
一、meanshift
均值漂移就是把指定的样本点沿着密度上升的方向移向高密度区域。这里可以用矢量加法的几何意义来理解。参考博文Mean Shift 聚类算法
meanshift为
M r ( x ) = 1 k ∑ x i ∈ S r ( x ) ( x i − x ) M_r(x)=\frac{1}{k}\sum\limits_{x_i\in S_r(x)}(x_i-x)M r (x )=k 1 x i ∈S r (x )∑(x i −x )
其中S r ( x ) = { y : ∥ y − x ∥ < = r } S_r(x)={y:\|y-x\|,k k k是S r ( x ) S_r(x)S r (x )中点的个数。
更 新 x = x + M r ( x ) 更新x=x+M_r(x)更新x =x +M r (x )
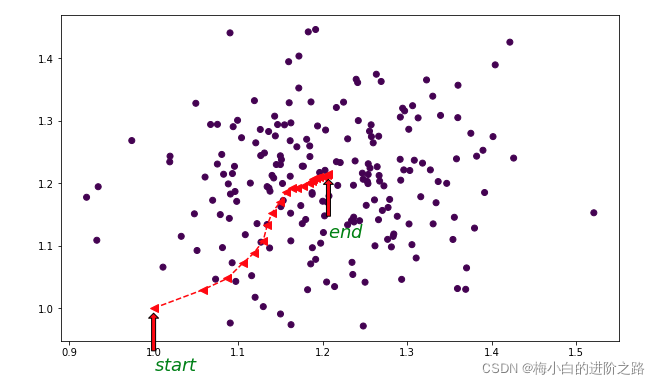
实现上图的python代码:
from sklearn.datasets import make_blobs
X1,y1=make_blobs(n_samples=200, n_features=2, centers=[[1.2, 1.2]],
cluster_std=[[.1]], random_state=9)
plt.scatter(X1[:,0],X1[:,1],c=y1)
def meanshift(point,X,r,eps):
pointNeigh=X[np.linalg.norm(X-point,axis=1)r]
shift=np.sum(pointNeigh-point,axis=0)/len(pointNeigh)
points=[point]
while np.linalg.norm(shift)>eps:
point=point+shift
pointNeigh=X[np.linalg.norm(X-point,axis=1)r]
shift=np.sum(pointNeigh-point,axis=0)/len(pointNeigh)
points.append(point)
return points
points=meanshift(np.array([1,1]),X1,0.1,0.000001)
points=np.array(points)
plt.figure(figsize=(10,6))
plt.scatter(X1[:,0],X1[:,1],c=y1)
plt.plot(points[:,0],points[:,1],'r,markersize=8)
plt.annotate(r'$start$', xy = (1, 1), xytext = (1, 0.9),
arrowprops = {
'headwidth': 10,
'headlength': 5,
'width': 4,
'facecolor': 'r',
'shrink': 0.1,
},
family='Times New Roman',
fontsize=18,
fontweight='bold',
color='green',
)
plt.annotate(r'$end$', xy = (points[-1][0],points[-1][1] ), xytext = (points[-1][0], points[-1][1]-0.1),
arrowprops = {
'headwidth': 10,
'headlength': 5,
'width': 4,
'facecolor': 'r',
'shrink': 0.1,
},
family='Times New Roman',
fontsize=18,
fontweight='bold',
color='green',
)
二、meanshift聚类
1.算法流程
需要给定的参数
bandwidth----带宽
Mindist—漂移均值收敛的阈值
center_distance----合并簇的阈值
第一阶段—聚类
需要初始化的集合
创建一个空的中心点集centers,用于存放各个簇所对应的中心点
创建一个空的集合results,用于存放各个簇所包含的点
1.将数据集X的点都标记为未访问unvisited;
2.从数据集X中取出一个点,记为point,判断它是否属于unvisited,如果属于,将其从unvisited删除,并进行第3步,否则重新从X取点;
3.创建一个空的集合result_point,用来存放point对应的簇中所包含的点;
4.从X中找到位于以point为中心,带宽为bandwidth之内的点,用neighbor表示;
5.判断neighbor是否为空集,则返回第2步,否则将neighbor中全部点加入到result_point中,并将这些点从unvisited中删除;
6.计算point在neighbor上的漂移均值meanshift;
7.判断shift是否大于给定的阈值Min-dist,如果大于,更新点point=point+shift并返回第4步,否则将point加入到centers,result_point加入到results中,再返回第2步//
第二阶段–合并
由第一阶段得到centers和相应的results。由于centers中有一些中心点之间的距离可能很小,我们需要将其所对应的簇合并成一个簇,并更新中心点。
第三阶段–分组
由于X中的点可能位于多个簇(result_point)中,我们需要确定其到底属于哪一个簇。
统计每个点在各个簇中所出现点次数,次数最高的簇就是该点最终所属的簇。
2.python代码
import math
def euclidean_dist(self,pointA,pointB):
""""""
if pointA.shape==pointB.shape:##pointA和pointB是两个点
return np.linalg.norm(pointA-pointB)
else:##pointA和pointB中有一个是点集
return np.linalg.norm(pointA-pointB,axis=1)
def gaussian_kernel(dist,bandwidth):
"""dist---欧式距离
bandwidth---带宽
"""
weight=(1/(np.sqrt(2*math.pi)*bandwidth))*np.exp(-(dist**2)/(2*np.power(bandwidth,2)))
return weight
def compute_shift(pointNeigh,point,bandwidth,kernel):
if kernel==False:
shift=np.sum(pointNeigh-point,axis=0)/len(pointNeigh)
else:
dists=np.linalg.norm(pointNeigh-point,axis=1)
point_weight=gaussian_kernel(dists,bandwidth)
point_weight=point_weight.reshape(len(point_weight),1)
shift=np.sum((pointNeigh-point)*point_weight,axis=0)/np.sum(point_weight)
return shift
def Clustering(X,bandwidth,MinDist,kernel=False):
"""init_result---各个簇所包含的点的索引,
init_centers--中心点"""
unvisited=list(np.arange(len(X)))
init_result=[]
init_centers=[]
for i in range(len(X)):
point=X[i]
if i in unvisited:
unvisited.remove(i)
c_i=[]
indexs=np.where(np.linalg.norm(X-point,axis=1)bandwidth)[0]
pointNeigh=X[indexs]
c_i.extend(indexs)
for j in list(indexs):
if j in unvisited:
unvisited.remove(j)
shift=compute_shift(pointNeigh,point,bandwidth,kernel)
while np.linalg.norm(shift)>MinDist:
point=point+shift
indexs=np.where(np.linalg.norm(X-point,axis=1)bandwidth)[0]
if len(indexs)==0:
break
pointNeigh=X[indexs]
c_i.extend(indexs)
for k in list(indexs):
if k in unvisited:
unvisited.remove(k)
shift=compute_shift(pointNeigh,point,bandwidth,kernel)
init_centers.append(point)
init_result.append(c_i)
return init_result,init_centers
def merge(init_centers,init_result,center_distance):
final_centers=[init_centers[0]]
final_result=[init_result[0]]
k=len(init_centers)
i=1
stats=True
while i<k:
for j in range(len(final_centers)):
if np.linalg.norm(init_centers[i]-final_centers[j])center_distance:
final_centers[j]=(init_centers[i]+final_centers[j])/2
final_result[j].extend(init_result[i])
stats=False
break
if stats==True:
final_centers.append(init_centers[i])
final_result.append(init_result[i])
i+=1
stats=True
return final_result,final_centers
def groupPoint(X,final_result,final_centers):
result_table=pd.DataFrame(np.zeros((len(X),len(final_centers))),index=range(len(X)),columns=range(len(final_centers)))
for i in range(len(final_centers)):
clusterI_index=final_result[i]
for j in range(len(clusterI_index)):
result_table.iloc[clusterI_index[j],i]+=1
result_id=np.argmax(result_table.values,axis=1)
return result_id
def plot(X,result_id,final_centers):
for i in range(len(final_centers)):
plt.scatter(X[result_id==i][:,0],X[result_id==i][:,1])
三、测试
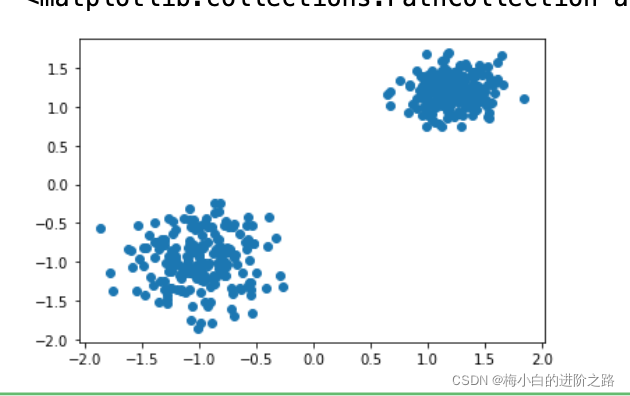
1.数据集一
from sklearn.datasets import make_blobs
X,y=make_blobs(n_samples=400, n_features=2, centers=[[1.2, 1.2],[-1,-1]],
cluster_std=[0.2,0.3], random_state=9)
plt.scatter(X[:,0],X[:,1])
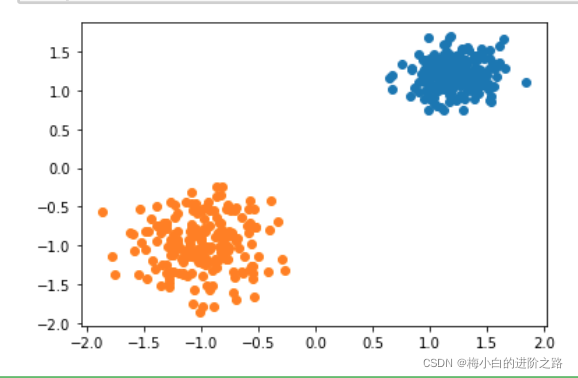
init_result,init_centers=Clustering(X,0.4,0.00001,kernel=True)
final_result,final_centers=merge(init_centers,init_result,1.2)
result_id=groupPoint(X,final_result,final_centers)
plot(X,result_id,final_centers)
2.数据集二
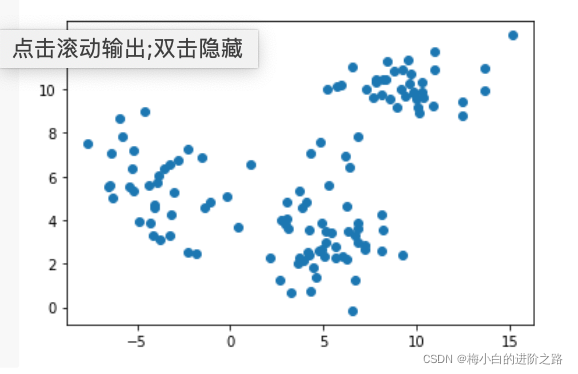
X_d=np.array(data)
init_result,init_centers=Clustering(X_d,4,0.00001,kernel=True)
final_result,final_centers=merge(init_centers,init_result,1.2)
result_id=groupPoint(X_d,final_result,final_centers)
plot(X_d,result_id,final_centers)
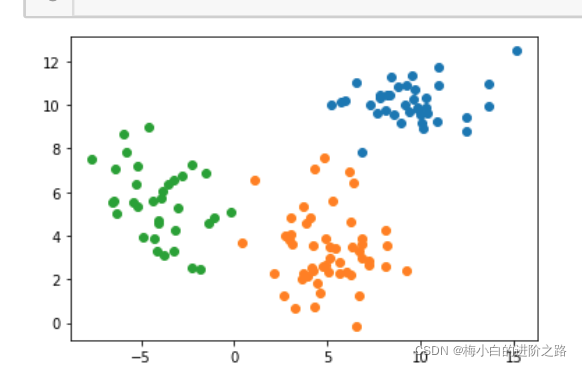
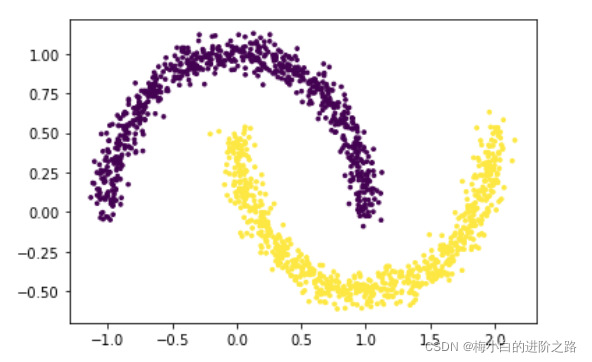
3. 数据集三
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
x,y = make_moons(n_samples=1500, shuffle=True,
noise=0.06, random_state=None)
plt.scatter(x[:,0], x[:,1], c=y, s=7)
plt.show()
init_result,init_centers=Clustering(x,0.5,0.00001,kernel=True)
final_result,final_centers=merge(init_centers,init_result,1.)
result_id=groupPoint(x,final_result,final_centers)
plot(x,result_id,final_centers)
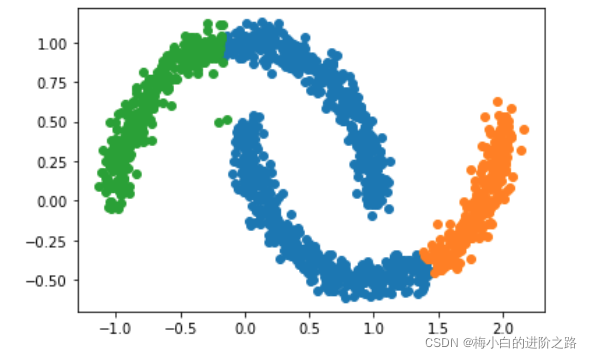
经过反复的调center_distance这个参数,都没有达到理想的聚类结果。
三、带有核函数的meanshift聚类
带有核函数的meanshift
m ( x ) = ∑ s ∈ S g ( ∥ s − x h ∥ 2 ) ( s − x ) ∑ s ∈ S g ( ∥ s − x h ∥ 2 ) m(x)=\frac{\sum\limits_{s\in S}g(\|\frac{s-x}{h}\|^2)(s-x)}{\sum\limits_{s\in S}g(\|\frac{s-x}{h}\|^2)}m (x )=s ∈S ∑g (∥h s −x ∥2 )s ∈S ∑g (∥h s −x ∥2 )(s −x )
更新中心坐标:
x = m ( x ) + x x=m(x)+x x =m (x )+x
四、疑点
如何能把用于合并簇的阈值参数取消掉。
Original: https://blog.csdn.net/m0_45411005/article/details/123376318
Author: 梅小白的进阶之路
Title: Meanshift均值漂移聚类算法
相关阅读
Title: TensorFlow基本知识及常用函数
张量(Tensor)
维度阶名字例子0-D0标量s=1 2 31-D1向量v = [1, 2, 3]2-D2矩阵m = [[1, 2, 3], [4, 5, 6]]n-Dn张量t = [[[ ...
- tf.int, tf.float ... tf.int32 tf.float32 tf.float64
- tf.bool tf.constant([True, False])
- tf.string tf.constant("Hello")
tf.constant(张量内容, dtype=数据类型(可选))
tf.convert_to_tensor(数据名, dtype=数据类型(可选))
tf.zeros(维度)
tf.ones(维度)
tf.fill(维度, 指定值)
tf.random.normal(维度, mean=均值, stddev=标准差)
tf.random.truncated_normal(维度, mean=均值, stddev=标准差)
tf.random.uniform(维度, minval=最小值, maxval=最大值)
tf.cast(张量名, dtype=数据类型)
tf.reduce_min(张量名)
tf.reduce_max(张量名)
在一个二维张量或数组中,可以通过调整axis等于0或1控制执行维度
- axis=0表示跨行(第一个维度, x轴),axis=1表示跨列(第二个维度, y轴)
- 如果不指定axis,则所有元素参与运算
tf.reduce_mean(张量名, axis=操作轴)
tf.reduce_sum(张量名, axis=操作轴)
tf.Variable()将变量标记为"可训练的",被标记的变量会在反向传播中记录梯度信息。神经网络训练中,常用该函数标记待训练参数。
tf.Variable(初始值)
w = tf.Variable(tf.random.normal([2, 2], mean=0, stddev=1))
对应元素的四则运算: tf.add, tf.subtract, tf.multiply, tf.divide
平方、次方和开方: tf.square, tf.pow, tf.sqrt
矩阵乘: tf.matmul
tf.add(张量1, 张量2)
tf.subtract(张量1, 张量2)
tf.multiply(张量1, 张量2)
tf.divide(张量1, 张量2)
data = tf.data.Dataset.from_tensor_slices((输入特征, 标签))
with tf.GradientTape() as tape:
grad = tape.gradient(函数, 对谁求导)
enumerate(列表名)
seq = ["one", "two", "three"]
for i, element in enumerate(seq):
print(i, element)
0 one
1 two
2 three
tf.one_hot(待转换数据, depth=几分类)
classes = 3
labels = tf.constant([1, 0, 2])
output = tf.one_hot(labels, depth=classes)
print(output)
[[0. 1. 0.]
[1. 0. 0.]
[0. 0. 1.]], shape=(3, 3), dtype=float32
tf.nn.softmax(x)
y = tf.constant([1.01, 2.01, -0.66])
y_pro = tf.nn.softmax(y)
print(y_pro)
tf.Tensor([0.25598174 0.69593046 0.0481878], shape=(3,), dtype=float32)
w.assign_sub(w要自减的内容)
tf.argmax(张量名, axis=索引号)
Original: https://blog.csdn.net/apple_52296856/article/details/120930706
Author: 9ack!?
Title: TensorFlow基本知识及常用函数