
随着一个《霍格沃茨:一段校史》风格的大字(呃,这字好像并不大......)标题的出现,无聊的我没事干,又开始整活了~
之前我做的程序,一个使用了Tkinter库,一个则是Pygame,总之都是带有图形化的界面的。但作为一个懒汉,我自然能懒必懒(这点我非常有自知之明),这次,我就来一个简单朴素的没有图形界面的程序。
这是一个闹钟,一个可以设定时间的闹钟(虽然操作的界面有点简陋,但丝毫不影响它的强大功能)。
首先,我们要编闹钟的响铃程序。
我们先新建一个文件,后缀是".pyw"(这样可以保证程序运行的时候不会弹出一个Python自带的窗口)。
首先,老规矩,第一行一定是:
然后,我们要导入所需的模块:
本次所需的模块不多,由于都是我原先安装好的,所以我也并不确定它们是否要用pip安装。当然,使用PyCharm进行编程可以自动为你安装你使用到的未安装的模块。
首先,我们需要获取电脑中的音乐。我们用os.walk获取Music文件夹中的所有ogg和mp3文件(这是由于我播放音乐使用的是Pygame,它似乎只支持这两种文件的音乐)。同时,通过对路径字符串的文字处理,提取出音乐名称存储入列表all_songs,并将其和原先的路径对应存入字典all_songs_dict。这时存入这两个变量中的音乐信息相当于一种保险机制,可以确保在找不到铃声文件时有备用铃声可以使用(当然,如果你的音乐文件夹是空的,这当然没用;但我不认为你的文件夹中会没有音乐)。
我们的闹钟时间当然需要存储在某个文件中,这样才能防止这个信息丢失。于是,我们打开了一个"alarm_list.txt"文件(为防止文件不存在,我们需要先用写入的模式打开一次文件,这样可以在文件不存在时创建;同时为防止这个操作清空文件,我们必须用追加写的"a"而不是"w")。我们会读取文件中的内容,并删除换行后存入alarm_list。我们不必忧心文件中有无法识别的内容,因为文件是通过另一个编辑程序写入的,那个程序会保证文件内容是这个程序所能识别的。
同理,对"dates_one.txt"和"dates_two.txt"也需要类似的处理。当然,因为文件中存储有表格,我们有必要用eval()函数回复它的表格类型。第二个不同在于这两个文件的内容会被存入一个字典,而不是表格。
在对"songs_one.txt"和"songs_two.txt"的处理中,我们就需要用到表格all_songs了。为保证音乐都存在,它会尝试打开路径所指向的文件。如果找不到文件,它会将音乐修改为all_songs中所记录的随机一个音乐(在这里可以进行改善:加一个if判断,如果路径指向的文件后缀不是".mp3"或".ogg",则也要修改音乐。这个工作感兴趣的读者可以自行加上,在此我不再给出代码——这主要是由于我在解释我的程序代码时即使发现了不合理之处,只要不是大问题,就也不愿再行修改的习惯)。
我的删除闹钟的程序片段不知为何,一直有一些BUG,会在删除处于结尾的闹钟时留下空行(这会导致程序运行出错)。于是,我们很有必要对其的后果作出一些挽回:将每一个文件结尾的换行符删除。而这个程序就是进行了这样一个工作。
这就是刚刚提到的有BUG的删除程序。这里输入的i是闹钟的时间(在这个程序中,闹钟时间具有唯一性,一个时间只对应一个闹钟)。这个程序试图删除i所对应的所有信息,但是,对于位于文件和表格结尾的闹钟,它不能有效处理。我试图使它删除上一条末尾的换行符,但显然出现了某种错误。我因此不得不另加一行代码来弥补它的后果。
播放程序,用于在时间到时播放音乐。这里不仅使用了Pygame的音乐播放,还使用了Pynput的键盘监听,这样可以在按下空格时关闭音乐(当然,有时候在打字时也许会误关闹钟,但这无关紧要——你完全可以设置另一个不常用的键来关闭闹钟)。
毫无疑问,在这些代码后面,跟的是程序的核心代码。但接下来这一段无疑令人失望:
没错,这就是前面的存储载入的代码。这是为了刷新对文件的读取,毕竟,你很有可能会在程序运行时修改闹钟。
这才是你们期待的核心代码(虽然功能很核心,但却还是很简单的)我们将闹钟列表遍历,将时间与闹钟所设置的时间所比对,如果现在是某个闹钟所设定的时间,同时现在日期在一星期中的位置(暂且就这么表述,我突然发现像"星期一"之类的词似乎......没有一个统称)也存在于对应的表格中,同时现在的日期也没有超过闹钟的截止日期,我们就会响铃(铃声会遵从该闹钟的设置)。同时,对于已截至的闹钟,它会予以删除。
这样,响铃的程序就已初步完成。但是,为了使程序不挤占进程(很多闹钟程序都会如此),我们还是有必要加上这一段代码:
当然最后得运行函数:
这样,我们就把闹钟的程序完成了。
附上完整代码:
你是否疑惑:我们如何设置闹钟?这后面的内容,我们就来解决这一件事。
最简单的办法,当然是将闹钟手动输入到文件中。"alarm_list.txt"中需要输入的是闹钟的时间,格式"00:00";"dates_one.txt"和"songs_one.txt"中储存的其实也是这一内容。"songs_two.txt"中是音乐的路径,这个也没问题;最重要的是"dates_two.txt"。我们不妨举个例子。"['1', '2', '3', '4', '5', 'kill9999&99']",这是什么意思?"1""2""3""4""5"指响铃的星期,其中"0"代表周日,"1"代表周一,后面以此类推。"kill9999&99"是闹钟截至日期,或者说有效期,"9999"是年,"99"是在这年中的天数,"kill9999&99"意为"有效期至公元9999年的4月9日",在这里我们可以简单粗暴的认为是永不停止(因为一般来说,这个程序是绝对不会运行到那一天的)。也就是说"['1', '2', '3', '4', '5', 'kill9999&99']"的意思大概就是,每周工作日响铃,永远有效。
当然,这么做实际会比较繁琐,因此我经过一连串更繁琐的步骤后,制作了一个闹钟的设置程序(在此只给出代码,因为它里面主要都是些简单却反复的内容):
这个程序不能是pyw文件,而必须是py(因为它需要输入与输出)。我们需要将其和刚刚的响铃程序放在同一个文件夹中,并对两个程序分别创建一个快捷方式。然后,我们要将响铃程序放入"启动"文件夹(在C盘,名称叫"StartUp"。它在我的电脑上路径为"C:\ProgramData\Microsoft\Windows\Start Menu\Programs\StartUp",不同电脑上路径可能稍有不同,但搜索总是能找到的)。而另一个,这个设置程序的快捷方式,你可以放在桌面,方便打开程序。
同作者推荐(本人较为满意的其他作品,点击连接看看吧):
声明:
Original: https://www.cnblogs.com/godforever/p/16418496.html
Author: GodForever
Title: Python:一个闹钟
相关阅读1
Title: python入门基础(6)--语句基础(if语句、while语句)
一、if语句
if 语句让你能够检查程序的当前状态,并据此采取相应的措施。if语句可应用于列表,以另一种方式处理列表中的大多数元素,以及特定值的元素
1、简单示例
names=['xiaozhan','caiyilin','zhoushen','DAOlang','huangxiaoming']
for name in names:
if name == 'caiyilin': #注意:双等号'=='解读为"变量name的值是否为'caiyilin'
print(name.upper())
else:
print(name.title())
每条if语句的核心都是一个值为 True 或 False 的表达式,这种表达式被称为条件测试(如上述条件 name == 'caiyilin'),根据条件测试的值为 True 还是 False 来决定是否执行 if 语句中的代码。如果条件测试的值为True ,Python就执行紧跟在 if 语句后面的代码;如果为 False , Python 就忽略这些代码,不执行。
在Python中检查是否相等时区分大小写,例如,两个大小写不同的值会被视为不相等
my_fav_name = 'daolang'
for name in names:
if name == my_fav_name:
print('Yes')
print('No')
print('\n')
for name in names:
if name.lower() == my_fav_name:
print('Yes')
print('No')
print('\n')
#下方使用 if......else语句
for name in names:
if name.lower() != my_fav_name: #检查是否不相等
print('NO')
else:
print('YES')
查多个条件:有时候需要两多个条件都为True时才执行操作;或者多个条件中,只满足一个条件为True时就执行操作,在这些情况下,可分别使用关键字and和or
ages=['73','12','60','1','10','55','13']
for age in ages:
if age > str(60): #注意:ages中为列表字符串,所以age也是字符串,无法与整型的数字相比,需要先将数字转化为字符串再比较。
print("The "+str(age)+" years has retired!")
elif age > str(18) and age#两个条件都为True时
print("The "+str(age)+" years is an Adult!")
elif age > str(12):
print("The "+str(age)+" years is a student!")
else:
print("The "+str(age)+" years is a child!")
二、while语句
for 循环用于针对集合中的每个元素都一个代码块,而 while 循环不断地运行,直到指定的条件不满足为止。
例如,while 循环来数数
current_number = 1
while current_number :
print(current_number)
current_number += 1
print("\n")
print(current_number)
当x
Original: https://www.cnblogs.com/codingchen/p/16133182.html
Author: PursuitingPeak
Title: python入门基础(6)--语句基础(if语句、while语句)
相关阅读2
Title: 微服务架构 | 10. 分布式追踪
- 前言
- 1. 分布式追踪的基本概念
- 1.1 该技术的提出背景
- 1.2 分布式追踪的几种不同方向
- 1.3 日志聚合架构的概念图
- 1.4 几种开源的日志聚合产品
- 1.5 目前几种流行的分布式追踪组件对比
- 2. Spring Cloud Sleuth
- 3. Papertrail
- 4. Zipkin
- 最后
前言
参考资料:
《Spring Microservices in Action》
《Spring Cloud Alibaba 微服务原理与实战》
《B站 尚硅谷 SpringCloud 框架开发教程 周阳》
微服务的调试问题会比较复杂,可以使用分布式追踪解决;
1. 分布式追踪的基本概念
又称:分布式请求链路跟踪;
1.1 该技术的提出背景
- 在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,每一个前段请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败;
1.2 分布式追踪的几种不同方向
- 追踪日志链 -> Sleuth:使用一个 追踪 ID 将跨多个服务的日志串联起来
- 日志聚合 -> Papertrail:将所有服务实例的日志流到一个集中的聚合点;
- 可视化事务流 -> Zipkin:
- 正好对应下面将要介绍的三种技术;
1.3 日志聚合架构的概念图

1.4 几种开源的日志聚合产品
产品名称 实现模式 备注 Elasticsearch;Logstash;Kibana (ELK) 开源;商业;通常实施与内部部署 通用搜索引擎;可以通过 ELK 技术栈进行日志聚合;需要最多的手工操作 Graylog 开源;商业;内部部署 设计为在内部安装的开源平台 Splunk 商业;内部部署和基于云 最古老且最全面的日志管理和聚合工具;最初是内部部署,后来提供云服务 Sumo Logic 免费增值模式;商业;基于云 免费增值模式/分层定价模型;仅作为云服务运行;需要用公司的工作账户去注册 Papertrail 免费增值模式;商业;基于云 免费增值模式/分层定价模型;仅作为云服务运行;
1.5 目前几种流行的分布式追踪组件对比
名称 厂商 特点(优点) 缺点 Spring Cloud Sleuth Spring Cloud Papertrail Zipkin
2. Spring Cloud Sleuth
Spring Cloud Sleuth 是一个 Spring Cloud 项目,它将关联 ID 装备到 HTTP 调用上,并将生成的跟踪数据提供给 OpenZipkin 的钩子。Spring Cloud Sleuth 通过添加过滤器并与其他 Spring 组件进行交互,将生成的关联 ID 传递到所有系统调用;
- 即:使用追踪D将跨多个服务的事务链接在一起;
- 点击访问:微服务架构 | 10.1 使用 Sleuth 追踪服务调用链;
3. Papertrail
Papertrail 是一种基于云的服务(基于免费增值),允许开发人员将来自多个源的日志数据聚合到单个可搜索的数据库中。开发人员可以为日志聚合选择的解决方案包括内部部署解决方案、基于云解决方案、开源解决方案和商业解决方案;
- 即:来自多个服务的日志数据聚合为一个可搜索的源 ;
- 点击访问:微服务架构 | 10.2 使用 Papertrail 实现日志聚合;
4. Zipkin
Zipkin 是一种开源数据可视化工具,可以显示跨多个服务的事务流。Zipkin 允许开发人员将事务分解到它的组件块中,并可视化地识别可能存在性能热点的位置;
- 即:可视化跨多个服务的用户事务流,并理解事务每个部分的性能特征 ;
- 点击访问:微服务架构 | 10.3 使用 Zipkin 可视化日志追踪;
最后
新人制作,如有错误,欢迎指出,感激不尽! 欢迎关注公众号,会分享一些更日常的东西! 如需转载,请标注出处!

Original: https://www.cnblogs.com/dlhjw/p/15862699.html
Author: 多氯环己烷
Title: 微服务架构 | 10. 分布式追踪
相关阅读3
Title: scrapy爬虫框架使用
一、scrapy框架
1.什么是scrapy:
爬虫中封装好的一个明星框架。功能:高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式。
2.使用方法:
安装:
下载tiwisted,此处位下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
安装tiwisted,pip install tiwisted-xxxx
安装pywin32:pip install pywin32
安装scrapy:pip install scrapy
安装完成后在终端输入scrapy如果没有报错即安装成功。
创建项目:
输入 scrapy startprojet projectName 创建项目

创建爬虫文件:cd至spiders文件夹下,在终端输入 scrapy genspider spidername www.xxx.com 用以创建爬虫文件。

二、数据解析
此处使用汽x之家做个样例
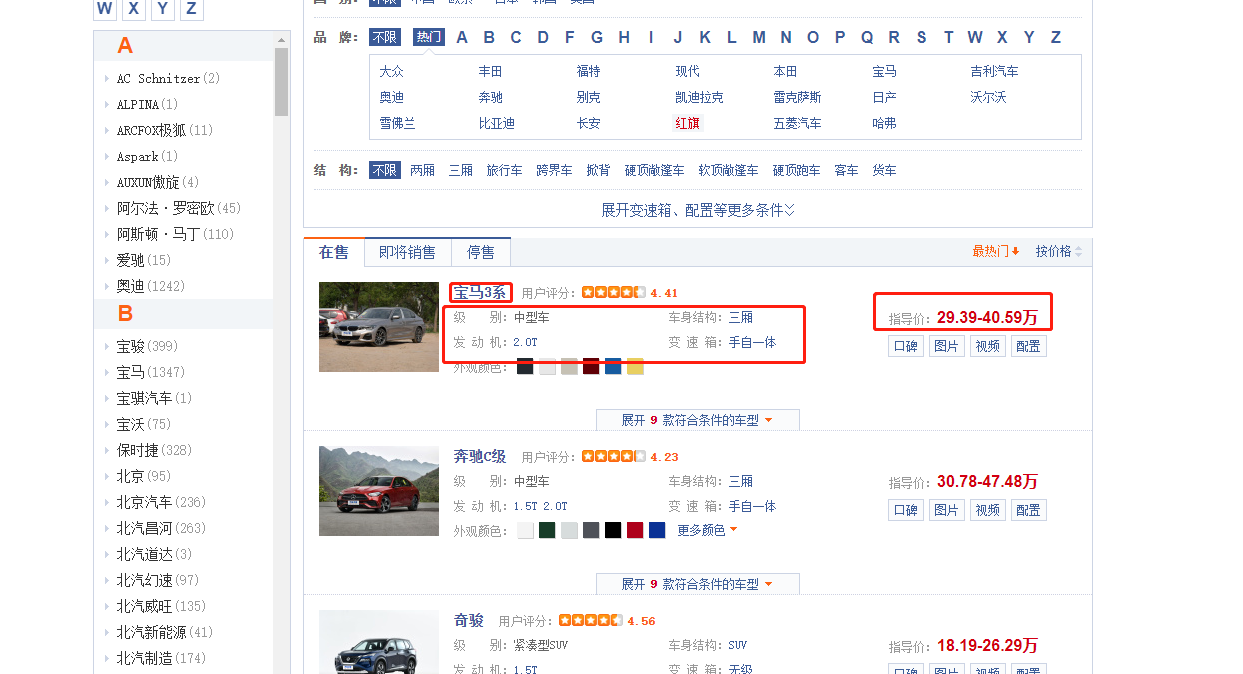
通过数据解析来获取网站中的汽车名称,级别,发动机,车身结构,变速箱以及售价数据
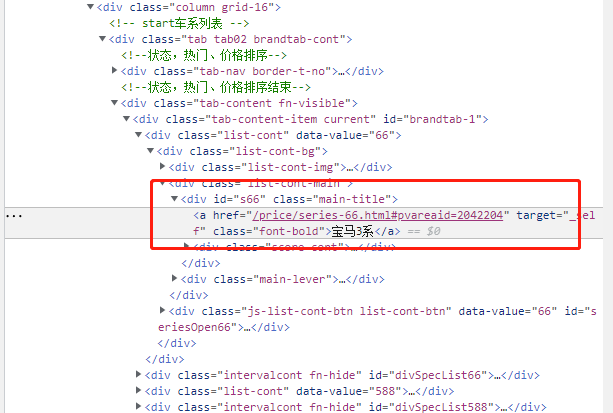
通过浏览器的抓包工具可已看出将要爬取数据的所在位置信息
在spider文件中使用小xpath表达式来解析想要获取的数据
undefined
import scrapyclass HomeStartSpider(scrapy.Spider): name = 'home_start' # 此处为允许使用的url通常情况下选择注释 # allowed_domains = ['www.xxxx.com'] # 起始url start_urls = ['https://car.autohome.com.cn/price/list-0-0-0-0-0-0-0-0-0-0-0-0-0-0-0-1.html'] def parse(self, response): #编写xpath表达式 div = response.xpath('//div[@id="brandtab-1"]/div[@class="list-cont"]') for div_list in div: # 汽车的详细信息地址 detail_url = 'https://car.autohome.com.cn/' + div_list.xpath('./div/div[2]/div[1]/a/@href').extract_first() #汽车名称 car_name = div_list.xpath('./div/div[2]/div[1]/a/text()').extract_first() #汽车级别 car_level = div_list.xpath('./div/div[2]/div[2]/div/ul/li[1]/span/text()').extract_first() #车身结构 car_body = div_list.xpath('./div/div[2]/div[2]/div/ul/li[2]/a/text()').extract_first() #发动机 car_engine = div_list.xpath('./div/div[2]/div[2]/div/ul/li[3]/span/a/text()').extract_first() #变速箱 trancase = div_list.xpath('./div/div[2]/div[2]/div/ul/li[4]/a/text()').extract_first() #价格 carprice = div_list.xpath('./div/div[2]/div[2]/div[2]/div/span/span/text()').extract_first() print(detail_url,car_name,car_level,car_body,car_engine,trancase,carprice)
undefined
在终端运行spider文件查看是否成功

三、持久化存储
scrapy 的持久化存储分类基于管道存储,和基于终端指令存储
基于终端指令存储方式简单便捷但是局限性强;持久化存储对应的文本文件的类型只可以为:'json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle
基于终端的存储方式
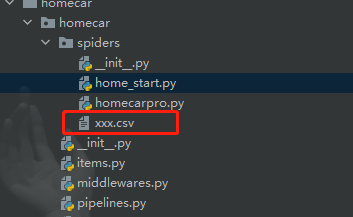
C:\Users\admin\Desktop\pythonProject2\homecar\homecar\spiders>scrapy crawl home_start -o xxx.csv
运行后即可在文件夹下查看到保存好的数据
基于管道的持久化存储
.items:存储解析到的页面数据
.pipelines:处理持久化存储的相关操作
.代码实现流程:
1.将解析到的页面数据存储到items对象
2.使用yield关键字将items提交给管道文件进行处理
3.在管道文件中编写代码完成数据存储的操作
4.在配置文件中开启管道操作
在homestart.py中使用将汽车的信息穿入item
import datetime
from TJJ.items import TjjItem
import scrapy
class TjjcjSpider(scrapy.Spider):
name = 'tjjcj'
# 此处为允许使用的url通常情况下选择注释
# allowed_domains = ['www.xxxx.com']
# 起始url
start_urls = ['https://car.autohome.com.cn/price/list-0-0-0-0-0-0-0-0-0-0-0-0-0-0-0-1.html']
def parse(self, response):
# 编写xpath表达式
div = response.xpath('//div[@id="brandtab-1"]/div[@class="list-cont"]')
for div_list in div:
# 汽车的详细信息地址
detail_url = 'https://car.autohome.com.cn/' + div_list.xpath('./div/div[2]/div[1]/a/@href').extract_first()
# 汽车名称
car_name = div_list.xpath('./div/div[2]/div[1]/a/text()').extract_first()
# 汽车级别
car_level = div_list.xpath('./div/div[2]/div[2]/div/ul/li[1]/span/text()').extract_first()
# 车身结构
car_body = div_list.xpath('./div/div[2]/div[2]/div/ul/li[2]/a/text()').extract_first()
# 发动机
car_engine = div_list.xpath('./div/div[2]/div[2]/div/ul/li[3]/span/a/text()').extract_first()
# 变速箱
trancase = div_list.xpath('./div/div[2]/div[2]/div/ul/li[4]/a/text()').extract_first()
# 价格
carprice = div_list.xpath('./div/div[2]/div[2]/div[2]/div/span/span/text()').extract_first()
print(detail_url, car_name, car_level, car_body, car_engine, trancase, carprice)
item = TjjItem()
item['detail_url'] = detail_url
item['car_name'] = car_name
item['car_level'] = car_level
item['car_body'] = car_body
item['car_engine'] = car_engine
item['trancase'] = trancase
item['carprice'] = carprice
yield item
Items.py 中的将接收的文本传入管道
import scrapy
class TjjItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()
detail_url = scrapy.Field()
car_name = scrapy.Field()
car_level = scrapy.Field()
car_body = scrapy.Field()
car_engine = scrapy.Field()
trancase = scrapy.Field()
carprice = scrapy.Field()
pipelines.py中对管道进行配置
class TjjPipeline(object):
fp = None
# 整个爬虫文件中,只会在开始爬虫的时候调用一次
def open_spider(self, spider):
print('开始爬虫')
self.fp = open('./homecar_pipe.txt', 'w', encoding='utf-8')
# 该方法就可以接受爬虫文件中提交过来的item对象,并且对item对象中存储的页面数据进行持久化存储
# 参数:item表示的就是接收到的item对象
# 每当爬虫文件向管道提交一次item,则该方法就会被执行一次
def prcess_item(self, item, spider):
detail_url = item['detail_url']
car_name = item['car_name']
car_level = item['car_level']
car_body = item['car_body']
car_engine = item['car_engine']
trancase = item['trancase']
carprice = item['carprice']
print(detail_url)
self.fp.write(detail_url + ":" + car_name + ":" + car_level + ":" + car_body + ":" +car_engine + ":" + trancase + ":" + carprice)
return item
# 整个爬虫过程中,该方法只会在开始爬虫的时候被调用一次
def close_spider(self, spider):
print('爬虫结束')
self.fp.close()
settings.py中开启管道服务
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'TJJ.pipelines.TjjPipeline': 300,
}
Original: https://www.cnblogs.com/t-dashuai/p/15162136.html
Author: 佟大帅
Title: scrapy爬虫框架使用