
初衷

程序运行时keras及方法可以正常导入,
目的是消除如上图中的红线,以及获得代码自动补全的功能
尝试方法
翻了下网上基本3种方法
# 1st
from tensorflow.python.keras.layers import Dense
2nd
import tensorflow
Dense = tensorflow.keras.layers.Dense
3rd
from keras.layers import Dense
查看原始方法,和以上3种方法的layers调用地址:
结论
网上有这样的观点:
- tensorflow.python.*为核心部分代码, 不建议调用
- keras与tf.keras在版本相同时可以通用,不过tf以tf.keras作为高级api,可能有些交互和执行上的优化,建议调用tf.keras
所以只有第2种方法和原始的import是等价的。
代码补全是实现不了了,嫌弃红线可以用第2种变量声明的方法...
唉,就这样把...
其他
查看tensorflow.init()中对keras的定义部分:
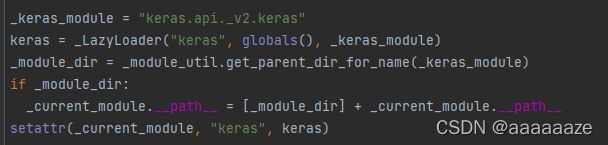
看不太懂,不过大概可以认为源码的思路是: 加载keras.api下的keras并返回一个变量或实例,用以调用keras下的方法。而这一过程必须在运行时才能发生。。
pycharm一类的解释器,识别不了这种调用方式。这应该就是导致红线和无法自动补全的原因。
Original: https://blog.csdn.net/aaaaaaze/article/details/123743185
Author: aaaaaaze
Title: tensorflow.keras的导入问题
相关阅读1
Title: gensim实现TF-IDF和LDA模型、sklearn实现聚类
假如我有100篇文章,每篇文章形如:
本发明公开的一种冰箱用的三风门,其包括:一风门本体,所述风门本体上设置有第一风口、第二风口和第三风口;安装在所述风门本体上的电动机构;分别设置在所述第一风口、第二风口和第三风口上的第一风门、第二风门、第三风门,所述第一风门、第二风门、第三风门由所述电动机构驱动按照一定的程序开启和关闭第一风口、第二风口和第三风口。本发明的冰箱用的三风门为整体结构、依靠一套传动机构来驱动三个风门启闭,其能够简化冰箱的结构,降低冰箱的成本。
是一个字符串。
那么我想要使用gensim构造基于TF-IDF的LDA模型模型,首先要构造特征。
思路:构造词袋模型->构造TF-IDF模型->构造LDA模型。
而gensim构造词袋模型的输入必须先对文章进行分词。
1.1 分词
一般使用jieba.lcut(string)
如果有stopwords可以这样
[k for k in jieba.lcut(string,cut_all=False) if k not in stop]
结果是这样:
['本发明', '公开', '一种', '冰箱', '风门', '包括', '风门', '本体', '所述', '风门', '本体', '设置', '第一', '风口', '风口', '第三', '风口', '安装', '所述', '风门', '本体', '电动', '机构', '设置', '所述', '第一', '风口', '风口', '第三', '风口', '第一', '风门', '风门', '第三', '风门', '所述', '第一', '风门', '风门', '第三', '风门', '所述', '电动', '机构', '驱动', '程序', '开启', '关闭', '第一', '风口', '风口', '第三', '风口', '本发明', '冰箱', '风门', '整体', '结构', '一套', '传动', '机构', '驱动', '三个', '风门', '启闭', '简化', '冰箱', '结构', '降低', '冰箱', '成本']
1.2 清洗
如果只想保留汉字,使用:
[i for i in string_list if re.match(r"[\u4e00-\u9fa5]", i)]
现在已经有一个100string_list的数据。
分别放着100篇文章分词清洗后的词。
假设名为 string_list100*
2.1 词典创建
import gensim.corpora as corpora
id2word = corpora.Dictionary(string_list100)
id2word.filter_extremes(no_below=3, no_above=0.5, keep_n=3000)
id2word.save_as_text("dictionary")
2.2 corpus创建
corpus = [id2word.doc2bow(text) for text in string_list100]
print(corpus[:1])
print([[(id2word[id], freq) for id, freq in cp] for cp in corpus[:1]])
输出形如:
[(0, 2), (1, 2)]
[('一侧', 2), ('一端', 2)]
2.3 词袋转为TF-IDF
from gensim import models
tfidf_model = models.TfidfModel(corpus=corpus, dictionary=id2word)
tfidf_model.save('test_tfidf.model')
tfidf_model = models.TfidfModel.load('test_tfidf.model')
corpus_tfidf = [tfidf_model[doc] for doc in corpus]
print(corpus_tfidf[:1])
print([[(id2word[id], freq) for id, freq in cp] for cp in corpus_tfidf[:1]])
输出形如:
[(0, 0.010196106762123805), (1, 0.0094972374458957)]
[('一侧', 0.010196106762123805), ('一端', 0.0094972374458957)]
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus_tfidf,
id2word=id2word,
num_topics=20,
random_state=100,
update_every=1,
chunksize=100,
passes=10,
alpha='auto',
per_word_topics=True)
3.1 结果查看
pprint 让输出更美观,num_words指的是每一个主题输出前多少的词。
from pprint import pprint
pprint(lda_model.print_topics(num_words=50))
3.2 评估指标
coherence_model_lda = CoherenceModel(model=lda_model, texts=string_list100, dictionary=id2word, coherence='c_v')
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score: ', coherence_lda)
4.1 构造特征
def get_features(corpus_one):
new_feature=[0 for k in range(3000)]
for j in corpus_one:
new_feature[j[0]]=j[1]
return new_feature
因为gensim得到的词袋模型以及tf-idf特征是不完整的,需要使用以上函数把每一篇文章的词袋数据转化为3000维的特征。
维度说明:
corpus = corpus_tfidf: 100 * 若干(每篇文章不一样)
对corpus_tfidf每一项get_features得到all_features: 100 * 3000
4.2 KMeans
from sklearn.cluster import KMeans
from sklearn import metrics
y_pred = KMeans(n_clusters=20, random_state=9).fit(all_features)
n_clusters表示分20类
print(y_pred.labels_)
print(y_pred.cluster_centers_)
print(y_pred.predict(new_feature))
4.3 评估指标
如果有分类的标注数据label
print(metrics.adjusted_rand_score(label, y_pred.labels_))
print(metrics.adjusted_mutual_info_score(label, y_pred.labels_))
以上是常用的KMeans评估方法。
参考文章1:文本聚类(一)—— LDA 主题模型
https://blog.csdn.net/weixin_37179744/article/details/108694415#12__94
参考文章2:用scikit-learn学习K-Means聚类
www.cnblogs.com/pinard/p/6169370.html
参考文章3:分别使用sklearn和gensim提取文本的tfidf特征www.jianshu.com/p/c7e2771eccaa
Original: https://blog.csdn.net/weixin_43499457/article/details/121087816
Author: 持续战斗状态
Title: gensim实现TF-IDF和LDA模型、sklearn实现聚类
相关阅读2
Title: okhttp3重试拦截
重试拦截器:
注意:两处while是因为如果请求中出现异常,也能进行重试,比如超时,后面会有例子。
网络拦截器,打印请求、响应时间、响应状态码,响应内容
1、带参数的get请求
测试:
String url = "http://localhost:8080/test/12346/query";Map params = new HashMap<>();params.put("aaa","111");params.put("bbb","222");HttpUtils httpUtils = HttpUtils.getInstance();httpUtils.get(url,params);打印日志如下:[main][2019-09-21 10:19:02.072] [INFO] [NetworkIntercepter.intercept:40] responseTime= 62, requestUrl= http://localhost:8080/test/12346/query?aaa=111&bbb=222, params=, responseCode= 200, result= {"result_code":"success","data":{"aaa":"111"},"path":"/test/12346/query"}
2、不带参数的get请求
测试:
String url = "http://localhost:8080/test/12346/query?ccc=1&ddd=2";HttpUtils httpUtils = HttpUtils.getInstance();httpUtils.get(url);打印日志如下:[main][2019-09-21 10:25:46.943] [INFO] [NetworkIntercepter.intercept:38] responseTime= 11, requestUrl= http://localhost:8080/test/12346/query?ccc=1&ddd=2, params=, responseCode= 200, result= {"result_code":"success","data":{"aaa":"111"},"path":"/test/12346/query"}
测试:
Gson gson = new Gson();String url = "http://localhost:8080/test/12346/query";Map params = new HashMap<>();params.put("aaa","111");params.put("bbb","222");Map bodyMap = new HashMap<>();bodyMap.put("name","zhangsan");bodyMap.put("age",15);HttpUtils httpUtils = HttpUtils.getInstance();httpUtils.post(url,params,gson.toJson(bodyMap));打印日志[main][2019-09-21 10:37:04.577] [INFO] [NetworkIntercepter.intercept:38] responseTime= 304, requestUrl= http://localhost:8080/test/12346/query?aaa=111&bbb=222, params={"name":"zhangsan","age":15}, responseCode= 200, result= {"result_code":"success","data":{"aaa":"111"},"path":"/test/12346/query"}
2、post发送json
测试:
Gson gson = new Gson();String url = "http://localhost:8080/test/12346/query";Map bodyMap = new HashMap<>();bodyMap.put("name","zhangsan");bodyMap.put("age",15);HttpUtils httpUtils = HttpUtils.getInstance();httpUtils.post(url,gson.toJson(bodyMap));
打印日志:
[main][2019-09-21 10:44:00.835] [INFO] [NetworkIntercepter.intercept:38] responseTime= 17, requestUrl= http://localhost:8080/test/12346/query, params={"name":"zhangsan","age":15}, responseCode= 200, result= {"result_code":"success","data":{"aaa":"111"},"path":"/test/12346/query"}
3、post发送表单
测试:
String url = "http://localhost:8080/test/12346/query";Map params = new HashMap<>();params.put("aaa","111");params.put("bbb","222");HttpUtils httpUtils = HttpUtils.getInstance();httpUtils.post(url,params);打印日志:[main][2019-09-21 10:49:54.136] [INFO] [NetworkIntercepter.intercept:38] responseTime= 21, requestUrl= http://localhost:8080/test/12346/query, params=aaa=111&bbb=222, responseCode= 200, result= {"result_code":"success","data":{"aaa":"111"},"path":"/test/12346/query"}
1、404重试
测试:
String url = "http://localhost:8080/test/12346/query2";Map params = new HashMap<>();params.put("aaa","111");params.put("bbb","222");HttpUtils httpUtils = HttpUtils.getInstance();httpUtils.post(url,params);日志打印:
[main][2019-09-21 10:56:20.495] [INFO] [NetworkIntercepter.intercept:38] responseTime= 26, requestUrl= http://localhost:8080/test/12346/query2, params=aaa=111&bbb=222, responseCode= 404, result= {"timestamp":1569034580,"status":404,"error":"Not Found","message":"Not Found","path":"/test/12346/query2"}
[main][2019-09-21 10:56:20.506] [INFO] [NetworkIntercepter.intercept:38] responseTime= 4, requestUrl= http://localhost:8080/test/12346/query2, params=aaa=111&bbb=222, responseCode= 404, result= {"timestamp":1569034580,"status":404,"error":"Not Found","message":"Not Found","path":"/test/12346/query2"}
[main][2019-09-21 10:56:20.512] [INFO] [NetworkIntercepter.intercept:38] responseTime= 4, requestUrl= http://localhost:8080/test/12346/query2, params=aaa=111&bbb=222, responseCode= 404, result= {"timestamp":1569034580,"status":404,"error":"Not Found","message":"Not Found","path":"/test/12346/query2"
重试了2次,共请求3次
2、超时重试
日志打印:
[main][2019-09-21 10:59:30.086] [ERROR] [NetworkIntercepter.intercept:33] timeout
[main][2019-09-21 10:59:30.092] [INFO] [NetworkIntercepter.intercept:38] responseTime= 2009, requestUrl= http://localhost:8080/test/12346/query, params=aaa=111&bbb=222, responseCode= null, result= null
[main][2019-09-21 10:59:32.097] [ERROR] [NetworkIntercepter.intercept:33] timeout
[main][2019-09-21 10:59:32.097] [INFO] [NetworkIntercepter.intercept:38] responseTime= 2004, requestUrl= http://localhost:8080/test/12346/query, params=aaa=111&bbb=222, responseCode= null, result= null
[main][2019-09-21 10:59:34.101] [ERROR] [NetworkIntercepter.intercept:33] timeout
[main][2019-09-21 10:59:34.101] [INFO] [NetworkIntercepter.intercept:38] responseTime= 2002, requestUrl= http://localhost:8080/test/12346/query, params=aaa=111&bbb=222, responseCode= null, result= null
Original: https://www.cnblogs.com/endv/p/16300051.html
Author: Endv
Title: okhttp3重试拦截
相关阅读3
Title: android开发-百度语音识别Android SDK的简单使用,跨平台小程序开发框架
===========================================================
1.引言
在人际交往中,言语是最自然并且最直接的方式之一。随着技术的进步,越来越多的人们也期望计算机能够具备与人进行言语沟通的能力,因此,语音识别这一技术也越来越受到关注。尤其,随着深度学习技术应用在语音识别技术中,使得语音识别的性能得到了显著提升,也使得语音识别技术的普及成为了现实。今天,我就用百度语音识别SDK做一个简单的使用案例。
2.开发环境
Android studio 3.6.1;
百度语音识别Android SDK3.1.6;
3.准备开发环境
3.1安装Android studio
3.2创建百度智能云平台应用
①登录百度智能云之后点击创建应用开始创建平台应用

②打开左侧导航栏找到语音技术
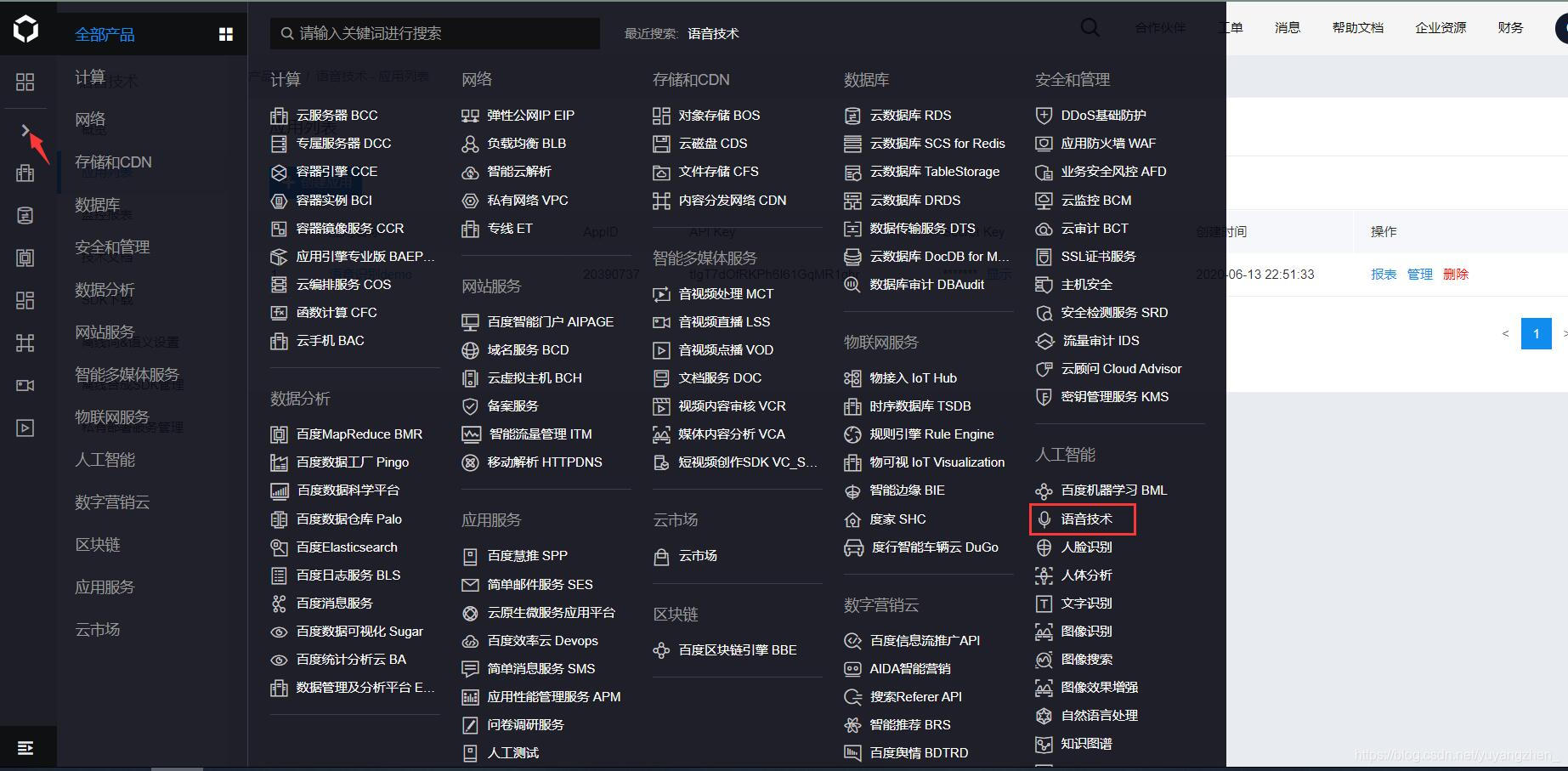
③进入到概览界面中,点击创建应用
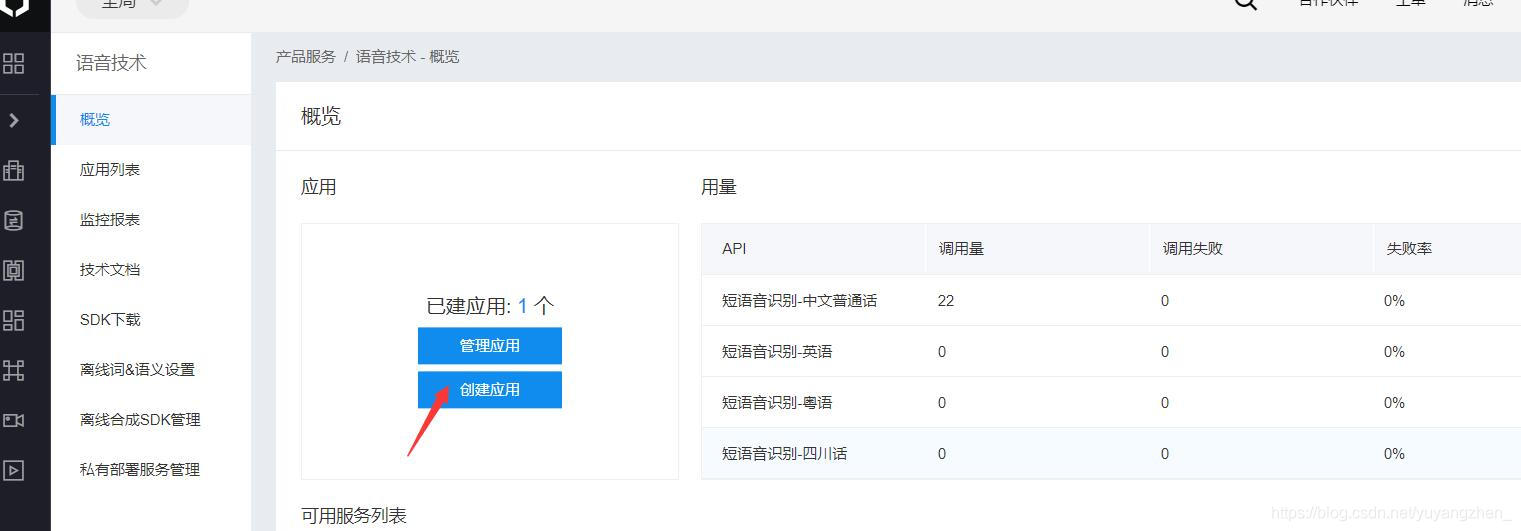
④填写新应用相关信息
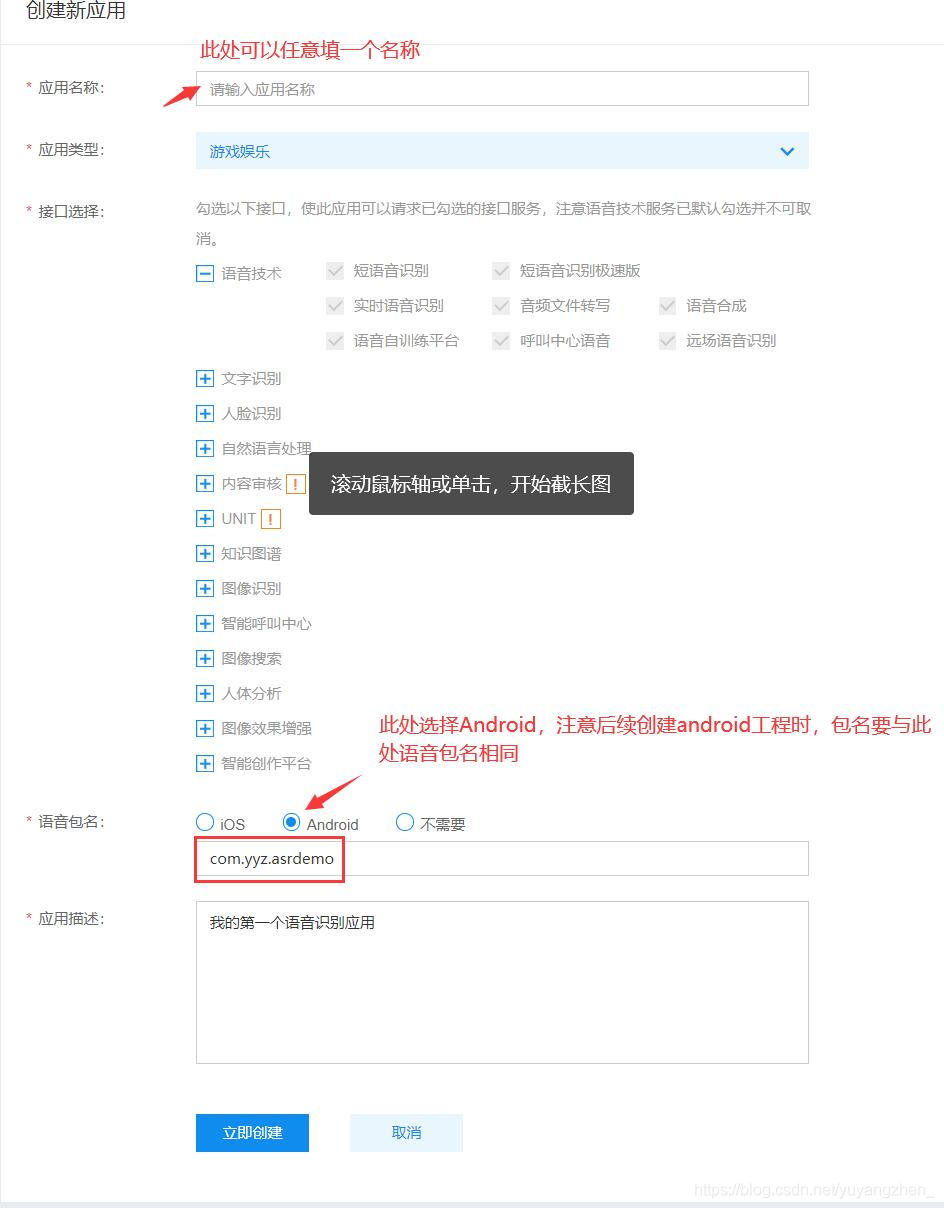
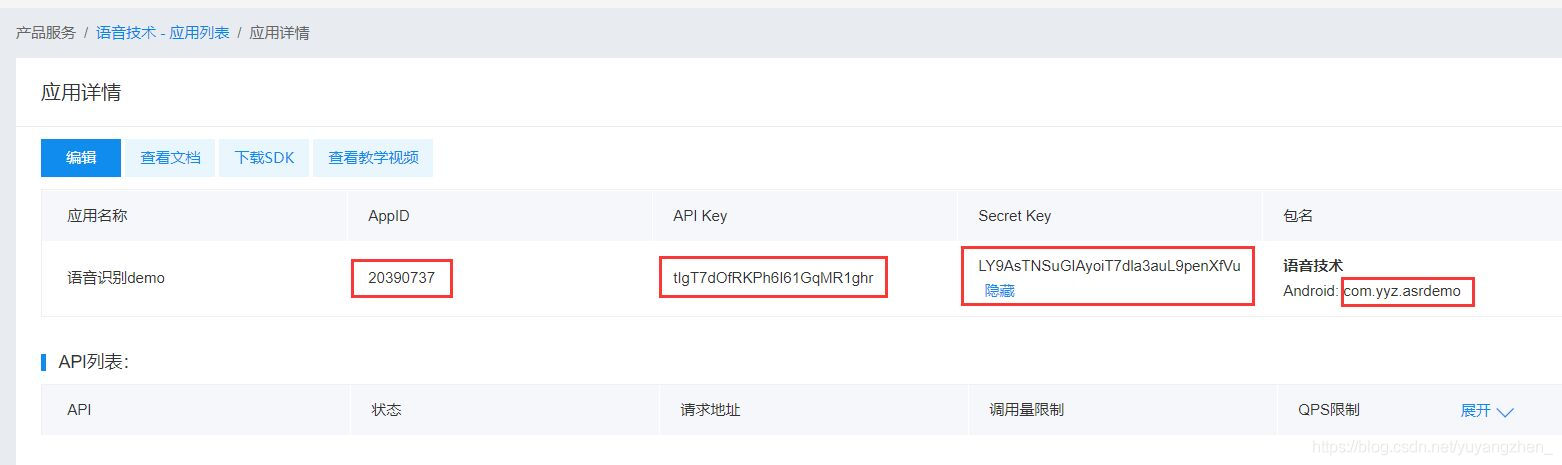
⑤点击立即创建后再点击查看应用详情,此处的AppID,AppID,Secret Key与包名都是后续需要使用到的,到时直接复制黏贴即可
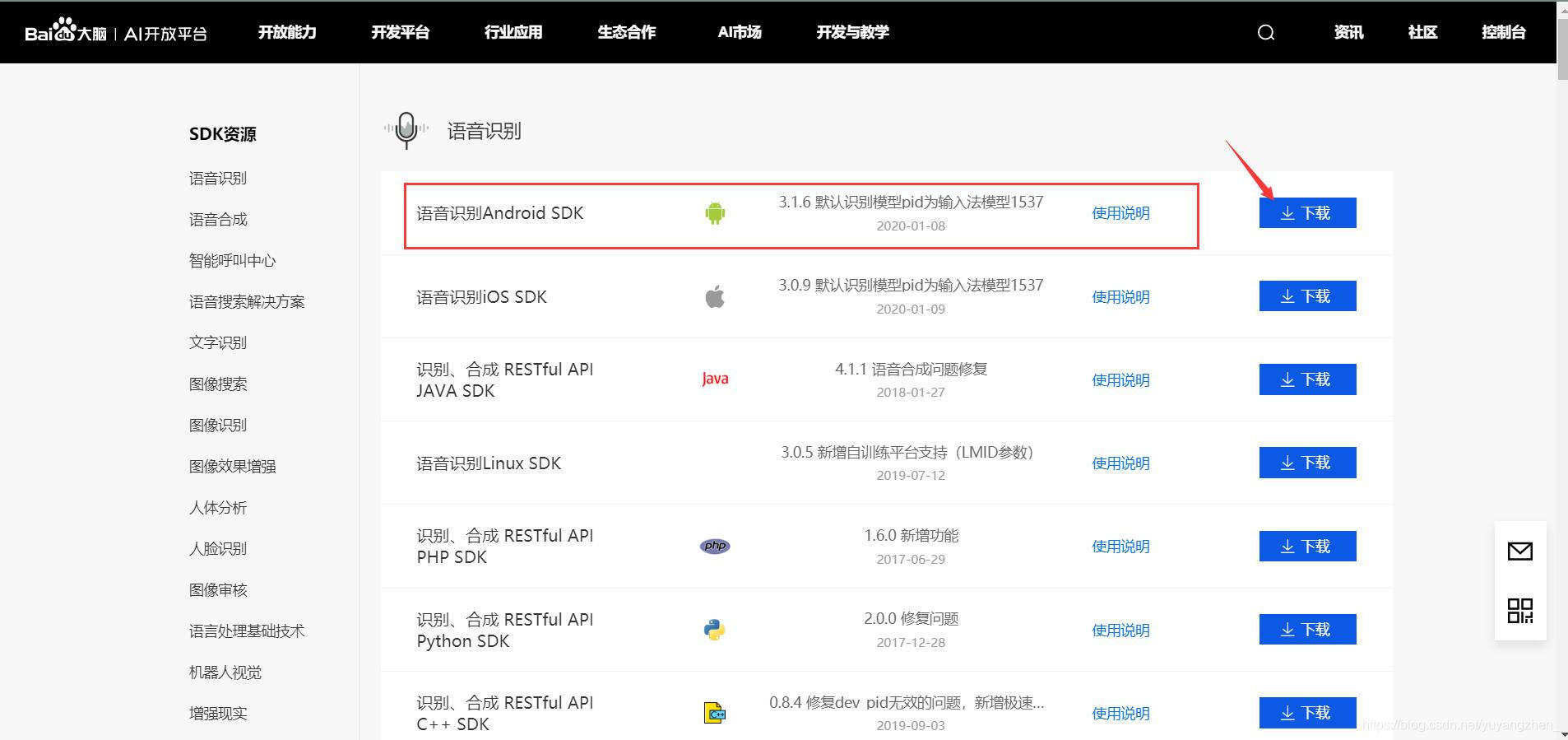
; 3.1下载百度语音识别SDK
。
下载后解压到本地。解压后会发现是个安卓工程,若想要把该工程跑起来可以自己看看其中的README文档。想要深入了解,可看。
4.实现语音识别的简单案例
4.1创建Android工程
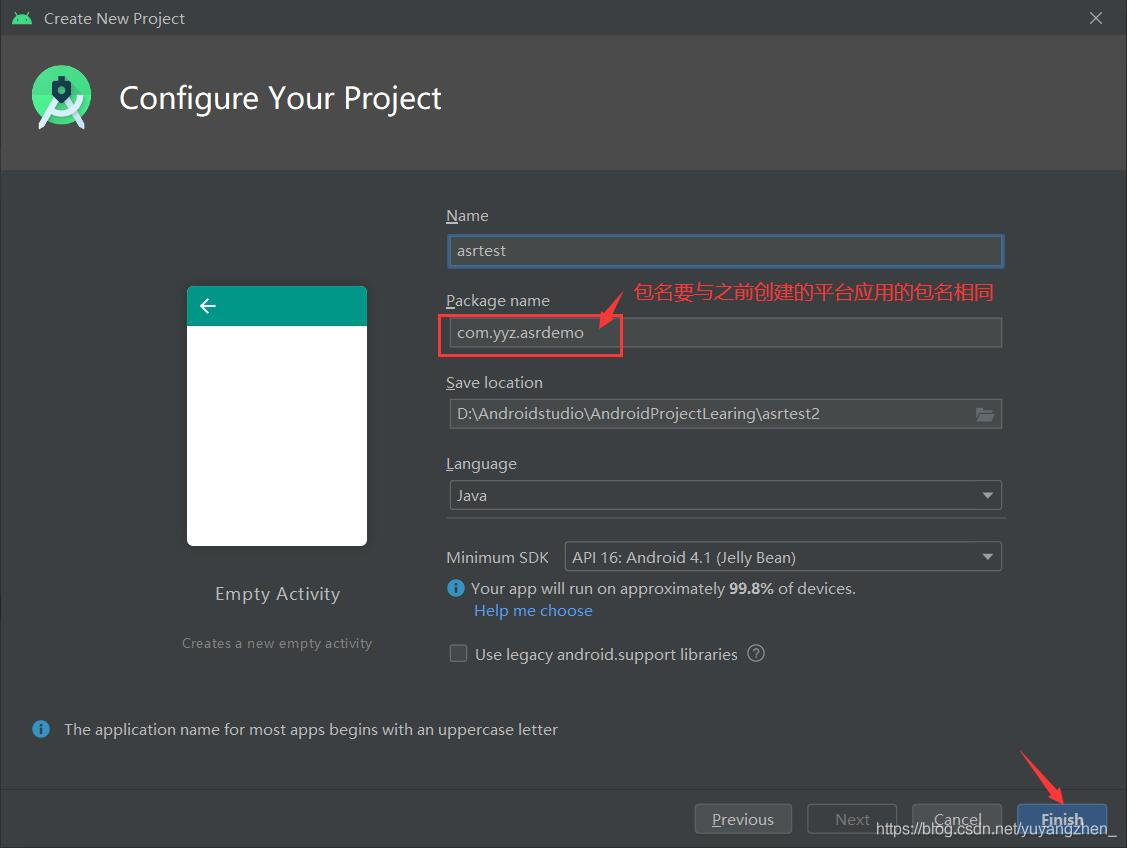
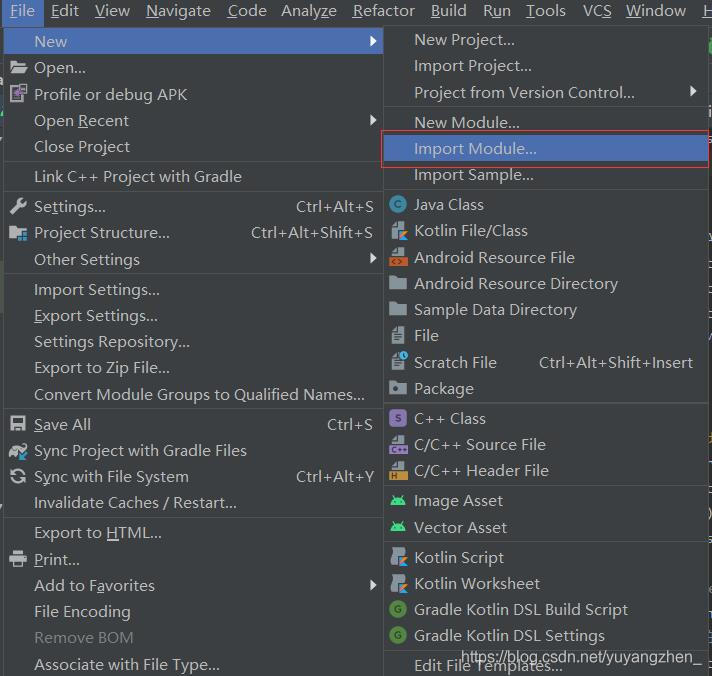
; 4.2导入core模块
①File→New→Import Module
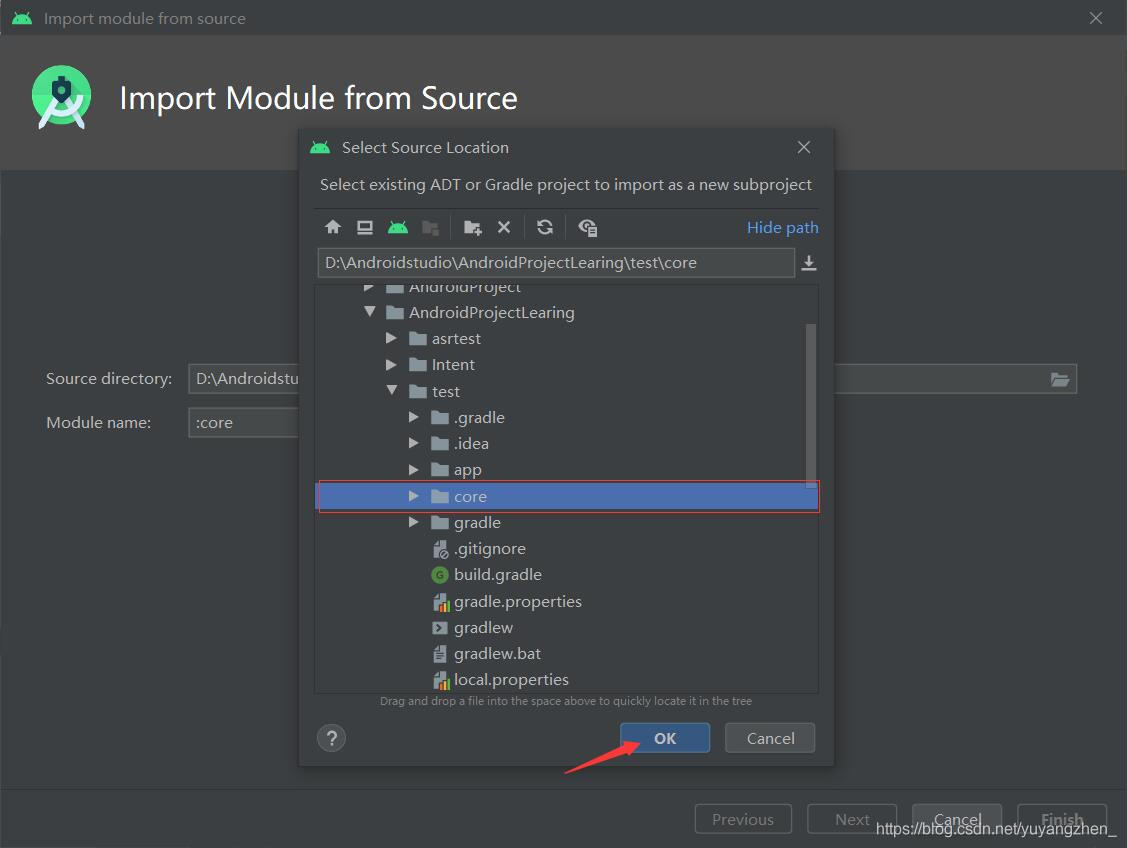
②找到之前解压出的文件中的core文件夹,选择OK→Finish
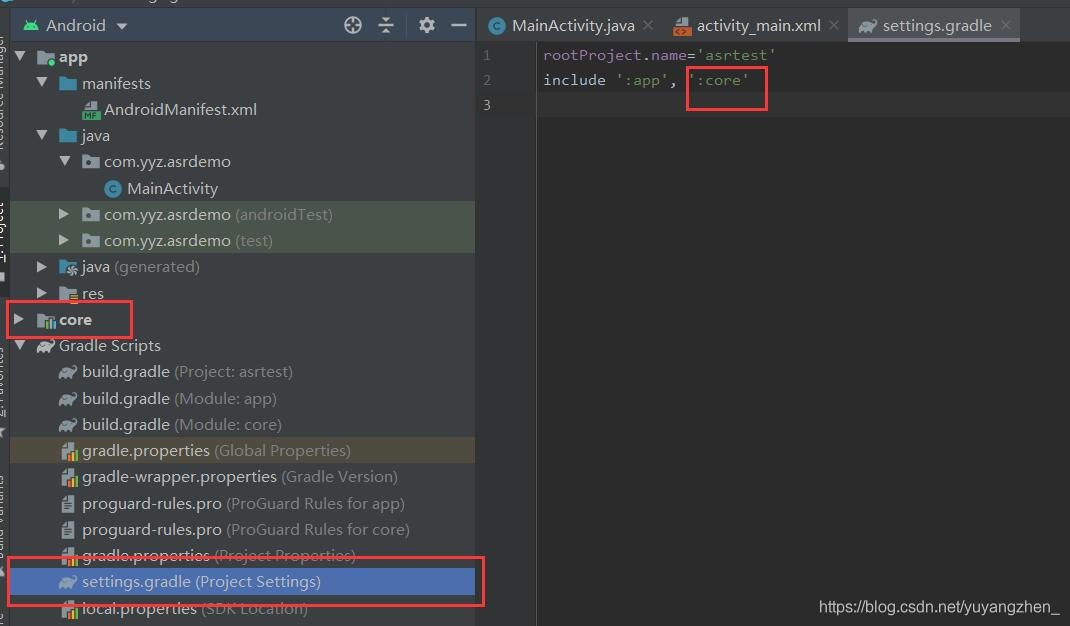
③此时查看项目目录下的settings.gradle, 可以看见core module已经被加载,同时可以看见core目录的图标,说明导入成功
4.3配置app依赖core
①右击app目录选择Open Module Settings
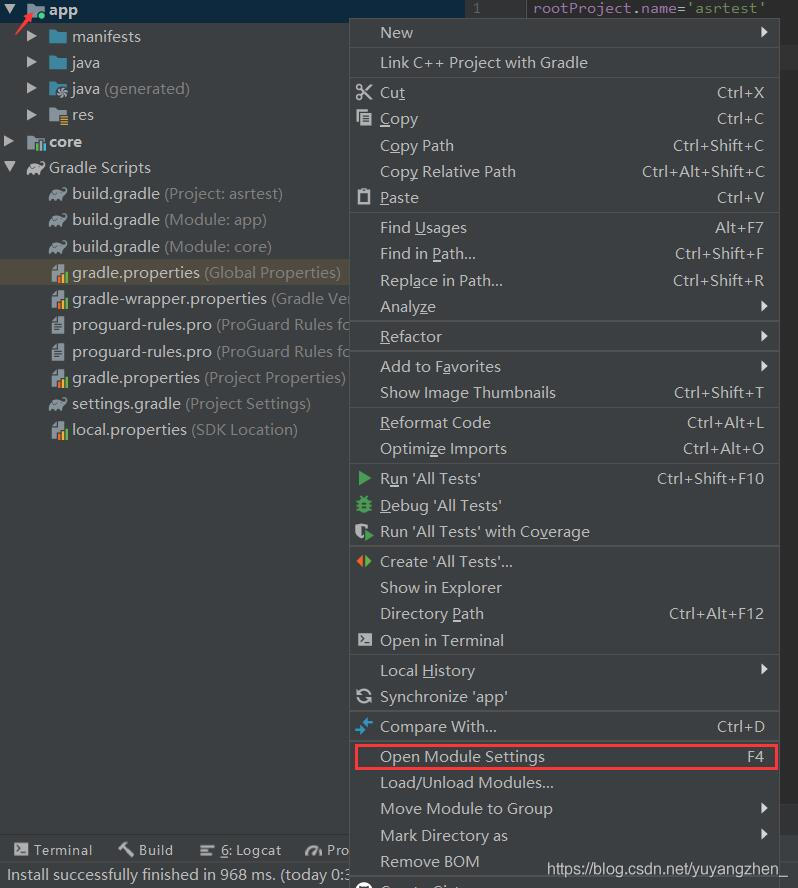
②在打开的界面选择Dependencies→app→+号→Module Dependency
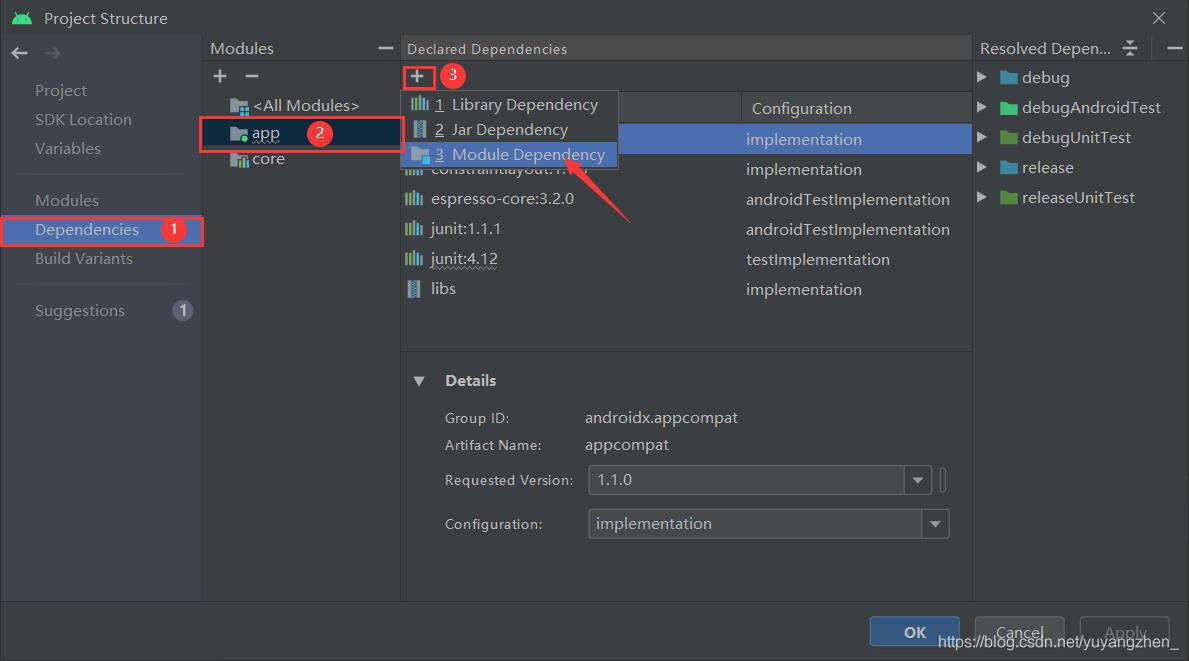
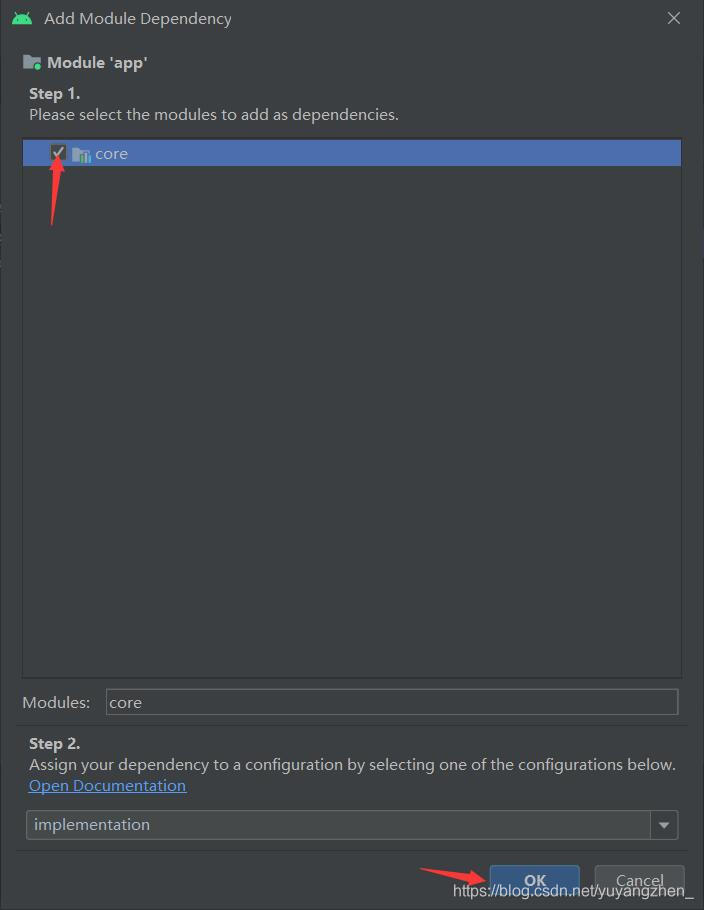
③在弹出的界面勾选core后点击OK,然后选择Apply
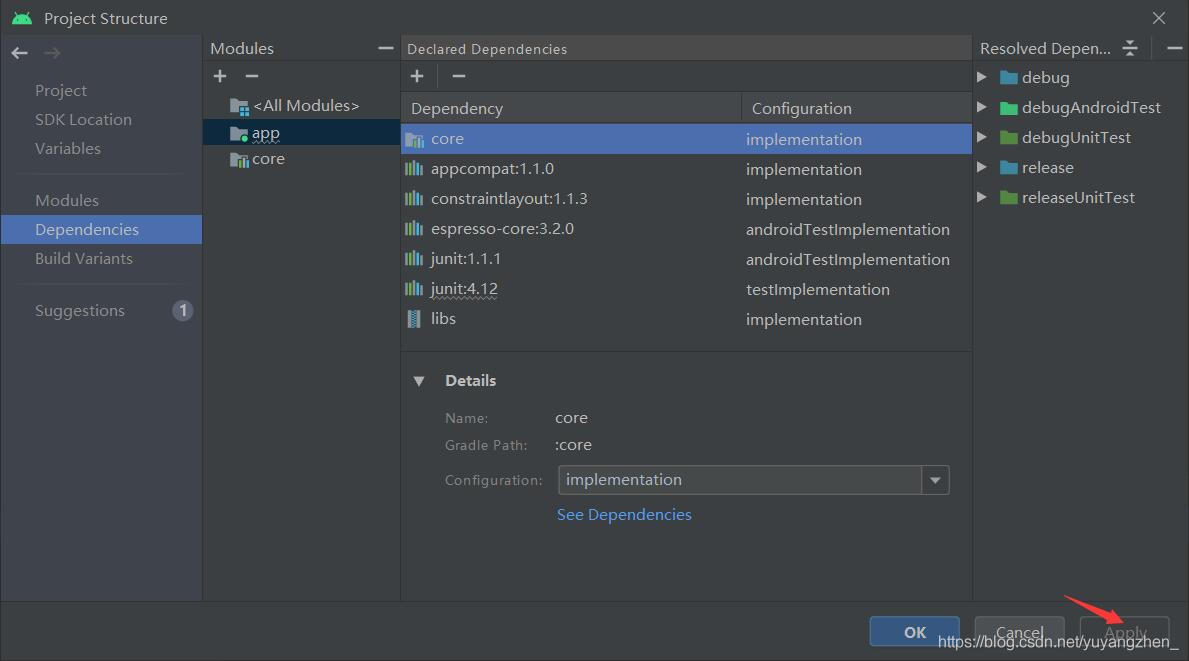
④此时观察build.gradle(module :app)文件,发现自动添加了如下一行
implementation project(path: ':core')
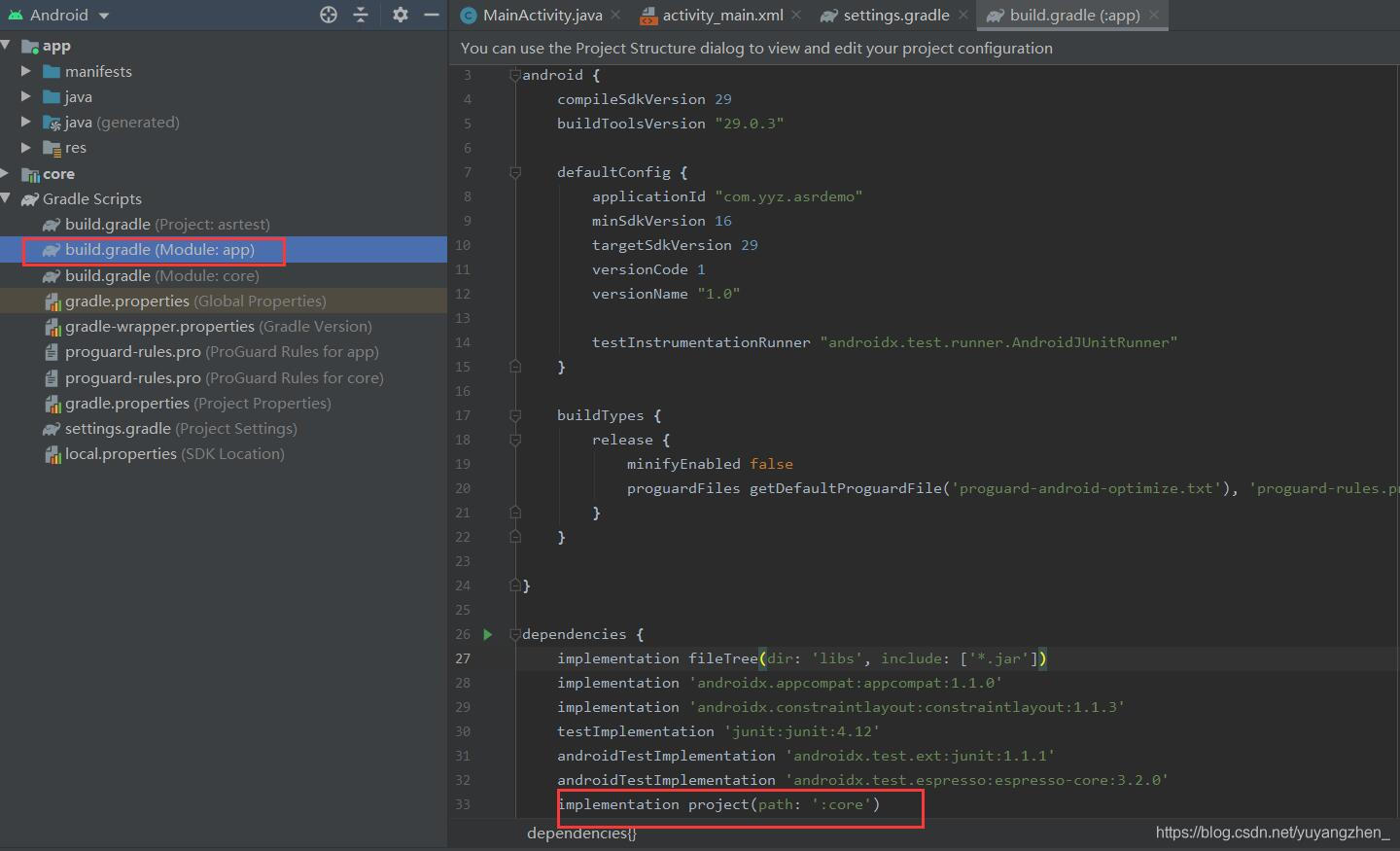
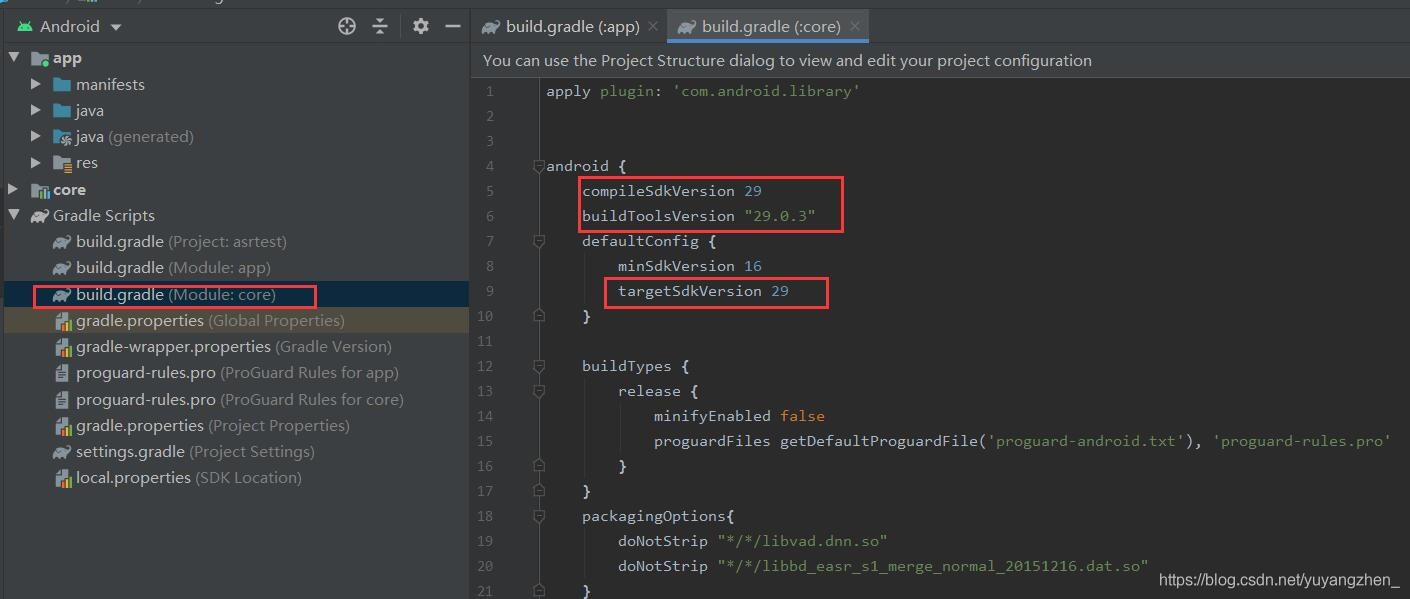
⑤根据app/build.gradle(module :app)更改core/build.gradle(module :core)部分版本号。因为我用的API Level是29所以我改成29,你的不一定和我一样,以你的app/build.gradle(module :app)文件中内容为准。
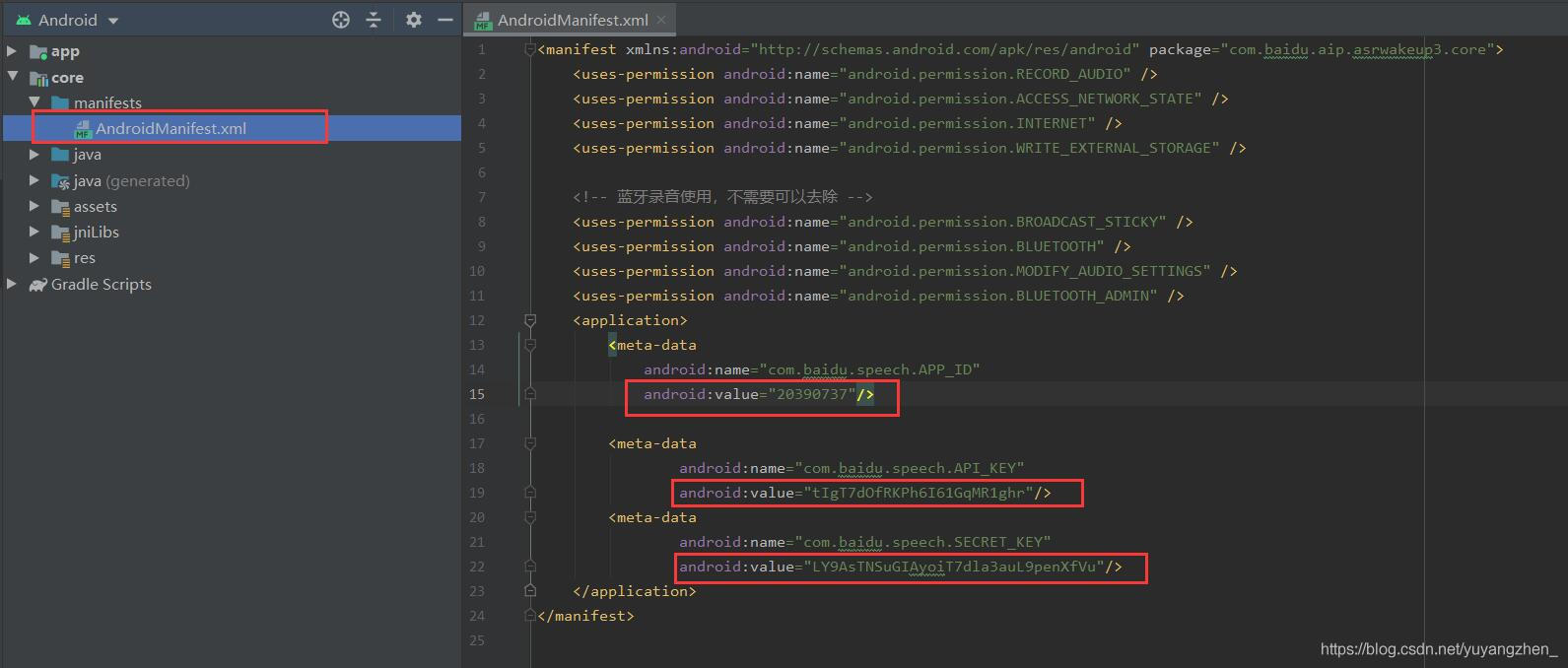
⑥在你的core\manifests\AndroidManifest.xml文件里,替换你的appId 丶appKey与secretKey为之前你在百度智能云上创建的应用的对应信息
; 4.4使用百度语音识别SDK
①修改布局文件app\res\layout\activity_main.xml,简单写一个界面即可
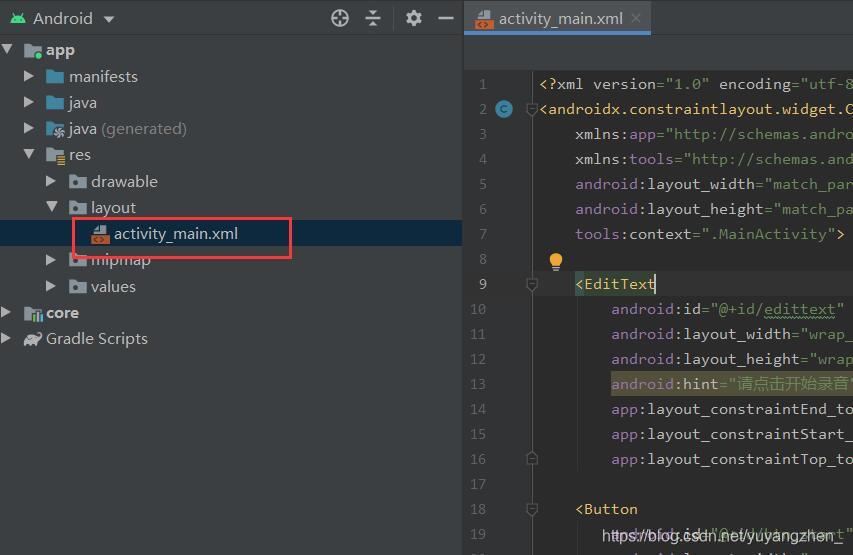
代码如下:
Original: https://blog.csdn.net/m0_64382743/article/details/121556945
Author: m0_64382743
Title: android开发-百度语音识别Android SDK的简单使用,跨平台小程序开发框架