
最近几天我一直常用的Kubuntu(KDE yes!)更新至22.04后居然出现无法更改软件源的bug,去Kubuntu论坛一看有同样问题的人还不在少数,但却没有好的解决办法,故而只有备份数据装回Ubuntu。
由于学习需要,我需要再装一遍Pytorch。Pytorch在linux上安装推荐使用conda,使用conda安装会打包cudatoolkit等一系列必要的软件包,不过有一点值得注意,一定要换源,清华上交的都可以,而且要删除config文件里的--default,不然还是会使用默认源,我个人的计算机会在进度50多的时候显示网络问题终止安装。不过安装完成后仍有问题,第一是:
显示没有安装nvidia-tool-kit,第二是因为ubuntu22.04是前天才发布的版本,nvidia驱动没有自带。总而言之
返回的是False。
对于第二个问题,很容易解决,去英伟达官网搜索自己显卡对应的驱动安装即可,而且后来我对比了一下,在终端中输入:
是可以找到官网提供的显卡驱动,我选择的是版本号510的最新稳定驱动。使用 apt-get install指令安装即可
然后使用:
可以看到自己显卡的CUDA版本,我的是11.6,虽然我在conda里确实看到了cuda等一系列包已经正确配置。没办法,我只得再去官网重新下载cudatoolkit对应的版本,照着上面的指示安装即可,安装完成后
返回值为True,这个过程大概耗了我一个下午。
Original: https://www.cnblogs.com/BensonLau/p/16184095.html
Author: BensonLau
Title: Ubuntu下安装PyTorch杂记
相关阅读1
Title: 【2022知乎爬虫】我用Python爬虫爬了2300多条知乎评论!
您好,我是
@马哥python说
,一枚10年程序猿。
一、爬取目标
前些天我分享过一篇微博的爬虫:
https://www.cnblogs.com/mashukui/p/16414027.html
但是知乎平台和微博平台的不同之处在于,微博平台的数据用于分析社会舆论热点事件是极好的,毕竟是个偏娱乐化的社交平台。但知乎平台的评论更加客观、讨论内容更加有深度,更加有专业性,基于此想法,我开发出了这个知乎评论的爬虫。
二、展示爬取结果
我在知乎上搜索了5个关于"考研"的知乎回答,爬取了回答下方的评论数据,共计2300+条数据。
https://www.zhihu.com/question/291278869/answer/930193847
https://www.zhihu.com/question/291278869/answer/802226501
https://www.zhihu.com/question/291278869/answer/857896805
https://www.zhihu.com/question/291278869/answer/910489150
https://www.zhihu.com/question/291278869/answer/935352960
爬取字段,含:
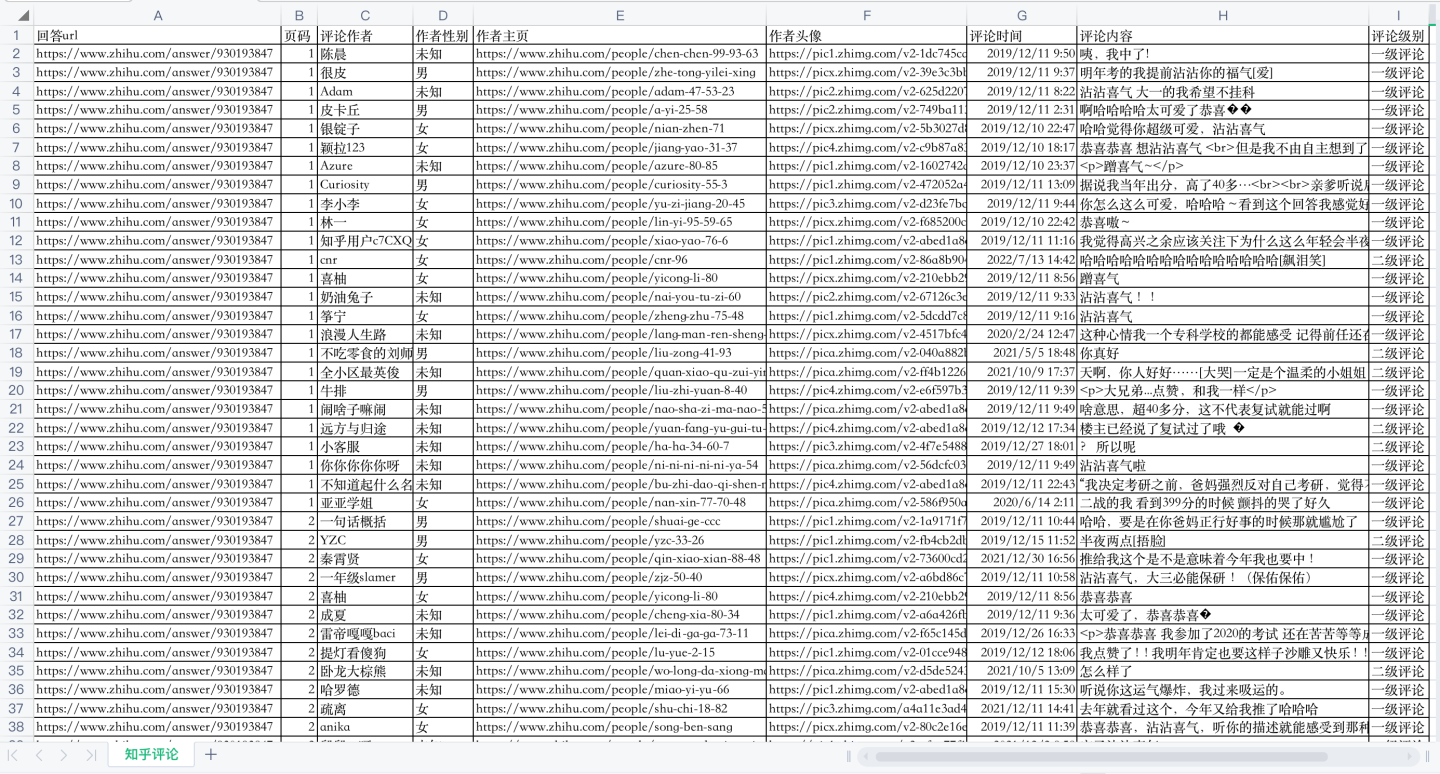
回答url、页码、评论作者、作者性别、作者主页、作者头像、评论时间、评论内容、评论级别。
部分数据截图:
三、爬虫代码讲解
3.1 分析知乎页面
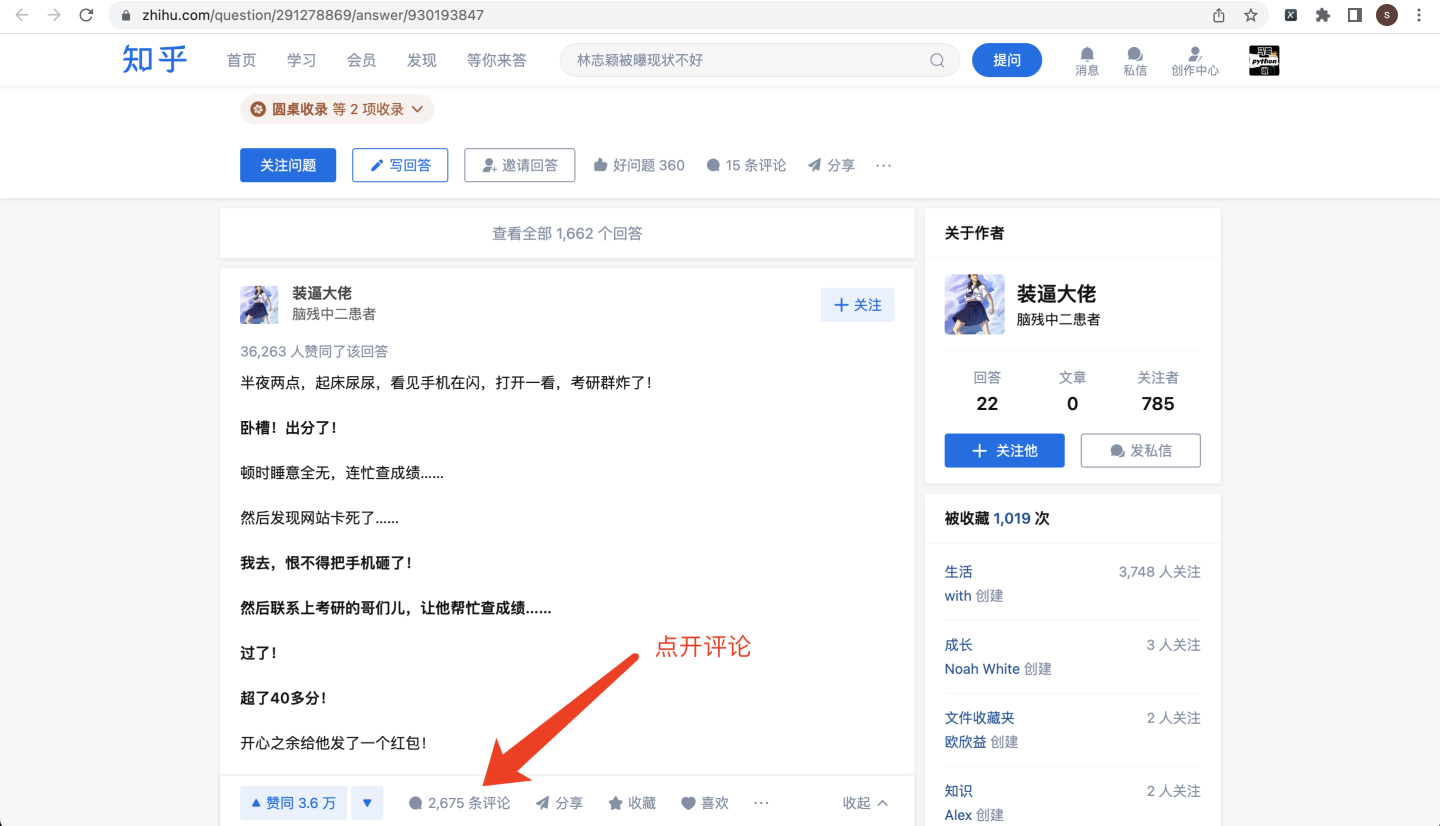
任意打开一个知乎回答,点开评论界面:
同时打开chrome浏览器的开发者模式,评论往下翻页,就会找到目标链接:
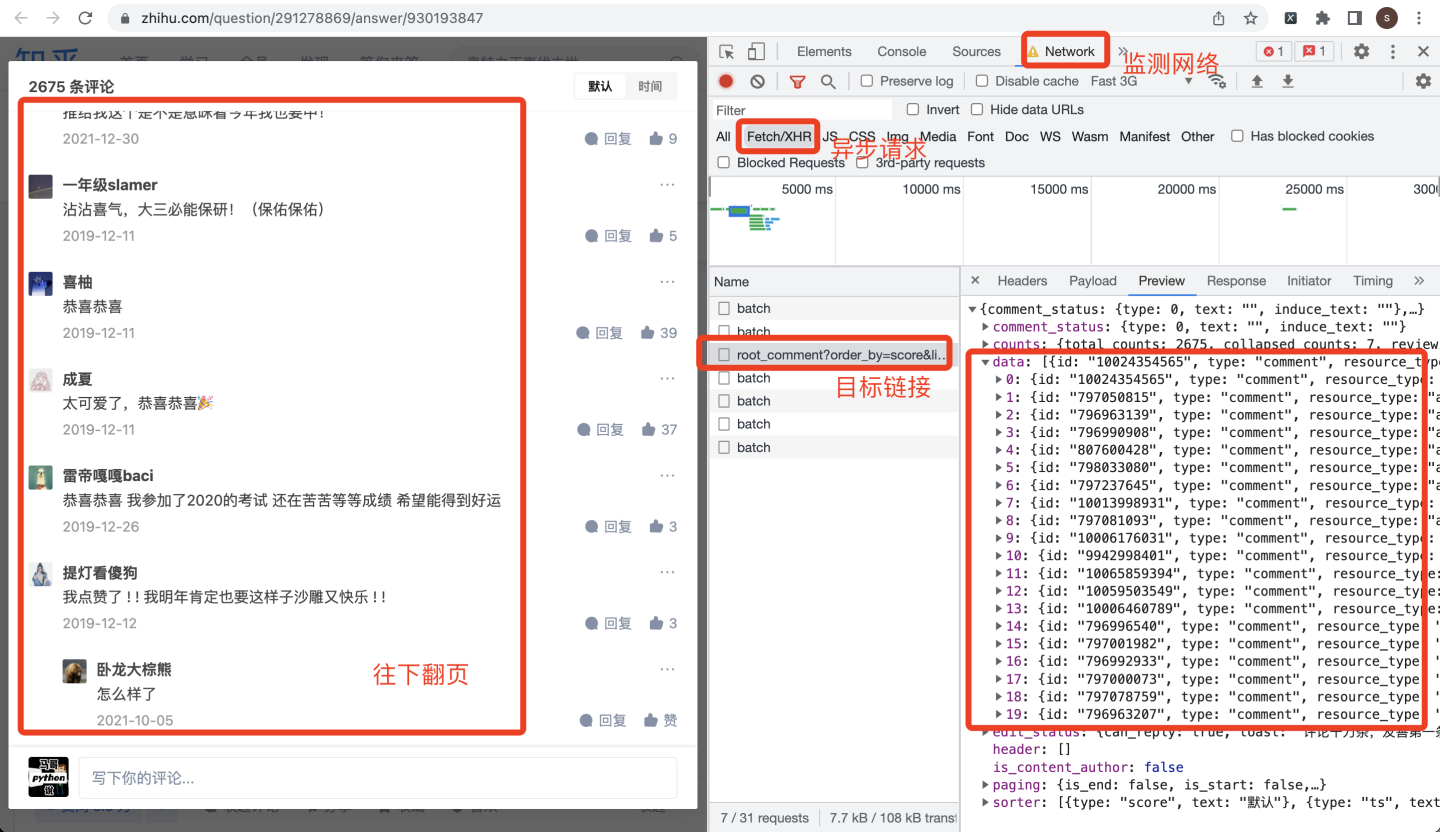
作为爬虫开发者,看到这种0-19的json数据,一定要敏感,这大概率就是评论数据了。猜测一下,每页有20条评论,逐级打开json数据:

基于此数据结构,开发爬虫代码。
3.2 爬虫代码
首先,导入用到的库:
import requests
import time
import pandas as pd
import os
从上面的截图可以看到,评论时间created_time是个10位时间戳,因此,定义一个转换时间的函数:
def trans_date(v_timestamp):
"""10位时间戳转换为时间字符串"""
timeArray = time.localtime(v_timestamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
作者的性别gender是0、1,所以也定义一个转换函数:
def tran_gender(gender_tag):
"""转换性别"""
if gender_tag == 1:
return '男'
elif gender_tag == 0:
return '女'
else: # -1
return '未知'
准备工作做好了,下面开始写爬虫。
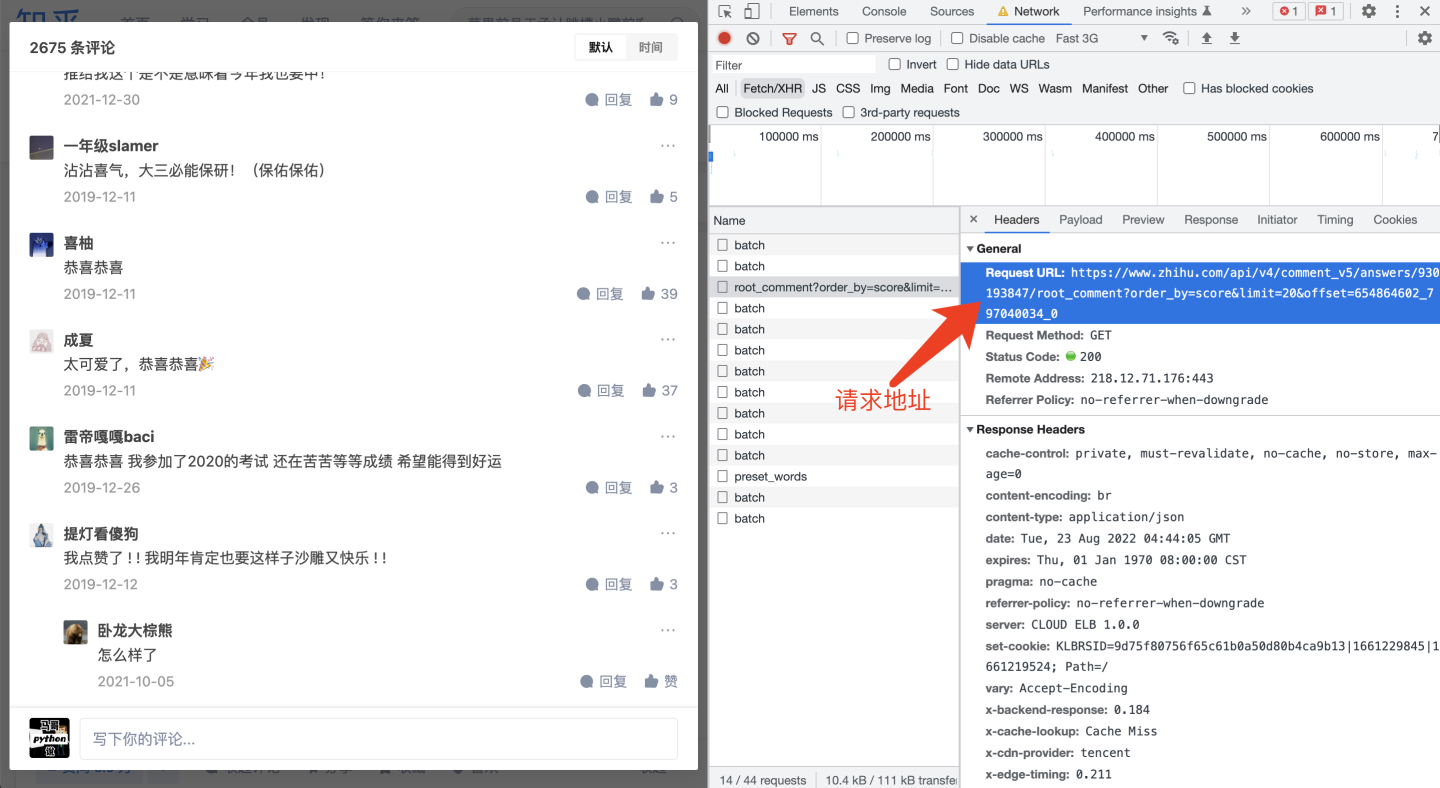
请求地址url,从哪里得到呢?
打开Headers,找到Request URL,直接复制下来,然后替换:
先提取出一共多少评论,用于计算后面的翻页次数:
url0 = 'https://www.zhihu.com/api/v4/answers/{}/root_comments?order=normal&limit=20&offset=0&status=open'.format(answer_id)
r0 = requests.get(url0, headers=headers) # 发送请求
total = r0.json()['common_counts'] # 一共多少条评论
print('一共{}条评论'.format(total))
计算翻页次数,直接用评论总数除以20就好了:
判断一共多少页(每页20条评论)
max_page = int(total / 20)
print('max_page:', max_page)
下面,再次发送请求,获取评论数据:
url = 'https://www.zhihu.com/api/v4/answers/{}/root_comments?order=normal&limit=20&offset={}&status=open'.format(answer_id,str(offset))
r = requests.get(url, headers=headers)
print('正在爬取第{}页'.format(i + 1))
j_data = r.json()
comments = j_data['data']
现在,所有数据都在comments里面了,开始for循环遍历处理:
字段过多,这里以评论作者、评论性别为例,其他字段同理:
for c in comments: # 一级评论
# 评论作者
author = c['author']['member']['name']
authors.append(author)
print('作者:', author)
# 作者性别
gender_tag = c['author']['member']['gender']
genders.append(tran_gender(gender_tag))
其他字段不再赘述。
需要注意的是,知乎评论分为一级评论和二级评论(二级评论就是一级评论的回复评论),所以,为了同时爬取到二级评论,开发以下逻辑:(同样以评论作者、评论性别为例,其他字段同理)
if c['child_comments']: # 如果二级评论存在
for child in c['child_comments']: # 二级评论
# 评论作者
print('子评论作者:', child['author']['member']['name'])
authors.append(child['author']['member']['name'])
# 作者性别
genders.append(tran_gender(child['author']['member']['gender']))
待所有字段处理好之后,把所有字段的列表数据拼装到DataFrame,to_csv保存到csv文件里,完毕!
df = pd.DataFrame(
{
'回答url': answer_urls,
'页码': [i + 1] * len(answer_urls),
'评论作者': authors,
'作者性别': genders,
'作者主页': author_homepages,
'作者头像': author_pics,
'评论时间': create_times,
'评论内容': contents,
'评论级别': child_tag,
}
)
保存到csv文件
df.to_csv(v_result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
完整代码中还涉及到避免数据重复、字段值拼接、判断翻页终止等细节逻辑,详细了解请见文末。
四、同步视频
演示视频:
https://www.zhihu.com/zvideo/1545723927430979584
五、完整源码
附:此处点击完整源码
更多爬虫源码: 点击前往
Original: https://www.cnblogs.com/mashukui/p/16622995.html
Author: 马哥python说
Title: 【2022知乎爬虫】我用Python爬虫爬了2300多条知乎评论!
相关阅读2
Title: 【Python】列表生成式中的八重境界
1. 引言
在Python中有非常多且好用的技巧,其中使用最多的是列表生成式,往往可以将复杂的逻辑用简单的语言来实现,本文重点介绍列表生成式应用的八重境界。 闲话少说,我们直接开始吧!
2. Level1: 基础用法
最最简单的列表生成式,举例如下:
a = [1, 2, 3]b = [n*2 for n in a]# b = [2, 4, 6]
上述代码实现了对列表中单个元素求平方的操作。
3. Level2: 加入条件语句
其实,我们可以在列表生成式中添加if来获取我们需要的元素,举例如下:
a = [1, 2, 3, 4, 5]b = [n for n in a if n<4]# b = [1, 2, 3]
上述代码中,我们添加了一个条件来决定在列表生成式中应该保留哪些元素。这里我们的条件是,如果n<4,则只保留小于4的数。
4. Level3: 加入 enumerate()
我们知道,枚举函数 ​enumerate()​可以同时生成元素以及相应的元素的索引。如果我们需要元素的索引以及元素,我们可以在列表生成式中使用函数 ​enumerate()​。 举例如下:
a = ["apple", "orange", "pear"]b = [(i,fruit) for i,fruit in enumerate(b)]# b is [(0,"apple"), (1,"orange"), (2,"pear")]
5. Level4: 加入 zip()
更进一步,我们知道函数 ​zip()​可以非常方便地使我们同时遍历2个或多个列表。 在列表生成式中加入函数 ​zip()​,样例如下:
a = ["apple", "orange", "pear"]a2 = ["pie", "juice", "cake"]b = [i+j for i,j in zip(a, a2)]# b is ["applepie", "orangejuice", "pearcake"]
6. Level5: 加入三目运算符
三元运算符 ​A if condition else B​允许我们根据条件将每个元素转换为其他元素。
在列表生成式中同样可以使用三目运算符,样例如下:
a = [56, 45, 76, 23]b = [("pass" if n>=50 else "fail") for n in a]# b is ["pass", "fail", "pass", "fail"]
7. Level6: 嵌套循环
其实,我们当然也可以在列表生成式中使用嵌套循环,我们来看个例子,如下:
a = [10, 20, 30]a2 = [1, 2, 3]b = [i+j for i in a for j in a2]# b is [11, 12, 13, 21, 22, 23, 31, 32, 33]
实质上,上述实现等价代码如下:
newlist = []for i in a: for j in a2: newlist.append( i+j )
8. Level7: 嵌套列表生成式
更高级一点,我们可以在列表生成式中嵌套列表生成式,举例如下:
a = [1, 2, 3]b = [[i for i in range(1, n+1)] for n in a]# b is [[1], [1, 2], [1, 2, 3]]
9. Level8: 合并上述所有技巧
最后的最后,让我们将上述介绍的几个技巧进行合并,我们来看如下例子:
a = [1, 2, 3, 4, 5]b = [[xx if xx>yy else yy for xx in range(x) for yy in range(y)] for i,(x,y) in enumerate(zip(a, a[::-1])) if i%2==0]# [[0, 1, 2, 3, 4], [0, 1, 2, 1, 1, 2, 2, 2, 2], [0, 1, 2, 3, 4]]
上述实现意义不大,我们尝试应用上了上面介绍的所有技巧,但是毕竟代码可读性太大。其主要目的还是为了说明我们可以结合多种技巧,来使我们的列表生成式实现更加强大的功能。
10. 应用栗子
好吧,我们来看个实际的应用例子吧! 假设我们班级上有如下同学信息:
students = [ ("bob", "m", [67, 89, 60]), ("alice", "f", [97, 85, 61]), ("cassie", "f", [78, 91, 89]), ("tim", "m", [47, 57, 24]), ("tom", "m", [91, 79, 72]),]
上述列表展示了每个学生的姓名、性别和考试成绩,这里假设如果一个学生的平均分数≥ 50,那么这个学生有资格获奖。这里我们需要编写代码,来找到上述列表中有资格获奖的男生。 样例代码如下:
x = [(name, "eligible" if sum(scores)/len(scores) >=50 else "not eligible") \ for name,gender,scores in students if gender=="m"]#[('bob', 'eligible'), ('tim', 'not eligible'), ('tom', 'eligible')]
11. 总结
本文重点介绍了理解Python中的列表生成式的八重境界,并给出了相应的代码示例。
您学废了嘛?

Original: https://blog.51cto.com/u_15506603/5642551
Author: sgzqc
Title: 【Python】列表生成式中的八重境界
相关阅读3
Title: 13行python代码实现对微信进行推送消息
Python可以实现给QQ邮箱、企业微信、微信等等软件推送消息,今天咱们实现一下Python直接给微信推送消息。
这里咱们使用了一个第三方工具 pushplus

单人推送
实现步骤:
1、用微信注册一个此网站的账号
2、将token复制出来,记录到小本本上。
代码展示
import requests
# Python源码资料电子书领取群 279199867
def send_wechat(msg):
token = 'XXXXXXXXXXXX'#前边复制到那个token
title = 'title1'
content = msg
template = 'html'
url = f"https://www.pushplus.plus/send?token={token}&title={title}&content={content}&template={template}"
print(url)
r = requests.get(url=url)
print(r.text)
if __name__ == '__main__':
msg = 'Life is short I use python'
send_wechat(msg)
在手机上看一下结果
局限性:这个只能给自己推送,别人推送不了。那怎么给别人推送呢?
一对多推送
实现步骤
1、在一对多推送的tab页面里,新建群组,并记录下群组编码。
2、点击生成二维码,将二维码发给要接受消息的人。让他们用微信扫码。
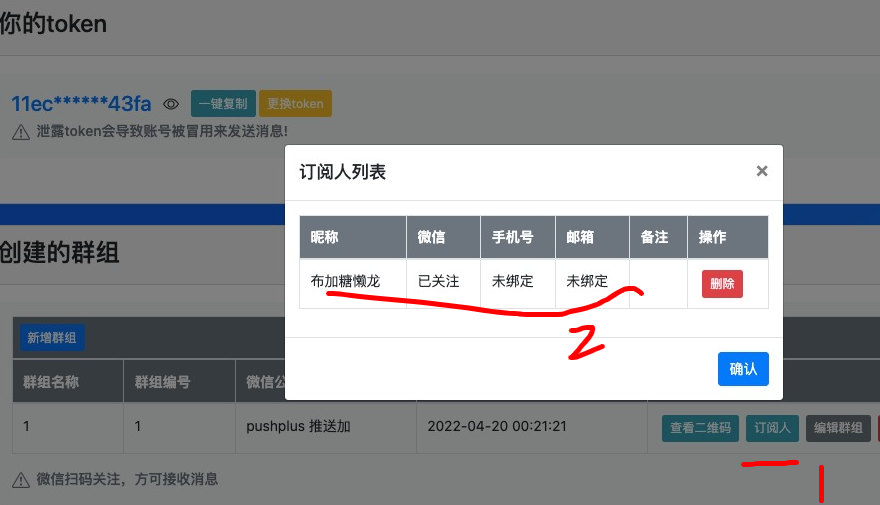
3、扫码后,看看订阅人,扫码之后的人,会显示在这里。给这个群组发送的消息,这里的人都会接收到。
4、写代码发送消息到微信
import requests
def send_wechat(msg):
token = ' XXXXXXXXXXXXXXXXXX' #前边复制到那个token
title = 'test notice title'
content = msg
template = 'html'
topic = '1'
url = f"http://www.pushplus.plus/send?token={token}&title={title}&content={content}&template={template}&topic={topic}"
print(url)
r = requests.get(url=url)
print(r.text)
if __name__ == '__main__':
msg = 'this is a one to more lizi'
send_wechat(msg)
效果展示
至此到这里就完成啦!
注:普通用户和会员的最大的区别:
普通用户一天仅可请求200次,会员扩大到1000次。所以普通用户基本上也够用了。真想支持网站作者,就买个会员,一个月也就10块钱。
Python爬虫入门到实战:100个爬虫实战项目!
兄弟们,觉得不错的话,点赞收藏一下呗!
Original: https://www.cnblogs.com/hahaa/p/16583878.html
Author: 轻松学Python
Title: 13行python代码实现对微信进行推送消息