
1.取得每个部门最高薪水的人员名称
先取出每个部门的最高薪水,再作为临时表与(对应最高薪水的人员名称表)连接
select
e.ename,t.*
from
emp e
join
(select deptno,max(sal) as maxsal from emp group by deptno)t
on
t.deptno = e.deptno and t.maxsal = e.sal
- 哪些人的薪水在部门的平均薪水之上
先取出每个部门的平均薪水,再作为临时表与(薪水在其部门平均薪水上的部门名称,薪水表)连接
select
t.*,e.ename,e.sal
from
emp e
join
(select deptno,avg(sal) as avgsal from emp group by deptno)t
on
e,deptno = t,deptno and e.sal > t.avgsal;
3.取得部门中所有人的平均薪水等级
找到每个人的薪水等级(emp连接salgrade)
select
e.ename,e.sal,e.deptno,s.grade
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal;
基于以上结果继续按照deptno分组,求grade的平均值(直接两张表就行,不需要临时表)
select
e.deptno,avg(s.grade)
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal
group by
e.deptno;
4.不准用组函数(Max),取得最高薪水(给出两种解决方案)
第一种,降序(limit)
select ename,sal from emp order by sal desc limit 1;
第二种方案,表的自连接
select sal from emp where sal not in(select distinct a.sal from emp a join emp b on a.sal
5.取出平均薪水最高的两个部门编号(至少给出两种解决方案)
第一种方案:
select deptno,avg(sal) as avgsal from emp group by deptno order by avgsal desc limit 1;
第二种解决方案:
select max(t.avgsal) from (select avg(sal) as avgsal from emp group by deptno) t;
select
deptno,avg(sal) as avgsal
from
emp
group by
deptno
having
avgsal = (select max(t.avgsal) from (select avg(sal) as avgsal from emp group by deptno) t);
6.求平均薪水的等级最低的部门的部门名称
找出最低平均薪水对应的等级
select
grade
from
salgrade
where
(select avg(sal) as avgsal,deptno from emp order by avgsal asc limit 1) between losal and hisal;
找出(等于最低平均薪水的等级对应的)部门名称,平均薪水,等级
select
t.*,s.grade
from
(select d.dname,avg(sal) as avgsal from emp e join dept on e.deptno = d.deptno group by d.dname) t
join
salgrade s
on
t.avgsal between s.losal and s.hisal;
where
s.grade = (select grade from salgrade where (select avg(sal) as avgsal,deptno from emp order by avgsal asc limit 1)
between losal and hisal);
7.取出比普通员工(员工代码没有在mgr字段出现的)的最高薪水还要高的领导人姓名
注意:not in 在使用时,后面小括号里记得排除 null
找到普通员工的最高薪水
select max(sal) from emp where empno not in(select distinct mgr from emp where mgr is not null);
找到高于(普通员工的最高薪水)的员工
select
ename,sal
from
emp
where
sal > (select max(sal)
from
emp
where
empno not in(select distinct mgr from emp where mgr is not null));
8.取出薪水最高的前五名
select ename,sal from emp order by sal desc limit 5;
9.取出薪水最高的第六到第十的员工
select ename,sal from emp order by sal desc limit 5,5;
10.取出最后入职的5名员工;
select ename,hiredate from emp order by hiredate desc limit 5;
11.取出每个薪水等级有多少个员工
select
s.grade,count(*)
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal
group by
s.grade;
12.列出所有员工及领导的名字
select
a.ename '员工',b.ename '领导'
from
emp a
left join
emp b
on
a.mgr = b.empno;
13.列出受雇日期早于直接上级的所有员工的姓名,受雇日期,直接上级的姓名,受雇日期,部门名称
select
a.empno '员工',a.hiredate,b.ename '领导',b.hire date,d.dname
from
emp a
join
emp b
on
a.mgr = b.empno
join
dept d
on
a.deptno = d.deptno
where
a.hiredate < b.hiredate;
14.列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门
select
e.*,d.dname
from
emp e
right join
dept d
on
e.deptno = d.deptno;
15.列出至少有5个员工的所有部门
select
deptno
from
emp
group by
deptno
having
count(*) >= 5;
16.列出薪水比"SMITH"多的所有员工
select
ename,sal
from
emp
where
sal > (select sal from emp where ename = 'SMITH');
17.列出最低薪水大于1500的各种工作及其从事此工作的全部雇员人数
select
job,count(*)
from
emp
group by
job
having
min(sal) > 1500;
18.列出在部门"SALES"
select
ename
from
emp
where
deptno = (select deptno from dept where dname = 'SALES');
19.列出薪水高于公司平均薪水的所有员工,所在部门,上级领导,雇员的工资等级
select
e.ename '员工',d.dname,l.ename '领导',s.grade
from
emp e
join
dept d
on
e.empno = d.deptno
left join
emp l
on
e.mgr = l.empno
join
salgrade s
on
e.sal between s.losal and s.hisal
where
e.sal > (select avg(sal) from emp);
20.列出与"SCOTT"从事相同工作的所有员工及其部门名称
select
e.ename,e.job,d.dname
from
emp e
join
dept d
on
e.deptno = d.deptno
where
e.job = (select job from emp where ename = 'SCOTT')
and e.name <> 'SCOTT';
21.列出薪水等于部门30中员工的薪水的其他员工的姓名和薪水
select
ename,sal
from
emp
where
sal in(select distinct sal from emp where deptno = 30)
and
deptno <> 30;
22.列出薪水高于在部门30工作的所有员工的薪水的员工姓名和薪水,部门名称
select
e.ename,e.sal,d.dname
from
emp e
join
dept d
on
e.deptno = d,deptno
where
e.sal > (select max(sal) from emp where deptno = 30) ;
23.列出在每个部门工作的员工数量,平均工资和平均服务期限
select
d.deptno,
count(e.ename) as ecount,
ifnull(avg(e.sal),0) as avgsal,
ifnull(avg(timestampdiff(YEAR,hiredate,now())),0) as avgtime
from
emp e
right join
dept d
on
e.deptno = d.deptno
group by
d.deptno;
计算两个时间间隔的函数,语法为:
timestampdiff(间隔类型,前一个日期,后一个日期)
返回日期间的整数差。
FRAC_SECOND 表示间隔是毫秒
SECOND 秒
MINUTE 分钟
HOUR 小时
DAY 天
WEEK 星期
MONTH 月
QUARTER 季度
YEAR 年
24.列出所有员工的姓名,部门名称,和薪水
select
e.ename,d.dname,e.sal
from
emp e
join
dept d
on
e.deptno = d.deptno;
25.列出所有部门的详细信息和人数
select
d.deptno,d.dname,d.loc,count(e.ename)
from
emp e
join
dept d
on
e.deptno = d.deptno
group by
d.deptno,d.name,d.loc;
26.列出各种工作的最低工资及从事此工作的雇员姓名
select
e.ename,t.*
from
emp e
join
(select job,min(sal) as minsal from emp group by job)t
on
e.job = t.job and e.sal = t.,minsal;
27.列出各个部门MANAGER(领导)的最低薪水
select
deptno,min(sal)
from
emp
where
job = 'MANAGER'
group by
deptno;
28.列出所有员工的年工资,按年薪从低到高排序
select
ename,(sal + ifnull(comm,0))*12 as yearsal
from
emp
order by
yearsal asc;
29.求出员工领导薪水超过3000的员工名称和领导
select
a.ename '员工',b.ename '领导'
from
emp a
join
emp b
on
a.mgr = b.empno
where
b.sal > 3000;
30.求出部门名称带'S'的部门员工的工资合计,部门人数
select
d.deptno,d.dname,d.loc,count(e.ename),ifnull(sum(e.sal),0) as sumsal
from
emp e
right join
dept d
on
e.deptno = d.deptno
where
d.dname like '%S%'
group by
d.deptno,d.name,d.loc;
31.给任职日期超过30年的员工加薪 10%
update
emp
set
sal= sal*1.1 where timestampdiff(YEAR,hiredate,now())>30;
ps:博主少写了3道哟! ( •̀ ω •́ )✧
Original: https://www.cnblogs.com/Burning-youth/p/15685482.html
Author: 猿头猿脑的王狗蛋
Title: 【MySQL】试题 --- 31道巩固 SQL 语句的练习题
相关阅读1
Title: MySQL源码解析之执行计划
- MySQL执行计划介绍
- MySQL执行计划代码概览
- MySQL执行计划总结
一、MySQL执行计划介绍
在MySQL中,执行计划的实现是基于 JOIN和 QEP_TAB这两个对象。其中JOIN类表示一个查询语句块的优化和执行,每个select查询语句(即Query_block对象)在处理的时候,都会被当做JOIN对象,其定义在 sql/sql_optimizer.h。
QEP_TAB是 Query Execution Plan Table的缩写,这里的表Table对象主要包含物化表、临时表、派生表、常量表等。 JOIN::optimize()是优化执行器的统一入口,在这里会把一个查询语句块 Query_block最终优化成 QEP_TAB。
在 MySQL-8.0.22版本之后,又引入访问方式 AccessPath和执行迭代器 Iterator对象,再结合JOIN和QEP_TAB对象,最终得到整个解析计划的执行路径。
二、MySQL执行计划代码概览
本文主要 基于MySQL-8.0.25版本,进行说明。
优化器的入口函数: bool JOIN::optimize(),对应代码文件 sql/sql_optimizer.cc。
// 主要功能是把一个查询块Query_block优化成一个QEP_TAB,得到AccessPath
bool JOIN::optimize() {
...
// 下面主要是为了可以借助INFORMATION_SCHEMA.OPTIMIZER_TRACE表,跟踪优化器的执行状态和执行步骤
Opt_trace_context *const trace = &thd->opt_trace;
Opt_trace_object trace_wrapper(trace);
Opt_trace_object trace_optimize(trace, "join_optimization");
trace_optimize.add_select_number(Query_block->select_number);
Opt_trace_array trace_steps(trace, "steps");
...
// 窗口函数装配优化
if (has_windows && Window::setup_windows2(thd, m_windows))
...
// 拷贝Query_block上的条件副本到JOIN结构关联的成员对象,为后续优化做准备
if (Query_block->get_optimizable_conditions(thd, &where_cond, &having_cond))
...
// 统计抽象语法树中的叶节点表,其中leaf_tables是在Query_block::setup_tables中进行装配
tables_list = Query_block->leaf_tables;
...
// 分区裁剪
if (Query_block->partitioned_table_count && prune_table_partitions()) {
...
// 尝试把聚合函数COUNT()、MIN()、MAX()对应的值,替换成常量
if (optimize_aggregated_query(thd, Query_block, *fields, where_cond,
&outcome)) {
...
// 采用超图算法生成执行计划,注意超图算法通过set optimizer_switch="hypergraph_optimizer=on"方式启用
if (thd->lex->using_hypergraph_optimizer) {
FindBestQueryPlan(thd, Query_block, /*trace=*/nullptr);
// 如果Join优化器是超图算法,处理结束直接返回
return false;
}
...
下面代码主要涉及Join优化器连接方式为 左深树的情况,主要用到 join_tab数组来进行组织关联
根据代价计算表的连接方式,核心函数 make_join_plan(),实现非常复杂。比较关键的函数是 bool Optimize_table_order::choose_table_order()
其主要思想是通过贪婪搜索 Optimize_table_order::greedy_search,根据最小的连接代价,进行有限的穷举搜索(细节参考Optimize_table_order::best_extension_by_limited_search)
最终找到近似最优解的连接排列组合
if (make_join_plan()) {
...
// 语句块谓词条件下推,提升过滤性能
if (make_join_Query_block(this, where_cond)) {
...
// 优化order by/distinct语句
if (optimize_distinct_group_order()) return true;
...
// 分配QEP_TAB数组
if (alloc_qep(tables)) return (error = 1); /* purecov: inspected */
...
// 执行计划细化,优化子查询和半连接的情况,具体策略可以参考mariadb的文档:
// https:// mariadb.com/kb/en/optimization-strategies/
// 关键代码是setup_semijoin_dups_elimination,主要对半连接关联的策略进行装配
if (make_join_readinfo(this, no_jbuf_after))
...
// 为处理group by/order by创建开辟临时表空间
if (make_tmp_tables_info()) return true;
...
// 生成访问方式AccessPath,供后续迭代器Iterator访问使用
create_access_paths();
...
return false;
}
三、MySQL执行计划总结
MySQL的执行计划是整个数据库最核心的模块,其代码也在不断地迭代更新过程中。执行计划中优化器的好坏和背后的搜索策略、数学模型紧密相关。MySQL支持的搜索策略有穷举搜索、贪婪搜索,对应的Join优化器有左深树算法和超图算法,整个优化过程主要是基于CBO策略进行优化。
执行计划运行的过程, 实际上就是一个动态规划的过程。这个过程的优劣,快慢决定了MySQL和主流商业数据库的差距。只有深入地理解MySQL优化器的运行原理,才能帮助我们积极有效地探索更高性能优化的可能。
最后由于笔者知识水平有限,疏漏之处,还望斧正。
Enjoy GreatSQL 😃
文章推荐:
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
微信&QQ群:
QQ群: 533341697
微信群:可搜索添加 GreatSQL社区助手微信好友,发送验证信息"加群"加入GreatSQL/MGR交流微信群
GreatSQL社区助手: wanlidbc
Original: https://www.cnblogs.com/greatsql/p/16560603.html
Author: GreatSQL
Title: MySQL源码解析之执行计划
相关阅读2
Title: ImageIo.read 返回null
一、问题描述
今天收到一个bug就是imageio读取图片会返回null,具体如下
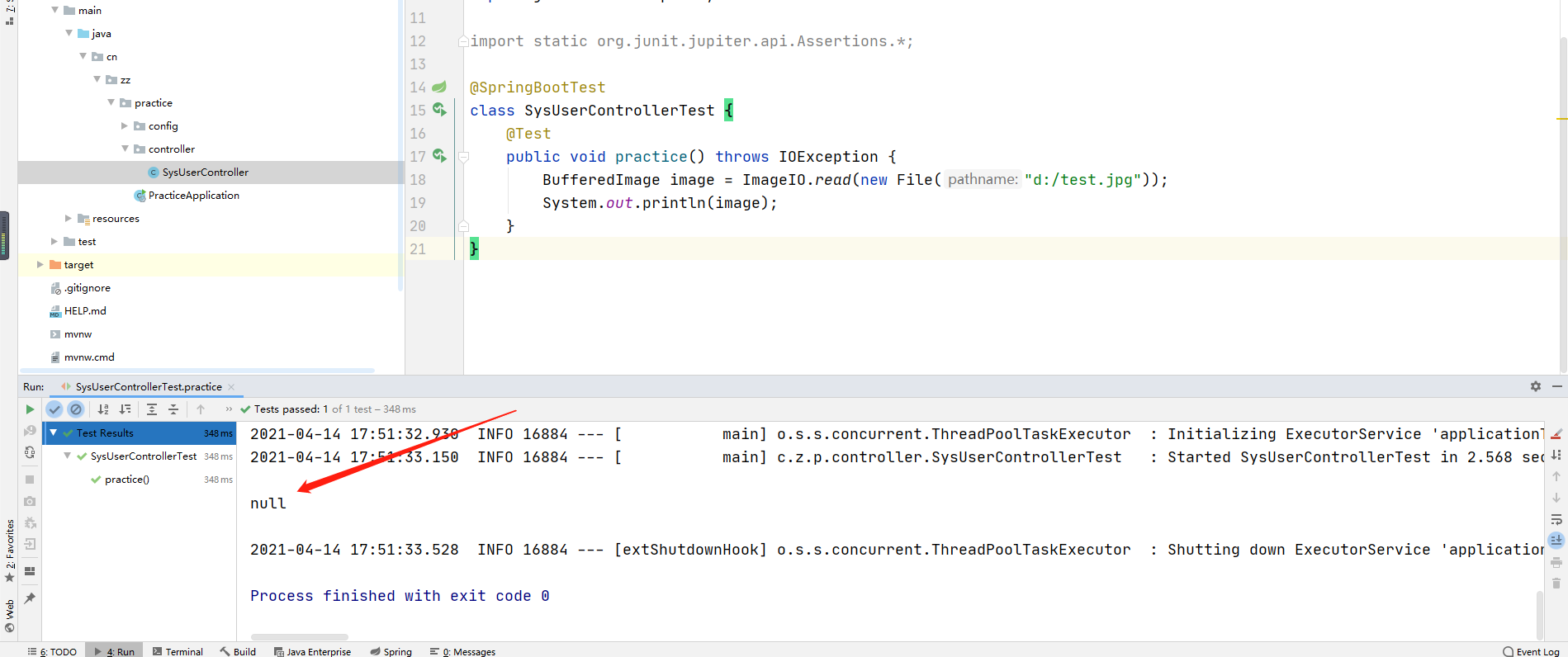
但是其他的图片就没有问题

二、问题分析
结合百度发现这张图片原本的后缀并非是jpg,使用notpard++打开就可以发现

好家伙是webp格式的!!!!
WebP是google开发的一种旨在加快图片加载速度的图片格式。图片压缩体积大约只有JPEG的2/3,并能节省大量的服务器带宽资源和数据空间。是现代图像格式,提供了优越的无损和有损压缩的图片在网络上。使用WebP,网站管理员和web开发人员可以创建更小、更丰富的图像,使网页更快。
WebP无损的png图像小26%。WebP有损图像是25 - 34%小于等效SSIM质量指数可比JPEG图像
无损WebP支持透明(也称为alpha通道)的成本只有22%额外的字节。对有损压缩RGB压缩情况下是可以接受的,有损WebP还支持透明度,通常提供3×PNG相比较小的文件大小。
但是!!!由于Webp格式推出比较晚, Jdk 内置的图片编解码库对此并不支持。我只需要知道如何把webp格式转换成jpg或者其他格式就可以了!!!

三、解决问题
1、在百度找到一个api(地址如下)
我是地址
友情建议,最好用0.1.0哪个版本的其他版本试了都有问题~~~~~~
2、由于这个项目并未发布到maven中央仓库,所以需要手动导入本地jar包.
(1)、maven导包
<dependency>
<groupid>com.github.nintha</groupid>
<artifactid>webp-imageio-core</artifactid>
<version>{versoin}</version>
<scope>system</scope>
<systempath>${project.basedir}/libs/webp-imageio-core-{version}.jar</systempath>
</dependency>
(2)、gradle导包
dependencies {
compile fileTree(dir:'src/main/resources/libs',include:['*.jar'])
}
当然了,你想放在自己仓库中也是无可厚非的
3、上代码
(1)、Webp编码
public static void main(String args[]) throws IOException {
String inputPngPath = "test_pic/test.png";
String inputJpgPath = "test_pic/test.jpg";
String outputWebpPath = "test_pic/test_.webp";
// Obtain an image to encode from somewhere
BufferedImage image = ImageIO.read(new File(inputJpgPath));
// Obtain a WebP ImageWriter instance
ImageWriter writer = ImageIO.getImageWritersByMIMEType("image/webp").next();
// Configure encoding parameters
WebPWriteParam writeParam = new WebPWriteParam(writer.getLocale());
writeParam.setCompressionMode(WebPWriteParam.MODE_DEFAULT);
// Configure the output on the ImageWriter
writer.setOutput(new FileImageOutputStream(new File(outputWebpPath)));
// Encode
writer.write(null, new IIOImage(image, null, null), writeParam);
}
(2)、Webp解码
public static void main(String args[]) throws IOException {
ImageReader reader = ImageIO.getImageReadersByMIMEType("image/webp").next();
WebPReadParam readParam = new WebPReadParam();
readParam.setBypassFiltering(true);
// Configure the input on the ImageReader
reader.setInput(new FileImageInputStream(new File(webp图片地址)));
// Decode the image
BufferedImage image = reader.read(0, readParam);
ImageIO.write(image, "jpg", new File(输出jpg的地址,png什么的也可以));
}
搞完收工!

Original: https://www.cnblogs.com/pkkyh/p/14659327.html
Author: 迷途者寻影而行
Title: ImageIo.read 返回null
相关阅读3
Title: centos8安装mysql
前言
最近在centos8系统下部署django项目时,要用到mysql数据库,在安装中遇到了点坑,之后参考了一位博主的文章,也是顺利的安装配置成功,博主原文连接:
((20条消息) centos8安装mysql8.0.22教程(超详细)_上善若水滴世界的博客-CSDN博客_centos mysql8安装)
我写这篇文章是为了以后便于查找,怕找不到,所以内容和原博主并无多大的差别。
安装步骤如下:
1.1 首先用xshell远程连接到服务器
1.2 如果服务器之前安装过mysql请先卸载,我这里是用yum安装的,现在通过yum去卸载
yum remove -y mysql
find / -name mysql //找到残留的文件,再通过rm -rf去删除对应的文件
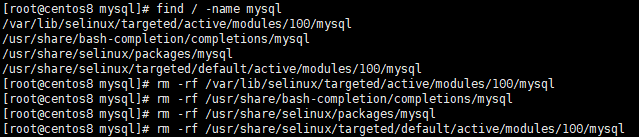
1.3 卸载完成后,使用以下命令:
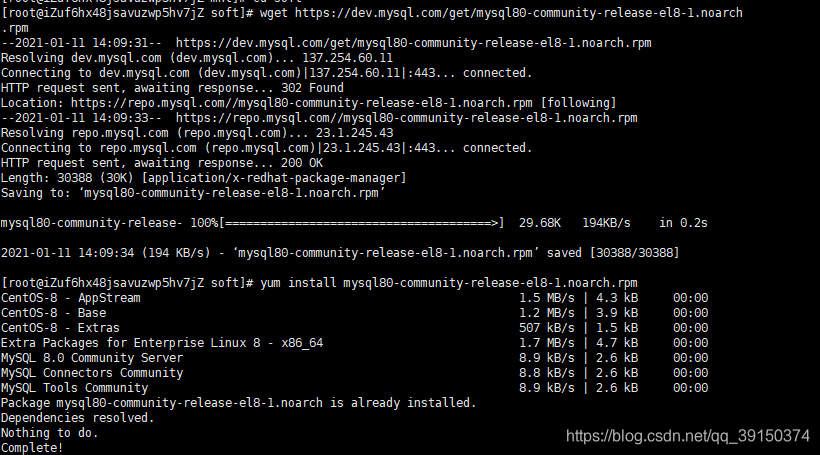
下载mysql安装包:
wget https://dev.mysql.com/get/mysql80-community-release-el8-1.noarch.rpm
yum install mysql80-community-release-el8-1.noarch.rpm
成功示意图:
1.4 检查数据源
查看mysql源是否安装成功:
yum repolist enabled | grep "mysql.*-community.*"
示意图:

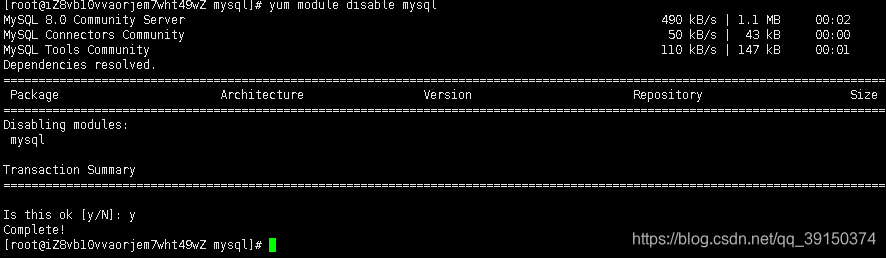
1.5 禁用CentOS8自带mysql模块
如果出现No match for argument: mysql-community-server
可执行 yum module disable mysql命令
yum module disable mysql // 禁用命令
示意图:
1.6 安装mysql命令
前面都是必不可少的准备工作,现在才是重点:
yum install mysql-community-server 这一步的时候可能很多人安装不上,
因为是yum安装库的问题,错误(Error: GPG check FAILED),可以将--nogpgcheck添加到后面:
yum install mysql-community-server --nogpgcheck
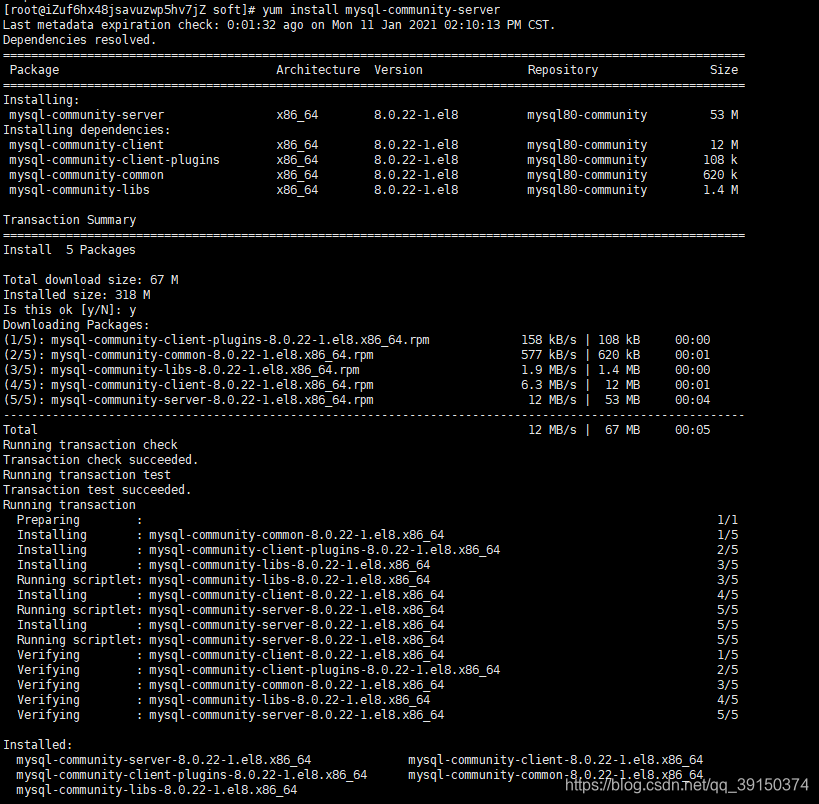
Is this ok [y/Y] 一直 y到底
1.7 启动mysql
在启动mysql时,遇到了一个问题:
[root@iZuf6hx48jsavuzwp5hv7jZ soft]# service mysqld start //启动命令
遇到问题:
[root@iZuf6hx48jsavuzwp5hv7jZ soft]# service mysqld start
Redirecting to /bin/systemctl start mysqld.service//错误提示
正确启动命令:
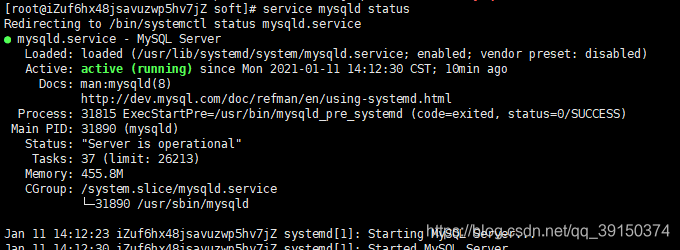
[root@iZuf6hx48jsavuzwp5hv7jZ soft]# /bin/systemctl start mysqld.service//启动命令
[root@iZuf6hx48jsavuzwp5hv7jZ soft]# service mysqld status //
示意图:
1.8 显示mysql的随机密码
grep 'temporary password' /var/log/mysqld.log
密码是host:后面的一串字符。

1.9 登录并修改mysql密码
mysql -u root -p //输入上面生成的密码
修改密码:
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Root_21root';
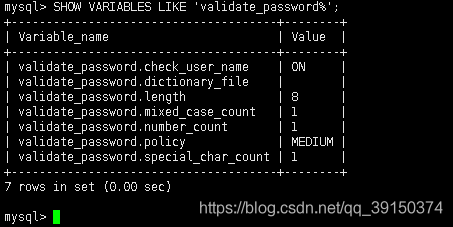
修改密码需要注意,这里密码先修改成 "Root_21root",因为我们随便修改密码时,一般都不满足它的策略
修改密码长度:
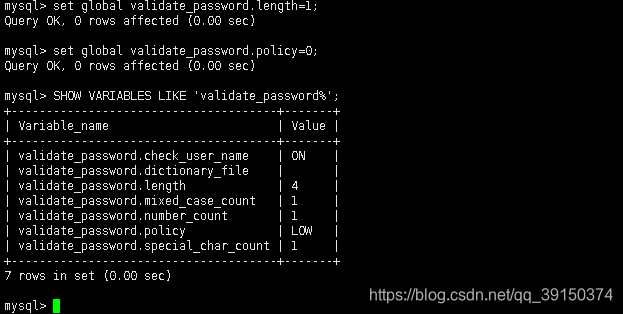
set global validate_password.length=1; //(长度)
修改密码等级:
set global validate_password.policy=0; //(等级)
设置成自己想要的密码:
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
修改前策略:
修改后策略:
1.10 Mysql8.0.22开放远程访问
这部分我没试过,如有需要请查看原博主文章
Original: https://www.cnblogs.com/minqiliang/p/16577102.html
Author: minqiliang
Title: centos8安装mysql