
抵扣说明:
1.余额是钱包充值的虚拟货币,按照1:1的比例进行支付金额的抵扣。
2.余额无法直接购买下载,可以购买VIP、C币套餐、付费专栏及课程。
Original: https://blog.csdn.net/qq_35812205/article/details/123781093
Author: 山顶夕景
Title: 【推荐算法实战】DeepFM模型(tensorflow版)
相关阅读1
Title: delf配置:基础环境(一)
windows下delf配置:delf环境(二)
windows下delf配置:delf测试(三)
一、版本
github配置源码的时候一定要看文档!!!!
一定要注意版本要求,否则后期bug一堆,环境重配!!!
官方文档
https://github.com/tensorflow/models/tree/master/research/delf
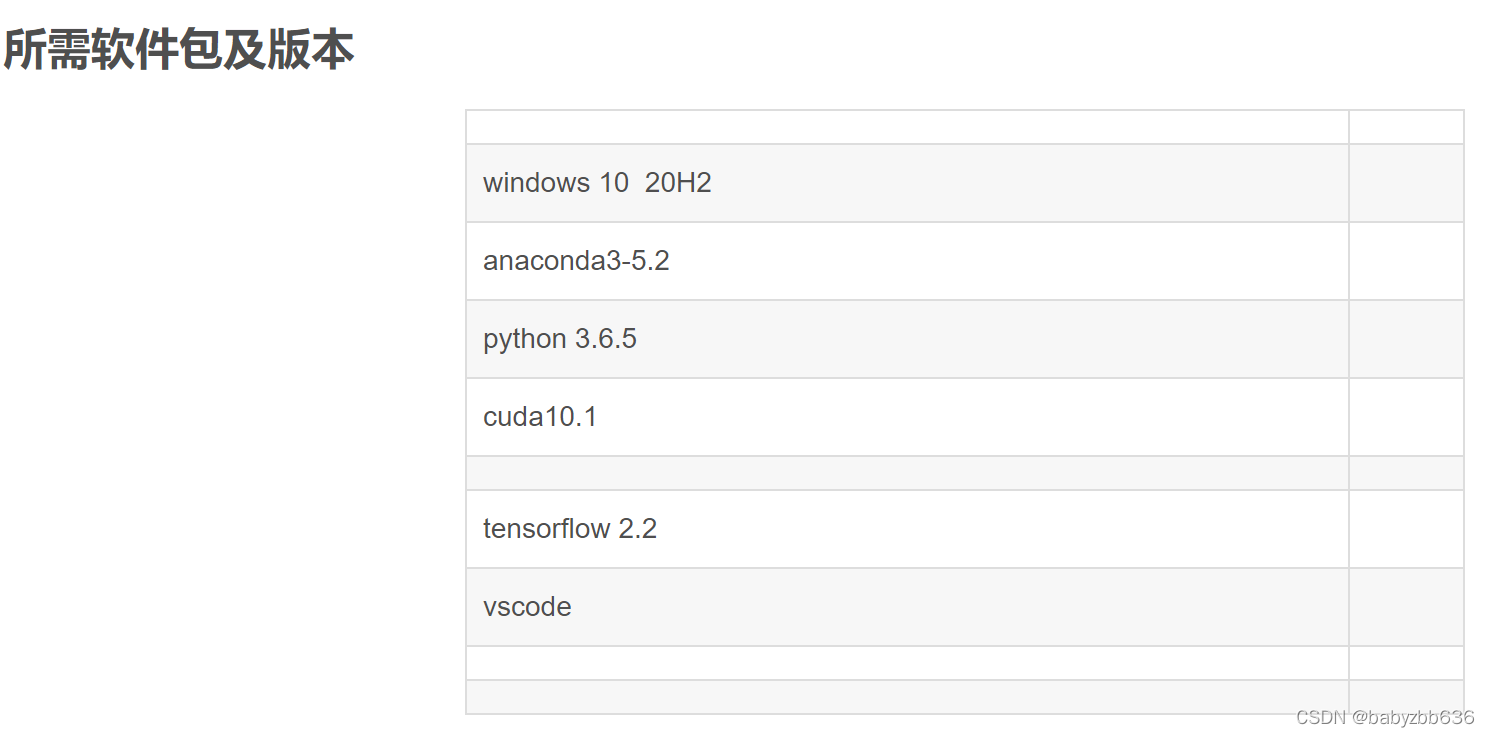
; 二、安装tensorflow-gpu
conda install tensorflow-gpu
参考win10 配置tensorflow gpu版–不用装CUDA
说个坑,这样比较方便,不用安装nvida、cuda,但是默认是安装最新的package,最新的一般问题较多资料也难找,import keras一直报错,说是tensorflow和keras版本不对应啊,但是也有网友说tensorflow2.6对应keras2.6,但是也不行,坑啊 ,搞了一晚上
千万不要因为怕麻烦不安装cuda、cudnn,安装新版本调bug更麻烦还要从头再来
2.1推荐用pip安装tensorflow-gpu
- 一配置python环境变量(来回切换太麻烦)
- 二在AncondaPromt里面activate 某env,就可以使用当前环境的pip(推荐)
conda create -n tensorflow python=3.6
activate tensorflow
pip install numpy
pip安装tensorflow
pip install -i https:
也可以使用下面的命令安装cpu版本的tensorflow
pip install -i https:
上面是用清华镜像安装,公网用户可以将镜像地址替换为豆瓣
http:
2.2pip安装keras
tensorflow2.2.0对应keras2.3.1
pip install i https:
pip install i https:
三、安装cuda(cuda drive)、cudnn
3.1下载CUDA10.1
- 官网,下载地址 CUDA Toolkit 10.1 update2 Archive | NVIDIA Developer
- 官网,cudnn要与cuda一致,cudnn下载地址或者cudnn下载较慢,采用其他博主分享,cudnn-10.1-windows10-x64-v7.6.0.64.zip_免费高速下载|百度网盘-分享无限制
或者参考我之前博客分享的cuda10.0与对应cudnn
3.2安装CUDA10.1
- 如果没有安装drive,可以一起安装,比较方便
- CUDA安装很简单,运行CUDA安装程序,全程默认安装。
- 若显示,安装失败,则可能是vs插件的问题,后来看到提示,是Visual Studio Intergration没有对应的vs版本,如果不需要在vs中安装,可以省去,参考之前博客
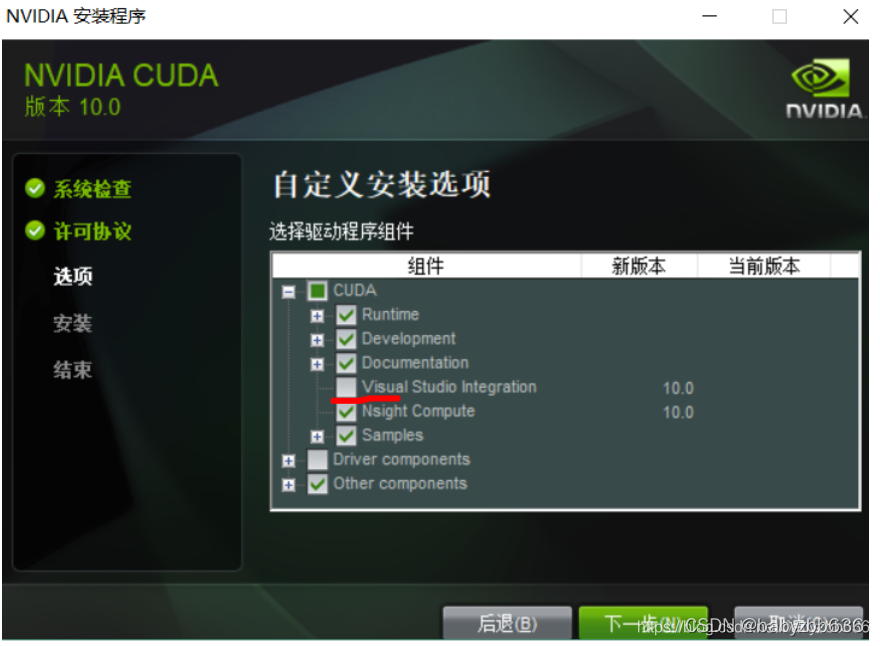
; 3.3cuDNN安装
先解压,然后将下面的文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1目录,这个是CUDA10.1默认安装目录。
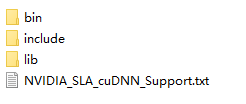
覆盖完成后的文件夹是这样的
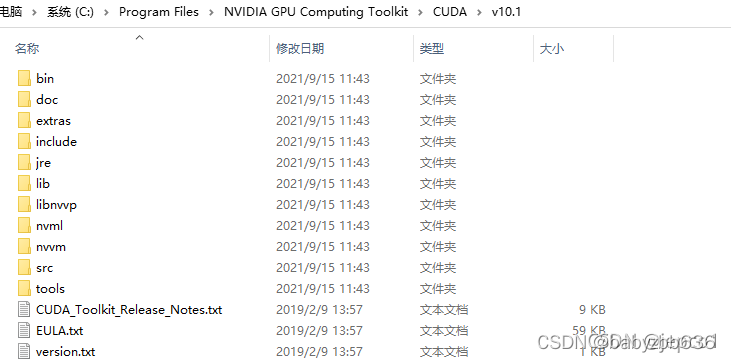
3.4 配置环境变量
在系统设置中选择path
在path中添加以下目录,
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib\x64
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\CUPTI\lib64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.1\bin\win64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.1\common\lib\x64
3.5 测试cuda
cmd,输入nvcc -V(中间有空格)后,按回车,会显示CUDA的版本号信息,表明安装成功
nvidia-smi显示gpu使用(注意没有空格)
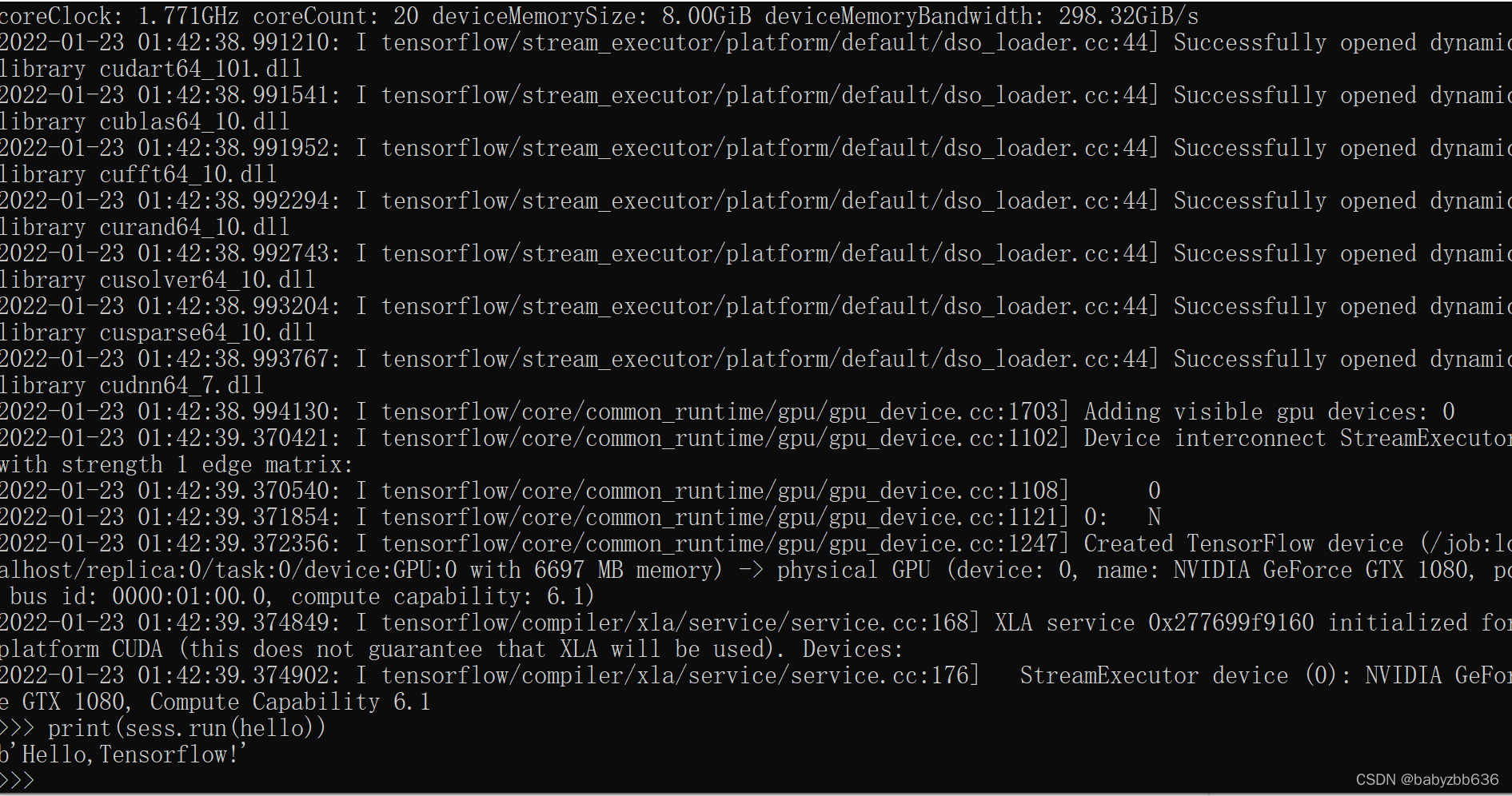
3.6测试tensorflow-gpu
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
hello=tf.constant('Hello,Tensorflow!')
sess=tf.compat.v1.Session()
print(sess.run(hello))
参考博客
1、DELF: DEep Local Features在windows10环境下的安装配置
Original: https://blog.csdn.net/babyzbb636/article/details/122630653
Author: babyzbb636
Title: delf配置:基础环境(一)
相关阅读2
Title: 【语音识别】玩转语音识别 2 知识补充
【语音识别】⚠️玩转语音识别 2⚠️ 知识补充
概述
从今天开始我们将开启一个新的深度学习章节, 为大家来讲述一下深度学习在语音识别 (Speech Recognition) 的应用. 语音识别技术可以将语音转换为计算机可读的输入, 让计算机明白我们要表达什么, 实现真正的人机交互. 希望通过本专栏的学习, 大家能够对语音识别这一领域有一个基本的了解.

; RNN
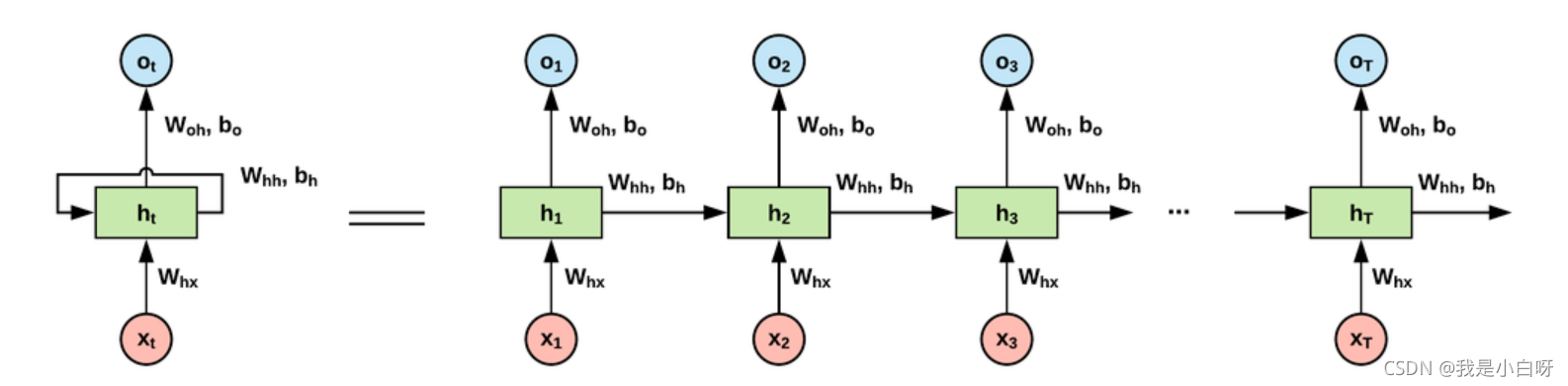
RNN (Recurrent Neural Network) 即循环神经网络, 用于处理输入有相关性的任务. RNN 网络包括一个输入层, 一个隐层, 和一个输出层组成, 如图:
计算
隐层 (Hidden Layer) 定义了整个网络的状态, RNN 网络的计算过程如下:

计算状态 (State)

计算输出:
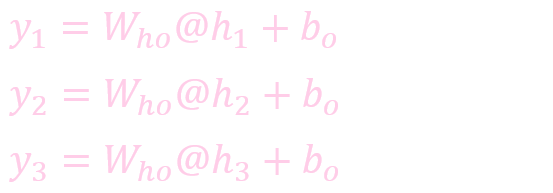
; RNN 存在的问题
梯度消失问题 (Vanishing gradient problem). 如果导数小于 1, 随着网络层数的增加梯度跟新会朝着指数衰减的方向前进, 这就是梯度消失, 如图:

我们可以看出, 随着时间的增加, 深层的网络对浅层的感知变得越来越微弱, 梯度接近于0.
梯度爆炸问题 (Exploding gradient problem). 如果导数大于 1, 随着网络层数的增加梯度跟新会朝着指数增加的方向前进, 这就是梯度爆炸. 当 RNN 网络导数大于 1 时就会出现时序依赖, 从而造成梯度爆炸.
LSTM
LSTM (Long Short Term Memory), 即长短期记忆模型. LSTM 是一种特殊的 RNN 模型, 解决了长序列训练过程中的梯度消失和梯度爆炸的问题. 相较于普通 RNN, LSTM 能够在更长的序列中有更好的表现. 相比 RNN 只有一个传递状态 ht, LSTM 有两个传递状态: ct (cell state) 和 ht (hidden state).
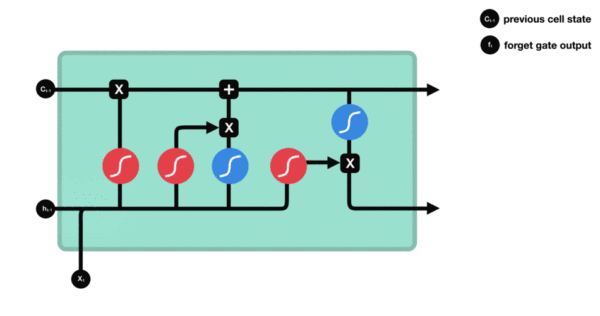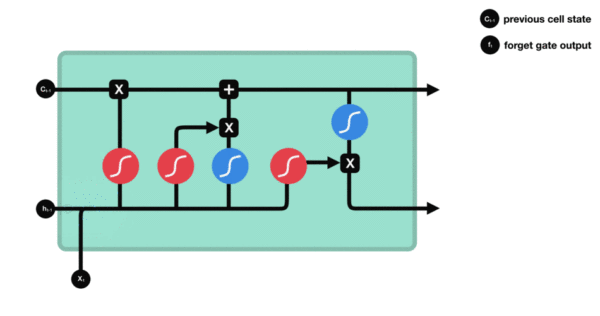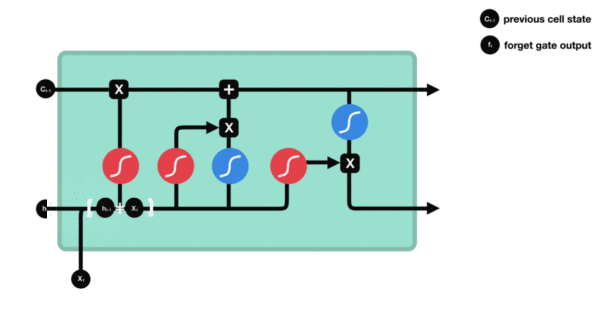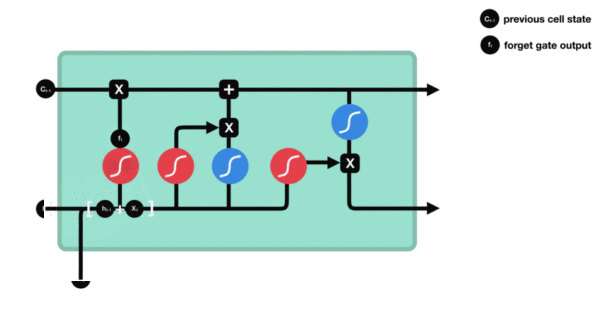
LSTM 增加了输入门, 输出门, 遗忘门 三个控制单元. LSTM 的 cell 会决定哪些信息被留下, 哪些信息被遗忘, 从而解决神经网络中长序列依赖的问题.
; GRU
GRU (Gate Recurrent Unit) 和 LSTM 类似, 但是更易于计算. GRU 由重置门, 更新门, 和输出门组成. 重置门和 LSTM 的遗忘文作用一样, 用于决定信息的去留. 同理, 更新门的作用类似于 LSTM 的输入门.

Seq2seq
Seq2seq 由 Encoder 和 Decoder 两个 RNN 组成. Encoder 将变长序列输出, 编码成 encoderstate 再由 Decoder 输出变长序列.
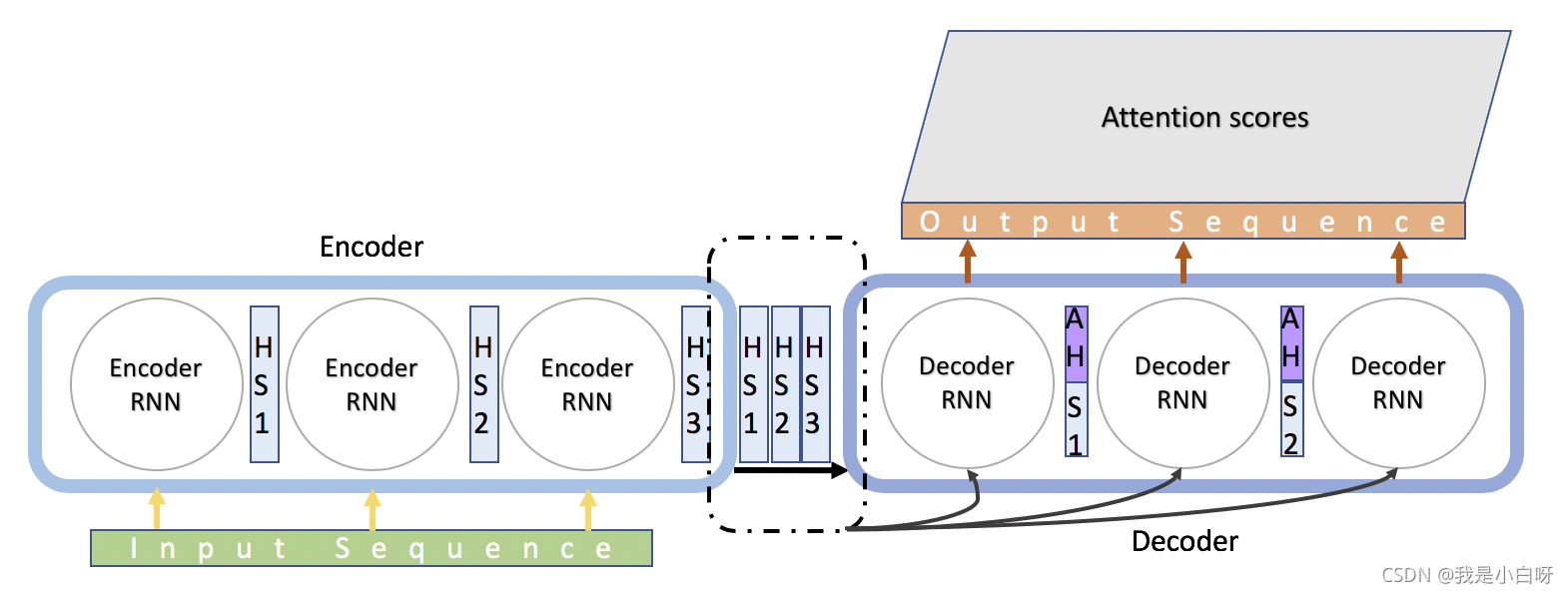
; Attention 模型
Attention 是一种用于提升 RNN 的 Encoder 和 Decoder 模型的效果的机制. 广泛应用于机器翻译, 语音识别, 图像标注等多个领域. 深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似. 核心目标也是从众多信息中选择出对当前任务目标更关键的信息.

Attention 实质上是一种 content-based addressing 的机制. 即从网络中某些状态集合中选取给定状态较为相似的状态, 进而做后续的信息抽取.

首先根据 Encoder 和 Decoder 的特征计算权值, 然后对 Encoder 的特征进行加权求和, 作为 Decoder 的输入. 其作用的将 Encoder 的特征以更好的方式呈献给 Decoder. (并不是所有的 context 都对下一个状态的生成产生影响, Attention 就是选择恰当的 context 用它生成下一个状态.
Teacher Forcing 机制
早起的 RNN 在训练过程中的预测能力非常弱, 如果一个 unit 预测错了, 后面的 unit 就很难再获取对的结果. 比如我们翻译一句话:
- Life is like a box of chocolates.You never know what you're going to get
- 人生就像一盒巧克力,你永远也不知道下一块是什么味道
如果我们把 life 翻译成 "西伯利亚", 那么后面再翻译对的可能性就几乎为 0.

Teacher Forcing 是一种网络训练的方法, 使用上一个 label 作为下一个 state 的输入. 还是用上面的例子说明: 当使用 Teacher Forcing 机制的时候, 即时我们把 life 翻译成 "西伯利亚", 下一个 Decoder 的输入我们会使用上一个的 label 作为 state, 即 "人生", 而不是 "西伯利亚". 这样就大大提高了 RNN 网络的预测能力.
Original: https://blog.csdn.net/weixin_46274168/article/details/121437315
Author: 我是小白呀
Title: 【语音识别】玩转语音识别 2 知识补充
相关阅读3
Title: 风控必学|肘部法与客户分群——客户画像中的聚类与特征画像分析
客户聚类分析,在信贷圈子里,是一种很常见的数据挖掘场景,对于从事金融数据分析岗位的我们,也是需要必备掌握能力之一。无论是策略分析岗,还是数据建模岗,或者是数据分析岗,客户样本的分群画像,在某些程度上来讲,是我们实际工作中比较基础的内容,但又是需要有业务经验支撑的综合能力体现。
客户分群,从原理上分析是比较简单的,也就是将一批样本用户根据特点进行分类,然后根据特征分布进行客户画像。这不仅有利于公司对自营产品流量的整体了解,而且为风控流程提供客户分层的数据参考,另外在客户管理方面可以实现精准营销,从这几个典型应用可以看出,客户分群的聚类分析,在实际业务中的贡献价值是非常大的。客户分群的实现,比较靠谱的方法是通过机器学习算法来训练模型,而不是简单地依靠经验来主观判断。大家也了解机器学习模型分为有监督模型和无监督模型,而这两类算法也都可以实现客户分群的过程。但是,对于我们比较熟悉的信贷场景,比如贷前或贷中环节,在客户的贷后表现数据还未产生时,我们只能根据所谓的X特征来进行客户分群,这时我们经常采用的是无监督算法中的聚类模型,而聚类模型最常用的是K-means聚类。
当我们理解了前边介绍的业务背景后,这里有一个重要的问题是我们特别关注的,也是我们本文想和大家分享的主题要点,就是客户聚类的最终数量多少才算合适。虽然有些时候,我们对客户分群的数量是按照公司老板指示,或者相关部门的任务要求定下来的,但是在多数场景下,我们是没有明确目标来直接划分客群的,这时候我们就需要通过对样本数据进行客观分析来得到具体分类的数量,而且是有实际解释意义的值。我们就以K-means(K均值)聚类来实现客户分群,比较形象的说,是如何确定这个K值,接下来我们就结合实际案例来梳理下K值的分析过程,并介绍下客户群体划分后的特征画像。
1、案例样本数据
我们先来了解下样本数据的概况,本案例数据共有3000条样本,5个特征字段,包含1个id主键,以及4个X变量,分别为年龄(age)、性别(gender)、学历程度(education)、住房类型(house),取前10条样本数据如图1所示。
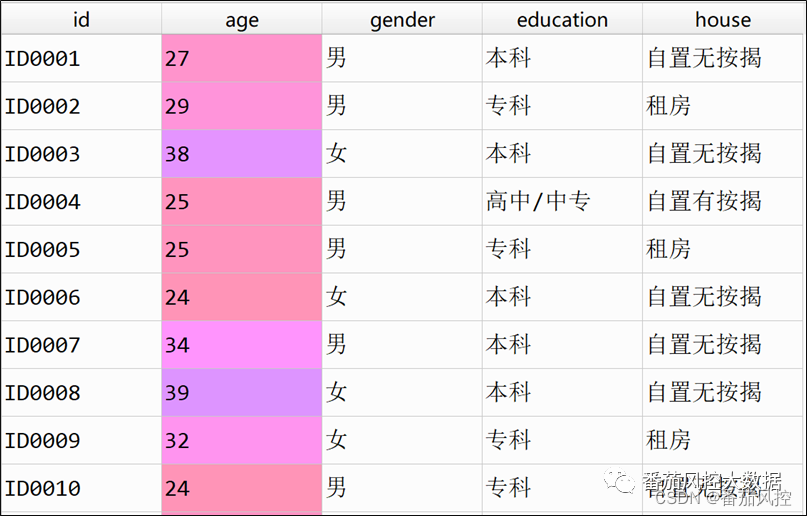
图1 样本数据
由上图数据样例可知,样本是没有Y字段的,我们需要根据特征age、gender、education、house的分布特点来进行客户分群,我们通过代码来输出各字段的取值分布,具体如图2所示。
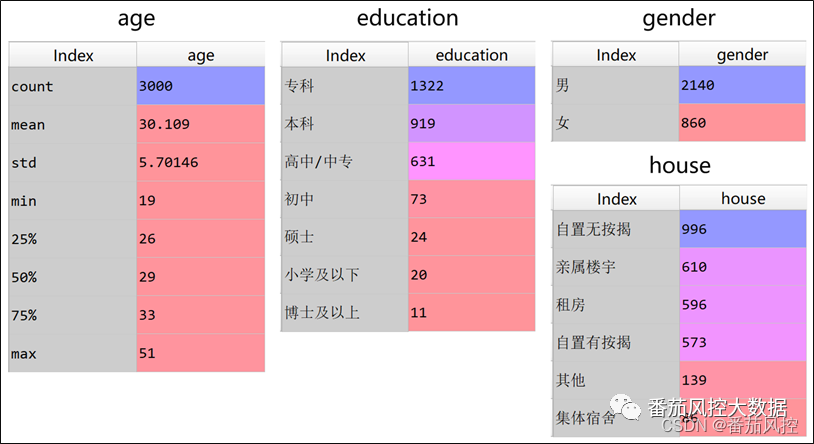
图2 特征分布
2、特征数据处理
在采用K-means聚类算法分析之前,我们需要注意的是,K-means的原理逻辑是以距离作为样本间相似度的度量标准,将距离相近的样本分配到同一个类别。样本间距离的计算方式可以是欧式距离、曼哈顿距离、余弦相似度等,K-means算法通常采用欧氏距离来度量各样本间的距离,而得到距离的前提条件是特征类型必须是数值型。因此,本案例样本中的变量gender、education、house,需要进行特征转换,将字符型转为数值型。由于原特征education、house属于有序分类型变量,这里根据实际业务的信息比较含义,可以采用特征标签编码方式进行数据处理,具体逻辑如图3所示。


图3 特征编码
当特征完成编码后,针对数据处理环节,大家还需要注意另外一个细节,如果各个特征的取值范围差异性较大,会对样本间的距离结果造成很大的干扰。例如,本案例样本的变量age的取值范围为1951,而变量house的取值范围为14,那么在欧式距离的计算过程中,age的数值权重明显高于house,这显然不符合实际业务理解。因此,为了避免这种情况的出现,我们往往在聚类模型训练之前,将所有参与聚类的特征进行标准化处理。当然,变量标准化的实现方法,如min-max或z-score都是可以的。
以上关于特征编码与特征标准化的数据处理过程,针对本样本数据案例,具体的实现代码如图4所示,其中特征标准化处理采用了min-max算法。

图4 特征处理
3、聚类数量确定
当样本数据经过前边处理之后,下面便是K-means聚类的一个重点,那就是聚类数量K如何来确定。我们这里排除从实际业务需求直接指定的分类数量,而是根据样本分布来寻找合适的K值。在实际业务场景中,我们往往采用的是"肘部法"可视化分析,下面先简单描述下原理逻辑。
肘部法的核心思想是随着聚类数K的增大,样本数据会划分的更为精细准确,促使每个分类簇的聚合程度提高,从而导致聚类效果指标SSE(误差平方和)逐渐变小。当K值小于最佳聚类数量时,K值的增大会较大幅度增加每个分类簇的聚合程度,这样SSE的下降幅度也会很大;当K值达到最佳聚类数量时,此时再增加K值所得到的聚合程度,SSE的下降幅度会骤减,而且随着K值的持续增大而逐渐趋于平缓。这个过程反映在K值与指标SSE的关系图上是一个类似"手肘"的形状,而这个肘部对应的K值就是样本数据的最佳聚类数量。
理解了"肘部法"的原理逻辑后,我们来通过代码来实现这个过程,具体代码如图5所示,生成的可视化结果如图6所示,横纵坐标分别为K值与SSE误差平方和。
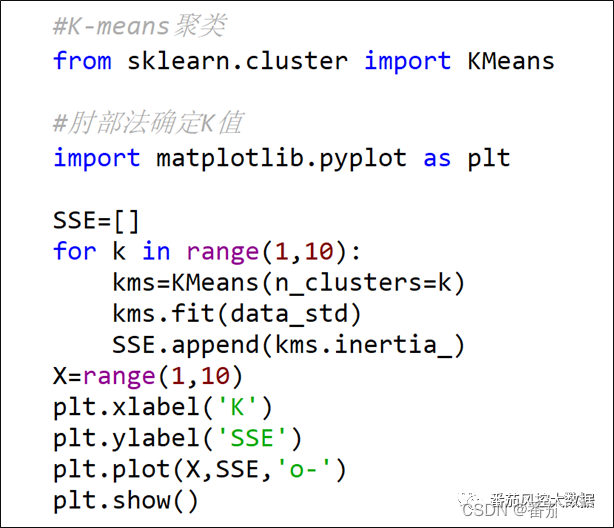
图5 肘部法确定K值
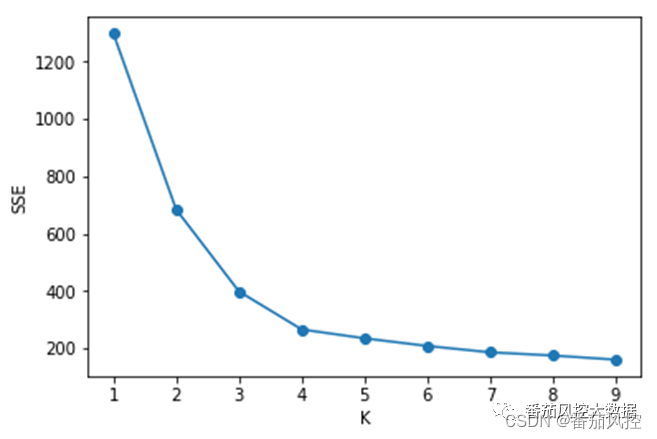
图6 K与SSE关系图
从图5可知,K-means聚类的K值与指标SSE的数据分布关系,非常类似一个"手肘"的形状,且肘部对应的拐点很明显是K=4,说明本案例样本数据如果采用K-means进行聚类,分为4类较为合适。下面我们通过K-mean算法指定4类进行模型训练,并将各聚类簇的标签和种子中心输出,具体代码如图6所示。

图7 K-means聚类模型训练
4、聚类客户画像
将样本数据分为4个合适的类别后,接下来我们需要对每个客群的数据分布进行分析,主要包括以下两个方面:
1、频数分布:各簇的样本量是否合适,如果各簇数量差异过大,显然在实际场景中没有太多的应用价值;
2、均值分布:各簇的数据均值可以直接体现样本的特点,便于针对客户群体进行画像描述分析,此外最大值最小值仅作为参考。
通过图8代码定义输出聚类各簇的频数、占比,以及各特征的样本均值。
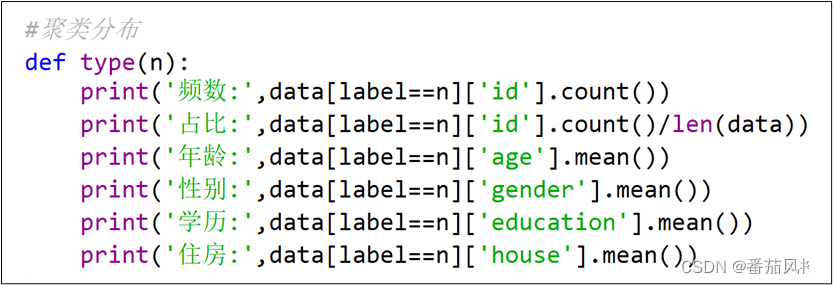
图8 聚类各簇分布实现
依次调用type( )函数可以输出聚类各簇的特征分布结果,具体如图9所示。

图9 各簇样本特征分布
根据以上结果可以看出,各客户群体的频数分布是比较合理的,均具有一定业务代表性。下面我们结合实际场景情况,以及图3的特征编码字典,来对各个客群作个简单画像分析:
客群1:年龄平均约为29岁,全部男性,学历程度平均为专科,住房类型多数亲属楼宇或集体宿舍等;
客群2:年龄平均约为28岁,全部女性,学历程度平均为专科,住房类型多数亲属楼宇或集体宿舍等;
客群3:年龄平均约为32岁,全部女性,学历程度平均为专科,住房类型多数为自置无按揭;
客群4:年龄平均约为32岁,全部男性,学历程度平均为专科,住房类型多数为自置无按揭。
从客群画像描述可知,各客群的学历程度基本相当;从年龄或住房类型角度看,客群1、2与客群3、4分别可以归为一类;从性别角度看,客群1、4与客群2、3分别可以归为一类。在聚类分析的4个变量中,house(住房类型)是可以最直接体现出客户资产能力的特征,因此客群3、4具有很高的营销价值。此外,从age(年龄)分布也可以看出,这类客群的稳定性相比客群1、2要表现较好。
以上内容便是围绕客户分群的实际业务场景,结合具体的案例分析,给大家介绍了客户聚类分析的业务背景、K-means聚类的K值确定、数据处理的特征编码与标准化,以及聚类结果的客户画像分析。为了便于大家进一步理解与掌握本文关于客户聚类的分析过程,我们准备了与以上案例内容同步的样本数据与Python代码,供各位童鞋实操练习,详情请大家移步至知识星球查看相关内容。

...
~原创文章
Original: https://blog.csdn.net/weixin_45545159/article/details/125152102
Author: 番茄风控
Title: 风控必学|肘部法与客户分群——客户画像中的聚类与特征画像分析