
1.1 问题描述
定义以下函数:
def exposure_mat(a_embedded, model_expo, N_rays, N_samples_, chunk):
a_embedded_ = repeat(a_embedded, 'n1 c -> (n1 n2) c', n2=N_samples_)
...
调用上述函数时,运行至 a_embedded_ = repeat(a_embedded.numpy(), 'n1 c -> (n1 n2) c', n2=int(N_samples_)),报错 Type Error: unhashable type: 'Dimension'
1.2 解决方法:
网上看到的解决方法都没能解决,然后查询unhashable是什么意思(详见Python异常:unhashable type 是怎么回事?),最后确定原因 N_samples_不是 int类型,转为 int就可以啦。
还有我这里用的 a_embedded是用 tf.get_variable()获得的,需要转化为 numpy。
最后能成功运行的代码为:
def exposure_mat(a_embedded, model_expo, N_rays, N_samples_, chunk):
repeat(a_embedded.numpy(), 'n1 c -> (n1 n2) c', n2=int(N_samples_))
...
2.1 问题描述
tf.concat([rays, rays_o[..., 3]], axis=-1)
其中 rays的shape为:(8192,74)
rays_o[..., 3]的shape为:(8192,)
报错信息为 Ranks of all input tensors should match: shape[0] = [8192,74] vs. shape[1] = [8192] [Op:ConcatV2] name: concat
2.2 问题分析
要拼接的两个 tensor维度不一致,需要对 rays_id进行reshape,采用 tf.reshape 函数
2.3 解决方法
rays_id = tf.reshape(rays_o[..., 3],[rays.shape[0],1])
rays = tf.concat([rays, rays_id], axis=-1)
3.1问题描述
out = rearrange(out, '(n1 n2) c -> n1 n2 c', n1=N_rays, n2=int(N_samples_))
出现报错:
{AttributeError}module 'tensorflow.python.keras.api._v1.keras.backend' has no attribute 'is_keras_te
3.2 解决方法
网上类似的问题说是版本原因,但我有类似的代码是可以运行的。所以猜测是 out数据类型的问题,把 out改为 array(用 out.numpy())后,问题解决,代码如下:
out = rearrange(out.numpy(), '(n1 n2) c -> n1 n2 c', n1=N_rays, n2=int(N_samples_))
4.1 问题描述
运行:
a_embedded = tf.gather(a_embedded, ray_batch[:, -1]))
其中a_embedded是用tf.get_variable()获得的,
出现报错:InvalidArgumentError: Value for attr 'Tindices' of float is not in the list of allowed values: int32, int64 ; NodeDef: {{node ResourceGather}};
4.2 解决方法
用tf.gather时,索引的列表的数据必须是int类型的,所以修改为:
a_embedded = tf.gather(a_embedded, np.array(ray_batch[:, -1]).astype(int))
Original: https://blog.csdn.net/fighterlucky/article/details/124290107
Author: 猪小肥呀
Title: Tensorflow学习(二)——遇到的报错及解决方法
相关阅读1
Title: 虚拟数字人很忙
最近,虚拟数字人有点忙,在直播,品牌营销,企业服务上都看到虚拟数字人身影。虚拟数字人跟元宇宙有什么关系,我们一起来说说。
一、虚拟数字人概念
1、定义
"虚拟数字人"一词最早源于 1989 年美国国立医学图书馆发起的"可视人计划"(Visible Human Project, YHP)。其指存在于非物理世界中,由计算机图形学、图形渲染、动作捕捉、深度学习、语音合成等计算机手段创造及使用,并具有多重人类特征(外貌特征、人类表演能力、人类交互能力等)的综合产物。
- 外貌特征:具有特定的相貌、性别和性格等人物特征
- 人类表演能力:拥有人的行为,具有用语言、面部表情和肢体动作表达的能力
- 人类交互能力:拥有人的思想,具有识别外界环境、并能与人交流互动的能力
"人"是其中的核心的因素,高度拟人化为用户带来的亲切感、关怀感与沉浸感是多数消费者的核心使用动力。能否提供足够自然逼真的相处体验,将成为虚拟数字人在各个场景中取代真人,完成语音交互方式升级的重要标准。
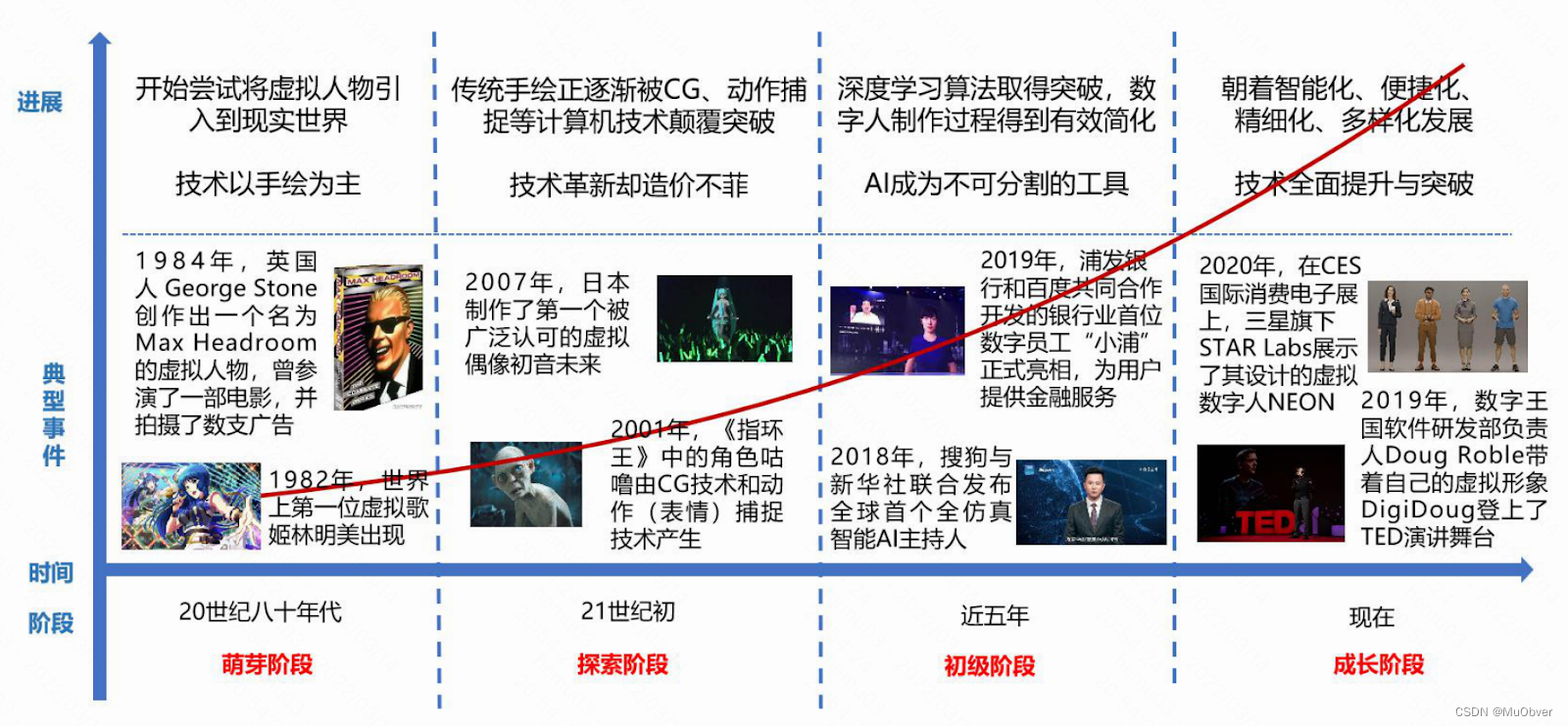
2、发展历程
从最早的手工绘制到现在的 CG(Computer Graphics,电脑绘图)、人工智能合成,虚拟数字人大致经历了萌芽、探索、初级和成长四个阶段。
二、虚拟数字人相关技术
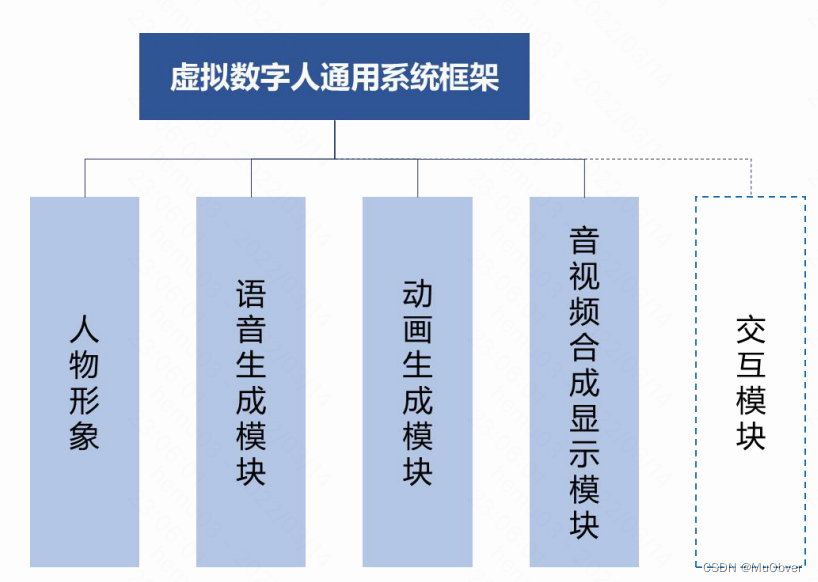
1、虚拟数字人通用系统框架
虚拟数字人系统一般情况下由人物形象、语音生成、动画生成、音视频合成显示、交互等 5 个模块构成。
- 人物形象:根据人物图形资源的维度,可分为 2D 和 3D 两大类,从外形上又可分为卡通、拟人、写实、超写实等风格
- 语音生成模块和动画生成模块:可分别基于文本生成对应的人物语音以及与之相匹配的人物动画
- 音视频合成显示模块:将语音和动画合成视频,再显示给用户
- 交互模块:使数字人具备交互功能,即通过语音语义识别等智能技术识别用户的意图,并根据用户当前意图决定数字人后续的语音和动作,驱动人物开启下一轮交互
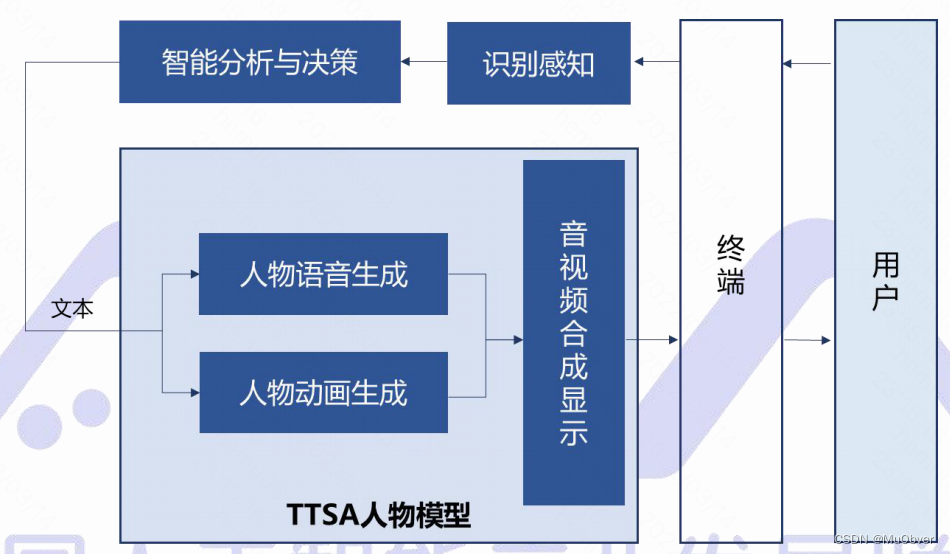
交互模块根据其有无,可将数字人分为交互型数字人和非交互型数字人。
- 非交互型数字人:系统依据目标文本生成对应的人物语音及动画,并合成音视频呈现给用户
- 交互型数字人:根据驱动方式的不同可分为智能驱动型和真人驱动型
- 智能驱动型数字人:该人物模型是预先通过AI技术训练得到可通过文本驱动生成语音和对应动画,业内将此模型称为TTSA(Text To Speech & Animation)人物模型
- 真人驱动型数字人:真人根据视频监控系统传来的用户视频,与用户实时语音,同时通过动作捕捉采集系统将真人的表情、动作呈现在虚拟数字人形象上,从而与用户进行交互
2、三大核心技术
为了实现"拟人化",技术层面主要体现为以下三点:
- CG建模/图像迁移技术:影响外观呈现。体现为虚拟数字人外观的拟人程度
- NLP交互技术:影响交互体验。以对话能力为核心,该技术继续在虚拟数字人中发挥核心作用,可以视作为虚拟数字人的脑
- CV等深度学习模型:影响驱动效果。受数据量、计算框架、关键特征点等因素深刻影响。能否呈现自然的面部表情变动、肢体变动等,在极大程度上取决于语音驱动的深度模型效果
三、虚拟数字人产业应用
1、行业现状
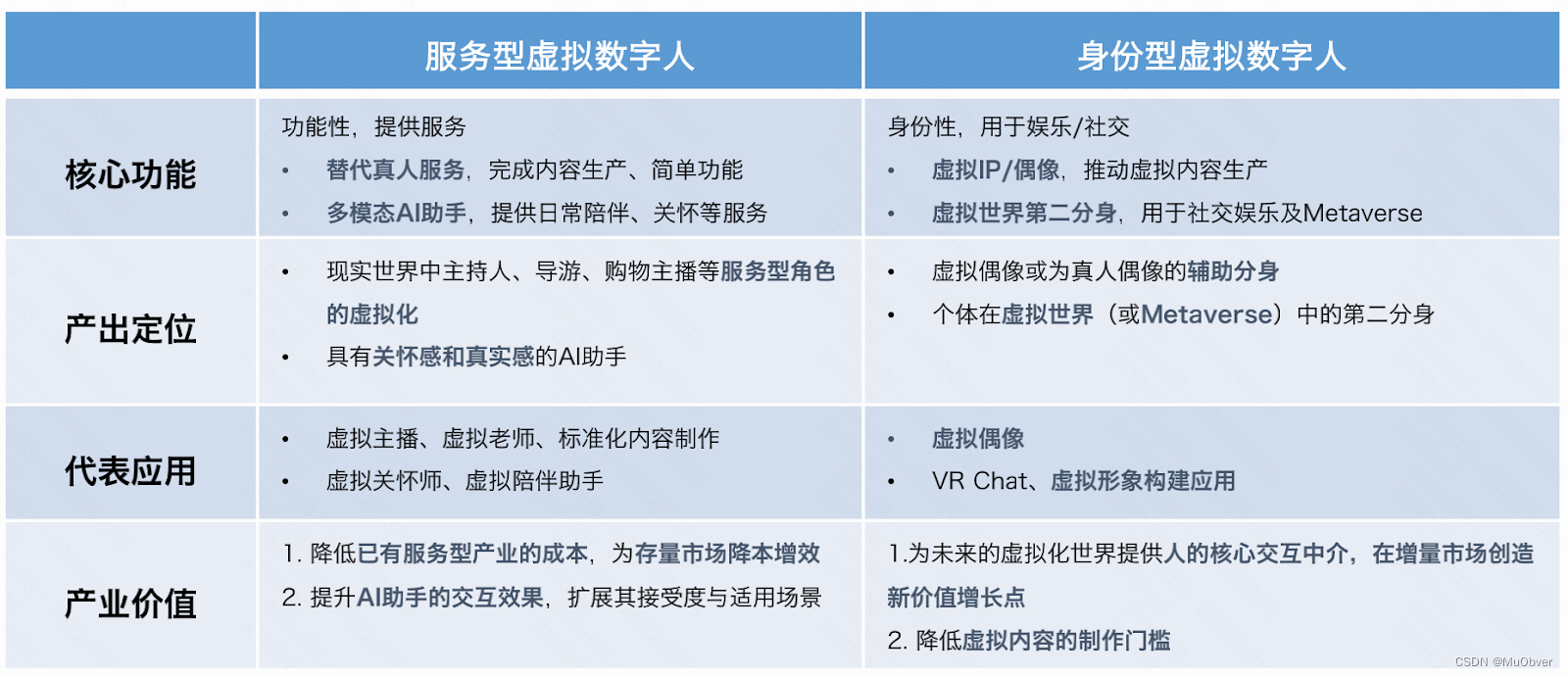
按照产业应用,可以将虚拟数字人划分为两类, 服务型虚拟数字人和 身份型虚拟数字人。"量子位虚拟数字人产业报告"预测,在2030年,我国虚拟数字人整体市场规模将达到2700亿。其中,得益于虚拟IP的巨大潜力,以及虚拟第二分身的起步,身份型虚拟数字人将占据主导地位,约1750亿,并逐步成为Metaverse中的重要一环。服务型虚拟数字人则相对稳定发展,多模态AI助手仍有待进一步发展,多种对话式服务升级至虚拟数字人形态,总规模超过950亿。
2、产业划分
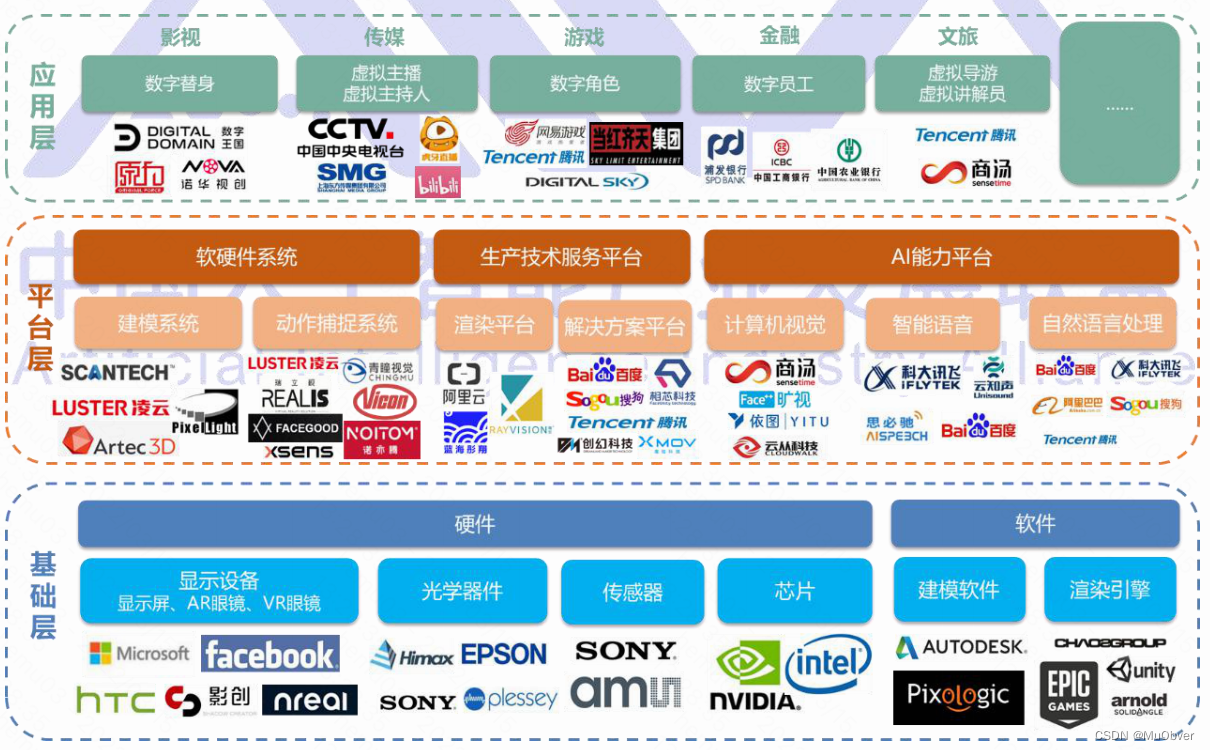
虚拟数字人的产业链从下到上分为基础层、平台层、应用层,下层赋能上层并不断合作形成了多元的商业模式。
- 基础层:为虚拟数字人提供基础软硬件支撑,硬件包括显示设备、光学器件、传感器、芯片等,基础软件包括建模软件、渲染引擎
- 平台层:包括软硬件系统、生产技术服务平台、AI 能力平台,为虚拟数字人的制作及开发提供技术能力
- 应用层:指虚拟数字人技术结合实际应用场景领域,切入各类,形成行业应用解决方案,赋能行业领域
3、虚拟IP应用Case
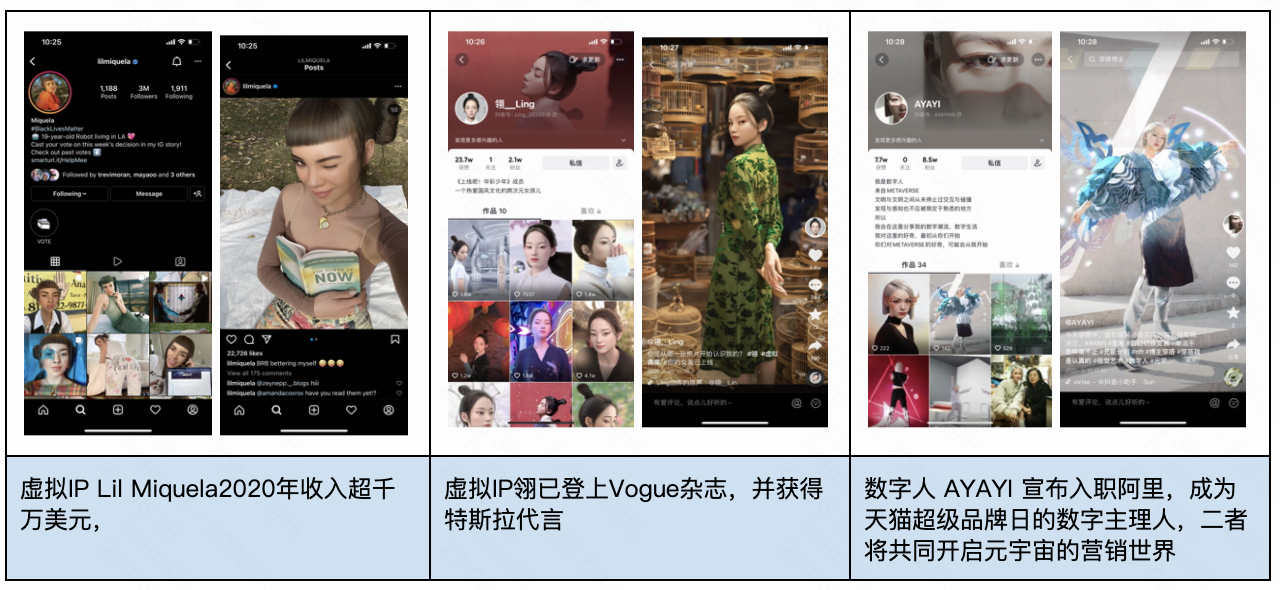
虚拟IP相对于真人IP,解决了MCN对特定IP长期稳定持有的问题,以偶像/网红为核心场景,在直播、代言等领域均有所发展。由于我国的短视频和直播业态正在迅速发展,面对高频、碎片且实时的IP运营需求,虚拟IP更能够适应这一趋势。代言领域,欧莱雅(M姐)、花西子(花西子)已开始有所尝试,通过虚拟IP打造完全符合品牌调性的虚拟代言人。
四、总结
技术是进入行业的核心门槛,需要进入玩家在机器视觉、语音交互和自然语言处理方面都具有深厚的技术积累,并将三者进行有机结合。当前虚拟数字人向自我管理的演化,认知智能、灵活性、个性化、情感化都是虚拟数字人需要进一步提升的技术方面。
尽管技术壁垒增加了商业化成本,但虚拟数字人给元宇宙打开了更大的想象空间。你是否也想拥有一个虚拟数字人呢?
参考文献:
《2020 年虚拟数字人发展白皮书》中国人工智能产业发展联盟总体组,中关村数智人工智能产业联盟数字人工作委员会
《虚拟数字人深度产业报告》量子位
Original: https://blog.csdn.net/MMjoy666/article/details/124697808
Author: MuObver
Title: 虚拟数字人很忙
相关阅读2
Title: 【windows10卸载并重新安装CUDA、cuDNN】,【TensorFlow-CUDA-cuDNN-GPU版本对应】,【cuDNN系统环境变量设置】
目录
2、提前查电脑显卡支持的CUDA版本,便于后续下载对应的CUDA版本
4、tensorflow和CUDA、cuDNN版本型号要匹配
1、卸载之前的旧的或者不匹配的CUDA、cuDNN
图片来源:windows 7 下cuda 9.0 卸载、cuda8.0 安装_shuiyuejihua的博客-CSDN博客
2、提前查电脑显卡支持的CUDA版本,便于后续下载对应的CUDA版本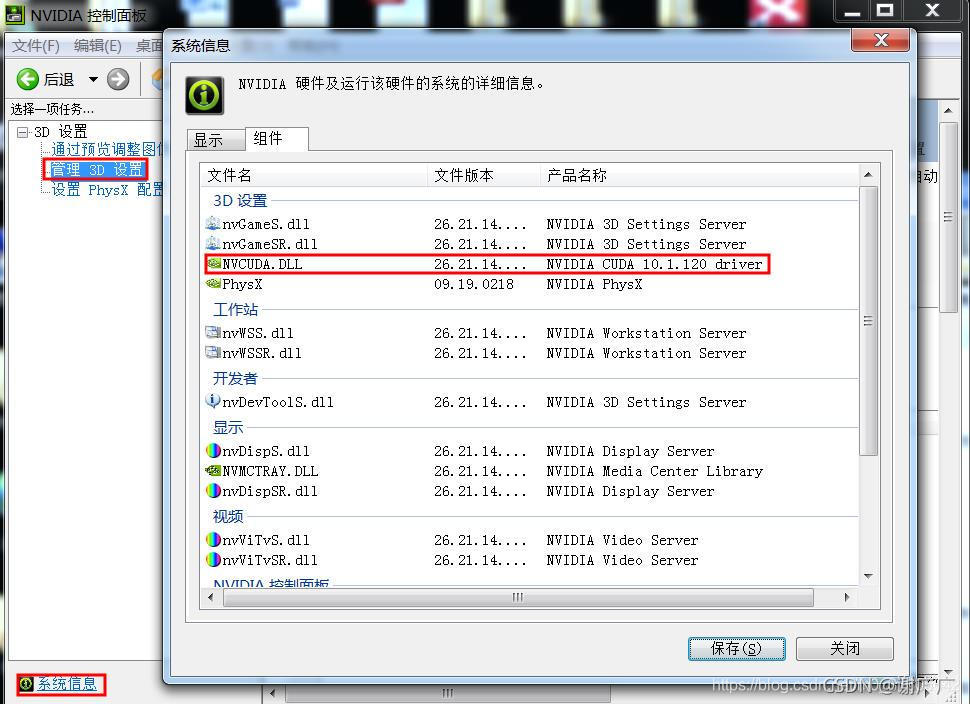
来源:CUDA、CUDNN在windows下的安装及配置_m0_37605642的博客-CSDN博客_cudnn配置
3、下载CUDA、cuDNN
官网下载都是直接下载最新的,自己需要选择
各版本CUDA链接CUDA Toolkit Archive | NVIDIA Developer
各版本cuDNN链接https://developer.nvidia.com/rdp/cudnn-archive
此处参考链接Win10中CUDA、cuDNN的安装与卸载 - 程序员大本营
4、tensorflow和CUDA、cuDNN版本型号要匹配
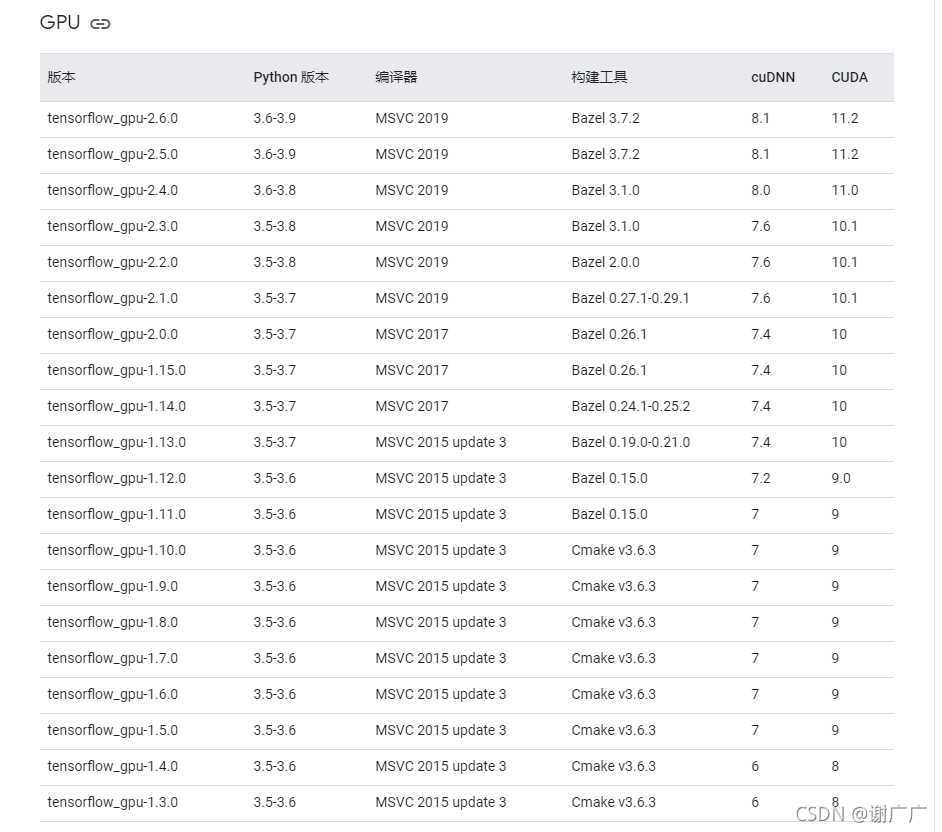
表格来源于官网: 在 Windows 环境中从源代码构建 | TensorFlow
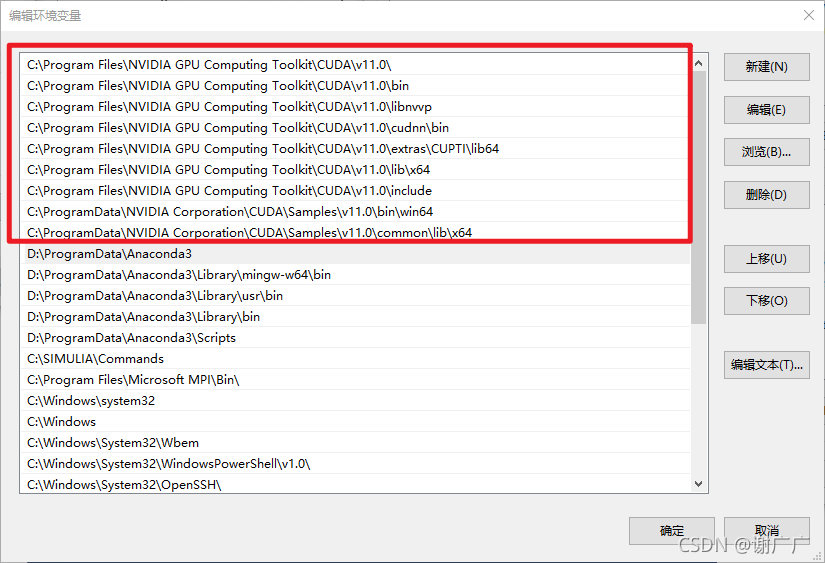
5、配置9条环境路径(默认安装可复制以下代码):
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\libnvvp
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\cudnn\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\extras\CUPTI\libx64
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\lib\x64
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include
C:\ProgramData\NVIDIA Corporation\CUDA\Samples\v11.0bin\win64
C:\ProgramData\NVIDIA Corporation\CUDA\Samples\v11.0\common\lib\x64
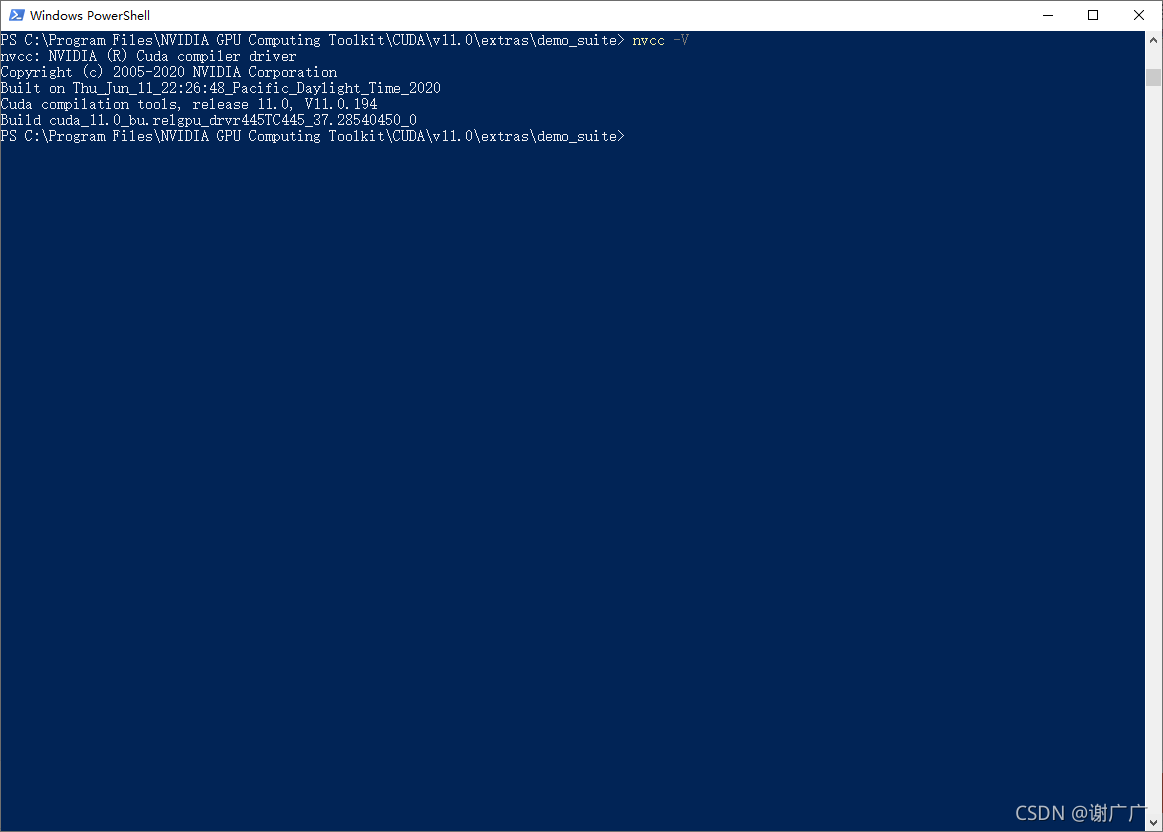
6、检查安装的CUDA版本
powershell或者cmd都可以,两者同为终端,相同功能。在 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\extras\demo_suite路径下打开powershell,需要按住shift,再鼠标右击
nvcc -V
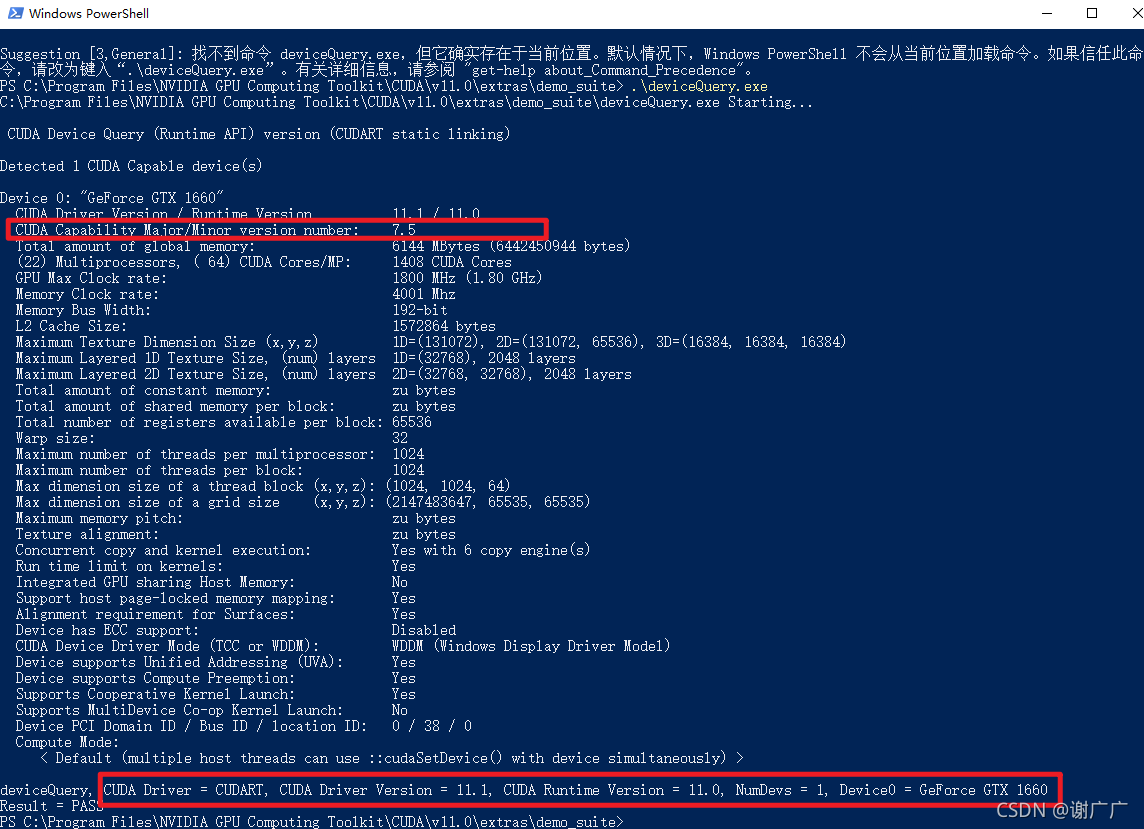
7、查询显卡算力
cd C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\extras\demo_suite
deviceQuery.exe
Original: https://blog.csdn.net/m0_60262754/article/details/121451663
Author: 谢广广
Title: 【windows10卸载并重新安装CUDA、cuDNN】,【TensorFlow-CUDA-cuDNN-GPU版本对应】,【cuDNN系统环境变量设置】
相关阅读3
Title: 数学建模系列笔记6:聚类和判别分析
原理简介:现实中的数学模型可以分为三大类:确定性数学模型、随机性数学模型、模糊性模型,模糊数学正是研究带有模糊性问题的方法,只要定义了隶属函数,有了隶属度,就可以对样本进行模糊识别和模糊聚类。
定义:设R = ( r i j ) n × n R = (r_{ij})_{n\times n}R =(r i j )n ×n 是n阶模糊方阵,I是n阶单位方阵,若R满足:
定理:设R是n阶模糊等价矩阵,则∀ 0 ≤ λ < μ ≤ 1 , R μ \forall 0 \leq \lambda < \mu \leq 1,R_{\mu}∀0 ≤λ<μ≤1 ,R μ所决定的分类中的每一个类是R λ R_{\lambda}R λ所决定的分类中的某个子类。
该定理表明,当λ < μ \lambda < \mu λ<μ时,R μ R_{\mu}R μ的分类是R λ R_{\lambda}R λ分类的加细,当λ \lambda λ由1变到0时,R λ R_{\lambda}R λ的分类由细到粗,形成一个动态的聚类图。
模糊聚类的一般流程
模糊聚类的详细步骤
聚类分析:群分析,它是研究聚类问题的一种多元统计方法。
将相似元素聚为一类,通常选取元素的许多共同指标,然后通过分析元素的指标值来分辨元素间的差距,从而达到聚类的目的。
聚类分析分为Q型(样品聚类)聚类、R型(指标聚类)聚类。
聚类分析步骤:
系统聚类分析聚类数的确定:
对于海量数据,几乎难以实现聚类。 动态聚类法对于容量较大的样本聚类会比较方便。
方法理论简介:
总结与体会
- k均值方法对初始点敏感
-
k均值方法的计算比较耗时
-
模式识别的本质特征:一是事先已知若干标准模式,称为标准模式库;二是有待识别的对象。
- 所谓模糊模式识别,是指在模式识别中,模式是模糊的,或有待识别的对象是模糊的。
模式识别数学原理
最大隶属原则|:设A 1 , A 2 , ... , A m A_1,A_2,...,A_m A 1 ,A 2 ,...,A m 为给定的论域U上的m个模糊模式,x 0 ∈ U x_0 \in U x 0 ∈U为一个待识别对象,若A i ( x 0 ) = m a x { A 1 ( x 0 ) , A 2 ( x 0 ) , ... , A m ( x 0 ) } A_i(x_0) = max{A_1(x_0),A_2(x_0),...,A_m(x_0)}A i (x 0 )=m a x {A 1 (x 0 ),A 2 (x 0 ),...,A m (x 0 )},则认为x 0 x_0 x 0 优先归属于模糊模式A i A_i A i 。
最大隶属原则||:设A为给定论域U上的一个模糊模式,x 1 , x 2 , ... , x n x_1,x_2,...,x_n x 1 ,x 2 ,...,x n 为U中的n个待识别对象,若A ( x i ) = m a x { A ( x 1 ) , A ( x 2 ) , ... , A ( x n ) } A(x_i) = max{A(x_1),A(x_2),...,A(x_n)}A (x i )=m a x {A (x 1 ),A (x 2 ),...,A (x n )},则认为模糊模式A应优先录取x i x_i x i 。
阈值原则:设A 1 , A 2 , ... , A m A_1,A_2,...,A_m A 1 ,A 2 ,...,A m 为给定论域U上的m个模糊模式,规定一个阈值λ ∈ [ 0 , 1 ] , x 0 ∈ U \lambda \in [0,1],x_0 \in U λ∈[0 ,1 ],x 0 ∈U为一个待识别对象。
择近原则:
贴近度:σ ( A , B ) \sigma(A,B)σ(A ,B )表示两个模糊集A,B之间的贴近程度
格贴近度:σ 0 ( A , B ) = 1 2 [ A ∘ B ] + ( 1 − A ⊙ B ) ] \sigma_0(A,B) = \frac{1}{2}[A\circ B] + (1-A\odot B)]σ0 (A ,B )=2 1 [A ∘B ]+(1 −A ⊙B )]
其中:A ∘ B = m a x { A ( x ) ∧ B ( x ) } A\circ B = max{A(x) \wedge B(x) }A ∘B =m a x {A (x )∧B (x )}表示两个模糊集A,B的内积
A ⊙ B = m i n { A ( x ) ∨ B ( x ) } A\odot B = min {A(x) \vee B(x)}A ⊙B =m i n {A (x )∨B (x )}表示两个模糊集A,B的外积
定义(公理化定义)若(A,B)满足
模糊模式识别可以广泛被运用到模糊识别的各个方面,使用时最基本的是要建立评价模式和被评价对象的恰当指标,其次才是运用各类识别原则,对被评价对象进行模式识别。
为了能识别待判断的对象x = ( x 1 , x 2 , ... , x m ) T x= (x_1,x_2,...,x_m)^T x =(x 1 ,x 2 ,...,x m )T是属于已知类A 1 , A 2 , ... , A r A_1,A_2,...,A_r A 1 ,A 2 ,...,A r 中的哪一类,需要有一个一般规则做出判断,这样一个规则为 判别规则(用于衡量待判别对象与各已知类别接近程度的方法准则)
判别分析的假设条件:
方法理论简介:
假设对所研究的对象有了一定的认识,重新计算样品属于各总体的条件概率:
f ( g ∣ x ) ( g = 1 , 2 , ... , k ) f(g|x) (g=1,2,...,k)f (g ∣x )(g =1 ,2 ,...,k )
比较这k各概率大小,然后将新样本判归为来自后验概率最大的总体。
Bayes判别法的基本思想
在观测一个样品x的情况下,可用Bayes公式计算它来自第g总体的后验概率
p ( g ∣ x ) = q j f j ( x ) ∑ i = 1 k q j f j , j = 1 , 2 , ... , k p(g|x) = \frac{q_j f_j(x)}{\sum_{i=1}^k q_j f_j},j = 1,2,...,k p (g ∣x )=∑i =1 k q j f j q j f j (x ),j =1 ,2 ,...,k
在得到样本后,首先可以根据样本信息修正之前所获得的先验概率分布,进一步获得后验概率分布,之后可以通过新的后验概率分布进行各种统计推断。
一种好的判别方法,一定要考虑到每个总体出现的先验概率,同时能够对误判所出现的损失进行评估。贝叶斯判别法就具备上述优点。
样本空间的划分
定义:设S为试验E的样本空间,B 1 , B 2 , ... , B n B_1,B_2,...,B_n B 1 ,B 2 ,...,B n 为E的一组事件,若
全概率公式
试验E的样本空间为S,A为E的事件,B 1 , B 2 , ... , B n B_1,B_2,...,B_n B 1 ,B 2 ,...,B n 为S的一个划分,且P ( B i ) > 0 ( i = 1 , 2 , ... , n ) P(B_i)>0(i=1,2,...,n)P (B i )>0 (i =1 ,2 ,...,n ),则
P ( A ) = ∑ i = 1 n P ( A ∣ B i ) P ( B i ) P(A) = \sum_{i=1}^n P(A|B_i)P(B_i)P (A )=i =1 ∑n P (A ∣B i )P (B i )
贝叶斯公式
P ( B i ∣ A ) = P ( B i A ) P ( A ) = P ( A ∣ B i ) P ( B i ) ∑ j = 1 n P ( A ∣ B j ) P ( B j ) , i = 1 , 2 , ... , n P(B_i|A) = \frac{P(B_iA)}{P(A)} = \frac{P(A|B_i)P(B_i)}{\sum_{j=1}^n P(A|B_j)P(B_j)},i = 1,2,...,n P (B i ∣A )=P (A )P (B i A )=∑j =1 n P (A ∣B j )P (B j )P (A ∣B i )P (B i ),i =1 ,2 ,...,n
贝叶斯判别的理论基础
G 1 , G 2 — p G_1,G_2—p G 1 ,G 2 —p维总体,密度f ( x ) , f 2 ( x ) f_(x),f_2(x)f (x ),f 2 (x ),各总体先验概率p 1 = P ( G 1 ) , p 2 = P ( G 2 ) , p 1 + p 2 = 1. p_1 = P(G_1),p_2 = P(G_2),p_1 + p_2 = 1.p 1 =P (G 1 ),p 2 =P (G 2 ),p 1 +p 2 =1 .
样品x = ( x 1 , x 2 , ... , x p ) T x = (x_1,x_2,...,x_p)^T x =(x 1 ,x 2 ,...,x p )T属于G1,G2的后验概率为
P ( G 1 ∣ x ) = p 1 f 1 ( x ) p 1 f 1 ( x ) + p 2 f 2 ( x ) , P ( G 2 ∣ x ) = p 2 f 2 ( x ) p 1 f 1 ( x ) + p 2 f 2 ( x ) P(G_1|x) = \frac{p_1 f_1(x)}{p_1f_1(x)+p_2f_2(x)},P(G_2|x) = \frac{p_2 f_2(x)}{p_1f_1(x)+p_2f_2(x)}P (G 1 ∣x )=p 1 f 1 (x )+p 2 f 2 (x )p 1 f 1 (x ),P (G 2 ∣x )=p 1 f 1 (x )+p 2 f 2 (x )p 2 f 2 (x )
两个总体的Bayes判别准则
x ∈ G 1 , P ( G 1 ∣ x ) ≥ P ( G 2 ∣ x ) p 1 f 1 ( x ) ≥ p 2 f 2 ( x ) x ∈ G 2 , P ( G 1 ∣ x ) < P ( G 2 ∣ x ) p 1 f 1 ( x ) < p 2 f 2 ( x ) x \in G_1,P(G_1|x)\geq P(G_2|x) p_1f_1(x)\geq p_2f_2(x)\ x \in G_2,P(G_1|x)< P(G_2|x) p_1f_1(x)< p_2f_2(x)x ∈G 1 ,P (G 1 ∣x )≥P (G 2 ∣x )p 1 f 1 (x )≥p 2 f 2 (x )x ∈G 2 ,P (G 1 ∣x )<P (G 2 ∣x )p 1 f 1 (x )<p 2 f 2 (x )
Original: https://blog.csdn.net/weixin_46530492/article/details/122663501
Author: Cachel wood
Title: 数学建模系列笔记6:聚类和判别分析