
SuperPoint: Self-Supervised Interest Point Detection and Description
前言
SuperPoint是一种基于深度学习的自监督特征点检测算法,关于这个论文的详细内容不在此篇文章解释,本文只介绍如何使用该算法进行特征点检测。
paper原文:SuperPoint: Self-Supervised Interest Point Detection and Description
官方代码:GitHub/magicleap/SuperPointPretrainedNetwork
因为原文作者明确表示不发布训练&评估代码,本篇文章使用的代码是非官方的训练代码,链接:GitHub/rpautrat/SuperPoint
在此之前已经有人写过SuperPoint训练的过程,但用的是官方训练的COCO数据集,我将在此基础上更详细的介绍并补充如何替换训练数据集及使用评估代码。
准备工作
运行环境:python==3.6.1。
requirements.txt:
tensorflow-gpu==1.12
numpy
scipy
opencv-python==3.4.2.16
opencv-contrib-python==3.4.2.16
tqdm
pyyaml
flake8
jupyter
make install
我用的是Debian GNU系统,其他Linux发行版也一样。
关于dataset读取路径和输出路径都在 superpoint/settings.py 中,分别为DATA_PATH和EXPER_PATH。
第一步:创建Synthetic Shapes Dataset并训练MagicPoint特征检测器
Synthetic Shapes Dataset是合成形状数据集,该数据集有9种不同的形状(包括椭圆和高斯噪声,作为负样本),并有.npy文件记录特征点的坐标位置作为label进行训练,如下图所示。

python experiment.py train configs/magic-point_shapes.yaml magic-point_synth
其中magic-point_synth是实验名称,可以更改为任何名称。训练可以在任何时候使用Ctrl+C中断,权重将保存在 EXPER_PATH/magic-point_synth/ 中,里面也包括了Tensorboard的记录文件。当第一次训练时,将生成合成形状数据集,数据集保存在 superpoint/datasets/synthetic_shapes_v6 文件夹中。
magic-point_shapes.yaml文件里面有可修改的各种数据及训练参数。
第二步:MagicPoint检测器自标注数据集
得到训练后的MagicPoint检测器后,我们需要使用它对真实图像数据集进行标注,获得伪真实(pseudo-ground truth)的data及label,其中进行了一个图像处理操作叫做 Homographic Adaptation,它也是SuperPoint这么好用的一个创新点。当然,你也可以在yaml文件中设置选择开启或关闭该操作。
python export_detections.py configs/magic-point_coco_export.yaml magic-point_synth --pred_only --batch_size=5 --export_name=magic-point_coco-export1

输出为一堆.npy文件,记录了输入图像的特征点伪真实标签,输出路径在 EXPER_PATH/outputs/magic-point_coco-export1/ 。在npy文件中特征点坐标保存在 属性f.points 。同样,在 magic-point_coco_export.yaml 文件中可以进行各种调参。
查看特征点标签(label)的坐标:
import numpy as np
point_path = r'hjOD70.npz'
npz = np.load(point_path)
point = npz.f.points.tolist()
print(npz.f.points)
这一步我们可以选择不用COCO数据集,替换为自己的数据集,但要注意替换的数据集图像尺寸必须要能被8整除。
1.修改训练图像尺寸
paper和code中使用COCO数据集图像尺寸为240×320,如果想要修改尺寸需要在 superpoint/datasets/coco.py 代码中default_config ={''preprocessing ': ['resize' : [240, 320] ] }修改成自己数据集图像的尺寸。
coco.py:
default_config = {
'labels': None,
'cache_in_memory': False,
'validation_size': 100,
'truncate': None,
'preprocessing': {
'resize': [800, 400]
},
......
2.修改读取图像路径
在 coco.py 文件中修改base_path,DATA_PATH在 settings.py 中修改。
coco.py:
def _init_dataset(self, **config):
base_path = Path(DATA_PATH, '自己的数据集地址')
......
3.(可选)修改数据集名称
如果你的数据集不想叫COCO...可以修改 magic-point_coco_export.yaml 文件data的name属性。
magic-point_coco_export.yaml:
data:
name: 'coco' <-----修改这里
cache_in_memory: false
validation_size: 100
但一定要在 superpoint/datasets/ 文件夹下复制 coco.py 并重命名为自己的 数据集名称.py ,且修改其中的class类名为自己的数据集名称。
下图是用MagicPoint检测器检测到的特征点。

第三步:再次训练MagicPoint检测器
在第一步训练出来的MagicPoint检测器虽然可以检测出一些特征点,可因为是使用合成形状数据集训练出来的模型,检测性能还有些不足,所以进行第二步自标注数据,再用标记好的真实图像训练,得到的强化版的检测器。
python experiment.py train configs/magic-point_coco_train.yaml magic-point_coco
在此步骤依旧需要修改labels读取路径,将第二步得到的npz文件夹路径替换到labels路径中,代码作者也在 magic-point_coco_train.yaml 文件中做了提醒。
magic-point_coco_train.yaml:
data:
name: 'coco'
labels: outputs/mp_synth-v10_ha2-100
cache_in_memory: false
validation_size: 192

训练结束后会得到最终的MagicPoint特征检测器。
第四步:(可选)使用MagicPoint进行特征检测
paper中使用Hpatches数据集进行性能评估验证,HPatches: Homography-patches dataset.该数据集在ECCV2016上提出,被用作局部描述符评估挑战的基础,每个文件夹下包含5张.ppm格式的图像与其单应矩阵H,每张图像相较于原图像都做了不同的变换(视角或光照)。评估检测器的性能:
python export_detections_repeatability.py configs/magic-point_repeatability.yaml magic-point_coco --export_name=magic-point_hpatches-repeatability-v
结果保存在 EXPER_DIR/outputs/magic-point_hpatches-repeatability-v/ ,我们还可以修改 magic-point_repeatability.yaml 中的相关参数 :
data:
name: 'patches_dataset'
dataset: 'coco'
alteration: 'all'
preprocessing:
resize: [384, 384]
如果我们的数据集仅有图像,不是Hpatches dataset格式(有变化后的图像和可验证单应矩阵H),作者还为我们留了生成该格式的代码 generate_coco_patches.py ,修改代码的43和45行的base_path、output_dir,运行后就可以得到Hpatches dataset格式的图像数据。

每个文件夹都包含了原图像和变换后的图像。

评估后的结果是一堆.npz格式文件,里面的f属性包含以下5个内容,分别是单应矩阵、原图像、原图像每个点的特征置信度、变换图像、变换图像每个点的特征置信度。这些是paper中repeatability评估指标的所需数据,更多解释在paper中寻找...

第五步:训练SuperPoint检测器
将第二步标注好的label用来训练SuperPoint模型,首先修改 superpoint_coco.yaml 中data/label的路径:
data:
name: 'coco'
cache_in_memory: false
validation_size: 96
labels: outputs/mp_synth-v11_export_ha2
修改完成后键入指令:
python experiment.py train configs/superpoint_coco.yaml superpoint_coco

等待训练完成即可得到SuperPoint特征检测模型。
注意此环节可能报错:段错误 或 Segmentation fault,是因为爆显存了...本人使用tesla P100 16G显卡,训练384×384尺寸 共10000张图像,在 superpoint_coco.yaml 配置文件中batch size设置1(初始为2),可解决此问题。
未完待续...
Original: https://blog.csdn.net/weixin_43380735/article/details/121469030
Author: 不入流儿
Title: SuperPoint特征检测算法Train&Evaluate教程
相关阅读1
Title: 六、NLP聊天机器人原理(seq2seq模型)
一、seq2seq模型
1.概念
- seq2seq是一个Encoder-Decoder结构的网络,它的输入是一个序列,输出也是一个序列。
- Encoder中将一个可变长度的信号序列变为固定长度的向量表达,Decoder将这个固定长度的向量变成可变长度的目标的信号序列。
- 这个结构最重要的地方在于输入序列和输出序列的长度是可变的。
- 可以用于翻译,聊天机器人、句法分析、文本摘要等。
2.encoder过程
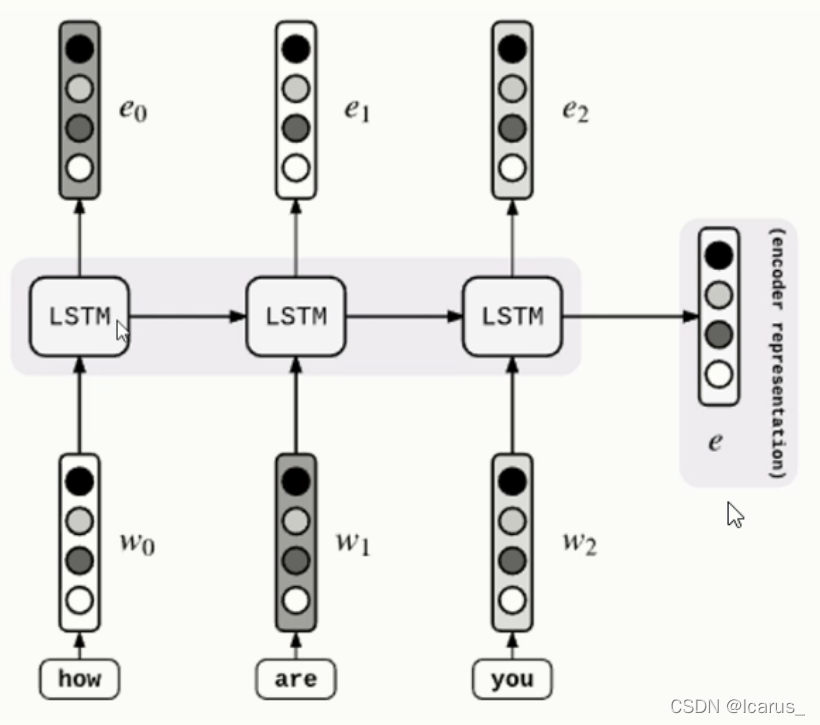
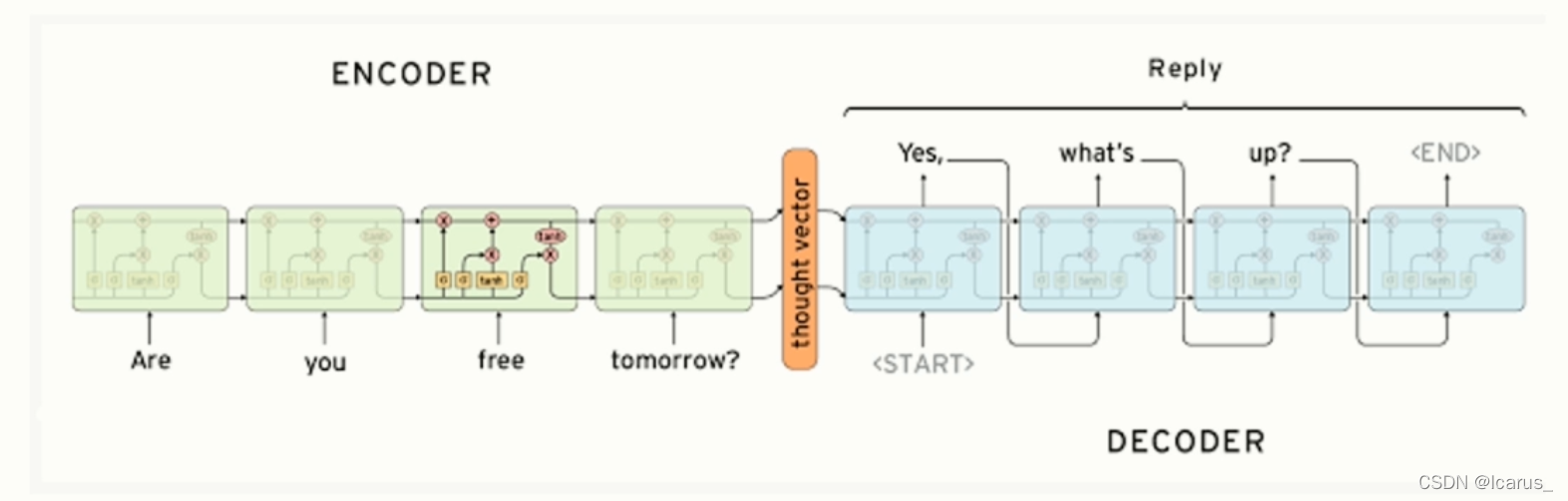
encoder过程实际上就是编码的过程。看这张图,输入的how are you 三个英文单词,通过这个三个权重输入到LSTM。LSTM就是扮演一个在传统神经网络中隐藏层的部分,处理完了之后再输出,但是输出的是e。在从左到右翻译的过程中,第一个是上一个时间的输出,当前的输入,LSTM这里面还有上一个时刻的状态位,也是输入进去了,经过他的翻译,最后输出到这里。这个encoder过程,实际上是一个编码的过程,就是将一个文本序列进行一个编码。
(1)取得输入的文本,进行embedding,生成向量
(2)传入到LSTM中进行训练
(3)记录状态,并输出当前cell的结果
(4)依次循环,得到最终结果
3.decoder过程
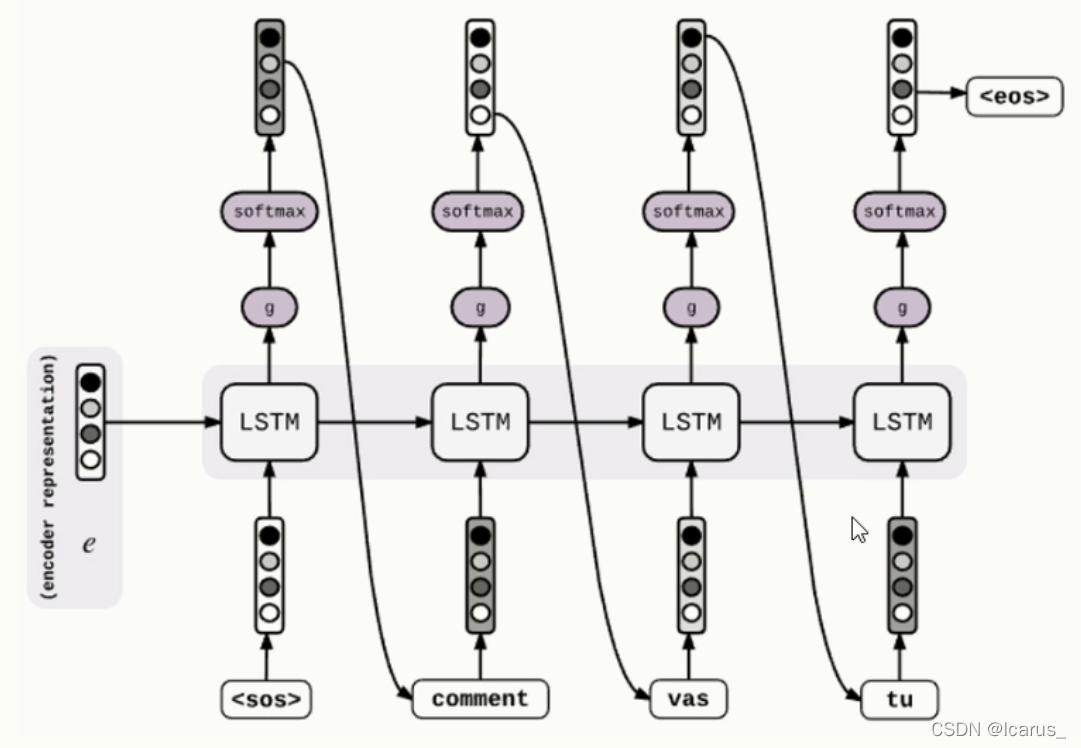
(1)在encoder最后一个时间步长的隐藏层之后输入到decoder的第一个cell里
(2)通过激活函数softmax得到候选的文本
(3)筛选出可能性最大的文本作为下一个时间步长的输入
(4)依次循环,得到目标
4.seq2seq模型
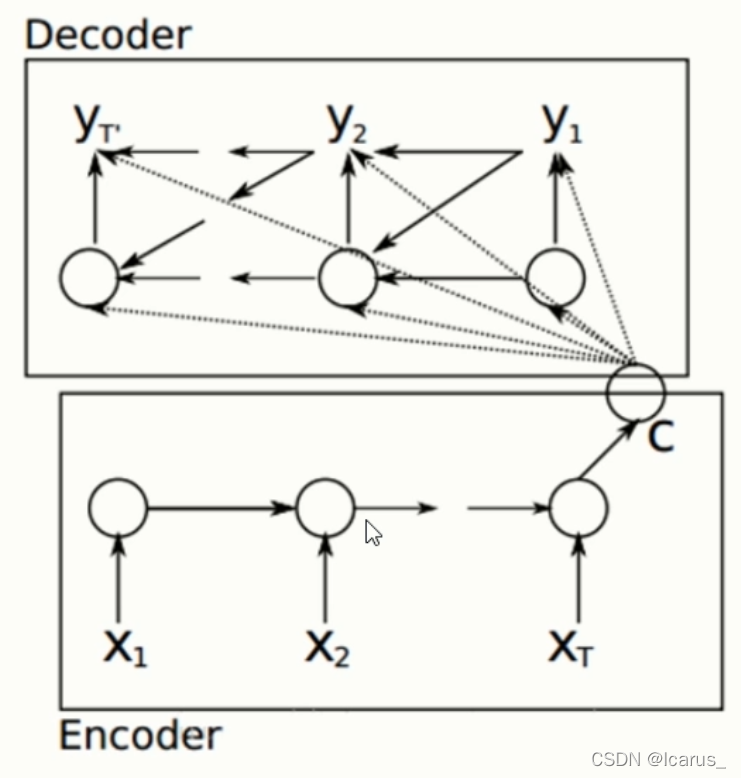
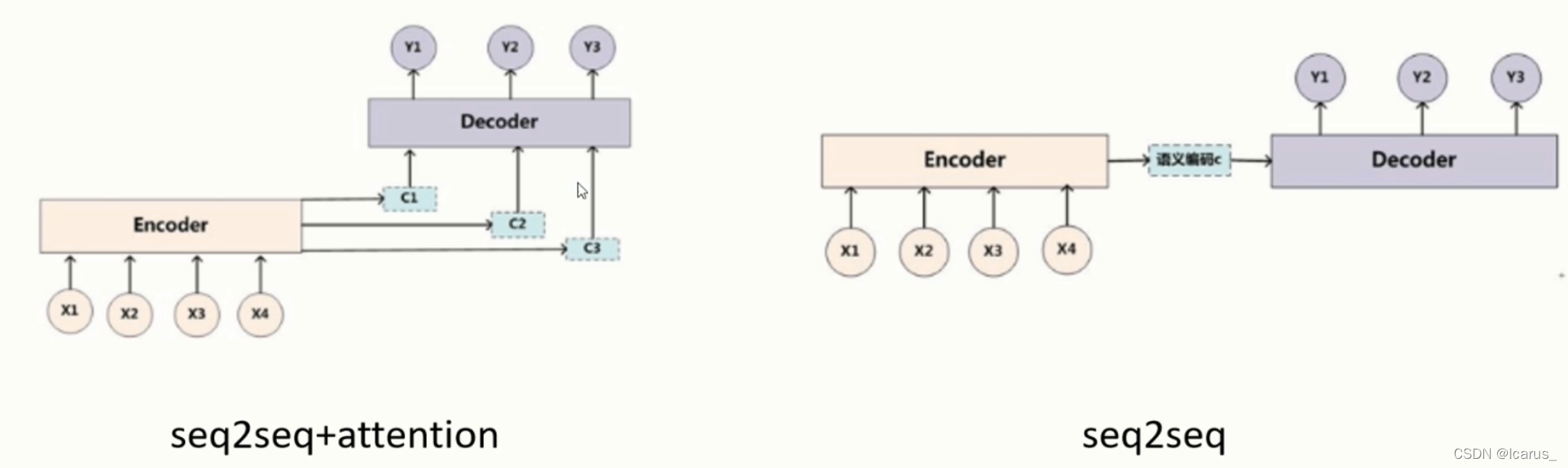
这个图就是编码器和解码器的结构图。编码器和解码器分别对应着输入序列和输出序列的两个循环神经网络,是两个RNN。一般来讲,我们用seq2seq模型的时候,通常在输出序列和输入序列的头部和尾部一般会加一个go和一个eos,来表示开始和结束,但这个表达只是一个文本形式,或者说是在一般做模型形式上的一个表达。这个编码器的作用是什么,就是把一个不定长度输入序列转化成一个定量的背景向量。这个背景向量就包含了输入序列的信息,我们常用的编码器,就可以是一个循环神针网络,循环神针网络在做这个文本处理或者nlp领域中是一个非常常用的编码器结构。我们看这里面,假设这个编码器的输入就是这个x1,x2...xt,它会经过一定的变换之后变换成一个隐藏的变量,在经过这一点c进入c然后解码器通过这个c来获取编码器的内容,也就是x1,x2...xt,这些内容编码之后,会放到c里面。解码器从c里面去读所要的这个信息,再去获取编码器的内容,然后变成y1,y2...yt。那么在seq2seq模型中,解码器一般是通过c这个向量拿到编码器的信息,然后再通过RNN进行传递,然后再输出。
二、注意力机制

这张图是这个这张图是这个seq2seq的一个翻译的例子,a,b,c是输入,w,x,y,z是输出,那么在这个模型中,使用了seq2seq的方法,通过预测字符序列,最后得到了这个结果。实际上,每一个里面我们可以看做是一个RNN,或者说一个LSTM。那么,在LSTM中,每一个单元获取到的是上一个单元的输出以及输入,以及加上上一个单元传过来的状态的信息。经过一层一层的预测,最后得到了一个w,x,y,z的结果。这个结构就是利用这种方式进行这个编码和解码的。刚刚我说的是预测,那换一种说法来说,就是把他作为一个编码器进行编码,还把后面这一块作为一个解码器进行解码。
这个sseq2seq模型还有一个缺点。我们还是来看这张图,比如说我们要去预测w,w他只能去拿上一个点的输出,以及当前点的输入,进行预测,那么这就会产生一个问题,如果说我们需要w,可能需要a点的信息或者b点的信息,那么他是拿不到的,那为了弥补这个缺点,可以引入一个注意力模型
(1)注意力机制是在序列到序列模型中用于注意编码器状态的最常用方法,它同时还可用于回顾序列模型的过去状态。
(2)注意力机制不仅能用来处理编码器或前面的隐藏层,它同样还能用来获得其他特征的分布,例如阅读理解任务中作为文本的词向量。
2.为什么需要注意力机制
(1)减小处理高维输入数据的计算负担,通过结构化的选取输入的子集,降低数据维度。
(2)让任务处理系统更专注于找到输入数据中显著的与当前输出相关的有用信息,从而提高输出的质量。
(3)Attention模型的最终目的是帮助类似编解码器这样的框架,更好的学到多种内容模态之间的相互关系,从而更好的表示这些信息,客服其无法解释从而很难设计的缺陷。
三、seq2seq与注意力机制
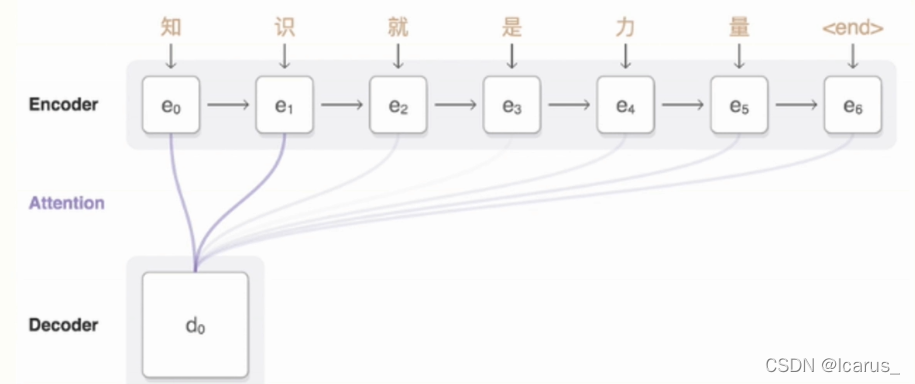
首先第一步还是Encoder进行编码,把 知识就是力量一直从e0到6然后最后加一个结束补位。补到这个6的编码,编码之后我们用注意力机制进行翻译,我们可以看到,在这个翻译的过程中,我们不仅把这个知识拿过来,还会把后面其他的相关的一些信息都放进来。
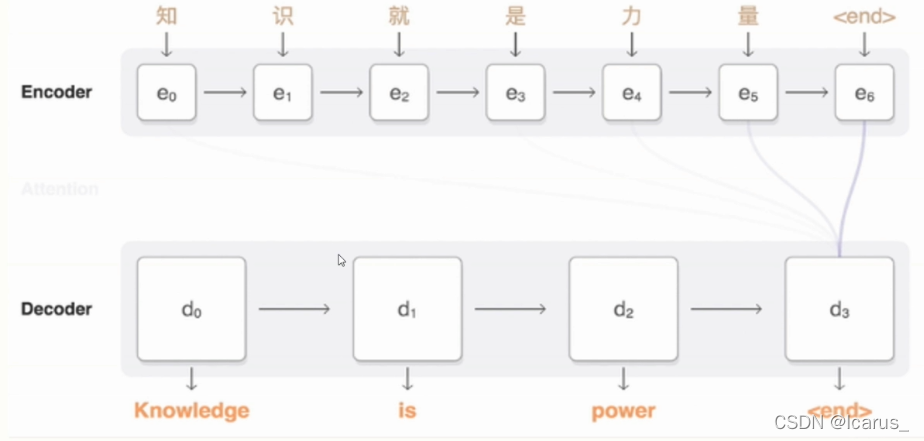
用注意力机制的话,他会紧密的去联系前后相关的信息。通过这个前后相关的信息,再来进行相关的操作,得到最后想要的这么一个结果。
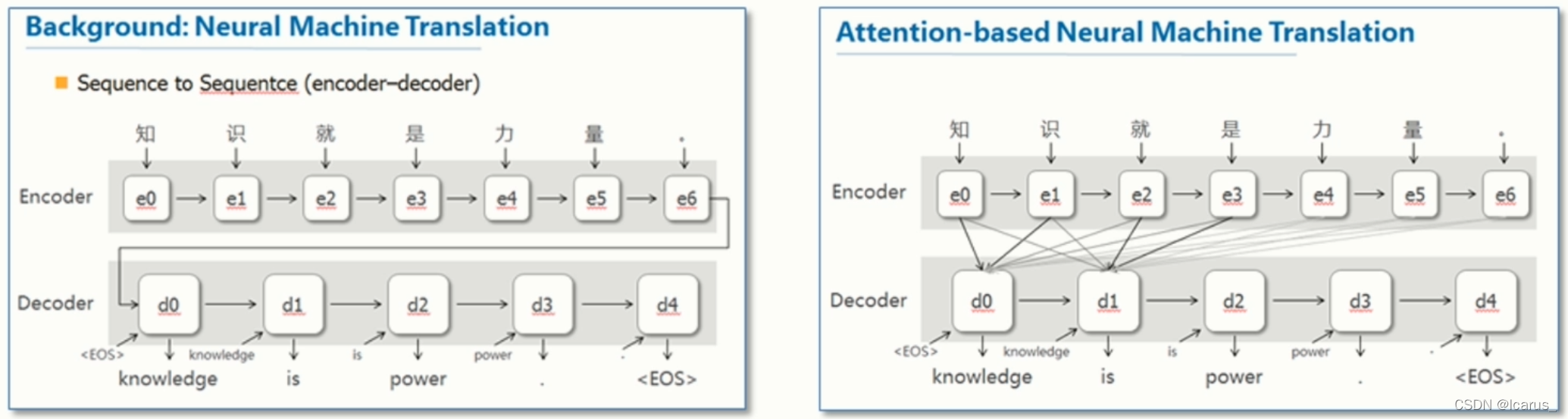
来看这两个图,第一个图是使用seq2seq模型来进行操作。第二个是使用注意力机制进行操作,这两个图的区别在于如果用普通的seq2seq模型,他是先把所有的词加到encoder里面之后。在统一的进行decoder,那这样的话一个缺点就是只能通过这种序列化的形式去找前一个,或者说当前和前一个,他们两个相关的一个内容进行一个翻译。那么,针对于较长的文本的话,翻译起来肯定是不是特别准的。肯定会有一定的误差,那么我们使用这个注意力机制呢?它的优点就在于,每一个翻译,他都会去寻找这个前后各种各样的这个文本信息,他都会拿进来。也是说,当对一个文本的一块进行做翻译的时候,会把所有的注意力都集中在这一个单元里,从而使翻译的准确率更高,实际上,我们使用这个注意力机制,或者说attation机制,它的优点也就在于此
接下来我们看这两张图,这两张图也是一个是使用这个注意力机制,一个是没有使用注意力机制,在做这个编解码的过程中的一些差别。我们可以看到,如果使用注意力机制,在每一个序列中,它都有一个相应的这个状态位。我们根据这个相应的状态位可以把注意力集中到一起,进行翻译,编码之后,得到相应的结果。如果说没有使用这种注意力机制,他就会把所有的这个输入序列前的输入进来,之后最后再统一再做这个decoder。这样的话,那就会使得我们最后的结果准确度没有这么高。
四、聊天机器人根据对话的产生方式
1.基于检索的模型
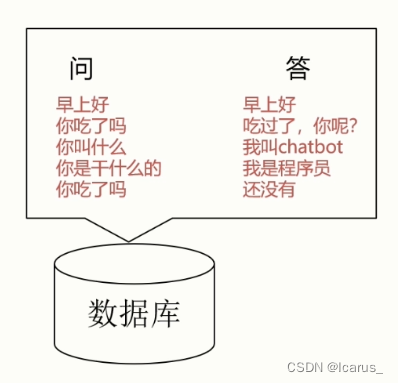
- 有明确的问答对数据库
- 使用语句匹配的形式查找答案
- 答案相对固定,且很少出现语法错误
- 不会出现新的语句
2.生成式模型
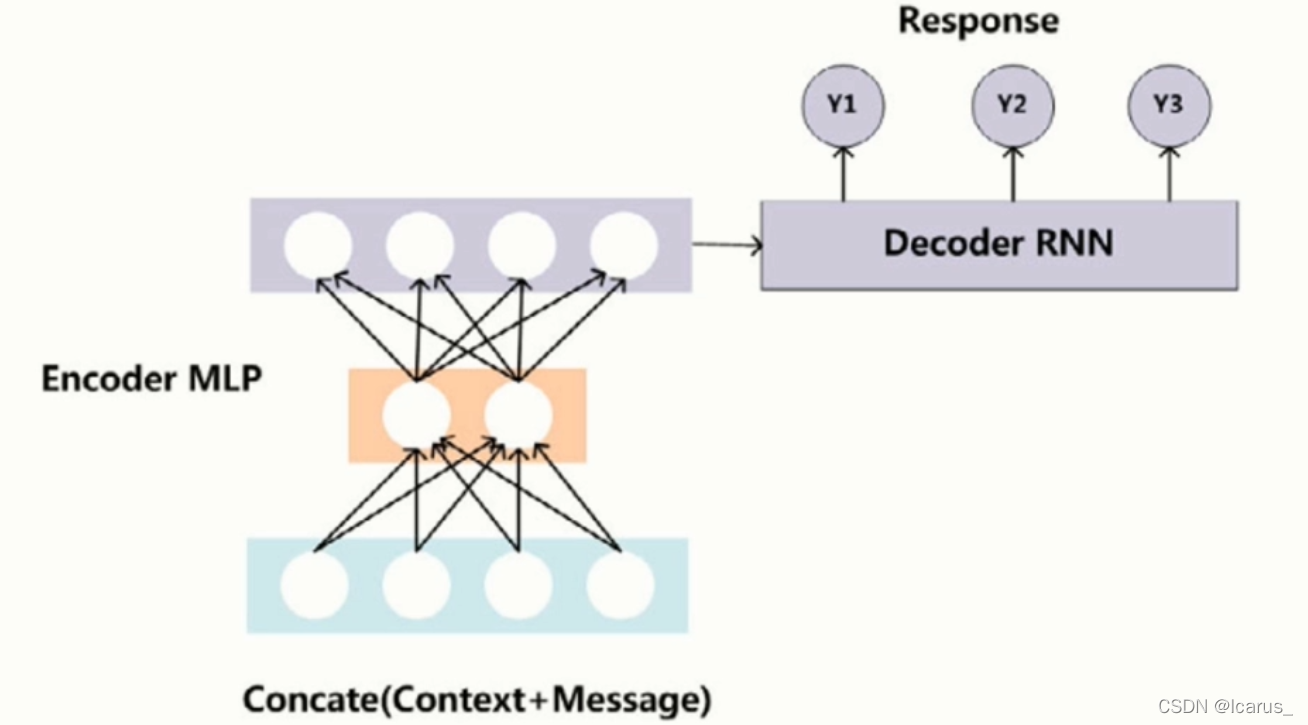
- 不依赖预先设定的问答库;
- 通常基于机器翻译技术
- 需要大量的语料进行训练
- Encoder-Decoder模式;
- 机器翻译;
- 输入的是问题,翻译的是回答;
这个图也是一个基于生制模型的一个案例。这就是一个对话的案例,他的输入是 不好意思,刚有事好,回答是, 亲。没事的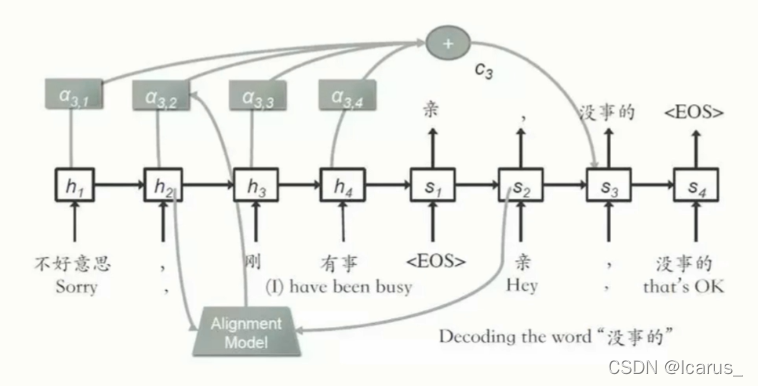
首先,他把这个 。不好意思,刚刚有事这几个字输入进来,然后当做输出的时候,是利用注意力模型,我可以看到。他把之前的一些的信息都收集过来。也就说在做这个 亲这个词的时候,就是用到了之前的这些信息, 没事的也是用到了之前的这些信息,通过这个信息的一个处理,或者用seq2seq加上attention机制的处理。最后告诉你, 没事的。这个实际上也是用这个生成式模型来做的。
但是刚刚也说了基于生成式模型,他有一个最大的缺点是目前大家训练的要求非常高,对数据的要求也高,对这个训练的这个硬件或者对训练的轮次时间。要求也高,而且呢,目前来讲这个效果还并不是特别好。那如果使用传统的检索模型也有一个缺点,就是说,只能在特定的这个数据集中进行去查找。我不能告诉跳出我们这个特定的问答句之外,那么这也是一个麻烦的事。
3.混合模式
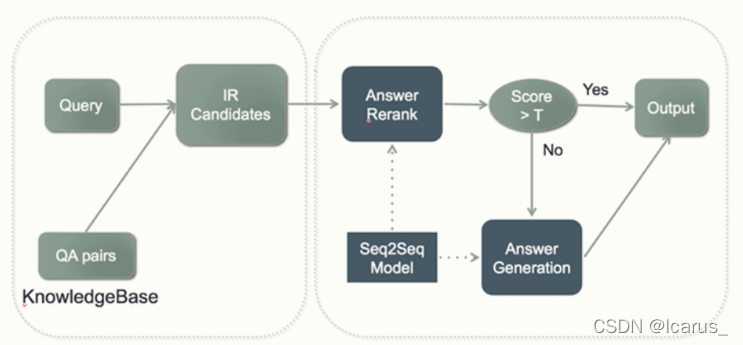
- 兼具检索模式和生成模式;
- 目前最常用的解决方案
- 检索模式产生候选数据集
- 生成模式产生最终答案
虽然这这个图中左面这一个部分,我们实验就是用了这个检索模式。而右面这个部分,那实际上就是用了一个生成模式,我们把它两个结合是如何来去做的呢。比如说让我们输入了一个句子,输入了一个早上好,或者说输入了一个你叫什么名字。他首先就会在这个知识库里,这个数据库里搜索有没有这个问题,如果有这个问题,搜索到了,他可能会有好多种答案。那他再把这个被选的可能性的这些答案全都列出来。全都列出来之后呢,就生成了一个候选的答案。然后,再送到这个生成模型中,那生成模型中,再根据这个候选的这个答案进行seq2seq模型的匹配和可能性的判断。经过这个匹配和这个判断,得出一个分数,如果说当这个分数大于一定的分值的话,大于0.5或者大于0.6。那么,我们认为这个回答可能是用户想要的,再把它进行输出。如果说不是的话,那么我们再去做回答的匹配。这就混合模式,它的优势在于前期的处理量可能会小得多,因为他使用这种检索模式,已经帮我们过滤出一大部分这种数据集了。而我们只需要通过这个生成模式在这个检索模式得到的这个数据及的结果的前提下。来找到一个最可能想要这种的一个答案,最后进行输出。所以说一般来讲,在做这种聊天机器人的时候,一般都是使用这种混合的模式进行那种输出和这种开发。
Original: https://blog.csdn.net/Icarus_/article/details/122118415
Author: Icarus_
Title: 六、NLP聊天机器人原理(seq2seq模型)
相关阅读2
Title: 浅谈深度学习的落地问题
前言
深度学习不不仅仅是理论创新,更重要的是应用于工程实际。
关于深度学习人工智能落地,已经有有很多的解决方案,不论是电脑端、手机端还是嵌入式端,将已经训练好的神经网络权重在各个平台跑起来,应用起来才是最实在的。
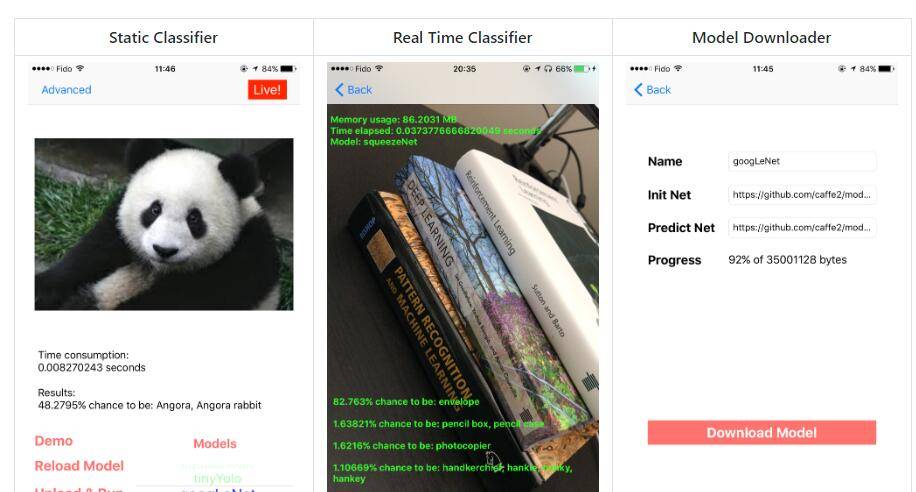
(caffe2-ios:https://github.com/KleinYuan/Caffe2-iOS)
这里简单谈谈就在2018年我们一般深度学习落地的近况。
Opencv
Opencv相比大家都比较了解,很流行很火的开源图像处理库,人工智能深度学习大伙,Opencv自然不能落下。早在去年Opencv开始加入Dnn模块,并且一直更新,但是有点需要注意, Opencv的深度学习模块是用来 inference推断而不是用来训练的。
为什么,因为现在已经存在很多优秀的深度学习框架了(TensorFlow、Pytorch),Opencv只需要管好可以读取训练好的权重模型进行推断就足够了。
(opencv-4.0.0已经发布)
自己试着跑了一下Opencv版的yolov3,利用yolo官方训练好的权重,读取权重并且利用Opencv的前向网络运行——速度还可以,在 i5-7400 CPU上推断用了 600+ms。

而我用2017版MacBookPro-2.3GHz版本的CPU(i5-7260u)则跑了 500ms。要知道这是完全版本的yolo-v3。如果进一步优化的话,在稍微好点的CPU端是可以跑到10fps!
另外在learnopencv相关文章中,也有详尽的评测:
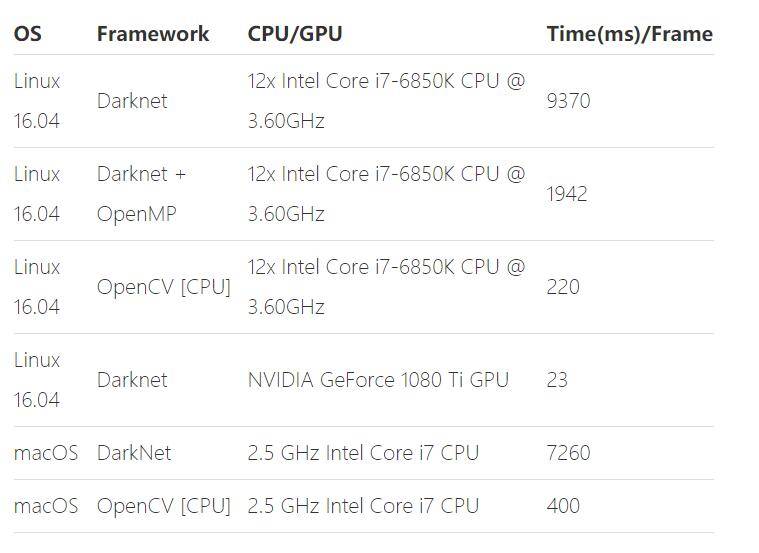
在6核12线程的CPU中可以跑到 200ms,速度相当快了,而且优化的空间还是有的。
为什么Opencv版的比Darknet版的速度快那么多,是因为Opencv的Cpu端的op编写过程中利用了CPU-MKL等很多优化库,针对英特尔有着很好的优化,充分利用了多线程的优势(多线程很重要,并行计算比串行计算快很多)。
当然这些优化还不是尽头,Opencv也在一直更新:
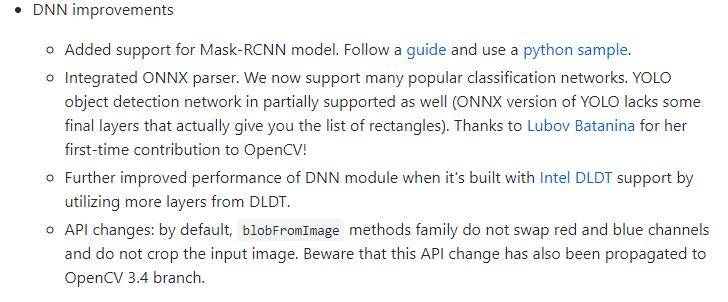
Opencv可以作为一个不错的落地的深度学习推断平台,只要安装好Opencv,就可以跑深度学习代码了,不需要安装其他深度学习框架了。但是有点需要注意,Opencv最好的实践是CPU端,GPU端Opencv对cuda的支持不是很好,Opencv只有利用OpenCL支持GPU,但速度没有cuda库快。
Pytorch-v1.0
Pytorch-v1.0的预览版已经发布了,正式版应该是在国庆节的第一天发布。

但我们在观察Pytorch的1.0文档中已经可以熟知,为什么Pytorch-v1.0称为从 研究到生产:

最重要的三点:
- 分布式应用
- ONNX的完全支持
- 利用C++部署生成环境
简单谈谈第三个要点,看了官方的说明文档,Pytorch也做了类似于Opencv工作,新的Pytorch支持直接应用Pytorch的C++部分从而编译可以单独执行Pytorch的推断部分而不需要安装所有Pytorch的组件。
近期会测试一下Pytorh和Opencv相比在Cpu端的速度,看看哪个对CPU端的优化更好些。
IOS、安卓
IOS最大的看点就是:Iphone最新出来的A12仿生处理器!

5W亿次每秒运行速度,跟专业显卡比起来可能不算什么,但是在手机端,意思可想而知。
只是不知道具体的速度如何,跑Yolo的话可不可以实时,期待之后的测评吧。

不过在HomeCourt这款APP中(中国目前还不可以使用),凭借A12强大的性能,貌似可以实时追踪人体骨架。还是很值得期待的。
至于安卓端,因为华为的芯片还没有具体公布,目前在移动端上的神经网络框架大部分是用CPU跑。
速度快慢就看在arm端的优化如何了。
比较流行的两个框架是ncnn(主要是cpu)和mace(也支持Gpu)。都在发展阶段,前者出世1年左右,后者出世半年不到。
也期待一下吧!
后记
深度学习落地,最繁琐的莫过于配置各种环境,希望之后各大深度学习框架能够在落地这块加大投入,实现快速方便地部署吧!
配一张Openpose的配置信息:

(OpenPose中对Windows的要求较为苛刻)
撩我吧
- 如果你与我志同道合于此,老潘很愿意与你交流;
- 如果你喜欢老潘的内容,欢迎关注和支持。
- 如果你喜欢我的文章,希望点赞👍 收藏 📁 评论 💬 三连一下~
想知道老潘是如何学习踩坑的,想与我交流问题~请关注公众号「oldpan博客」。
老潘也会整理一些自己的私藏,希望能帮助到大家,点击神秘传送门获取。
Original: https://www.cnblogs.com/bigoldpan/p/14424489.html
Author: 老潘的博客
Title: 浅谈深度学习的落地问题
相关阅读3
Title: DBSCAN算法(python代码实现)
DBSCAN
上次学了kmeans基于划分的方法,这次学一个基于密度的聚类算法:DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
一个例子
想象有一个很大的广场,上面种了很多的鲜花和绿草。快要到国庆节了,园丁要把上面的鲜花和绿草打造成四个字:欢度国庆。于是园丁开始动手,用绿草作为背景去填补空白的区域,用红色的鲜花摆成文字的形状,鲜花和绿草之间都要留下至少一米的空隙,让文字看起来更加醒目。
国庆节过后,园丁让他的大侄子把这些花和草收起来运回仓库,可是大侄子是红绿色盲,不能通过颜色来判断,这些绿草和鲜花的面积又非常大,没有办法画出一个区域来告知大侄子。这可怎么办呢?
想来想去,园丁一拍脑袋跟大侄子说:"你就从一个位置开始收,只要跟它连着的距离在一米以内的,你就摞在一起;如果是一米以外的,你就再重新放一堆。" 大侄子得令,开开心心地去收拾花盆了。最后呢,大侄子一共整理了三堆花盆:所有的绿草盆都摞在一起,"国" 字用的红花摞在一起,"庆" 字用的红花摞在了一起。这就是一个关于密度聚类的例子了。

; DBSCAN算法将数据点分为三类:
- 核心点:在半径Eps内含有不少于MinPts数目的点
- 界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内
- 噪音点:既不是核心点也不是边界点的点
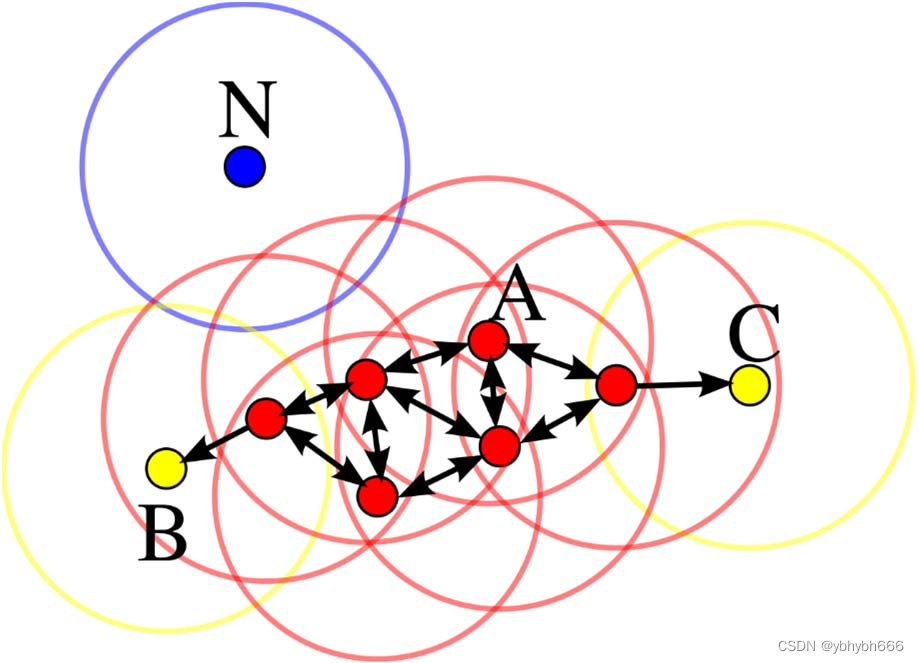
在这幅图里,MinPts = 4,点 A 和其他红色点是核心点,因为它们的 ε-邻域(图中红色
圆圈)里包含最少 4 个点(包括自己),由于它们之间相互相可达,它们形成了一个聚类。
点 B 和点 C 不是核心点,但它们可由 A 经其他核心点可达,所以也和A属于同一个聚类。点 N 是局外点,它既不是核心点,又不由其他点可达。
算法原理
上面的例子看起来比较简单,但是在算法的处理上我们首先有个问题要处理,那就是如何去衡量密度。在 DBSCAN 中,衡量密度主要使用两个指标,即半径和最少样本量。
对于一个已知的点,以它为中心,以给定的半径画一个圆,落在这个圆内的就是与当前点比较紧密的点;而如果在这个圆内的点达到一定的数量,即达到最少样本量,就可以认为这个区域是比较稠密的。
在算法的开始,要给出半径和最少样本量,然后对所有的数据进行初始化,如果一个样本符合在它的半径区域内存在大于最少样本量的样本,那么这个样本就被标记为核心对象。
这里我画了一幅图,假设我们的最小样本量为 6,那么这里面的 A、 B、 C 为三个核心对象。
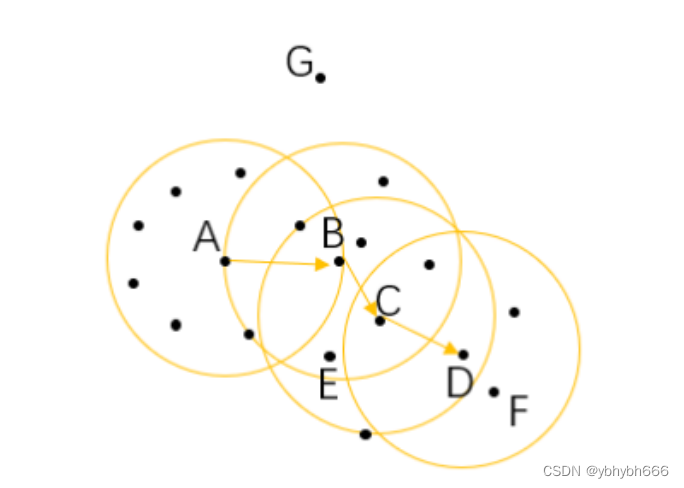
对于在整个样本空间中的样本,可以存在下面几种关系:
- 直接密度可达: 如果一个点在核心对象的半径区域内,那么这个点和核心对象称为直接密度可达,比如上图中的 A 和 B 、 B 和 C 等。
- 密度可达: 如果有一系列的点,都满足上一个点到这个点是密度直达,那么这个系列中不相邻的点就称为密度可达,比如 A 和 D。
- 密度相连: 如果通过一个核心对象出发,得到两个密度可达的点,那么这两个点称为密度相连,比如这里的 E 和 F 点就是密度相连。
; DBSCAN 处理步骤
经过了初始化之后,再从整个样本集中去抽取样本点,如果这个样本点是核心对象,那么从这个点出发,找到所有密度可达的对象,构成一个簇。
如果这个样本点不是核心对象,那么再重新寻找下一个点。
不断地重复这个过程,直到所有的点都被处理过。
这个时候,我们的样本点就会连成一片,也就变成一个一个的连通区域,其中的每一个区域就是我们所获得的一个聚类结果。
当然,在结果中也有可能存在像 G 一样的点,游离于其他的簇,这样的点称为异常点。
算法优缺点
优点
- 不需要划分个数。 跟 K-means 比起来, DBSCAN 不需要人为地制定划分的类别个数,而可以通过计算过程自动分出。
- 可以处理噪声点。 经过 DBSCAN 的计算,那些距离较远的数据不会被记入到任何一个簇中,从而成为噪声点,这个特色也可以用来寻找异常点。
- 可以处理任意形状的空间聚类问题。 从我们的例子就可以看出来,与 K-means 不同, DBSCAN 可以处理各种奇怪的形状,只要这些数据够稠密就可以了。
缺点
- 需要指定最小样本量和半径两个参数。 这对于开发人员极其困难,要对数据非常了解并进行很好的数据分析。而且根据整个算法的过程可以看出, DBSCAN 对这两个参数十分敏感,如果这两个参数设定得不准确,最终的效果也会受到很大的影响。
- 数据量大时开销也很大。 在计算过程中,需要对每个簇的关系进行管理。所以当数据量大的话,内存的消耗也非常严重。
- 如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差。
在使用的过程中十分要注意的就是最小样本量和半径这两个参数,最好预先对数据进行一些分析,来加强我们的判断
python 代码实现
今天我们使用的数据集不再是鸢尾花数据集,我们要使用 datasets 的另外一个生成数据的功能。
在下面的代码中可以看到,我调用了 make_moons 这个方法,在 sklearn 的官网上,我们可以看到关于这个方法的介绍:生成两个交错的半圆环,从下面的生成图像我们也能够看到,这里生成的数据结果,是两个绿色的半圆形。
我们今天调用的聚类方法是 sklearn.cluster 中的 dbscan。
from sklearn import datasets
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import dbscan #今天使用的新算法包
import numpy as np
X,_=datasets.make_moons(500,noise=0.1,random_state=1) #单单用x=。。。的话最后面还会有一个类别的数组
df = pd.DataFrame(X,columns=['x','y'])
df.plot.scatter('x','y',s=200,alpha=0.5,c='green')
# 接下来我们就用dbscan算法来进行聚类计算
# eps为邻域半径, min_samples为最少样本量
core_samples,cluster_ids=dbscan(X,eps=0.2,min_samples=20)
# cluster_ids中 -1表示对应的点为噪声
df= pd.DataFrame(np.c_[X,cluster_ids],columns=['x','y','cluster_id'])
# np.c 中的c 是 column(列)的缩写,就是按列叠加两个矩阵,就是把两个矩阵左右组合,要求行数相等。
df['cluster_id']=df['cluster_id'].astype('i2') #变整数
df.plot.scatter('x','y',s=200,c=list(df['cluster_id']),cmap='Reds',colorbar=False,alpha=0.6,title='DBSCAN')
最后,我们使用不同的颜色来标识聚类的结果,从图上可以看出有两个大类,也就是两个月亮的形状被聚类算法算了出来。
但是眼尖的同学可能看到,在月亮两头的区域有一些非常浅色的点,跟两个类别的颜色都不一样,这里就是最后产生的噪声点,根据我们设置的参数计算,这些点不属于任何一个类别。
Original: https://blog.csdn.net/abc1234564546/article/details/126135022
Author: ybhybh666
Title: DBSCAN算法(python代码实现)