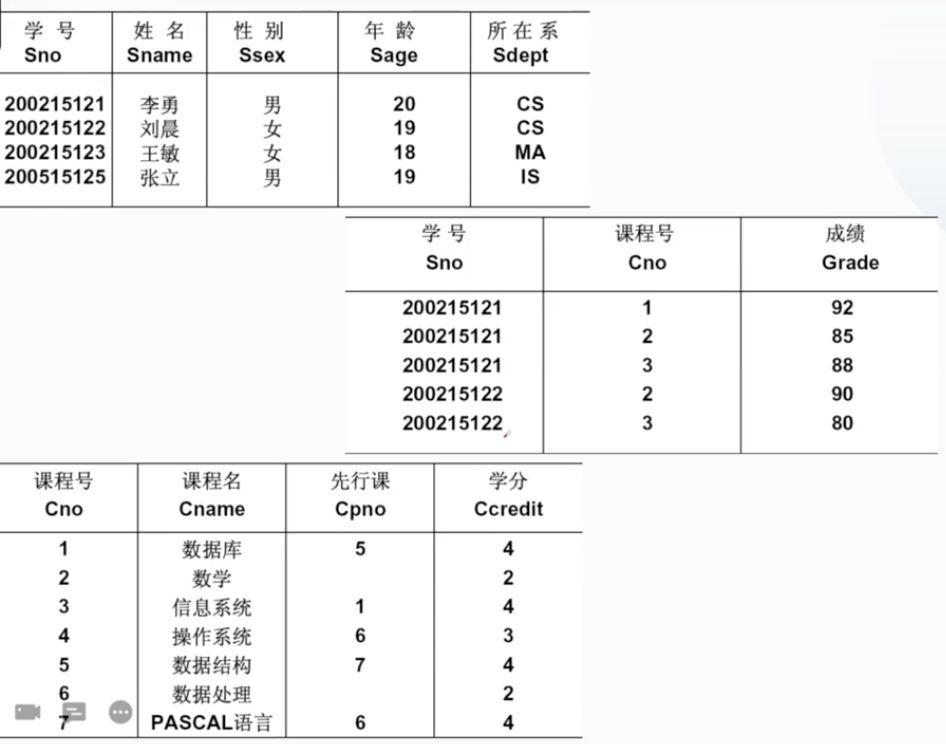
比如我们要定义基本表——学生表Student。例:建立"学生"表Student,它由学号Sno,姓名Sname,性别Ssex,年龄Sage,所在系Sdept五个属性组成。学号是主码,姓名取值唯一。

5.1.3 选中表中的若干列
查询指定列:

选出所有属性列,在Select关键词后面列出所有的列名。将

还可以进行计算,比如我们的列中没有出生这一列。我们想输出结果2004-Sage结果如下:

另外也可以指定查询条件,加入where 指定条件

确定范围(谓词)使用Between and语句:

也可以进行字符匹配,分为固定字符串和《含通配符的字符串》两种:



对于不同的DBMS通配符是不一样的,针对具体数据库具体分析。
5.1.4 数据更新
数据的插入、修改、删除。
1、首先是插入:

 into是非常灵活的,不一定要死板一致
into是非常灵活的,不一定要死板一致

不推荐下面这种简写方式,可读性差很多。语义不清晰,维护很麻烦。


RDBMS将在新插入记录的Grade列上自动赋空值,因为没有指定。或者也可以按下面这样写。

2、然后是修改数据



我们看例6,这个语句是从后面开始读的。首先看Student和SC表对应的Sno,在学生表中选出Sdept系的信息,对应是计算机专业,并把SC表中的Grade都改成0.
3、最后是删除数据

delete from一定要加where啊,如果不加where那就寄了。
我们有三种删除方式:删除某一元组的值,删除多个元组的值,带子查询的删除语句。



删除操作之前要对数据库和表做好备份,一旦删错后果不堪设想。
5.2 关系代数
5.2.1 概述
关系代数运算的三个要素:
运算对象:关系 运算结果:关系 运算符:四类
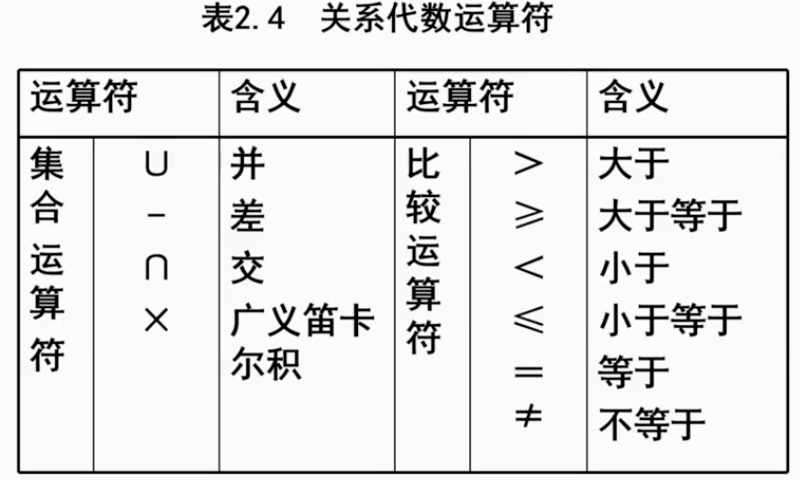
5.2.2 传统的集合运算
1、并Union
设R和S两个关系都有n个属性(称为n目),相应的属性取自同一个域
R和S并在一起仍然是n目关系,由属于R或输入S的元组组成。元组数量会有差异

2、差Difference
前提和并一样,R-S仍然是n目关系,由属于R而不属于S的所有元组组成
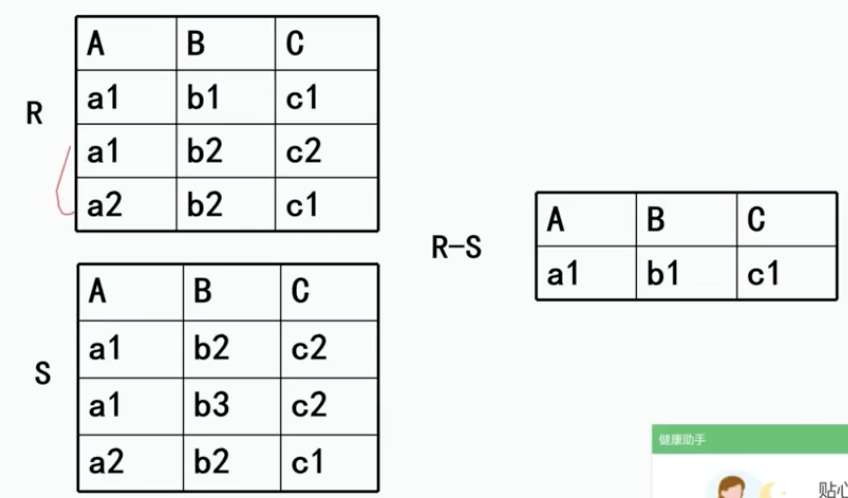
3、交Intersection
顾名思义,前提和前两者保持一致。

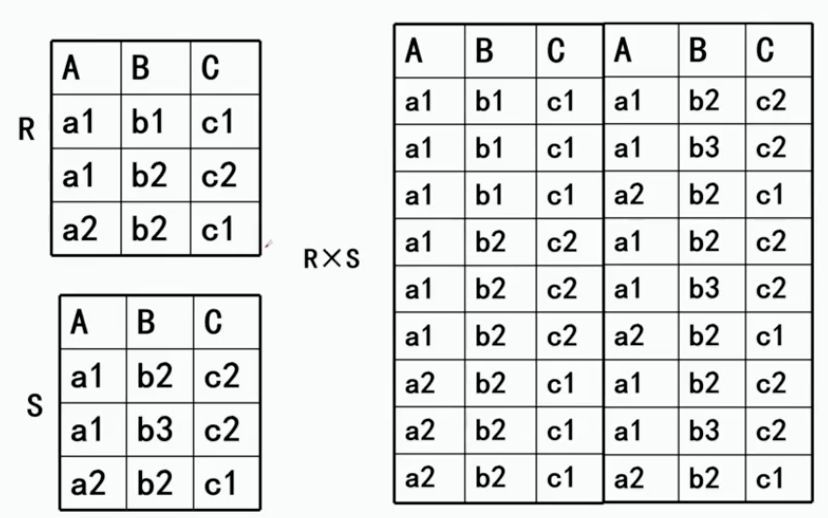
4、广义笛卡尔积
开始不一样了啊注意,R是n目关系,k1个元组;S是m目关系,k2个元组

看一下例子就懂了:就是按照行做组合就完事儿了
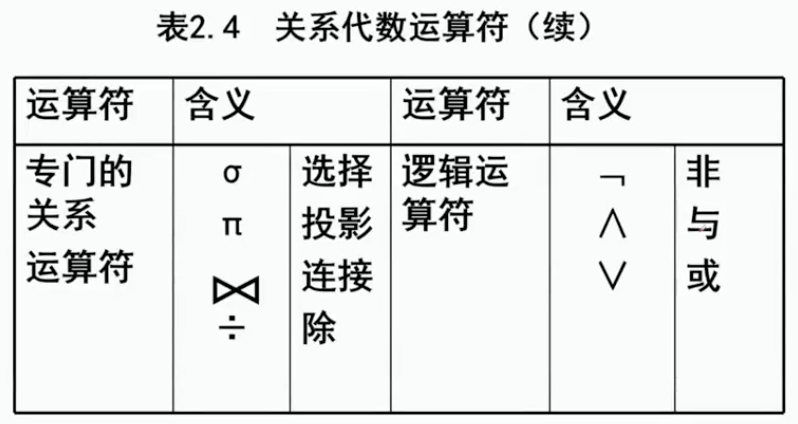
5.2.3 专门的关系运算
再来介绍几种在关系数据库上专门的关系运算:选择、投影、连接、除。首先先给出Student表Course表和选修关系SC表:
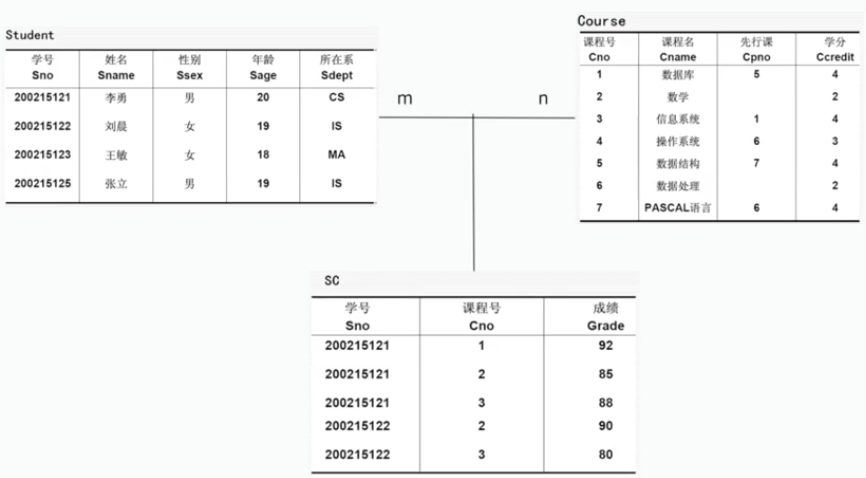
Student,Course之间存在着多对多关系。接下来我们就在这个表中进行几种关系的演示:
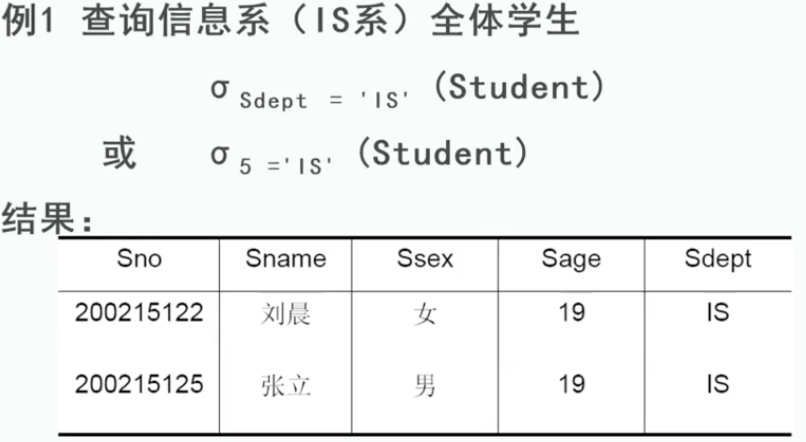
1、 选择
又称为限制,在关系R中选择满足给定条件的诸元组。

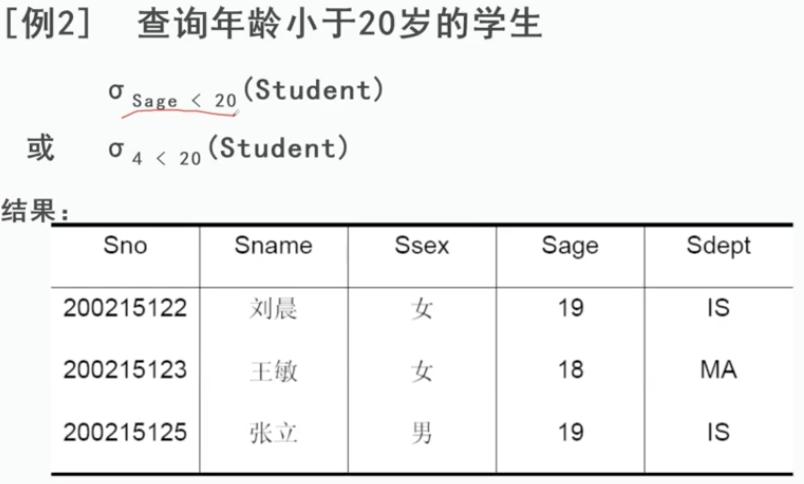
或写法不推荐,语义太不清晰了
2、投影

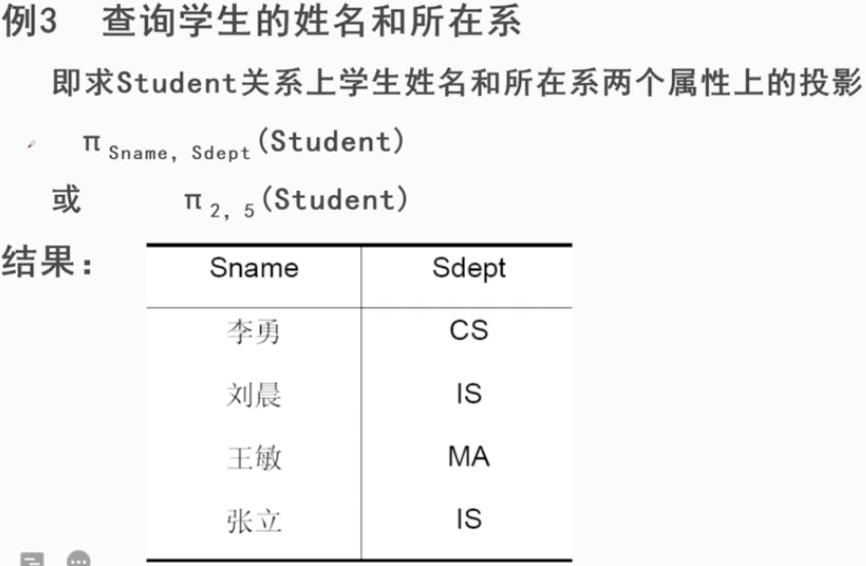
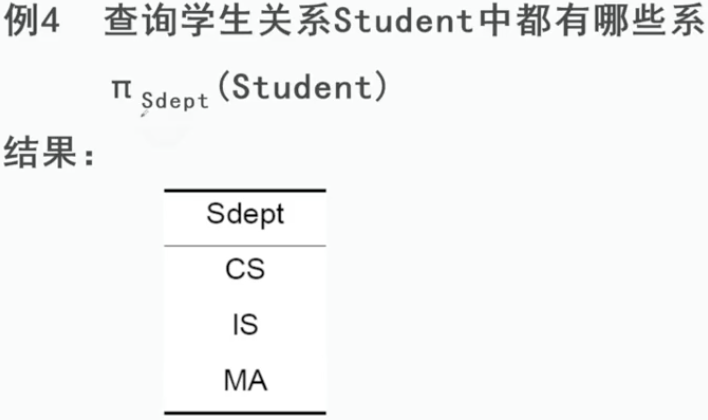
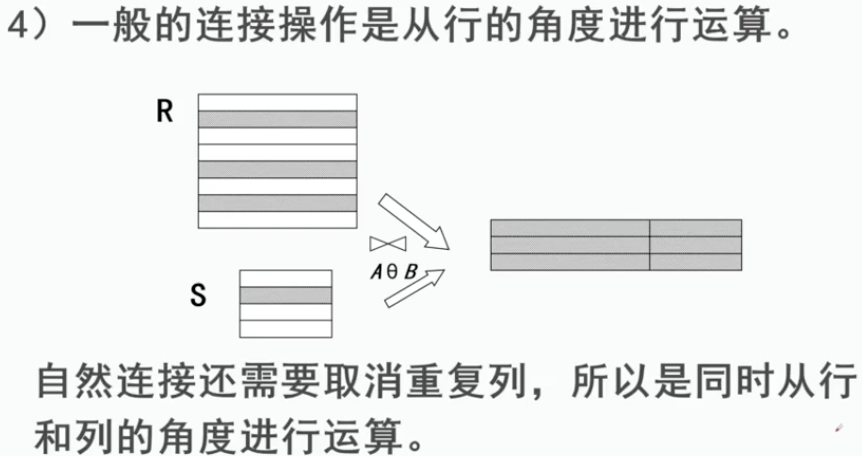
3、连接Join

连接又分为几类:自然连接(等值连接),外连接,左外连接,右外连接
连接是在广义笛卡儿积上进行选取的一种操作。

外连接:把舍弃的元组也保存在结果关系中, 其他属性上填空值 OutJoin
左外连接:只把左边关系R中要舍弃的元组保留就叫做左外连接 LeftJoin
右外连接:只把右边关系S中要舍弃的元组保留就叫做右外连接 RightJoin
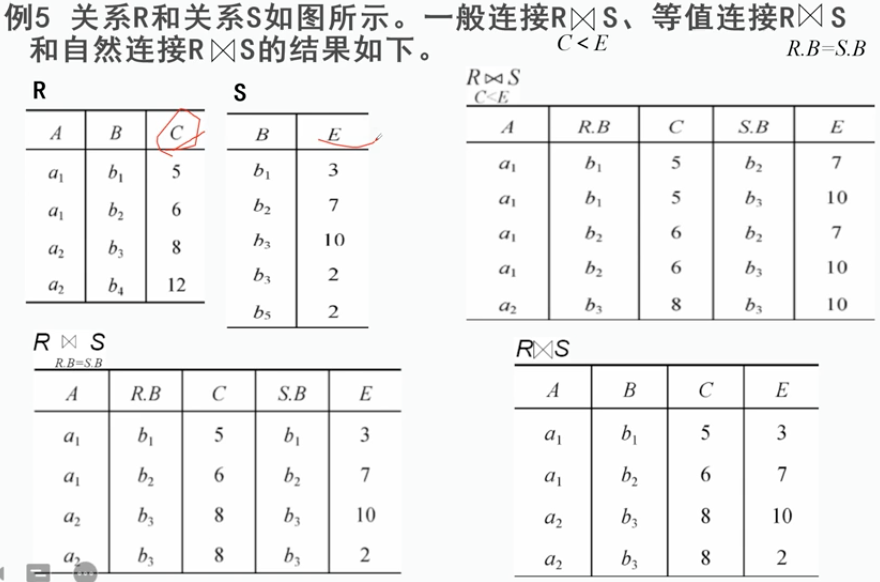
连接又考虑关系R又考虑关系S,半链接主要以某个表为主。
5.3 SPARQL语言
SPARQL:RDF的标准查询语言
他对应的数据和SQL不同,对应图数据库而不是关系型数据库。它最早被提出就是针对RDF三元组的。08年第一次提出。
5.3.1 SPARQL查询实例

我们知道RDF前缀使用的是uri,所以我们在查询语句中也要规定。
我们要使用?+变量名来定义 后面这个模式就是主谓宾三元组模式
所以上面这个意思就是在foaf数据库中,对于person变量如果有名字name属性就把他筛选出来
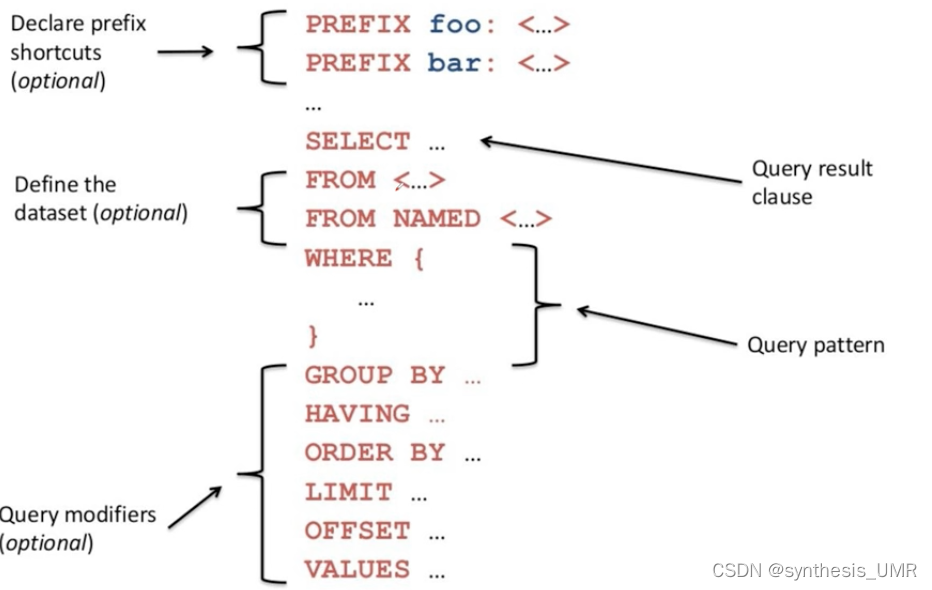
望文生义就可以了,这些和sql是非常像的
我们除了查找一个三元组,我们还有查找多三元组模式:

上图包含两个三元组:这个person变量拥有name属性和mailbox,我们把person这两个属性都筛选出来。称为这种模式基本图模式。
还有一种:BGP图模式
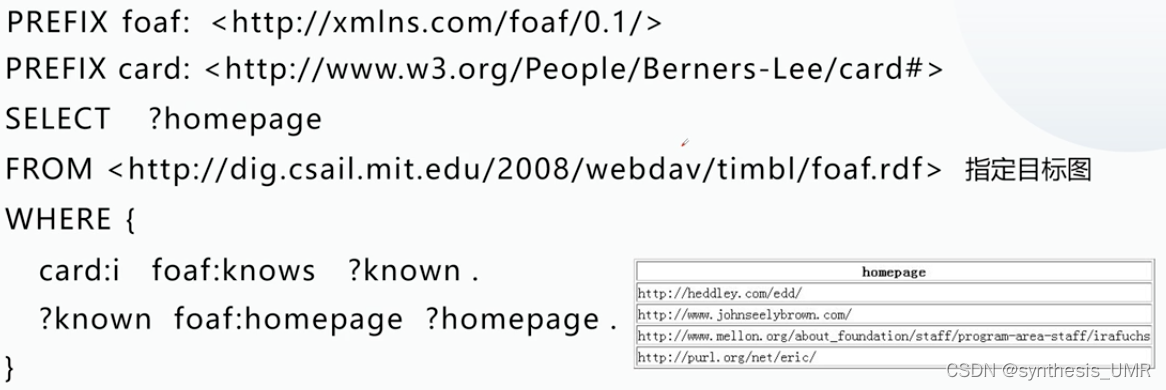
上图中,对于i认识的人known,他如果具有homepage就选出来。这是一种多跳模式。

我们可以看出这种语言是对RDF友好的
命名图查询(多图查询)
找到参加了至少参加了3次ISWC ESWC的人
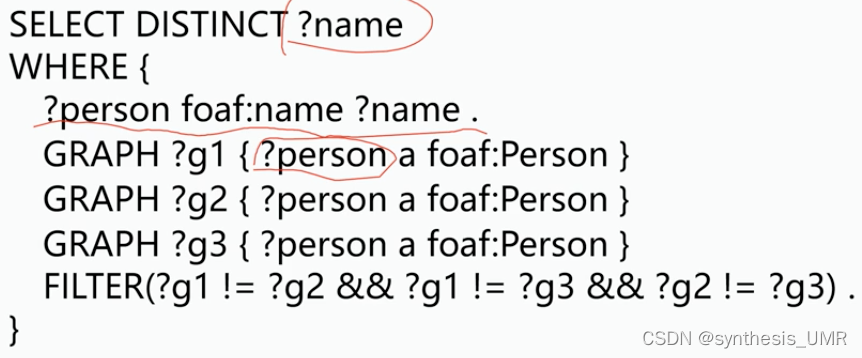
假设三个图对应了参加不同学术会议的人,把他们的名字列出来
属性路经查询

x变量拥有alice账号属性,经过knows这个关系,遍历到一个具有name属性的节点。
斜杠就是经过的属性路径顺序。

+说明这个knows是可以多跳的,上面那个是不可以多跳的。还有很多其他的特殊符号,这个可以自己查询一下。
5.3.2 SPARQL 查询形式
一共有四种:select construct ask describe
select就是纯纯的返回
construct在查询的同时返回一个查询到RDF三元组图
ask返回一个bool值说明查到没有
describe把想要查询的三元组的所有资源都返回。

返回的形式是根据construct后面定义的模板,where是我们要查的。我们看这个返回值,标准的RDF其实就是三个uri。我们要确保主语和宾语全局唯一可查。

首先要查询amazon和nile河的长度是多少,如果大于成立的话返回True


总结:我们要知道查询的目标和返回的形式是什么,这是我们这章需要掌握的。
5.4 Cypher语言 属性图模型
5.4.1 属性图
neo4j图数据库的查询语言。基于java开发磁盘存储的数据库,可扩展性很好,并行性好,相对以前的关系型数据库,Neo4j解决了传统RDBMS在查询时出现的性能衰退问题。因为围绕图进行查询,查询节点和边的时间cost是一致的。
属性图:边标记有向图

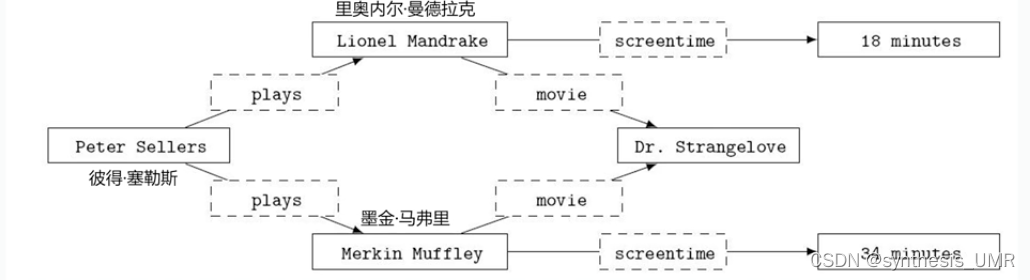
第一个是属性图,第二个是传统RDF三元组。n1n2这些代表节点,边对应e1e2这些,另外属性图中边和节点的地位相同,都具有属性。边还可以指定方向,置信度,权重这些。
属性图中的节点(椭圆框)对应实体,标签n对应类别,边连接节点
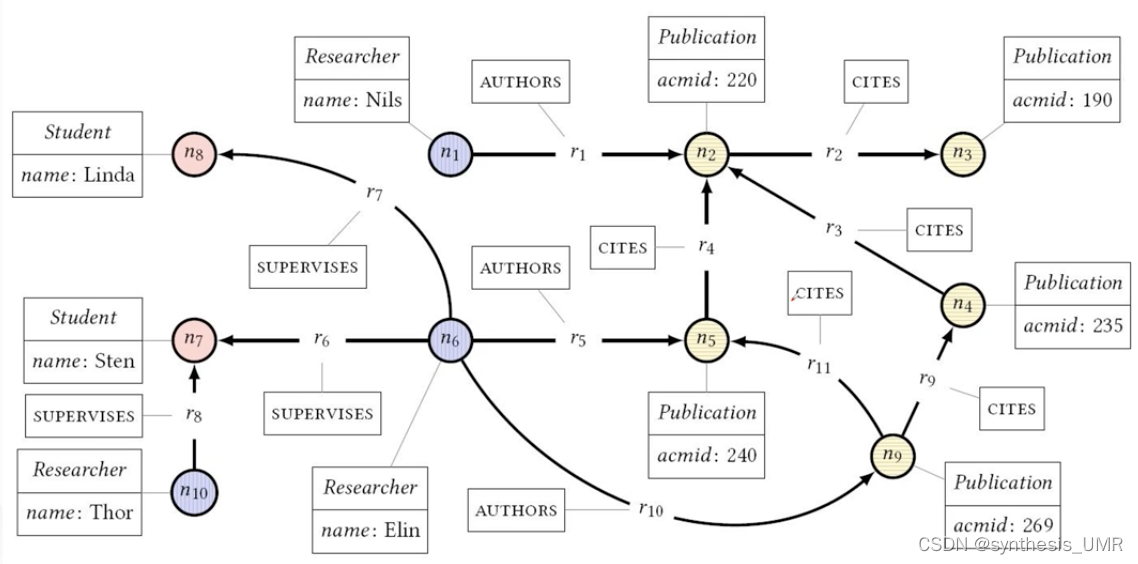
上图实例中通过不同颜色区分类别,实际上通过标签进行区分。所以上图有3种类型的实体,对应的属性看框里的,不同实体可能有不同的属性。 实体间关系有很多不同的边类型。
属性图优缺点:
优点:兼容关系型数据库和图数据
局限:无法满足以下需求:对图中模式的捕获;验证和数据完整性,丰富规则捕获等
(主要是因为图数据库的查找是一个子图同构问题,他是一个NP困难问题)
属性图基本了解到这儿,接下来我们对Cypher查询实例进行一些举例:

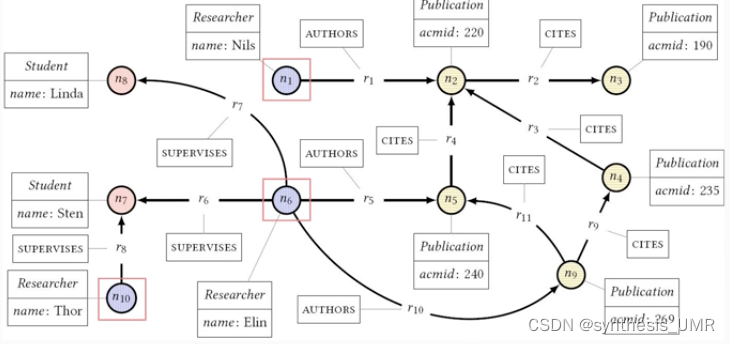
语句1找出了红色框框出的这些节点;语句2定义了元组:经过REsearcher supervises能访问到的n8和n7Student节点; 语句3 r代表researcher,count(s)把语句2找到的Student找到的s数量返回;语句4R从R出发经过authors可以访问到的publication,对应n2 n5 n9;语句5把259分别作为尾实体,找引用过该尾实体的publication实体,*表示可以多跳访问到,所以n9多跳到n2也可以算进去。最终语句6返回学者的名字,学生的数量,计算没有重复distinct的p2并记为citedCount。

这就是Cypher的一个查询实例,要好好理解。
5.4.2 Cypher语法基本元素
利用这个语法规范我们可以把属性图转换成下面这个样子:

lambda用来表示label,在上图中没写出来。
Cypher的语法表达式构成基本如下:

太多了不方便用,下面我们重点看一下几个重要的语法命令:
1、Create创建

是注释标注,不用太关心
2、结果修改更新:Match+Set+Return

第一个:满足dc是DebitCard的,把pin改成3456,返回修改后的dc;Limit表示把最头上的2条返回。
这个Match和Select还挺像的。
3、按照路径查询

还有无方向的:

还有关注多跳的:

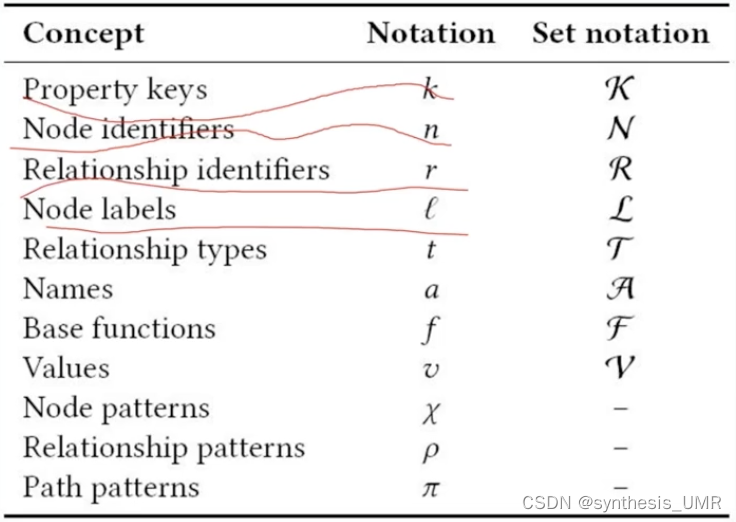
如果要查找有方向的多层关系和结点:
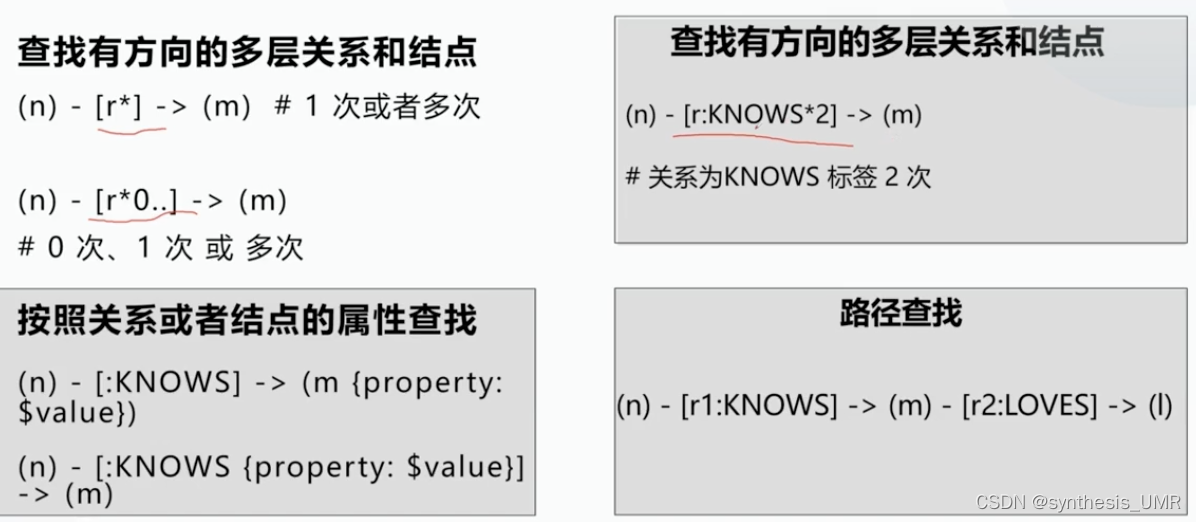
其他的一些查询语句:比如模式匹配,路径赋值

其他的就自己看吧,需要用的时候再学一学:
三者的关系如上图,Cypher和SPARQL是可以相互转换的,参照下图: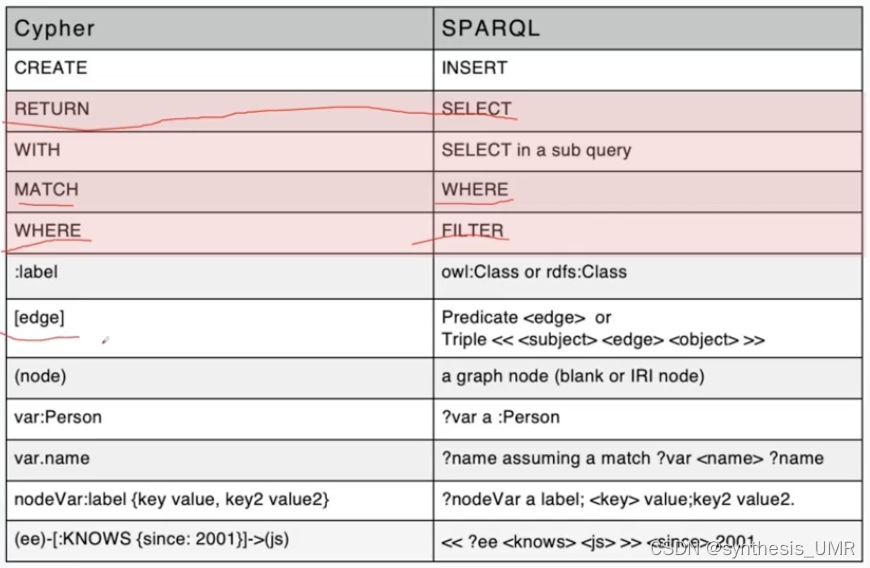
小结:Cypher是一个属性图的声明式语言;Cypher提供丰富的查询和数据更新能力。
本章我们学了SQL 关系代数 SPARQL CYPHER语言
第六章 知识问答
6.1 知识库问答
6.1.1 知识问答历史
KBQA(knowledge-based question and answer)问答系统是知识图谱自然语言处理的一个非常重要的研究方向。

基于检索:关键词模糊匹配+信息抽取+浅层语义分析
基于社区:网民贡献,基于关键词检索
知识库:基于知识库和语义解析
6.1.2 知识问答形式
一问一答
交互式问答
阅读理解
6.1.3 问答系统框架(了解)
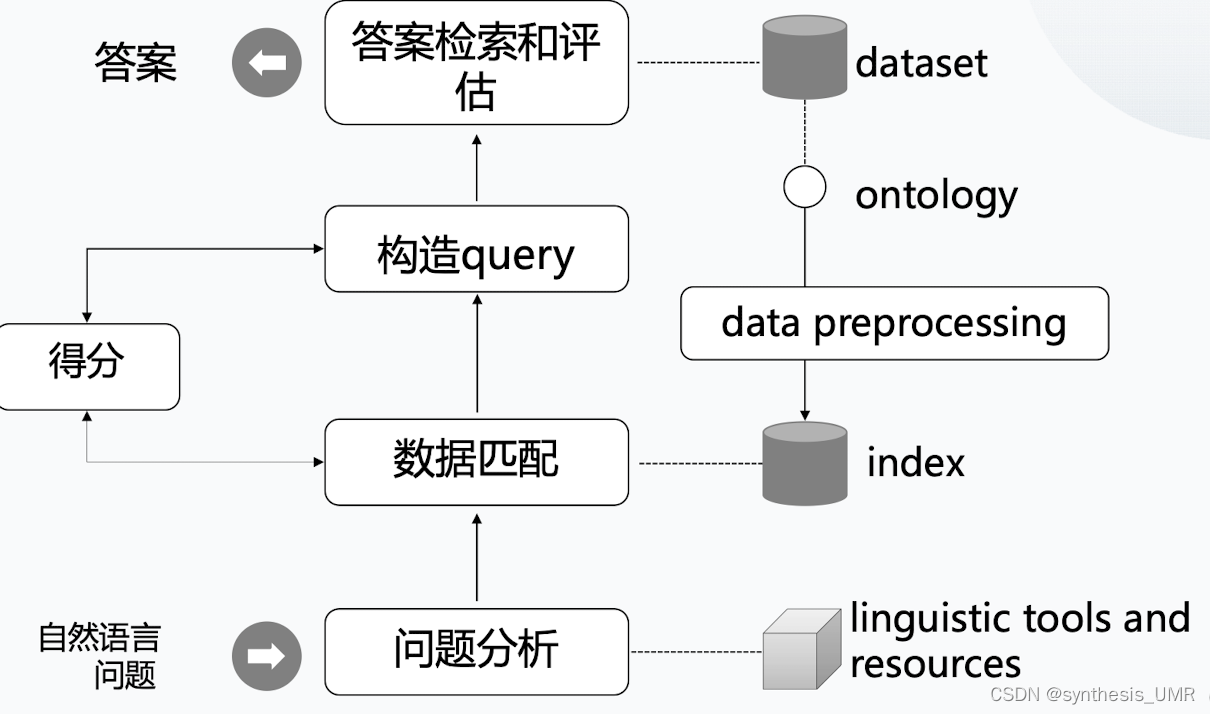
6.1.4 问答系统流程

我们来看两个例子:
首先是基于符号表示的问答:
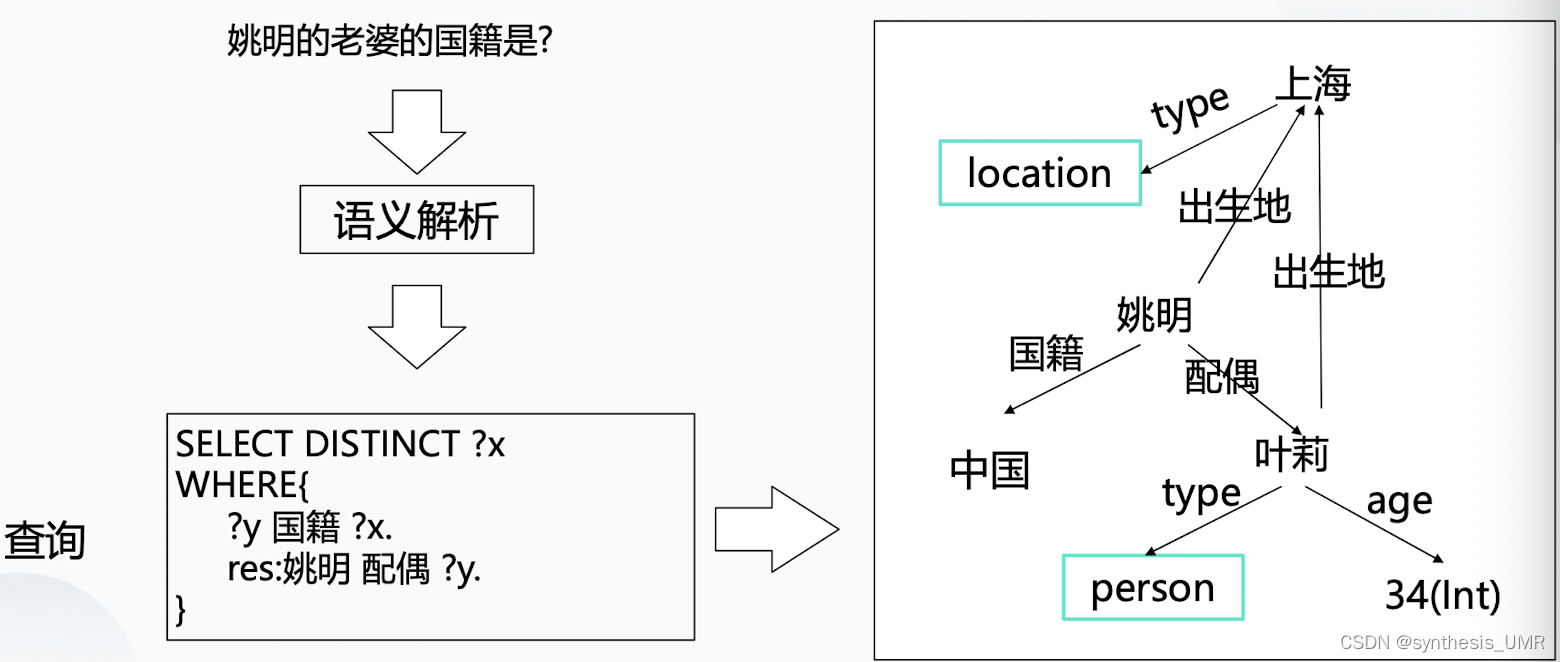
语义解析就像我们前面讲的基于文本的预处理,可以做分词,做词性标注,做句法依存分析。对应在数据库里面的形式是右图形式。
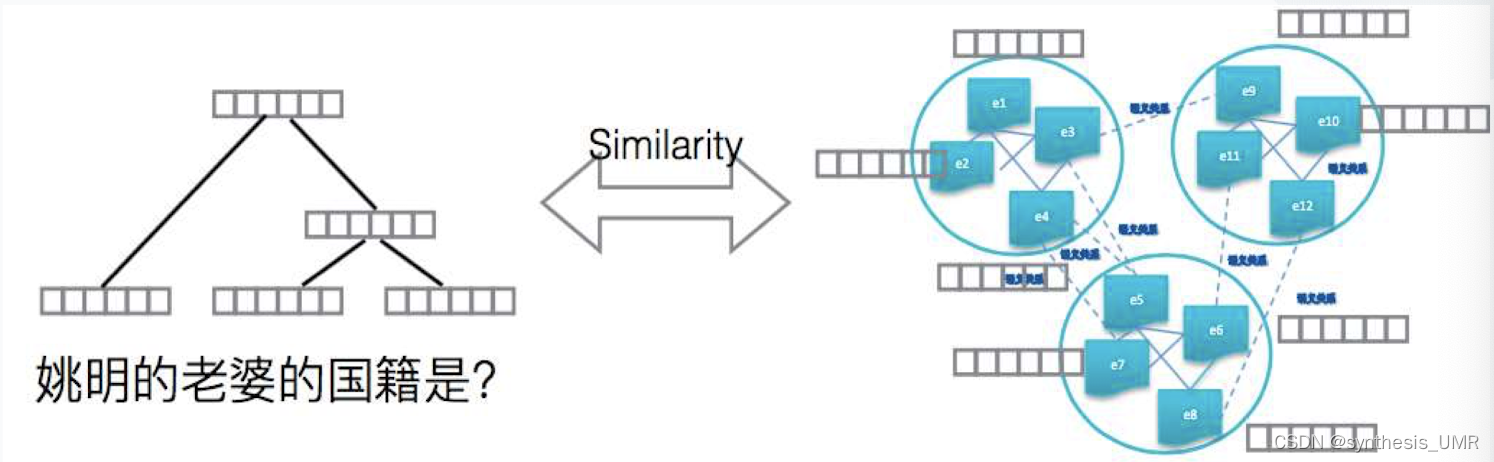
通常我们对于问题就要进行分布式表示。我们主要关注第一种方式。
6.1.5 问答系统概念
1、问句短语
我们可以先对问题本身进行分析:
Wh-words:
who what which when where why how
wh+nouns,adj or adv:
which party which actress how long how tall
2、问题类型
问题类型决定了后续采用什么样的回答处理策略:
事实型问题,列表型问题,最高级型问题,对错型问题,谓词型问题
观点性,因果型,方法型,解释型,关联型,比较型
3、答案类型
事实型答案(实体,人,地址,数值,时间),摘要型,描述型(解释型,证据型)
4、问题主题
关于哪方面(地理,医学)
5、答案来源类型
结构化数据,半结构化数据,非结构化数据
数据源(单个数据库,分布式,网络)
6、领域类型
领域:开放域(自由领域),特定域(垂直领域)
数据类型:文本、图片、音频、视频
多模态问答,视觉问答
6.2 知识库问答方法
比如说现在司法考试也让人工智能进行答题,很多人用分类模型进行做。这也是一个问答问题。
现在常见的有三种方法:基于模板,基于语义解析,基于深度学习
6.2.1 基于模板的问答方法
本部分主要分为三点:模板定义,模板生成,模板匹配
可以是面向用户问题的模板,也可以面向数据库的查询模板的匹配
我们首先以TBSL2012为例进行讲解,下面是一个sparql模板

我们来解释一下这个语句是怎么进行描述的,先看最后c对应了film类,p的意思是produced。
然后再看回括号内:y的类型是电影,y是被x制作的。以y(电影)的数量为倒叙排序,找出电影最多的对应的第一个x,并输出。
我们可以将这个模板实例化:

c变量是file,p变量是制片人。这样就可以进行查询啦~
1、基于模板的问答方法——模板定义
我们结合KG格式和问句句式进行模板定义。通常没有统一标准。
TBSL模板定义为SPARQL query模板。直接与自然语言映射。
TBSL架构
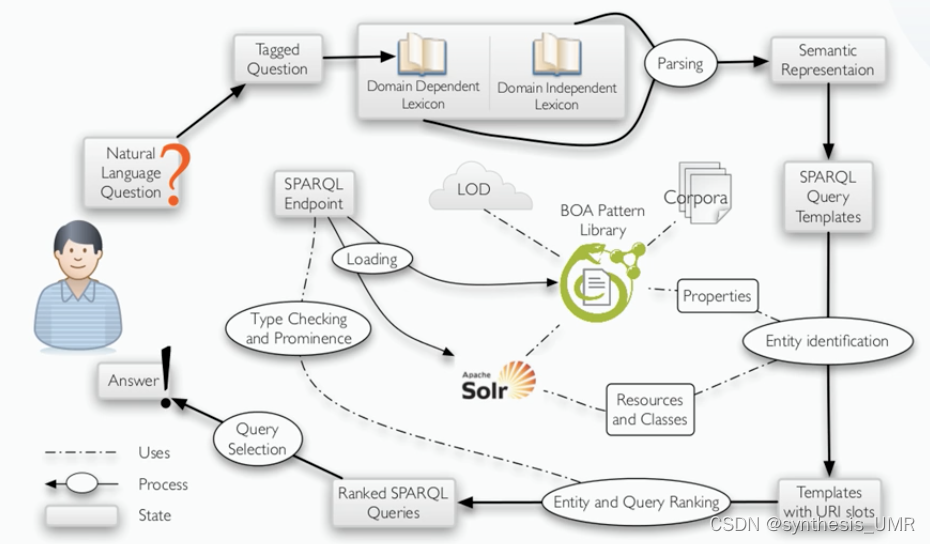
简单来讲:1、用户提出问题 2、分词句法分析得到关键核心词(名词 动词对应SVO)3、建立SPARQL查询模板,得到待填充槽位 4、定位可能满足的查询位置(知识库资源映射)文本相似度匹配(要考虑来自问句的实体和知识库中待查询的实体之间相似度 比如后文的FIlm和filmfestival)得到candidate answer 5、打分,显著度相似度打分。
我们可以借用很多的知识库资源(比如网络资源:WordNet)来得到更好的效果。
Template based semetic web language patten
第一步:模板生成
1、获得自然语言问题的POS tags信息
2、基于POS tags和语法规则表示问句(规则一般是分词词性标注,然后做句法依存分析,然后用来表示问句进行一些浅层语义表示)
3、利用domain-dependent词汇和domain-independent词汇辅助分析问题
4、将语义转化为一个SPARQL模板
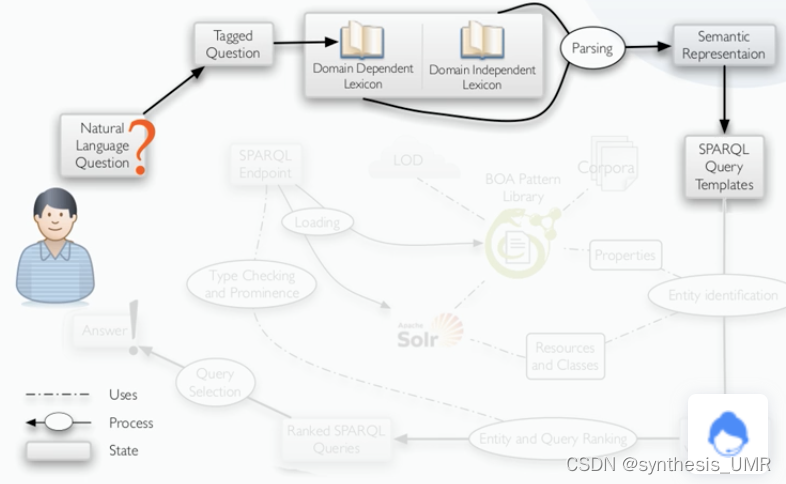
比如说这个问题:Who produced the most films?
domain-independent: who, the most
domain-dependent: produced/VBD(动词), films/NNS(复数名词)

针对上面这个问题可能产生上述两种模板。 我们把要查询的x叫做槽位slot,我们找到的最终结果可能是SPO里面的SO,这个过程叫做槽位填充。
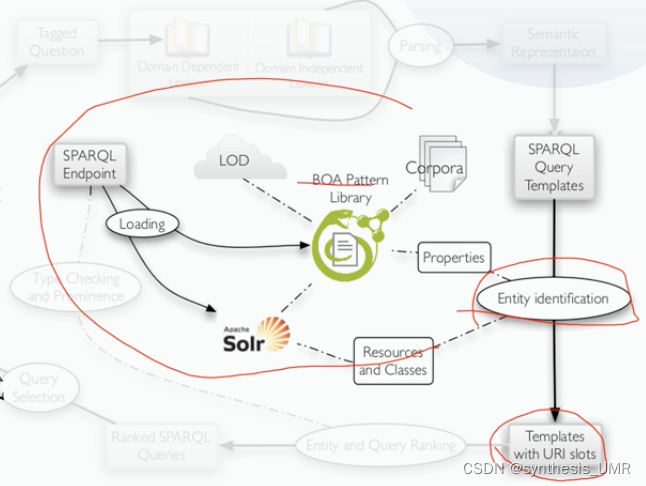
第二步:模板匹配和实例化
有了模板以后,需要进行实例化和具体的自然语言问句匹配。就是把自然语言问句和知识库中本体概念相映射的过程。
1、对于resources和classes,实体识别常用方法:(我们常用的实体连接方法)
·用WordNet(一个网络资源)定义知识库中标签的同义词
·计算字符串相似度(这个最为直接)
2、对于property labels,将还需要与存储在模式库中的自然语言表示进行比较。
3、最高排位的实体将作为填充查询槽位的候选答案。

第三步:排序打分
1、每个entity根据string similarity和prominence获得一个打分
2、一个query模板的分值根据填充slots的多个实体的平均打分
3、另外需要检查type类型:对所有三元组?x rdf:type
4、对于全部的查询集合,仅仅返回打分最高的
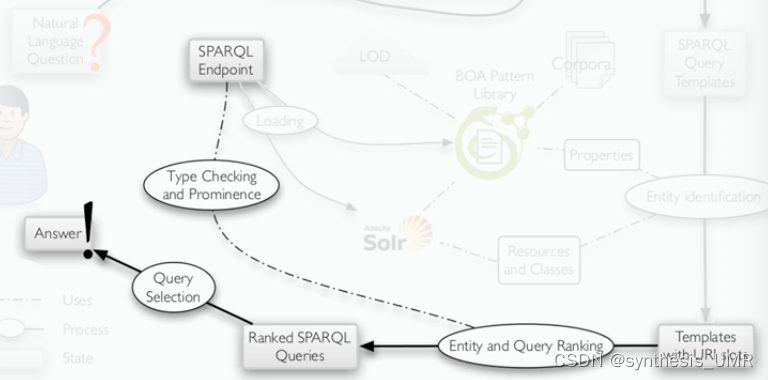

我们看上图的实例,Film和FilmFestival不一样,上面的得分高,所以我们选上面的。
总结:基于模板方法的优缺点:
优点:快,准确
缺点:经常无法和真实问题匹配;若想要回答更多的问题需要建立庞大的模板库,查询效率很低。
6.2.2 基于语义解析的回答方式
主要分为四步:资源映射,Logic Form,候选答案生成,排序
Logic From主要是基于符号化的表述形式。
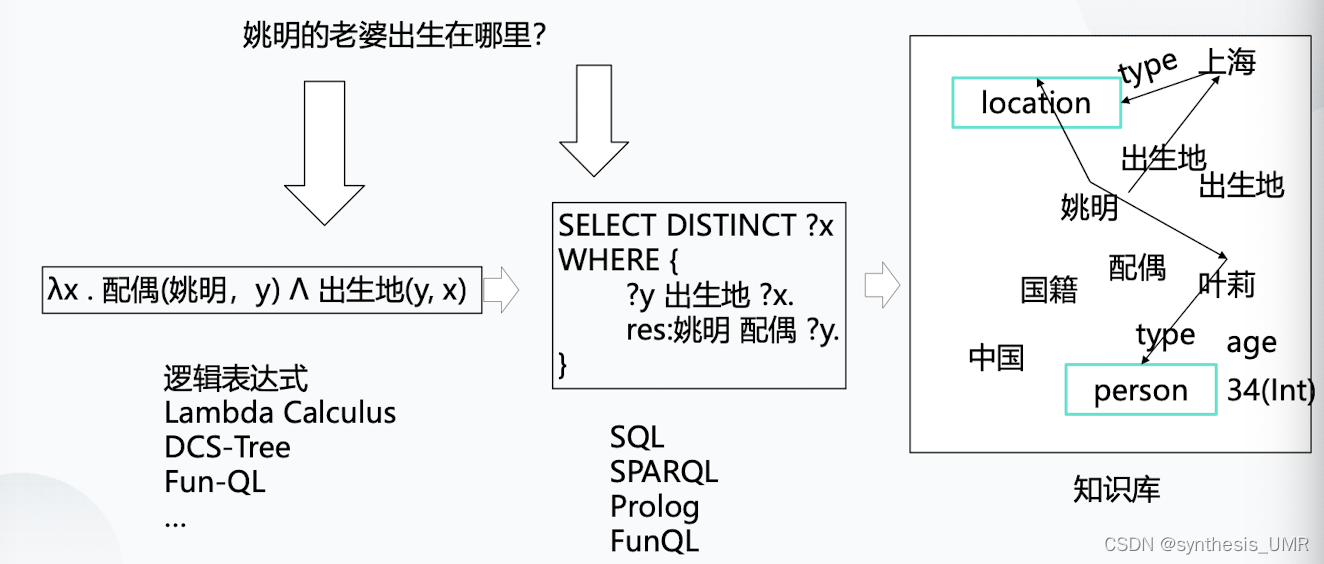
如果是使用基于模板的方法,我们把这个问题拆解成两个SVO:首先找出姚明的老婆,然后找出她出生在哪儿。如果是语义解析的方式要把它化为逻辑表示形式。
上图中的lambda是一个关系算子,可以对应一阶二阶谓词。对应后面两个关系(配偶,出生地)必须都为真,才返回x。
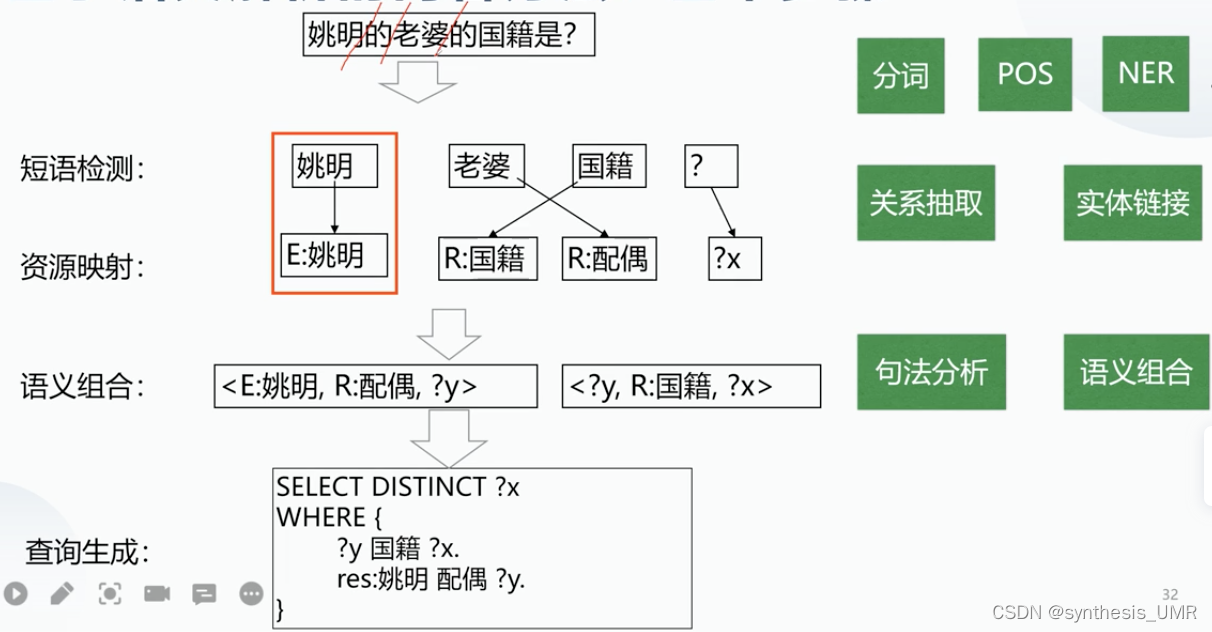
首先进行 分词工作(因为是中文的,英文词和词之间天然具有间隔),然后做词性标注POS,然后NER命名实体识别出关键实体。然后进行关系抽取(配偶,拥有),可能的话还要进行实体连接,主要是在资源映射要用到的技术。把问句里提到的实体和知识库里提到的进行实体对齐(比如说问句里的老婆和知识库里的配偶是一样的)达到的效果是实体连接。然后呢,我们在知识库中找姚明这个节点,但是这个也不太好找,因为有多个姚明,而我们一般指的是打篮球的姚明,所以在这个过程中也有一个实体连接问题。这个过程我们就叫做知识库的资源映射。
做完资源映射了(老婆对应了配偶,国籍对应了国籍,姚明对应到了篮球姚明),接下来进行语义组合,根据句法分析结果,分析出老婆是姚明的老婆;姚明是老婆的定语。从而得到三元组
这个三元组之间对应了一个逻辑表达形式,也可以写成lambda算子形式

进行了这样的语义表示之后,我们就可以面向多个知识库语言进行面向知识库的SQL查询语句。这就是典型的语义查询的方法。
上面这个例子极其重要,要好好感受。我们通过它可以知道基于语义解析方法的关键要素:
1、获得短语(用户文本中自然语言短语)到资源的映射——资源映射

可以通过构造词汇表来完成这样的映射
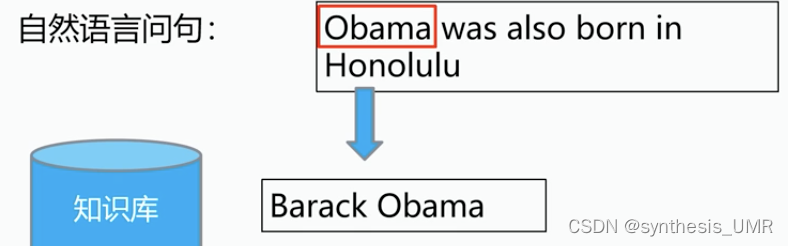 简单映射:字符串相似度匹配
简单映射:字符串相似度匹配
复杂映射:"was also born in"——PlaceOfBirth 两者么有任何字符上的相似性,语义上有相似性
较难通过字符串匹配的方式建立映射,可以采用统计方法,比如birth很有可能和born有关。
实体对entity1 entity2作为SO出现在was also born in两侧,我们可以认为was also born in这个短语可以和PlaceOfBirth建立映射。
2、如何解决文本的歧义——逻辑表达式
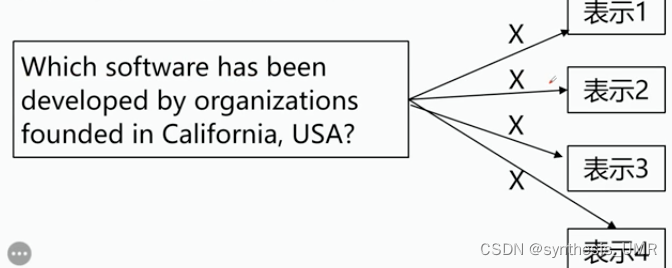
我们怎么能知道California是指美国的呢?就是指这种歧义。还要关心上下文,比如苹果到底是水果呢还是公司呢?
逻辑表达式简介:
逻辑表达式是一种能让知识库看懂的表示。可以表示知识库中实体,实体关系。
可以分为一元形式和二元形式。
· 一元实体:对应知识库中的实体
· 二元实体关系,对应知识库中所有与该实体关系相关的三元组的实体对。
当然也可以进行连接、集合运算,聚合操作等等。
逻辑表达式构建:
一步到位:直接获得与知识库相关的语义表示
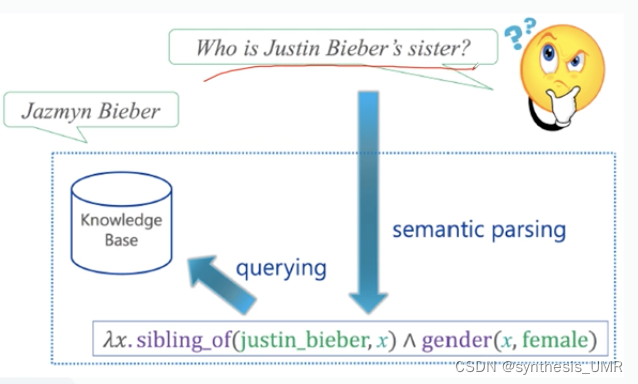
两步到位:先通用语义表示,再实现知识库映射
一旦落实到具体系统中特别难,比如上海到大连的机票多少钱,一下子就可以得到4个实体。但也有"我现在在大连,好想去上海,现在飞到那儿多少钱"这样的表述方式。这个咋搞?那儿还有 指代消解的问题。这里句式也不标准,依存句法分析很麻烦,钱要对应价格。。。这么多问题,所以要做一个靠谱的系统真是不容易啊。
问题定义
问题答案对数据集来训练分析器。我们通常是用有监督学习进行,数据集是标准的问题答案对来构建。那么这个问题对是标准的还是口语化的,训练出来的效果就不一样

监督数据来源:手工编写规则 vs 问题、答案对
手工的局限:需要专家编写-进度缓慢,代价昂贵,不可扩展,仅在受限领域推广
问题答案对的优势:较为轻松获取(但是质量不齐)
目标:通过大规模知识库上的问题、答案对集合训练Parser
6.2.3 基于深度学习的问答方法(了解)
把Q和A都直接输入到网络中,人们现在认为深度神经网络的方法对于语义信息的表示是最好的(相较于以往的特征工程和统计学习方法)。
6.2.4 问答方法对比
模板方法:快,准确,可以回答比较复杂的问题。但是人工编写费事,经常无法和真实问题匹配
语义方法:人工编写规则工程量大,可以回答比较复杂问题
深度学习方法:无需人工编写模板,学习过程自动进行,但目前只能处理简单题和单边关系。通常不包含聚类操作,时序性问题不太好应对。(两个但是现在好像已经解决了)需要的运算资源最大。
6.3 知识库问答系统KBQA
知识库的构建在QA两端都是有难度的。QA端的任务可能是接近的。两者可以相互辅助完成。
人机交互式的问答系统的挑战还是很大的。
知识库问答的方法主要分为:1.基于语义分析的方法 2. 基于信息检索的方法
语义分析:将非结构化语言转化为逻辑形式。查询知识库找到表达语义的逻辑形式
信息检索:问题中提取信息,利用知识库得到候选答案并对其排序。图匹配技术和语义查询图。
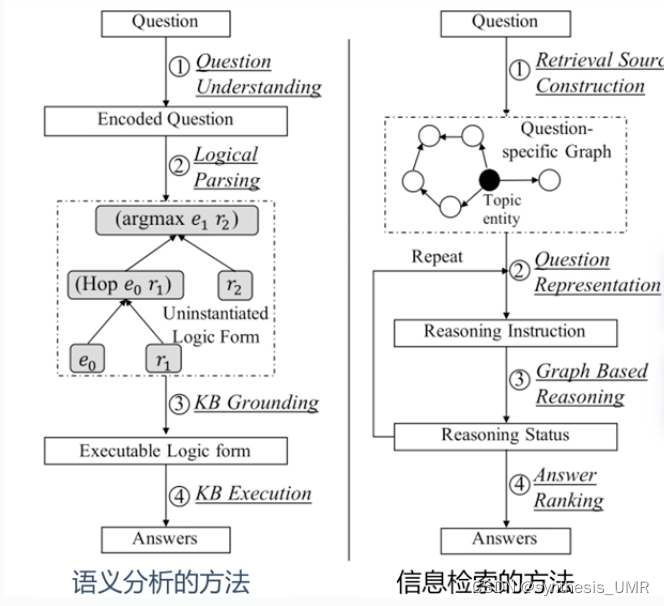
我们首先看左上图这个语义分析的方法,输入一个问题,对问题进行编码,然后进行逻辑语义分析。Logical Parsing逻辑解析的过程就是找出SPO三元组的过程。可以是根据逻辑表达式模板生成。生成逻辑表达式以后再和KB里面的库进行匹配。再生成SPAQL查询语句最后找到答案。
然后是右上基于信息检索的,通常根据用户问句生成语义查询图,然后在图结构上生成用户问句。接着和数据库中的RDF子图进行匹配,最后生成结果。最近的很多方法加入一个循环过程来辅助匹配。
接下来我们将介绍两个典型的系统:
6.3.1 Elasticsearch
系统设计背景
本身是一个成熟的搜索和数据分析引擎。公共接口是HTTP上的JSON,可扩展性非常的强。
系统功能
主要依靠强大的搜索功能,可以实现简单的知识问答。
Elasticsearch的知识问答主要基于四个功能:
1、基于实体检索的问答
这要在数据库中搜索姚明,然后返回他的属性和属性值 。
2、基于实体属性检索的问答

首先确定姚明这个entity,然后确定出生地这一属性,最后返回属性值
3、基于多跳查询的问答
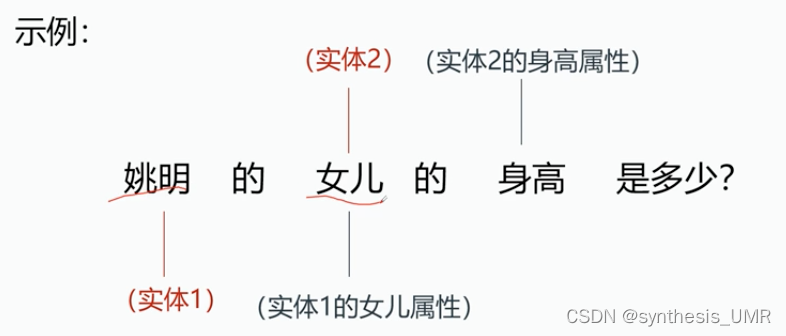
首先确定这句话中有姚明和女儿两个实体,然后根据姚明:女儿查到姚明的女儿的属性值。但同时这个属性值也作为一个实体存在在数据集中,所以继续对这个实体查询身高属性。
4、根据属性值查询实体的问答

首先确定属性,然后确定关系式AND,再从数据库中搜索实体的姓名属性返回。
小结:
这个框架是分布式搜索框架,包括特征:

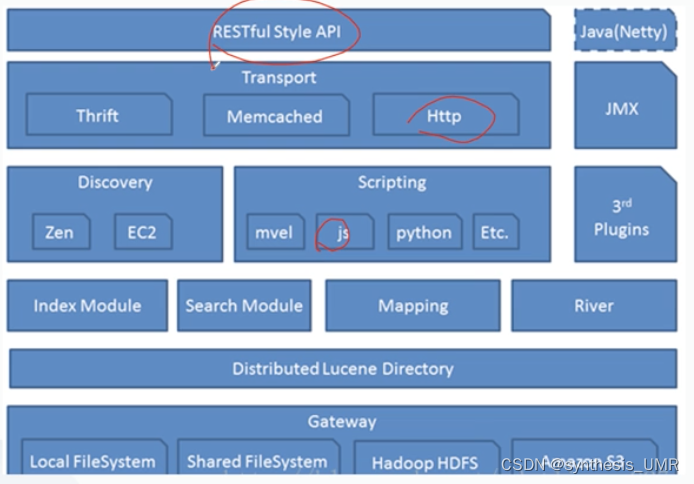
ElasticSearch的知识问答流程
基于Elasticsearch的知识问答包括以下四个步骤:
1、数据准备:数据集转化为JSON,可以进行属性同义词扩展
2、导入Elasticsearch,在其中创建index和type索引,并导入JSON数据
3、自然语言转化为Logical form:解析自然语言,生成逻辑模板
4、Logical form翻译成ES查询语句:生成ES查询语句,执行查询指令
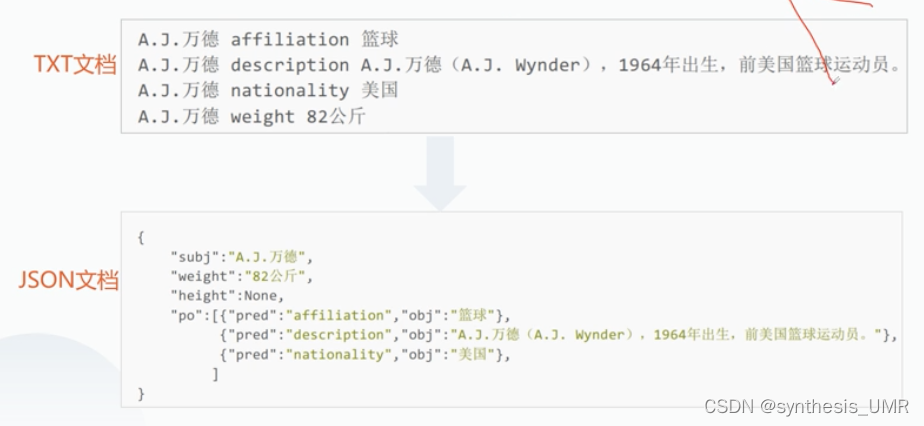
1、数据准备
Elasticsearch要求输入JSON,所以txt要转化为JSON。每个entity对应一个json的object,也就是Elasticsearch中的一个文档。
2、数据导入
用index和type管理导入的文档。
index可以认为是一个单独的数据库。里面存放结构相似的文档。
type是index的一个子结构,可以存放不同部分的数据。
type可以类比成一张表,每一篇文档都存储在一个type中,类似于一条记录存储在一张表中。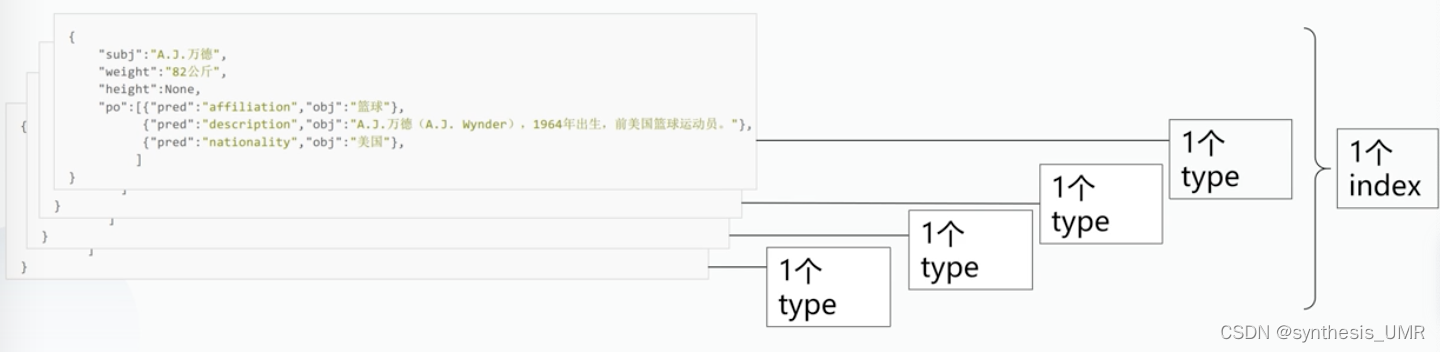
3、自然语言解析
首先要生成logicform模板。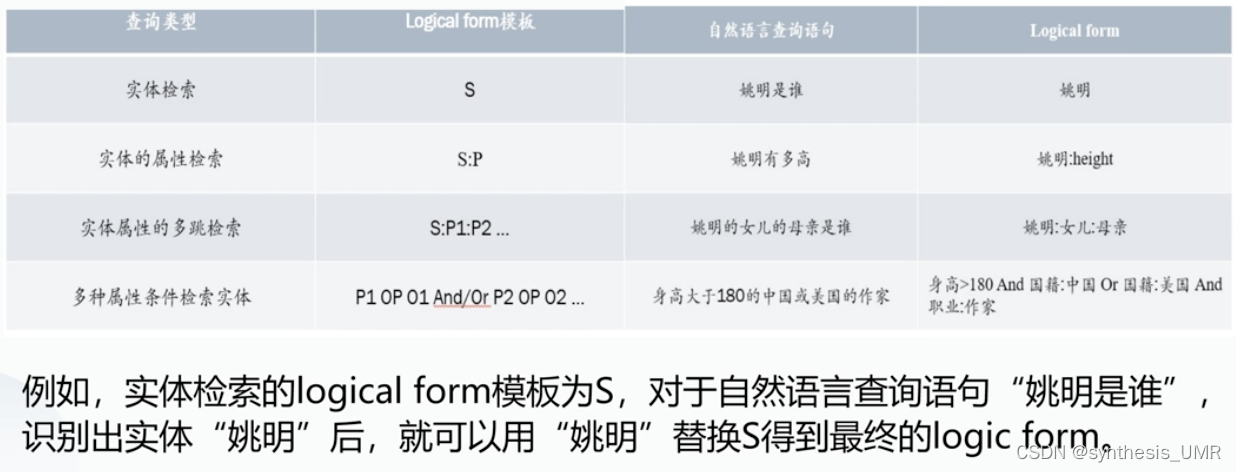
4、ES查询
生成的逻辑模板然后翻译成数据库查询语句。
同样是对于每种查询类型需要预定义ES模板,然后进行逻辑填充。 

Restful风格非常简单 url后面带着 ?参数名,这就是很简洁的restful风格。配置起来非常的简单。
但是对于深层语义的表示非常困难
接着我们介绍第二套系统:gAnswer基于信息检索的方法
6.3.2 gAnswer系统
北京大学计算机系邹磊老师。
主要解决RDF Q/A的两个挑战:
语义消歧(资源映射):比如PaulAnderson和Paul S. Anderson 和Paul W. S. Anderson如果需要消去错误的歧义,需要找到正确的映射。
查询构建(语义组合):如何将映射后的额实体和谓词拼接成一个完成的SPARQL查询。
gAnswer是怎么应对这两个挑战的呢?
首先gAnswer将消歧义和查询评估结合起来。就是在查询匹配的时候解决自然语言问题的歧义。
其次gAnswer构建了一个表示用户查询意图的查询图。但接受在问题理解阶段出现的歧义。比如说短语连接和查询图结构的歧义。解决了在查询评估中找到匹配项时的模糊性。
一般我们的做法都是将语义消歧和查询分开来做,消歧义这个步骤往后放了。
系统功能
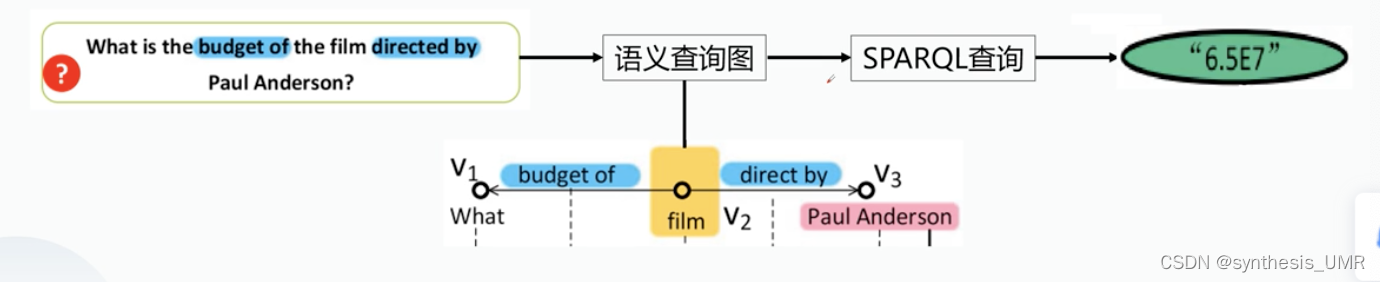
重点在于语义查询图的构建部分。
系统将NLP问题转化为包含语义信息的查询图,然后将查询图转化为标准的SPARQL查询。并将这些查询在图数据库中执行。最终得到用户的答案。
系统框架
用两个数据驱动框架,将消歧义和查询评估结合在一起:
1、关系优先框架:解决了查询评估中短语连接的歧义
2、结点优先框架:短语连接和查询图形结构的模糊性得到了解决。
1、关系优先框架
我们来看原始问题:What is the budget of the film directed by Paul Anderson
这其中What film Paul Anderson是实体,the budget directed by是知识库中对应的关系。
那么在关系优先框架下,我们首先识别关系:
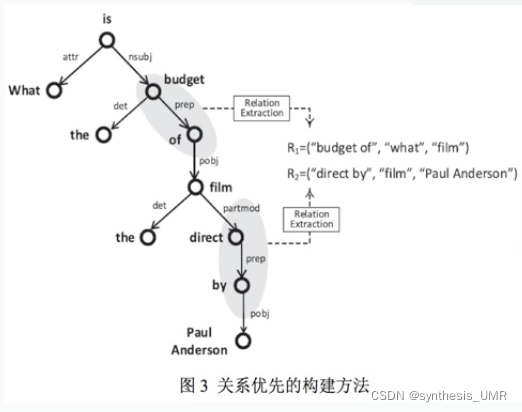
通过句法依存树进行模板匹配能够识别出多条关系,进而回答多跳问题。
关系两边的实体节点是要通过启发式规则确定的。
具体的操作方式:在语义查询图Semetic Query Graph上面进行操作
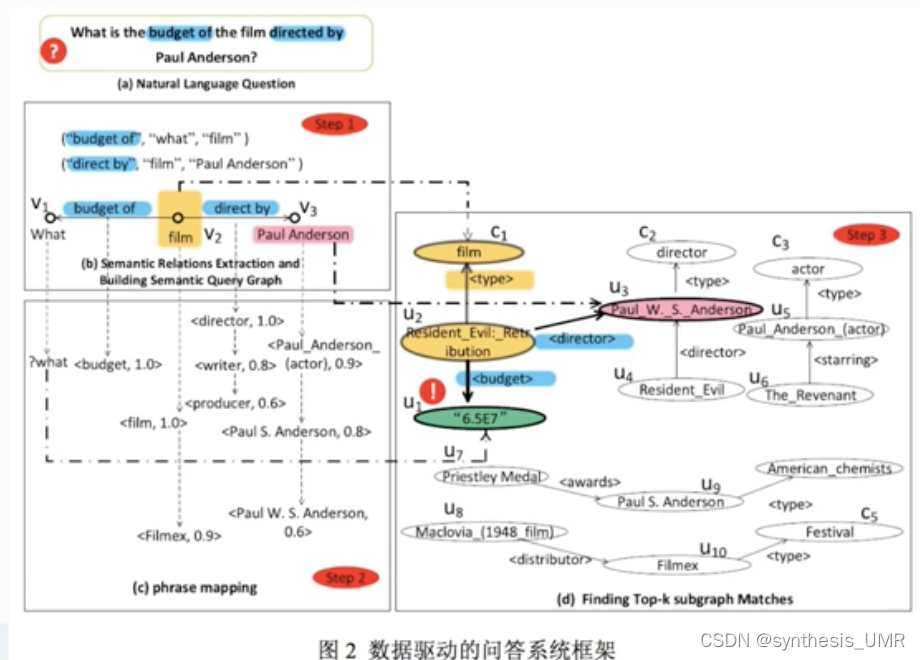
1、提取所有的语义关系, 边对应关系。
2、与rdf子图匹配得到得分(虚线框内的)最后会返回分值最高的匹配项的结果。
两个显著的缺点:

所以我们采用了第二种框架:结点优先框架
2、结点优先框架
先识别问题中的(实体、类别、变量)再通过句法依存树构造查询图结构。最后为图中各个边分配候选的谓词。
优点:不仅可以识别多关系,还可以处理隐式关系,并且不依赖于预先定义的图结构模板。 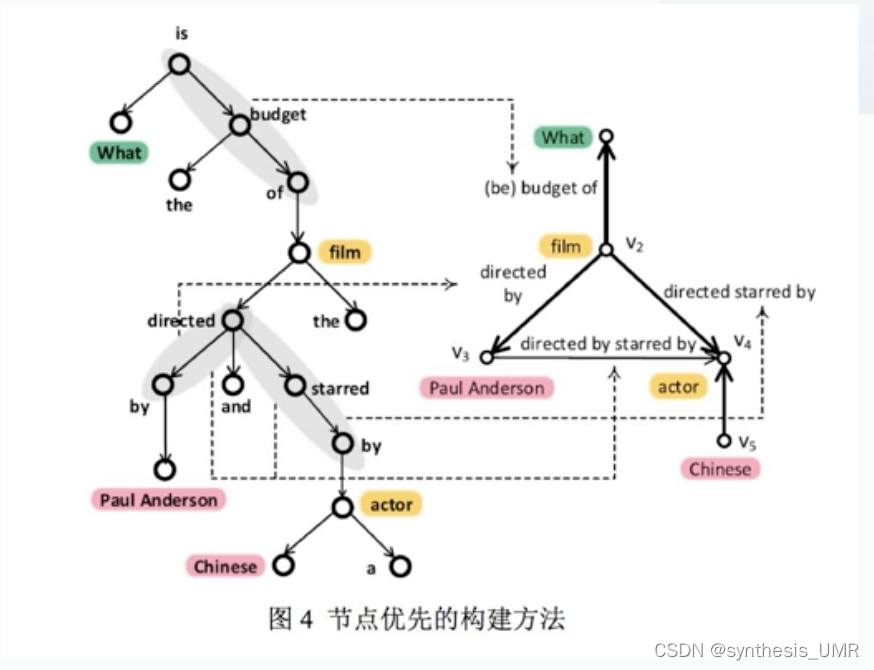
这样构造出的查询图叫做超查询图。
gAnswer的关键技术点:语义查询图

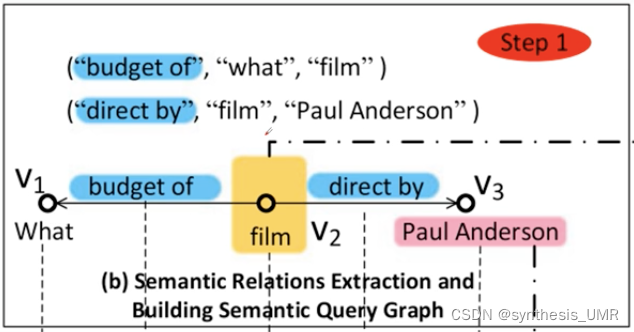
本质上这个结构反映了三元组的形式。
有了语义查询图以后,我们如何进行匹配工作呢?
gAnswer的技术点:Match
假设一个语义查询图有n个节点,每个节点都有一个候选实体列表Cn,每一个边也有一个候选谓词列表Ce。
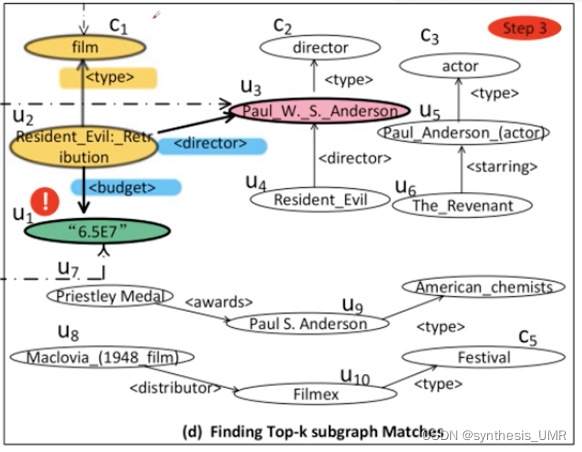

解读: 查询图里面的vi可以映射到RDF图中的一个实体ui。
gAnswer的技术点:Sturcture Construction
节点之间的关系也是通过句法依存树



gAnswer优缺点:语义查询图阶段具有歧义,查询阶段在rdf子图中找匹配,这样也很好的解决了模糊匹配的问题。

节点优先方法理论上覆盖了关系优先方法,但是关系优先应该更快些,所以就应该是对应了不同类型的问题。
KBQA工作总结:2021
图结构的表示方法现在GCN,以前GNN
数据库的查询部分SPARQL,或者子图匹配这样的
还有比如说直接基于知识图谱图结构表示,现在很多边的表示放到节点表示里面做。到了后面映射到低维稠密空间,直接基于向量之间的相似度就可以查询相似度了。
第七章 知识推理
7.1 传统推理与知识推理的基本概念
什么是推理?
推理是从已知事实推导出新的事实的过程。
推理有三种形式:演绎推理,归纳推理,溯因推理
1、演绎推理
从一般到特殊的推导过程

2、归纳推理
从特殊到一般的推导过程

归纳推理不一定正确
3、溯因推理
将抽象的规则知识和观察现象结合,寻找可能的原因的推理过程

关注推理结果的可解释性。溯因推理是三种推理中最困难的一种,最近研究的也很多。目前的事理图谱(哈工大做的,可以部分具备溯因推理能力)
知识推理的任务
1、可满足性:检测一个实例或者关系的可满足性(是否成立)
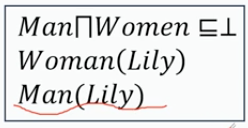
2、 分类:计算新的概念包含关系

3、实例化:计算某个概念或关系的实例集合
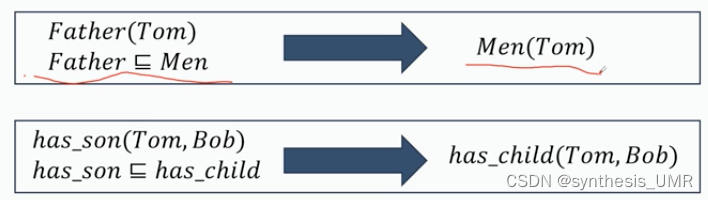
基于知识图谱的推理
主要关注围绕关系的推理,即基于图谱中已有事实或关系和推断未知的事实或者关系,一般着重考察实体,关系和图谱结构三个方面的特征信息。

7.2 基于规则的知识推理
演绎推理(人工定义): Tableaux,Datalog
归纳推理(机器学习):PRA,AMIE
7.2.1 演绎推理
1、Tableaux运算
适用于:检查某一本体概念的可满足性和实例检测
思想:构建一系列Abox(论断)来检测可满足性,或者检测某一实例是否存在于某概念。基本思想类似于一阶逻辑的归结反驳。
运算规则:
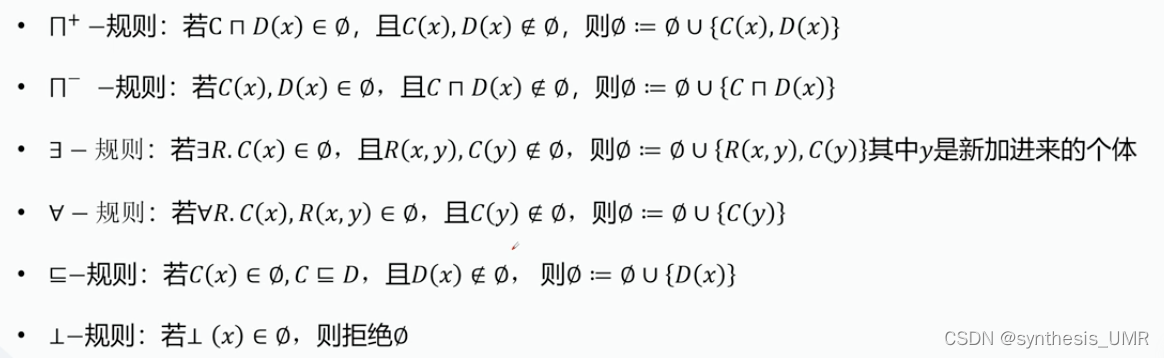
比如 合取plus:合取之后属于fai,各自不属于fai,那么合取之后可以加入到fai中。以此类推。

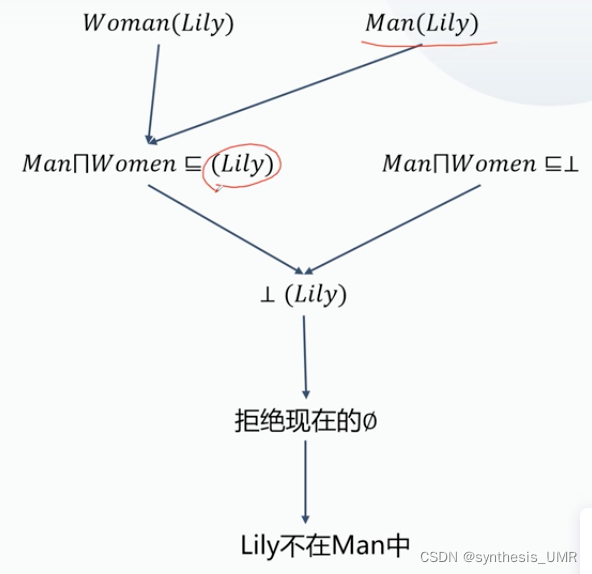

优势:表达清晰。
缺点:仅支持预定义的本体公理上的推理(无法针对自定义的词汇支持灵活推理)
用户无法定义自己的推理过程。因此我们引入规则推理Datalog:
可以根据特定的场景定制规则,实现用户自定义的推理过程。
2、Datalog语言
面向知识库和数据库设计的逻辑语言,表达能力和OWL相当。支持递归。
便于撰写规则,实现推理
事实+规则=结果 前身是Prolog
Datalog语法

由若干body原子得到了头原子

7.2.2 归纳推理
1、PRA路径排序算法 Path Ranking Algorithm
知识图谱推理本质上是面向知识图谱的一个链路预测任务。将实体间存在的路径作为判断实体间是否存在指定关系
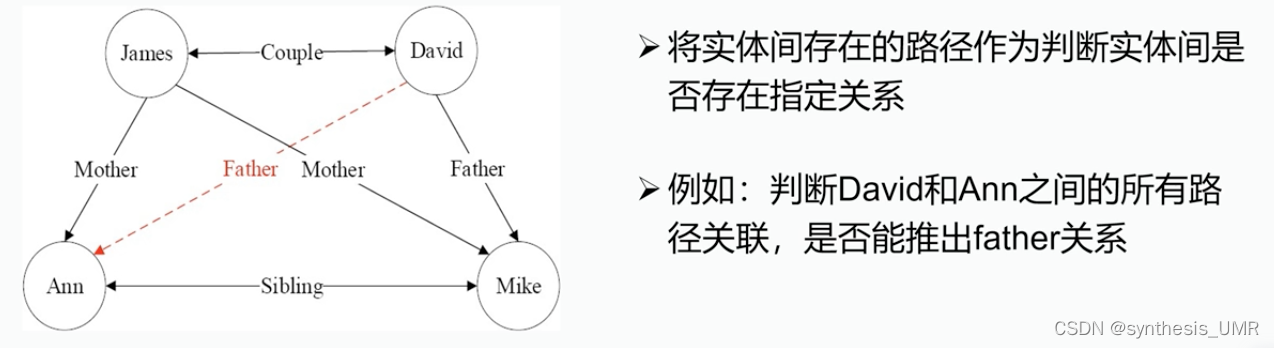
充分利用知识图谱的图结构信息。
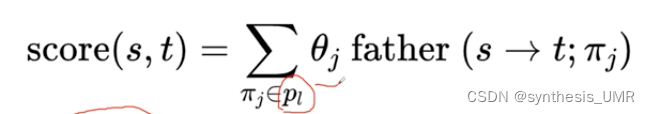

生成方法:
特征抽取:生成并选择路径特征集合。随机游走(从一个节点跳转到另一个随机节点,可以指定不二次访问的规则),BFS,DFS等
特征计算:计算每个训练样例的特征值可以是从s除法,通过paii到达t的概率,也可以表达为布尔值,表示他们之间是否存在路径。还可以是st之间路径出现的频次,频率等。
分类器训练:根据训练样例的特征值,为目标关系训练分类器。训练好分类器就可以将该分类器用于推理两个实体之间是否存在目标关系。
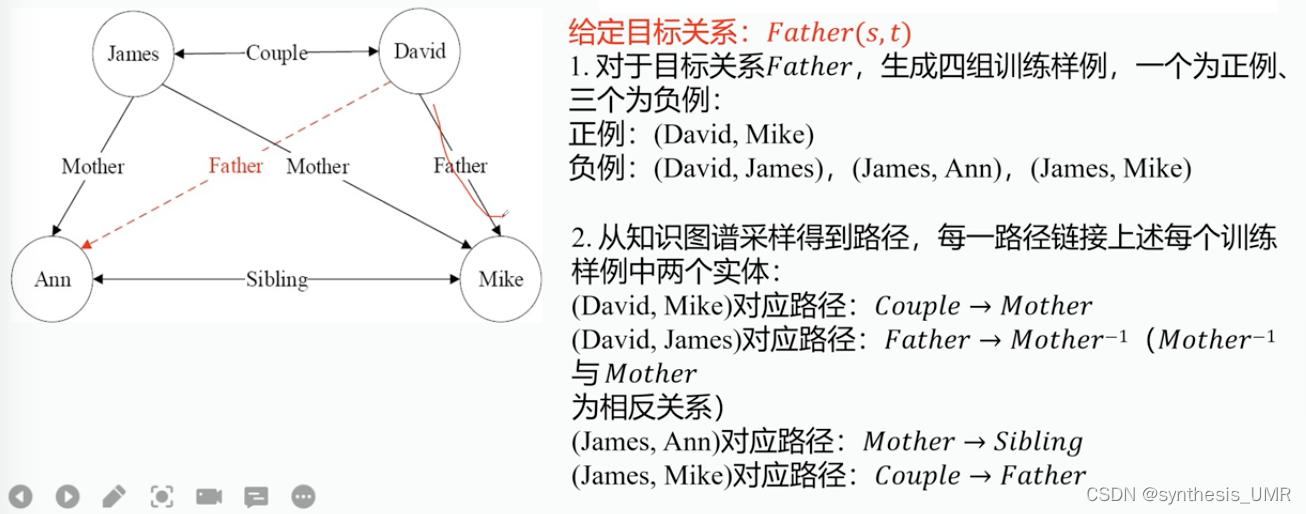
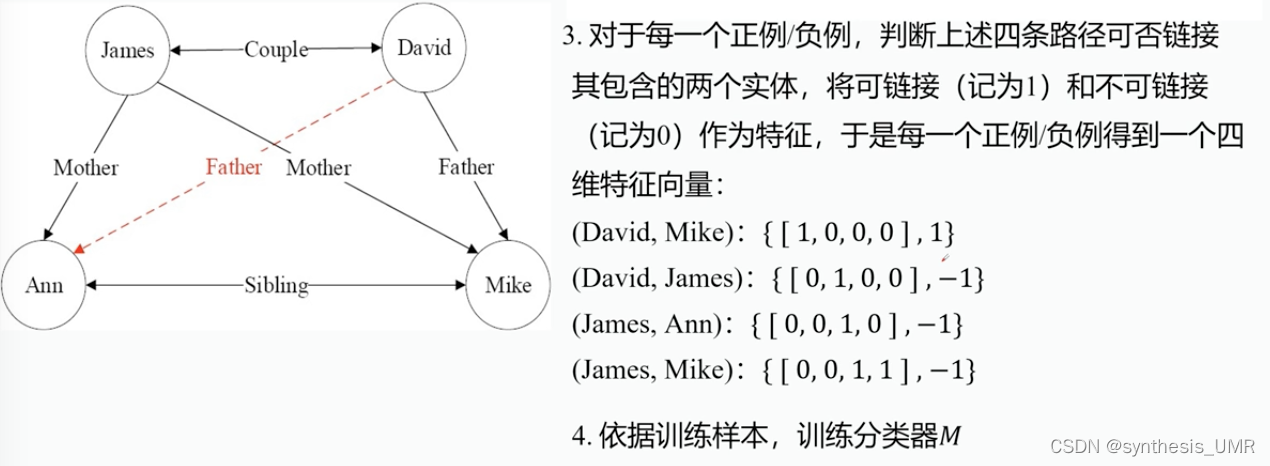
2、AMIE算法
规则挖掘算法:从不完备的知识库中挖掘规则
算法:对于美中关系,从规则体为空开始,通过三种扩展操作,保留置信度大于阈值的规则
三种扩展操作:添加悬挂边,添加实例边,添加闭合边

看一下PCA,x如果能连接到y以外的对象,把他放进分母中。也就是我把错误的考虑入分母中,从而降低pca的置信度。
三种扩展方式其实就是挖掘规则的方式:
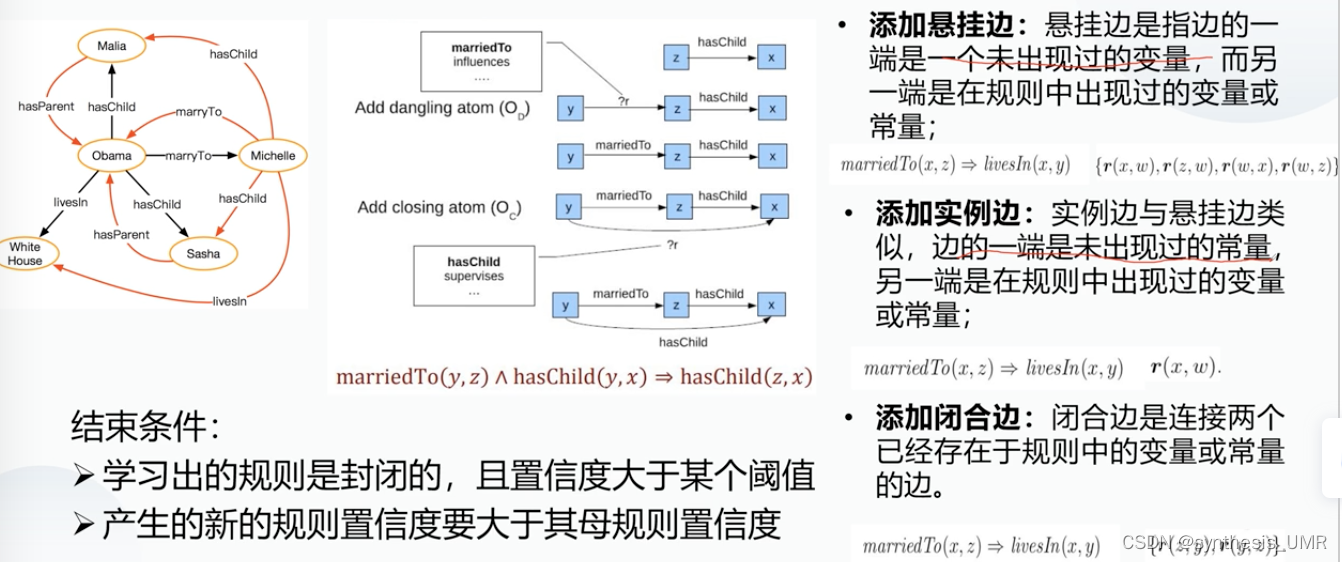
置信度每次都上升,这样就完成了学习的过程。
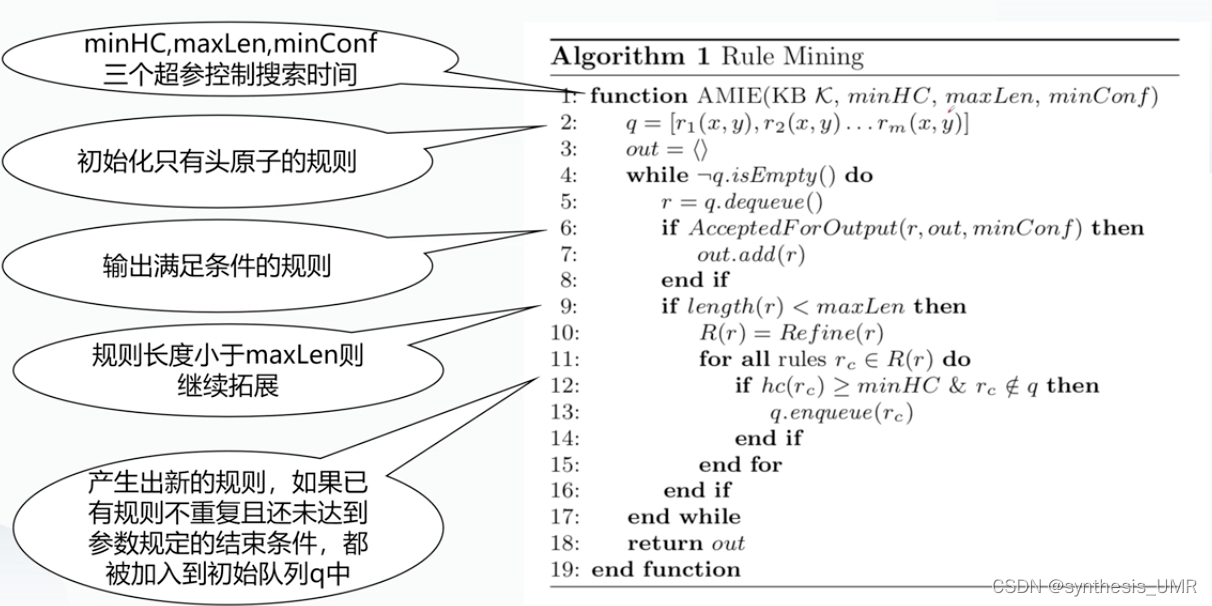
非常的快,1m的数据量3min可以挖掘出7000条规则。这个算法是非常优秀的。
7.3 基于嵌入式表示的知识推理
将图结构中隐含的关联信息映射到欧式空间,易于捕捉隐含的关联,但是可解释性较差。
典型的有:张量分解模型,距离模型。
7.3.1 张量分解
思想:使用张量分解对高维信息进行降维处理,得到低维向量表示,预测实体之间的关系。具有代表性的模型是RESCAL。这个模型的可解释性还是可以的。
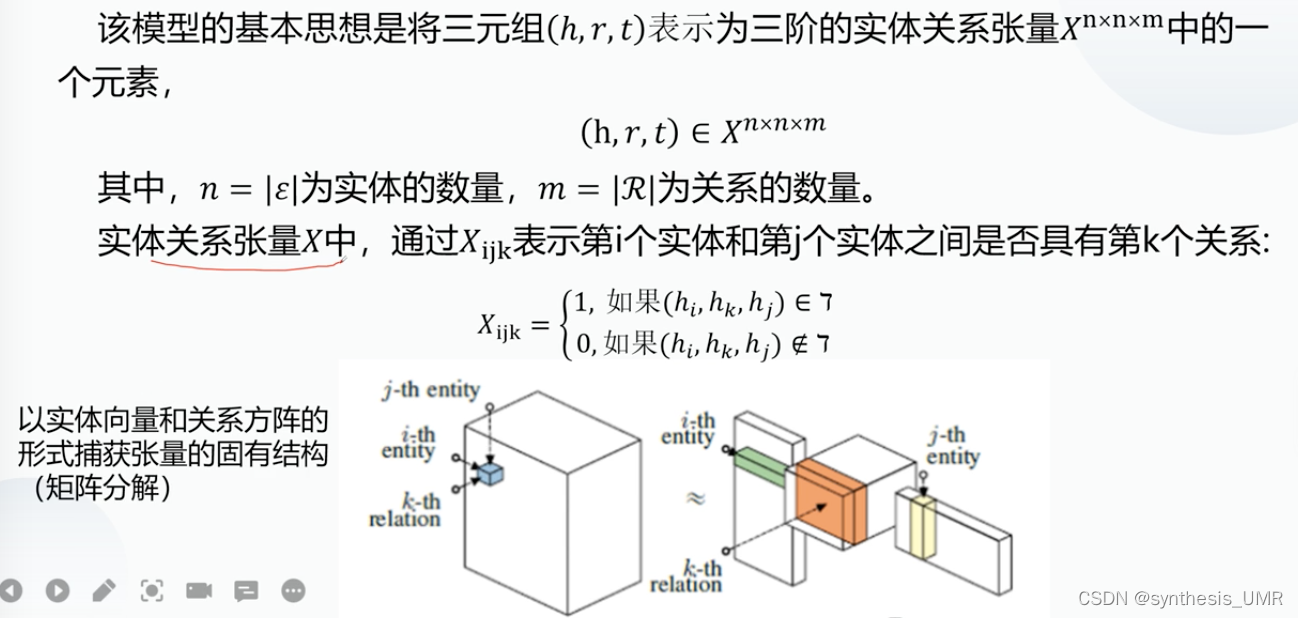
在RESCAL模型中,对于一个具有总共m个关系的知识图谱,其第k个关系切片可以分解为:
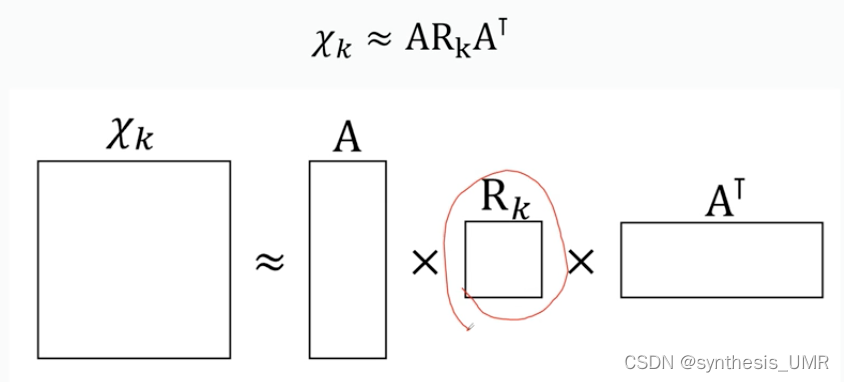
R是关系矩阵(邻接矩阵)
7.3.2 距离模型

7.4 基于神经网络的知识推理
Original: https://blog.csdn.net/synthesis_30/article/details/123207279
Author: synthesis_UMR
Title: 知识工程课程笔记
相关阅读
Title: 平衡车Car_Balance(一)——电机
目录
1.平衡小车——直流有刷减速电机(配置减速箱后的直流有刷电机)
一、电机简要概述
电机俗称马达,指依据电磁感应定律实现电能转换或传递的一种电磁装置。
二、常见电机种类
1.直流有刷电机(BDC,最最最常见的电机)
直流有刷电机:能够实现正反转、通过PWM调速。常用于精度要求比较低的场合。比如说:玩具车。
图:

优点:价格低、控制方便
缺点:结构复杂,可靠性差,故障多,维护工作量大,寿命短,换向火花易产生电磁干扰。
2.直流无刷电机(BLDC)
直流无刷电机:基于直流有刷电机发展而来,驱动电流有梯形波(方波)和正弦波两种。
方波驱动——直流无刷电机(BLDC)
正弦波驱动——永磁同步电机(PMSM),实际上就是伺服电机(下面有介绍)
图:

3.舵机
舵机:由直流电机、减速齿轮组、传感器、控制电路组成的一套自动控制系统。舵机只能在一点角度内转动,不能一圈圈转。常用于控制某物体转动一点角度,如机器人的关节。
如图:
4.步进电机
步进电机:将电脉冲转换成角位移的执行机构。也就是说,一个脉冲电机旋转一个角度,换而言是,脉冲数决定了旋转角度,脉冲频率决定了旋转速度。常用于一些有定位要求的场合,比如说:线切割的工作台拖动(精度要求不会非常高的场合)。
图:
优点:控制简单,低速扭矩大,成本低。
缺点:当脉冲高于一定频率,步进电机无法启动,并伴有尖锐的啸叫声,同时步进电机是开环控制,控制精度和速度都没有伺服电机那么高。(伺服电机和步进电机长得很像,伺服电机的控制方法和步进电机类似,但它是闭环控制的,因此它可以非常精确地控制角度和速度,而且它很贵很贵,常用于对角度、速度精度要求很高的场合,比如说机械臂)
三、平衡小车选用电机及需要关注的参数
1.平衡小车——直流有刷减速电机(配置减速箱后的直流有刷电机)
①平衡小车对旋转角度、速度精度要求都不太高,并且直流有刷电机易于控制、驱动电路简单、价格较低。
②为了增大电机的输出转矩,一般会给直流有刷电机配置一个减速箱,通过减速箱后电机的扭矩会大大增加,同时电机的转速会按一定比例下降。
③平衡车控制系统中采用了PID速度环控制算法,也就是说控制系统中需要电机速度的反馈,所以我们要在电机的输出端额外增加测速装置或电机自带的测速装置来实时获取电机转速。
综上平衡小车建议使用直流有刷减速电机。
2.我们设计电路和编写程序时需要关注的电机参数:
①额定电压:长时间工作时的最佳电压。
②额定转速:满载时的电机转速。
③减速比:是指减速机构中瞬时输入速度与输出速度的比值,如30:1,指直流有刷电机转动30圈,经过减速箱后,实际输出只转动1圈。
④测速装置的分辨率:电机输出轴转动一圈测速装置输出的信号数。
下一节我将和大家一起探讨电机的驱动电路。文章有不足的地方期盼大家指出,谢谢大家。
Original: https://blog.csdn.net/m0_65066988/article/details/122538139
Author: 曾老师的熊同学
Title: 平衡车Car_Balance(一)——电机