
首先确定想要安装的TensorFlow版本,须知TensorFlow与cuda版本具有对应关系,可以在这里查看从源代码构建 | TensorFlow (google.cn)![]() https://tensorflow.google.cn/install/source#gpu ;
https://tensorflow.google.cn/install/source#gpu ;
我用的是CUDA11.2+TensorFlow2.6
那么我们正式开始安装过程:
1、 下载安装cuda
进入NVIDIA官网,初次使用可能需要创建账户CUDA Toolkit 11.6 Update 2 Downloads | NVIDIA Developer ![]() https://developer.nvidia.com/cuda-downloads ;
https://developer.nvidia.com/cuda-downloads ;
这里可以选择对应电脑系统的安装包,我的电脑是windows10系统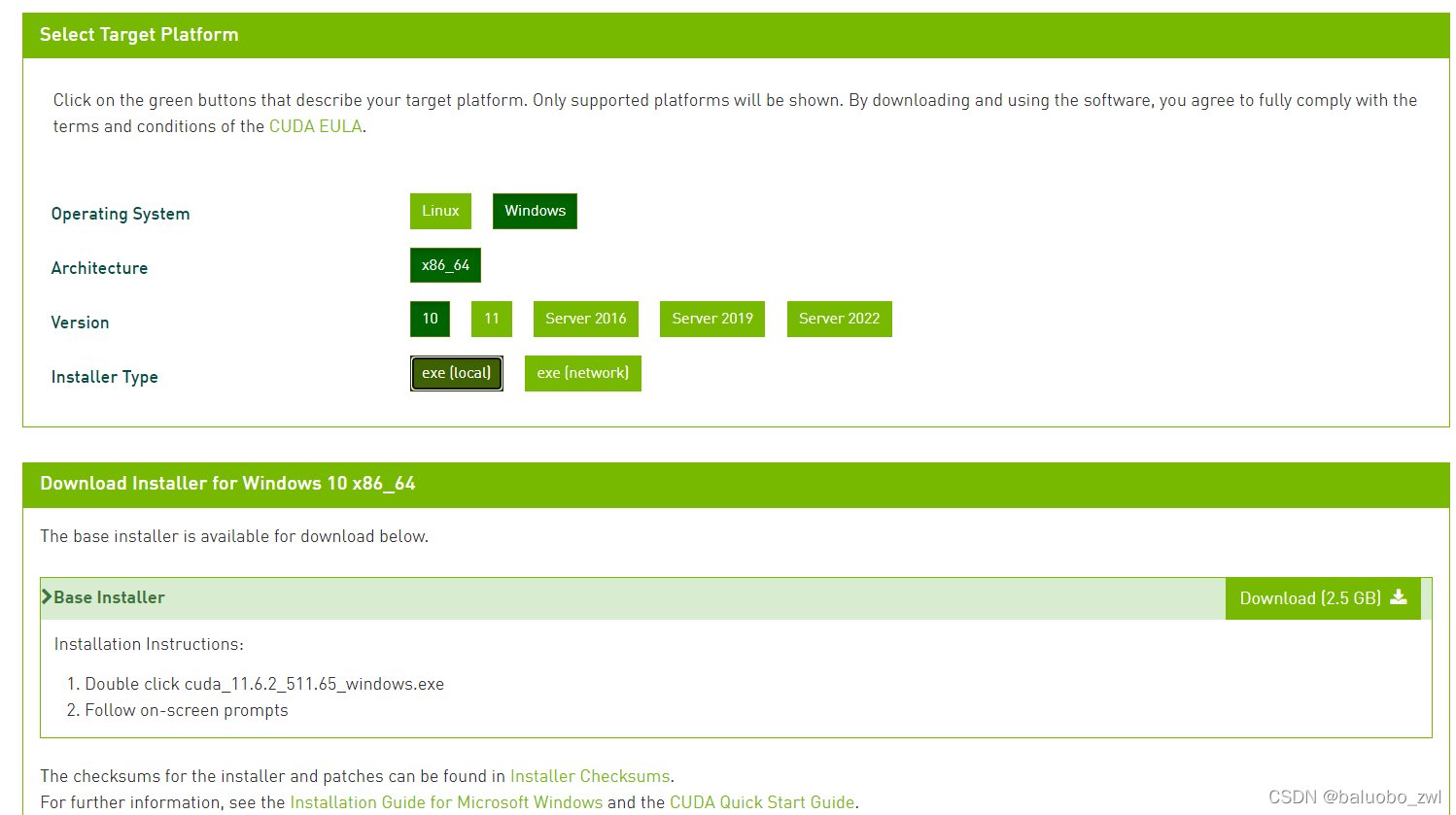
注意注意注意!!!
这里是11.6版本,想要下载旧版本需要在网页下面选择previous cuda releases
下载好后,应该是个exe,双击运行,选择自定义安装,这里的安装地址都可以选择安装在非系统盘,但是不能路径里面不能有中文字符。
当然你的C盘够大话,就当我没说 。其中更细节的部分可以见这篇文章,其中安装和卸载部分写的很棒(31条消息) CUDA、CUDNN在windows下的安装及配置_花花少年的博客-CSDN博客_cudnn配置![]() https://blog.csdn.net/m0_37605642/article/details/98854753 ;
https://blog.csdn.net/m0_37605642/article/details/98854753 ;
安装程序显示安装成功后,直接关闭安装程序
然后打开"cmd",输入
nvcc -V
或者
nvidia-smi
我的显示为cuda11.2,这就安装完了第一部分
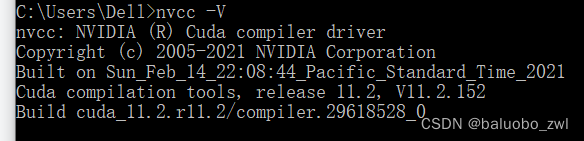
注:命令行里面使用nvcc -V命令得到的cuda版本,会与电脑上nvidia程序里面的显示不同,这是正常现象,具体原因我没有深究
2、下载安装anaconda
下载地址如下,选择适合自己电脑的版本即可
Anaconda Nucleus ![]() https://anaconda.cloud/support-center/installers ;
https://anaconda.cloud/support-center/installers ;
安装过程如下,注意安装时, 勾选上添加环境变量,很重要
3、安装TensorFlow
这一步全都是在cmd命令行完成的,建议 使用管理员身份打开cmd,可以避开一些奇怪的坑
开始之前我们需要了解一下anaconda到底干了什么,对编程有了解的小伙伴,应该知道解释器,对应的Python也有很多版本的解释器。
我们平时能够在pycharm这样的IDE里面编程序,并且能够运行起来都是因为,我们电脑上装好了Python的环境,包括解释器,还你import的库这些。你回忆一下平时使用pip install ,其实都是往这个环境里面丰富一些库
可以理解成电脑上有一个盆子,里面装了一些基础材料以及工具,然后你在这个盆子里用了这些材料和工具,终于写好代码,才可以正常运行
正常情况,电脑里只装了一个版本的Python;那么anaconda的作用就在于帮你的电脑分出来几个盆子,你可以多装几个不同版本的Python,一个盆子用来跑跑简单程序,一个盆子用来泡深度学习,不同盆子里的东西互不干扰。
那么我们现在回到anaconda中来,在我们安装好后,它已经具有了一个盆子base,我们可以使用以下代码段查看
conda env list
我现在装好了TensorFlow环境,所以显示两个

安装步骤,按照视频来就行
4、开始编程
你以为这已经搞定了?
不不不,还远远不止
你现在可能还会遇到各种报错,import失败等等
当然大部分问题都可以在CSDN解决,其中有几个要点
1、检查环境变量是否配置成功
2、有的依赖库可以从其它虚拟环境里复制过来
3、无法下载依赖库时,可以通过更新conda来解决
pip install 库名
pip install 库名 --upgrade
或者
conda install 库名
conda update 库名
更新所有库
conda update --all
更新 conda 自身
conda update conda
更新 anaconda 自身
conda update anaconda
5、安装pytorch(CUDA与anaconda的安装方法与TensorFlow规则相同)
1、管理员打开anaconda prompt,创建环境
conda create -n pytorch python=3.8
2、激活新环境,安装pytorch
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=10.2 -c pytorch
3、验证pytorch是否可以调用GPU
(pytorch) C:\WINDOWS\system32>python
>>> import torch
>>> print(torch.__version__)
>>> print(torch.cuda.is_available())
4、安装torch库
pip install torch==1.10.1+cu102 torchvision==0.11.2+cu102 torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html
conda常用操作代码
Original: https://blog.csdn.net/baluobo/article/details/124060075
Author: baluobo_zwl
Title: 记录:TensorFlow2.6版本环境搭建cuda11.2 anaconda python3.9 ++++ pytorch环境安装
相关阅读1
Title: 【从kitti开始自动驾驶】--9.1 利用IMU/GPS测距并比较效果(jupyter)
本届jupyter工程存放在est3_autodrive_ws/src/jupyter_prj/Mesure_distance.ipynb
要得到距离,需要知道两个因素:角度偏移和移动的距离
1.1 角度计算
角度计算较为简单, 在GPS/IMU数据中,有yaw航向角数据,两帧做差即可得到角度偏移
1.2 距离计算
得到距离有两种计算方法:
2.1 大圆距离公式函数
- 输入这一帧的经纬度, 上一帧的经纬度
- 地球半径6371000
- clip限幅函数,对delta_sigma限幅
def compute_great_circle_distance(lat1, lon1, lat2, lon2):
'''
Compute the great circle distance from two gps data
Input: latitudes and longitudes in degree
Output : distance in meter
'''
delta_sigma = float(np.sin(lat1*np.pi/180)*np.sin(lat2*np.pi/180) +
np.cos(lat1*np.pi/180)*np.cos(lat2*np.pi/180)*np.cos(lon1*np.pi/180 - lon2*np.pi/180))
return 6371000.0*np.arccos(np.clip(delta_sigma, -1, 1))
2.2-a GPS测距离
- 利用大圆距离公式/经纬度数据测距离
- 建立这一帧和上一帧数据
- 循环迭代
prev_imu_data = None
gps_distance = []
imu_distance = []
for frame in range(150):
imu_dat = read_imu('/home/qinsir/kitti_folder/2011_09_26/2011_09_26_drive_0005_sync/oxts/data/%010d.txt'%frame)
if prev_imu_data is not None:
gps_distance += [compute_great_circle_distance(imu_dat.lat, imu_dat.lon, prev_imu_data.lat, prev_imu_data.lon)]
prev_imu_data = imu_dat
2.2-b IMU测距离
- 利用vl和vf数据测距离
- linalg.onrm函数用于计算一个向量的模
- 速度转距离乘以时间0.1即可
prev_imu_data = None
gps_distance = []
imu_distance = []
for frame in range(150):
imu_dat = read_imu('/home/qinsir/kitti_folder/2011_09_26/2011_09_26_drive_0005_sync/oxts/data/%010d.txt'%frame)
if prev_imu_data is not None:
imu_distance += [0.1 * np.linalg.norm(imu_dat[['vf', 'vl']])]
prev_imu_data = imu_dat
2.3 绘图
- 在同一张画布上展示,将会更加直观:
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 10))
plt.plot(gps_distance, label = 'gps_distance')
plt.plot(imu_distance, label = 'imu_distance')
plt.legend()
plt.show()
2.4 效果展示
- 蓝色为GPS的效果
- 红色为IMU的效果

2.5 结论
通过下=上图看出来,GPS速度非常不平滑,只能反映大概的走势, 反观IMU则速度平滑
- 在短时间,短距离内使用IMU会更符合实际情况
- 但在长时间,IMU的误差会随着时间的累积会越来越多,长时间GPS精准度高
源码上传至资源,建议自己编写,资源与如下代码无异
import numpy as np
import pandas as pd
IMU_COLUMN_NAMES = ['lat', 'lon', 'alt', 'roll', 'pitch', 'yaw', 'vn', 've', 'vf', 'vl', 'vu', 'ax', 'ay', 'az', 'af',
'al', 'au', 'wx', 'wy', 'wz', 'wf', 'wl', 'wu', 'posacc', 'velacc', 'navstat', 'numsats', 'posmode',
'velmode', 'orimode']
def read_imu(path):
df = pd.read_csv(path, header=None, sep=" ")
df.columns = IMU_COLUMN_NAMES
return df
def compute_great_circle_distance(lat1, lon1, lat2, lon2):
'''
Compute the great circle distance from two gps data
Input: latitudes and longitudes in degree
Output : distance in meter
'''
delta_sigma = float(np.sin(lat1*np.pi/180)*np.sin(lat2*np.pi/180) +
np.cos(lat1*np.pi/180)*np.cos(lat2*np.pi/180)*np.cos(lon1*np.pi/180 - lon2*np.pi/180))
return 6371000.0*np.arccos(np.clip(delta_sigma, -1, 1))
prev_imu_data = None
gps_distance = []
imu_distance = []
for frame in range(150):
imu_dat = read_imu('/home/qinsir/kitti_folder/2011_09_26/2011_09_26_drive_0005_sync/oxts/data/%010d.txt'%frame)
if prev_imu_data is not None:
gps_distance += [compute_great_circle_distance(imu_dat.lat, imu_dat.lon, prev_imu_data.lat, prev_imu_data.lon)]
imu_distance += [0.1 * np.linalg.norm(imu_dat[['vf', 'vl']])]
prev_imu_data = imu_dat
gps_distance
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 10))
plt.plot(gps_distance, label = 'gps_distance')
plt.plot(imu_distance, label = 'imu_distance')
plt.legend()
plt.show()
Original: https://blog.csdn.net/Eric_Sober/article/details/124441985
Author: 终问鼎
Title: 【从kitti开始自动驾驶】--9.1 利用IMU/GPS测距并比较效果(jupyter)
相关阅读2
Title: 用 DeepLab-V3+ 模型做 Cityscapes 的 segmentation 任务,in Keras/TensorFlow 2.8
文章目录
前言
DeepLab-V3+ 是一个很好的 segmentation 架构。→ arXiv 论文链接在此
可以用 Inception-ResNet V2 作为脊柱 backbone,搭建一个 DeepLab-V3+ 模型,在 Cityscapes 数据集上做 segmentation 任务,效果如下。
- 在训练集上的效果:
说明:每一行 3 张图片,其中左图为数据集的原图,最右图为模型预测的结果,即 segmentation mask,中间的图片是把原图和 mask 重叠的结果,以方便检查 segmentation mask 的准确度。


- 在验证集上的效果:


- 在测试集上的效果:

下面用 Keras/TensorFlow 2.8 来搭建这个 DeepLab-V3+ 模型。
; 1. DeepLab-V3+ 的主体架构。
DeepLab-V3+ 的结构图如下。
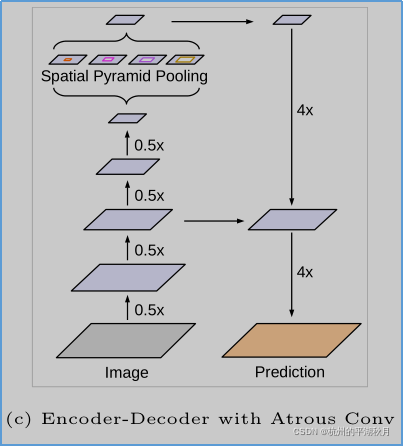
DeepLab-V3+ 的主体架构有 3 个关键点:
- 模型分为前后 2 个部分。前半部分用于对图片进行理解(即上面结构图的左半部分),后半部分则用于给图片各个区域进行分类(上面结构图的右半部分),生成 mask。前半部分也叫做编码器 encoder,而后半部分也叫做解码器 decoder。
- 编码器顶部,使用了 ASPP 模块(Atrous Spatial Pyramid Pooling)。ASPP 的主要作用是,借助 atrous convolution(也叫 dilation convolution)使得模型有 5 种不同大小的感受域(3 个空洞卷积,1 个普通卷积,再加 1 个平均池化),将小的特征信息和大的特征信息进行混合,从而获得更好的场景信息 semantic information。 ASPP 的另一个名字是 DSPP(Dilated Spatial Pyramid Pooling)。
- 在解码器 decoder 部分,从 encoder 获得了一个底层特征 low-level features,作为输入注入到解码器中(即上面结构图中,左右两部分中间位置,进行横向连接的那个箭头)。这个底层特征的作用,是使得模型预测结果 mask 中,各个类别的轮廓更加准确。(BTW,顺着这个思路,我对 DeepLab-V3+ 模型做了一点修改,增加了一个底层特征注入到解码器中,以使得各个类别的轮廓更清晰,似乎有一点作用。用 keras.utils.plot_model 查看模型结构时,可以看到我增加的这个连接。)
2. 使用 Cityscapes 数据集。
- Cityscapes 数据集的内容很多。在这个模型中,只需要用到数据集的 2 个文件夹, "leftImg8bit_foggy " 和 "gtFine"。
- 需要制作 colormap 文件。colormap 中保存的是颜色映射关系,即 Cityscapes 的 34 个类别和 34 种颜色的一一对应关系。我已经根据 Cityscapes 官方的颜色对应关系制作好了这个 colormap_cityscapes.json 文件,可以直接使用。如果是应用到其它数据集,需要自行制作其它数据集的 colormap 文件。
3. 环境配置和使用方法。
为了方便训练模型和调试,需要使用 Jupyter Lab,在 cityscapes_deeplab_v3plus.ipynb 文件中进行模型训练。
而其它函数,则集中放在 Python 文件 deeplab_v3_plus.py 中。
TensorFlow: 2.8
使用时,只需要在 Jupyter Lab 中打开 cityscapes_deeplab_v3plus.ipynb 文件操作即可。下面为 Jupyter Lab 中训练模型部分的图示。
如果显存不够大,可以设置如下 2 项:
- 设置图片大小。在 deeplab_v3_plus.py 中,设置 MODEL_IMAGE_SIZE(实际设置 model_image_height 即可,会自动计算 MODEL_IMAGE_SIZE)。MODEL_IMAGE_SIZE 是输入给模型的图片大小。
- 设置批次大小。在 cityscapes_deeplab_v3plus.ipynb 文件中,设置 BATCH_SIZE 。
如果是单张 RTX 3090 显卡,可以使用模型默认的设置,MODEL_IMAGE_SIZE = 512 x 1024 , BATCH_SIZE = 8。如果显存不够,可以降低图片大小为 320 x 640,或降低批次大小。
; 4. 参考代码。
我的模型参考了 Keras 官方代码。→ 官方代码链接在此 官方代码使用的是一个不同的 backbone 和一个不同的数据集,有兴趣的同学可以学习一下。
需要注意的是,官方代码中有一点不足,即在对标签 mask 进行图片缩放操作时,使用了 bilinear 插值方法。但实际上,应该使用最邻近点插值方法(在 TensorFlow 中为 tf.image.ResizeMethod.NEAREST_NEIGHBOR。这个问题属于吴恩达在深度学习课程中所说的 subtlety,即容易被忽视的要点)。经验证后发现,使用官方代码的插值方法,会使得准确度下降 2%。
举例说明为什么只能用最邻近点插值方法。假设 mask 图片中有一个桌子,桌子上面放着一个杯子。桌子的类别为 0,而杯子的类别为 2。当使用 bilinear 或 bicubic 插值方法时,可能会插入一个值 1,但是类别 1 有可能是代表了一辆火车。这时 mask 中就会出现一个错误的情形,即一辆火车被夹在一个桌子和一个杯子中间,从而导致模型学习到一些错误的信息。反之,如果使用最邻近点插值方法,就不会出现这种问题。
5. github 下载链接。
下面是创建 DeepLab-V3+ 模型的主函数,其它完整数据,可以在 github 下载。→ 下载链接在此
def inceptionresnetv2_deeplabv3plus(model_image_size, num_classes,
rate_dropout=0.1):
"""使用 Inception-ResNet V2 作为 backbone,创建一个 DeepLab-V3+ 模型。
Arguments:
model_image_size: 一个整数型元祖,表示输入给模型的图片大小,格式为
(height, width, depth)。注意对于 Inception-ResNet V2,要求输入图片的像
素值必须转换到 [-1, 1] 之间。
为了便于说明数组形状,这里假设模型输入图片的大小为 (512, 1024, 3)。
num_classes: 一个整数,是模型中需要区分类别的数量。
rate_dropout: 一个浮点数,范围是 [0, 1],表示 SpatialDropout2D 层的比例。
Returns:
model: 一个以 Inception-ResNet V2 为脊柱的 DeepLab-V3+ 模型。
"""
keras.backend.clear_session()
model_input = keras.Input(shape=(*model_image_size, 3))
conv_base = keras.applications.InceptionResNetV2(
include_top=False,
input_tensor=model_input)
low_level_feature_backbone = conv_base.get_layer(
'activation_4').output
for _ in range(2):
low_level_feature_backbone = convolution_block(
low_level_feature_backbone)
low_level_feature_backbone = keras.layers.Conv2DTranspose(
filters=256, kernel_size=3,
kernel_initializer=keras.initializers.HeNormal())(
low_level_feature_backbone)
low_level_feature_backbone = convolution_block(
low_level_feature_backbone, num_filters=256, kernel_size=1)
if rate_dropout != 0:
low_level_feature_backbone = keras.layers.SpatialDropout2D(
rate=rate_dropout)(low_level_feature_backbone)
encoder_backbone = conv_base.get_layer('block17_10_ac').output
encoder_backbone = dilated_spatial_pyramid_pooling(encoder_backbone)
decoder_backbone = keras.layers.Conv2DTranspose(
256, kernel_size=3, kernel_initializer=keras.initializers.HeNormal())(
encoder_backbone)
decoder_backbone = keras.layers.UpSampling2D(
size=(4, 4), interpolation='bilinear')(decoder_backbone)
if rate_dropout != 0:
decoder_backbone = keras.layers.SpatialDropout2D(rate=rate_dropout)(
decoder_backbone)
x = keras.layers.Concatenate()(
[decoder_backbone, low_level_feature_backbone])
for _ in range(2):
x = convolution_block(x)
if rate_dropout != 0:
x = keras.layers.SpatialDropout2D(rate=rate_dropout)(x)
x = keras.layers.UpSampling2D(size=(4, 4), interpolation='bilinear')(x)
if rate_dropout != 0:
x = keras.layers.SpatialDropout2D(rate=rate_dropout)(x)
down_sampling_1 = model_input
down_sampling_1 = convolution_block(down_sampling_1, num_filters=8,
separableconv=False)
for _ in range(2):
down_sampling_1 = convolution_block(down_sampling_1, num_filters=8)
if rate_dropout != 0:
down_sampling_1 = keras.layers.SpatialDropout2D(rate=rate_dropout)(
down_sampling_1)
x = keras.layers.Concatenate()([down_sampling_1, x])
for _ in range(2):
x = convolution_block(x, num_filters=64)
model_output = keras.layers.Conv2D(
num_classes, kernel_size=(1, 1), padding='same')(x)
model = keras.Model(inputs=model_input, outputs=model_output)
return model
Original: https://blog.csdn.net/drin201312/article/details/123353599
Author: 杭州的平湖秋月
Title: 用 DeepLab-V3+ 模型做 Cityscapes 的 segmentation 任务,in Keras/TensorFlow 2.8
相关阅读3
Title: Lite Pose: Efficient Architecture Design for 2D Human Pose Estimation 阅读笔记
Lite-Pose:2D人体姿态估计的高效架构设计
摘要:姿态估计在以人为中心的视觉应用中发挥关键作用。但由于高昂的计算成本(每帧超过150个GMACs(一个 GMACS:等于每秒10亿 (=10^9) 次的定点乘累加运算)),基于 HRNet 的 sota 姿态估计模型难以部署在资源受限的边缘设备上。本文研究了边缘实时多人姿态估计的有效架构设计。通过 gradual shrinking 实验,我们发现 HRNet 的高分辨率分支对处于低计算区域的模型是冗余的,删除它们可以提高效率和性能。受这一发现的启发,我们设计了有效的姿态估计单分支架构:LitePose,并引入两种简单方法( fusion deconv head 和 large kernel conv)来增强LitePose的性能。在 mobile 平台上,与现有的高效 sota 姿态估计模型相比,LitePose 在不牺牲性能的情况下将延迟减少了 5.0× ,推动了实时多人位姿估计的前沿发展。
文章目录
- Lite-Pose:2D人体姿态估计的高效架构设计
- 1. Introduction
- 2. Related Work
- 3. Rethinking the Efficient Design Space 反思高效设计空间
* - 3.1. Scale-Aware Multi-branch Architectures 尺度感知多分支架构
- 3.2. Redundancy in High-Resolution Branches 高分辨率分支中的冗余
- 3.3. Fusion Deconv Head: Remove the Redundancy 融合卷积头:移除冗余
- 3.4. Mobile Backbone with Large Kernel Convs 具有大核卷积的 mobile backbone
- 3.5. Single Branch, High Efficiency 单分支,高效率
- 4. Neural Architecture Search 神经架构搜索
- 5. Experiments
* - 5.1. Dataset & Metrics 数据集和评估标准
- 5.2. Experiment Setting 实验设置
- 5.3. Ablation Experiments
- 5.4. Main Results
- 6. Conclusion
1. Introduction
人体姿态估计旨在从图像中预测每个人的关键点位置。它是许多需要理解人体行为的视觉应用的关键技术。典型的人体姿态估计模型可以分为两种范式:Top-down 和 Bottom-up。Top-down 范式先通过额外的人体检测器检测人,然后对每个检测到的人执行单人姿态估计。Bottom-up 范式先预测与身份无关的关键点,然后将其分组给每个人。由于 Bottom-up 范式不涉及额外的人体检测器,也无需重复运行姿态估计模型来估计每个人的姿态,因此它更适合于边缘上的实时多人姿态估计。但现有的 Bottom-up 姿态估计模型主要关注高计算区域,例如 HigherNet 在 CrowdPose 数据集上以超过 150GMACs 实现了sota性能,这对于边缘设备来说是不适用的。在保持良好性能的同时,设计计算成本低的模型具有重要意义。
本文研究 Bottom-up 人体姿态估计的高效架构设计。先前在高计算区域的研究(Higherhrnet,DEKR)表明,保持高分辨率表示对 bottom-up 姿态估计性能至关重要,但目前尚不清楚高分辨率表示是否适用于低计算区域的模型。为回答此问题,我们通过 gradual shrinking(图2) 在具有代表性的多分支架构 HigherNet 和单分支架构之间建立了一座"桥梁"。我们惊讶地发现,在低计算区域缩小模型的高分辨率分支深度时,性能得到了改善(图3)。 受这一发现的启发,我们设计了一种 单分支架构 LitePose,进行高效的 Bottom-up 姿态估计。LitePose 使用改进的MobileNetV2作为backbone,并进行了两项重要改进: fusion deconv head 和 large kernel conv,来有效处理单分支设计中的尺度变化问题。fusion deconv head 消除了高分辨率分支中的冗余细化,因此允许以单分支方式进行尺度感知多分辨率融合(图6)。同时,不同于图像分类,large kernel conv 在 bottom-up 姿态估计上的改进更显著(图7)。 最后,我们应用 Neural Architecture Search (NAS) 优化模型架构并选择适当的输入分辨率。
在COCO 和 CrowdPose 数据集上广泛的实验结果验证了 LitePose 的有效性。在CrowdPose上,LitePose以更好的性能实现了 2.8× 的 MACs 减少和高达 5.0× 的延迟减少。在COCO上,相较于EfficientHRNet,LitePose减少了 2.9× 的延迟,同时实现了更好的性能。
我们的贡献如下:
- 我们设计了 gradual shrinking 实验,揭示了高分辨率分支对于在低计算区域的模型是冗余的。
- 我们提出了一个有效的 Bottom-up 姿态估计架构:LitePose,引入了两种提高LitePose性能的技术: fusion deconv head 和 large kernel conv。
- 在COCO 和 CrowdPose 数据集上广泛的实验表明了 LitePose 的有效性:在CrowdPose上,相较于基于 HRNet 的 sota 方法,LitePose 实现了 2.8× 的 MACs 下降和高达5.0× 的延迟下降。
2. Related Work
2D人体姿态估计。 2D人体姿态估计旨在定位人体解剖关键点(如肘部、腕部)或部位。分为两个主要框架:Top-down 和 Bottom-up。Top-down 先检测图像中的每个人,再执行单人姿态估计,而 Bottom-up 以端到端的方式直接检测每个人的关键点。典型的 Bottom-up 法包括两个步骤:预测关键点热图,然后将检测到的关键点分组个每个人。在这些方法中,基于HRNet 的多分支结构(Higherhrnet,DEKR)实现了 sota, 他们设计了一种多分支架构进行多分辨率融合来解决 Bottom-up 姿态估计的尺度变化问题。但所有这些方法都过于计算密集(大多数>150GMAC),无法部署在边缘设备上。本工作重点关注Bottom-up的效率框架。遵循基于HRNet的 sota 方法(Higherhrnet),我们使用关联嵌入(associative embedding)进行分组。
模型加速。 除了直接设计有效模型外,模型加速的另一种方法是压缩现有的大型模型。一些方法旨在消除在连接和卷积滤波器内部的冗余。另外一些方法侧重于量化网络。此外几种 AutoML 方法能自动进行模型压缩和加速。LiteHRNet关注 Top-down 姿态估计,而我们关注 bottom-up 范式。EfficientHRNet 针对有效的bottom-up姿态估计,其将 EfficientNet 中的compound scaling 思想应用于 HigherHRNet 并实现了1.5×的MACs减少。但当面对更严格的计算约束时,这些方法的性能会严重下降。我们的工作将MACs下降率推到了 5.1×,并且相较于EfficientHRNet,在mobile平台上将冗余降低了 5.0×。
Neural Architecture Search。 神经结构搜索(NAS)在 large-scale 图像分类任务中取得了巨大成功。自动设计的模型明显优于手工制作的模型。为了提高搜索过程的效率,研究人员提出了一种 one-shot NAS方法,不同的子网络共享相同的权重集。为进一步探索我们的体系架构的潜力,我们应用 Once-for-all(一劳永逸)方法来自动修剪 通道内的冗余 并选择适当的输入大小。 与手工设计的从头开始训练的模型相比,我们搜索的模型实现了高达 3.6 AP 的性能提升。
3. Rethinking the Efficient Design Space 反思高效设计空间
在 bottom-up 姿态估计任务中,多分支网络已经实现了巨大的成功。代表性工作 HigherHRNet 使用多分支架构进行多分辨率融合,缓解了尺度变化问题。得益于此,多分支体系结构优于单分支体系结构,并获得 sota 结果。但这些方法中的大多数(HigherHRNet,DEKR,Stacked hourglass,Personlab )仍存在一个问题,即它们的sota性能是在大于150GMACs的情况下实现的,方法间的比较也大多是在这样高的计算量下进行的。对于实际的边缘应用,研究具有较低计算量的有效人体姿态估计具有重要意义。本节先介绍基于HRNet的多分支架构,以及它们如何处理尺度变化问题。然后,我们通过在计算受限情况下 gradual shrinking 指出高分辨率分支中的冗余。基于这一观察结果,我们提出了 fusion deconv head,它消除了高分辨率分支中的冗余细化,可以有效处理尺度变化问题。另一方面,实验发现,与图像分类任务相比, 大核卷积在姿态估计任务上的改进更显著。大量实验和消融研究验证了我们方法的有效性,并揭示:适当设计的单分支架构可以实现更好的性能和更低的延迟。
3.1. Scale-Aware Multi-branch Architectures 尺度感知多分支架构
Scale-Awareness 尺度感知。 多分支设计旨在缓解自底向上姿态估计中的尺度变化问题。姿态估计需要预测图像中所有人的关节坐标,单分支结构通常难以识别小尺度人体并从最终的低分辨率特征中区分紧密的关节,如图5(b) 所示,而多分支结构引入的高分辨率特征可以保留更细节性信息,因此有助于神经网络更好地捕捉小尺度人体并区分紧密关节。
机制。 如图2 所示,基于HRNet的多分支架构(HigherHRNet,DEKR)的main body 包含4个阶段。本文将 stem 视作 stage 1,stage n 有 n 个分支分别控制 n 个不同分辨率的输入特征图。在处理输入特征时,每个分支先分别细化自己的输入特征,然后在分支间交换信息以获得多尺度信息。
3.2. Redundancy in High-Resolution Branches 高分辨率分支中的冗余
然而,当关注低计算量的性能时,我们发现多分支架构可能不是最佳选择。本节提出 gradual shrinking 方法来揭示多分支体系结构的高分辨率分支中的冗余。如图2和图3所示,通过逐渐缩小高分辨率分支的深度,多分支网络的表现越来越像单分支网络,但性能并没有降低甚至有所提高。

图2 gradual shrinking 实验中的4个结构配置。使用 HigherHRNet 作为baseline进行比较。被删除的block以透明形式显示。从 baseline 到 Shrink3,网络越来越接近单分支架构。为确保不同的架构配置具有相似的MACs,将 Shrink2 和 Shrink3 的基本通道从16增加到18。

图3. 对 HigherHRNet-W16 的高分辨率分支逐渐收缩时,性能提高了
Gradual Shrinking. 为揭示基于HRNet的多分支架构内部的冗余,我们在每个阶段的分支上设计了一个gradual shrinking 实验。令 A n = [ a 1 , . . . , a n ] A_n= [a_1, . . . , a_n]A n =[a 1 ,...,a n ] 表示在 stage n 融合前用于细化每个分支特征的 block 数(a i a_i a i 代表第 i 分支的block数),分支 i 处理的特征图分辨率高于分支 i+1。然后将整个多分支架构的设置定义为:A = { A 1 , A 2 , A 3 , A 4 } A={A_1, A_2, A_3, A_4}A ={A 1 ,A 2 ,A 3 ,A 4 }。A n ′ = [ a 1 ′ , . . . , a n ′ ] A'n= [a'_1, . . . , a'_n]A n ′=[a 1 ′,...,a n ′] 是从 A n = [ a 1 , . . . , a n ] i f ∀ j ∈ { 1 , . . . , i } , a j ′ ≤ a j A_n= [a_1, . . . , a_n] \quad if \quad ∀ j∈{1, . . . , i},a'_j≤a_j A n =[a 1 ,...,a n ]i f ∀j ∈{1 ,...,i },a j ′≤a j 的收缩,方便起见,用 A i ′ ≤ A i A'_i≤A_i A i ′≤A i 表示,A 配置 A' 称为从 A ( 即 , A ′ ≤ A ) i f ∀ i ∈ { 1 , 2 , 3 , 4 } , A i ′ ≤ A i A(即,A'≤A) \quad if \quad ∀ i∈ {1,2,3,4},A'_i≤A_i A (即,A ′≤A )i f ∀i ∈{1 ,2 ,3 ,4 },A i ′≤A i 的收缩。使用上述符号, gradual shrinking 意味着我们构造了一系列配置 [ C 1 , . . . , C m ] s . t . C i + 1 ≤ C i , ∀ i ∈ 1 , . . . , m − 1 [C_1, . . . , C_m] \quad s.t. \quad C{i+1}≤C_i, \quad ∀i∈ {1, . . . , m−1}[C 1 ,...,C m ]s .t .C i +1 ≤C i ,∀i ∈1 ,...,m −1。如图2和图3所示,逐渐缩小高分辨率分支的深度甚至有助于提高性能。同时,逐渐收缩的过程使整个网络越来越类似于单分支网络,充分证明单分支架构更适合 Bottom-up 姿态估计任务。为使逐渐收缩过程更清晰,下面详细列出了四种配置:

; 3.3. Fusion Deconv Head: Remove the Redundancy 融合卷积头:移除冗余
虽然我们已经展示了上述多分支架构中的冗余,但其仍有强大的处理尺度变化问题的能力。 我们能否在保持单分支架构优点(例如,高效率)的同时,将此功能结合到我们的设计中呢?为实现这一目标,我们提出了 fusion deconvolution 作为最终预测头,如图4和图6(b)所示,我们直接(即不进行任何细化)利用前一阶段生成的 low-level high-resolution 特征进行反卷积和最终预测层。一方面,LitePose使用具有低延迟特性的单分支架构作为backbone,另一方面,直接使用 low-level high-resolution 特征可以避免多分支HR融合模块中的冗余细化,因此,LitePose具有单分支设计和多分支设计的优点。图5 和 图6(a)展示了融合反卷积头的能力,在几乎不增加计算成本的情况下,性能得到显著提升(+7.6AP)。

图4. LitePose架构。LitePose 由 Backbone 和 fusion deconvolution head 构成。符号表示 concatenate 操作。final convs 用于多分辨率监督

图5. with/without larger kernel convs 和 fusion deconv head的模型可视化。具有larger kernel convs 和 fusion deconv head的Liteposeca可以更好地识别较小的人体并区分紧密关节。

图6. 不同于传统的 single-branch deconv head (从黑块到红块),我们的 fusion deconv head利用了HR融合模块的优势,并去除了高分辨率冗余细化块。相较于普通的反卷积头,它增加较小计算量,实现了很大的性能提升(+7.6AP)。
3.4. Mobile Backbone with Large Kernel Convs 具有大核卷积的 mobile backbone
一些工作研究在严格计算约束下图像分类任务的高效架构。如图4所示,LitePose 使用改进的 MobileNetV2 作为backbone,遵循 Efficientpose,通过删除最后的下采样阶段,对原始MobileNetV2进行了微小修改。 过多的下采样层会丢失基本信息,不利于姿态估计任务的高分辨率输出。
为进一步缓解尺度变化问题,我们在高效的架构设计中引入了大内核。与传统的图像分类任务不同,这种修改在我们 MobileNetV2-based backbone中发挥重要作用。图7中展示了 kernel size 为3,5,7(仅用于姿态估计)的模型在图像分类和姿态估计任务上的性能比较。在计算成本增加相似(约25%)的情况下,姿态估计任务的性能增益(+13.0AP) 远超于图像分类任务 (+1.5% Acc),图5中的可视化结果也可以验证这一观点。但并非"越大越好",过大的kernel 将引入许多无用的参数和难以忽略的noisy,使训练变难,性能下降,如图7中k=9的情况所示。由于我们进一步发现,将 kernel size 合并到 search space 将严重降低 NAS 的性能(这可能是由 kernel size 变化的巨大影响导致的),因此我们将kernel size 固定为7×7。

图7. k表示 kernel size。k的增加会适度提高图像分类的性能,但会极大影响姿态估计的性能。具体而言,将 kernel size 从3增加到7可以在CrowdPose实现13% mAP的性能提升。
; 3.5. Single Branch, High Efficiency 单分支,高效率
除性能外,单分支LitePose的另一个优点是其硬件友好性。正如ShuffleNetV2提到的那样,network fragmentation (如多分支设计)降低了某些硬件上的并行度,因此,对于实际应用,单分支架构是更好的选择。 总之,图3 展示了HigherHRNet-W16 和 Litepose-L间的定量比较结果。相较于HigherHRNet-W16, Litepose-L不仅实现了更好的性能提升(+11.6AP),且在具有甚至更大 MACs 的 Qualcomm Snapdragon 855上获得了相似的延迟。所有这些结果都验证了单分支 LitePose 的高效性。

图8. 相较于多分支 HigherHRNet-W16,单分支LitePose-L具有更高的并行性。因此,它不仅实现了更好的性能提升(+11.6AP),且在具有甚至更大 MACs 的 Qualcomm Snapdragon 855上获得了相似的延迟。
4. Neural Architecture Search 神经架构搜索
现有的bottom-up姿态估计工作通常在模型的所有层上使用手工制作的(且基本统一)通道宽度和固定的大分辨率(例如,512×512)。为进一步探索我们模型的潜在紧凑性,本节将 once-for-all(一劳永逸) 应用于自动修剪通道中的冗余,并选择最佳输入分辨率。优化目标和搜索过程如下所述,通过NAS,我们得到了四个用于不同计算预算的LitePose模型(XS、S、M和L)。5.3节详细展示了NAS的有效性。
Optimization Goal 优化目标。 假设原始的 LitePose 的每个层包含 { c k } k = 1 K {c_k}^K_{k=1}{c k }k =1 K 个通道,K 表示网络的层数。我们的优化目标是找到一个输入分辨率是 r'
One-shot Supernet Training。 先训练一个LitePose supernet(超网),该超网遵循 (Once-for-all,Single path one-shot neural architecture search with uniform sampling)的权重共享来支持不同的通道数配置。对每个 training iteration,统一采样一个通道配置,并用它训练超网。这样,每个配置都经过同等训练,可以独立运行。为了帮助超网更好地学习 associate embedding 进行分组,使用预训练权重初始化超网。有关supernet的训练和预训练详见 5.2 节。
Search & Fine-tune。 由于超网是通过权重共享进行彻底训练的,因此我们可以直接提取某个子网的权重并评估子网,而无需进一步微调,这近似于子网的最终性能。我们使用进化算法来寻找给定特定效率约束(例如MAC)的最优配置,找到最优配置后,对一些 epoch微调相应的子网,并报告了最终性能。有关微调的更多详细信息,请参阅第5节。
5. Experiments
5.1. Dataset & Metrics 数据集和评估标准
数据集:COCO,CrowdPose。
评估标准:由OKS计算的AP。
5.2. Experiment Setting 实验设置
数据增强。 数据增强包括随机旋转[−30◦,30◦],随机尺度变换[0.75,1.5],随即平移([−40,40]),以及随即翻转。
预训练细节。 我们发现,若从头开始训练 one-shot supernet,网络将学习低质量的 Associative Embedding(AE)。为了解决此问题,我们借助于预训练。具体而言,在COCO train set,不使用AE loss (即,只有热图损失)训练最大超网,训练了100个epoch。然后,将其作为预训练模型,用于进一步的超网训练。
超网训练设置。 在CrowdPose数据集上执行 one-shot NAS。用不同的训练超参和 search space 训练 LitePose-L/M/S 和 LitePose-XS。设置 batch size=32,对LitePOSE-L/M/S supernet 进行了 800 个 epoch 的训练;设置 batch size=128,对LitePOSE XS supernet 进行了 2400 个epoch的训练。 在每个训练 step 中,从search space 中统一采样架构配置,并用它训练超网 (lr= 0.001 for bs= 32,lr= 0.004 for bs= 128)。
Fine-tuning Setting 调优设置。 在CrowdPose数据集上,我们 fix(固定?) 架构配置,并对模型进行了 batch size=32 的 200 个 epoch 的调整。初始学习率为 1 0 − 3 10^{-3}1 0 −3,在第50和第180个epoch,学习率分别 drop 到1 0 − 4 和 1 0 − 5 10^{−4} 和 10^{−5}1 0 −4 和1 0 −5(对于 bs=128 的情况,线性增加)。在COCO数据集上,采用在 CrowdPose 上训练的超网作为预训练模型。对每个 searched configuration,设置 batch size=32,相应的模型训练 500 个epoch,初始学习率为 1 0 − 3 10^{-3}1 0 −3,在第350和第480个epoch,学习率分别 drop 到1 0 − 4 和 1 0 − 5 10^{−4} 和 10^{−5}1 0 −4 和1 0 −5。
Search Details。 在CrowdPose数据集上执行NAS。在获得搜索到的架构后,直接将其泛化到COCO数据集上,并报告其在两个数据集上的性能。对于 LitePose-L/M/S supernet 训练,从[512,448]中选择分辨率,从[1.0,0.75,0.5] 中选择 channel width ratio。对于 LitePose-XS supernet 训练,从[512,448,384,320,256]中选择分辨率,从[1.0,0.75,0.5,0.25]中选择channel width ratio。
Measurement Details。 在Qualcomm Snapdragon 855 GPU、Raspberry Pi 4B 和 NVIDIA Jetson Nano GPU上测量模型的延迟。对于实际的边缘部署,DL模型能有效集成一些优化的库且运行时作为其后端并生成尽可能快的可执行文件至关重要。因此,我们在 raspberry Pi 4B和NVIDIA Jetson Nano GPU上报告的所有延迟结果都通过 TVM Auto Scheduler 进行了优化,这可以帮助我们更好地模拟真实应用程序的延迟。
5.3. Ablation Experiments
Large Kernels。 如表3和图7所示,7×7 kernel 只增加了很小的计算量,提高了处理尺度变化问题的能力,实现了最佳性能。

表3. 消融实验。0.5 LitePose 指将每个层线性扩展到 LitePose supernet,使其达到50%通道。Knl:内核大小;Fsn:融合反卷积头;Spnt.:Supernet 训练;Dstl:蒸馏。大核和融合反卷积头分别实现+13.0AP 和 +7.6AP 的性能提升。supernet 训练将这两种配置的性能提升了+2.7AP 。架构搜索将手工设计模型的性能提升了+2.2AP。蒸馏将 LitePose-XS 的性能提升了 +1.1AP。
Fusion Deconv Head. 处理尺度变化问题的另一种方法是多分辨率融合,通过引入大分辨率特征来更好地捕捉小尺度人体。表3和图6中显示了定量性能增益:我们的高效融合反卷积头在计算量微增的情况下,将CrowdPose数据集上的性能提高了+7.6AP。
Neural Architecture Search. 神经结构搜索(NAS)从两个方面受益:one-shot 超网训练和调优架构搜索。
; 5.4. Main Results
crowdpose上的结果:

表1. CrowdPose test set 上的结果。Nano, Mobile, 和 Pi 分别代表NVIDIA Jetson Nano GPU, Qualcomm Snapdragon 855 和 Raspberry Pi 4B+。相较于 HigherHRNet,LitePose在移动平台上实现了更好的性能:高达10.4×MACs 的下降和 8.2× 的延迟减少。

图9. 在CrowdPose 上,相较于EfficientHRNet,LitePose实现了2.8×MACs 的减少。LitePose的硬件友好设计允许高并行性,因此在各种移动平台上实现了更低的延迟:在Raspberry Pi 4B+, Qualcomm Snapdragon 855, 和 NVIDIA Jetson Nano上,他分别实现了 5.0×,4.9×, 和 5.0× 的延迟减少。
coco数据集上的结果:

表2. COCOval/test-devset 上的结果。相较于EfficientHRNet,LitePose在提供更好的性能的同时,实现了1.8×MACs 的减少以及高达 2.9× 的延迟减少。相较于轻量级的 OpenPose,它以更低的延迟实现了更高的性能 (+14.0AP)。

图1. 使用Qualcomm Snapdragon 855 ,在COCO数据集上,相较于EfficientHRNet,LitePose 在获得更高的mAP的同时,实现了高达 2.9× 的延迟减少。 相较于轻量级的 OpenPose,在COCO数据集上,LitePose以更低的延迟获得了14% higher mAP。
6. Conclusion
本文研究了边缘多人姿态估计的有效架构设计。本文设计了一个 gradual shrinking 实验来 bridge 多分支和单分支架构。我们的研究表明,对于在低计算区域的模型,高分辨率分支是冗余的。受此启发,我们提出了一种有效的姿态估计架构LitePose,它具有单分支和多分支架构的优点。大量实验验证了 LitePose 的有效性和鲁棒性,为边缘应用的实时人体姿态估计铺平了道路。
Original: https://blog.csdn.net/unauna9739/article/details/125693963
Author: AnZhiJiaShu
Title: Lite Pose: Efficient Architecture Design for 2D Human Pose Estimation 阅读笔记