
先上图
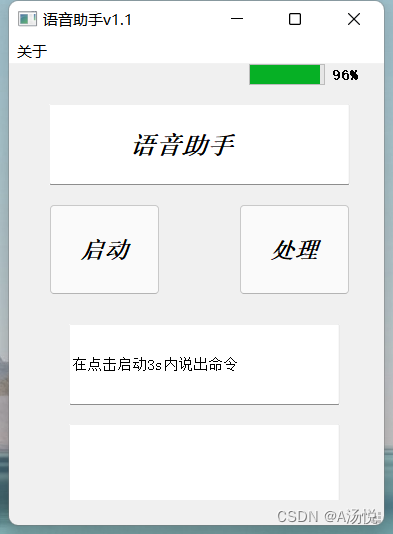
本程序使用的软件:
PyCharm,Designer(PyQt5界面编辑软件)
步骤
1.使用designer绘制出程序界面的图
使用的控件:
按键

文本框
Line Edit

电量显示
Priogress Bar
这里是装饰的一个作用
布局好了以后可以自己调节各个控件字体的样式,点击你需要调整的控件,在designer的右边的属性编辑器选择。
字体:
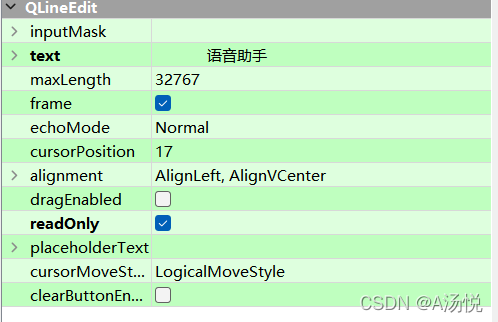
这里我将第一个文本显示改成了只读形式:
布局完成后保存到文件夹里,是一个ui文件,之后需要打开cmd,通过cd指令进入到ui文件所在的文件夹里,使用ui转py文件的指令,其中name是文件的名字
pyuic5 -o name.py name.ui
之后用pycharm打开生成的py文件,在文件夹内新建一个main程序,实现ui与程序的分离
代码如下,其中ty包是我生成的py文件
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow
import ty
if __name__ == '__main__':
app = QApplication(sys.argv)
MainWindow = QMainWindow()
ui = ty.Ui_mainWindow()
ui.setupUi(MainWindow)
MainWindow.show()
sys.exit(app.exec_())
这时运行程序可以看到界面显示出来。
1.在main程序下定义一个录音的函数
程序如下,dir_name是你的项目所在路径
def rec():
dir_name = 'D:\\xun\\'
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 14400
RECORD_SECONDS = 3.5
file_name = "123.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(dir_name + file_name, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
ui.lineEdit_2.setText("我已经听到了,请点击处理按键")
录音函数定义好以后将第一个按键与该函数绑定起来,注意这里绑定的函数不需要括号。
MainWindow.show()后加上
ui.pushButton.clicked.connect(partial(rec))
2.语音识别技术由百度AI提供网址在这
登录以后找到控制台,找到语音技术的模块,创建一个新应用,之后可以看到这个新应用的AppID,API Key,Secret Key
在此图的右下角有领取免费资源,点进去领取短语音识别,领完后大概半小时就能够使用。
创建应用完成后,在python程序里安装baidu-aip的包,
在main程序下定义一个函数,第7行里的是你的录音文件的路径和一个读取文件的函数
def make():
APP_ID = '你的id'
API_KEY = '你的key'
SECRET_KEY = '你的secret key'
aipSpeech = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
q=aipSpeech.asr(get_file_content('D:\\xun\\123.wav'), 'wav', 16000, {'dev_pid': 1537,})
if q.get('result'):
ui.lineEdit_2.setText(q.get('result')[0])
fun(q)
定义读取文件函数
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
make()函数与第二个按键绑定
ui.pushButton_2.clicked.connect(partial(make))
3.接下来需要一个根据处理出来的内容来判断执行什么样的操作的函数,此部分为def fun(q)。
其中ui.lineEdit_3.setText是文本控件的显示函数。
if q.get('result')[0]=='你好。':
ui.lineEdit_3.setText("你好,很高兴为您服务。")
elif q.get('result')[0]=='打开QQ。':
ui.lineEdit_3.setText("正在为您打开QQ。")
auto.open_app_qq()
elif q.get('result')[0] == '播放音乐。':
ui.lineEdit_3.setText('爱了吗?')
auto.music()
elif q.get('result')[0] == '':
ui.lineEdit_3.setText("可能是声音太小。")
else:
ui.lineEdit_3.setText("我还不明白你说的。")
4.这里我重新写了个库auto,用来存放一些功能的函数,如果要打开qq,需要找到qq的exe文件的路径,使用os库的命令来打开,其他同理
import os
def open_app_qq():
dir1 = r'D:\Program Files\Tencent\QQ\Bin\QQScLauncher.exe'
os.startfile(dir1)
def music():
dir2=r'"D:\xun\music.mp3"'
os.startfile(dir4)
整体代码如下:各个函数里面我就没添加进来,上面都有。
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow
from functools import partial
import ty
from aip import AipSpeech
import pyaudio
import wave
import auto
def fun(q):
def rec():
def make():
def get_file_content(filePath):
if __name__ == '__main__':
app = QApplication(sys.argv)
MainWindow = QMainWindow()
ui = ty.Ui_mainWindow()
ui.setupUi(MainWindow)
MainWindow.show()
ui.pushButton.clicked.connect(partial(rec))
ui.pushButton_2.clicked.connect(partial(make))
sys.exit(app.exec_())
运行以后点击启动按键,对麦克风说话,给出提示后点击处理就能执行你所说的功能了。
Original: https://blog.csdn.net/euygnat/article/details/123292863
Author: A汤悦
Title: python简易语音助手
相关阅读1
Title: GCN学习笔记
Modeling Relational Data with Graph Convolutional Networks论文学习笔记1
论文链接:Modeling Relational Data with Graph Convolutional Networks
GitHub链接:Graph Convolutional Networks for relational graphs
摘要
1.文章介绍并应用 关系图卷积神经网络(R-GCN)来解决2个标准的知识库完善工作: 链路预测(通过已知的网络节点和网络结构预测还未产生连边的两个节点产生链接的可能性)和 实体分类(恢复缺失的实体属性)。
2.R-GCN将神经网络应用于图,并用来处理具有多种关系数据特点的真实知识库。
3.文章证明了R-GCN模型用于实体分类的出色的有效性;进一步表明进行链路预测时,因素分解模型(factorization model)(e.g. DistMult)的效能可以通过使用编码器模型(encoder model)提高。
1. 介绍
预测知识库中的缺失信息是 统计关系学习(statistical relational learning,SRL)的主要焦点。根据之前有关SRL的工作,假设知识库存储(subject, predicate, object)三元组形式的知识。例如三元组 (Mikhail Baryshnikov, educated at, Vaganova Academy),Mikhail Baryshnikov和Vaganova Academy是实体,educated at是关系。此外,假设实体以type为标签(e.g. Vaganova Academy is marked as a university),可以通过图1的方式对知识库进行展示。

SRL的链路预测和实体分类中,许多缺失的信息会驻留在通过邻域结构编码的图形中。例如,知道 Mikhail Baryshnikov was educated at the Vaganova Academy,则意味着 _Mikhail Baryshnikov_的标签是人,并且三元组(Mikhail Baryshnikov, lived in, Russia) 也一定属于这个知识图谱。按照这种直觉,文章为关系图中的实体开发了编码器模型并应用于两种任务中。
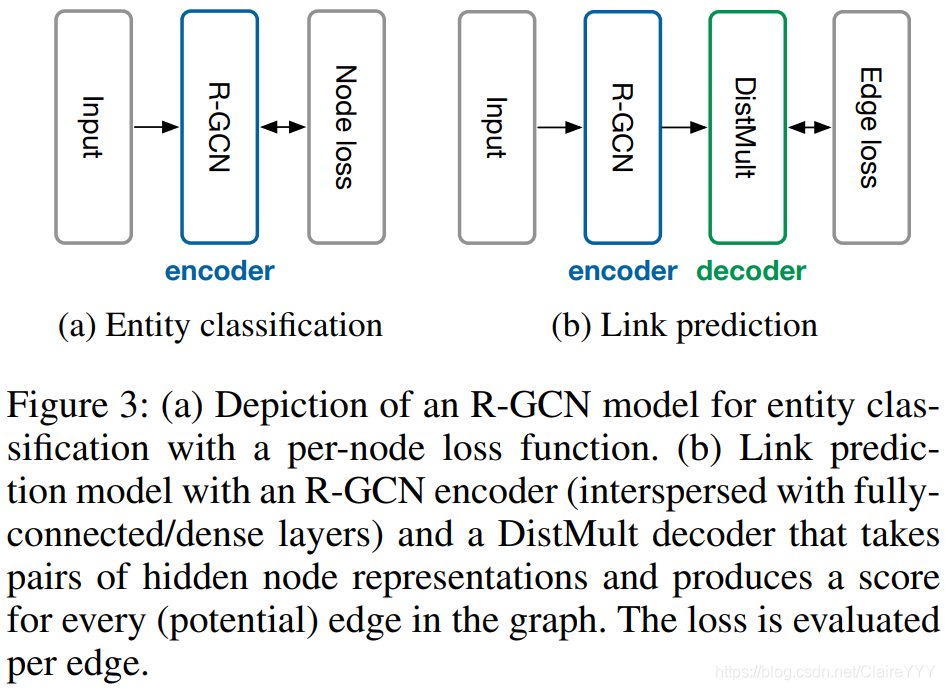
1.实体分类模型:于图中的每个节点使用softmax分类器,分类器采用R-GCN提供的节点形式并且进行标签预测。该模型通过优化交叉熵损失(cross-entropy loss)进行学习,包括R-GCN参数。
2.链路预测模型:可被看作自动编码器,包括(1)编码器:由R-GCN产生的实体的潜在特征表示;(2)解码器:张量因素分解模型(tensor factorization model)——DistMult (Yang et al. 2014),利用这些特征表示预测带标签的边。
文章优势:1.表明GCN框架可被用来为关系型数据建模(特别是链路预测、实体分类);2.提出参数共享和实施稀疏性约束的技术,并将R-GCN应用于含有大量关系的多图中;3.表明分解模型(e.g.DistMult)的性能可以通过执行关系图中多个信息传播的步骤的编码器模型进行提升。
; 2. 神经关系模型
符号:有向的有标签的多图 G=(V, E, R)
节点(实体) v_i _i i ∈ ∈∈ _V,有标记的边(关系) (v i _i i , r, v j _j j )∈ ∈∈ E,边的类型 r∈ ∈∈ R。
2.1 关系图卷积神经网络
R-GCN层与层之间的传播方式:
h i i i ( l + 1 ) ^{(l+1)}(l +1 )=σ σσ(∑ ∑∑r ∈ R {r∈R}r ∈R ∑ ∑∑j j j ∈ ∈∈N i r {N_i^r}N i r 1 c i , r \frac{1}{c{i,r}}c i ,r 1 W r _r r ( l ) ^{(l)}(l )h j _j j ( l ) ^{(l)}(l )+W 0 _0 0 ( l ) ^{(l)}(l )h i _i i ( l ) ^{(l)}(l )) (1)
N i r {N_i^r}N i r :关系r∈R下节点i的邻域索引集
c i , r {i,r}i ,r :特定于问题的归一化常数。可以通过学习得到或事先选择(例如c i , r {i,r}i ,r =∣ N i r ∣ \lvert {N_i^r} \rvert ∣N i r ∣)
R-GCN模型中单个节点更新的计算图如图2:
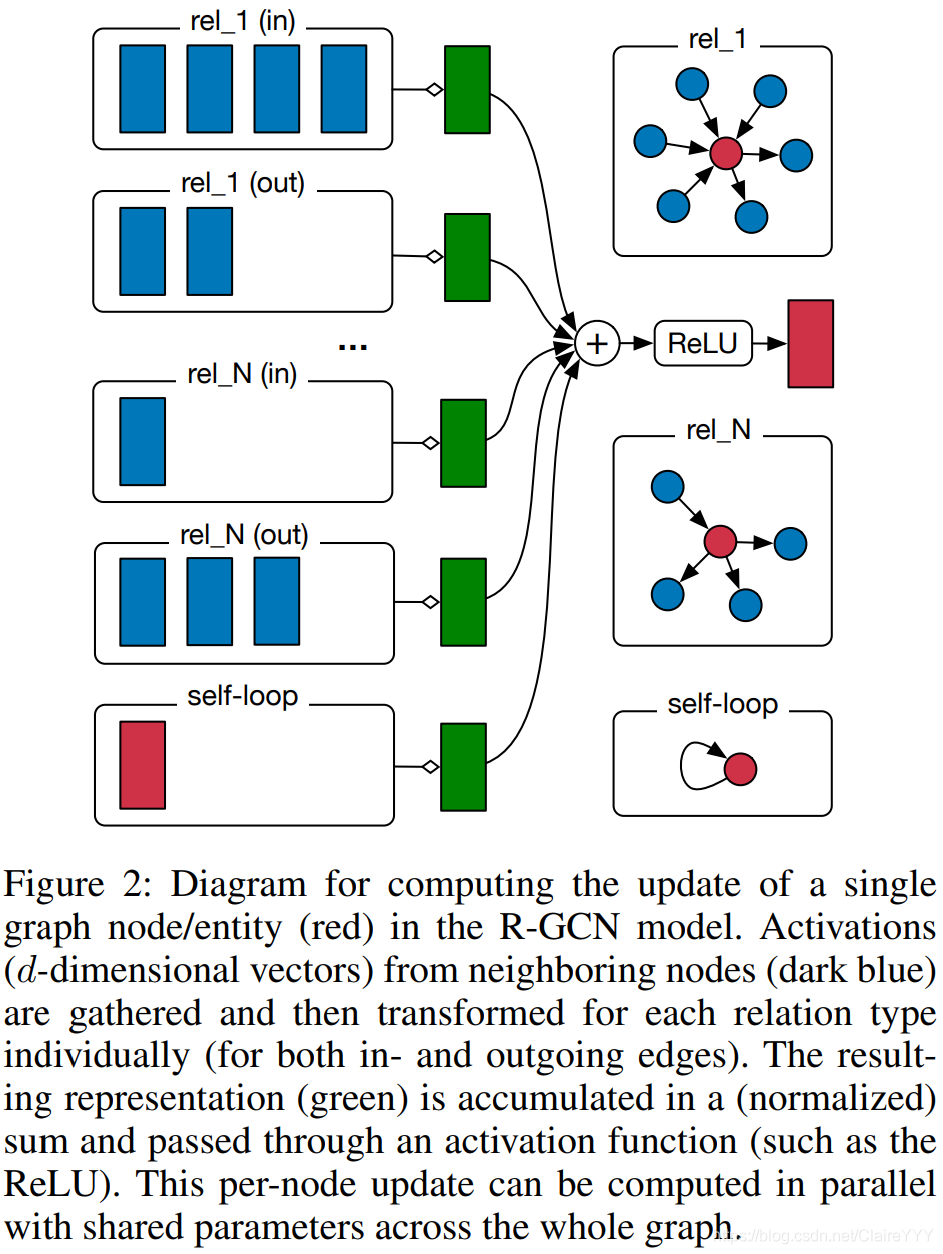
- 图2:R-GCN模型对图中的节点或实体(红色)进行计算更新隐含表示的示意图;
- 对每个节点引入了一个特殊的关系类型:自连接;
- 深蓝色表示来自于邻居节点激活的特征(d维向量)
- rel_N(in/out)不同关系类型in和out两种类型的边
- 每个节点的更新可以用整个图中的共享参数并行计算
特点:在GCN中引入特定关系的转换(i.e.依赖边的类型和方向)。为了确保l l l+1层节点的表现能在l l l层有相应表现,给每个节点增加一个特殊关系类型的单独的自连接。
注意:这里应用的是 简单线性的信息转换,以后可使用更灵活的方程。神经网络层更新包含了对图中的每个节点同时评估公式(1),实际操作中可使用 稀疏矩阵乘法( sparse matrix multiplications)来避免对邻域进行显式求和。
; 2.2 正则化
公式(1)应用于多关系数据的核心问题是,随着图中关系数量的增长参数数量也快速增长,这很容易对稀有关系和大样本量模型过度拟合。
为解决这一问题,引入两个独立的方法对R-GCN层的权重进行正则化:基函数分解和块对角分解(两种方法都能减少关系非常多的数据在训练中需要学习的参数,因为高频和低频关系共享更新的参数)。
基函数分解(basis decomposition):
W r ( l ) r^{(l)}r (l )=∑ ∑∑b = 1 B {b=1}^B b =1 B a r b ( l ) _{rb}^{(l)}r b (l )V b ( l ) _b^{(l)}b (l ) (2)
- 其实就是基转换V b ( l ) b^{(l)}b (l )∈R d ( l + 1 ) × d ( l ) \mathbb{R}^{d^{(l+1)}×d^{(l)}}R d (l +1 )×d (l )和系数a r b ( l ) {rb}^{(l)}r b (l )的线性组合,只有系数a r b ( l ) _{rb}^{(l)}r b (l )依赖于r。
- 基函数分解可被看作不同关系类型之间有效权重共享的一种形式。
块对角分解(block-diagonal decomposition):
W r ( l ) r^{(l)}r (l )=⊕ b = 1 B ⊕{b=1}^B ⊕b =1 B Q b r ( l ) _{br}^{(l)}b r (l ) (3)
- W r ( l ) r^{(l)}r (l ):一系列低维矩阵的直接求和。其为块对角矩阵:diag(Q 1 r ( l ) {1r}^{(l)}1 r (l ),...,Q B r ( l ) {Br}^{(l)}B r (l )),Q b r ( l ) {br}^{(l)}b r (l )∈R ( d ( l + 1 ) / B ) × ( d ( l ) / B ) \mathbb{R}^{(d^{(l+1)}/B)×(d^{(l)}/B)}R (d (l +1 )/B )×(d (l )/B )
- 块对角分解可看作是对每个关系类型在权重矩阵上的稀疏约束
总体的R-GCN模型采用如下形式:
- 按照公式(1)对L L L层进行堆叠。
- 如果不存在其他特征,则可以将第一层的输入选择为图中每个节点的唯一独热向量(one-hot vector)。对于块表示,通过单个线性变换将这个独热向量映射为密度表示。(仅在此文中考虑这种无特征方法)
3. 实体分类
对于节点(实体)的(半)监督分类,简单地堆叠公式(1)的R-GCN层,最后一层的输出对每个节点使用softmax(·)激活。对所有有标签的节点(忽略无标签节点)最小化交叉熵损失函数(cross-entropy loss):
L \mathcal{L}L=-∑ i ∈ Y ∑{i∈Y}∑i ∈Y ∑ k = 1 K ∑{k=1}^{K}∑k =1 K t i k {ik}i k ln h i k ( L ) {ik}^{(L)}i k (L ) (4)
- Y:有标签的节点的索引集;
- h i k ( L ) _{ik}^{(L)}i k (L ) :网络输出第i个有标签节点的第k个条目;
- t i k _{ik}i k :节点各自的ground truth标签。
- 使用(full-batch)gradient descent
; 4. 链接预测
目的:预测新的三元组(subject, relation, object)
任务:给可能的边 (s, r, o)指定分数f(s, r, o),来判断这些边属于E的可能性。
方法:
引入 图自动编码模型(graph
auto-encoder model):包含实体编码器和评分函数(解码器)
- 编码器:把每个实体v i ∈ _i∈i ∈V映射到真值向量e i ∈ _i∈i ∈R d \mathbb{R}^d R d
- 解码器:通过顶点表示重建图的边。i.e. 通过函数s s s:R d \mathbb{R}^d R d×R R R×R d \mathbb{R}^d R d→R \mathbb{R}R 对三元组评分。
大部分之前的方法是在训练时对每个节点v i ∈ _i∈i ∈V使用一个真值向量e i _i i 进行优化,但本文使用R-GCN编码器通过e i _i i =h i ( L ) _i^{(L)}i (L )来计算节点表示。
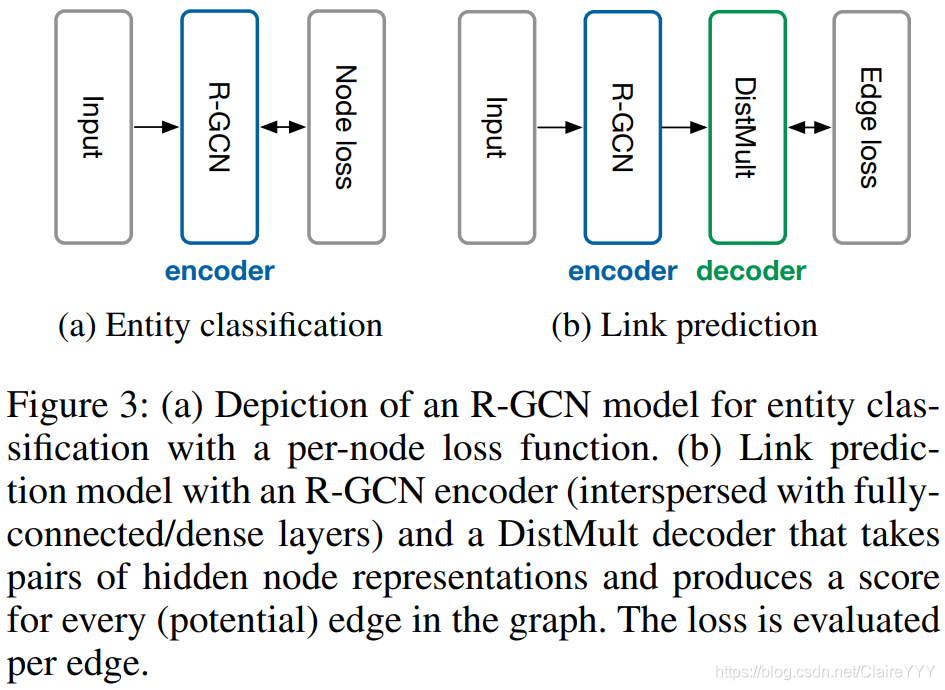
- 本文使用的评分函数(解码器):DistMult 因数分解。
在DistMult中,每个关系r都和一个对角线矩阵R r ∈ r∈r ∈R d × d \mathbb{R}^{d×d}R d ×d有关;三元组(s , r , o s,r,o s ,r ,o)评分为:
f ( s , r , o ) f(s,r,o)f (s ,r ,o )=e s T R r e o e_s^TR_re_o e s T R r e o (5)
采用负采样训练模型——对每个观测到的样本,抽取w w w个负样本。通过随机破环每个正样本的subject或object进行采样。
针对交叉熵损失进行了优化,以使模型的可观测三元组得分高于负三元组:
L \mathcal{L}L=-1 ( 1 + w ) ∣ E ^ ∣ \frac{1}{(1+w)|\widehat{E}|}(1 +w )∣E ∣1 ∑ ( s , r , o , y ) ∈ T ∑{(s,r,o,y)∈T}∑(s ,r ,o ,y )∈T y l o g l ( f ( s , r , o ) ) y log l(f(s,r,o))y l o g l (f (s ,r ,o ))+( 1 − y ) l o g ( 1 − l ( f ( s , r , o ) ) ) (1-y) log (1-l(f(s,r,o)))(1 −y )l o g (1 −l (f (s ,r ,o )))$ (6)
T T T:real and corrupted 三元组的集合
l l l:logistic sigmoid function
y y y:indicator集合,y y y=1表示正三元组,y y y=0表示负三元组
内容过长,剩余部分请查看Modeling Relational Data with Graph Convolutional Networks论文学习笔记2
Original: https://blog.csdn.net/ClaireYYY/article/details/111225902
Author: ClaireYYY
Title: GCN学习笔记
相关阅读2
Title: Kaldi语音识别:基于aidatatang模型实现自制语音数据的识别
aidatatang简介及相关安装、配置等见上一篇文章:Kaldi语音识别:aidatatang_asr开源模型实现中文语音识别详细及遇到的问题【亲自跑通】
一、面临的问题
用CVTE提供的测试集试验跑通了aidatatang后,需要根据自己的需求来确定问题。
1.1 模型运行后测试结果的文本覆盖问题
问题描述:
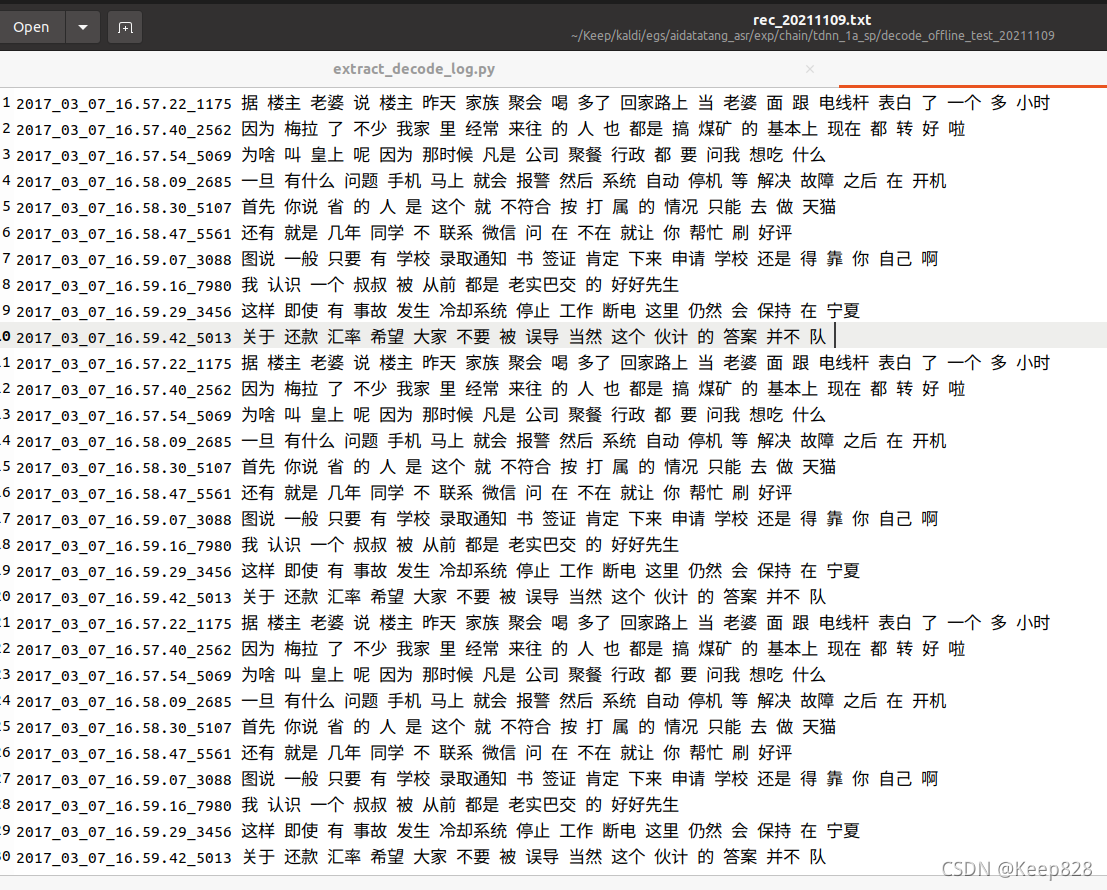
如果不对项目文件作修改,每次跑模型都会在同一个输出文本文件中以'a'的方式写入新的识别结果,它并不会每次运行自动清空Result里的文本,这样看起来会比较乱,如下:
问题解决:
找到写result的python文件,路径 /home/keep/Keep/kaldi/egs/aidatatang_asr/local/extract_decode_log.py,将下面的代码添加到第9行至第10行之间。
with open(outfile, 'w') as n:
n.write("")
即:
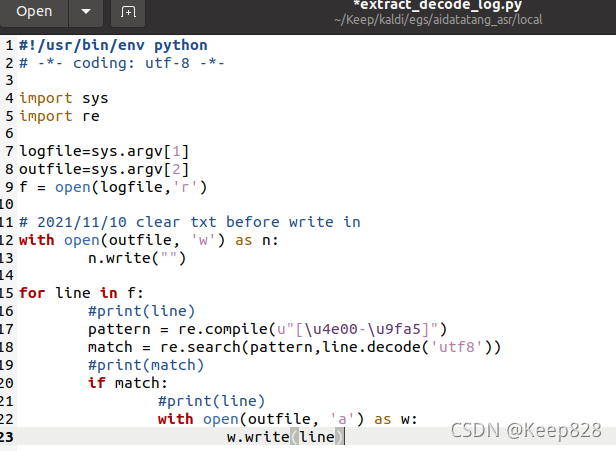
这样就实现了每次运行都会自动清空result中的文本。
1.2更换WAVPath中数据后的识别结果没有更新
问题描述:
在运行完一次识别任务后,识别结果会放在指定的路径中的名为rec_2021xxxx.txt(xxx表示日期)文本文件中。更改WAVpath中的需识别的测试数据集.wav后,在第二次以及之后运行识别任务不会更改之前的识别内容,即,模型仍然将之前加载进来的测试数据作为需要识别的任务进行识别并输出。
问题解决:
待补充
二、制作自己的语音数据作输入
这里用sox工具来制作.wav数据,语音文件原格式是通过iPhone录音录制的.m4a格式。
SoX 可以读取和写入常见格式的音频文件,并在此过程中选择性的加入一些声音效果。它可以组合多个输入源及合成音效,在许多系统上也可以作为音频播放器或多轨录音机使用。
SoX 工具在大部分 Linux 系统上都可以直接通过软件包管理器安装(如sudo apt-get install sox),Mac 系统上则可以使用 brew install sox命令。
这里使用Sox转换m4a的指令后出现
sox FAIL formats: no handler for file extension `m4a'
查阅了相关资料,发现其他人说sox不能转m4a格式
avconv -i xx.m4a xx.wav
暂时用一个在线网页版转换代替:在线转音频格式
搞到了待检测语音文件16bit,16000hz的.wav文件,将其放置在WAVpath文件夹中。
sox工具的相关使用感谢:https://blog.csdn.net/qq_39516859/article/details/87980189
三、运行识别任务
在 aidatatang_asr/中键入 ./run.sh WAVpath命令后,开始识别任务。
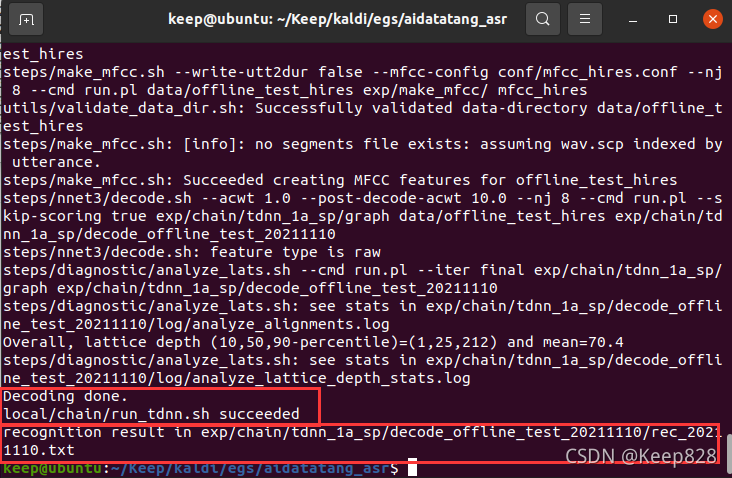
经过了大约8~9分钟的等待(有点久,还不知道为啥),识别完毕,结果放置在目录 exp/chain/tdnn_1a_sp/decode_offline_test_20211110/rec_20211110.txt
内
查看识别结果:
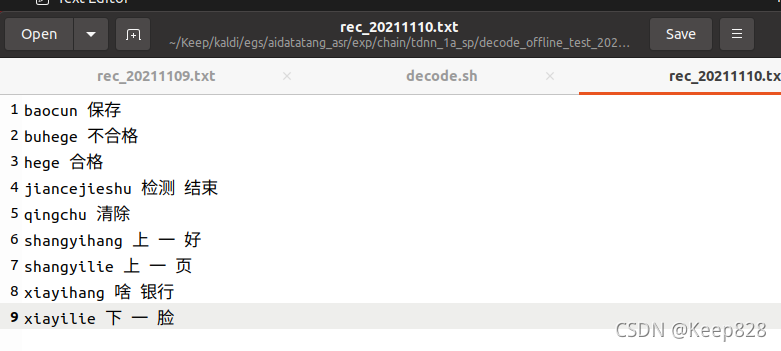
前面的拼音对应的就是答案标签,录制环境是在略微嘈杂的实验室内(身边同学恰好在讨论问题),识别正确率76%。
Original: https://blog.csdn.net/Ryan0828/article/details/121249698
Author: Keep828
Title: Kaldi语音识别:基于aidatatang模型实现自制语音数据的识别
相关阅读3
Title: 关于聚类问题的算法python代码实现-K-均值聚类方法
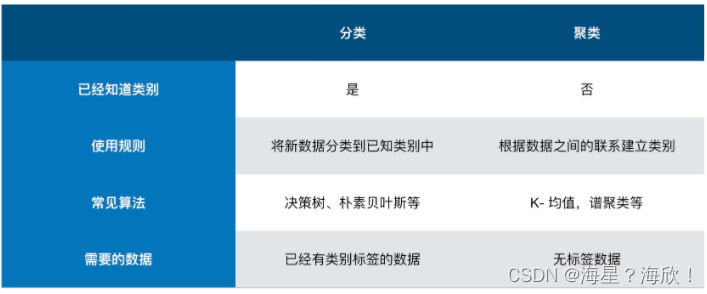
聚类含义
定义:聚类,也叫做聚类分析,依据对象的属性,将相似的对象归位一类。聚类,就是寻找发生数据之间内在联系的方法。
分类:从聚类的类型来讲,一般有结构性聚类、分散性聚类、密度聚类等。
- 结构性聚类是指,可以从上至下或者从下至上双向进行计算。从下至上是以单个对象开始,不断与周围相近的对象进行融合,最终将全部数据分成多种类别。而从上至下算法则恰恰相反,它先将全部数据当作一个整体,然后逐渐分小。在结构性聚类中,我们的重要依据为距离。一般情况下,我们会使用欧式距离,或者曼哈顿距离来测量两个对象之间的相似程度。
- 与结构性聚类不同,分散性聚类会一次性确定所有类别。
- 度聚类的主要特点为将测算距离改为计算密度。
聚类vs分类:一般来讲,在一个机器学习任务或者数据分析实例中,我们会先采用聚类算法对数据进行处理。使用聚类算法对历史数据处理之后,就可以人为的给每一种类别打上标签。而这些存在标签的数据,就可以被应用到下一步的分类学习中。简而言之、在执行聚类之前,我们的数据没有任何类别可言。但在执行分类之前,我们应该已经有了类别,才能对新数据进行分类。
; K-均值聚类
K-均值聚类(又叫 K-Means 聚类)是最常用的聚类方法之一。从它的名字来讲,K 代表最终将全部样本数据集和聚为 K 个类别。而「均值」代表在聚类的过程中,我们计算聚类中心点的特征向量时,需要采用求相邻样本点特征向量均值的方式进行。
例如,我们将 𝑋1=(𝑥1,𝑦1) , 𝑋2=(𝑥2,𝑦2) , 𝑋3=(𝑥3,𝑦3) 聚为一类时,中心点坐标 𝑂(𝑜1,𝑜1) 为: 𝑜1=(𝑥1+𝑥2+𝑥3)/3 , 𝑜2=(𝑦1+𝑦2+𝑦3)/3 。
聚类三步:
第一步:选择聚类数量,也就是 𝑘 值的大小。
第二步:实施聚类算法,k-均值等。
第三步:对聚类结果进行人工标注和分析。
K-均值聚类步骤
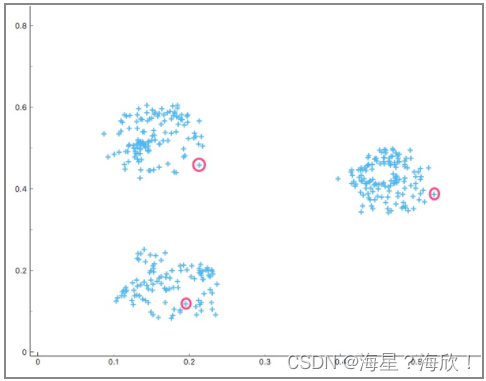
1.人为确定 𝑘 值的大小,也就是聚类的数量。然后,我们会使用一种叫 Forgy 的方法初始化聚类,Forgy 也就是随机地从数据集中选择 𝑘 个观测作为初始的均值点。例如,下图中,我们定 𝑘=3 ,然后随机选择 3 个数据点初始化聚类。
2.以这三个样本点(红色)为基准,将剩余的数据点按照与其距离最近的标准进行类别划分。
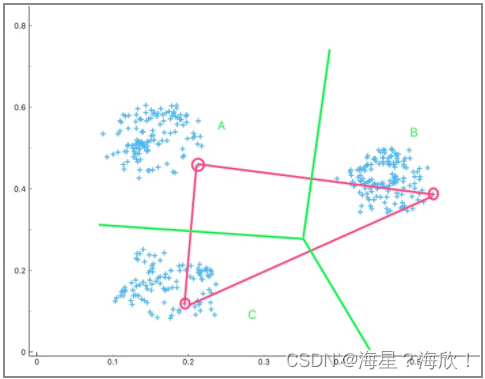
3.就得到了通过绿色线条划分的 A,B,C 三个区域。下面求解各区域中数据点集的中心点,这一步也就是更新。然后得到三个紫色中心点。重复上面的步骤,得到由黄色线条划分的 D, E, F 三个区域。
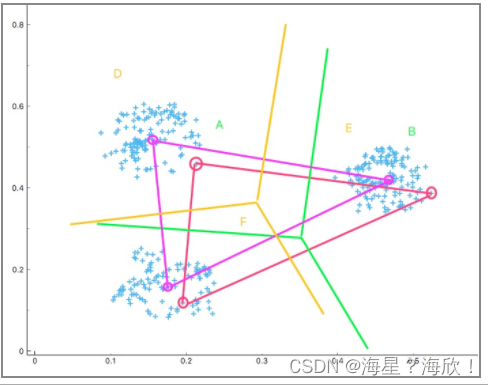
4.重复上面的步骤,直到三个区域的中心点变化非常小或没有变化时,终止迭代。最终,就将全部数据划分为 3 了类别。
K值选择
K值不能人为随便确定
K-Means 聚类中,我们一般通过计算轮廓系数,来确定 𝑘 值的大小。轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式。轮廓系数结合内聚度(Cohesion)和分离度(Separation)两种因素,可以用来在相同原始数据的基础上用来评价不同算法、或者算法不同运行方式对聚类结果所产生的影响。
对于某一点 𝑖 ,我们用 𝑎(𝑖) 表示 𝑖 距离同类中其它点之间的距离的平均值,而 𝑏(𝑖) 表示 𝑖 到所有非同类点的平均距离,然后取最小值。于是, 𝑖 的轮廓系数计算如下: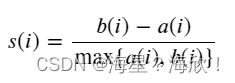
然后,我们计算数据集中所有点的轮廓系数,最终以平均值作为当前聚类的整体轮廓系数。整体轮廓系数介于 [−1,1] ,越趋近于 1 代表聚类的效果越好。
案例实现:数据用数据源里的three_class_data.csv
import pandas as pd
data = pd.read_csv(
"http://labfile.oss.aliyuncs.com/courses/764/three_class_data.csv", header=0)
data.head()
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from matplotlib import pyplot as plt
%matplotlib inline
X = data[["x", "y"]]
score = []
for i in range(10):
model = KMeans(n_clusters=i+2)
model.fit(X)
score.append(silhouette_score(X, model.labels_))
plt.figure(figsize=(11, 5))
plt.subplot(1, 2, 1)
plt.scatter(data['x'], data['y'])
plt.subplot(1, 2, 2)
plt.plot(range(2, 12, 1), score)
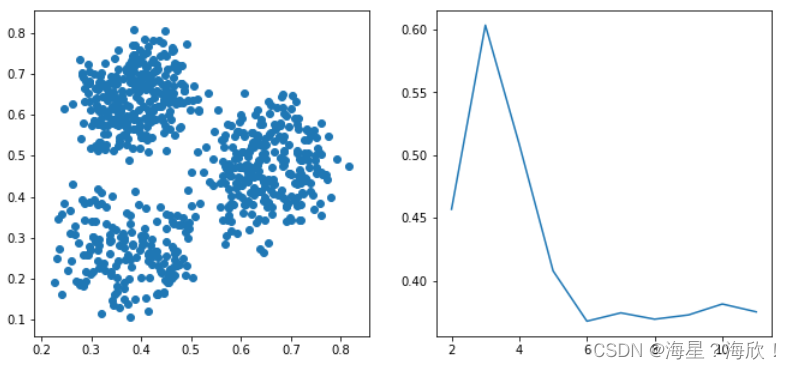
右图说明,当 𝑘 取 3 时,轮廓系数最大。也就是推荐将原数据聚合为三类
model = KMeans(n_clusters=3)
model.fit(X)
plt.scatter(data['x'], data['y'], c=model.labels_)
import numpy as np
x_min, x_max = data['x'].min() - 0.1, data['x'].max() + 0.1
y_min, y_max = data['y'].min() - 0.1, data['y'].max() + 0.1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .01),
np.arange(y_min, y_max, .01))
result = model.predict(np.c_[xx.ravel(), yy.ravel()])
result = result.reshape(xx.shape)
plt.contourf(xx, yy, result, cmap=plt.cm.Greens)
plt.scatter(data['x'], data['y'], c=model.labels_, s=15)
center = model.cluster_centers_
plt.scatter(center[:, 0], center[:, 1], marker='p',
linewidths=2, color='b', edgecolors='w', zorder=20)
其他聚类算法
Mini Batch K-Means
Mini Batch K-Means 整体上和 K-Means 很相似,它是 K-Means 的一个变种形式。与 K-Means 不同的地方在于,其每次从全部数据集中抽样小数据集进行迭代。Mini Batch K-Means 算法在不对聚类效果造成较大影响的前提下,大大缩短了计算时间。
Affinity Propagation
Affinity Propagation 又被称为亲和传播聚类。Affinity Propagation 是基于数据点进行消息传递的理念设计的。与 K-Means 等聚类算法不同的地方在于,亲和传播聚类不需要提前确定聚类的数量,即 𝑘 值。但是运行效率较低。
Mean Shift
MeanShift 又被称为均值漂移聚类。Mean Shift 聚类的目的是找出最密集的区域, 同样也是一个迭代过程。在聚类过程中,首先算出初始中心点的偏移均值,将该点移动到此偏移均值,然后以此为新的起始点,继续移动,直到满足最终的条件。Mean Shift 也引入了核函数,用于改善聚类效果。除此之外,Mean Shift 在图像分割,视频跟踪等领域也有较好的应用。
Spectral Clustering
Spectral Clustering 又被称为谱聚类。谱聚类同样也是一种比较常见的聚类方法,它是从图论中演化而来的。谱聚类一开始将特征空间中的点用边连接起来。其中,两个点距离越远,那么边所对应的权值越低。同样,距离越近,那么边对应的权值越高。最后,通过对所有特征点组成的网络进行切分,让切分后的子图互相连接的边权重之和尽可能的低,而各子图内部边组成的权值和经可能高,从而达到聚类的效果。谱聚类的好处是能够识别任意形状的样本空间,并且可以得到全局最优解。
Agglomerative Clustering
Agglomerative Clustering 又被称为层次聚类。层次聚类算法是将所有的样本点自下而上合并组成一棵树的过程,它不再产生单一聚类,而是产生一个聚类层次。层次聚类通过计算各样本数据之间的距离来确定它们的相似性关系,一般情况下,距离越小九代表相似度越高。最后,将相似度越高的样本归为一类,依次迭代,直到生成一棵树。由于层次聚类涉及到循环计算,所以时间复杂度比较高,运行速度较慢。
BIRCH
BIRCH 是英文 Balanced Iterative Reducing and Clustering Using Hierarchies 的简称,它的中文译名为「基于层次方法的平衡迭代规约和聚类」,名字实在太长。BIRCH 引入了聚类特征树(CF 树),先通过其他的聚类方法将其聚类成小的簇,然后再在簇间采用 CF 树对簇聚类。BIRCH 的优点是,只需要单次扫描数据集即可完成聚类,运行速度较快,特别适合大数据集。
DBSCAN
DBSCAN 是英文 Density-based spatial clustering of applications with noise 的简称,它的中文译名为「基于空间密度与噪声应用的聚类方法」,名字同样很长。DBSCAN 基于密度概念,要求聚类空间中的一定区域内所包含的样本数目不小于某一给定阈值。算法运行速度快,且能够有效处理特征空间中存在的噪声点。但是对于密度分布不均匀的样本集合,DBSCAN 的表现较差。
用代码实现上述8种聚类方法
from sklearn import cluster
import time
cluster_names = ['KMeans', 'MiniBatchKMeans', 'AffinityPropagation', 'MeanShift',
'SpectralClustering', 'AgglomerativeClustering', 'Birch', 'DBSCAN']
cluster_estimators = [
cluster.KMeans(n_clusters=3),
cluster.MiniBatchKMeans(n_clusters=3),
cluster.AffinityPropagation(),
cluster.MeanShift(),
cluster.SpectralClustering(n_clusters=3),
cluster.AgglomerativeClustering(n_clusters=3),
cluster.Birch(n_clusters=3, threshold=0.1),
cluster.DBSCAN()
]
plot_num = 1
plt.figure(figsize=(14, 7))
for name, model in zip(cluster_names, cluster_estimators):
tic = time.time()
model.fit(X)
plt.subplot(2, len(cluster_estimators) / 2, plot_num)
x_min, x_max = data['x'].min() - 0.1, data['x'].max() + 0.1
y_min, y_max = data['y'].min() - 0.1, data['y'].max() + 0.1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .01),
np.arange(y_min, y_max, .01))
if hasattr(model, 'predict'):
result = model.predict(np.c_[xx.ravel(), yy.ravel()])
result = result.reshape(xx.shape)
plt.contourf(xx, yy, result, cmap=plt.cm.Greens)
plt.scatter(data['x'], data['y'], c=model.labels_, s=15)
if hasattr(model, 'cluster_centers_'):
center = model.cluster_centers_
plt.scatter(center[:, 0], center[:, 1], marker='p',
linewidths=2, color='b', edgecolors='w', zorder=20)
toc = time.time()
cluster_time = (toc - tic)*1000
plt.title(str(name) + ", " + str(int(cluster_time)) + "ms")
plot_num += 1
聚类算法方法的选择
每一种方法的使用情况不同,下面说明一下简易的选择步骤:
如果已知 𝑘 值,即聚类的数量:
- 样本数量 < 1 万,首选 K-Means,效果不好再选择 Spectral Clustering。
- 样本数量 > 1 万,首选 MiniBatch K-Means。
如果 𝑘 值未知: - 样本数量 < 1 万,首选 Mean Shift。
- 样本数量 > 1 万,依靠经验灵活应对了。
Original: https://blog.csdn.net/Sun123234/article/details/125455574
Author: 海星?海欣!
Title: 关于聚类问题的算法python代码实现-K-均值聚类方法