
1.不同的协议在同一条网线上传递(传递的都是数据流) 1.send 发 2.receive 收2.OSI七层协议 应用层 表示层 会话层 传输层 网络层 ip 数据链路层 mac 物理层 传输层:数据通信需要规则: TCP/IP : 三次握手 、四次断开 syn syn+ack ack UDP3. 一台电脑上可开辟的端口数为:65535 port nginx:80 mysql:33064.模拟通信 发送端: import socket : 因为socket封装了所有的上层协议,所以在使用时,需要指明要使用的协议 socket.TCP/IP (声明协议类型) connect(a.ip, a.port) 建立链接,链接对方的ip以及端口号 socket.send(hello) 发送数据 rece() 接收数据 socket.close() 关闭链接 接收端: 注意,先要有接收端(服务端),再有发送端 import socket socket.TCP/IP (声明协议类型) listen(0.0.0.0, 3306) 监听(术语):因为一台机器有多个网卡,所以要先声明自己的网卡(0.0.0.0表示选择所有网卡),再声明自己的端口号 waiting() 等待接收数据 reve() 接收数据 send() 发送数据 服务器端不需要关闭,等待其他程序来连
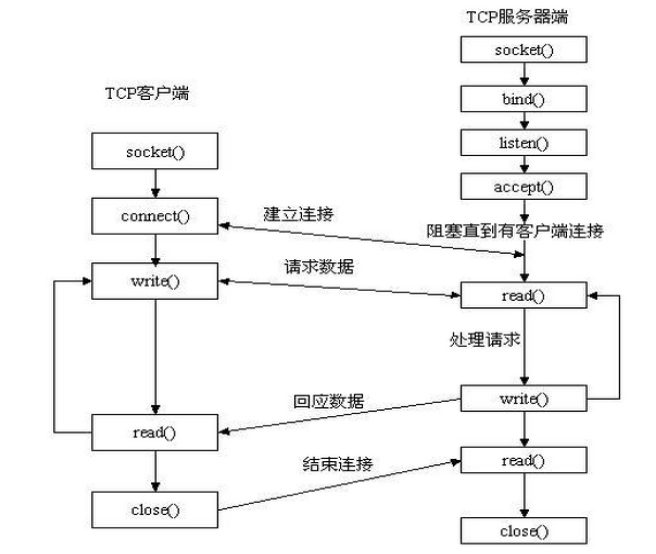
简单的服务器-客户端


# -*- coding:utf8 -*-
# 客户端
import socket
client = socket.socket() # 声明socket协议类型,同时生成socket链接对象
client.connect(("localhost", 6996)) # 连接服务器的ip和端口号
client.send("hello你好".encode(encoding="utf8")) # 在python3中,发送的数据都是二进制数据流,所以需要将字符串转化为二进制
data = client.recv(1024) # 接收服务器端发送过来的数据,大小上线为1024字节
print(data.decode())
client.close()
client
# -*- coding:utf8 -*-
# 服务器端
import socket
server = socket.socket() # 声明socket协议类型,同时生成socket链接对象
server.bind(("localhost", 6996)) # 绑定需要监听的 网卡ip 和 端口号
server.listen() # 监听
print("我要开始等电话了")
"""
等待电话打进来
conn:就是客户端连接进来,服务器端为其生成的一个链接实例
addr:客户端ip
"""
conn, addr = server.accept()
print(conn, addr)
print("电话来了")
data = conn.recv(1024) # 1024为接收客户端发送过来数据的上限为1024字节
print("reve", data.decode())
conn.send(data.upper()) # 发送数据给客户端
server.close() # 关闭服务器端
server
上面的代码的有一个问题, 就是SocketServer.py运行起来后, 接收了一次客户端的data就退出了。。。, 但实际场景中,一个连接建立起来后,可能要进行多次往返的通信。
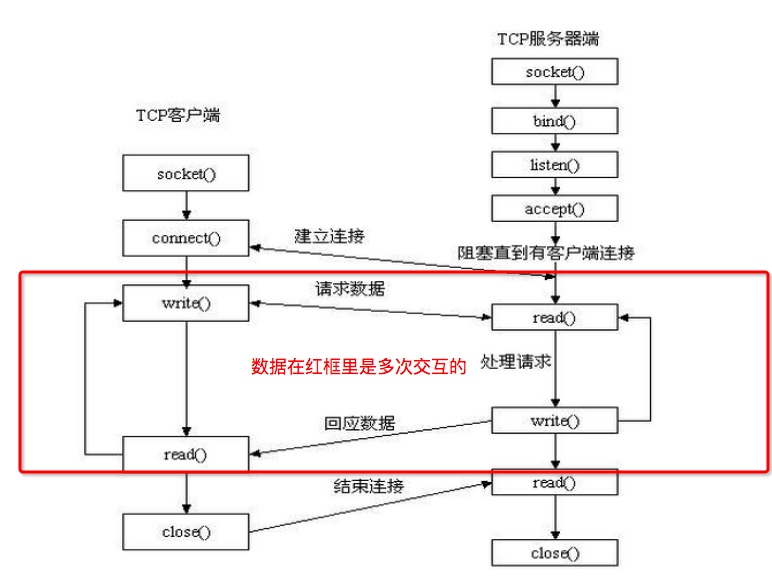
优化后的服务器-客户端
光只是简单的发消息、收消息没意思,干点正事,可以做一个极简版的ssh,就是客户端连接上服务器后,让服务器执行命令,并返回结果给客户端。
import os
import socket
server = socket.socket()
server.bind(("localhost", 6996))
server.listen(5) # 设置客户端连接上限
while True:
print("等待连接")
conn, addr = server.accept()
while True:
data_1 = conn.recv(1024)
if not data_1:
print("客户端断开了...", conn.getpeername())
break # 这里断开就会再次回到第一次外层的loop
data_2 = os.popen(data_1.decode()).read()
conn.send(str((len(data_2.encode()))).encode()) # 提醒客户端将会发送数据的长度
conn.send(data_2.encode())
print("已将消息发送给:", conn.getpeername())
server.close()
服务器端
import socket
client = socket.socket()
client.connect(("localhost", 6996))
while True:
str_input = input("请输入命令").strip()
if len(str_input) == 0: continue
client.send(str_input.encode())
data_len = client.recv(1024)
pd_len = 0
data_1 = b""
while pd_len < int(data_len):
data = client.recv(1024)
data_1 += data
pd_len += len(data)
print(pd_len, data_len)
print(data_1.decode())
client.close()
客户端
粘包:
- 如果出现粘包问题(通知客户端长度的数据和需要发送给客户端的数据,被缓冲池统一处理发送给了客户端),只需要在发送这两个数据中间,在进行一次交互就可以了(例如:客户端:发送我准备好接收数据了,服务器端:接收到反馈后,给客户端发送数据)
*
如何解决粘包的问题?> 每次发送的消息时,都将消息划分为 头部(固定字节长度) 和 数据 两部分。例如:头部,用4个字节表示后面数据的长度。> - 发送数据,先发送数据的长度,再发送数据(或拼接起来再发送)。> - 接收数据,先读4个字节就可以知道自己这个数据包中的数据长度,再根据长度读取到数据。
-
""">对于头部需要一个数字并固定为4个字节,这个功能可以借助python的struct包来实现:"""
import struct
len_v1 = struct.pack("i", 999) # i代表以int类型以4个字节 将999打包成一个4个字节的字节流
print(len_v1) # b'\xe7\x03\x00\x00'
num_len = struct.unpack("i", len_v1) # 以int类型的4个字节,将len_v1的字节流 转换成一个元组
print(num_len) # (999,)
- 示例代码:
"""解决粘包问题的服务器端"""
import socket
import struct
# 声明协议并创建链接对象
server = socket.socket()
# server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 设置ip可复用,参数暂时没有掌握
# 声明ip和端口号
server.bind(("localhost", 5002))
# 设置监听为5
server.listen(5)
# 等待连接
conn, addr = server.accept()
# 接收第一条数据,先接收数据的长度
data_len = conn.recv(4)
leng = struct.unpack('i', data_len)[0]
recv_len = 0 # 记录已经接收数据的长度
data_recv_sum = b"" # 记录接收的所有数据
while True:
length = leng - recv_len # 剩余数据长度
length = length if length < 1024 else 1024
data_recv = conn.recv(length)
data_recv_sum += data_recv
recv_len += len(data_recv)
if recv_len == leng:
break
print(data_recv_sum.decode("utf_8")) # 9527:你好中国
# 接收第二条数据同理
data_len = conn.recv(4)
leng = struct.unpack("i", data_len)[0]
recv_len = 0 # 记录已经接收数据的长度
data_recv_sum = b"" # 记录接收的所有数据
while True:
length = leng - recv_len # 剩余数据长度
length = length if length < 1024 else 1024
data_recv = conn.recv(length)
data_recv_sum += data_recv
recv_len += len(data_recv)
if recv_len == leng:
break
print(data_recv_sum.decode("utf_8")) # 9527:你好中国,哈哈哈
服务器端
"""解决粘包问题的服务器端"""
import socket
import struct
# 声明协议并创建链接对象
client = socket.socket()
# 创建连接
client.connect(("localhost", 5002))
# 发送第一条数据
data_send = "9527:你好中国".encode("utf_8")
data_len = struct.pack("i", len(data_send))
client.sendall(data_len)
client.sendall(data_send)
# 发送第二条数据
data_send = "9527:你好中国,哈哈哈".encode("utf_8")
data_len = struct.pack("i", len(data_send))
client.sendall(data_len)
client.sendall(data_send)
客户端
Socket中的方法:
sk.bind(address) 必会
s.bind(address) 将套接字绑定到地址。address地址的格式取决于地址族。在AF_INET下,以元组(host,port)的形式表示地址。
sk.listen(backlog) 必会
开始监听传入连接。backlog指定在拒绝连接之前,可以挂起的最大连接数量。
backlog等于5,表示内核已经接到了连接请求,但服务器还没有调用accept进行处理的连接个数最大为5
这个值不能无限大,因为要在内核中维护连接队列
sk.setblocking(bool) 必会
是否阻塞(默认True),如果设置False,那么accept和recv时一旦无数据,则报错。
sk.accept() 必会
接受连接并返回(conn,address),其中conn是新的套接字对象,可以用来接收和发送数据。address是连接客户端的地址。
接收TCP 客户的连接(阻塞式)等待连接的到来
sk.connect(address) 必会
连接到address处的套接字。一般,address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。
sk.connect_ex(address)
同上,只不过会有返回值,连接成功时返回 0 ,连接失败时候返回编码,例如:10061
sk.close() 必会
关闭套接字
sk.recv(bufsize[,flag]) 必会
接受套接字的数据。数据以字符串形式返回,bufsize指定 最多可以接收的数量。flag提供有关消息的其他信息,通常可以忽略。
sk.recvfrom(bufsize[.flag])
与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。
sk.send(string[,flag]) 必会
将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。即:可能未将指定内容全部发送。
sk.sendall(string[,flag]) 必会
将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。
内部通过递归调用send,将所有内容发送出去。
sk.sendto(string[,flag],address)
将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。该函数主要用于UDP协议。
sk.settimeout(timeout) 必会
设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如 client 连接最多等待5s )
sk.getpeername() 必会
返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。
sk.getsockname()
返回套接字自己的地址。通常是一个元组(ipaddr,port)
SocketServer实现并发:
第一步: 你必须自己创建一个请求处理类,并且这个类要进程BaseRequestHandler,并且还要重写父类中的Handler()方法第二步: 你必须实例化TCPServer,并且传递server ip 和 你上面创建的请求处理类 给这个TCPServer第三步: server.randler_reques()只处理一个请求(所以一般不用) server.serve_forever()处理多个一个请求,永远执行第四步: 关闭服务器 server.close()
# -*- coding:UTF-8 -*-
import socketserver
# 创建请求类
class MySocketServer(socketserver.BaseRequestHandler):
# 与客户端所有的交互都重写在这个方法中
def handle(self) :
while True:
try:
# 在Python3中客户端断开链接,服务器端会抛出异常
self.data = self.request.recv(1024).strip()
print("客户端地址为:{}".format(self.client_address[0]))
print(self.data.decode())
self.request.send(self.data.upper())
except ConnectionResetError as reason:
print(reason)
break
if __name__ == "__main__":
HOST, PORK = "localhost", 999
# 这句代码可以实现服务器与客户端的一对一,但是不能一对多
#server = socketserver.TCPServer((HOST, PORK), MySocketServer)
# 把代码改为下面的代码,则可以实现,一对多
server = socketserver.ThreadingTCPServer((HOST, PORK), MySocketServer)
server.serve_forever()
server.server_close()
多并发服务器端
# # -*- coding:utf8 -*-
# 客户端
import socket
client = socket.socket() # 声明socket协议类型,同时生成socket链接对象
client.connect(("localhost", 999)) # 连接服务器的ip和端口号
while True:
a = input("请输入")
client.send(a.encode(encoding="utf8")) # 在python3中,发送的数据都是二进制数据流,所以需要将字符串转化为二进制
data = client.recv(1024) # 接收服务器端发送过来的数据,大小上线为1024字节
print(data.decode())
client.close()
客户端
阻塞和非阻塞
默认情况下我们编写的网络编程的代码都是阻塞的(等待)
# ################### socket服务端(接收者)###################
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setblocking(False) # 加上就变为了非阻塞
sock.bind(('127.0.0.1', 8001))
sock.listen(5)
# 非阻塞
conn, addr = sock.accept()
# 非阻塞
client_data = conn.recv(1024)
print(client_data.decode('utf-8'))
conn.close()
sock.close()
# ################### socket客户端(发送者) ###################
import socket
client = socket.socket()
client.setblocking(False) # 加上就变为了非阻塞
# 非阻塞
client.connect(('127.0.0.1', 8001))
client.sendall('哈哈'.encode('utf-8'))
client.close()

如果代码变成了非阻塞,程序运行时一旦遇到 accept、 recv、 connect就会抛出 BlockingIOError 的异常。
这不是代码编写的有错误,而是原来的IO阻塞变为非阻塞之后,由于没有接收到相关的IO请求抛出的固定错误。
非阻塞的代码一般与IO多路复用结合,可以迸发出更大的作用。
IO多路复用
- I/O多路复用指:通过一种机制,可以 监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
- 基于 IO多路复用 + 非阻塞的特性,无论编写socket的服务端和客户端都可以提升性能。其中
- IO多路复用,监测socket对象是否有变化(是否连接成功?是否有数据到来等)。
- 非阻塞,socket的connect、recv过程不再等待。
注意:IO多路复用只能用来监听 IO对象 是否发生变化,常见的有:文件是否可读写、电脑终端设备输入和输出、网络请求(常见)。
在Linux操作系统化中 IO多路复用 有三种模式,分别是:select,poll,epoll。(windows 只支持select模式)
监测socket对象是否新连接到来 or 新数据到来。
select
select最早于1983年出现在4.2BSD中,它通过一个select()系统调用来监视多个文件描述符的数组,当select()返回后,该数组中就绪的文件描述符便会被内核修改标志位,使得进程可以获得这些文件描述符从而进行后续的读写操作。
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点,事实上从现在看来,这也是它所剩不多的优点之一。
select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,不过可以通过修改宏定义甚至重新编译内核的方式提升这一限制。
另外,select()所维护的存储大量文件描述符的数据结构,随着文件描述符数量的增大,其复制的开销也线性增长。同时,由于网络响应时间的延迟使得大量TCP连接处于非活跃状态,但调用select()会对所有socket进行一次线性扫描,所以这也浪费了一定的开销。
poll
poll在1986年诞生于System V Release 3,它和select在本质上没有多大差别,但是poll没有最大文件描述符数量的限制。
poll和select同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
另外,select()和poll()将就绪的文件描述符告诉进程后,如果进程没有对其进行IO操作,那么下次调用select()和poll()的时候将再次报告这些文件描述符,所以它们一般不会丢失就绪的消息,这种方式称为水平触发(Level Triggered)。
epoll
直到Linux2.6才出现了由内核直接支持的实现方法,那就是epoll,它几乎具备了之前所说的一切优点,被公认为Linux2.6下性能最好的多路I/O就绪通知方法。
epoll可以同时支持水平触发和边缘触发(Edge Triggered,只告诉进程哪些文件描述符刚刚变为就绪状态,它只说一遍,如果我们没有采取行动,那么它将不会再次告知,这种方式称为边缘触发),理论上边缘触发的性能要更高一些,但是代码实现相当复杂。
epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在系统调用时复制的开销。
另一个本质的改进在于epoll采用基于事件的就绪通知方式。在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
"""非阻塞+IO多路复用"""
"""
非阻塞:代码不会自动检测recv accept connect是否有接收到讯息
IO多路复用:可以检测accept connect recv是否有接收到讯息
-> IO多路复用 + 非阻塞 + socket服务端,可以让服务端同时处理多个客户端的请求。
-> IO多路复用 + 非阻塞 + socket客户端,可以向服务端同时发起多个请求。
在Linux操作系统化中 IO多路复用 有三种模式,分别是:select,poll,epoll。(windows 只支持select模式)
-> select:1.对socket对象列表有限制,最大为1024 2.检测对象是否发生变化是通过遍历的方式,所以开销很大
-> poll:poll和select在本质上没有多大差别,但是poll没有最大文件描述符数量的限制
-> epoll:发生了变化的socket对象会告知epoll,让其处理,但是代码实现相当复杂
优点:1.可以在交互后做一些其他的事情 2.让服务器支持多个客户端连接
"""
"""IO多路复用的服务器端"""
import select
import socket
server = socket.socket()
server.bind(("localhost", 5001))
server.setblocking(False) # 设置为非阻塞
server.listen(5)
inputs = [server, ] # socket对象列表 -> [server, 第一个客户端连接conn ]
while True:
"""
r, w, e = select.select(inputs, [], [server,conn1,conn2], 0.05)
0.05:表示,最多花费0.05秒的时间,去检测inputs列表中的每一个socket对象是否有人向它们发起连接或数据,若没有接收到讯息,那么([], [], [])
返回值:1个为元组,元组中有3个列表([], [], [])
列表r:里面存储的是检测到,inputs中发生了变化的socket对象(server、第一个conn、第二个conn······)
列表w: 看客户端(连接成功了的对象)
列表e: 捕获第三个列表中socket对象发生的异常,如果有某个对象发生了异常,那么会将这个对象添加到列表e中
"""
r, w, e = select.select(inputs, [], [], 0.05)
for sock in r:
if sock == server: # 表示server对象接收到了新的连接
# 注意:因为server是有收到讯息的(因为是select处理的),所以这里没有报错(BlockingIOError)
conn, addr = sock.accept() # 把新连接的对象和ip记录下来记录下来
print("新连接产生,对方ip:{}".format(addr))
inputs.append(conn) # 将新连接对象添加到socket对象列表中
else: # 否则接收到的讯息就不是新连接,而是已经建立过的连接,发送了新的讯息过来
# 注意:因为coon(sock)是有收到讯息的(因为是select处理的),所以这里没有报错(BlockingIOError)
data_recv = sock.recv(1024)
if data_recv:
print(data_recv.decode("utf-8"))
else:
print("ip:{}断开连接".format(sock.getpeername()[1]))
inputs.remove(sock)
# 可以在这里做一些其他的事情
# ################### socket客户端 ###################
import socket
client = socket.socket()
# 阻塞
client.connect(('127.0.0.1', 8001))
while True:
content = input(">>>")
if content.upper() == 'Q':
break
client.sendall(content.encode('utf-8'))
client.close()
"""IO多路复用的客户端"""
# 优点:伪造并发现象
import select
import socket
client_list = [] # 存储client连接对象的列表
for x in range(5):
client = socket.socket()
client.setblocking(False) # 设置为非阻塞
try:
client.connect(("localhost", 5001)) # 虽然连接建立了,但是依然会抛出异常
except BlockingIOError as e:
pass
client_list.append(client) # 将连接对象添加到列表中
recv_list = [] # 存放连接成功了的client对象,用于检测服务器端是否有给客户端发送讯息
while True:
"""
r, w, e =select.select([], client_list, [], 0.1)
列表w:client_list列表中与客户端连接成功了的client对象
"""
r, w, e = select.select([], client_list, [], 0.1)
for sock in w:
# 向服务器发送请求,如发送下载图片的请求
sock.sendall(b"GET /nginx-logo.png HTTP/1.1\r\nHost:47.98.134.86\r\n\r\n")
# 存放连接成功了的client对象,用于检测服务器端是否有给客户端发送讯息
recv_list.append(sock)
# 移除存放在client_list中的client对象,否则,会一直执行这个循环,导致客户端重复向服务器发送下载图片的请求
client_list.remove(sock)
for sock in r:
# 数据发送成功后,接收的返回值(图片)并写入到本地文件中(省略代码)
data = sock.recv(8196)
# 根据需求是否移除recv_list列表中client对象
recv_list.remove(sock)
pass
# 判断client是否都处理完成
if not recv_list and not client_list:
break
Original: https://www.cnblogs.com/fjfsu/p/15700662.html
Author: J.FengS
Title: Socket
相关阅读
Title: 自底向上:从可变对象、不可变对象到深浅拷贝再到数据结构
一、不可变对象和可变对象**
Python 在 heap 中分配的对象分成两类:可变对象和不可变对象。所谓可变对象是指,对象的内容是可变的,例如 list。而不可变的对象则相反,表示其内容不可变。
不可变对象 :int,string,float,tuple -- 可理解为C中,该参数为值传递
可变对象 :list,dictionary -- 可理解为C中,该参数为指针传递
不可变对象
由于Python中的变量存放的是对象引用,所以对于不可变对象而言,尽管对象本身不可变,但变量的对象引用是可变的。运用这样的机制,有时候会让人产生糊涂,似乎可变对象变化了。如下面的代码:
for i in range(10):
print(id(i))
outputs:
2221403367696
2221403367728
2221403367760
2221403367792
2221403367824
2221403367856
2221403367888
2221403367920
2221403367952
2221403367984

从上面得知,不可变的对象的特征没有变,依然是不可变对象,变的只是创建了新对象,改变了变量的对象引用。
对于可变对象
其对象的内容是可以变化的。当对象的内容发生变化时,变量的对象引用是不会变化的。如下面的例子。
m = [1,2,3]
print(id(m))
m += [4]
print(id(m))
outputs:
2221492412544
2221492412544
对于可变对象 list这种进行操作时,相当于修改对象中某个属性,所以不会改变地址 python都是将对象的引用(内存地址)赋值给变量的。
现在问题来了
def myfunc(l):
l.append(1) # 列表加1
print(l)
l = [1,2,3]
myfunc(l) # [1,2,3,1]
print(l) # [1,2,3,1]
可变对象 l送进函数中操作后,对函数外面的也起作用,不可变对象则相反。因为函数直接对可变对象的 地址的值进行了修改。该操作对于类初始化传值有一样的效果。
只有搞懂可变对象和不可变对象之后,才能理解下面的深拷贝与浅拷贝。
二、深拷贝和浅拷贝
浅拷贝
- 浅拷贝会创建一个新的容器对象(compound object)
- 对于对象中的元素,浅拷贝就只会使用原始元素的引用(内存地址)
深拷贝
- 深拷贝和浅拷贝一样,都会创建一个新的容器对象(compound object)
- 和浅拷贝的不同点在于,深拷贝对于对象中的元素,深拷贝都会重新生成一个新的对象
更进一步,由于浅拷贝复制的是元素的地址引用,如果元素是不可变类型,修改就更新了地址,和原对象的地址不同了,所以原对象不会受到影响,当元素是可变类型,修改没有改变地址,这样原对象也就跟着变化。
对于深拷贝而言,改变任何一个对象都对另一个没有影响,它们是独立的。无论是不可变对象,还是可变对象,深拷贝后它们的地址已经不一样了。
三、哈希表中的可哈希和不可哈希对象
了解了上文之后,在python中使用哈希表(散列表)数据结构时,又有可哈希和不可哈希对象之分,其实这里就是可变对象和不可变对象。为什么呢?
对于不可变类型而言, 不同的值意味着不同的内存,相同的值存储在相同的内存,如果将我们的不可变对象理解成哈希表中的 Key,将内存理解为经过哈希运算的哈希值 Value,这不正好满足哈希表的性质嘛。
对于可变对象而言,比如一个列表,更改列表的值,但是对象的地址本身是不变的,也就是说 不同的 Key,映射到了相同的 Value,这显然是不符合哈希值的特性的,即出现了哈希运算里面的冲突。
所以在python中使用set()、dictionary()时键值都必须是不可变对象。
参考文章:Python基础:Python可变对象和不可变对象
Original: https://www.cnblogs.com/cs-markdown10086/p/16139269.html
Author: NEU_ShuaiCheng
Title: 自底向上:从可变对象、不可变对象到深浅拷贝再到数据结构