
如前面第3篇讲到,声音的几个主要特征有音量 Volume, 音高 Pitch, 音色 Timbre。
另外有一个重要的特征是过零率 zero crossing rate。
当我们在分析声音时,通常以「短时距分析」(Short-term Analysis)为主,因为音讯在短时间内是相对稳定的。我们通常将声音先切成帧(Frame),每一帧长度大约在 20 ms 左右,再根据帧内的信号来进行分析。
计算音量(Volume/Intensity/Energe)
「音量」代表声音的强度,又称为「响度」、「强度」(Intensity)或「能量」(Energy),可由一个音框内的讯号震幅大小来类比,基本上两种方式来计算:
1).每一个音帧的绝对值(信号绝对值)的总和:

其中 si 是一个音帧中的第 i 个取样点,而 n 则是每个音帧包含的采样点数。这种方法的计算较简单,只需要整数运算,适合用于低端平台(如微电脑等)。
2).每一个音帧的信号值平方值的总和,再取以 10 为底对数值,再乘以10:
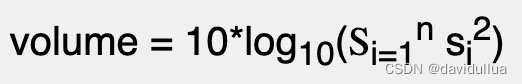
这种方法得到的值是以分贝(Decibels)为单位,是一个相对强度的值,比较符合人耳对于大小声音的感觉。以下网页有对分贝的详细说明:
dB: What is a decibel?
音量具有下列特性:
1.一般而言,有浊音(voiced sound)的音量大于清音/气音(unvoiced sound)的音量,而清音的音量又大于噪音的音量。
2.音量是一个相对性的指标,受到麦克风设定的影响很大。
3.通常用在端点侦测,估测浊音(Voiced sound)的音母或韵母的开始位置及结束位置。
4.在计算前最好先减去音讯讯号的平均值,以避免讯号的直流偏移(DC Bias)所导致的误差。 对于绝对值加和的方法,通常减去中位数( median subtraction )来计算; 而对于平方和取对数计算分贝的方法,通常减去平均数(mean substraction)来计算(目的都是为了使得一帧的总音量值在减去噪音的影响后尽可能小)。

上面是通过常量(固定的直流偏移/DC Bias 来做音量计算的零调整。
也可以通过多项式拟合的方法来找到直流偏移/噪音的曲线来做零调整。
在语音录制过程中,由于多种原因,包括静态效应、麦克风上的呼吸和 50Hz 交流电压信号,录制的语音信号很可能会在非零时变值附近振荡(偏移)。 为了避免在一帧内出现这种漂移,一种简单的方法是通过多项式拟合来识别时变零曲线(就是说即使没有声音的情况下, 也有在0点附近的信号时变近0信号),并通过在原始帧的曲线中删除噪音子轨道来消除漂移。
以下显示如何以两种方法(绝对值/分贝值,同时做零调整)来计算音量:
waveFile='sunday.wav';
% 帧大小取 256, 即每一帧 256 个采样点,两帧之间设置 123 个采样点的重叠。
frameSize=256;
overlap=128;
au=myAudioRead(waveFile); y=au.signal; fs=au.fs;
fprintf('Length of %s is %g sec.\n', waveFile, length(y)/fs);
% 调用 enframe 自动分帧
frameMat=enframe(y, frameSize, overlap);
frameNum=size(frameMat, 2);
% Compute volume using method 1
volume1=zeros(frameNum, 1);
for i=1:frameNum
frame=frameMat(:,i);
frame=frame-median(frame); % zero-justified
volume1(i)=sum(abs(frame)); % method 1
end
% Compute volume using method 2
volume2=zeros(frameNum, 1);
for i=1:frameNum
frame=frameMat(:,i);
frame=frame-mean(frame); % zero-justified
volume2(i)=10*log10(sum(frame.^2)+realmin); % method 2
end
sampleTime=(1:length(y))/fs;
frameTime=((0:frameNum-1)*(frameSize-overlap)+0.5*frameSize)/fs;
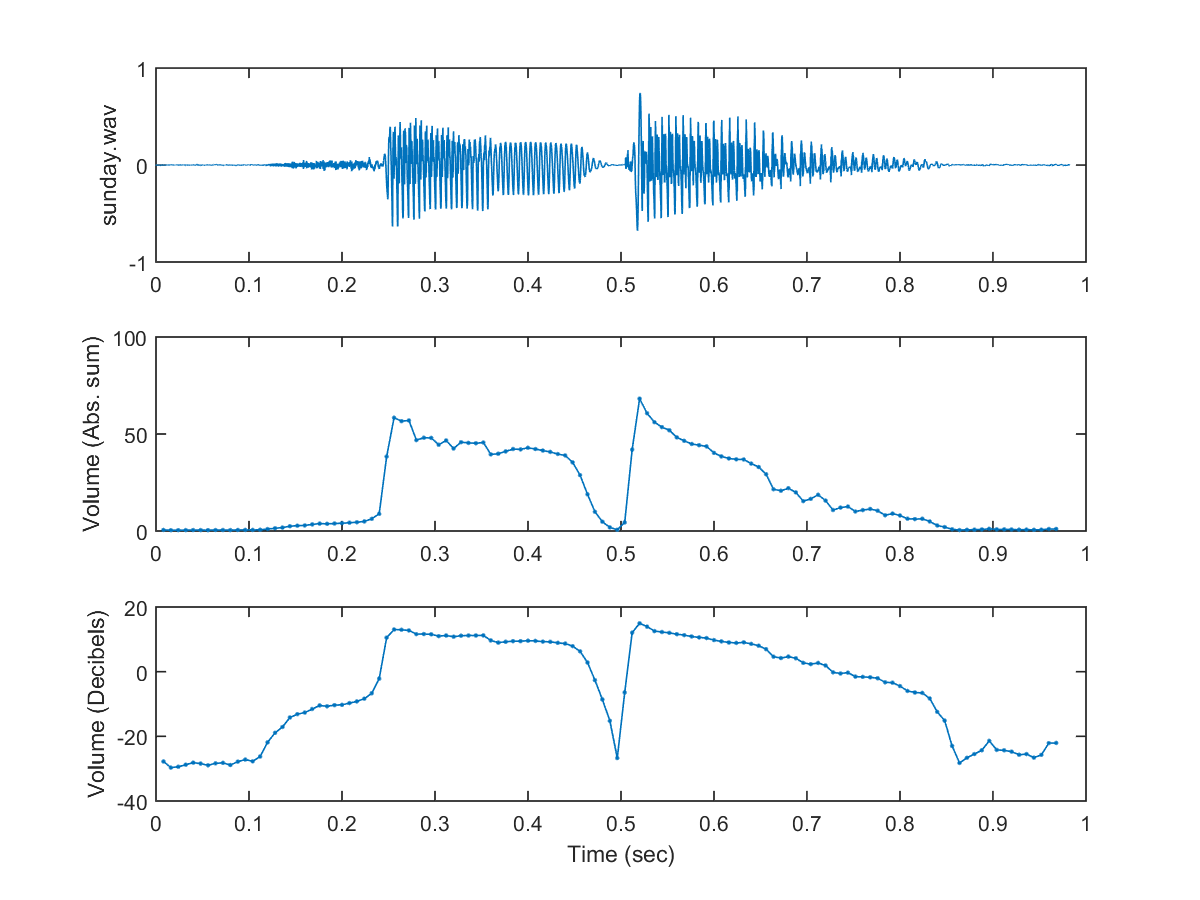
subplot(3,1,1); plot(sampleTime, y); ylabel(waveFile);
subplot(3,1,2); plot(frameTime, volume1, '.-'); ylabel('Volume (Abs. sum)');
subplot(3,1,3); plot(frameTime, volume2, '.-'); ylabel('Volume (Decibels)'); xlabel('Time (sec)');
分析绝对的音量,以及分贝值,得到这样的随着时间变化的波形图:
过零率(Zero Crossing Rate)的计算
「过零率」(Zero Crossing Rate,简称 ZCR)是在声音信号的每一帧中,声音信号的采样值通过零点的次数,具有下列特性:
1.一般而言,噪音及清音(unvoiced sound)的过零率均大于浊音(voiced sound)具有清晰可辨之音高,例如母音)。
2.ZCR 是噪音和清音(unvoiced sound)两者较难从过零率来分辨,会依照录音情况及环境噪音而互有高低。但通常清音的音量会大于噪音。
3.通常用在端点侦测,特别是用在估测清音的起始位置及结束位置。
4.可用来预估讯号的基频,但很容易出错,所以必须先进行前处理。
为了避免直流偏移,通常需要在每一帧里面减去均值。 直接计算过零率如下。
% zerocrossingrate.m
waveFile='csNthu.wav';
frameSize=256;
overlap=0;
au=myAudioRead(waveFile); y=au.signal; fs=au.fs;
frameMat=enframe(y, frameSize, overlap);
frameNum=size(frameMat, 2);
for i=1:frameNum
frameMat(:,i)=frameMat(:,i)-mean(frameMat(:,i)); % mean justification
end
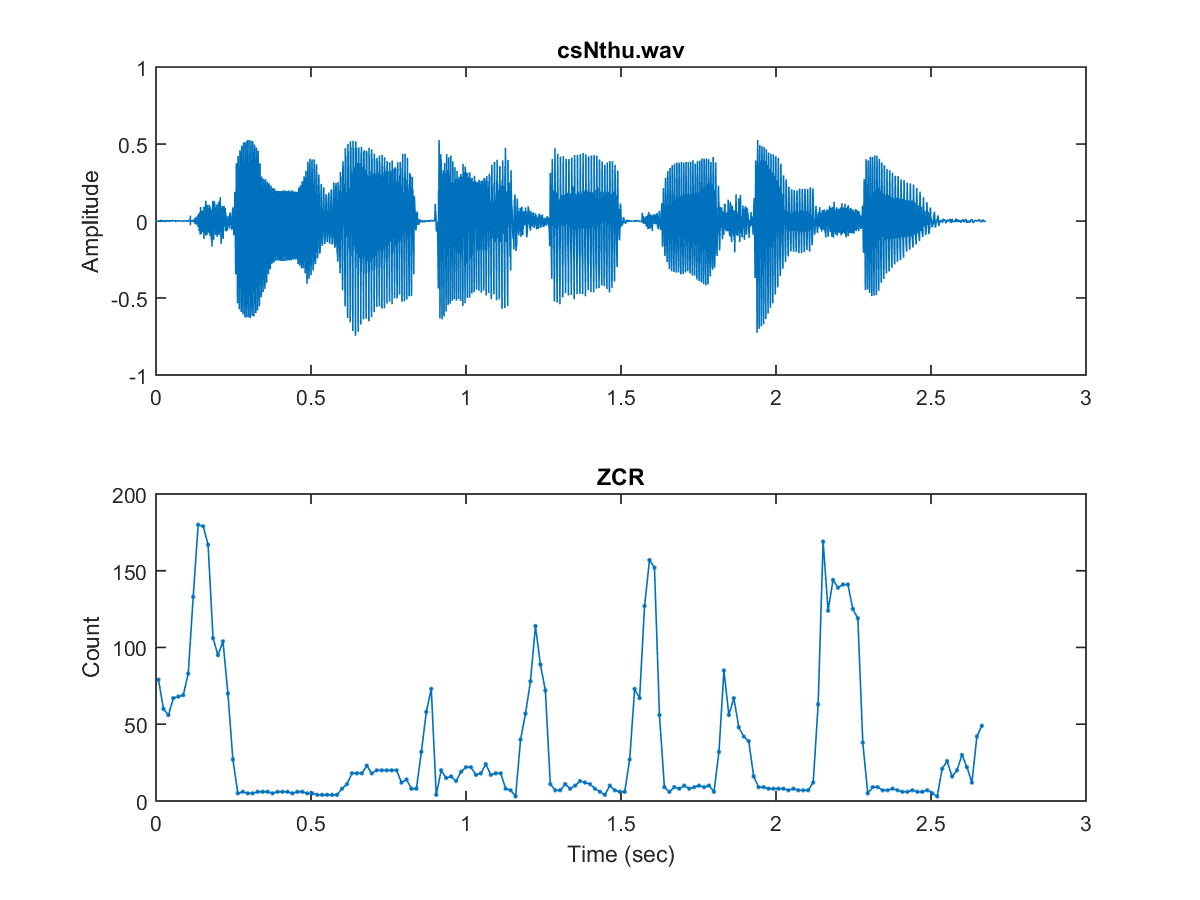
zcr=sum(frameMat(1:end-1, :).*frameMat(2:end, :)<0); sampletime="(1:length(y))/fs;" frametime="((0:frameNum-1)*(frameSize-overlap)+0.5*frameSize)/fs;" subplot(2,1,1); plot(sampletime, y); ylabel('amplitude'); title(wavefile); subplot(2,1,2); plot(frametime, zcr, '.-'); xlabel('time (sec)'); ylabel('count'); title('zcr');< code></0);>
可视化之后看到每个时刻点的信号量(归一后的信号量)、过零率的图
可以使用 frame2zcr 函数简化上面的例子,函数的 代码参考:
http://mirlab.org/jang/books/audiosignalprocessing/example.rar
waveFile='csNthu.wav';
frameSize=256;
overlap=0;
au=myAudioRead(waveFile); y=au.signal; fs=au.fs;
frameMat=enframe(y, frameSize, overlap);
frameNum=size(frameMat, 2);
zcr=frame2zcr(frameMat);
sampleTime=(1:length(y))/fs;
frameTime=frame2sampleIndex(1:frameNum, frameSize, overlap)/fs;
subplot(2,1,1); plot(sampleTime, y); ylabel('Amplitude'); title(waveFile);
subplot(2,1,2); plot(frameTime, zcr, '.-');
xlabel('Time (sec)'); ylabel('Count'); title('ZCR');
为了使用过零率 ZCR 来区分清音(unvoiced sound)和环境噪音,我们在计算 ZCR 之前做一个波形的偏移,这个方法在噪音比较小的时候特别有用(即每一个信号都减去噪音信号值,假设最小声音的信号是噪音)
偏移量:取音量最小的帧中,最大采样值的绝对值的2倍。比如两种方法计算过滤率:
waveFile='csNthu.wav';
frameSize=256;
overlap=0;
au=myAudioRead(waveFile); y=au.signal; fs=au.fs;
frameMat=enframe(y, frameSize, overlap);
frameNum=size(frameMat,2);
volume=frame2volume(frameMat);
[minVolume, index]=min(volume);
% shiftAmount is equal to twice the max. abs. sample value within the frame of min. volume
shiftAmount=2*max(abs(frameMat(:,index)));
method=1;
zcr1=frame2zcr(frameMat, method);
zcr2=frame2zcr(frameMat, method, shiftAmount); % ZCR with shift
sampleTime=(1:length(y))/fs;
frameTime=frame2sampleIndex(1:frameNum, frameSize, overlap)/fs;
subplot(2,1,1); plot(sampleTime, y); ylabel('Amplitude'); title(waveFile);
subplot(2,1,2); plot(frameTime, zcr1, '.-', frameTime, zcr2, '.-');
xlabel('Time (sec)'); ylabel('Count'); title('ZCR');
legend('ZCR without shift', 'ZCR with shift');
得到如下的图,图中红色的为加上偏移之后的过零率,很明显加偏移后,纯噪音的过零率都变成0了。从而和清音区分开来。(清音、噪音的过零率较大,而加偏移后,噪音的过零率变成0)
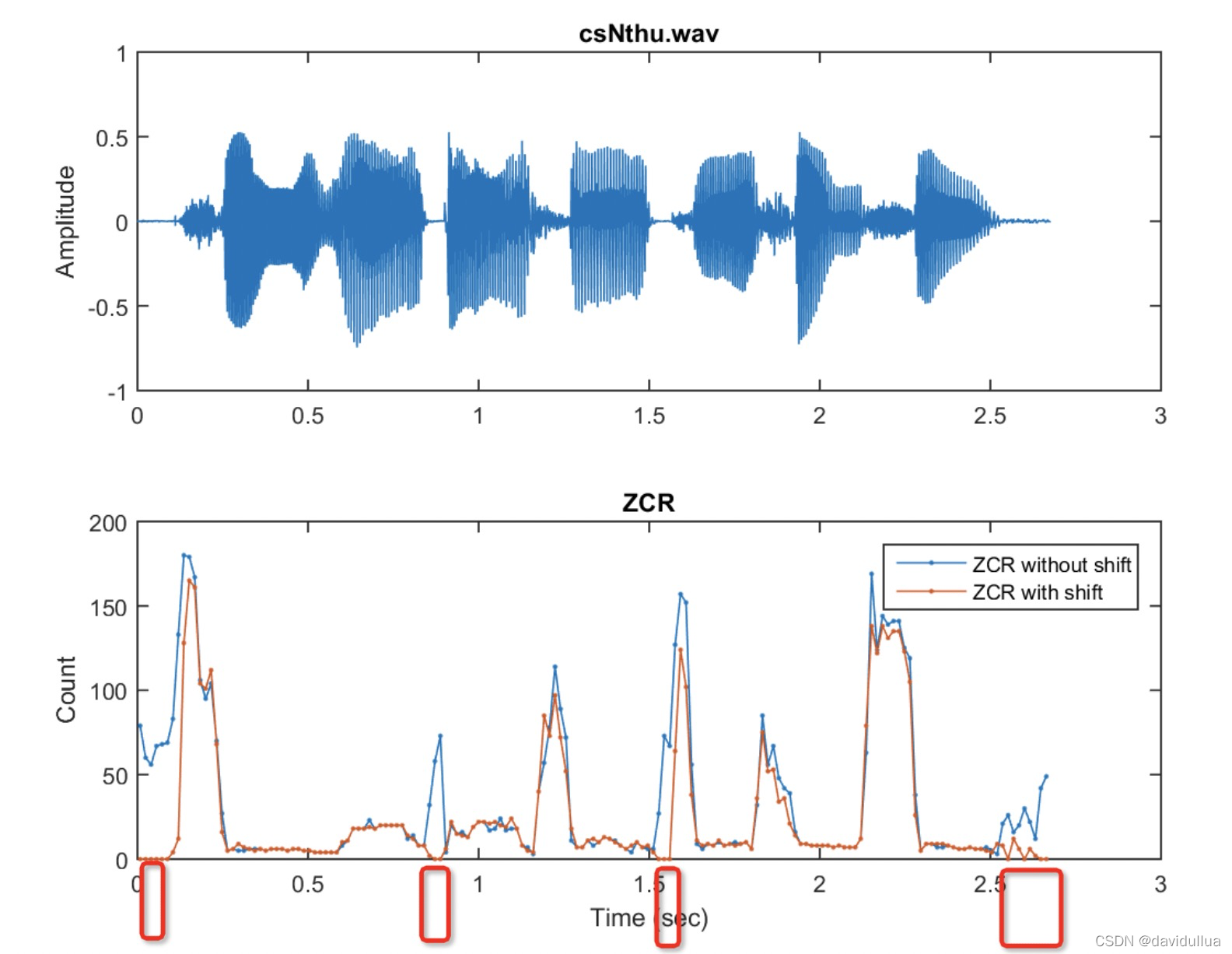
在这个例子中,偏移等于最小音量帧内最大信号值绝对值的两倍。 因此,静音的 ZCR 大幅降低,这时使用 ZCR 更容易区分清音和静音。
此外,我们应该注意到以下情况:
1).如果一个样本恰好位于零处,我们是否应该将其视为过零? 根据对这个问题的回答,我们有两种实现 ZCR 的方法。
2).大多数 ZCR 计算基于音频信号的整数值。 如果我们想做均值减法,平均值也应该四舍五入到最接近的整数。
若要侦测声音的开始和结束,通常称为「端点侦测」(Endpoint Detection)或「语音侦测」(Speech Detection),最简单的方法就是使用音量和过零率来判别,相关内容后面再做分享。
音高的计算(Matlab 例子)
「音高」(Pitch)是另一个音讯里面很重要的特征,直觉地说,音高代表声音频率的高低,而此频率指的是「基本频率」(Fundamental Frequency),也就是「基本周期」(Fundamental Period)的倒数。这个频率跟采样率(Sample Rate, Frequency of Sampling)不是同一个概念。
音高的计算公式: pitch=69+12*log2(ff/440); 其中 ff 是基本频率。
若直接观察音讯的波形,只要声音稳定,我们并不难直接看到基本周期的存在,以一个 3 秒的音叉声音来说,我们可以取一个 256 点的帧,将此帧画出来后,就可以很明显地看到基本周期,请见下列范例,对一个音叉发出来的声音做分析,计算:
waveFile='tuningFork01.wav';
au=myAudioRead(waveFile); y=au.signal; fs=au.fs;
index1=11000;
frameSize=256;
index2=index1+frameSize-1;
frame=y(index1:index2);
subplot(2,1,1); plot(y); grid on
xlabel('Sample index'); ylabel('Amplitude'); title(['Waveform of ', waveFile]);
axis([1, length(y), -1 1]);
subplot(2,1,2); plot(frame, '.-'); grid on
xlabel('Sample index within frame'); ylabel('Amplitude');
point=[7, 226]; % Peaks
axis([1, length(frame), -1 1]);
periodCount=6;
fp=((point(2)-point(1))/periodCount); % fundamental period
ff=fs/fp; % fundamental frequency
pitch=69+12*log2(ff/440);
fprintf('Fundamental period (fp) = (%g-%g)/%g = %g points\n', point(2), point(1), periodCount, fp);
fprintf('Fundamental frequency (ff) = %g/%g = %g Hz\n', fs, fp, ff);
fprintf('Pitch = %g semitone\n', pitch);
% === For plotting arrows, etc
% ====== Frame boundary
subplot(211);
line(index1*[1 1], [-1 1], 'color', 'r', 'linewidth', 1);
line(index2*[1 1], [-1 1], 'color', 'r', 'linewidth', 1);
% ====== FP coverage
subplot(212);
line(point, frame(point), 'marker', 'o', 'color', 'red');
% ====== Axis locations
subplot(211); loc1=get(gca, 'position');
subplot(212); loc2=get(gca, 'position');
% ====== arrow 1
x1=[loc1(1)+(index1(1)-1)/(length(y)-1)*loc1(3), loc2(1)];
y1=[loc1(2), loc2(2)+loc2(4)];
ah=annotation('arrow', x1, y1, 'color', 'r', 'linewidth', 1);
% ======= arrow 2
x2=[loc1(1)+(index2-1)/(length(y)-1)*loc1(3), loc2(1)+loc2(3)];
y2=[loc1(2), loc2(2)+loc2(4)];
ah=annotation('arrow', x2, y2, 'color', 'r', 'linewidth', 1);
% ====== Texts indicating start/end indices
h1=text(point(1), frame(point(1)), [' \leftarrow index=', int2str(point(1))], 'rotation', 30);
h2=text(point(2), frame(point(2)), [' \leftarrow index=', int2str(point(2))], 'rotation', 30);
Fundamental period (fp) = (226-7)/6 = 36.5
points Fundamental frequency (ff) = 16000/36.5 = 438.356 Hz
Pitch = 68.9352 semitone
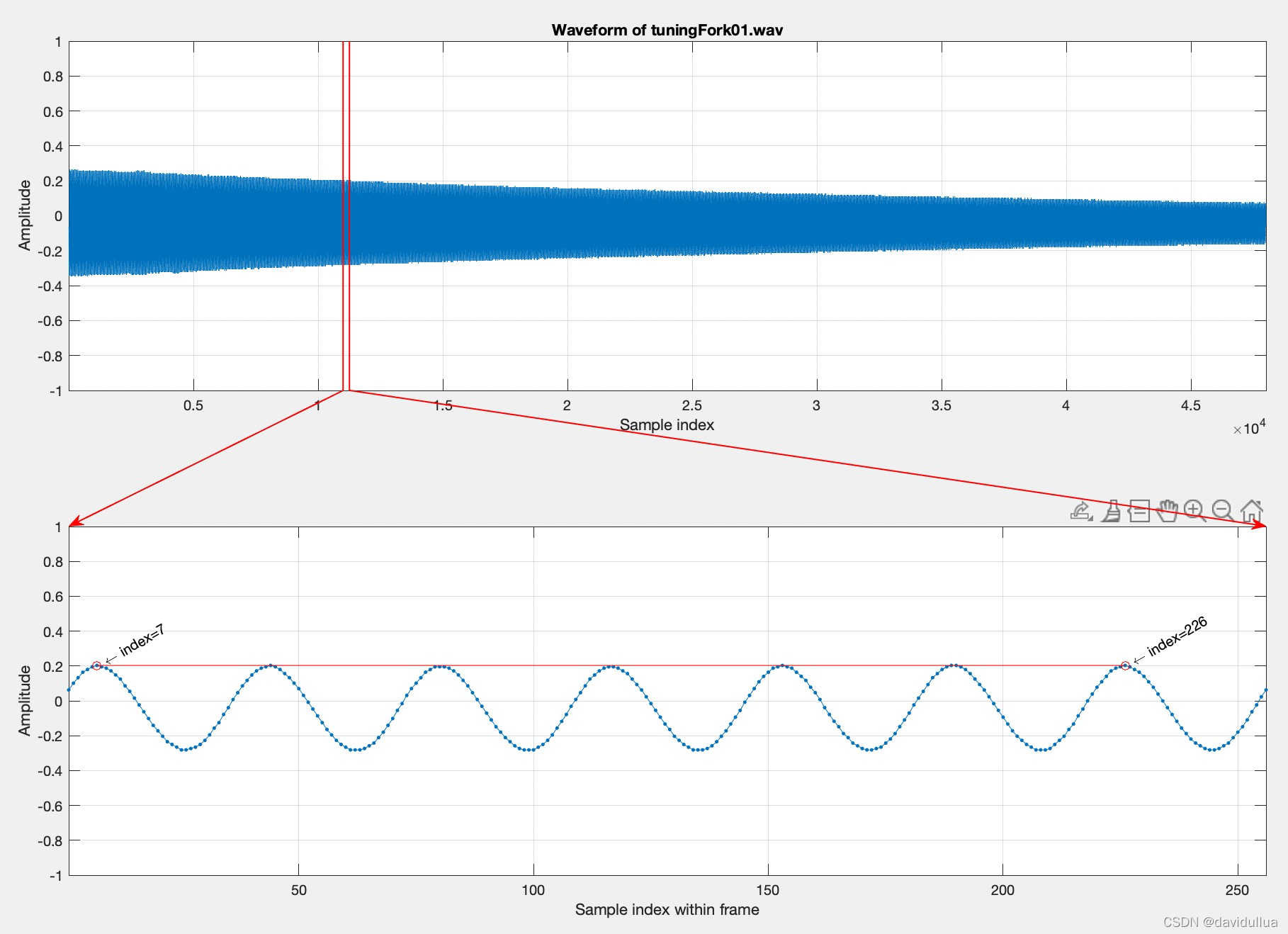
这个图示一个256个采样点的一帧音频的图。 从这个图中可以看出来,在一个简短的时间周期内,这个音频的信号是完全标准的周期性信号。
在上面的例子中,上图红线的位置代表音频这一帧的位置,下图即是 256 个采样点的帧,其中红线部分包含了 5 个基本周期,总共占掉了 182 单位点,因此对应的基本频率是 fs/(182/5) = 16000/(182/5) = 439.56 Hz,相当于 68.9827 半音(Semitone),其中由基本频率至半音的转换公式如下:
semitone = 69 + 12*log2(frequency/440)
换句话说,当基本频率是 440 Hz 时,对应到的半音差是 69,这就是钢琴的「中央 La」或是「A4」

一般音叉的震动频率非常接近 440 Hz,因此我们常用音叉来校正钢琴的音准。
上述公式所转换出来的半音音程,也是 MIDI 音乐档案所用的标准。从上述公式也可以看出:
1.每个全音阶包含 12 个半音(七个白键和五个黑键)。
2.每向上相隔一个全音阶,频率会变成两倍。例如,中央 la 是 440 Hz(69 Semitones),向上平移一个全音阶之后,频率就变成 880 Hz(81 Semitones)。
3.人耳对音高的「线性感觉」是随着基本频率的对数值成正比。
4.音叉的声音非常干净,整个波形非常接近弦波,所以基本周期显而易见。
在观察音讯波形时,每一个基本周期的开始点,我们称为「音高基准点」(Pitch Marks,简称 PM),PM 大部分是波形的局部最大点或最小点,例如在上述音叉的范例中,我们抓取的两个 PM 是局部最大点,而在我的声音的范例中,由于 PM 在局部最大点并不明显,因此我们抓取了两个局部最小点的 PM 来计算音高。 PM 通常用来调节一段声音的音高,在语音合成方面很重要。
由于生理构造不同,男女生的音高范围并不相同,一般而言:
男生的音高范围约在 35 ~ 72 半音,对应的频率是 62 ~ 523 Hz。
女生的音高范围约在 45 ~ 83 半音,对应的频率是 110 ~ 1000 Hz。
但是我们分辨男女的声并不是只凭音高,而还是依照音色(共振峰)。
使用「观察法」来算出音高,并不是太难的事,但是若要电脑自动算出音高,就需要更深入的研究。
音色
「音色」(Timber)是一个很模糊的名词,泛指音讯的内容,例如「天书」这两个字的发音,虽然都是第一声,因此它们的音高应该是蛮接近的,但是由于音色的不同,我们可以分辨这两个音。直觉来看,音色的不同,代表基本周期的波形不同,因此我们可以使用基本周期的波形来代表音色。若要从基本周期的波形来直接分析音色,是一件很困难的事。
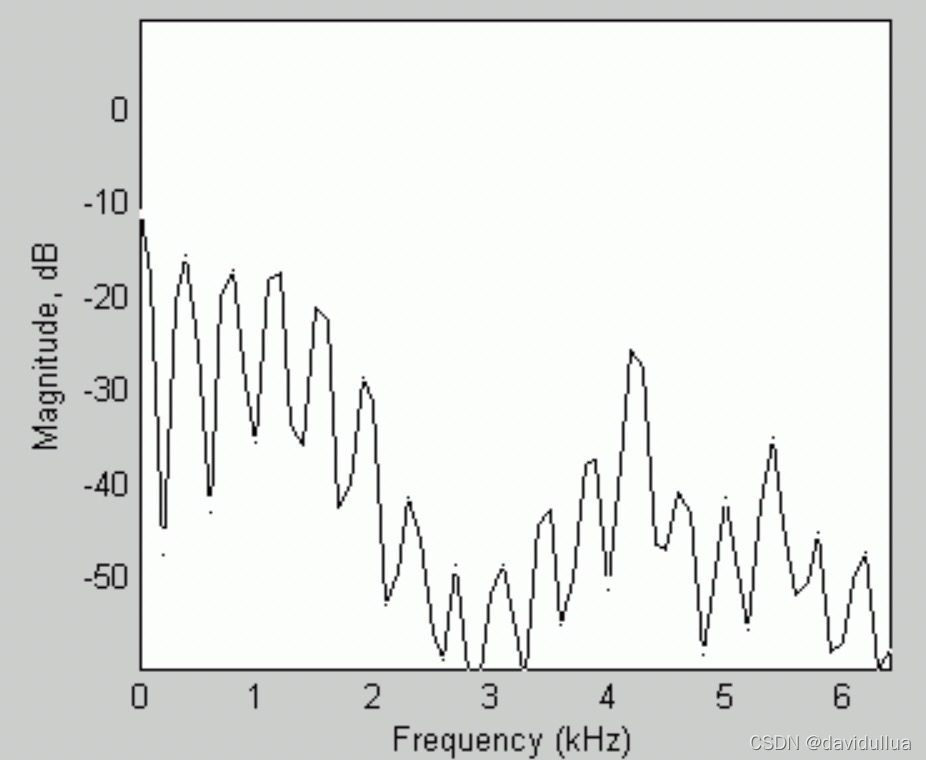
通常我们的作法,是将每一个音框进行频谱分析(Spectral Analysis),算出一个音框讯号如何可以拆解成在不同频率的分量,然后才能进行比对或分析。在频谱分析时,最常用的方法就是「快速傅立叶转换」(Fast Fourier Transform),简称 FFT,这是一个相当实用的方法,可以将在时域(Time Domain)的讯号转换成在频域(Frequency Domain)的讯号,并进而知道每个频率的讯号强度。
比如如下的频谱图 ,横轴是频率,纵轴是计算出来的数值。
若将频谱图「立」起来,并用不同的颜色代表频谱图的高低,就可以得到频谱对时间所产生的影像,称为 Spectrogram (语谱图),如下
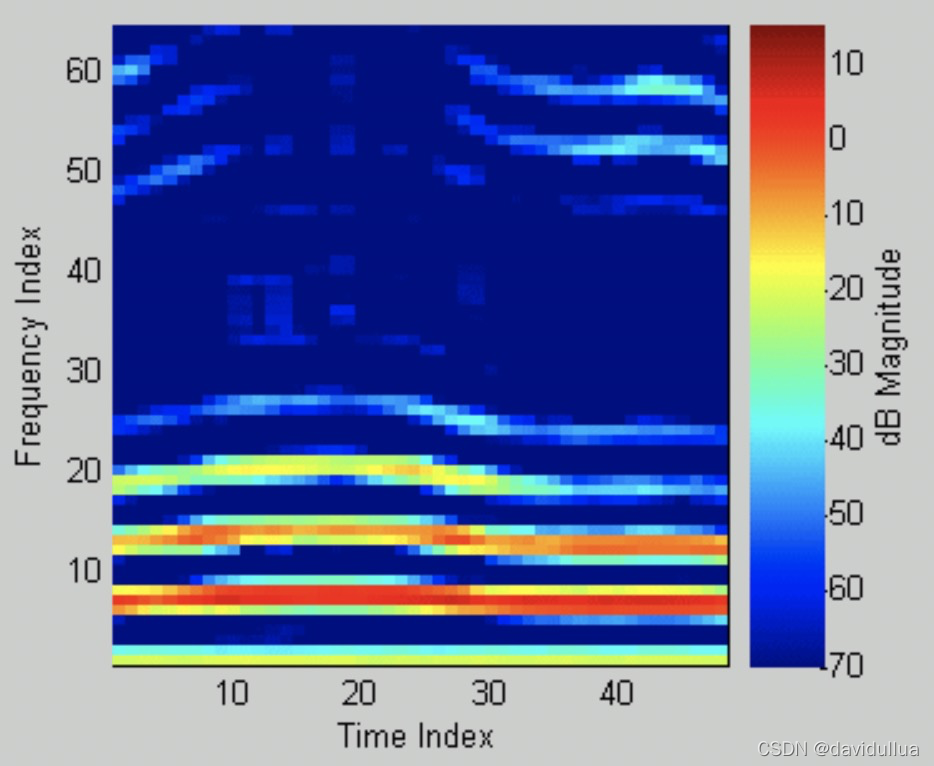
Spectrogram 代表了音色随时间变化的资料,因此有些厉害的人,可以由 Specgrogram 直接看出语音的内容,这种技术称为 Specgrogram Reading
Original: https://blog.csdn.net/davidullua/article/details/122915934
Author: davidullua
Title: 语音处理/语音识别基础(五)- 声音的音量,过零率,音高的计算
相关阅读1
Title: centos7.9部署Tensorflow版本
1、虚拟机部署Centos7.9最小版本
CentOS-7-x86_64-Minimal-2009.iso
TensorFlow 可以在系统范围内被安装,在一个 Python 虚拟环境,作为一个 Docker 容器,或者和 Anaconda 一起。
TensorFlow 同时支持 Python 2 和 3。
我们将会使用 Python 3 ,并且将 TensorFlow 安装在一个虚拟环境。这种方式下,你可以在一台简单的电脑上拥有不同的相互隔离的 Python 环境,并且可以针对每个项目安装一个指定版本的模块,而不用担心这个模块会影响你的其他项目。
1.1 安装 Python 3
我们将会从软件集合软件源(SCL)中安装 Python 3.6。
CentOS 7 搭载 Python 2.7.5 ,它是 CentOS 基础系统中的一个关键部分。SCL 将会允许在默认的 python v2.7.5 旁边你安装 Python 3.X 系列的新版本,而系统工具例如 yum 仍然能够正常运行。
想要启用这个软件源,安装 SCL 发布文件:
sudo yum install centos-release-scl
一旦完成,使用下面的命令安装 Python 3.6:
sudo yum install rh-python36
我们现在准备好为我们的 TensorFlow 项目创建一个虚拟环境了。
1.2 创建一个虚拟环境
从 Python 3.6 开始,推荐用来创建一个虚拟环境的方式就是使用venv模块。
想要访问 Python 3.6,你需要使用 scl 工具启动一个新的 shell 实例:
scl enable rh-python36 bash
导航到你想要存储 TensorFlow 项目的目录。它可以是你的主目录,或者任何其他用户拥有读写权限的目录。
为 TensorFlow 项目创建一个新的目录,并且 cd 进去:
mkdir tensorflow_project
cd tensorflow_project
在这个目录下,运行下面的命令创建虚拟环境:
python3 -m venv venv
上面的命令创建了一个文件夹,名字为venv,它包含了 Python 二进制的拷贝,Pip package manager,标准的 Python 库和其他支持文件。你可以为虚拟环境使用任何你想要的名字。
想要使用这个虚拟环境,你需要激活它,并且运行activate 脚本:
source venv/bin/activate
一旦激活,虚拟环境的 bin 目录将会被添加到$PATH 环境变量的前面。你的 shell 提示符将会改变,并且它将会显示你当前使用的虚拟环境的名字。在这里,名字是venv。
升级 pip 到最新版本,避免在安装软件包时出现问题:
pip install --upgrade pip
1.3 安装 TensorFlow
现在虚拟环境被激活了,是时候安装 TensorFlow 库文件了。想要这么做,输入下面的命令:
pip install -i https://pypi.douban.com/simple --upgrade tensorflow
国内源(如果不可用,切换源):
http://pypi.douban.com/ 豆瓣
http://pypi.hustunique.com/ 华中理工大学
http://pypi.sdutlinux.org/ 山东理工大学
http://pypi.mirrors.ustc.edu.cn/ 中国科学技术大学
如果你拥有独立的 NVIDIA GPU 并且想发挥它的处理能力,使用tensorflow-gpu替换tensorflow,它拥有 GPU 支持。
在虚拟环境内,你可以使用pip替换pip3,python替换python3。
想要验证安装,使用下面的命令将会打印出 TensorFlow 版本:
python -c 'import tensorflow as tf; print(tf.__version__)'
解除环境,通过输入deactivate,并且你将返回你的正常 shell。
deactivate
参考:
Original: https://blog.csdn.net/qq_31215163/article/details/122197591
Author: AhoBric
Title: centos7.9部署Tensorflow版本
相关阅读2
Title: 个推科普漫画,解读《女心理师》中的智能语音识别系统
近期的很多热播剧都和心理咨询相关,在《女心理师》中,有这样一个数据智能应用,吸引了Mr.Tech的目光。

▲图片来源:优酷网剧《女心理师》
在女主工作的心理救援中心,不仅有酷炫的可视化数据大屏,还有看起来非常高级的 智能语音识别系统。这个智能语音识别系统不仅能实时将通话双方的语音内容转译成文本,还能根据通话内容做出预警,帮助心理咨询师做判断和决策,从而更好地实施援助。
这样的"黑科技"具体如何实现呢?接下来,Mr.Tech就为大家图文并茂做深入解读。
第一步: 用傅里叶变换将声音信号处理成波数据
众所周知,计算机不能直接对声音文件进行计算和机器学习训练。算法工程师需要对声音文件进行处理,把MP3、MP4等声音文件转化成计算机擅长解决的数学问题。
学过中学物理课,我们都知道, 声音的本质是波,频率和振幅是描述声波的两个重要属性。我们将一定时间内声音的振幅和频率做成可视化图表,就能得到声波图。
看到以上的声波图,你想到了什么?是不是和数学里的 正弦函数图像长得特别像呢?
Bingo!
智能语音识别第一步要做的,就是选择正确类型的函数来描述不同的声波,然后再将数据交给机器去学习和计算。
理解了这点,你的右脚就已经踏进了智能语音识别科学的大门!
但是,声波是很复杂的。声波是不同频率、不同强度的正弦波的叠加。我们在将声音可视化时,得到的仅仅是叠加合成后的声波图。为了更好地理解声音信号,算法工程师还需要将声波图进行分解。
如下图:

这个将声音信号进行分解(变换)的过程,就是机器学习里经常提到的 "傅里叶变换"。

傅里叶变换(Fourier Transform,简称"FT")
是机器学习领域一个很常用的算法,它的作用是对数字信号进行解析,以方便后续进行数据处理。
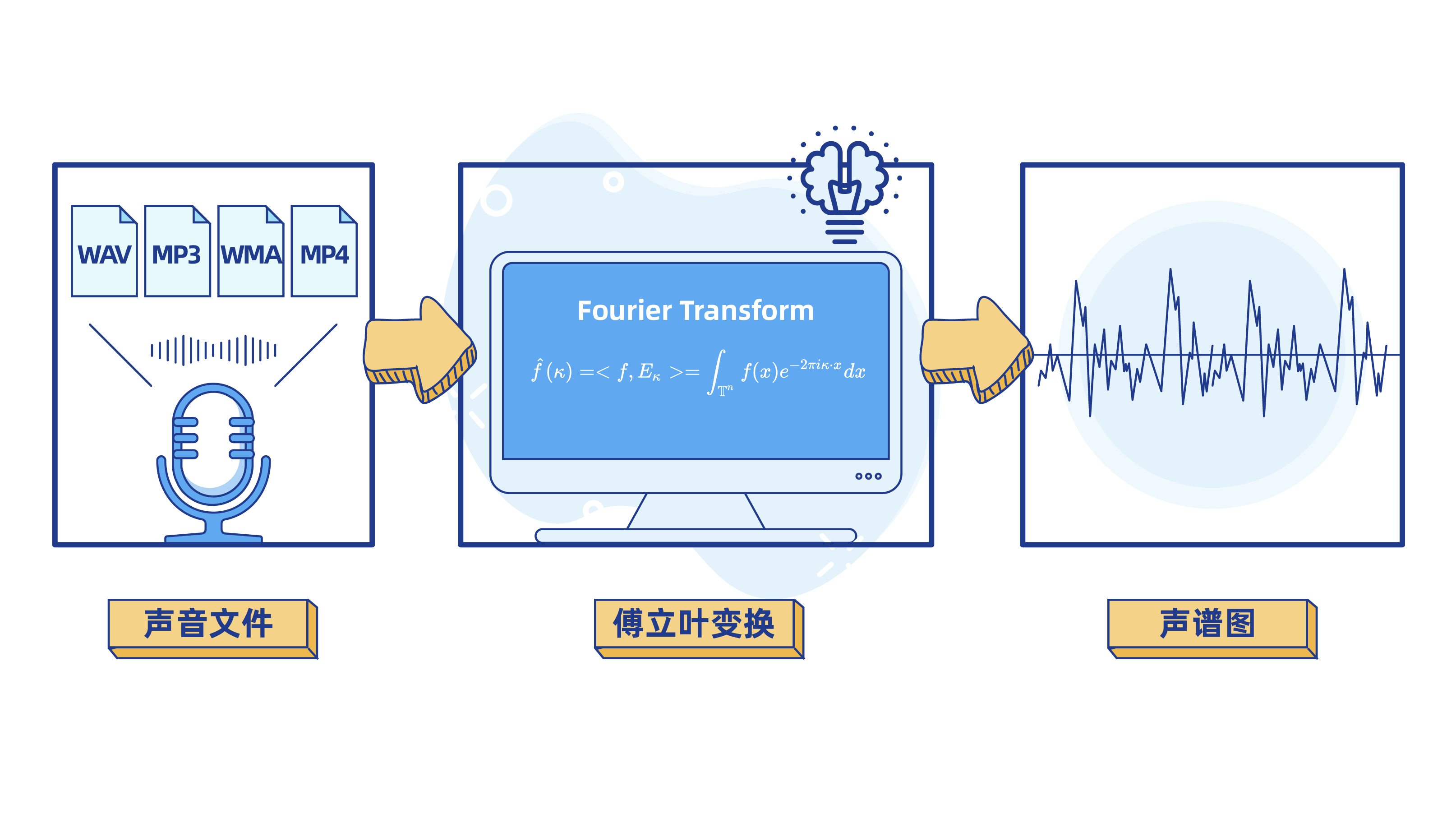
第二步: 对声音进行基础的特征识别
将声音文件解析成声谱图之后,机器就可以对声音进行简单的特征识别和判断,比如发声人的性别、年龄层次等。
我们知道,男性和女性的声音具有非常明显的区别。一般来说,男性声音洪亮,振幅较高,频率较低;女性声音尖细,频率较高,振幅较低。同时,还有一些异常情况,比如大声的呼救、病痛时的呻吟等,也都可以通过频率和振幅来进行刻画描述。
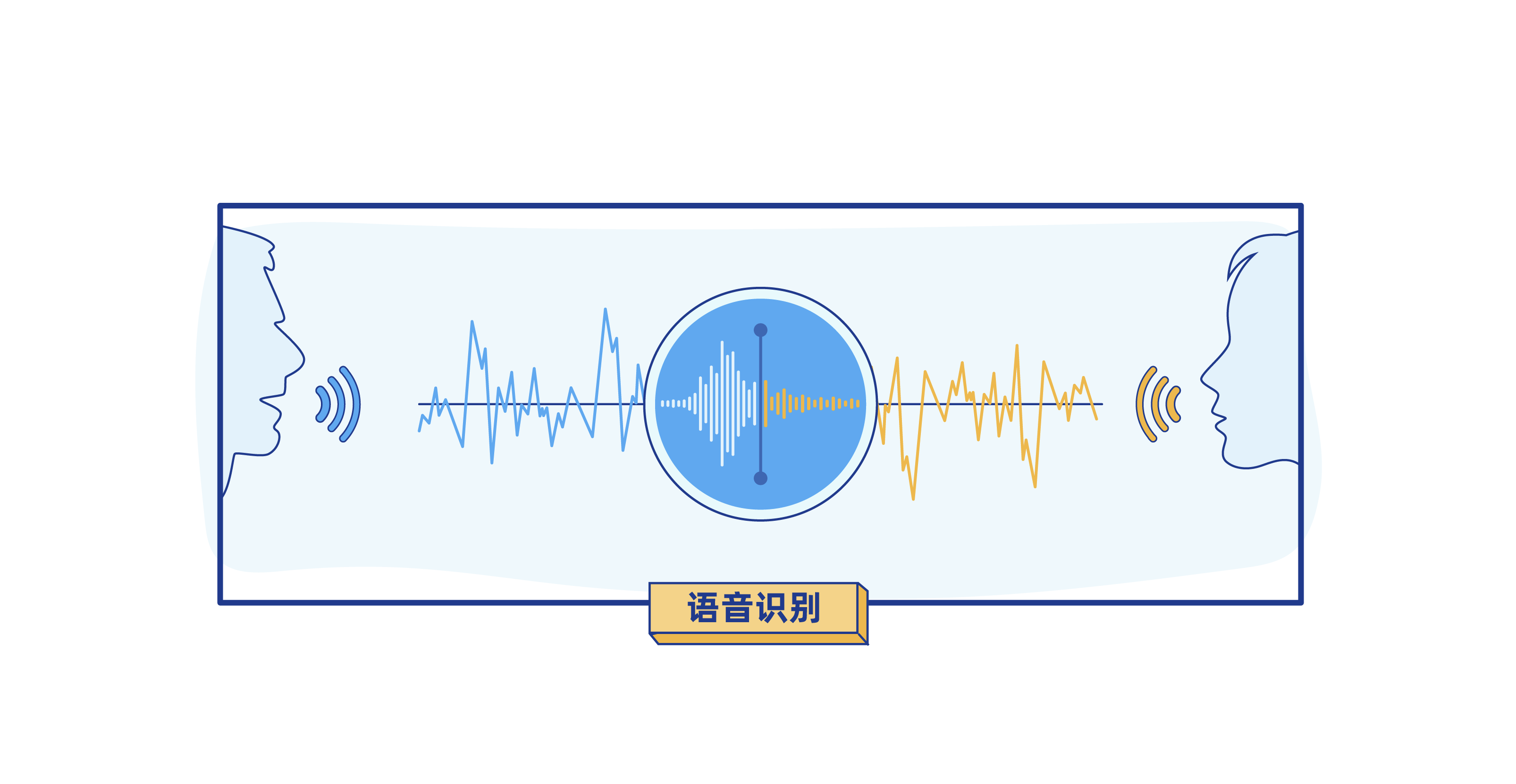
第三步: 将语音转化成文本,便于机器学习
《女心理师》中的智能语音识别系统还能将语音内容实时转译成文本,并根据语音内容做出预警提醒。
计算机是如何听懂人类语言的呢?
所谓"人工智能",其中离不开"人工"的作用。实现智能语音识别的本质其实是将声音波形特征和特定文字一一匹配。这就需要在前期构建 语音样本库,由人工对语音样本进行标注,然后抽取出声音波形特征和文字的对应关系,让机器去学习。通过大量的训练、学习,计算机便拥有了将语音转化成文字的能力。

不过,在该阶段,转译后的文字对于计算机而言,就如同"天书",计算机并不能理解文字中蕴含的涵义,更不能Get到文字中说话人所要表达的情感。

因此,还需要教会计算机听"懂"人话,并使其拥有一定程度的专业知识水平,能够对文本内容进行情感分析和自主推理,从而实现智能预警,更好地辅助研判。
具体如何实现呢?一起来看第四步。
第四步: 对文本内容进行情感分析
我们知道,句子由词汇组成,包括停顿词(的、和、地、得、之间......),正面评价词(价格便宜、干净、美丽、物美价廉......),负面评价词(埋汰、脏、差、坏......),程度词(还行、非常好、凑合、一般、特别......),疑问词(难道、岂、居然、竟然、究竟、简直、难道、反倒、何尝、何必......)以及否定词(不、莫、无、弗、非、否......)等等。要理解一句话的情感和态度,就需要对句子中各个词汇的词性进行分析。 所以我们需要对上阶段转译好的文本进行分词处理,然后综合每个词的情感倾向最终得出该语句整体的情感态度。
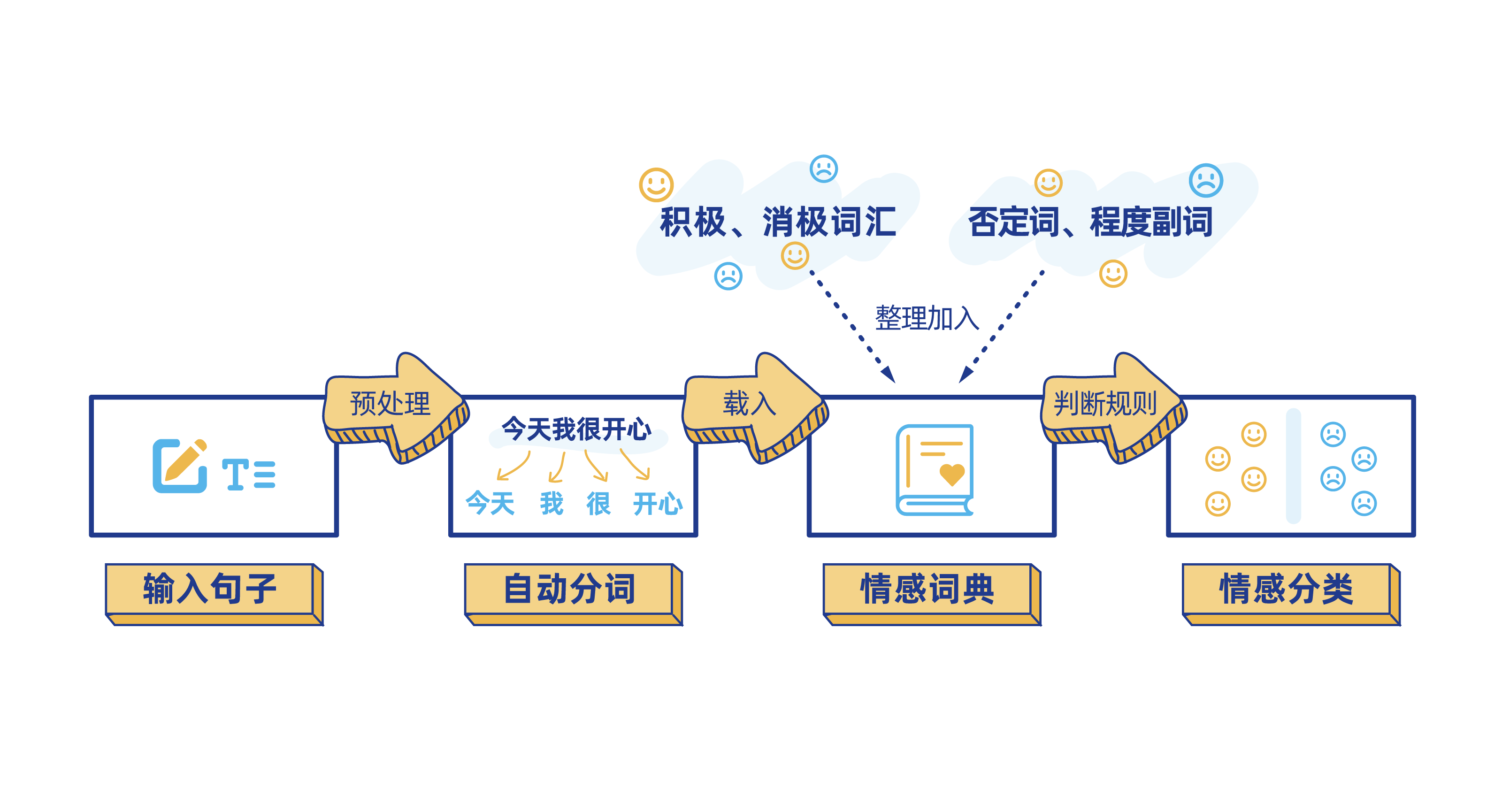
计算机在进行文本的情感分析时,还是要先将其转化为数学问题才能解决。
计算机一般采用如下类型的数学表达式来计算一句话的情感态度:

举个例子,比如在"难道非得让我说差么?" (疑问词"难道"往往和否定词结合起到双重否定的作用,有时人们也会把"难道"单独当成否定词来使用) 这样一句话中,"难道"和"非"都是否定词,所以该句话的整体分值就可以计算出来了,是(-1)^21-1 = -1,那么这句话要表达的就是偏负面的态度。
再比如"难道这样不好吗?"中,"难道"和"不"都是否定词,分值为(-1)^211=1,那这句话的情感就是偏正面的。
一般来说,词汇的情感是偏正面还是负面,在不同的领域有不同的标准和说法。比如,"声音大",在音响行业,其实就是非常正向的的词汇,但是在家电行业,说一个洗衣机"声音大",其实表达的是负向的态度。 所以,不同行业的算法工程师,都需要构建所属行业或领域的特色词库。
此时再看《女心理师》剧中的智能语音识别系统,就很好理解它的"聪明"所在了。在心理咨询或救援领域,"跳楼""自杀"这些都是负向词汇,"不用来找我了"这句话中也有否定词"不"。因此当系统判断语音内容非常消极和负面时,就会自动弹出相应警报。

▲图片来源:优酷网剧《女心理师》
看到这步,恭喜你把左脚也踏进了智能语音识别科学的大门!
第五步: 构建行业知识图谱
可以看到,上图中的警报弹框中,还有"需要专业支持"的提醒,智能水平较高。其实,在实际生活场景中,很多电商、互联网医疗等行业的企业所建设的智能客服系统,也已经进化到非常高的智能水平了,它们不仅能够理解文本内容,还能自主做推理、联想,提出相关专业建议,辅助决策。
而这个程度的"脑力"实现,使用到的正是 知识图谱(Knowledge Graph)的技术。
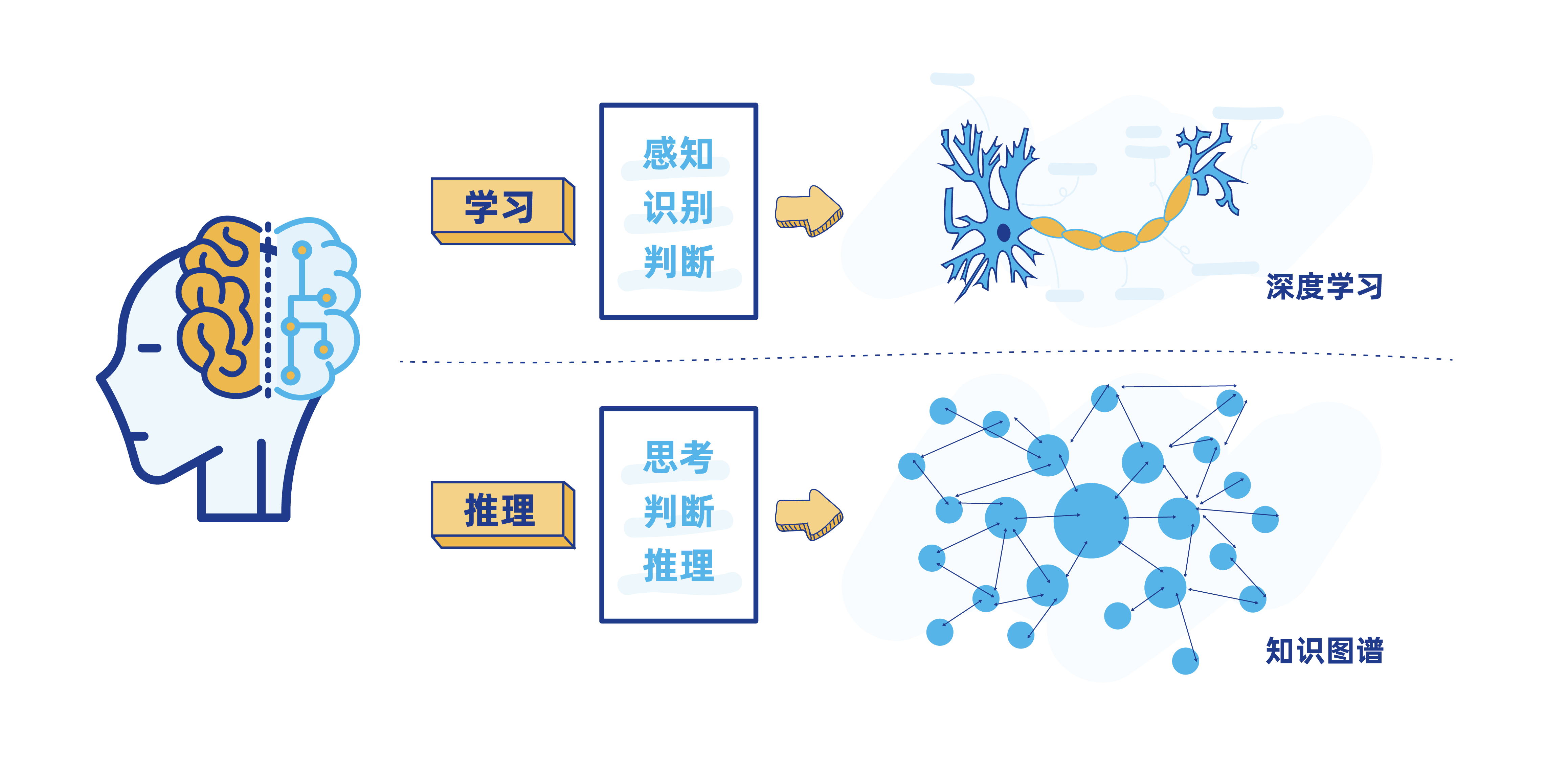
知识图谱,本质上是一种揭示实体之间关系的语义网络,在搜索引擎、文本挖掘等领域有广泛应用。比如,当用户使用搜索引擎搜索"水果"时,会出现"水果的分类""水果的营养价值""最近的水果店在哪里"等关联词条,其背后使用的就是"水果"领域的知识图谱。
我们在实际生活中使用到的智能客服系统,其"智力"也正是来自于对特定行业知识图谱的不断学习。比如,电商平台的智能客服,背后依托的就是商品、订单、物流等方面的知识图谱。当用户咨询某个商品时,智能客服就会调用相关图谱,为用户提供商品详情、订单状态、物流状态、商品历史价格走势、商品使用方式等相关信息和建议。
看完本文,相信大家已经比较深刻理解智能语音识别、知识图谱等的技术原理了。技术不仅是生产力,更是有温度的。在正确的应用姿势下,大数据和人工智能在各行各业都能发挥出巨大的正向价值。
个推的图挖掘实践
作为一家数据智能公司,个推在知识图谱、图挖掘等方面的实践也非常丰富。比如,个推在开展大数据抗疫时,正是基于万亿级图的构建和挖掘,实现了 疫情态势研判、传播路径分析等场景应用。详情查看>> 2021WAIC | 每日互动CTO叶新江:万亿级图下的数据智能
Original: https://blog.csdn.net/Androilly/article/details/122199531
Author: 个推技术
Title: 个推科普漫画,解读《女心理师》中的智能语音识别系统
相关阅读3
Title: 【Tensorflow】菜鸟学TensorFlow 2.0:TensorFlow2.0安装与环境配置
菜鸟学TensorFlow 2.0:TensorFlow2.0安装与环境配置
Tensorflow是当今深度学习很流行的一个框架,它是由谷歌开发的深度学习框架到现在已经发布到了TF2.0版本了。TensorFlow 2 废弃了大量重复的接口,将 Keras 作为搭建网络的主力接口,也添加了很多新的特性,极大地改进了可用性,能有效地减少代码量。TF的安装有两个版本一个是CPU版另一个是GPU版。当然GPU上运行TF的速度自然比CPU会快,但是自然它的安装也比CPU版要麻烦。
CPU版的TF的安装十分的简单,这里当然不作叙述,本文主要是想记录下自己安装GPU版中遇到的一些问题和坑。
-
TensorFlow依赖环境搭建
-
硬件环境
操作系统:Windows10
显卡型号:nvidia-smi,显卡一定要是NVDIA的AMD的不行,因为在后续要安装CUDA.
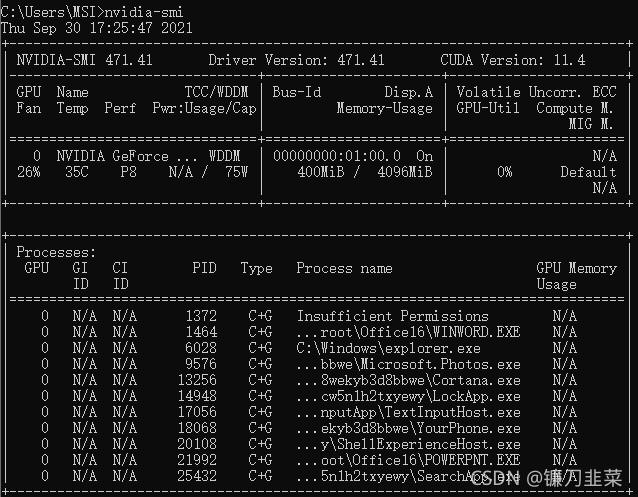
2. 软件要求
必须在系统中安装以下 NVIDIA® 软件:
- NVIDIA® GPU 驱动程序 - CUDA® 11.2 要求 450.80.02 或更高版本。
- CUDA® 工具包:TensorFlow 支持 CUDA® 11.2(TensorFlow 2.5.0 及更高版本)
- CUDA® 工具包附带的 CUPTI。
- cuDNN SDK 8.1.0 cuDNN 版本。
(可选)TensorRT 6.0,可缩短用某些模型进行推断的延迟时间并提高吞吐量。
1)安装 Anaconda3/
可以到清华大学开源软件镜像站下载:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/

2)安装CUDA Toolkit 11.4
地址:https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64

下载完成后,双击exe程序,开始安装CUDA,这里选择自定义安装(高级):
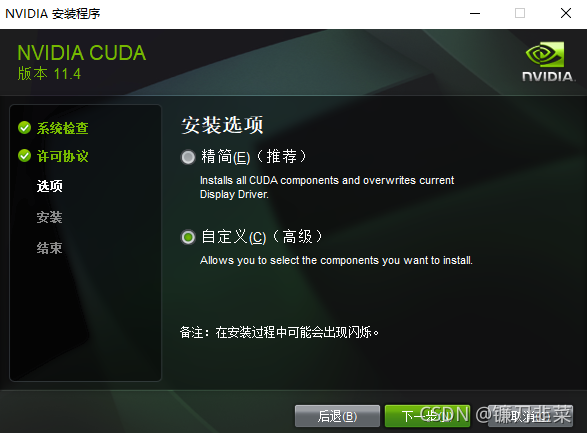
然后进入下一步,取消勾选NVIDIA GeForce Experience,然后展开CUDA列,里边有Visual Studio Integration,这里如果电脑上安装了Visual Studio,则可以勾选,否则取消勾选。由于深度学习的开发很多都是在轻量级开发工具中开发,因此取消勾选即可。

然后打开Driver components,确保Display Driver版本号高于当前版本号,否则取消勾选:

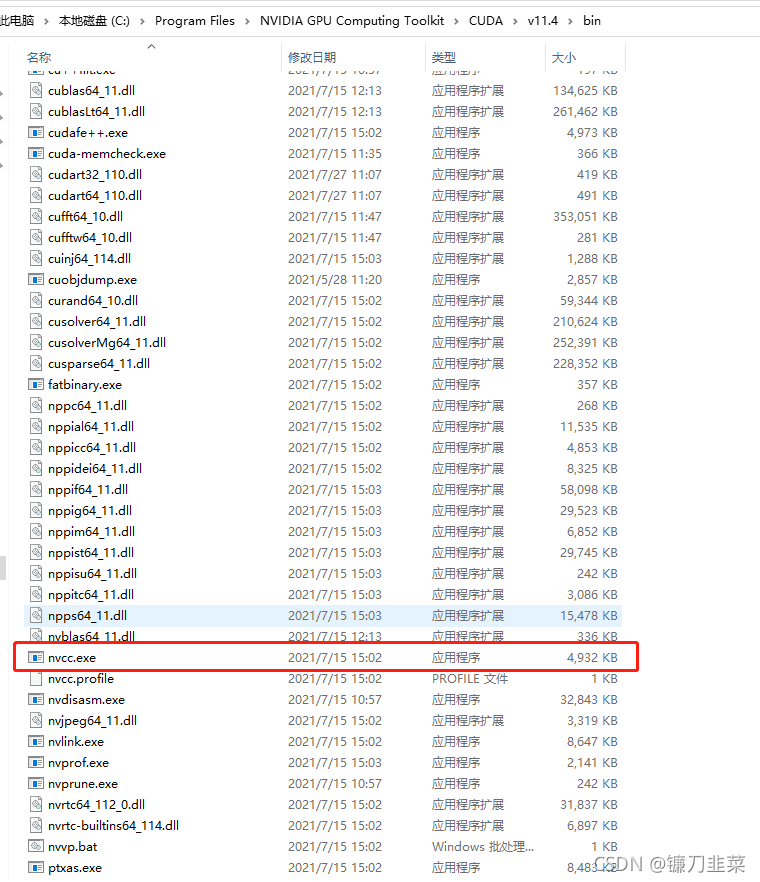
安装完成后,检验安装是否成功。在C盘默认安装路径:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\bin
找到nvcc.exe
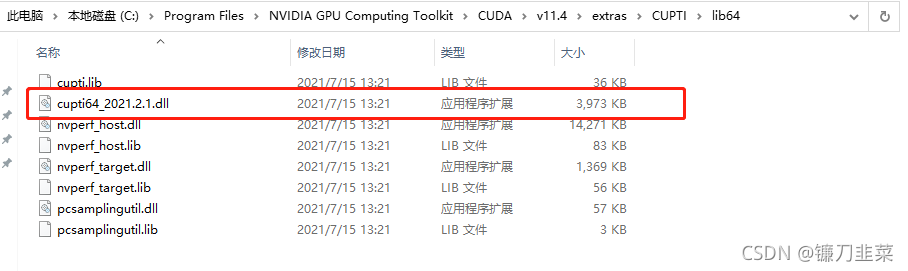
额外确认cputi安装情况。路径:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\extras\CUPTI\lib64
3)安装cuDNN
下载cuDNN需要NVIDIA注册。下载地址为:https://developer.nvidia.com/rdp/cudnn-archive
因为上面安装的版本为11.4,所以这里需要下载如下版本:
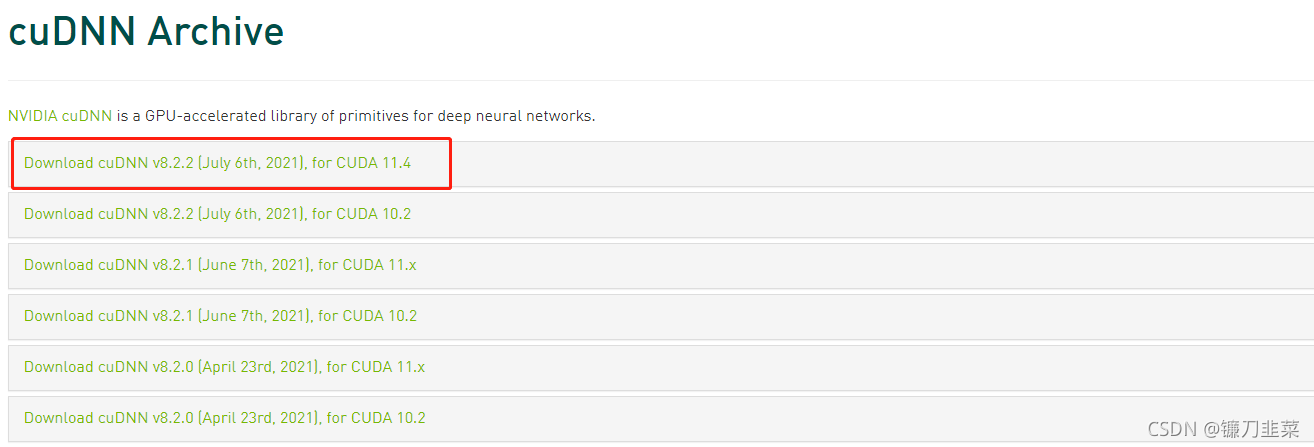
选择windows平台版本:
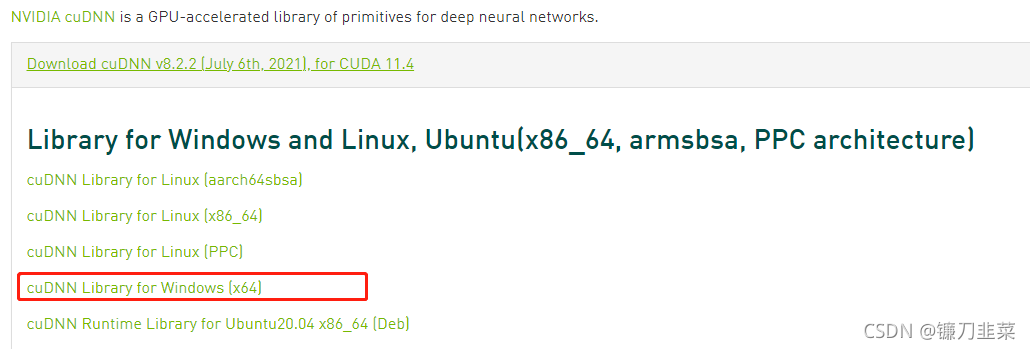
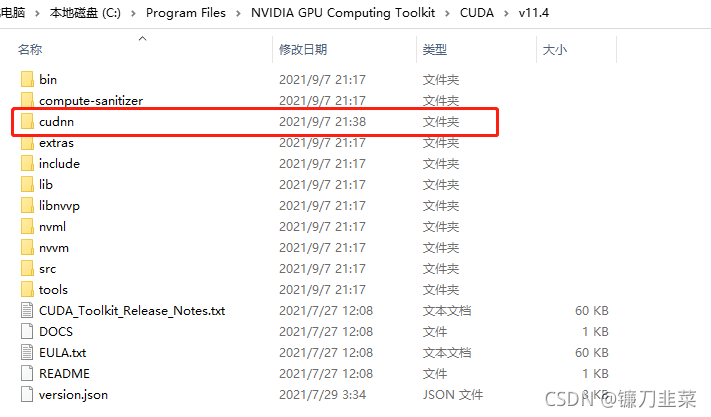
下载完成后,将其解压,然后将其重命名为cudnn,然后复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4
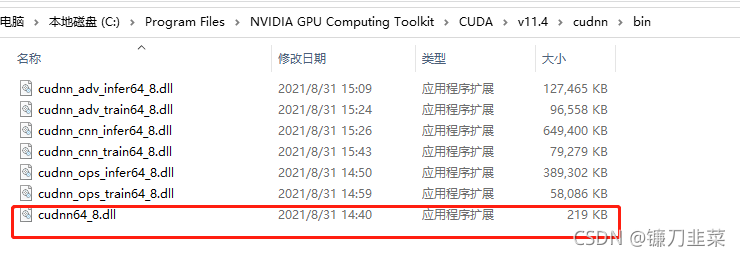
进入cudnn的bin目录,确认cudnn64动态库:
4)配置环境变量
将如下路径配置到系统PATH中,并将其放在一起,置顶。
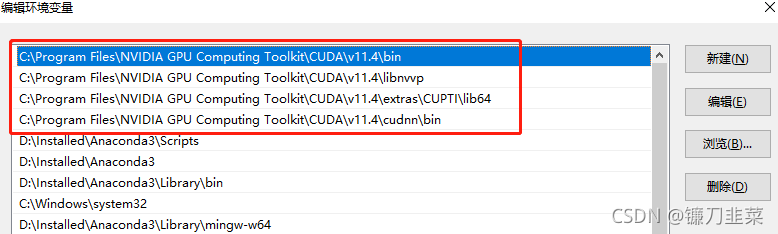
5)测试CUDA安装是否成功
使用命令 nvcc -V
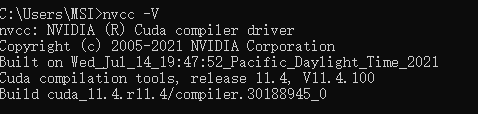
; 3. TensorFlow 2安装
pip install --upgrade pip
pip install tensorflow-gpu
pip install tf-nightly
验证tensorflow安装情况:

- 第一个TensorFlow程序
>>> import tensorflow as tf
>>> A = tf.constant([[1,2],[3,4]])
>>> B = tf.constant([[5,6],[7,8]])
>>> C = tf.matmul(A,B)
>>> print(C)
tf.Tensor(
[[19 22]
[43 50]], shape=(2, 2), dtype=int32)
>>>
到这里就说明 TensorFlow 已经安装成功了。
Original: https://blog.csdn.net/ARPOSPF/article/details/120570063
Author: 镰刀韭菜
Title: 【Tensorflow】菜鸟学TensorFlow 2.0:TensorFlow2.0安装与环境配置