
Python采集腾讯漫画, 下载你想看的高质量漫画
原创
lanxiaofang博主文章分类:Python ©著作权
文章标签 json html 解析数据 文章分类 Python 后端开发 指尖人生
©著作权归作者所有:来自51CTO博客作者lanxiaofang的原创作品,请联系作者获取转载授权,否则将追究法律责任
一、[知识点]:
爬虫基本流程
保存海量漫画数据
requests的使用
base64解密
二、[开发环境]:
版 本:python 3.8
编辑器:pycharm
requests: pip install requests
三、思路
爬虫:
分析网页数据来源 所有图片链接
https://ac.qq.com/ComicView/index/id/505430/cid/1
多个页面采集
四、代码实现:
-
发送请求
-
获取数据
-
解析数据
-
保存数据
五、完整代码
import requests # 发送请求(访问网站) 第三方import re # 解析数据import base64import jsonimport osimport parselheaders = { 'cookie': '__AC__=1; tvfe_boss_uuid=bb88930a5ac8406d; iip=0; _txjk_whl_uuid_aa5wayli=55a33622e35c40e987c810022a8c40c6; pgv_pvid=6990680204; ptui_loginuin=1321228067; RK=Kj3JwrkEZn; ptcz=42d9e016607f032705abd9792c4348479e6108da38fd5426d9ecaeff1088aa19; fqm_pvqid=d77fc224-90eb-4654-befc-ab7b6d275fb4; psrf_qqopenid=4F37937E43ECA9EAB02F9E89BE1860E2; psrf_qqaccess_token=2B1977379A78742A0B826B173FB09E92; wxunionid=; tmeLoginType=2; psrf_access_token_expiresAt=1664978634; psrf_qqrefresh_token=03721D80236524B49062B95719F2F8B4; psrf_qqunionid=FAEE1B5B10434CF5562642FABE749AB9; wxrefresh_token=; wxopenid=; euin=oKoAoK-ANens7z**; pac_uid=1_321228067; o_cookie=3421355804; luin=o3421355804; lskey=00010000cc21c5247a7b57cfa49ce4837f31c5b209104ee0097255fb83272e5526f2ebedd04b546e5739897b; nav_userinfo_cookie=; ac_wx_user=; ts_refer=www.baidu.com/link; ts_uid=6545534402; theme=white; roastState=2; readLastRecord=%5B%5D; _qpsvr_localtk=0.918720523577107; Hm_lvt_f179d8d1a7d9619f10734edb75d482c4=1660113387,1660132056; pgv_info=ssid=s9159912060; readRecord=%5B%5B505430%2C%22%E8%88%AA%E6%B5%B7%E7%8E%8B%22%2C2%2C%22%E7%AC%AC2%E8%AF%9D%20%E6%88%B4%E8%8D%89%E5%B8%BD%E7%9A%84%E8%B7%AF%E9%A3%9E%22%2C2%5D%2C%5B530876%2C%22%E6%8E%92%E7%90%83%E5%B0%91%E5%B9%B4%EF%BC%81%EF%BC%81%22%2C2%2C%22%E7%AC%AC1%E8%AF%9D%20%E7%BB%93%E6%9D%9F%E4%B8%8E%E5%BC%80%E5%A7%8B%22%2C1%5D%2C%5B17114%2C%22%E5%B0%B8%E5%85%84%EF%BC%88%E6%88%91%E5%8F%AB%E7%99%BD%E5%B0%8F%E9%A3%9E%EF%BC%89%22%2C3%2C%22%E7%AC%AC1%E9%9B%86%22%2C1%5D%2C%5B650998%2C%22%E5%A4%A7%E7%8C%BF%E9%AD%82%EF%BC%88%E8%A5%BF%E8%A1%8C%E7%BA%AA%E7%B3%BB%E5%88%97%EF%BC%89%22%2C1011%2C%22%E3%80%8A%E5%A4%A7%E7%8C%BF%E9%AD%82%E3%80%8B%E5%BA%8F%E7%AB%A0%22%2C1%5D%5D; Hm_lpvt_f179d8d1a7d9619f10734edb75d482c4=1660138229; ts_last=ac.qq.com/ComicView/index/id/505430/cid/2', 'referer': 'https://ac.qq.com/Comic/comicInfo/id/644270', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'}hhw_url = 'https://ac.qq.com/Comic/comicInfo/id/644270'htmlData = requests.get(url=hhw_url, headers=headers).textselect = parsel.Selector(htmlData)subUrlList = select.css('ol > li > p > span > a::attr(href)').getall()print(subUrlList)page = 1for subUrl in subUrlList[150:]: if not os.path.exists(f'航海王/第{page}话'): os.mkdir(f'航海王/第{page}话') url = f'https://ac.qq.com' + subUrl # 1. 发送请求 response = requests.get(url=url, headers=headers) # 2. 获取数据 # xpath css 解析方式 网页源代码 # re html_data = response.text # 3. 解析数据 # 匹配规则, 你要在哪里匹配 b4_str = re.findall("var DATA = '(.*?)',", html_data)[0] # print(base64.b64decode(b4_str)) # 把整个字符串长度获取下来 # for循环遍历 字符串 for i in range(len(b4_str)): # 字符串切片 一个个尝试 直到解析不出错 try: json_str = base64.b64decode(b4_str[i:].encode('utf-8')).decode('utf-8') # print(json_str) # "picture":[] pictures = re.findall('"picture":(\[.*?\])', json_str)[0] # print(pictures) json_list = json.loads(pictures) # print(json_list) for j in range(len(json_list)): imgUrl = json_list[j]['url'] print(f'第{page}话', imgUrl) imgData = requests.get(imgUrl).content # 4. 保存图片 with open(f'航海王/第{page}话/{j + 1}.jpg', mode='wb') as f: f.write(imgData) # 退出循环 break except: pass page += 1
- 赞
- 收藏
- 评论
- *举报
上一篇:淘宝电商数据客户价值分析
下一篇:9种常用的数据分析方法
Original: https://blog.51cto.com/lanxf/5616809
Author: lanxiaofang
Title: Python采集腾讯漫画, 下载你想看的高质量漫画
相关阅读1
Title: Python数据分析--Numpy常用函数介绍(5)--Numpy中的相关性函数
摘要:NumPy中包含大量的函数,这些函数的设计初衷是能更方便地使用,掌握解这些函数,可以提升自己的工作效率。这些函数包括数组元素的选取和多项式运算等。下面通过实例进行详细了解。
前述通过对某公司股票的收盘价的分析,了解了某些Numpy的一些函数。通常实际中,某公司的股价被另外一家公司的股价紧紧跟随,它们可能是同领域的竞争对手,也可能是同一公司下的不同的子公司。可能因两家公司经营的业务类型相同,面临同样的挑战,需要相同的原料和资源,并且争夺同类型的客户。
实际中,有很多这样的例子,如果要检验一下它们是否真的存在关联。一种方法就是看看两个公司股票收益率的相关性,强相关性意味着它们之间存在一定的关联性(特别是当所用的数据不够充足时,误差可能更大)
一、股票相关性分析
1、导出两个相关的股票数据,如下依次为:股票代码、日期、开盘价、最高价、最低价、收盘价、成交量。
2、分别从CSV文件中读入相关数据,即收盘价:
close = np.loadtxt('data036.csv',delimiter=',', usecols=(5,),converters={1:datestr2num},unpack=True)
new_close = np.loadtxt('data999.csv',delimiter=',', usecols=(5,),converters={1:datestr2num},unpack=True)
3、协方差描述的是两个变量共同变化的趋势,其实就是归一化前的相关系数。使用 cov 函数计算股票收益率的协方差矩阵,完整代码如下:
import numpy as np
from datetime import datetime
import matplotlib.pyplot as plt
def datestr2num(s): #定义一个函数
return datetime.strptime(s.decode('ascii'),"%Y-%m-%d").date().weekday()
close=np.loadtxt('data036.csv',delimiter=',', usecols=(5,),converters={1:datestr2num},unpack=True) #导入data036.csv数据 new_close=np.loadtxt('data999.csv',delimiter=',', usecols=(5,),converters={1:datestr2num},unpack=True)#导入data999.csv数据covariance = np.cov(close,new_close) #使用numpy.cov() 函数计算两个数列的协方差矩阵print(close.mean()) #求close的平均值print(new_close.mean())#求new_close的平均值print('covariance:','\n',covariance)
运行结果:
48.40690476190476
18.85157142857143
covariance:
[[30.46934553 1.5201865 ]
[ 1.5201865 8.96031113]]
1)用 diagonal 函数查看矩阵对角线上的元素
print ("对角元素:", covariance.diagonal()) # diagonal查看对角上的元素
运行结果:
对角元素: [30.46934553 8.96031113]
2)使用 trace 函数计算矩阵的迹,即对角线上元素之和
print("Covariance trace", covariance.trace()) #对角线上元素之和
3)两个向量的相关系数被定义为协方差除以各自标准差的乘积。计算向量 a 和 b 的相关系数的公式:corr(a,b)=cov(a,b)/(std(a)*std(b))
covar = covariance/ (np.std(close) * np.std(new_close))
print("相关系数矩阵:", covar)
运行结果:
相关系数矩阵: [[1.84843969 0.09222295]
[0.09222295 0.54358223]]
注意:由于covariance是一个矩阵,因而得到的covar也是一个矩阵
相关系数是两只股票的相关程度。相关系数的取值范围在 -1 到 1 之间。根据定义,一组数值与自身的相关系数等于 1 ,numpy中使用 corrcoef 函数计算相关系数
closecorr = np.corrcoef(close,new_close)
print("相关系数:",'\n', closecorr )
运行结果:
相关系数:
[[1. 0.09200338]
[0.09200338 1. ]]
对角线上的元素即close和new_close与自身的相关系数,因此均为1。相关系数矩阵是关于对角线对称的,因此另外两个元素的值相等,表示close和new_close的相关系数等于new_close和close的相关系数。
判断两只股票的价格走势是否同步的要点是,它们的差值偏离了平均差值2倍于标准差的距离,则认为这两只股票走势不同步。代码如下:
difference = close - new_close
avg = np.mean(difference)
dev = np.std(difference)
print ("Out of sync:", np.abs(difference[-1]-avg)>2*dev)
运行结果:
Out of sync: False
二、多项式
微积分里有泰勒展开,也就是用一个无穷级数来表示一个可微的函数。实际上,任何可微的(从而也是连续的)函数都可以用一个N次多项式来估计,而比N次幂更高阶的部分为无穷小量可忽略不计。
NumPy中的 ployfit 函数可以用多项式去拟合一系列数据点,无论这些数据点是否来自连续函数都适用。
继续使用close和new_close的股票价格数据。用一个三次多项式去拟合两只股票收盘价的差价。
t = np.arange(len(close)) #得到close数列的长度
poly = np.polyfit(t, close - new_close, 3) #利用长度t和两只股票的价差,生成一个三项式,三项式有3个系数和一个常量print("Polynomial fit", poly)
运行结果:
Polynomial fit: [ 1.61308827e-07 -4.34114354e-04 1.84480028e-01 1.33680483e+01]
用我们刚刚得到的多项式对象以及 polyval 函数,推断下一个差值:
print ("Next value:", np.polyval(poly, t[-1] + 1)) #用生成的多项式拟合求下一个差值
print(difference[-1]) #打印最后一个实际的差值
运行结果:
Next value: 26.222936287829654
26.21
在极限情况下,差值可以在某个点为0。使用 roots 函数找出拟合的多项式函数什么时候到达0值:
print( "Roots", np.roots(poly))#root返回多项式的根
运行结果:
Roots [2138.21411788 615.9134063 -62.92728874]
三、求极值的知识
极值是函数的最大值或最小值。在高等代数微积分中,这些极值点位于函数的导数为0的位置,然后再求导数函数的根,即找出原多项式函数的极值点。
1)使用 polyder 函数对多项式函数求导
der = np.polyder(poly)
print("Derivative", der)
2)求出导数函数的根,即找出原多项式函数的极值点
print( "Extremas", np.roots(der))
运行后即得到如下:
Derivative: [ 4.83926482e-07 -8.68228709e-04 1.84480028e-01]
Extremas [1547.84609151 246.28739879]
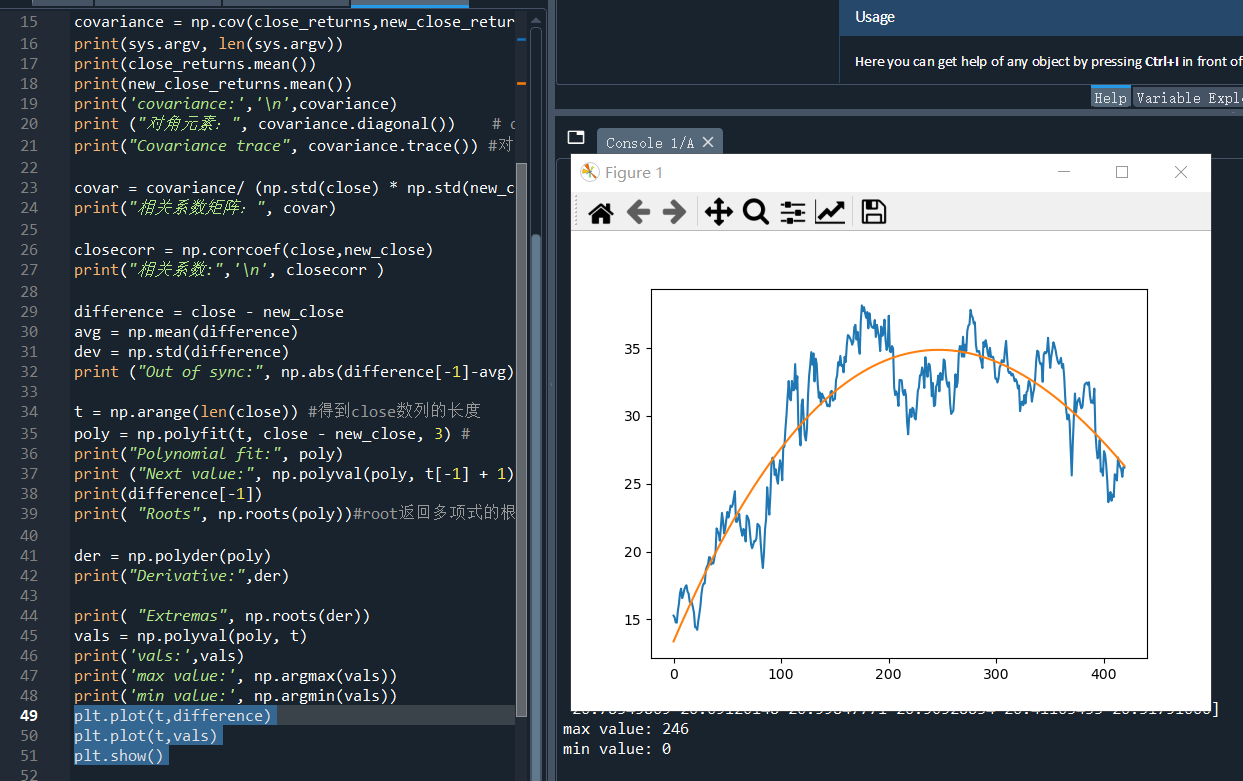
3)用 polyval 计算多项式函数的值,并用matplotlib显示
vals = np.polyval(poly, t)
print('vals:',vals)
print('max value:', np.argmax(vals))
print('min value:', np.argmin(vals))
plt.plot(t,difference)
plt.plot(t,vals)
plt.show()
运行结果如下:
Original: https://www.cnblogs.com/codingchen/p/16327800.html
Author: PursuitingPeak
Title: Python数据分析--Numpy常用函数介绍(5)--Numpy中的相关性函数
相关阅读2
Title: Django3.2 自动发现所有路由
实现 Django3.2 下,自动发项目本地所有URL,并定向排除部分URL
1.需求
发现项目本地所有带别名的URL,组成一个有序字典,方便后续调用;
定向排除部分URL,如Django自带的 admin下的路由;
2.代码实现
点击查看代码
import re # 正则
from collections import OrderedDict # 创建有序字典
from django.conf import settings # 导入setting配置文件(获取项目根路径urls.py)
from django.utils.module_loading import import_string # 字符串导入模块
from django.urls import URLPattern, URLResolver # Django自定义的类,可以判断当前URL是否为根路径(URLPattern)或继续向下分发(URLResolver )
def check_url_exclude(url):
"""
排除一些特定的URL
:param url: 待检验的URL
:return:
"""
for regex in settings.AUTO_DISCOVER_EXCLUDE: #将要定向排除的URL(可包含正则) 按照列表的形式写入配置文件 settings.AUTO_DISCOVER_EXCLUDE 下
if re.match(regex, url):
return True
"""
示例:
AUTO_DISCOVER_EXCLUDE = [
'/admin/.*',
'/login/',
'/logout/',
'/index/',
]
"""
def recursion_urls(pre_namespace, pre_url, urlpatterns, url_ordered_dict):
"""
递归的去获取URL
:param pre_namespace: namespace前缀,用于拼接name
:param pre_url: url前缀,用于拼接url
:param urlpatterns: 路由关系列表
:param url_ordered_dict: 用于保存递归中获取的所有路由
:return:
"""
for item in urlpatterns:
if isinstance(item, URLPattern): # 已经是根网址,获取name及url写入url_ordered_dict
if not item.name: # 没有别名(name)的路由地址直接跳过
continue
# 拼接路由别名(包含分发下来的namespace;如 "rbac:menu_list")
if pre_namespace:
name = "%s:%s" % (pre_namespace, item.name)
else:
name = item.name
# 拼接路由地址URl(包含分发下来的上层路由;如 "/rbac/menu/list")
url = pre_url + item.pattern.regex.pattern # 此时拼接的路由包含起止符号,如:/^rbac/^menu/list/$
url = url.replace("^", "").replace("$", "") # 删除起止符:/rbac/menu/list/
# 排除一些特定的路由URL
if check_url_exclude(url): # 调用check_url_exclude函数定向排除部分URL
continue
url_ordered_dict[name] = {"name": name, "url": url}
elif isinstance(item, URLResolver): # 路由分发,递归操作
if pre_namespace: # 上次循环(上一层)分发是否包含namespace
if item.namespace: # 本次循环(当前层)是否包含namespace
namespace = "%s:%s" % (pre_namespace, item.namespace,) # 上层、当前层都包含直接拼接两层的namespace
else:
namespace = pre_namespace # 当前层分发不包含namespace,直接用上一层的
else:
if item.namespace:
namespace = item.namespace # 上一层分发不包含namespace,直接使用当前层的
else:
namespace = None # 上一层、当前层都没有,直接定义层none
recursion_urls(namespace, pre_url + item.pattern.regex.pattern, item.url_patterns, url_ordered_dict) # 递归继续执行
def get_all_url_dict():
"""
获取项目所有路由
:return:
"""
url_ordered_dict = OrderedDict() # 包含本项目所有权限URl的有序字典
md = import_string(settings.ROOT_URLCONF) # 配置文件内的 ROOT_URLCONF 为本项目根路由urls.py 的路径(字符串),使用 import_string 用字符串加载模块
recursion_urls(None, "/", md.urlpatterns, url_ordered_dict) # 调用 recursion_urls 函数获取所有路由字典,根路径下没有namespace 定义为 None;没有url前缀 定义为 /
return url_ordered_dict
Original: https://www.cnblogs.com/GouHuang/p/15632008.html
Author: GouHuang
Title: Django3.2 自动发现所有路由
相关阅读3
Title: 【知识分享】Python开发简化代码的6个技巧!
常言道:熟能生巧,即便学编程也是这个道理,因此在学Python的时候,我们还需多动手练习敲代码。今天这篇文章为大家介绍一下Python开发简化代码的6个技巧,非常具有参考意义,我们一起来学习一下吧。
Python开发代码简化除了采用规范化的编程规则之外,代码编写的逻辑性和对内置规则的掌握也对其有一定的影响,以下是Python3支持的用法,合理的利用可以极大的简化代码的书写复杂度。
1.列表推导式
对于一组列表,如果想让其所有元素翻倍,很多人都会采用以往比较经典的写法,其实Python中有更精简的办法,实例如下:
以往做法:
num=[1, 3, 5, 7, 9]
for i in range(len(num)):
num[i]=num[i] * 3
Python简化写法:
num=[1, 3, 5, 7, 9]
bag=[elem * 3 for elem in num]
- 遍历列表
传统遍历列表是用函数表示列表的长度进行循环遍历,Python3可以省略这一步,更加简洁!
以往做法:
num=[1, 3, 5, 7, 9]
for i in range(len(num)):
print(num[i])
Python简化写法:
num=[1, 3, 5, 7, 9]
for i in num:
print(i)
3.元素互换
对于元素互换,传统做法需要设定一个中间变量,进行数值的承接,Python元素互换变得简单很多。
以往做法:
a=3
b=4
c=a
a=b
b=c
Python简化写法:
a=3
b=4
a,b= b,a
4.初始化列表
Python也有简洁的初始化列表表示方法,具体简洁程度,举个例子感受一下吧,以下是要一个是8个整数1的列表
以往做法:
bag=[]
for_in range(8):
bag.append(1)
Python简化写法:
bag=[1] * 8
5.构造字符串
经常打印字符串,需要用到构造函数,传统写法需要很多连接符和参数比较复杂,Python用法就简洁很多,以下是相关实例:
以往做法:
name="oldboy"
age="30"
born_in="beijing"
str="Hello my name is "+name+ "and I'm"+str(age)+"years old. I was born in"+born_in+"."
print(str)
Python简化写法:
name="oldboy"
age="30"
born_in="beijing"
str="Hello my name is {0} and I'm {1} years old. I was born in {2}.".format(name, age, born_in)
print(str)
6.返回tuples元组
Python允许一个函数中返回多个元素,以下是解包元组实例:
以往做法:
def binary():
return 0, 1
result=binary()
zero=result[0]
one=result[1]
Python简化写法:
def binary():
return 0, 1
zero,one=binary()
Original: https://blog.51cto.com/u_15052541/5488969
Author: 老男孩IT教育
Title: 【知识分享】Python开发简化代码的6个技巧!