
train.py: error: the following arguments are required: --config解决办法
最近在跑github上的深度学习开源项目,在导入项目运行train.py文件后,发现一直报 train.py: error: the following arguments are required: --config这个错误。错误截图如下:

上网查了很多方法,发现网上很多解决办法都不行,最后自己通过摸索找了解决办法。
解决方案:
首先通过报错语句,定位到错误代码。通过上图的报错语句,定位到了我的错误代码在train.py文件中parser.add_argument方法的问题,截图如下:
 通过百度parser.add_argument语句, 发现当required参数为True时,在运行时必须要为该命令指定路径。从上图可以看到第一条parser.add_argument的require参数为True,第二条为false,而第一条的正好是"–config"与报错语句对应,因此可以判断错误原因是未给"–config"指定路径。
通过百度parser.add_argument语句, 发现当required参数为True时,在运行时必须要为该命令指定路径。从上图可以看到第一条parser.add_argument的require参数为True,第二条为false,而第一条的正好是"–config"与报错语句对应,因此可以判断错误原因是未给"–config"指定路径。
因为代码是在github上下载的,笔者在项目文件夹中找有没有config文件,最后笔者发现没有config文件,但是有个configurations文件夹,文件夹里有两个数据集文件,截图如下:


上图PEMS04和PEMS08是两个数据集名称。
笔者将其中一个作为–config的路径,最终成功运行。
步骤如下:
在pycharm中依次点击菜单栏Run–>Edit Configurations,打开一个配置窗口,截图如下:


在打开的Configurations窗口,parameters框中输入–config "./configurations/PEMS04.conf",点击确认即可。

–config "./configurations/PEMS04.conf"中,–config是我报错的原因,"./configurations/PEMS04.conf"是我为config指定的路径。
这样写只适合这种错误,如果是类似的错误笔者认为也模仿着解决。
最后是运行成功截图:

可以看到加入config指定路径后,运行结果图也显示出来了(上图红笔处)。
Original: https://blog.csdn.net/weixin_43982422/article/details/117479588
Author: 威斯登
Title: train.py: error: the following arguments are required: --config解决办法
相关阅读1
Title: 图像加密技术综述(常见的图像加密算法简介)
彩色图像加密综述(An overview of encryption algorithms in color images):
此文总结了50多项这一领域的研究,还从应用领域的角度对现有的各种彩色(如RGB图像)图像加密方案进行了全面的研究,其中大部分研究已于去年发表。此外,此研究将彩色图像加密分为 10类方案,并对所提出的方案进行了比较,突出了它们的 优点和局限性。此外,还讨论了(灰度或彩色)图像加密的常用安全分析技术的完整列表,这些技术能够评估该方法对不同可能攻击的潜在抵抗力。此研究旨在提供有关RGB图像领域现有图像加密方案的详细知识。最后,指明未来的研究前景。
1.文本加密到图像加密
2.彩色图像加密的分类
1)按加密方法分
在目前的研究中,图像加密被分为10种主要技术。分别是基于混沌加密、置换加密、基于光学加密、基于DNA(脱氧核糖核酸)加密、基于频率加密、基于散列加密、基于进化加密、基于位平面加密、双(多)图像加密、基于置乱的图像加密。
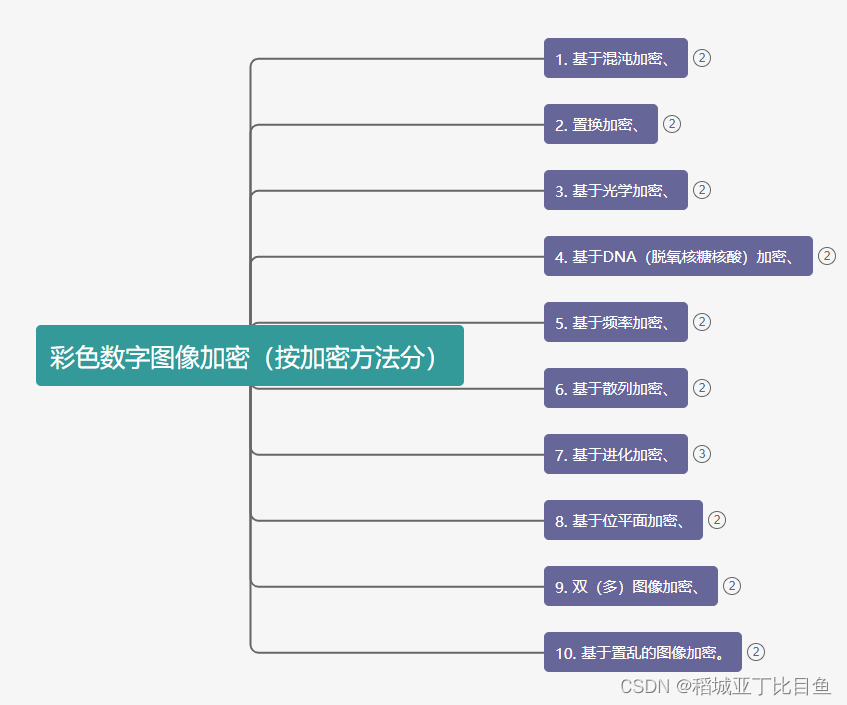
2)按加密所在域分:
频域加密:变换域中的加密算法主要基于对变换系数,将图像经过频域变换(如DWT(离散小波变换)、DCT(离散余弦变换)等)分化出高频域与低频域,并通过改变各个频域中系数进行加密。
空域加密:主要基于置乱图像像素或块,直接改变原始图像的像素值位置或者像素值,以Arnold置乱图像加密算法为代表。
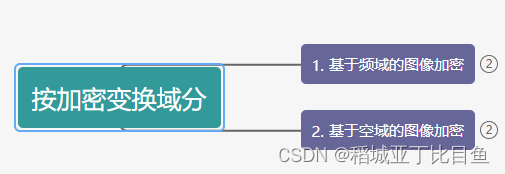
3.常见的加密方法
基于不同的技术提出了许多现有的图像加密手段:包括扫描、圆形随机网格、椭圆曲线ElGamal、格雷码、波传输、矢量量化,离散小波变换,p-斐波那契变换,混沌序列。
主要加密算法举例:
1)基于混沌序列的图像加密算法:混沌系统有许多优秀的固有特性,包括遍历性、非周期性、对初始条件和控制参数的高度敏感性以及伪随机性。典型的基于混沌映射的密码可以分为 置换和 扩散两个阶段。
某些算法的置换操作仅改变像素位置(即置乱);然而,混沌系统产生的 混沌序列与扩散过程无关。混沌加密具有很强的加密安全性与鲁棒性。
加密过程如下:
步骤1:根据密钥获取混沌系统的混沌序列。
步骤2:由混沌序列将图像像素值替换得混沌序列图像。
步骤3:重复步骤2,直到到达加密图像。
Aqeel ur Rehman等人(2018年)基于混沌理论和SHA 256提出了一种基于DNA互补规则的异或彩色图像加密技术。该研究利用SHA-256散列函数来修正混沌系统的初始条件和控制参数。根据分段线性混沌映射产生的混沌序列,将彩色图像的三个通道排列成一个一维向量并进行排序。然后,这个排列的阵列被分成三部分,每个部分代表一个颜色通道,并使用洛伦兹混沌系统再次独立排列。一旦进行了双重置换,每个通道的每个像素都被无序地独立编码成脱氧核糖核酸(DNA)碱基。
该算法的新颖之处在于,通道的每个像素都被DNA互补规则的异或运算所取代。利用多条DNA规则以随机次数按顺序重复此操作。此操作迭代将循环进行。循环操作开始时的DNA规则选择和操作继续依赖于陈氏混沌序列。大量的仿真实验结果表明,该算法在一轮加密中取得了良好的加密效果。
下图为基于Lorenz混沌序列的图像加密效果图:


2)使用置换的彩色图像加密算法
排列的常见级别为位级别、像素级别和块级别排列,此外,行置乱和列置乱被分类为块级别排列。位级置换(BLP)是2011年首次提出的一种新方法,在图像加密的置乱阶段被利用。在BLP中,图像被认为是由一个位矩阵组成的,所有的加密效果都被应用到该矩阵中;因此,加密后图像最终应反映这些加密效果的位分布。相比之下, 以前的图像加密算法用于在像素级执行加密过程,而BLP直接作用于普通图像中的每个位,而不是像素级的位组。大多数先前提出的图像加密算法在普通图像的不同位平面之间执行几轮2维和3维置换,随后将不同置换位平面组合以生成混淆(加密)的彩色图像。
如:
Abhimanyu Kumar Patro和Acharya(2018)在中提出了一种基于多级置乱操作的安全多图像加密技术;该技术与当前使用的多种图像加密技术完全不同。在所提出的加密技术中使用了三级置换操作,第一、第二和第三级置换操作在R、G和B分量中执行像素置乱操作,行置乱操作在像素洗牌的R、G和B分量之间执行,列置乱操作在行置乱组件之间,各自进行。
最后,使用所提出的加密算法执行块扩散操作,以获得最终的加密图像。此外,该算法使用的密钥不仅依赖于原始密钥值,而且还依赖于原始彩色图像。这支持针对已知纯文本和选定纯文本攻击的算法。仿真结果和安全性分析表明,该算法具有加密效果好、密钥空间大、对密钥和明文敏感度高、相邻像素相关性弱、像素随机性大、对各种常见攻击具有足够的抵抗能力等特点。
3)光学彩色图像加密算法
有学者因经典光学双随机相位编码(DRPE)系统结构启发而在提出一些光学图像加密技术。光学DRPE方法及其数值模拟算法首先结合基于输入信号传播的系统各个阶段的采样考虑因素进行了研究。然后,研究了各种著名的光学激励加密技术,并将其分为光学技术和图像置乱技术。对每种方法进行了数值实现,并与光学DRPE方案进行了比较,其中在不同变换后应用了随机相位扩散器(掩模)。
首先,演示了每种方法所采用的光学系统,然后检查了相应的数值算法的实现,以保持光学对应物的特性。常见的光学图像加密包括菲涅耳变换(FST)、偏振、回转器变换(GT)、哈特利变换、双随机相位编码和分数傅里叶变换(FFT)。下面。
如:Abuturab介绍了一种在GT域结构化相位编码中使用离散余弦变换的新方法,但用于保护彩色图像。该研究中提出的技术中,通过离散余弦变换(DWT)改变像素值的空间分布,将要加密的输入彩色图像分成三个通道,每个通道分别进行独立加密,然后使用结构化相位掩模对它们进行编码。GT是在合成光谱上进行的。在该方法中,结构化相位掩模、离散余弦变换和GT被两次使用。此外,结构化相位掩模的结构参数和GT在每个通道中的角度参数是主要的加密密钥。此外,在该方法中给出了电光实现原理图,所提出的结构不需要轴向移动。针对选定的和已知的纯文本攻击,证明了该算法的有效性;此外,数值仿真验证了该方法的安全性、有效性和性能。
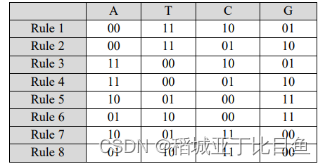
4)基于DNA的彩色图像加密
使用下表将图像编码为DNA碱基很简单。R、G和B通道使用四种DNA规则编码。以下介绍了在基于DNA的彩色图像加密领域完成的一些研究。
Wu等人(2015)提出了一种基于DNA序列运算和多个性能优异的改进一维混沌系统的彩色图像加密新方案。在本研究中,首先使用秘密密钥和普通图像以及密钥流从三个改进的一维混沌系统生成密钥流;此外,根据DNA编码规则将普通图像随机转换为DNA矩阵。其次,对DNA矩阵进行DNA互补和异或运算,得到乱序DNA矩阵。在第三步中,将打乱的DNA矩阵平均分解为块,然后将这些块随机洗牌。
表1.DNA序列编码和和解码的几种映射规则
5) 基于频域的彩色图像加密
水印或隐写技术可分为在空间域的与频率域的。空间域过程是考虑图像中像素插入水印的最古老技术。频谱和最低有效位(LSB)是常用的方法。然而,空域技术并不能抵抗所有类型的攻击。另一方面,通过使用离散小波变换(DWT)、脊波变换、离散余弦变换(DCT)、离散阿达玛变换(DHT)和离散傅里叶变换(DFT)变换原始图像,使用频域技术插入水印。然后,执行水印插入过程。这些技术被广泛接受,并且对所有类型的攻击都更具鲁棒性。以下是基于频域的彩色图像加密领域的一些研究。
Liu等人利用Arnold变换和DCT设计了一种彩色图像加密算法。该算法利用Arnold变换对彩色图像的RGB分量进行像素序列置乱。在由随机角度定义的矩阵控制下,随机交换和混合加扰后的RGB分量。采用DCT变换改变彩色图像的像素值。在该加密方案中,上述操作连续执行两次。采用Arnold变换和随机角度参数作为彩色图像加密方法的密钥。为了验证颜色加密算法的有效性和性能,进行了一些数值模拟。
基于频域的图像加密算法的优点是结构简单,易于实现;但使用这些算法的最重要原因是计算复杂度低。
6)基于哈希的彩色图像加密
哈希函数通常用于生成固定长度的输出位(相当于输入任意一篇文章,输出固定长度的摘要),用作为原始数据的缩短摘要。自从MD5的冲突被解决后,SHA-2已变得更适合密码系统设计,它由一组哈希函数组成,其摘要(digests:消息摘要:长度不固定的消息(message)作为输入参数,运行特定的Hash函数,生成固定长度的输出,这个输出过程就是Hash,也称为这个消息的消息摘要Message Digest)为224、256、384或512位,但迄今为止尚未发现冲突。2012年10月2日,Keccak被选为NIST哈希函数竞赛的获胜者,成为SHA-3。
一些散列函数为灰度图像设计的,另外一些散列函数(如以下方法)是为RGB彩色图像设计的。
如:
Dong(2015)设计了一种基于混沌的非对称彩色图像加密方案。将普通图像 散列值转换为分段线性混沌映射(PWLCM)的三个初始值,然后迭代生成三个伪随机序列,分别漫反射R、G和B分量。将散列值和初始迭代次数m作为加密过程中的密钥;此外,PWLCM的三个初始值和初始迭代数n被用作解密过程中的密钥。数值结果表明了所提出的非对称彩色图像加密系统的可行性和有效性。
7)使用进化方法的彩色图像加密
目前,科学家们非常重视进化算法(EAS),并在许多应用中使用。顾名思义,基于EA(evolutionary algorithms)的方法具有迭代性质,这种特殊特性有助于算法在每次迭代中改进其结果。EAS的主要优势在于,它能够以最少的信息处理问题,而不会留下任何引导结果的中间计算细节。这最后一点完美的使数据加密领域任何密码分析尝试复杂化等相当困难。因此,数据加密问题可以通过优化程序解决,从编码操作到最终结果的实现,通过以下小节保持详细的总体结构。在一项调查中,Enayatifar等人提出了一种基于加权离散帝国主义竞争算法(WDICA)的加密方法,或一种由遗传算法(GA)和Abdullah等人提出的混沌函数组成的混合模型。Kuppusamy等人提出了一种局部图像加密优化方案,使用daubechies 4域内采用粒子群优化(PSO)技术选择的变换图像的高能系数进行加密。此外,还设计了一些基于进化的彩色图像加密方法,如以下算法。
有学者介绍了一种新的彩色图像加密算法。在该研究中,获得了彩色平面图像RGB分量的24(R、G、B各8位)位平面,并将其重组为4个复合位平面;这可能会使这三个组成部分相互影响。一个四维(4D)记忆超混沌系统生成伪随机密钥流,其初始值来自彩色普通图像的SHA256散列值。基于 遗传重组原理对复合位平面和密钥流进行混淆,然后将混淆和扩散作为位平面的并集,得到彩色密码图像。实验结果和安全性分析表明了该算法的安全性和有效性;因此,它可以用于安全通信。
图像加密中的进化方法在创新方面有所提高,但这些算法的主要优点是其 高灵敏度和安全性。
8) 使用位平面分解的8位二进制彩色图像加密
灰度图像中的每个像素可以表示为8位二进制值,由下等式分布。
P(x,y)=K(8),K(7),K(6),K(5),K(4),K(3),K(2),K(1)
通常,8位灰度图像的上四位平面包含大量信息(即第8、第7、第6和第5),而下四位平面(第4、第3、第2和第1)包含的信息较少。像素信息百分比分布为下等式所示:
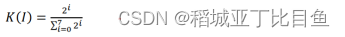
因此,利用位平面技术将图像分解为子部分,此外,使用二值位平面分解将灰度图像分离为8位二值平面,如图2所示;其中,第n位平面实际上由每个像素的二进制表示的所有第n位组成。非负十进制数N可用二进制序列(bn-1...b1,b0)表示,如下等式:

Sravanthi等人提供了另一种图像加密技术。考虑到使用分段线性混沌映射(PWLCM)和二维逻辑调整正弦映射的 位平面操作。最初,位平面扩散。使用PWLCM系统执行操作,然后使用二维逻辑调整正弦映射执行行洗牌和列洗牌操作。此外,利用安全散列算法SHA-256更新所提出密码系统的密钥,以抵抗已知明文和选择明文攻击。位平面运算是该算法的主要意义。除了同时扩散像素外,此操作还会混淆像素。仿真结果表明,该密码系统具有较好的加密效果,安全性分析表明,该密码系统对最常见的攻击具有较强的抵抗能力。
下图为彩色Lena图像的位平面分解图:
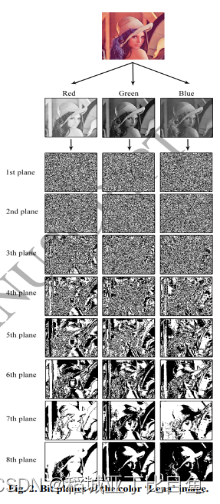
9)彩色图像的双(多)图像加密
使用迭代相位检索技术的双灰度图像加密算法包括一系列向前和向后迭代。为了检查双色图像,将分别对三组灰度图像(彩色图像分解为R、G和B通道,每个分量视为灰度图像)进行加密。但是,在这种方法中不使用颜色组件之间的相互关系。它还导致三倍大的迭代循环和相位函数。为了减少互联网上的图像通信过载,双(多)图像加密近年来引起了极大的兴趣。多重图像加密的优点是能够同步加密多个图像。一些研究人员提出了各种加密算法,包括双重(多重)图像加密;下面列出了一些关于双色图像加密的研究。
Wei等人(2017)提出了一种基于离轴全息和最大长度网状(cellular 蜂窝真状的、网状的;全息学(一种不用透镜的照相术;它利用激光在底片上记录出立体的形象。))自动机(MLCA)的双色图像加密方案。原始图像被分为红色、绿色和蓝色三个通道,每个通道使用MLCA掩码独立加密,以改变空间域中的强度值。然后将不同入射角的参考波引入离轴傅里叶变换全息图,实现双色图像加密。每个通道中离轴傅里叶变换的系统参数也是图像加密和解密的关键。在解密一幅原始图像时,利用了具有一定入射角的参考波和相应的MLCA掩模。一些数值模拟证明了所提方案的有效性,本文作者给出了初步实验的结果。有学者提出了一种光学双色图像密码,使用二维混沌Arnold变换(AT)作为预处理置乱阶段,并在基于菲涅耳(Fr)的Hartley变换(HT)中使用二维混沌逻辑调整正弦映射(LASM)相位掩模。在这种光学双色图像密码中,利用二维混沌等离子体产生混沌相位掩模。首先利用二维混沌对彩色平面图像RGB通道进行置乱。在下一步中,使用二维混沌等离子体相位掩模对加扰的彩色平面图像R-G-B通道进行调制,并使用基于Fr的HT进行变换。变换后的复R-G-B通道的分布用二维混沌AT置乱,用二维混沌等离子体相位掩模调制,然后用基于Fr的HT变换。除了2D混沌AT,2D混沌等离子体相位掩模的使用提供了有效的密钥管理和通信。此外,光学几何参数被视为额外的密钥,增强了该方案的保密性。对所提出的方案进行了全面的安全性研究,测试结果验证并确保了所提出方案的高安全性和抵抗大多数潜在攻击的能力。
10)使用置乱变换的彩色图像加密
图像置乱是一种图像加密或辅助加密技术[172],也是图像隐藏、共享和数字水印中预处理和后处理的重要方法。Arnold变换、Jigsaw变换、Fibonacci变换、Knight's tour、Lucas变换、幻方变换、格雷码、细胞自动机、Baker映射和亚仿射变换是图像加密中流行的图像置乱方法。使用置乱变换在彩色图像加密领域完成的一些研究如下。
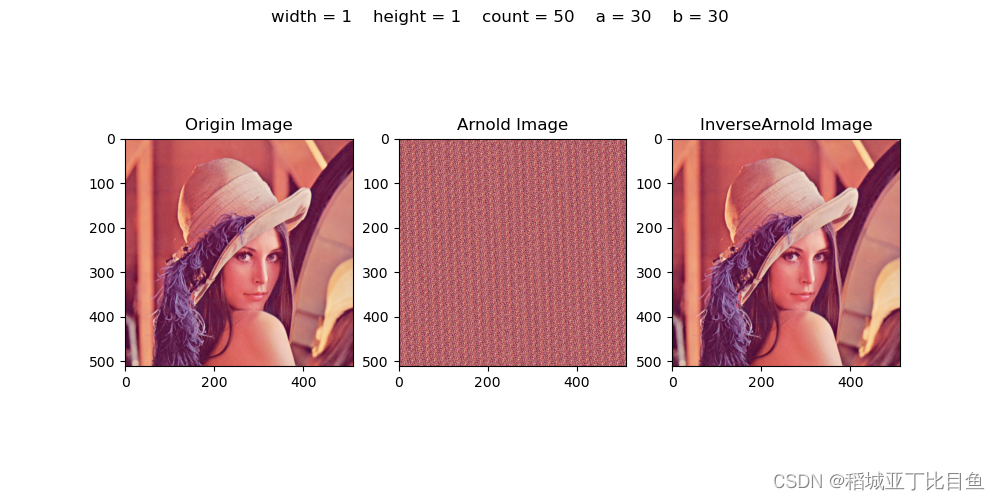
有学者提出了一种利用GT和Arnold变换的彩色图像加密方案;该方案包括两个安全级别。在方案的第一级,将彩色图像分为红色、绿色和蓝色三个分量,并使用Arnold变换对其进行归一化和置乱。绿色分量与第一个随机相位掩模组合,并使用GT转换为过渡。加密结果在一定程度上符合平稳白噪声分布和伪装特性。在加密和解密过程中,GT的旋转角度、Arnold变换的迭代次数、混沌映射的参数以及产生的伴随相函数作为加密密钥,从而提高了系统的安全性。仿真结果和安全性分析证实了该方案的安全性、有效性和可行性。
下图为基于Arnold变换加密示意图

4.图像加密的安全等级
低级:如果加密方案不能抵御密码分析攻击,则安全性将被评估为较低。
中级:如果加密方案对某些密码分析攻击是安全的,则安全性评估为中等。
高级:如果它对所有密码分析和特殊攻击都是鲁棒的,则该方案被评估为高度安全。
5.图像加密的评价指标
1)直方图分析(Histogram Analysis:):直方图显示图像的灰度强度和统计信息,以及像素强度值的分布,此外还提供有关直方图攻击中使用的普通图像的信息。然而,在直方图一致的情况下,信息变得不可预测,可以避免直方图攻击。
2)相关性分析(Correlation Analysis:):平面图像中的两个相邻像素在垂直和水平方向上具有强相关性。这是图像的特性,相关系数的最大值和最小值分别为1和0;对统计攻击进行稳健加密的图像的相关系数值应为0。
3)信息熵分析(Information Entropy Analysis):熵分析是对信息随机性的一种度量,计算每个颜色通道的每个灰度的像素扩散。如果分布更均匀,它将更强地抵抗统计攻击。对于彩色图像,强度在0-255之间的R-G-B通道和加密消息的理想熵分数越高,值越高,分布越均匀。
4)加密质量(Encryption Quality: ):加密质量(EQ)表示每个灰度级L的平均变化次数。图像EQ可通过以下等式确定,其中E(i,j)和i(i,j)是加密图像和普通图像中网格(i,j)处像素的灰度值,每个像素的大小分别为M×N个像素和L个灰度级。很明显,I(I,j)和E(I,j)∈ {0,1,...,L-1}。HL(I)和HL(E)将分别定义为普通图像和密码图像中每个灰度级L的出现次数。EQ值越大,加密安全性越好。
5)敏感度:表示更改清晰图像中的单个位必须导致加密图像中至少50%的位发生更改。使用两个参数评估灵敏度:像素数变化率(NPCR)和统一平均变化强度(UACI)。NPCR和UACI分别表示两个加密图像之间的变化像素数和两个加密图像之间的平均变化强度数。NPCR和UACI的理想值分别为99.61%和33.46%。
6)雪崩效应:雪崩效应是指在纯文本中改变一位时,密码文本中改变的位所占的比例。雪崩效应的理想值为0.5,它通常用于指示密码文本中发生变化的比特数的比率,而系统中的比特数略有变化。
7)密钥空间分析:指能够用于产生密钥的所有可能密钥的集合,是决定密码系统强度的最重要特征之一。尝试查找的次数直接指密码系统的密钥空间随着密钥大小的增加呈指数增长。也就是说,将一个算法的密钥大小加倍并不仅仅是将所需的操作数加倍,而是将它们平方化。密钥大小为128位的加密算法将密钥空间定义为2128,使用现代高性能计算机检查所有可能的密钥大约需要1021年。因此,密钥大小为128位的密码系统在计算上看起来对暴力攻击具有鲁棒性。安全算法应该对密钥完全敏感,即加密图像不能通过密钥的细微变化来解密。
8)密钥敏感性分析:理想的多媒体加密应该对密钥敏感,也就是说,密钥中单个比特的变化应该伴随着产生完全不同的加密结果,称为密钥敏感性。一般来说,混沌密码的密钥敏感性是指混沌映射初始状态的敏感性以及控制参数的敏感性。
对比度调整:为了便于观看,图像必须具有适当的亮度和对比度,其中前者表示整个图像的亮度或黑暗度,而后者定义亮度差,以确定不同区域的清晰分离。因此,对比度调整是一种图像处理机制,其中输入强度被映射到期望水平以增强感兴趣的区域或区域。这种对比度增强在加密图像上以70%和30%的两个不同级别应用,较低的值意味着较高的对比度,然后比较解密图像和原始图像。
9)高斯噪声分析:通信噪声的失真、退化和污染在物理世界中很常见。因此,为了测试算法在这种情况下的鲁棒性,数字被均值为零且方差为0.0001、0.0003和0.0005的高斯噪声污染,并且再次在加密图像中添加了密度为1%、5%、10%和25%的椒盐噪声。对有噪声的加密图像进行解密,并对结果进行比较。因此,抗噪声的鲁棒性是测试加密方案性能的重要指标。
10)遮挡噪声分析:当通过互联网进行通信时,图像的一部分可能会被剪切甚至丢失,因此建议的密码必须能够以适当的方式处理有损图像的加密。为了显示针对这种情况提出的密码的强度,从图形中移除红色通道的像素块、绿色通道的像素块和所有通道的像素块,然后对它们进行加密;如果原始信息在解密后被保留,并且可以可视化原始图像的内容,则建议的密码将能够处理有损图像的解密。
11)直方图均衡化:图像的直方图包括灰度范围和每个灰度的出现情况[96]。在对有噪声的加密图像进行解密后,如果图像的视觉信息保持不变,则所提出的密码将能够对直方图均衡化进行反击。利用峰值信噪比(PSNR)参数对直方图均衡化进行评估。PSNR是峰值信号功率与噪声功率之比。基本上,均方误差(MSE)表示隐藏和原始图像之间的总平方误差。MSE和误差之间存在比例关系,其中MSE的Ler值与Ler误差相同。m x n单色图像的关系如下所示。因此,MAX表示图像像素的最大值。总的来说,对于每个采样8位的像素,图像的值是255。
12)JPEG压缩:这也是图像处理中常见的操作。在仿真中,首先使用不同的质量因子对加密图像进行压缩;较大的质量因子意味着较小的压缩率,在JPEG压缩后产生更好的图像质量。在解密图像和原始图像之间比较PSNR值。如果仍然可以识别解密后的图像,则该算法对JPEG压缩攻击具有鲁棒性。
13)裁剪攻击:在实际应用中,图像裁剪是一种非常常见的操作,这种操作可能导致数据丢失。裁剪是有意删除加密图像中的一些像素值,并将其传递给解密算法。然后对解密后的图像进行分析,测试所采用的加密方案的鲁棒性。
速度分析:分析图像加密算法的计算代价是必要的。与文本相比,多媒体数据的容量大得惊人。如果密码系统在重要性方面对所有多媒体数据位进行同等加密,计算复杂度可能为H,这通常被证明是不必要的。加密方案的速度也是实时应用中的一个重要问题。
14)随机性测试:为了保证密码系统的安全性,密码必须具有分布性好、周期长、复杂度高、效率高等特点。这些测试的主要目的是集中于序列中各种可能的随机性。其中一些测试包括许多子测试。最近,NIST设计了一组不同的统计测试,旨在证明基于硬件或软件的加密随机数或伪随机数生成器生成的二进制序列的随机性。
15)纯密文攻击:当密码文本本身可用时,试图解密密码文本的攻击。对手试图恢复相应的纯文本或加密密钥。
16)已知纯明文攻击:对手试图在访问密码文本和相关纯文本时恢复密钥。
17)选择明文攻击:具有良好扩散特性的图像加密算法能够抵抗选择纯文本攻击。然而,当几种现有的图像加密算法使用相同的安全密钥加密原始图像时,它们的加密图像是重复的。攻击者利用此安全弱点,使用选定的纯文本攻击破坏加密算法。
参考文献
[1].Ghadirli H M, Nodehi A, Enayatifar R. An overview of encryption algorithms in color images[J]. Signal Processing, 2019, 164: 163-185.
Original: https://blog.csdn.net/qq_48951688/article/details/125565984
Author: 稻城亚丁比目鱼
Title: 图像加密技术综述(常见的图像加密算法简介)
相关阅读2
Title: 人脸识别AdaFace学习笔记
背景
由于人脸图像的模糊和退化,在低质量的数据集中进行人脸识别具有一定的挑战性。如图1所示,低质量人脸图像的缺陷在于当图像退化过大时,会丢失掉相关身份信息,导致无法正常识别。由于在视频监控等场景中经常出现低质量的图像,低质量图像正逐渐成为人脸识别数据集的重要组成部分,如何在训练中利用好这些低质量图像已成为亟需解决的问题。

图1 具有不同图像质量的图像示例
创新点
(1)作者提出了一种基于图像质量自适应的损失函数,该函数能够根据图像质量为不同难度的样本分配不同的权重。
(2)作者观察到角度裕值 (angular margin) 会根据训练样本的难度来对梯度进行缩放。基于这一现象,作者自适应地改变裕值函数以在图像质量高时强调难例样本,如果图像质量低则忽略超难例样本(无法识别的图像)。
(3)作者证明了特征规范化可以表示图像质量,从而无需使用额外的模块来估计图像质量。
相关工作
1、基于裕值的损失函数
将裕值添加到基于softmax loss的损失函数中可以增强学习特征的判别力,经典的方法有SphereFace、CosFace以及ArcFace,通用公式如下:
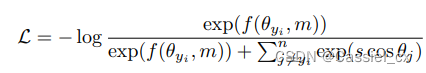
其中, 是特征向量与第
个分类器权重向量之间的夹角,
是
标签的索引,
是裕值,是一个尺度超参数。
是裕值函数,不同损失函数有不同的
,公式如下:
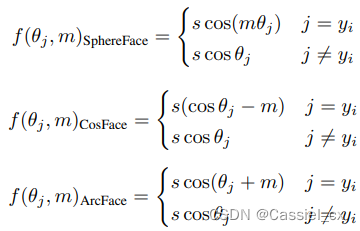
2、自适应损失函数
许多研究已经在训练目标中引入了自适应学习,如 CurricularFace,它在训练的初始阶段将余弦相似度的裕值设置得较小,以便学习简单样本,在训练后期,裕值逐渐增大以学习难例样本。公式如下:
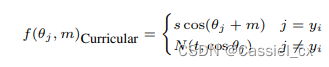
其中,
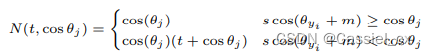
是随着训练进行而逐渐增加的参数。
方法论
对于样本 ,它的 cross entropy-softmax 损失如下:
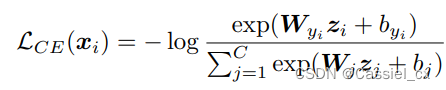
其中, 是样本
的嵌入特征,
是
对应的标签。
是最后一个全连接层权重矩阵的第 j 列,
是对应的偏移值。
是训练集中的样本类别总数。
为了使训练目标直接优化余弦距离,SphereFace 和 NormFace 使用归一化的 softmax,其中偏移值设置为零,并且在训练期间对特征 进行归一化并用 s 进行缩放。 修改后的损失函数如下:
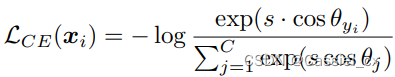
基于上述公式,ArcFace 和 CosFace 在此基础上引入了一个裕值以减少类内变化并增强特征的判别力。
1、裕值和梯度
以前关于基于裕值的 softmax 的工作集中在裕值如何改变决策边界以及它们的几何解释是什么。作者展示了在反向传播期间,角度裕值可以在梯度方程中引入一个附加项,根据样本的训练难度缩放信号。为了证明以上说法,作者展示梯度方程如何随裕值函数变化,
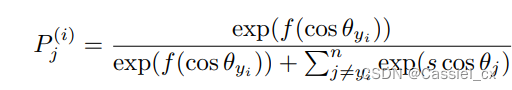
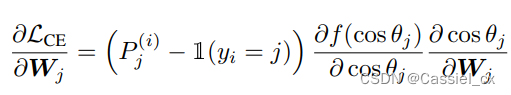
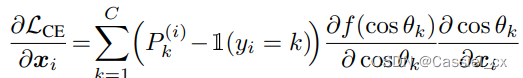
其中, 是对输入
进行 softmax 运算并预测为第 j 类的概率输出,可以将公式中的前两项视为梯度缩放项 (GST) 并表示为:
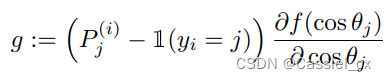
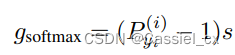
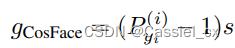
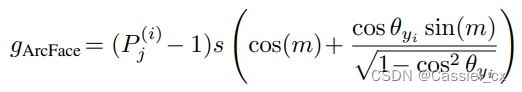
因为 GST 是关于 和
的函数,那么则可以根据训练难度 (
) 对不同的样本分配不同的权重。
在图3中, 和
分别表示不带和带有裕值的决策边界,简单样本会靠近
(正确分类),而困难样本则会靠近
(错误分类)。弧线里面的颜色代表了 GST 的大小,深红色区域的样本对训练的贡献更大,裕值只影响决策边界的位置,而不影响 GST 的大小。然而,正角度裕值不仅会移动决策边界的位置,还使得决策边界附近的 GST 较大、远离决策边界位置的 GST 较小,因此没有利用好难例样本。AdaFace则基于特征范数值自适应地改变裕值函数,当范数较大时,会对远离决策边界的样本分配较大的权重,当范数较低时,则强调靠近决策边界的样本。
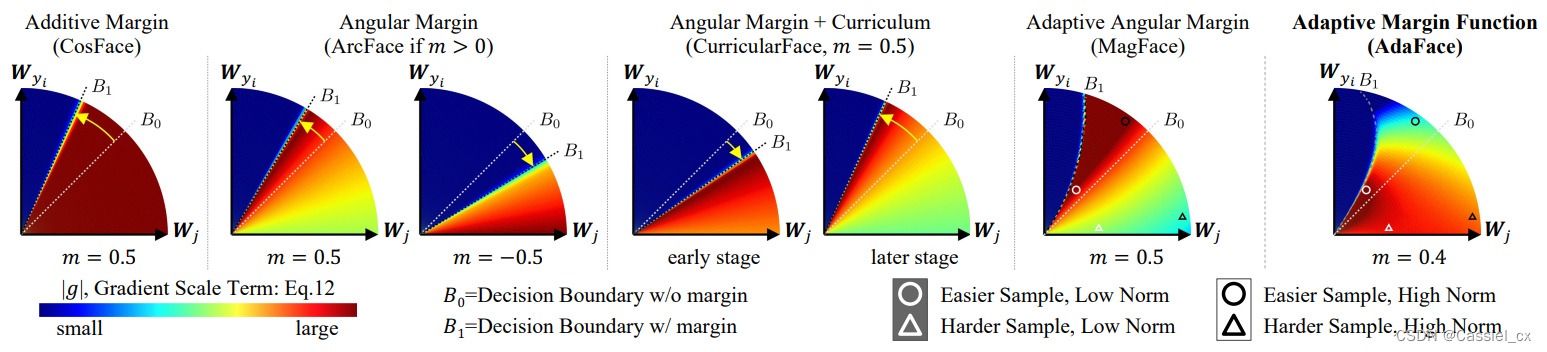
图3 不同裕值函数及其在特征空间上的GST
2、规范化和图像质量
图像质量是一个综合术语,涵盖了亮度、对比度和清晰度等特征。 图像质量评估 (IQA) 在计算机视觉中得到了广泛的研究。在 AdaFace 中,无需引入一个额外的模块来计算图像质量,而直接使用特征范数 (feature norm) 来表示图像质量,特征范数与图像质量密切相关,如图4所示。从图4(a)可以看出,特征范数与图像质量之间的相关性大于概率输出与图像质量之间的相关性。
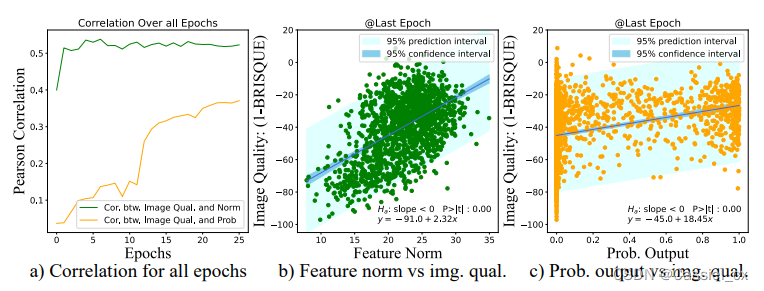
图4 a)各变量间的皮尔逊相关系数图;b)特征范数与图像质量之间的散点图;c)概率输出与图像质量之间的散点图
3、基于特征范数的自适应裕值(AdaFace)
为了解决无法识别的图像引起的问题,AdaFace 基于特征范数来调整裕值函数。此外,由于裕值函数可以改变决策边界的位置,因此可以利用裕值函数来强调样本的不同训练难度。
作为特征范数, 是模型相关量,作者使用批量统计值
和
对特征范数进行归一化,公式如下:
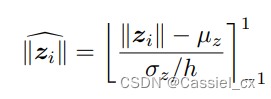
其中, 和
分别是在一个 batchsize 内,所有
的均值和标准差。作者将上式的输出范围限制在-1到1之间。
为0.33,使得
尽可能在 [-1,1] 之间。
此外,如果训练时的 batchsize过小, 和
可能会不太稳定,因此使用指数滑动平均 (EMA) 来稳定批处理统计信息
和
,公式如下:
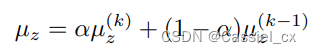
其中, 表示第
次迭代优化,
是一个值为0.99的动量。
公式同上。
AdaFace 损失函数满足以下两个要求:1) 如果图像质量高,则强调难例样本,2)如果图像质量低,则不强调难例样本。作者通过两个自适应项 和
来实现上述功能,这两项分别对应角度裕值和附加裕值。AdaFace 损失函数的公式如下:
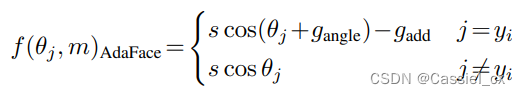
其中, 和
是关于图像质量指标 (
) 的函数,它们的定义如下:
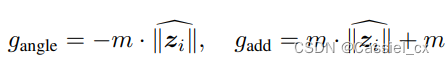
注意到,当 = -1 时,损失函数变成了 ArcFace;当
= 0 时,则变成了 CosFace;当
= 1 时,变成了带有偏移量的负角度裕值。这样,当特征范数较高时,将在远离决策边界的地方获得更高的梯度尺度,而当特征范数较低时,将在决策边界附近获得更高的梯度尺度。 对于低范数特征,远离边界的难例样本被淡化。
实验结果
表1 对各超参数进行的消融实验结果
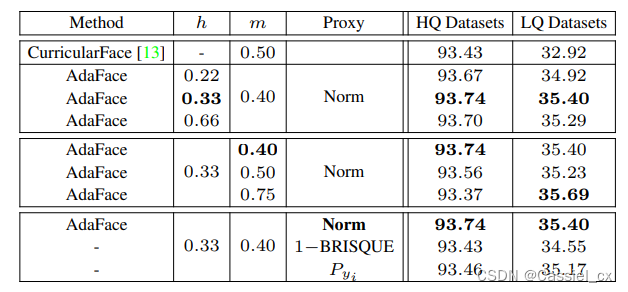
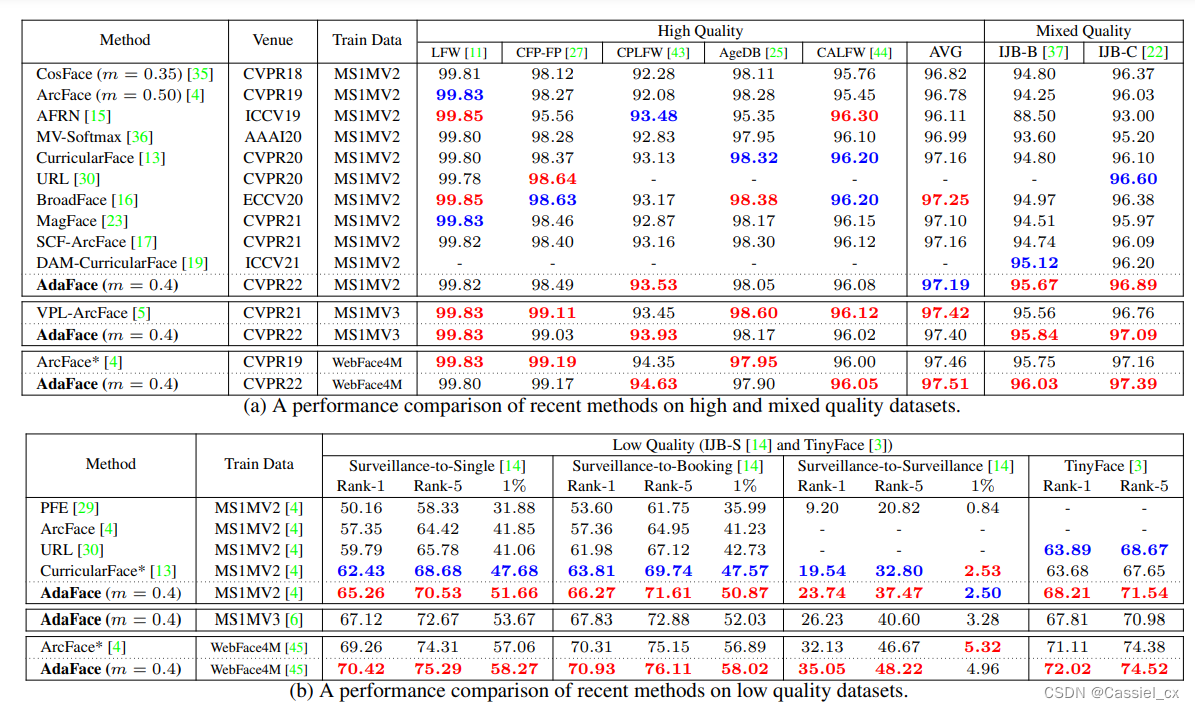
表2 在不同图像质量的数据集中与 SoTA 方法的比较
Original: https://blog.csdn.net/qq_38964360/article/details/125567226
Author: Cassiel_cx
Title: 人脸识别AdaFace学习笔记
相关阅读3
Title: 机器学习笔记 - 同步定位与地图构建 (SLAM)
一、概述
SLAM(simultaneous localization and mapping),也称为CML (Concurrent Mapping and Localization), 即时定位与地图构建,或并发建图与定位。
视觉 SLAM 不涉及任何特定的算法或软件。它指的是确定传感器相对于其周围环境的位置和方向的过程,同时映射该传感器周围的环境。
SLAM 并不是真正的一种技术产品或单一系统。
相反,同时定位和映射是一个更广泛的概念,具有近乎无限的可变性。许多不同的软件解决方案和算法可以实现到基于 SLAM 的系统中,所有这些都取决于环境、用例和所涉及的其他技术。
有几种不同类型的 SLAM 技术,其中一些根本不涉及相机。Visual SLAM 是一种特定类型的 SLAM 系统,当环境和传感器的位置都不知道时,它利用 3D 视觉来执行定位和映射功能。视觉 SLAM 技术有不同的形式,但总体概念在所有视觉 SLAM 系统中的作用方式相同。
二、SLAM 示例
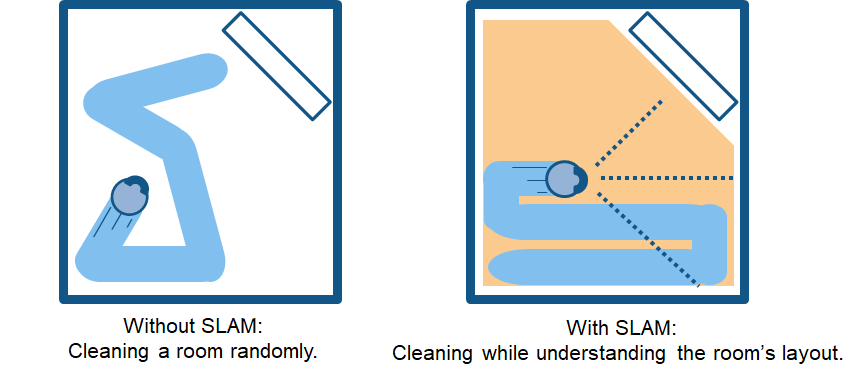
假设有一个家用扫地机器人。没有 SLAM,它只会在房间里随机移动,无法打扫整个地面空间。此外,这种方法会消耗更多功率,因此电池会更快耗尽。相反,采用 SLAM 的机器人可以使用滚轮转数等信息以及来自相机和其他成像传感器的数据,确定所需的移动量。这称为定位。机器人还可以同步使用相机和其他传感器创建其周围障碍物的地图,避免同一区域清洁两次。这称为建图。
三、工作原理
大致说来,实现 SLAM 需要两类技术。一类技术是传感器信号处理(包括前端处理),这类技术在很大程度上取决于所用的传感器。另一类技术是位姿图优化(包括后端处理),这类技术与传感器无关。
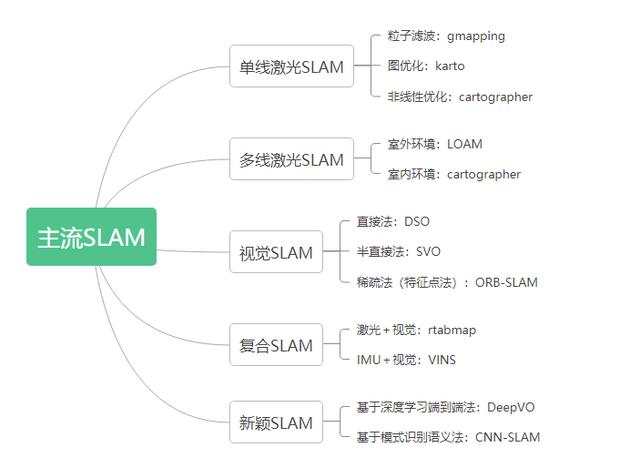
1、视觉 SLAM
顾名思义,视觉 SLAM(又称 vSLAM)使用从相机和其他图像传感器采集的图像。视觉 SLAM 可以使用普通相机(广角、鱼眼和球形相机)、复眼相机(立体相机和多相机)和 RGB-D 相机(深度相机和 ToF 相机)。
视觉 SLAM 所需的相机价格相对低廉,因此实现成本较低。此外,相机可以提供大量信息,因此还可以用来检测路标(即之前测量过的位置)。路标检测还可以与基于图的优化结合使用,这有助于灵活实现 SLAM。
使用单个相机作为唯一传感器的 vSLAM 称为单目 SLAM,此时难以定义深度。这个问题可以通过以下方式解决:检测待定位图像中的 AR 标记、棋盘格或其他已知目标,或者将相机信息与其他传感器信息融合,例如测量速度和方向等物理量的惯性测量单元 (IMU) 信息。vSLAM 相关的技术包括运动重建 (SfM)、视觉测距和捆绑调整。
视觉 SLAM 算法可以大致分为两类。稀疏方法:匹配图像的特征点并使用 PTAM 和 ORB-SLAM 等算法。稠密方法:使用图像的总体亮度以及 DTAM、LSD-SLAM、DSO 和 SVO 等算法。
2、激光雷达 SLAM
光探测与测距(激光雷达)方法主要使用激光传感器(或距离传感器)。
对比相机、ToF 和其他传感器,激光可以使精确度大大提高,常用于自动驾驶汽车和无人机等高速移动运载设备的相关应用。激光传感器的输出值一般是二维 (x, y) 或三维 (x, y, z) 点云数据。激光传感器点云提供了高精确度距离测度数据,特别适用于 SLAM 建图。一般来说,首先通过点云匹配来连续估计移动。然后,使用计算得出的移动数据(移动距离)进行车辆定位。对于激光点云匹配,会使用迭代最近点 (ICP) 和正态分布变换 (NDT) 等配准算法。二维或三维点云地图可以用栅格地图或体素地图表示。
但就密度而言,点云不及图像精细,因此并不总能提供充足的特征来进行匹配。例如,在障碍物较少的地方,将难以进行点云匹配,因此可能导致跟丢车辆。此外,点云匹配通常需要高处理能力,因此必须优化流程来提高速度。鉴于存在这些挑战,自动驾驶汽车定位可能需要融合轮式测距、全球导航卫星系统 (GNSS) 和 IMU 数据等其他测量结果。仓储机器人等应用场景通常采用二维激光雷达 SLAM,而三维激光雷达点云 SLAM 则可用于无人机和自动驾驶。
3、其它类型
除了激光雷达和视觉,还有复合类型的SLAM系统(极光+视觉),以及深度学习的方式。
四、SLAM的应用
SLAM是自动驾驶汽车所用的一种技术,您不仅可以用它构建地图,还可同时在该地图上定位您的车辆。SLAM 算法让汽车能够构建未知环境的地图。工程师们使用地图信息执行路径规划和避障等任务。
视觉 SLAM 系统也用于各种现场机器人。例如,探索火星的漫游者和着陆器使用视觉 SLAM 系统进行自主导航。农业领域的机器人以及无人机可以使用相同的技术在农田中独立行走。
视觉 SLAM 系统在某些应用中取代 GPS 跟踪和导航。GPS 系统在室内或天空视野受阻的大城市中没有用,而且它们只能在几米范围内准确。视觉 SLAM 系统解决了这些问题中的每一个,因为它们不依赖于卫星信息,并且可以对周围的物理世界进行准确的测量。
SLAM与无人机结合。
五、面临的挑战
定位误差累积,导致与实际值产生偏差。
定位失败,地图上的位置丢失。
图像处理、点云处理和优化带来高计算成本。
每项挑战都可以凭借特定的对策加以克服。
六、常见SLAM开源库
OpenSLAM.org OpenSLAM.org ![]() https://openslam-org.github.io/;
https://openslam-org.github.io/;
GitHub - HKUST-Aerial-Robotics/VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator ![]() https://github.com/HKUST-Aerial-Robotics/VINS-Mono ; https://github.com/HKUST-Aerial-Robotics/VINS-Fusion
https://github.com/HKUST-Aerial-Robotics/VINS-Mono ; https://github.com/HKUST-Aerial-Robotics/VINS-Fusion ![]() https://github.com/HKUST-Aerial-Robotics/VINS-Fusion ; Bitbucket
https://github.com/HKUST-Aerial-Robotics/VINS-Fusion ; Bitbucket ![]() https://bitbucket.org/dysonroboticslab/elasticfusionpublic/src/master/; GitHub - tum-vision/dvo_slam: Dense Visual Odometry and SLAM
https://bitbucket.org/dysonroboticslab/elasticfusionpublic/src/master/; GitHub - tum-vision/dvo_slam: Dense Visual Odometry and SLAM ![]() https://github.com/tum-vision/dvo_slam ;
https://github.com/tum-vision/dvo_slam ;
七、常用第三方库
1、Eigen
Eigen 是一个线性算术的C++模板库,包括:vectors, matrices, 以及相关算法。功能强大、快速、优雅以及支持多平台。
2、OpenCV
OpenCV 是 Intel 开源计算机视觉库。它由一系列 C 函数和少量 C++ 类构成,实现了图像处理和计算机视觉方面的很多通用算法。
3、PCL
点云库 (PCL) 是一个独立的、大规模的、开放的 2D/3D 图像和点云处理项目。 PCL 是根据 BSD 许可条款发布的,因此可免费用于商业和研究用途。
4、g2o
g2o(General GraphicOptimization)是一个基于图优化的库,将非线性优化与图论结合起来的理论,我们可以利用g2o求解任何可以表示为图优化的最小二乘问题。
5、Ceres
Ceres solver 是谷歌开发的一款用于非线性优化的库,在谷歌的开源激光雷达slam项目cartographer中被大量使用。
八、参考资料
布法罗大学+SLAM+讲义PPT-机器学习文档类资源-CSDN下载布法罗大学SLAM讲义PPT下载。1、SLAM是一种用于在未知环境或已知环境中构建地图同时跟踪当更多下载资源、学习资料请访问CSDN下载频道.https://download.csdn.net/download/bashendixie5/85054352 ; SLAM领域著名实验室及大牛、SLAM领域大佬(不定期更新)_人工智能博士的博客-CSDN博客_slam大牛目录SLAM领域著名实验室1. 苏黎世联邦理工学院2. 明尼苏达大学3. 慕尼黑工业大学4. 香港科技大学5. 浙江大学6. 武汉大学7. 中科院自动化研究所国家模式识别实验室Robot Vision Group8. 清华大学自动化系宽带网络与数字媒体实验室BBNC9 加拿大谢布鲁克大学Int...
https://blog.csdn.net/qq_15698613/article/details/84871119 ;
Original: https://blog.csdn.net/bashendixie5/article/details/123511423
Author: 坐望云起
Title: 机器学习笔记 - 同步定位与地图构建 (SLAM)