
Jenkins Pipeline 的核心概念:
- Pipeline 是一套运行于
Jenkins上的 工作流框架,将原本独立运行于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程编排与可视化。 - Pipeline_是 _Jenkins2.X 的
最核心的特性,帮助 Jenkins 实现从CI到CD与DevOps的转变。 - _Pipeline_是一组插件,让
Jenkins可以实现 *持续交付管道的落地和实施。
持续交付管道(CD Pipeline)是将软件从版本控制阶段到交付给用户或客户的完整过程的自动化表现。软件的每一次更改(提交到源代码管理系统)都要经过一个复杂的过程才能被发布。
Pipeline_提供了一组可扩展的工具,通过 _Pipeline Domain Specific Language(DSL)syntax_可以达到 _Pipeline as Code(Jenkinsfile存储在项目的源代码库)的目的。
Pipeline入门:
先决条件
要使用Jenkins Pipeline,您将需要:
- Jenkins 2.x或更高版本
- Pipeline插件(请自行在插件管理中安装。)
_Pipeline_支持两种语法:
- Declarative 声明式
-
Scripted pipeline 脚本式

-
直接在Jenkins网页界面中输入脚本。
- 通过创建一个Jenkinsfile可以检入项目的源代码管理库。
用任一方法定义Pipeline的语法是一样的,但是Jenkins支持直接进入Web UI的Pipeline,通常认为最佳实践是在Jenkinsfile Jenkins中直接从源代码控制中加载Pipeline。
要在 Jenkins Web UI_中创建基本 _Pipeline:
- Stages:阶段组/Stage:阶段
- 一个 Pipeline 有多个 Stage 组成,每个 Stage 包含一组 Step。
- 注意一个 Stage 可以跨多个 Node 执行,即 Stage 实际上是 Step 的逻辑分组。
- 一个Jenkinsfile 可以分为大的阶段,如打包、构建、 部署。测试
- 构建的流程,可以分为这几步,获取源代码,然后打包,构建,进行编译,替换配置文件,编译完打包,进行部署 这个阶段就是stage
- Node:节点,一个Node就是一个Jenkins节点,或者是Master,或者是Agent,是执行Step的具体运行环境。
-
Steps:步骤,Step是最基本的操作单元,小到创建一个目录,大到构建一个Docker镜像,由各类Jenklins Plugin提供,例如:sh 'make'
-
块(blocks{}):
由大括号括起来的语句,如pipeline{},Section{},parameters{},script{} - 章节(Sections):
通常包含一个或多个指令或步骤。如 agent 、post、stages、steps - 指令(Directives):
environment、options、parameters、triggers(触发)、stage、tools、when - 步骤(Steps):
执行脚本式pipeline:在该语句块内使用script{} - agent
必须存在,agent必须在pipeline块内的顶层定义,但stage内是否使用是可选的
参数:any/none/label/node/docker/dockerfile
常用选项 label/cuetomWorkspace/reuseNode
指令名 说明 作用域 agent 定义执行任务的代理 stage 或pipeline input 暂停pipeline,提示输入内容 stage environment 设置环境变量 stage或pipeline tools 自动下载并安装指定的工具,并将其加入到PATH变量中 stage或pipeline options 配置Jenkins pipeline本身,如options{retry(3}},指pipeline失败时再重试2次 stage 或 pipeline build 触发其他的job steps when 定义阶段执行的条件 stage triggers 定义执行pipeline的触发器 pipeline parameters 执行pipeline前传入一些参数 pipeline parallel 并行执行多个step stage
示例:
- agent:
agent { label 'my-label' }
agent {
node {
label 'my-label'
customWorkspace '/some/other/path'
}
}
agent {
docker {
image 'application_name:verison'
label 'my-label'
args '-v /tmp:/tmp'
}
}
- stage间通过stash进行文件共享,即使stage不在同一个执行主机上:
pipeline{
agent none
stages{
stage('stash'){
agent { label "master" }
steps{
writeFile file: "a.txt", text: "$BUILD_NUMBER"
stash name: "abc", includes: "a.txt"
}
}
stage('unstash'){
agent { label "node" }
steps{
script{
unstash("abc")
def content = readFile("a.txt")
echo "${content}"
}
}
}
}
}
- steps中的一些操作:命令名 说明 error 抛出异常,中断整个pipeline timeout timeout闭包内运行的步骤超时时间 waitUntil 一直循环运行闭包内容,直到return true,经常与timeout同时使用 retry 闭包内脚本重复执行次数 sleep 暂停pipeline一段时间,单位为秒
pipeline{
agent any
stages{
stage('stash'){
steps{
timeout(50){
waitUntil{
script{
def r = sh script: 'curl http://xxx', returnStatus: true
return (r == 0)
}
}
}
retry(10){
script{
sh script: 'curl http://xxx', returnStatus: true
}
}
sleep(20)
}
}
}
}
- triggers:定时构建
pipeline {
agent any
triggers {
cron('H 9 * * *')
}
}
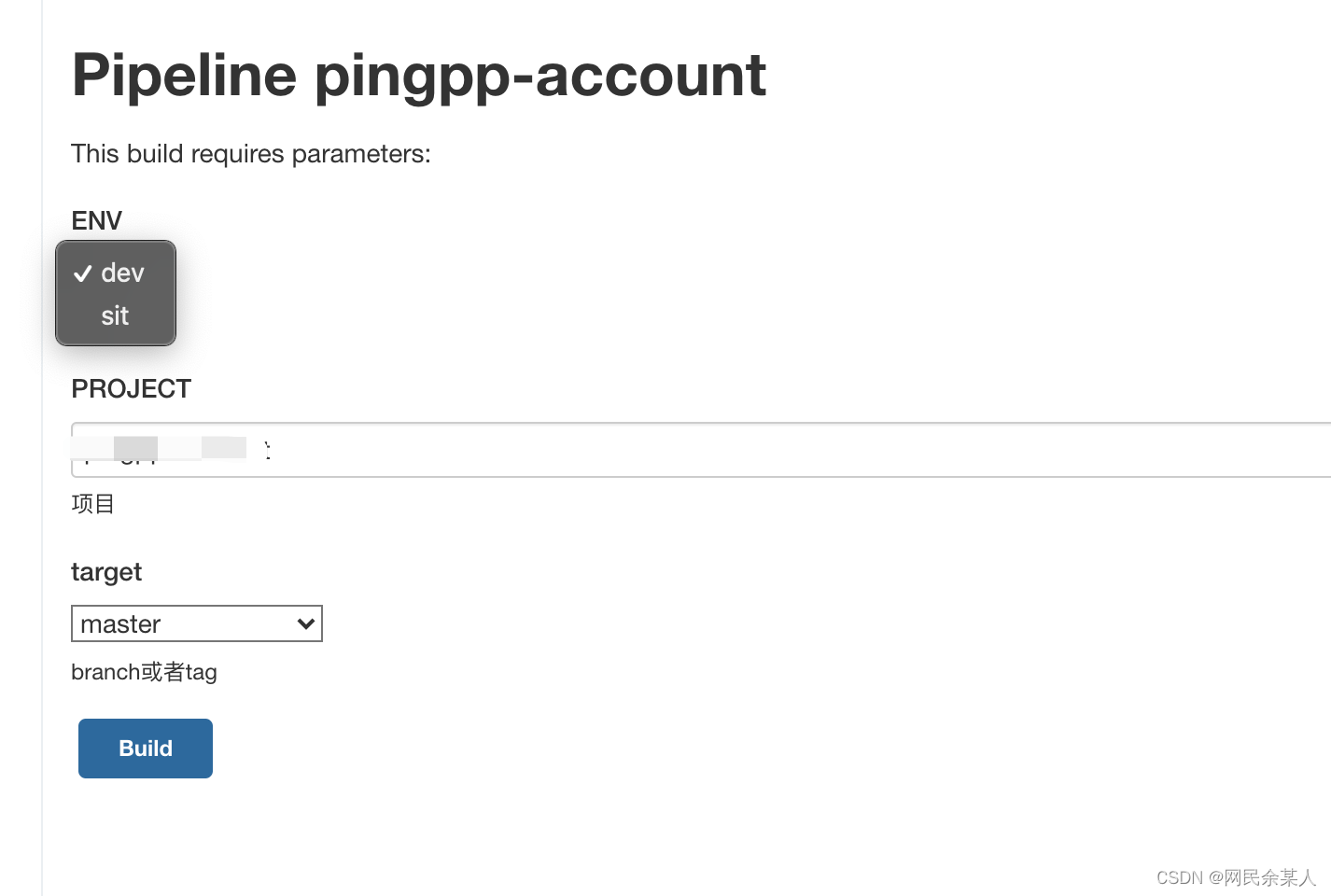
- paramparameters:参数化构建
- pipeline 脚本
pipeline {
agent any
parameters {
choice(name: 'ENV', choices: 'dev\nsit\nuat', description: '环境')
// 或者 choice(name: 'ENV', choices: ['dev','sit',uat'], description: '环境')
string(name: 'PROJECT', defaultValue: 'example-demo', description: '项目')
booleanParam(defaultValue: true, description: '', name: 'BOOLEAN')
text(defaultValue: '''this is a multi-line
string parameter example
''', name: 'MULTI-LINE-STRING')
}
stages {
stage('Hello') {
steps {
echo 'Hello World'
}
}
}
}
- web_ui配置:
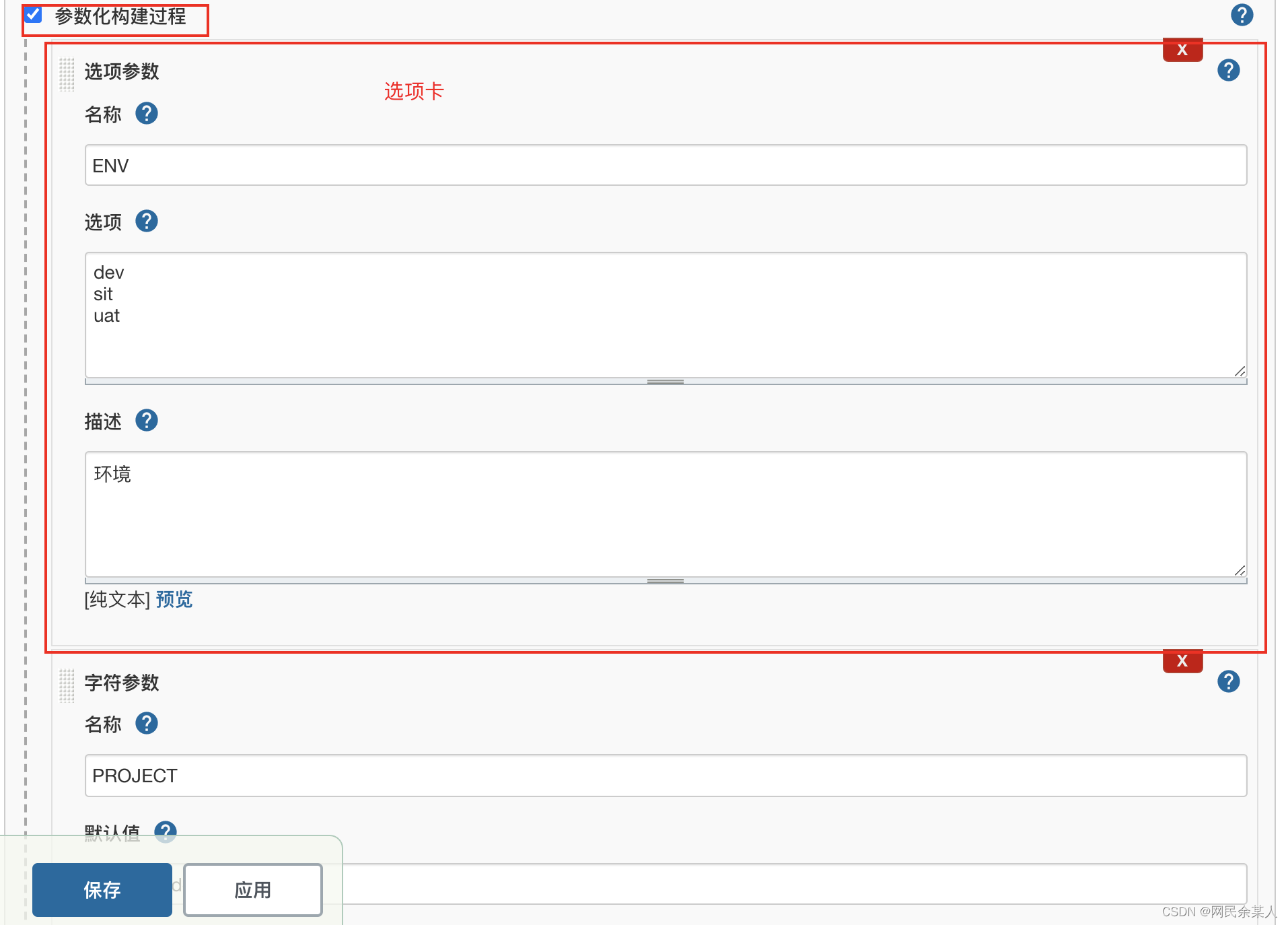
也可用于选择git分支/tag 进行发布- 添加参数类型为:
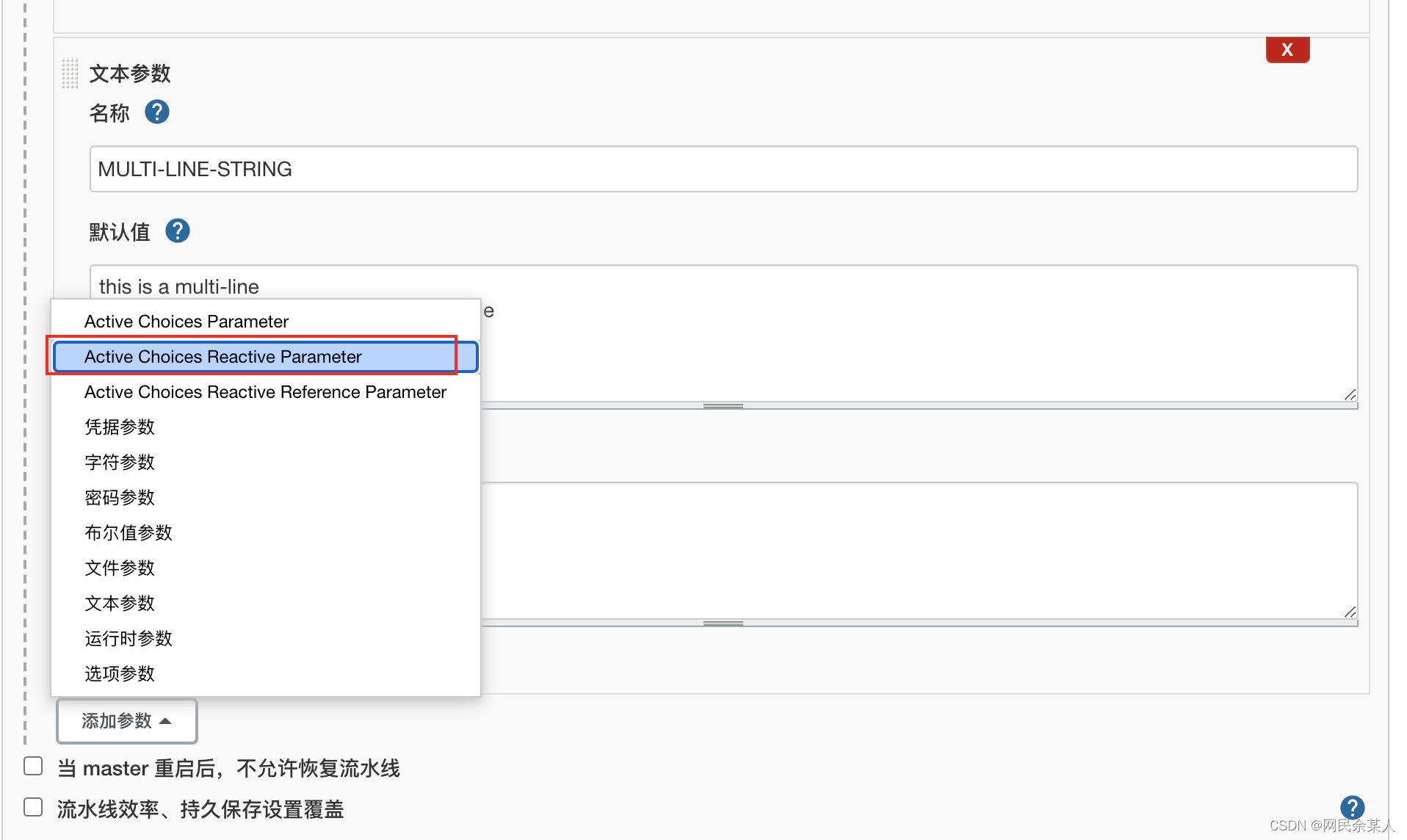
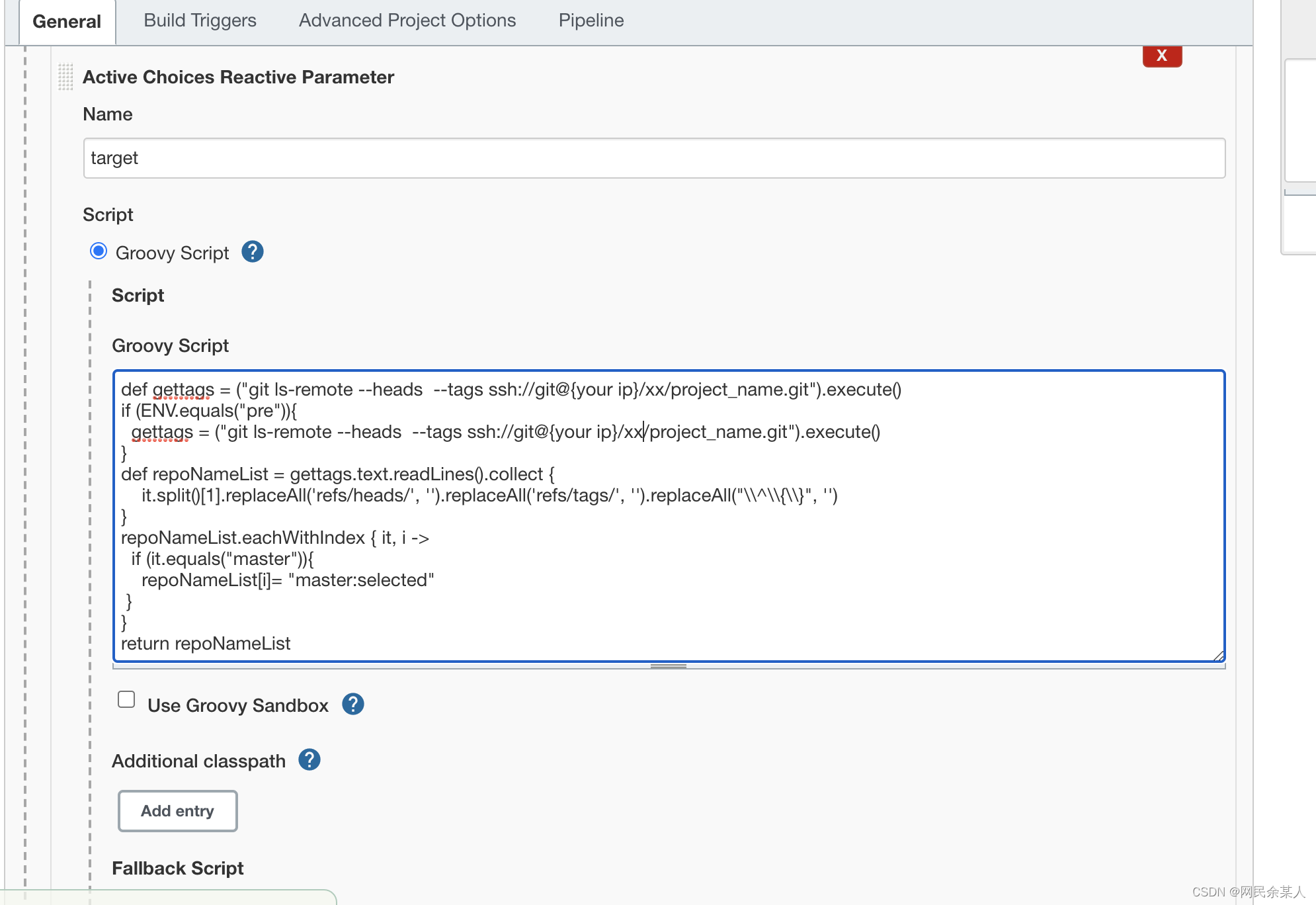
- 编写groovy脚本:
替换掉自己的git项目地址!
- 添加参数类型为:
def gettags = ("git ls-remote --heads --tags ssh://git@{ your ip }/xx/project_name.git").execute()
if (ENV.equals("pre")){
gettags = ("git ls-remote --heads --tags ssh://git@{ your ip }/xx/project_name.git").execute()
}
def repoNameList = gettags.text.readLines().collect {
it.split()[1].replaceAll('refs/heads/', '').replaceAll('refs/tags/', '').replaceAll("\\^\\{\\}", '')
}
repoNameList.eachWithIndex { it, i ->
if (it.equals("master")){
repoNameList[i]= "master:selected"
}
}
return repoNameList
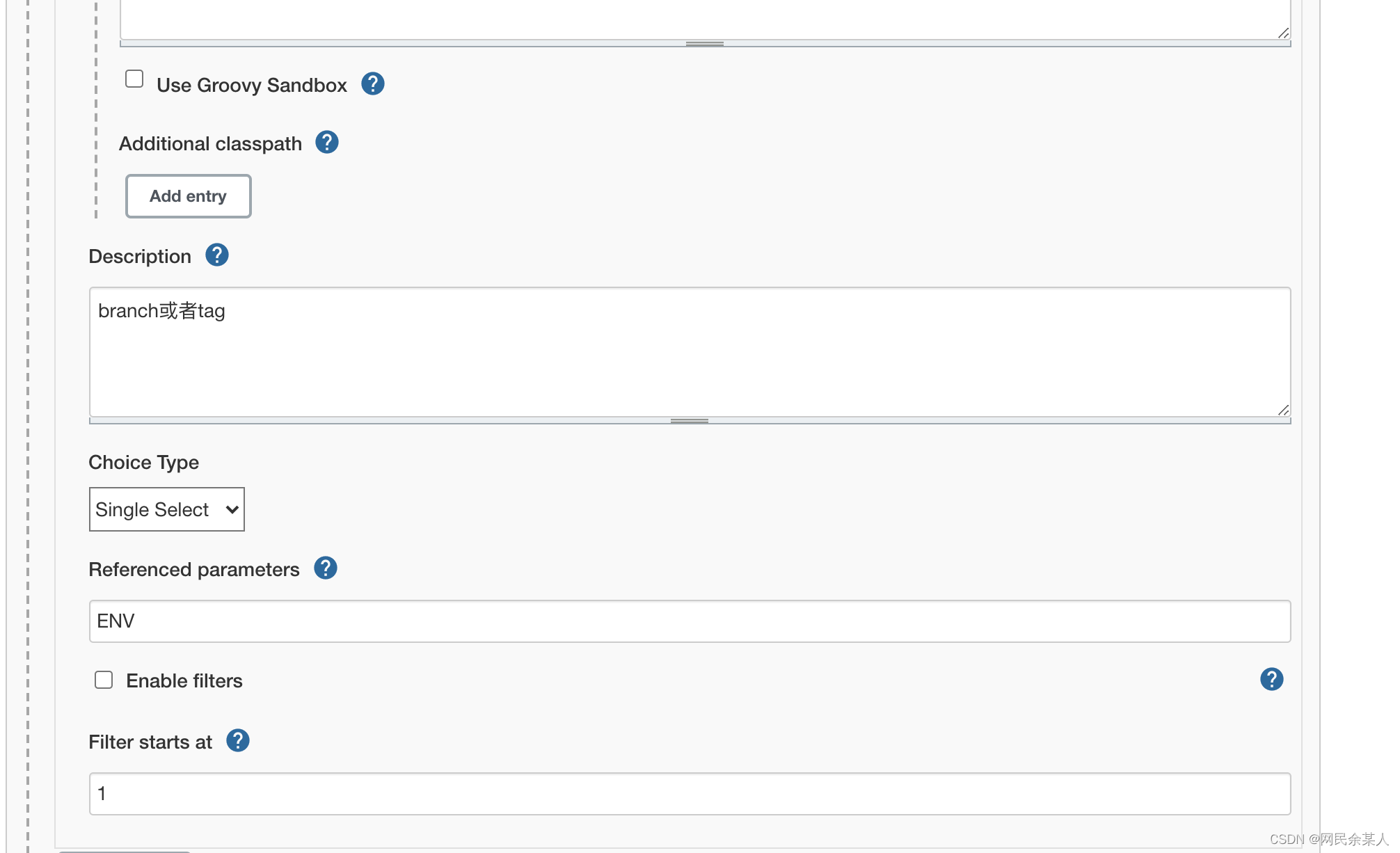 效果:
效果:
* post:后置操作
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Hello') {
steps {
sh 'ls'
}
post {
always {
echo '步骤Hello体里的post操作'
}
}
}
}
// post部分可以同时包含多种条件块。
post {
always {
echo '永远都会执行'
}
success {
echo '本次构建成功时执行'
}
unstable {
echo '构建状态为不稳定时执行。'
}
failure {
echo '本次构建失败时执行'
}
changed {
echo '只要本次构建状态与上一次构建状态不同就执行。'
}
fixed {
echo '上一次构建状态为失败或不稳定,当前完成状态为成功时执行。'
}
regression {
echo '上一次构建状态为成功,当前构建状态为失败、不稳定或中止时执行。'
}
aborted {
echo '当前执行结果是中止状态时(一般为人为中止)执行。'
}
cleanup {
echo '清理条件块。不论当前完成状态是什么,在其他所有条件块执行完成后都执行'}
}
}
效果: 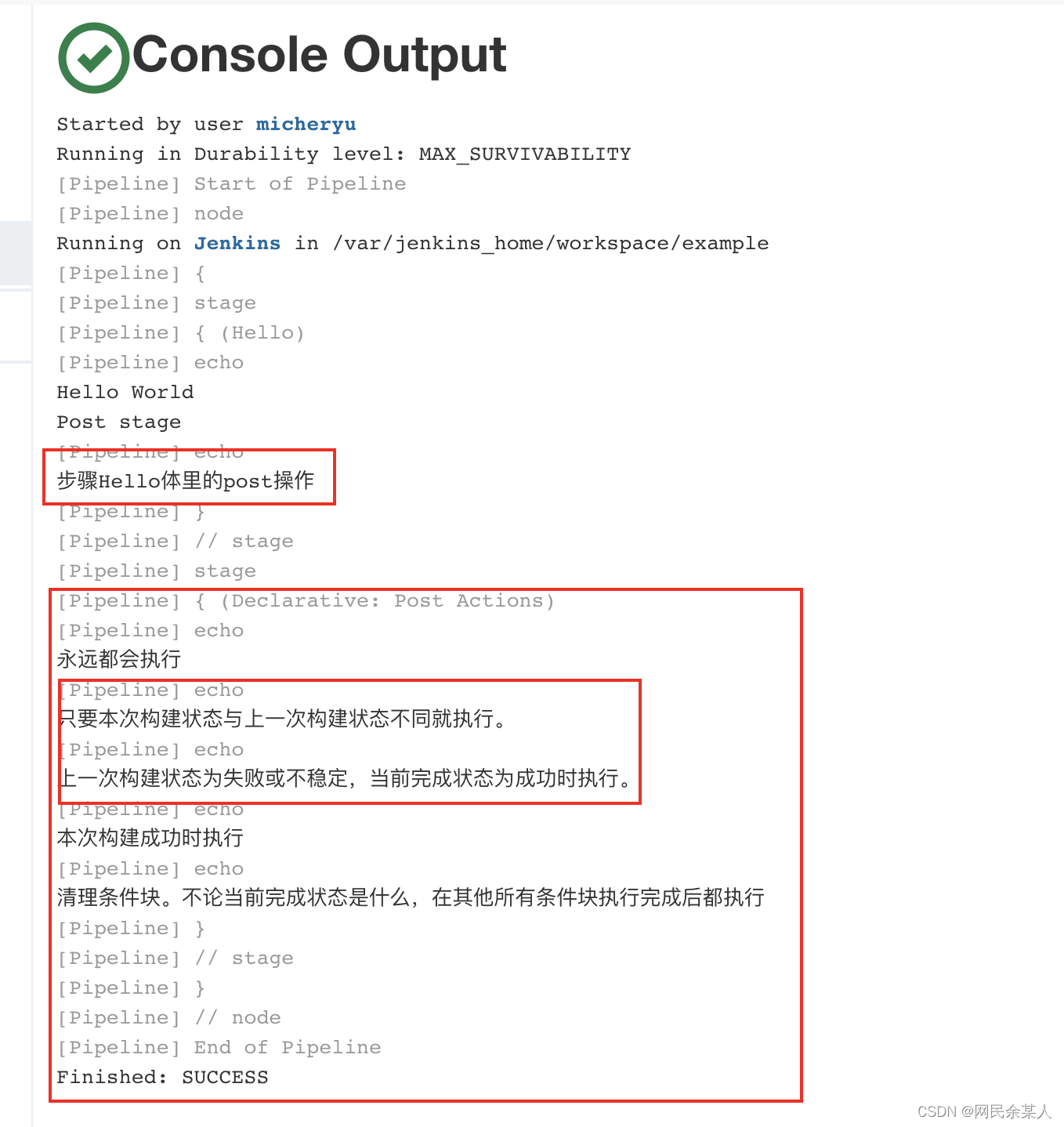
- 执行自动化测试脚本并通过飞书卡片消息发送执行结果到飞书群:
先上效果图:
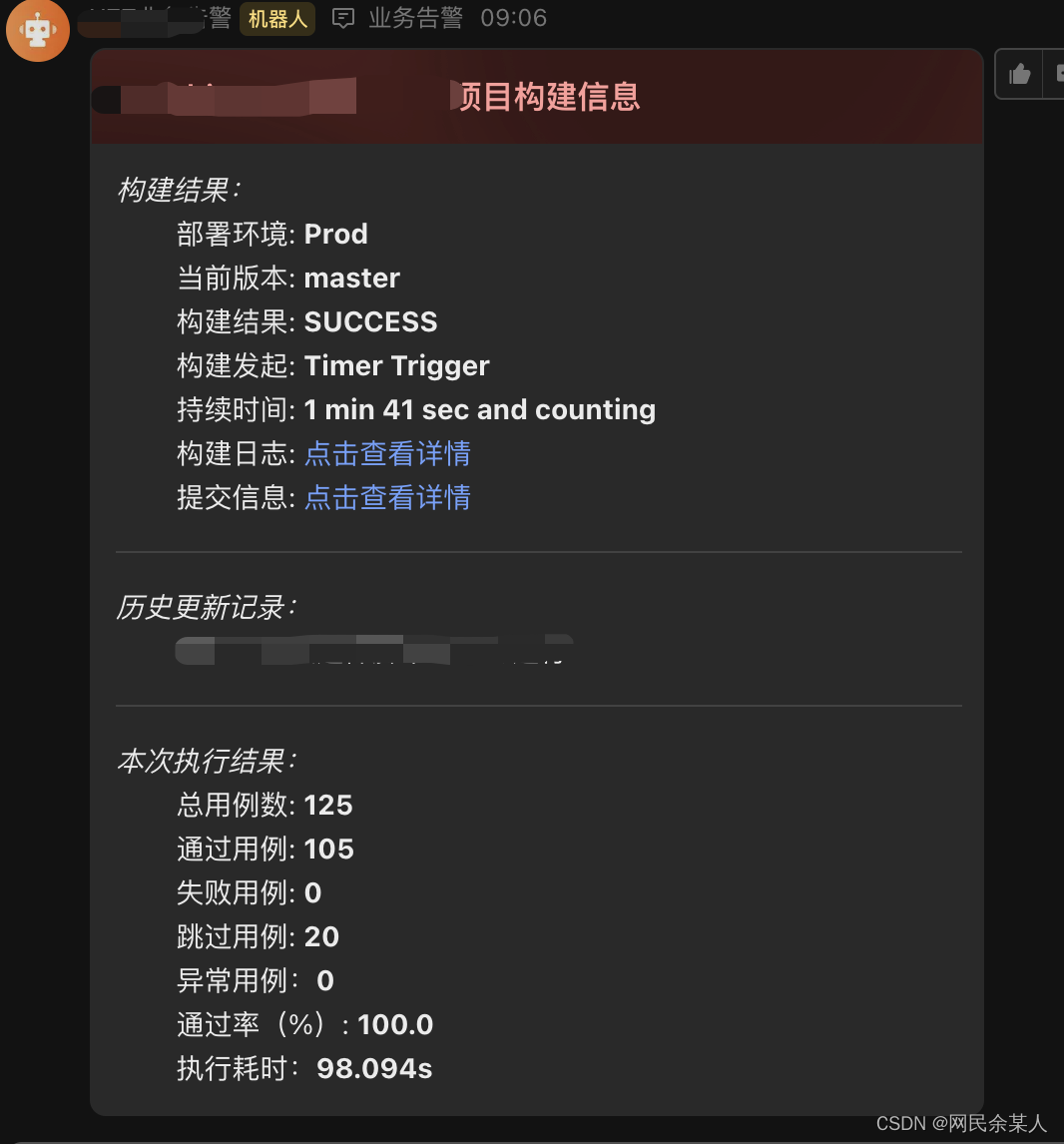
图中用例执行结果需在代码中获取pytest执行结果统计
需在最外层conftest中加以下代码:
from _pytest import terminal
def pytest_terminal_summary(terminalreporter):
"""收集测试结果,注:跟xdist插件不兼容"""
# print(terminalreporter.stats)
total = terminalreporter._numcollected - len(terminalreporter.stats.get('deselected', [])) # 收集总数-未选中用例数
passed = len([i for i in terminalreporter.stats.get('passed', []) if i.when == 'call'])
failed = len([i for i in terminalreporter.stats.get('failed', []) if i.when == 'call'])
error = len([i for i in terminalreporter.stats.get('error', []) if i.when != 'teardown'])
skipped = len([i for i in terminalreporter.stats.get('skipped', []) if i.when != 'teardown'])
pass_rate = round(passed / (total - skipped) * 100, 2)
# terminalreporter._sessionstarttime 会话开始时间
duration = time.time() - terminalreporter._sessionstarttime
# 将结果写入到一个文件中,后续再读取出来
result_path = os.path.join(PROJECT_DIR, "reports/result.json")
with open(result_path, "w")as fp:
fp.write(
str({"total": total, "passed": passed, "failed": failed, "error": error, "skipped": skipped,
"pass_rate": pass_rate, "duration": round(duration, 3)}))
如何发送卡片消息到飞书群(企微/钉钉同理):
Original: https://www.cnblogs.com/micheryu/p/15917059.html
Author: 网名余先生
Title: Jenkins系列之pipeline语法介绍与案例
相关阅读
Title: Python基础day23:绝对导入和相对导入、模块化编程简介、软件开发目录规范、常见内置模块collections和time
day23今日内容概要:
1.绝对导入与相对导入
2.包的概念(package)
3.模块化编程思想简介
4.软件开发目录规范
5.常见内置函数:collections和time
6.作业(将员工管理系统用模块化编程,结合软件开发目录规范来封装)
今日内容详解
1.绝对导入和相对导入
PS:只要存在import导入模块的操作,那么sys.path(程序系统环境变量)永远以当前执行文件的根目录为参考路径。
1.1.绝对导入:
句式:from 文件夹名 import py文件名
分析:这里的文件夹必须包含在当前执行文件的根目录下,可单层也可多层,
具体多少层路径需要在from后面采用 ad1.ad2.ad3 的形式注明
1.2.相对导入:
句式:from . import py文件名 或者是 from .. import py文件名
拓展知识:单句点符. 表示当前文件路径
双句点符.. 表示当前路径的上一层路径
../.. 表示上上层
分析:所以from . import py文件名 表示从关键字import所在的文件根目录下导入一个py文件,
from .. import py文件名 表示从当前文件根目录的上一层导入一个py文件
总结:相对导入依赖于关键字import所在的那个文件根目录路径,适合用来模块之间导入(前提是模块与模块在同一个根目录下),但是当模块比较多的时候还是容易找不到模块而报错。
而绝对导入依赖于当前执行文件的根目录路径,更不容易出现找不到模块而报错的情况,更加推荐使用绝对导入的方法来导入模块。
2.包的概念(package)
概念:"包"实际上就是文件夹,只是在文件夹里面多了一个__init__.py文件,而在这个__init__.py文件里面你可以配置这个文件夹里面哪些模块可以被调用。实际上在Python3里面对包和文件夹的区别已经不大了。
3.模块化编程简介
概念:类似前期将一段具有特定功能的代码封装成一个函数,需要的时候直接调用;而模块化编程就是将更多的代码或者定义好的函数、变量....封装成一个模块,当需要使用模块里面的功能时,直接导入这个模块即可。
4.软件开发目录规范
目的:为了方便代码的管理,项目的维护,调试等,将具有特定功能的文件(.py .TXT .log)分类放进一个指定的文件夹内
4.1规范的目录框架:
bin ->start.py 存放启动文件
configure ->setting.py 存放配置文件
core -> src.py 存放项目的核心逻辑代码文件
library -> common.py 存放各模块之间通用的文件
database -> user_data.txt 存放项目的数据库文件
interface -> order.py 存放项目的拓展接口文件
log -> log.txt 存放项目运行的日志文件
requirement.txt 存放运行该项目所需要具备的条件
readme.txt 存放对该项目的一些功能介绍等等
PS:实际项目开发中并不一定需要完完全全按照这个框架来设置文件目录,比如当bin文件夹里只有一个start.py文件时,完全可以把start文件拿出来直接放在项目的根目录下。总之只要能大致按照这个框架最终达到软件开发目录规范的目的即可。
5.常见内置模块
5.1.collections:
1.具名元组 namedtuple
导入:from collections import namedtuple
功能:point = namedtuple('三维坐标', 'x y z')
res = point(1, 2, 3)
print(res) # 三维坐标(x=1, y=2, z=3) 作用就是将数据值赋值给元祖里面的x,y,z并组成一个元组,同时还为这个元组绑定了一个名字
2.双端队列deque(只做了解)
from collections import deque
作用:队列前可以用appendleft(x)来追加数据,队列后可用.append(x)来追加数据,不同于列表,只能使用.append(x)在后面追加新数据
3.Counter(计数)
from collections import counter
str = 'hhhdbfhhffvbvhbfnfjuenvbfih'
res = Counter(str)
print(res) # Counter({'h': 7, 'f': 6, 'b': 4, 'v': 3, 'n': 2, 'd': 1, 'j': 1, 'u': 1, 'e': 1, 'i': 1}) Counter会统计字符串中每一个字符出现的次数,并生成一个字典
5.2.time(时间模块):
import time
time.time() 获取时间戳(从1970年到现在多少秒) # 1657789438.0584188
time.sleep(3) 定时,延时,总之让程序停止3秒钟
time.gmtime() 获取结构化时间(计算机更易读懂) # time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=9, tm_min=3, tm_sec=58, tm_wday=3, tm_yday=195, tm_isdst=0)
time.strftime(format) 获取格式化时间(更方便人查看) # 2022-07-14 17:12:40
PS:格式化时间的获取方式
res = time.strftime('%Y-%m-%d %H:%M:%S') # 需要给定一个时间格式
res2 = time.strftime('%Y-%m-%d %X') # %X = %H:%M:%S
print(res) # 2022-07-14 17:16:16
print(res2) # 2022-07-14 17:17:09
time.strptime(string, format) # 将给定的格式化时间string,按照给定格式format转换为结构化时间
eg:res = time.strptime('2022-07-14', '%Y-%m-%d')
print(res) # time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=195, tm_isdst=-1)
6.作业(将员工管理系统用模块化编程,结合软件开发目录规范来封装)

Original: https://www.cnblogs.com/amor815/p/16478578.html
Author: 海饼干815
Title: Python基础day23:绝对导入和相对导入、模块化编程简介、软件开发目录规范、常见内置模块collections和time