
本文为矩池云入门手册的补充:Pytorch训练MNIST数据集代码运行过程。
案例代码和对应数据集,以及在矩池云上的详细操作可以在矩池云入门手册中查看,本文基于矩池云入门手册,默认用户已经完成了机器租用,上传解压好了数据、代码,并使用jupyter lab进行代码运行。
在MATPool矩池云完成Pytorch训练MNIST数据集
1. 安装自己需要的第三方包
以tqdm包为例子,如果在运行代码过程出现了 ModuleNotFoundError: No module named 'tqdm',说明我们选择的系统镜像中没有预装这个包,我们只需要再JupyterLab的Terminal输入 pip install tqdm即可安装相关包。

其他自己需要的第三方包安装方法也类似。
2. 在JupyterLab中运行代码
JupyterLab目录里面,我们依次点击 mnt->MyMNIST进入到项目文件夹,在项目文件夹下双击 pytorch_mnist.ipynb文件,即可打开代码文件。
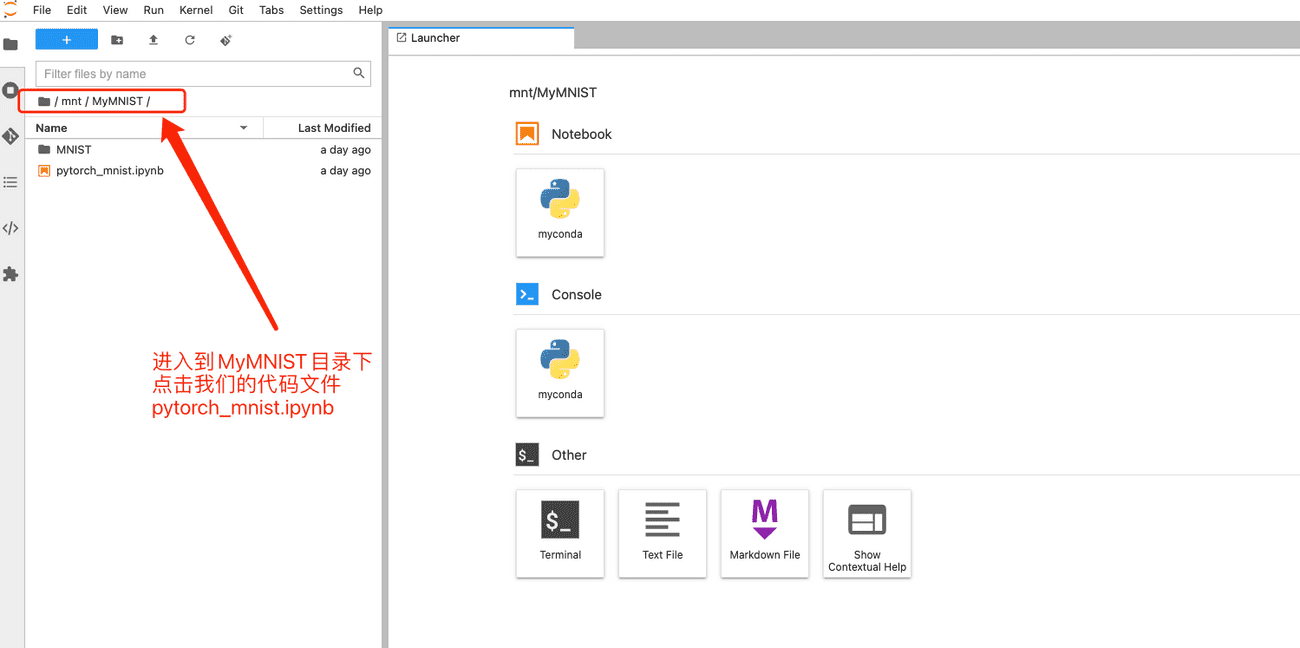
打开代码文件后,我们就可以直接运行了,截图中给大家说明了几个常用的JupyteLab 按钮功能。
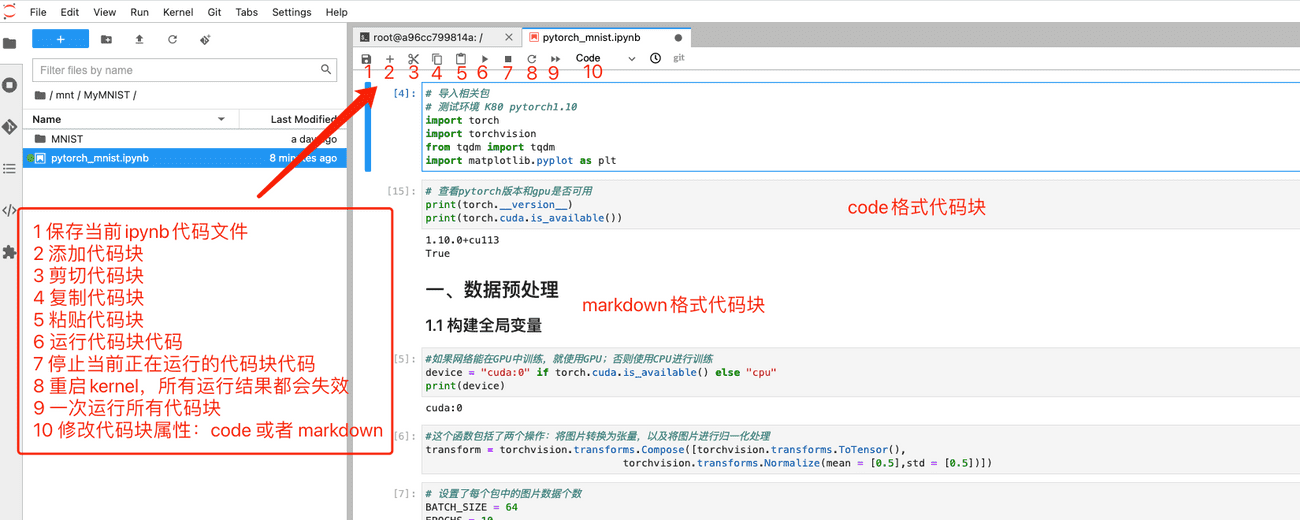
接下来我们开始运行代码~
2.1 导入需要的Python包
首先运行下面代码导入需要的模块,如:
- pytorch相关:torch、torchvision
- 训练输出进度条可视化显示:tqdm
- 训练结果图表可视化显示:matplotlib.pyplot
# 导入相关包
# 测试环境 K80 pytorch1.10
import torch
import torchvision
from tqdm import tqdm
import matplotlib.pyplot as plt
测试下机器中的pytorch版本和GPU是否可用。
# 查看pytorch版本和gpu是否可用
print(torch.__version__)
print(torch.cuda.is_available())
'''
输出:
1.10.0+cu113
True
'''
上面输出表示pytorch版本为1.10.0,机器GPU可用。
2.2 数据预处理
设置device、BATCH_SIZE和EPOCHS
# 如果网络能在GPU中训练,就使用GPU;否则使用CPU进行训练
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# 这个函数包括了两个操作:将图片转换为张量,以及将图片进行归一化处理
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean = [0.5],std = [0.5])])
# 设置了每个包中的图片数据个数
BATCH_SIZE = 64
EPOCHS = 10
加载构建训练和测试数据集
# 从项目文件中加载训练数据和测试数据
train_dataset = torchvision.datasets.MNIST('/mnt/MyMNIST/',train = True,transform = transform)
test_dataset = torchvision.datasets.MNIST('/mnt/MyMNIST/',train = False,transform = transform)
# 建立一个数据迭代器
# 装载训练集
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
# 装载测试集
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
2.3 构建数据训练模型并创建实例
构建数据训练模型
# 一个简单的卷积神经网络
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.model = torch.nn.Sequential(
#The size of the picture is 28x28
torch.nn.Conv2d(in_channels = 1,out_channels = 16,kernel_size = 3,stride = 1,padding = 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size = 2,stride = 2),
#The size of the picture is 14x14
torch.nn.Conv2d(in_channels = 16,out_channels = 32,kernel_size = 3,stride = 1,padding = 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size = 2,stride = 2),
#The size of the picture is 7x7
torch.nn.Conv2d(in_channels = 32,out_channels = 64,kernel_size = 3,stride = 1,padding = 1),
torch.nn.ReLU(),
torch.nn.Flatten(),
torch.nn.Linear(in_features = 7 * 7 * 64,out_features = 128),
torch.nn.ReLU(),
torch.nn.Linear(in_features = 128,out_features = 10),
torch.nn.Softmax(dim=1)
)
def forward(self,input):
output = self.model(input)
return output
构建模型实例
# 构建模型实例
net = Net()
# 将模型转换到device中,并将其结构显示出来
print(net.to(device))

2.4 构建迭代器与损失函数
# 交叉熵损失来作为损失函数
# Adam迭代器
loss_fun = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters())
2.5 构建并运行训练循环
history = {'Test Loss':[],'Test Accuracy':[]}
for epoch in range(1,EPOCHS + 1):
process_bar = tqdm(train_loader,unit = 'step')
net.train(True)
for step,(train_imgs,labels) in enumerate(process_bar):
train_imgs = train_imgs.to(device)
labels = labels.to(device)
net.zero_grad()
outputs = net(train_imgs)
loss = loss_fun(outputs,labels)
predictions = torch.argmax(outputs, dim = 1)
accuracy = torch.true_divide(torch.sum(predictions == labels), labels.shape[0])
loss.backward()
optimizer.step()
process_bar.set_description("[%d/%d] Loss: %.4f, Acc: %.4f" %
(epoch,EPOCHS,loss.item(),accuracy.item()))
if step == len(process_bar)-1:
correct,total_loss = 0,0
net.train(False)
with torch.no_grad():
for test_imgs,labels in test_loader:
test_imgs = test_imgs.to(device)
labels = labels.to(device)
outputs = net(test_imgs)
loss = loss_fun(outputs,labels)
predictions = torch.argmax(outputs,dim = 1)
total_loss += loss
correct += torch.sum(predictions == labels)
test_accuracy = torch.true_divide(correct, (BATCH_SIZE * len(test_loader)))
test_loss = torch.true_divide(total_loss, len(test_loader))
history['Test Loss'].append(test_loss.item())
history['Test Accuracy'].append(test_accuracy.item())
process_bar.set_description("[%d/%d] Loss: %.4f, Acc: %.4f, Test Loss: %.4f, Test Acc: %.4f" %
(epoch,EPOCHS,loss.item(),accuracy.item(),test_loss.item(),test_accuracy.item()))
process_bar.close()

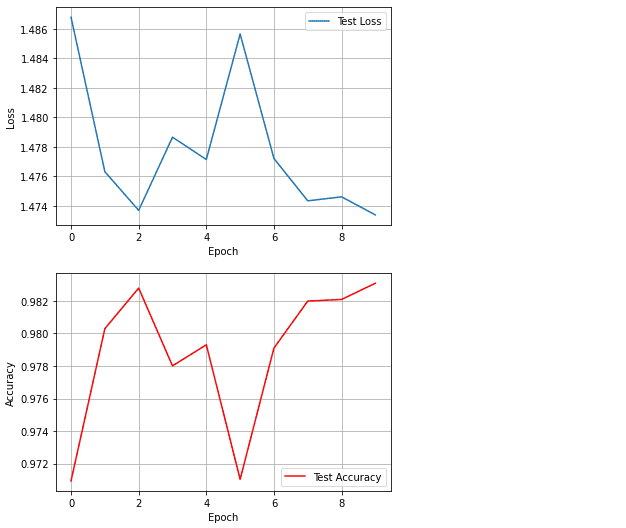
2.6 训练结果可视化
#对测试Loss进行可视化
plt.plot(history['Test Loss'],label = 'Test Loss')
plt.legend(loc='best')
plt.grid(True)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
#对测试准确率进行可视化
plt.plot(history['Test Accuracy'],color = 'red',label = 'Test Accuracy')
plt.legend(loc='best')
plt.grid(True)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.show()
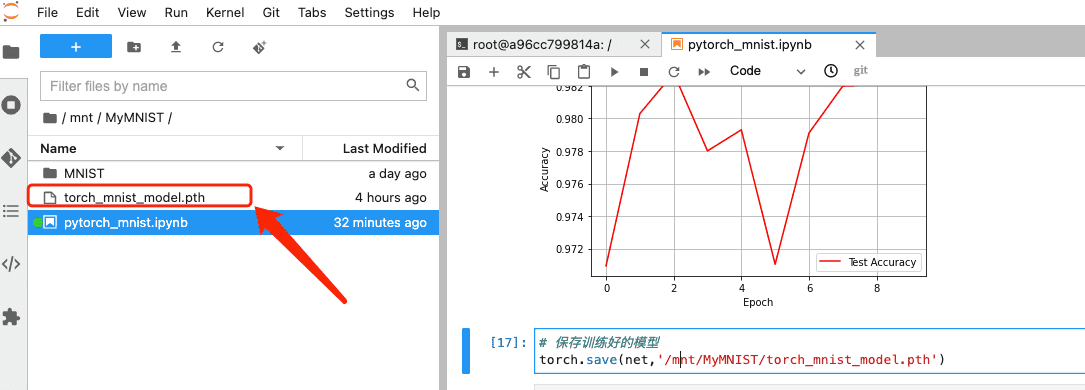
2.7 保存模型
# 保存训练好的模型
torch.save(net,'/mnt/MyMNIST/torch_mnist_model.pth')
保存成功后,JupyterLab 中对应文件夹会出现该文件,在矩池云网盘对应目录下也会存在。
参考文章
Original: https://www.cnblogs.com/matpool/p/16158482.html
Author: 矩池云
Title: 在MATPool矩池云完成Pytorch训练MNIST数据集
相关阅读
Title: 装备保障性验证知识图谱构建方法研究-学习笔记
装备保障性验证知识图谱构建方法研究
领域知识图谱构建
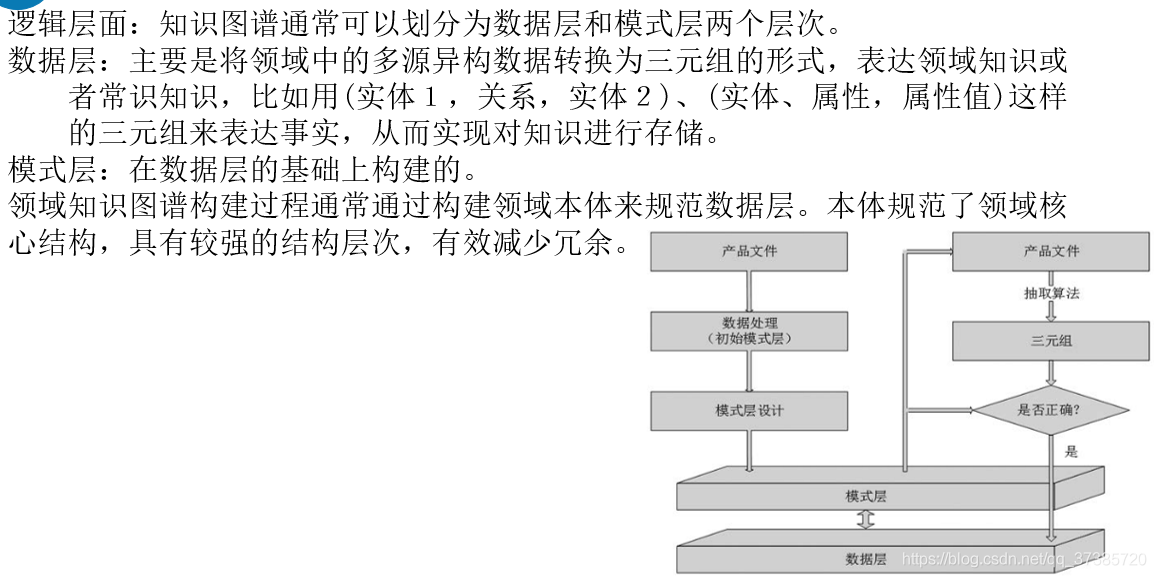
在逻辑层面,知识图谱通常可以划分为数据层和模式层两个层次。数据层主要是将领域中的多源异构数据转换为三元组的形式,通过一系列三元组表达领域知识或者常识知识,比如用(实体1,关系,实体2)、(实体、属性,属性值)这样的三元 组来表达事实,从而实现对知识进行存储。模式层是在数据层的基础上构建的,领域知识图谱构建过程通常通过构建领域本体(Ontology)来规范数据层。本体规范了领域核心结构,具有较强的结构层次,有效减少冗余。
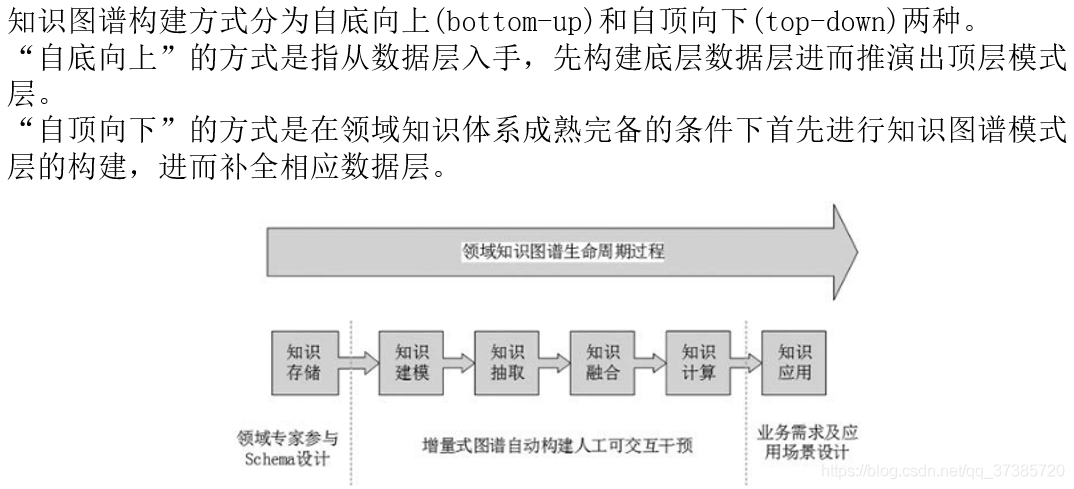
由于垂直领域知识图谱对领域知识准确性以及领域知识之间深层次关系要求较高,因此一般采用自顶向下构建方式。
虽然垂直领域知识图谱一般面向不同的特定领域和不同的数据模式,现在没有统一的构建标准和规范。但是一般构建过程可以分为六个阶段,即知识建模、知识存储、知识抽取、知识融合、知识计算、知识应用。
面向装备保障性验证的知识图谱构建
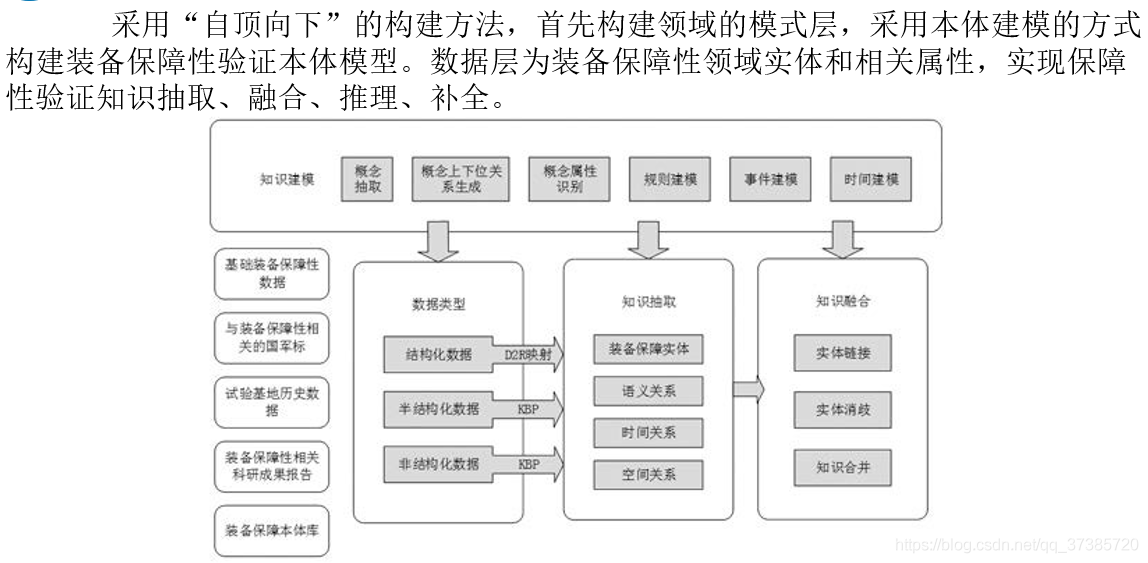
装备保障性验证知识图谱构建技术流程。
D2R 将关系数据库中的数据映射到RDF (资源描述框架,表示为三元组形式,RDF 本质是一种数据模型(Data Model),RDF 假设所有语义都可以以三元组形式进行表示,复杂语义可以由n 个三元 组组合表示,它提供了一种统一的描述实体、概念、属性的标准,形式上表示为SPO 三元组形式)中。
KBP ( 知识库填充,关系抽取语料)KBP 评测由文本分析会议主办,其目标是开发和评估从非结构化文本中获取知识填充知识库的技术。KBP 评测覆盖了知识库填充的独立子任务以及被称为"冷启动"的端到端知识库构建任务。

采用应用最为广泛的OWA 形式化定义进行装备保障性验证领域本体建模。
C 是领域概念集;A 是概念的属性集;R 是关系集;A 是每个关系属性集;H 表示概念层次;X 表示公理集。
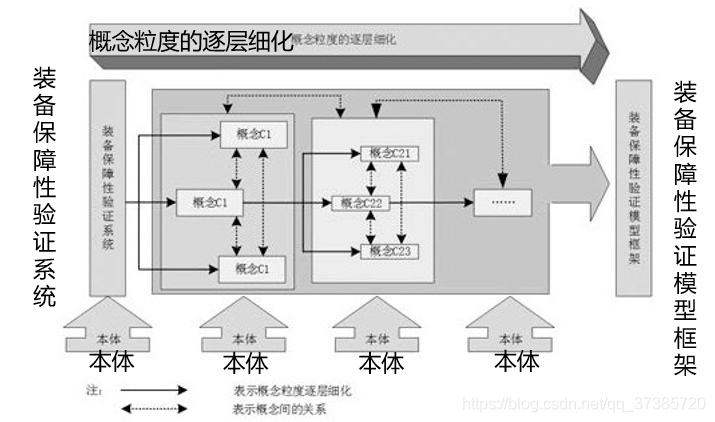
基于本体的保障性验证系统分析的核心在于:在OWA 形式化规范下逐层确定装备保障系统概念和概念之间的关系。 如此逐层分析,直至确定研究目的下所定义的最小细粒度概念。 在概念分析的过程中会逐层体现所需建立的模型。

多源异构装备保障性实体抽取和实体关系构建包括装备保障性验证知识抽取、关系链接、关系推理等。
保障性验证领域知识的来源包括装备保障本体库、基础装备保障性数据、与装备保障性相关的国军标、装备保障性相关的科研项目成果(报告、模型)、试验基地的历史数据等。可从中提取装备保障性验证相关概念、装备保障性验证实体、装备保障性验证相关属性、语义关系、空间关系、时间关系。


时间关系主要描述在装备寿命周期各阶段装备保障性验证所处的不同状态以及任务属性。对时间关系的形式化描述可分为两类,
一类是装备保障性验证事件、过程等实体之间的时变关系描述,如事件:"在装备设计阶段,装备设计人员需要考虑加油口盖消沫功能"可对抽取得到的三元组"设计人—设计—加油口盖消沫功能"添加时间标签拓展为四元组,用来描述时间;
第二类是空间特征的时间变化属性。可用于实体和关系的更新,如装备进行长途奔袭过程中,装备的空间属性值以及装备状态属性值是随时间而变化的,这也是未来构建动态知识图谱的时间轴基础。
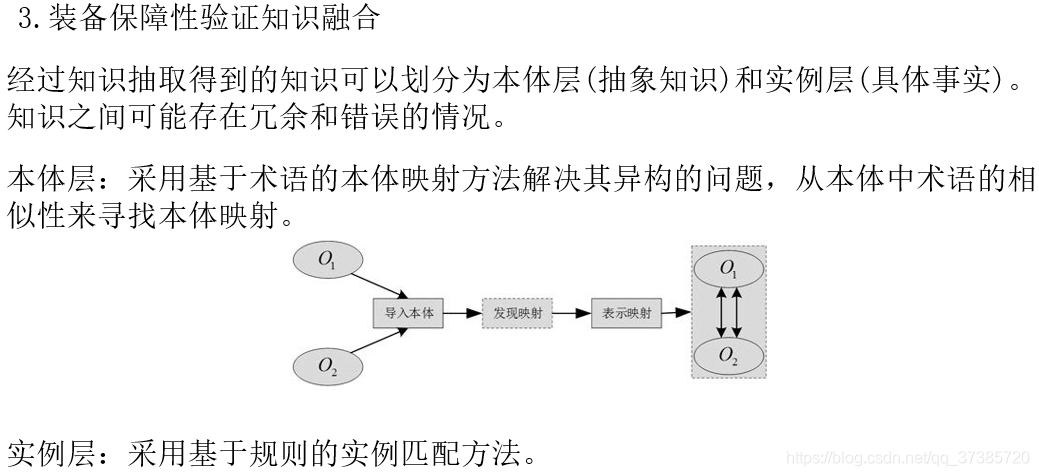
经过知识抽取得到的知识可以划分为本体层(抽象知识)和实例层(具体事实)。
虽然通过本体建模的方式构 建了装备保障性验证领域的本体模型,但是事实上,无法构建出一个能够包含全方面的统一本体,因为面向不同应用场景以及面向不同的用户使得不同本体之间有不同侧重点和差异。大量实例之间也存在异构性问题。
由于知识之间可能存在冗余和错误的情况,需要通过知识融合来解决本体层和实例层异构问题,以提高知识质量和精度。
如图描述了本体映射的基本过程。
基于术语:自然语言处理技术,比较映射对象之间的相似度
基于术语的本体映射
基于字符串
(1 )规范化
(2 )相似度量方法:
汉明距离:计算字符出现位置的不同
子串相似度
编辑距离:修改其中一个使之与另一个相同所需的最小操作代价
路径距离:考虑父概念
基于规则的实例匹配
基于EM 算法的半监督学习框架----自动寻找实例匹配规则
该框架以迭代的方式 自动发现匹配规则,逐步提高匹配规则集的质量,再利用跟新后的规则集来寻找高质量的匹配对。

在规范字符串的基础上,通过度量字符串的相似程度判断本体的映射关系,可以使用以下四种方法度量字符串相似度。
导入的任意两个本体字符s 和t 。
若存在两个字符串p 和q 使得s=p+t+q 或t=p+s+q ,则称t 是s 的子串或s 是t 的子串,令x 为s 和t 的最大公共子串,则s 和t 的子串相似度为:
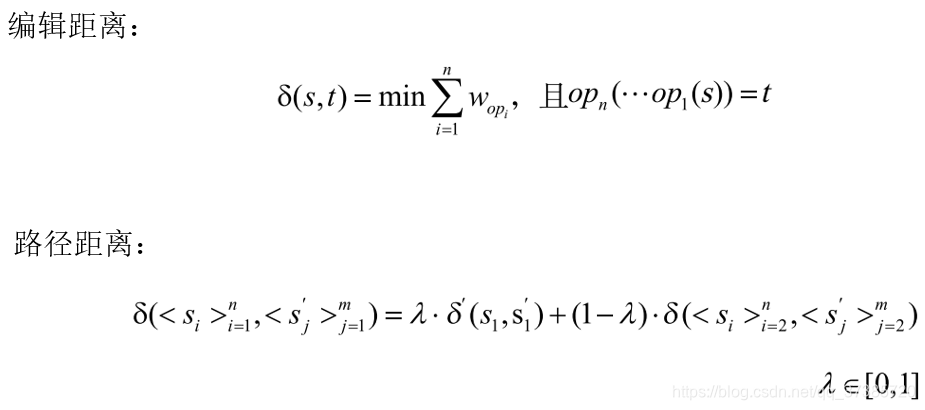
若给定一个字符串操作集合op 和一个代价函数w ,对于任意一对字符串s 和t ,存在将s 转化为t 的操作序列集合,则两字符串的编辑距离为:
若给定两个字符串序列,则路径距离计算,是某字符串度量函数
装备保障性验证知识图谱应用


Original: https://blog.csdn.net/qq_37385720/article/details/109032407
Author: ChanYeol666
Title: 装备保障性验证知识图谱构建方法研究-学习笔记