
2 k 均值聚类
目录
一 引言
无监督机器学习算法通常用于从复杂的大数据集中提取关键的结构或者内容信息,这些算法对手动输入的要求很低或无要求,并且不需要训练数据(也就是说用一些列带标签的解释变量和影响变量来训练算法,以识别所需要的分类边界),这意味着无监督算法能够有效的生成新数据或陌生数据集的结构和内容信息,以便分析师在短时间内深入理解数据
二 关于聚类分析简单入门那些事
聚类可能是最典型的无监督学习技术
聚类算法执行高效,算法实现的平滑复杂度在多项式级别,这使得同时执行多个聚类过程变得没那么复杂,即便是在大规模数据集上;此外,可扩展的实现方法也是存在的,他们可以在TB级的大规模的数据集上并行运行聚类算法
最常用的聚类算法是K均值,通过在数据空间中随机确定k个点,该算法可以构建k个簇,每个点都是对应k个簇的均值,然后可以进行如下循环过程
- 根据(簇内)最小平方和原则,也就是我们说的距离最近原则,将数据点分配至不同的簇
- 将每个簇的中心点(质心)作为新的均值,这会导致均值的位置发生变化
经过足够多的迭代后,质心就会移到能使性能指标(最常用的是簇内最小平方和指标)最小化的位置,此时观测点不会再随迭代而变化,算法也得到收敛,从而得出聚类的一个解
三 Start 聚类分析
# 聚类分析
from time import time
import numpy as np
import matplotlib.pyplot as plt
np.random.seed()
data = scale(digits.data)
n_samples,n_features = data.shape
n_digits = len(np.unique(digits.target))
labels = digits.target
sample_size = 300
print("n_digits: %d, \t n_samples %d, \t n_features %d" % (n_digits,n_samples,n_features))
print(79 * '_')
print('% 9s' % 'init''time inertia homo compl v-meas ARI AMI silhouette')
def bench_k_means(estimator,namendata):
t0 = time()
estimator.fit(data)
print('% 9s %.2fs %i %.3f %.3f %.3f %.3f %.3f %.3f'
% (name, (time() - t0),estimator.inertia_,
metrics.homogeneity_score(labels, estimator.labels_),
metrics.completeness_score(labels, estimator.labels_),
metrics.v_measure_score(labels, estimator.labels_),
metrics.adjusted_rand_score(labels, estimator.labels_),
metrics.silhouette_score(data, estimator.labels_,
metric = 'euclidean',
sample_size = sample_size)))
print(bench_k_means)
# 主成分分析
import numpy as np
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import scale
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
import matplotlib.cm as cm
digits = load_digits()
data = digits.data
n_samples,n_features = data.shape
n_digits = len(np.unique(digits.target))
labels = digits.target
pca = PCA(n_components = 10)
data_r = pca.fit(data).transform(data)
print('explained variance ratio (first two components): %s' %
str (pca.explained_variance_ratio_))
print('sum of explained variance (first two components): %s' %
str (sum(pca.explained_variance_ratio_)))
聚类分析代码与主成分分析代码的关键区别是 聚类分析代码先对digits数据集应用了标准化函数,将数据集的值限制在0-1,必须在有必要时对数据进行标准化,既可以是对数据的标准化,也可以是边界限制的标准化,以防止不同量级变量的变量值对数据集造成不成比例的重大影响
数据集是否需要进行标准化(以及采用何种标准化、标准化到什么范围)很大程度上取决于数据的形态和性质
如果数据的分布中出现了离群点或者是大范围的波动,那么应用对数据标准化更为合适
通过可视化和探索性分析还是统计分析结果来进行手动标准化,标注化决策往往与数据以及使用的分析方法紧密相关
scikit-learn 的有点就是默认应用k均值++算法,其兼顾了运行时间效率和聚类成功率,完美的避开了聚类糟糕的结果
k均值++算法通过运行初始化过程来寻找逼近簇内最小方差的簇质心
聚类算法的成功可以定义为 其能够解释数据中蕴含的分组方式,而这些方式会受到包括类的分离度、组间相似性和组间差异在内的各种因素的影响
同质性得分 是指一个取值在0-1的简单指标,用于度量簇内的数据点仅归属于某一类的程度;1代表所有簇内的数据点都属于同一类,该指标可与完整性得分一起使用,后者是一个类似的有界指标,度量给定类的成员被分配到同一个簇的程度,因此,完整性得分和同质性得分都为1的聚类就是完美的聚类
有效性测度(v值) 是指同质性得分和完整性得分的调和平均数,与二元分类的F值非常相似,其本质是用一个0-1范围内的值来代表聚类的同质性和完整性
调整兰德指数(ARI) 是一个相似性的指标,用于表示数据点集合间的一致性,对聚类分析来说,该指标度量的是已知的真实数据标签和基于聚类算法的预测标签之间的一致性,兰德指数在0-1有界范围内度量标签的相似性,代表完美的预测了标签
上述所有的性能指标和其他相似性指标都是基于真实情况理解的,也就是说,他们要求被分析的部分数据或者全部数据是需要具有标签的,如果标签不存在或者无法生成,那么这些方法都是无效的,这是一个极大地劣势
无需标注数据就可以度量k均值聚类效果的一种指标是轮廓系数,它能度量模型内聚类的明确程度,数据集的轮廓系数指的是每个样本系数的均值
- a样本和簇内其他所有数据点的距离的均值
- b 样本和最近邻簇内所有数据点的距离的均值
该公式的取值范围是 -1 - 1;其中 -1 代表错误聚类,1 代表密度极大的聚类,0 代表重叠聚类
对digits数据集上初始化 bench_k_means 函数
from time import time
import numpy as np
import matplotlib.pyplot as plt
np.random.seed()
data = scale(digits.data)
n_samples,n_features = data.shape
n_digits = len(np.unique(digits.target))
labels = digits.target
sample_size = 300
print("n_digits: %d, \t n_samples %d, \t n_features %d" % (n_digits,n_samples,n_features))
print(79 * '_')
print('% 9s' % 'init'' time inertia homo compl v-meas ARI AMI silhouette')
def bench_k_means(estimator,name,data):
t0 = time()
estimator.fit(data)
print('% 9s %.2fs %i %.3f %.3f %.3f %.3f %.3f %.3f'
% (name, (time() - t0),estimator.inertia_,
metrics.homogeneity_score(labels, estimator.labels_),
metrics.completeness_score(labels, estimator.labels_),
metrics.v_measure_score(labels, estimator.labels_),
metrics.adjusted_rand_score(labels, estimator.labels_),
metrics.silhouette_score(data, estimator.labels_,
metric = 'euclidean',
sample_size = sample_size)))
bench_k_means(KMeans(init = 'k-means++',n_clusters = n_digits,n_init = 10),
name = "k-means++",data = data)
print(79 * '_')
我们应用前面的主成分分析技术为输入数据进行降维
from time import time
import numpy as np
import matplotlib.pyplot as plt
np.random.seed()
data = scale(digits.data)
n_samples,n_features = data.shape
n_digits = len(np.unique(digits.target))
labels = digits.target
sample_size = 300
print("n_digits: %d, \t n_samples %d, \t n_features %d" % (n_digits,n_samples,n_features))
print(79 * '_')
print('% 9s' % 'init'' time inertia homo compl v-meas ARI AMI silhouette')
def bench_k_means(estimator,name,data):
t0 = time()
estimator.fit(data)
print('% 9s %.2fs %i %.3f %.3f %.3f %.3f %.3f %.3f'
% (name, (time() - t0),estimator.inertia_,
metrics.homogeneity_score(labels, estimator.labels_),
metrics.completeness_score(labels, estimator.labels_),
metrics.v_measure_score(labels, estimator.labels_),
metrics.adjusted_rand_score(labels, estimator.labels_),
metrics.silhouette_score(data, estimator.labels_,
metric = 'euclidean',
sample_size = sample_size)))
bench_k_means(KMeans(init = 'k-means++',n_clusters = n_digits,n_init = 10),
name = "k-means++",data = data)
print(79 * '_')
pca = PCA(n_components = n_digits).fit(data)
bench_k_means(KMeans(init = pac.components_,n_clusters = 10),
name = "PAC-based",
data = data)
四 调参
我们可以使用不同的k值重新运行前面的代码,并观察性能测量方法的值,但这无法告诉我们最能捕捉数据特征的k值是多少;k值调整存在的风险是 ——随着k的增大,轮廓系数或未解释方差可能会大幅减小,但我们无法得到有意义的聚类;极端情况 当 k = o 时(o为样本数据的观测数),当每个数据点都自成一簇时,轮廓系数会很小,但聚类结果毫无意义,此外还有许多k值导致过度拟合的例子
为缓解风险,可以使用辅助方式(如肘部图),先确定k的几个可能取值,肘部方法只需绘制解释方差随k值变化的图像即可
import numpy as np
from sklearn.cluster import Kmeans
from sklearn.datasets import load_digits
from scipy.spatial.distance import cdist
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import scale
digits = load_digits()
data = scale(digits.data)
n_samples,n_features = data.shape
n_digits = len(np.unique(digits.target))
labels = digits.target
K = range(1,20)
explainedvariance = []
for k in K:
reduced_data = PCA(n_components = 2).fit_transform(data)
kmeans = KMeans(init = 'k-maens++',n_clusters = k,n_init = k)
explainedvariance.append(sum(np.min(cdist(
reduced_data,kmeans.cluster_centers_,'euclidean'),axis = 1))/data.shape[0])
plt.plot(K,meandistortions,'bx-')
plt.show()
肘部图方法原理 选择能使解释方差达到最大、k达到最小的值。其中k是"肘"的拐弯处的值;其技术含义是 随着k的增大,解释方差的最小增长会与过度拟合的风险相抵消
肘部图的方法本质上是一种启发式探索,除了应用肘部图的方法,还可以观察聚类本身,使用主成分方法对数据进行降维
对数据集进行可视化、对数据映射聚类分配后,我们很容易发现,k均值聚类何时能找到局部最小值、何时会过度拟合
肘部图的另一个缺点 通过绘图检验聚类效果非常手工化,并且不适合生产环境或自动化,在这些情况下,更理想的方法是基于代码的可自动化方法,比如应用广泛的v重交叉验证
# 交叉验证
首先将数据集分为v份,其中一份用作测试集,然后用剩下的 v - 1 份数据来训练模型
# cv 交叉验证的参数;n_iter 循环次数;60%作为训练集;40%作为测试集
import numpy as np
from sklearn import cross_validation
from sklearn.datasets import load_digits
from sklearn.preprocessing import scale
from sklearn.cluster import Kmeans
digits = load_digits()
data = scale(digits.data)
n_samples,n_features = data.shape
n_digits = len(np.unique(digits.target))
labels = digits.target
kmeans = KMeans(init = 'k-maens++',n_clusters = n_digits,n_init = n_digits)
cv = cross_validation.ShuffleSplit(n_samples,n_iter = 10,test_size = 0.4,
random_state = 0)
scores = cross_validation.cross_val_score(kmeans,data,labels,cv = cv,
scoring = 'adjusted_rand_score')
print(scores)
print(sum(scores)/cv.n_iter)
大多情况下,我们无法得到数据集的实际标签,因此不得不使用轮廓系数的方法;当我们在分析陌生数据时,对于不同的k值,算法可能会错误解析某些噪声或者次级信号,并掩盖需要分析的信号
Original: https://blog.csdn.net/waywardG/article/details/122669046
Author: Persistent J
Title: 统计学习方法 -无监督学习(二)
相关阅读
Title: 世界坐标系、相机坐标系、图像坐标系、像素坐标系
四个坐标系都是什么?
1.世界坐标系->相机坐标系->图像坐标系->像素坐标系
2.像素坐标系->图像坐标系->相机坐标系->世界坐标系
图像处理、立体视觉等等方向常常涉及到四个坐标系:世界坐标系、相机坐标系、图像坐标系、像素坐标系

构建世界坐标系只是为了更好的描述相机的位置在哪里,在双目视觉中一般将世界坐标系原点定在左相机或者右相机或者二者X轴方向的中点。
接下来的重点,就是关于这几个坐标系的转换。也就是说,一个现实中的物体是如何在图像中成像的。
四个坐标系之间的相互转换
1. 从世界坐标系到相机坐标系
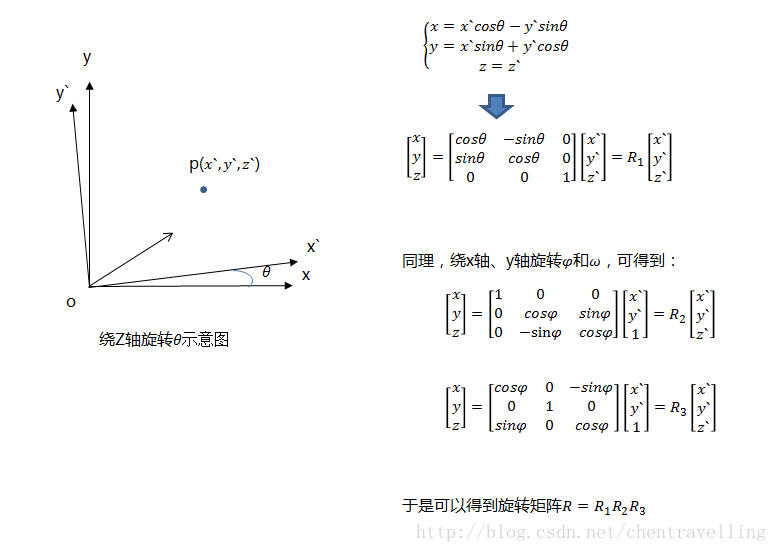
其中[ x ′ , y ′ ] 为世界坐标系下的坐标,将世界坐标系顺时针旋转θ得到相机坐标系,将[ x ′ , y ′ ]在相机坐标系下的坐标记为[ x , y ]。z轴坐标不发生改变。相当于我们沿z轴做旋转。
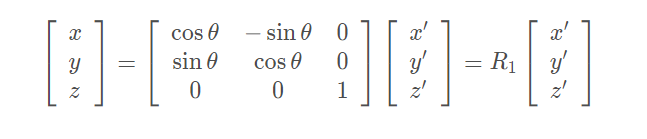
如果将世界坐标系逆时针旋转θ得到相机坐标系,此时得到坐标变换过程为:
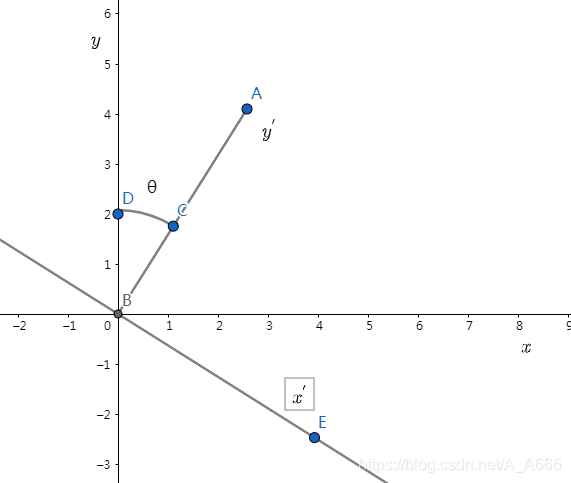
此时,我们
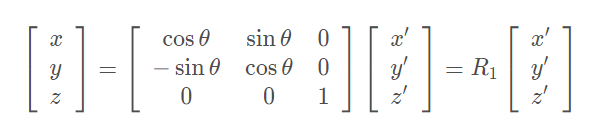
同理我们沿着剩下的两个坐标轴x和y进行旋转得到可以有剩下的两个变换矩阵R2和R3,那么我们从世界坐标系变换到相机坐标系所需要进行的变换是R = R1R2R3
这样我们就得到了,沿着Z轴方向旋转后的相机坐标new,和世界坐标wold之间的转换关系。
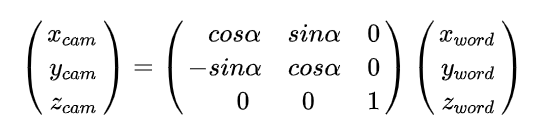
同理可得,沿着x轴和沿着y轴旋转的变化分别如下:
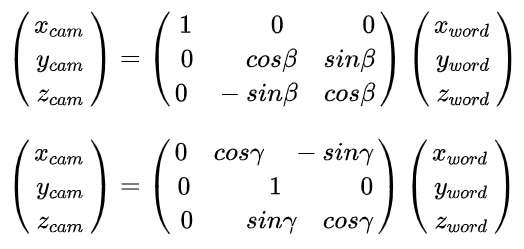
于是,新的相机坐标,即同时沿着x,y,z轴三个方向旋转的矩阵R如下:
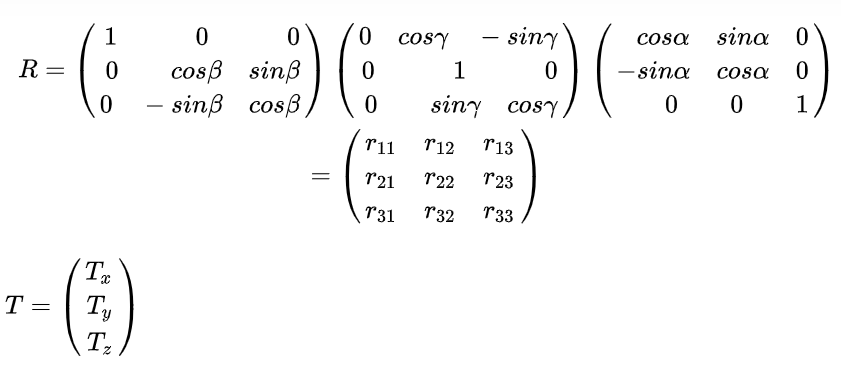
于是,世界坐标系到相机坐标系的转化可以写成:
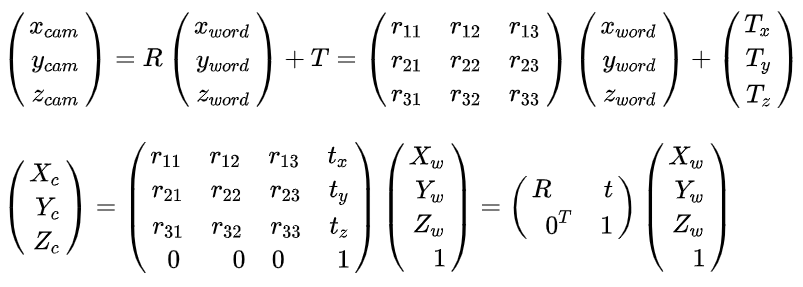
进行平移变换得到的结果为:
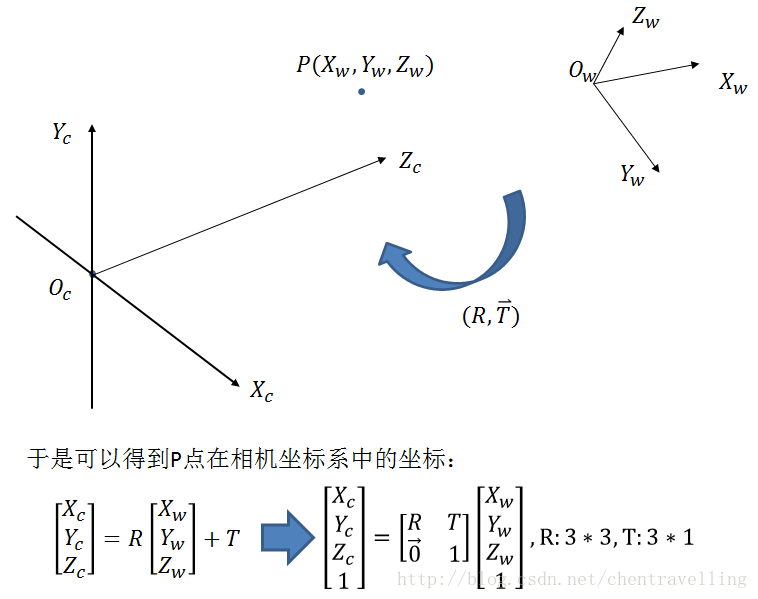
2. 从相机坐标系变换到图像坐标系,属于透视投影关系,从3D转换到2D。

此时投影点p的单位还是mm,并不是pixel,需要进一步转换到像素坐标系。
3. 从图像坐标系到像素坐标系。
像素坐标系和图像坐标系都在成像平面上,只是各自的原点和度量单位不一样。图像坐标系的原点为相机光轴与成像平面的交点,通常情况下是成像平面的中点或者叫principal point。图像坐标系的单位是mm,属于物理单位,而像素坐标系的单位是pixel,我们平常描述一个像素点都是几行几列。所以这二者之间的转换如下:其中dx和dy表示每一列和每一行分别代表多少mm,即1pixel=dx mm
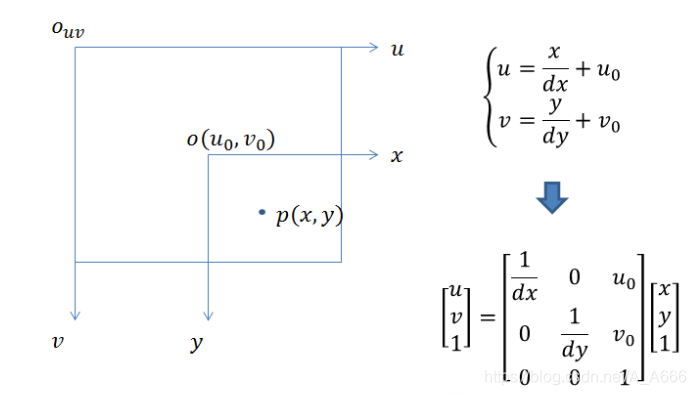
那么通过上面四个坐标系的转换就可以得到一个点从世界坐标系如何转换到像素坐标系的。
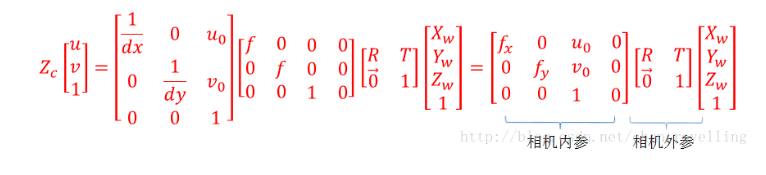
其中相机的内参和外参可以通过张正友标定获取,通过最终的转换关系来看,一个三维中的坐标点,的确可以在图像中找到一个对应的像素点,但是反过来,通过图像中的一个点找到它在三维中对应的点就很成了一个问题,因为我们并不知道等式左边的Zc的值。
其实在大多数时候,直接是像素坐标系和相机坐标系之间进行转换,因此可以将这两部分的转化矩阵合并,从而得到:
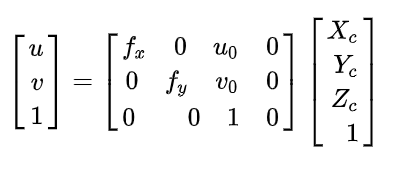
这样我们就完成了从世界坐标系到相机坐标系的一个转换,如果将 K1记录为相机的外参, K2为相机的内参。那么像素坐标系和世界坐标系可以之间的关系可以表示为如下的

像素坐标系->图像坐标系->相机坐标系->世界坐标系
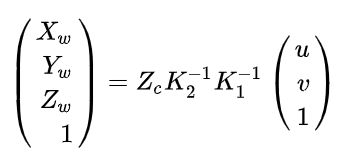
Original: https://blog.csdn.net/rukawashan/article/details/124811737
Author: rukawashan
Title: 世界坐标系、相机坐标系、图像坐标系、像素坐标系