
Softmax Multi-Class Classifier 多分类器
- MNIST数据集
- Fashion-MNIST数据集
- Flatten
- One-Hot Encoding
- Softmax介绍
- 应用Softmax实现多分类
- 交叉熵(Cross Entropy)
- Softmax与逻辑回归的联系
- GPU加速运算原理
- 使用Keras框架实现Softmax多分类
- 代码实现
- 相关测试图片
MNIST数据集
- MNIST数据集为手写体数字的数据集,由每一张图片组成,每一张图片为一张黑白的图片,像素值都在0-255之间,图片的大小均为28×28,也即是由28行以及28列组成。对于一个数据集而言,我们要将它分成训练集以及测试集,而对于MNIST数据集而言,它的训练集由60000张图片组成,测试集由10000张图片组成。由于每张图片的大小为28×28,所以训练集X_train的shape为60000×28×28,测试集X_test的shape为10000×28×28。每张图片有对应的Label,也即是图片上的数字。

; Fashion-MNIST数据集
- Fashion-MNIST数据集一共有10类,也即是Label有10种,和MNIST数据集一样,每一张图片为一张黑白的图片,像素值都在0-255之间,图片的大小均为28×28。MNIST数据集的每一张图片为数字,而Fashion-MNIST数据集的每一张图片则是服饰。同时,与MNIST数据集一样,它的训练集由60000张图片组成,测试集由10000张图片组成。由于每张图片的大小也为28×28,所以训练集X_train的shape为60000×28×28,测试集X_test的shape为10000×28×28。

Flatten
- 针对于MNIST与Fashion-MNIST数据集,每一张图片的大小均为28×28。对于一张黑白图片,我们可以用一个二维矩阵来表示。Flatten的意思就是我们将图片扁平化,将它拉直,也即是将二维矩阵变成一维的向量,将矩阵的第一行放在一维向量的起始位置,矩阵的第二行紧接着放在起始位置的后面,以此类推,一直到第28行。
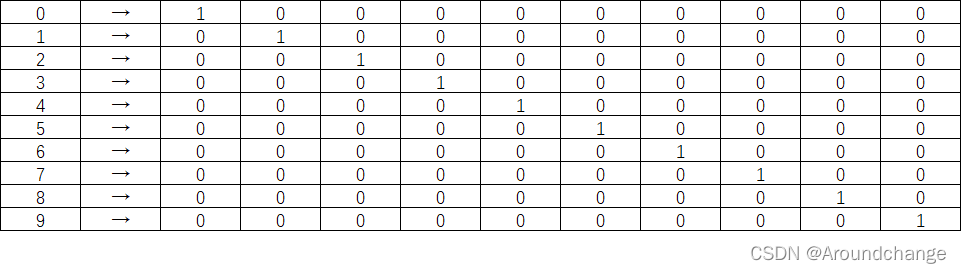
One-Hot Encoding
- 对于MNIST数据集,有对应数字为0-9的Label,如果我们直接将它给Moudel,Moudel会误认为这些数字存在数值上的差异,也即是会觉得与自身差值小的数字相距近,而与自身差值大的数字相距远。Label只是对于我们Feature的一个描述,并不是说它们存在什么距离,为了消除这个影响,我们将引入One-Hot Encoding。MNIST数据集的Label有10个数,我们可以初始化一个10维的向量,或者理解为数组,我们将Label的数字对应下标设为1,其它位置都设为0,这样便消除了影响。
; Softmax介绍
- 取三个数中的最大值可以表示为Max([1,3,5])=5,而Softmax([1,3,5])=[0.015,0.117,0.868]。其运算过程如下:
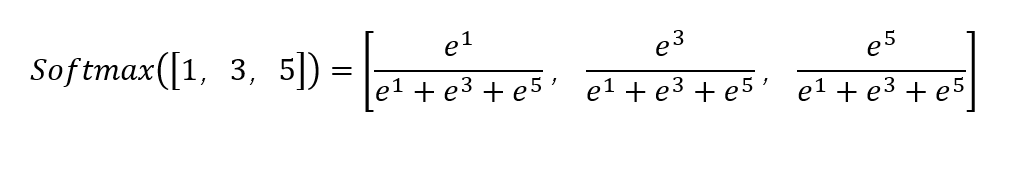
- 由于0.015+0.117+0.868=1,于是我们可以将它与概率联系起来。同时也可以看出,Softmax函数将最小值放得更小了,而将最大值放得更大了。
- Softmax函数代码实现:
import numpy as np
def softmax(array):
array = np.array(array)
exp_array = np.exp(array)
exp_sum = np.sum(exp_array)
return exp_array / exp_sum
softmax([1, 3, 5])
softmax([1, 2, 3, 4, 5])
print(softmax([1, 3, 5]))
print(softmax([1, 2, 3, 4, 5]))
- 运行结果:

应用Softmax实现多分类
- 首先我们实现一个三分类的分类任务,我们拿出训练集中的一个Sample,它的Feature以及经过One-Hot Encoding后的Label为:
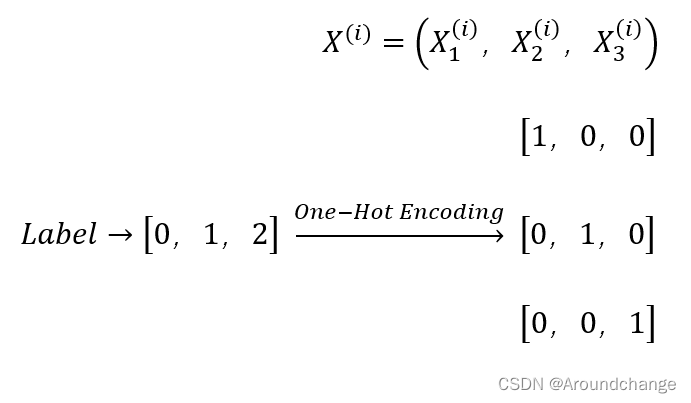
- 以Label为1,One-Hot Encoding为[0,1,0]举例,对应的Train为:
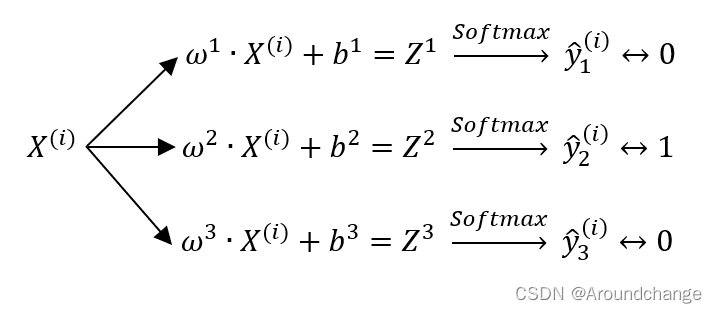
- 以Sample为3举例,对应的Predict为:
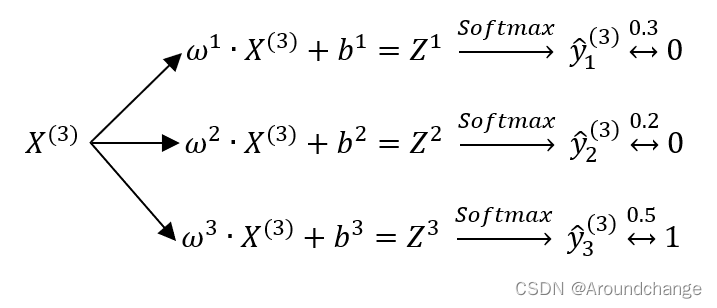
- 对于上式而言,假设预测值分别对应0.3,0.2,0.5,这个时候我们就将它预测为第三类,0.5是最大的值,对应0,0,1,也即是Label为2的值。
; 交叉熵(Cross Entropy)
- 模型中有预测值y ^1,y ^2,y ^3,以及实际值y1,y2,y3,我们需要用交叉熵来求它的损失。
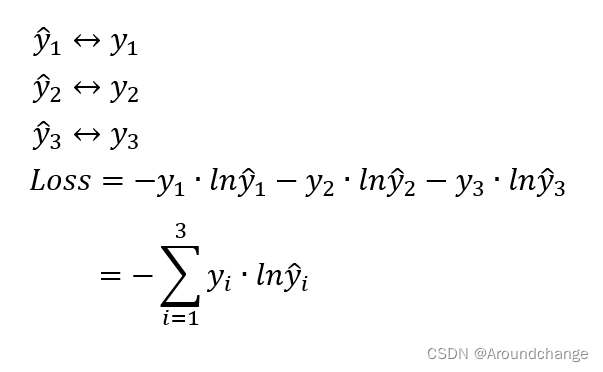
Softmax与逻辑回归的联系
- 逻辑回归可以参考之前写的这一篇博文:Logistic Regression 逻辑回归
- Categorical Cross Entropy

- Binary Cross Entropy

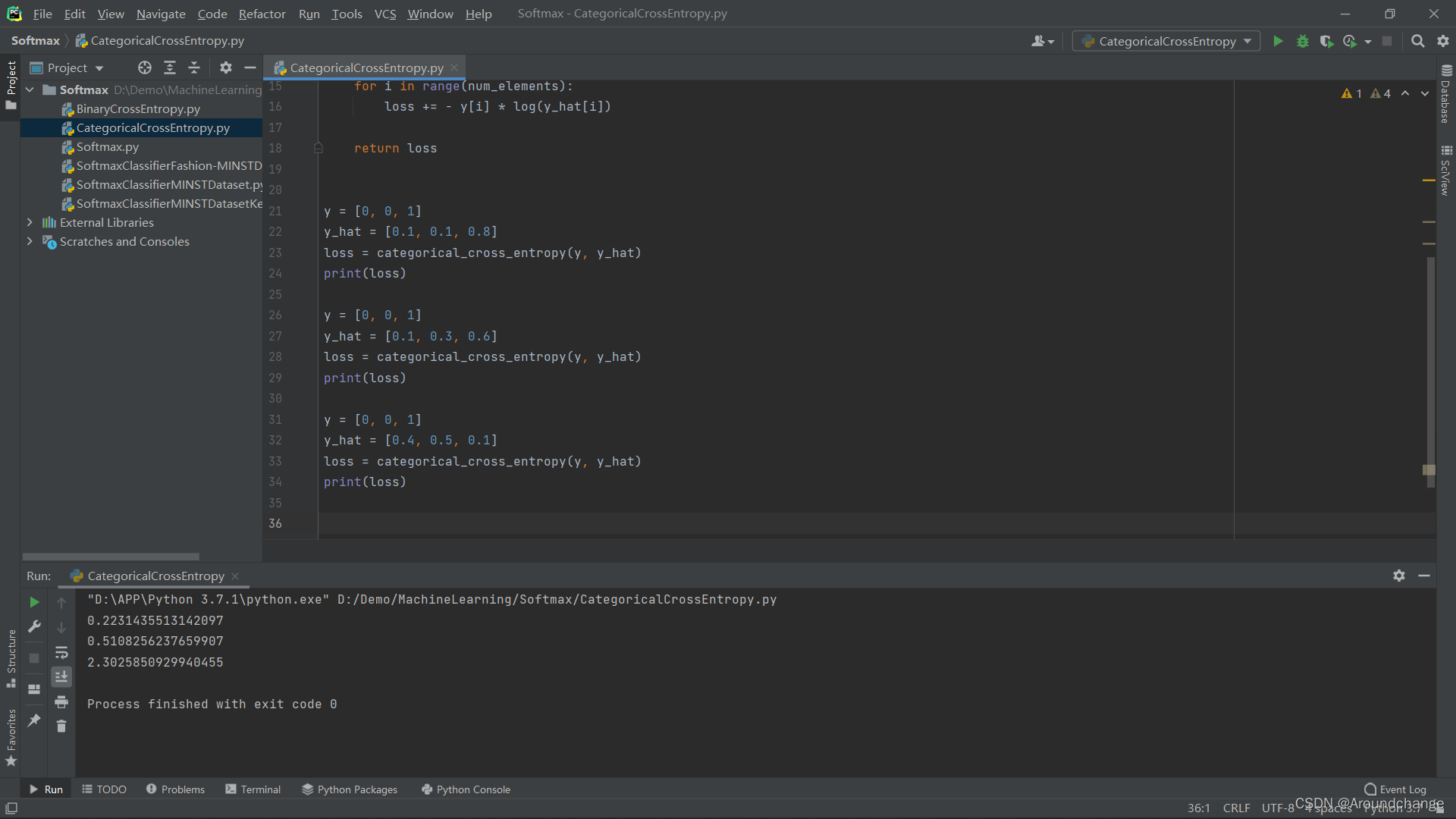
- Categorical Cross Entropy代码实现:
import numpy as np
from numpy import log
def categorical_cross_entropy(y, y_hat):
num_elements = len(y)
loss = 0
for i in range(num_elements):
loss += - y[i] * log(y_hat[i])
return loss
y = [0, 0, 1]
y_hat = [0.1, 0.1, 0.8]
loss = categorical_cross_entropy(y, y_hat)
print(loss)
y = [0, 0, 1]
y_hat = [0.1, 0.3, 0.6]
loss = categorical_cross_entropy(y, y_hat)
print(loss)
y = [0, 0, 1]
y_hat = [0.4, 0.5, 0.1]
loss = categorical_cross_entropy(y, y_hat)
print(loss)
- 运行结果:
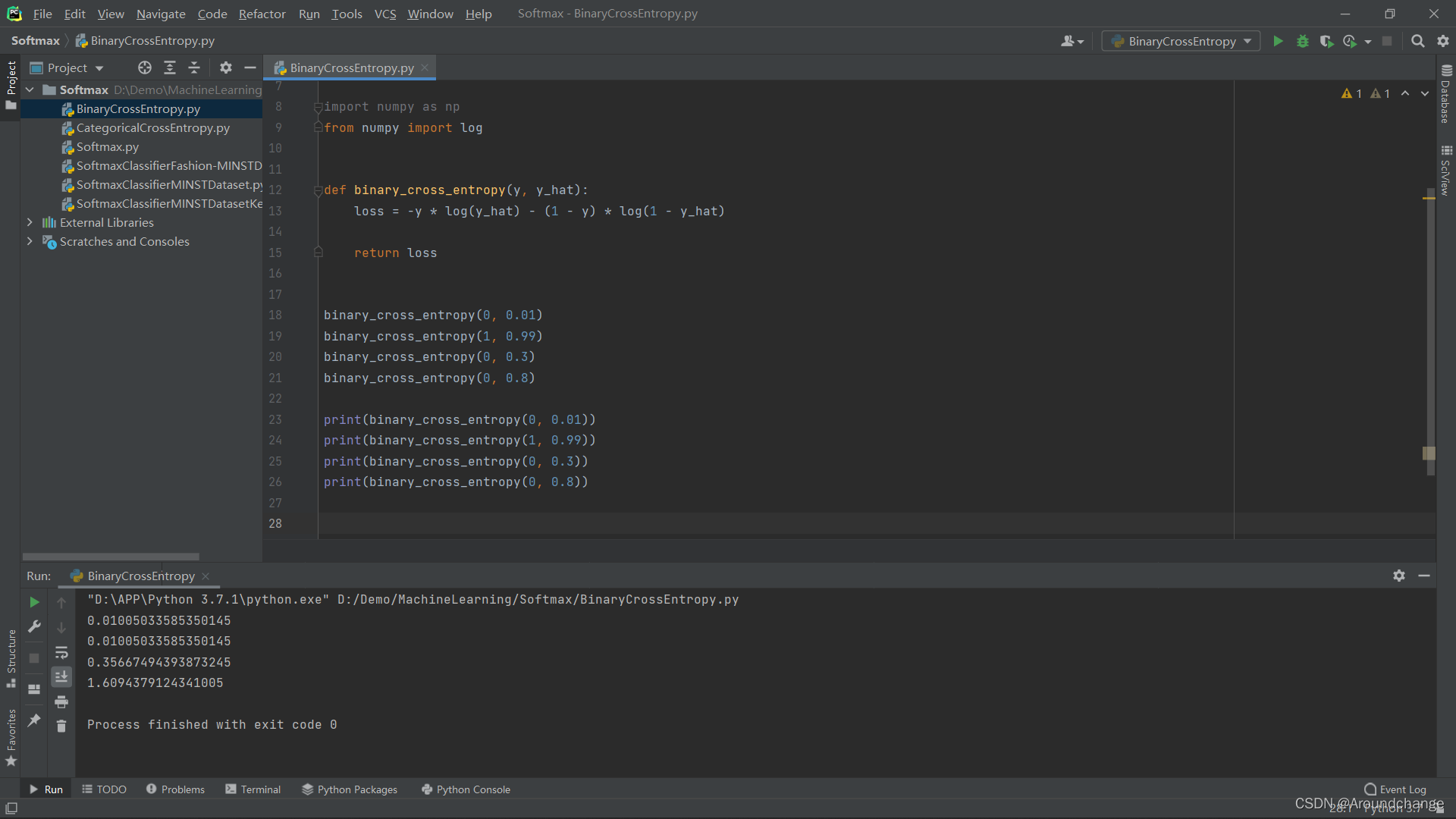
- Binary Cross Entropy代码实现:
import numpy as np
from numpy import log
def binary_cross_entropy(y, y_hat):
loss = -y * log(y_hat) - (1 - y) * log(1 - y_hat)
return loss
binary_cross_entropy(0, 0.01)
binary_cross_entropy(1, 0.99)
binary_cross_entropy(0, 0.3)
binary_cross_entropy(0, 0.8)
print(binary_cross_entropy(0, 0.01))
print(binary_cross_entropy(1, 0.99))
print(binary_cross_entropy(0, 0.3))
print(binary_cross_entropy(0, 0.8))
- 运行结果:
GPU加速运算原理
- 首先,GPU与CPU在核心数上有很大的差别。

- 在矩阵运算的乘法中,行列相乘时互不影响,也即是可以同时放到GPU的各个核心中进行计算,从而实现并行操作。由于GPU的核心数远大于CPU,所以在矩阵运算上,虽然单次处理速度GPU可能没有CPU快,但是由于CPU核心数有限,对于数量级较大的运算,GPU更具有优势。
; 使用Keras框架实现Softmax多分类
代码实现
- SoftmaxClassifierMINSTDataset
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
(X_train, y_train), (X_test, y_test) = mnist.load_data()
n_train = X_train.shape[0]
n_test = X_test.shape[0]
flatten_size = 28 * 28
X_train = X_train.reshape((n_train, flatten_size))
X_train = X_train / 255
y_train = to_categorical(y_train)
X_test = X_test.reshape((n_test, flatten_size))
X_test = X_test / 255
y_test = to_categorical(y_test)
X_train.shape
y_train.shape
y_train[0]
def softmax(x):
exp_x = np.exp(x)
sum_e = np.sum(exp_x, axis=1)
for i in range(x.shape[0]):
exp_x[1, :] = exp_x[i, :] / sum_e[i]
return exp_x
W = np.zeros((784, 10))
b = np.zeros((1, 10))
N = 100
lr = 0.00001
for i in range(N):
det_w = np.zeros((784, 10))
det_b = np.zeros((1, 10))
logits = np.dot(X_train, W) + b
y_hat = softmax(logits)
det_w = np.dot(X_train.T, (y_hat - y_train))
det_b = np.sum((y_hat - y_train), axis=0)
W = W - lr * det_w
b = b - lr * det_b
logits_train = np.dot(X_train, W) + b
y_train_hat = softmax(logits_train)
y_hat = np.argmax(y_train_hat, axis=1)
y = np.argmax(y_train, axis=1)
count = 0
for i in range(len(y_hat)):
if y[i] == y_hat[i]:
count += 1
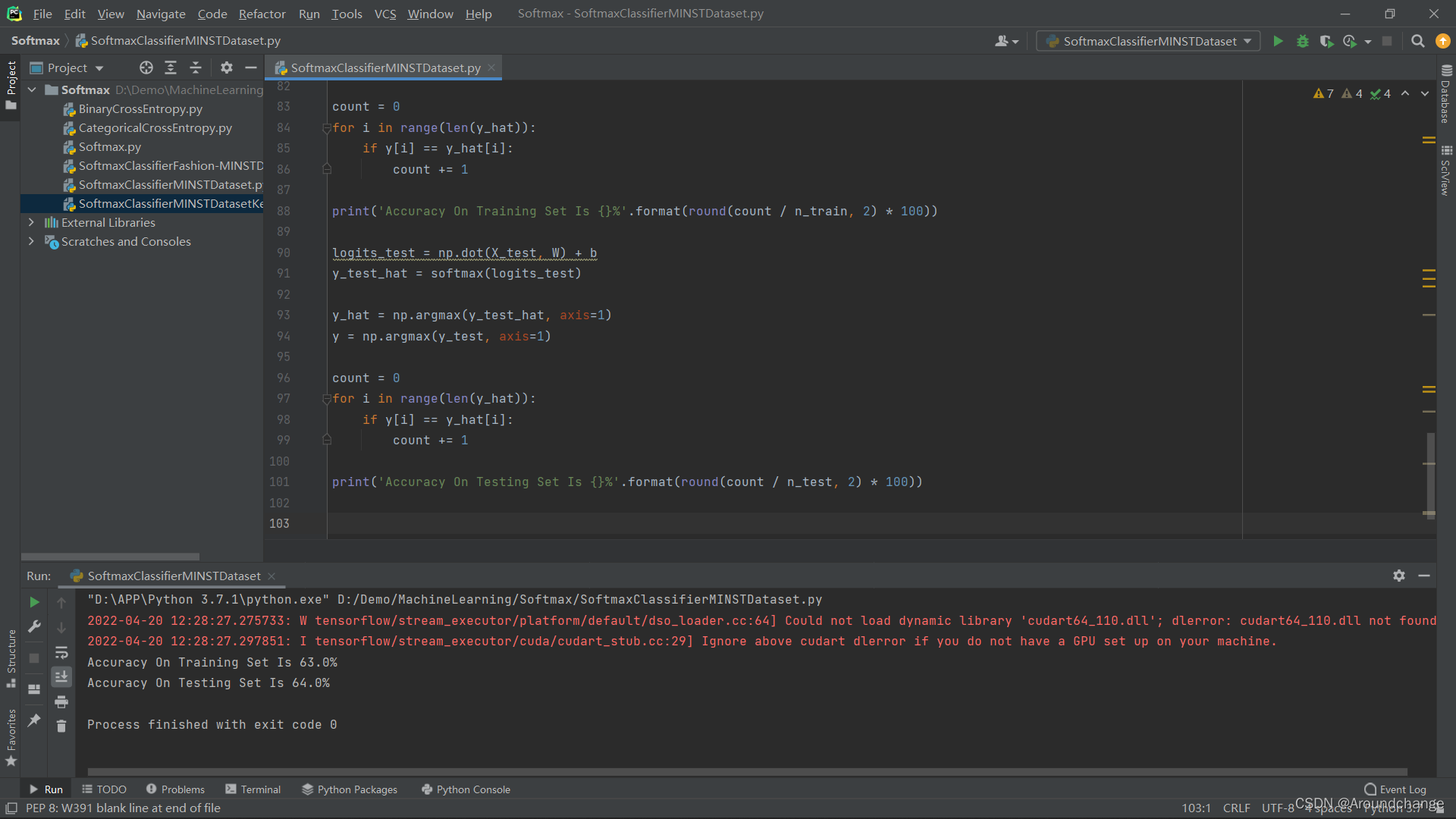
print('Accuracy On Training Set Is {}%'.format(round(count / n_train, 2) * 100))
logits_test = np.dot(X_test, W) + b
y_test_hat = softmax(logits_test)
y_hat = np.argmax(y_test_hat, axis=1)
y = np.argmax(y_test, axis=1)
count = 0
for i in range(len(y_hat)):
if y[i] == y_hat[i]:
count += 1
print('Accuracy On Testing Set Is {}%'.format(round(count / n_test, 2) * 100))
- 运行得到Accuracy的结果:
- SoftmaxClassifierMINSTDatasetKeras
import numpy as np
import pandas as pd
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import RMSprop
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train / 255
X_test = X_test / 255
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
model = Sequential()
model.add(Flatten(input_shape=(28, 28)))
model.add(Dense(units=10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
metrics=['accuracy'],
optimizer=RMSprop())
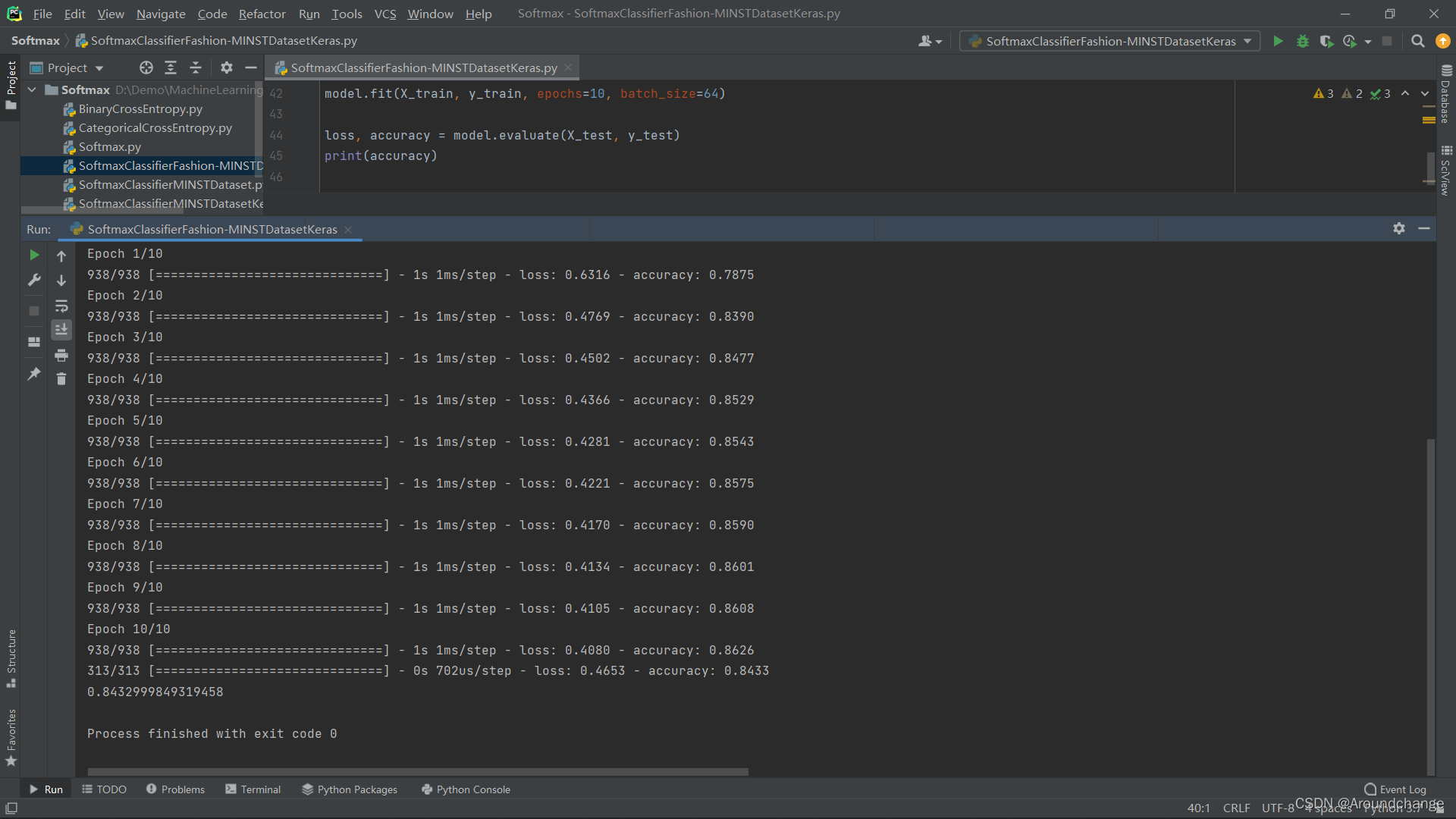
model.fit(X_train, y_train, epochs=10, batch_size=64)
loss, accuracy = model.evaluate(X_test, y_test)
print(accuracy)
- 运行结果:

- 通过以上运行结果可以看出,经过训练后,我们的Accuracy可以达到90%以上。
- SoftmaxClassifierFashion-MINSTDatasetKeras
import numpy as np
import pandas as pd
from tensorflow.keras.datasets import fashion_mnist
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import RMSprop
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
X_train = X_train / 255
X_test = X_test / 255
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
model = Sequential()
model.add(Flatten(input_shape=(28, 28)))
model.add(Dense(units=10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
metrics=['accuracy'],
optimizer=RMSprop())
model.fit(X_train, y_train, epochs=10, batch_size=64)
loss, accuracy = model.evaluate(X_test, y_test)
print(accuracy)
- 运行结果:
- 通过以上运行结果可以看出,经过训练后,我们的Accuracy只能达到80%以上,也即是用Softmax对Fashion-MINST数据集进行处理时显得有些吃力,我们可以用深度学习的方法对其进行优化。Softmax一般用在深度学习的最后一层做分类任务,在它之前我们可以加入一些深度学习的DNN、CNN、RNN进行优化,提取它的Feature,这样一来就会让Softmax在分类时表现得更加出色。
相关测试图片

完整代码已上传至Github,各位下载时麻烦给个follow和star,感谢!
链接:SoftmaxMulti-ClassClassifier 多分类器
Original: https://blog.csdn.net/weixin_49742236/article/details/124009614
Author: Aroundchange
Title: Softmax Multi-Class Classifier 多分类器
相关阅读1
Title: chap1-绪论
NLP:让计算机实现自动或人机互助的语言处理功能,实现海量语言信息的自动处理、知识挖掘和有效利用
基本概念
- 语言 Language
由语音、词汇、语法构成的一定系统
- 自然语言
区别于人为编造的语言,例如程序语言
- 语言学 Linguistics
语音和文字是语言的两个基本属性
三个不同语系
- 屈折语
用词的形态变化表示语法关系
- 黏着语
词内有专门表示语法意义的附加成分
- 孤立语/分析语
形态变化少,语法关系靠次序和虚词表示
- 语音学 Phonetics
研究人类发音特点,语音发音特点
- 一般语音学
对语音发音、声学、知觉的一般研究
- 实验语音学
对具体语言语音的研究
是语言学研究的一部分(基础)
使用复数的语言学科(Linguistics Sciences)描述语言学和语音学的总和
- 自然语言理解 NLU
判断计算机系统的智能:act、react、interact
图灵测试
- 自然语言处理 NLP
NLP要研制表示语言能力(Linguistic Competence)和语言应用(Linguistic Performance)
- 计算机语言学 Computational Linguitics
语言学的分支,用计算技术和概念阐述语言学和语音学问题
已开发领域包括 自然语言处理等等
- 中文信息处理 Chinese Information Processing
计算语言学、NLP、NLU现在常默认为同一概念
NLP的产生与发展
源自机器翻译(MT,Machine Translation)
曲折发展
研究内容
NLP主体
- 机器翻译
- 信息检索
- 自动文摘
- 问答系统
- 信息过滤
- 信息抽取
- 文档分类
- 情感分类
- 文字编辑和自动校对
- 语言教学
其他内容
- 语音识别
- 文字识别
- 文语转换/语音合成
- 说话人识别/认同/验证情感分类
基本问题和主要困难
又称词法,研究词(word)由有意义的基本单元——词素(morphemes)的构成
- 屈折变化
- 构词法
研究句子结构成分之间的相互关系和组成句子序列的规则
研究如何从语句中词的意义,以及词在语句中的句法结构推导语句的意义
研究在不同上下文中语句的应用,以及上下文对语句理解产生的影响
研究语音特性、语音描述、分类及转写方法
- 词法歧义
- 词性歧义
- 结构歧义
歧义结构分析结果的数量随介词短语数目的增加呈指数上升
C n = ( 2 n n ) 1 n + 1 C_n= \left( \begin{array}{cc} 2n\ n \end{array} \right) \frac{1}{n+1}C n =(2 n n )n +1 1
n n n为句子中介词短语个数
- 语义歧义
-
语音歧义
-
新词、人名、地名、术语
- 新含义
-
新用法、新句型
-
普遍存在的不确定性
- 未知语言现象的不可预测性
- 始终面临的数据不充分性
- 语言知识表达的复杂性
- 机器翻译中映射单元的不对等性
基本研究方法
- 理性主义
人的很大一部分语言知识与生俱来,由遗传决定
诺姆·乔姆斯基(Noam Chomsky)的内在语言官能(innate language faculty)理论被广泛接受
- 经验主义
人的语言知识通过感官输入,经过简单联想(association)与通用化(generalization)的操作得到
大量的语言数据中获得语言知识结构
- 理性主义
研究人的语言知识结构(语言能力,language competence)
- 经验主义
研究实际的语言数据(语言行为,language performance)
- 理性主义
基于Chomsky的语言原则,通过语言所必须遵守的一系列原则来描述语言
- 经验主义
基于香农(Shannon)信息论
- 理性主义
通过特殊的语句或语言现象的研究得到对人的语言能力的认识
- 经验主义
偏重对大规模语言数据中实际使用的语句进行统计
理性主义的问题求解方法
基于规则的分析方法,建立符号处理系统
知 识 库 + 推 理 系 统 → N L P 系 统 知识库+推理系统\rightarrow NLP~系统知识库+推理系统→N L P 系统
理论基础:Chomsky的文法理论
经验主义的问题求解方法
基于大规模真实语料的计算方法
语 料 库 + 统 计 模 型 → N L P 系 统 语料库+统计模型\rightarrow NLP~系统语料库+统计模型→N L P 系统
理论基础:统计学、信息论、机器学习
理性主义和经验主义的合谋
符号智能+计算智能,建立融合方法
研究现状
部分问题得到解决,可以提供辅助帮助;基础问题没有解决,技术不能应用于实践;社会需求日益迫切
国内外研究机构
Original: https://blog.csdn.net/weixin_45743469/article/details/122168939
Author: GxxxMiii
Title: chap1-绪论
相关阅读2
Title: 【ESP32 开发】ArduinoJson联合PSRAM解决 ESP32内存过小 无限重启的问题
一、前言
最近使用ESP32 WROOM开发语音识别项目时,需要使用阵列麦克风采集信号,并进行切片取出含有语音部分的片段,进而使用base64编码将语音上传到后端服务器进行识别。
在项目开发时,发现虽然ESP32 WROOM有520KB的SRAM,但是还是无法满足语音识别的需求。
查找资料后,发现ESP32-S3N16R8带有8MB的PSRAM,ESP32-S3 PSRAM的配置与测试方法见之前的一篇笔记。
本篇文章首先介绍Arduino环境中常用的Json库 ArduinoJson的普通用法,然后介绍联合PSRAM使用的方法。
二、ArduinoJson普通用法
ArduinoJson的安装方法可以看之前的一篇笔记。在 库管理器中搜索 ArduinoJson并下载即可。
ArduinoJson官方库地址为:https://github.com/bblanchon/ArduinoJson
快速上手:ArduinoJson官方贴心地提供了 Json助手,可以根据Json格式自动生成代码:https://arduinojson.org/v6/assistant/#/step1
1. ArduinoJson V6版本库函数
库函数整理引自:finedayforu

; 2. 核心类JsonDocument(内存管理)
JsonDocument作为整个V6版本ArduinoJson库的内存入口,负责处理整个json数据的内存管理,分为两个实现类:
- (1)DynamicJsonDocument
内存分配在heap区,无固定大小,可以自动增长所需空间,方法调用完自动回收,建议内存大小大于1KB使用;
DynamicJsonDocument doc(2048); //创建一个DynamicJsonDocument类型的doc对象,大小2048byte
- (2)StaticJsonDocument
StaticJsonDocument,内存分配在stack区,有固定大小,大小值由开发者定义,方法调用完自动回收,建议内存大小小于1KB使用;
StaticJsonDocument doc;
3. 具体使用案例
转自:Naisu Xu
(1)反序列化
- 引用ArduinoJson库;
- 声明JsonDocument对象;
- 尝试反序列化json字符串到JsonDocument对象;
- 根据需求取用数据;
#include
char myJson[] = "{\"myChar\":\"hello\",\"myArray\":[13,14],\"myObject\":{\"myFloat\":3.1415926}}";
void setup()
{
Serial.begin(115200);
Serial.println();
DynamicJsonDocument doc(200);
DeserializationError error = deserializeJson(doc, myJson);
if (!error)
{
const char *myC = doc["myChar"];
int myN0 = doc["myArray"][0];
int myN1 = doc["myArray"][1];
float myF = doc["myObject"]["myFloat"];
Serial.println(myC);
Serial.println(myN0);
Serial.println(myN1);
Serial.println(myF);
}
}
void loop()
{
}

(2)序列化
- 引用ArduinoJson库;
- 声明JsonDocument对象;
- 向JsonDocument对象中添加数据;
- 序列化处理JsonDocument对象使成为json字符串;
#include
void setup()
{
Serial.begin(115200);
Serial.println();
DynamicJsonDocument doc(200);
doc["myChar"] = "hello";
JsonArray myA = doc.createNestedArray("myArray");
myA.add(true);
myA.add(false);
JsonObject myO = doc.createNestedObject("myObject");
myO["myNumber"] = 1234567890;
serializeJson(doc, Serial);
Serial.println();
Serial.println();
serializeJsonPretty(doc, Serial);
}
void loop()
{
}

三、ArduinoJson联合PSRAM用法
ArduinoJson官方对PSRAM的介绍见:https://arduinojson.org/v6/how-to/use-external-ram-on-esp32/
ArduinoJson中默认使用 malloc()函数分配SRAM空间;而使用PSRAM需要使用 heap_caps_malloc(MALLOC_CAP_SPIRAM)函数分配空间。因此,要联合PSRAM使用,就不能像上面一样直接调用 DynamicJsonDocument
下面是具体实现案例:
struct SpiRamAllocator {
void* allocate(size_t size) {
return heap_caps_malloc(size, MALLOC_CAP_SPIRAM);
}
void deallocate(void* pointer) {
heap_caps_free(pointer);
}
void* reallocate(void* ptr, size_t new_size) {
return heap_caps_realloc(ptr, new_size, MALLOC_CAP_SPIRAM);
}
};
using SpiRamJsonDocument = BasicJsonDocument<SpiRamAllocator>;
这个片段定义的 SpiRamJsonDocument类的使用方法与 JsonDocument一致:
SpiRamJsonDocument doc(1048576);
deserializeJson(doc, input);
注意事项:
- 不能声明一个全局变量SpiRamJsonDocument,因为它会heap_caps_malloc()在 PSRAM 准备好使用之前调用。
- 需要开启PSRAM,否则ESP32-S3会无限重启。开启方法见之前的一篇笔记。
- ArduinoJson V5和V5并不兼容,注意检查版本为V6。
完整demo如下:
Original: https://blog.csdn.net/m0_43395703/article/details/125705231
Author: SimYng
Title: 【ESP32 开发】ArduinoJson联合PSRAM解决 ESP32内存过小 无限重启的问题
相关阅读3
Title: 实验---采用SOM网络进行聚类
1.SOM网络简介
自组织特征映射网络SOFM又称自组织映射网络SOM,是一种自组织竞争神经网络,一个神经网络接受外界输入模式时,将会分为不同的对应区域,各区域对输入模式具有不同的响应特征,而且这个过程是自动完成的。其特点与人脑的自组织特性相类似。
其主要思想是在学习过程中逐步缩小神经元之间的作用邻域,并依据相关的学习规则增强中心神经元的激活程度,从而去掉各神经元之间的侧向连接,以达到模拟真实大脑神经系统"近兴奋远抑制"的效果。
2.SOM实现聚类实验
(1)导入数据 选用MATLAB自带的数据simplecluster_dataset,该数据包含输入变量simpleclusterInputs,有1000组数据,每组数据为二维向量;目标输出变量simpleclusterTargets,有1000组数据,每组数据为四维向量,表示其类别。
代码如下:
%加载MATLAB自带数据simplecluster_dataset;
load simplecluster_dataset;
%将simpleclusterInputs和simpleclusterTargets分别赋值给x和t
[x,t] = simplecluster_dataset;
%绘制数据分析图
plot(x(1,:),x(2,:),'+')
执行结果如下:
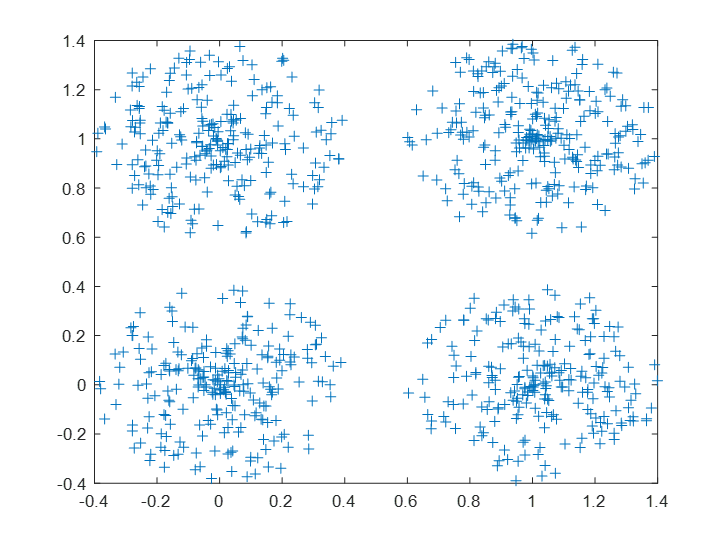
图1.数据分析图
(2)创建SOM网络 采用函数selforgmap创建SOM网络,该函数定义在两个学习阶段中使用的变量:
排序阶段学习率、排序阶段步骤、调整阶段学习率、调整阶段邻域距离,这些值用于训练和自适应。
创建网络需要指定映射大小,这对应于网格中的行数和列数。对于此示例,可以将映射大小值设置为 10,这对应于 10 行 10 列的网格。神经元的总数等于网格中的点数,在此例中,映射有 100 个神经元。可以在网络窗格中看到网络架构
代码如下:
dimension1=10;
dimension2=10;
%net为一个SOM网络
net = selforgmap([dimension1 dimension2]);
若设计为一维线阵,只写一个参数即可。例如selforgmap([dimension1])
也可以使用以下代码配置网络以输入数据并绘制所有这些数据
net = configure(net,x);
plotsompos(net,x);%绘制未训练前的权值位置
执行结果如下:
绿点是训练向量。selforgmap 的初始化将初始权重分布到整个输入空间。它们最初离训练向量有一定距离。
(3)训练网络
首先,网络为每个输入向量确定获胜神经元。随后将每个权重向量移至特定位置,即它作为获胜神经元或位于获胜神经元的临域时的所有对应输入向量的平均位置。定义邻域大小的距离在训练过程中的两个阶段会更改。
排序阶段
该阶段持续给定的步数。邻域距离从给定的初始距离开始,并减小到调整邻域距离 (1.0)。随着邻域距离在此阶段逐步减小,网络的神经元通常在输入空间中以与它们自己的物理排序相同的拓扑进行排序。
调整阶段
此阶段持续训练或自适应阶段的其余部分。邻域大小已降至 1 以下,因此只有获胜神经元对每个样本进行学习。
可以使用以下代码对网络进行训练
%net.trainParam.epochs = 1000; %对网络进行1000轮数的训练,也可以不设置系统默认为200轮
net = train(net,x);%查看网络训练界面
plotsompos(net,x);%绘制训练后的权值位置
view(net); 查看网络结构及数据分类结果
执行结果如下:
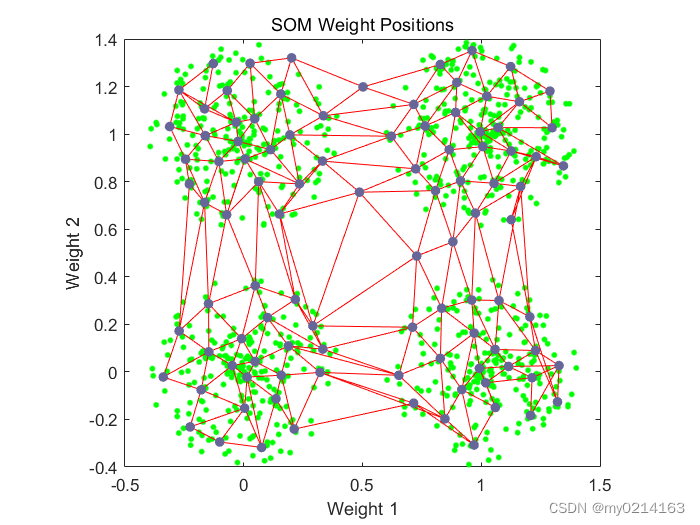
由上下两个图对比可以看到神经元已开始向不同训练组移动。直到训练到指定轮数。
在神经元更新其权重方面,自组织映射不同于传统的竞争学习。特征图不是只更新获胜神经元,而是更新获胜神经元及其邻点的权重。结果是相邻的神经元倾向于具有相似的权重向量,并对相似的输入向量作出响应。
(4)结果分析
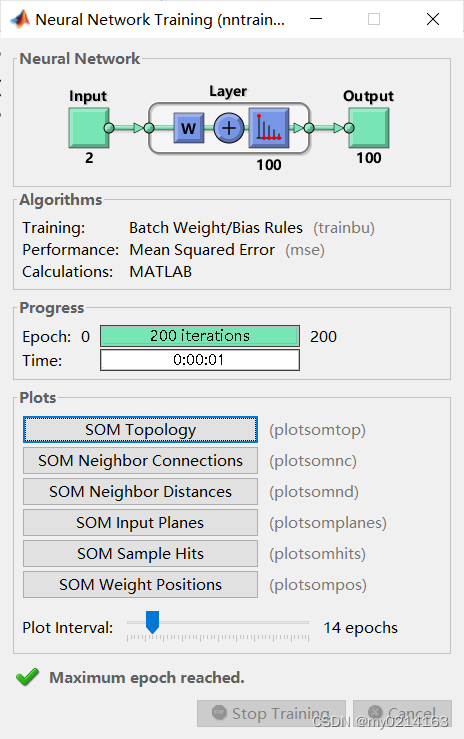
训练结果如上图所示是一个【Neural Network Training】的窗口。
在【Neural Network】图框下可以查看网络结构及数据分类结果,也可以用view(net);命令查看
在【Algorithms】图框中可以看到自组织特征映射中的默认学习在批量模式 (trainbu) 下进行,是以平均平方误差来表现的以及是运用MATLAB来计算的。
在【Progress】图框中显示了网络训练的次数200次以及运行的时间。
在【Plots】图框中显示六个按钮分别可以观察网络的拓扑结构(SOM Topology)、权值连接情况(SOM Neighbor Connections)、领域间的距离(SOM Neighbor Distance)、与输入连接的权值分布情况(SOM Input Planes)、输入激活神经元的情况(SOM Sample Hits)、权值的位置(SOM Weight Positions)。
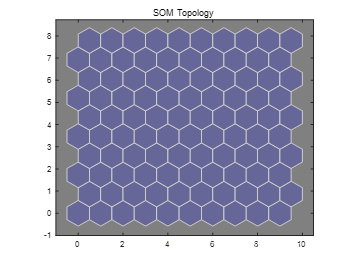
点击【SOM Topology】按钮或者输入plotsomtop(net)(这里的net为用selforgmap设置的SOM网络,没有数据集中的数据训练)命令可以查看SOM的网络的拓扑结构,如下图所示。每一个蓝色的六边形是一个神经元,在二维平面上排布为10×10的方阵,每一个神经元与其他六个神经元相连(默认为六边形结构,也可以设置为其他结构,边缘神经元除外)
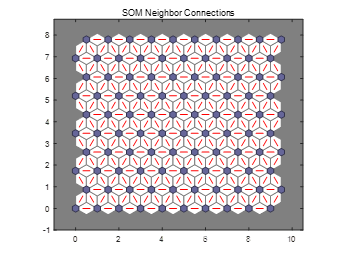
接着点击【SOM Neighbor Connections】按钮或者输入plotsomtop(net)(这里的net为运用数据集simplecluster_dataset 中的输入变量simpleclusterInputs训练后的,以后输入的net都是)如下图所示。可以看到权值连接情况:红色的线表示两个神经元之间存在连接。
接着点击【SOM Neighbor Distance】按钮或者输入plotsomnd(net)。如下图所示。可以看到神经元之间的连接强度,也就是神经元之间的距离。颜色越深表示神经元的距离越远,可以比较明显地看出在图中形成了两条交叉的分界线,把区域分成四部分,而每一部分恰好与样本的分布区吻合。

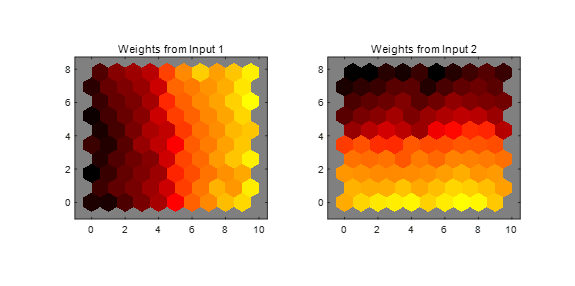
接着点击【SOM Input Planes】按钮或者输入plotsomplanes(net)。如下图所示。可以看出输入特征的每个元素的权重平面(此例中有两个),该图显示将每个输入连接到每个神经元的权重,颜色越暗,表示权重越大。如果两个特征的连接模式非常相似,则可以假设这两个特征高度相关。此例中输入1与输入2的连接模式非常不同。
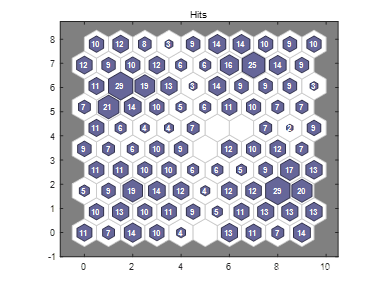
接着点击【SOM Sample Hits】按钮或者输入plotsomhits(net,x)。如下图所示。该拓扑是一个 10×10 网格,因此有 100 个神经元。可以看出拓扑中的神经元位置,并指示每个神经元(簇中心)有多少观测值相关联。此图中数字最大的是29,位于第八行第二列(左下角为原点)表示神经元成为28个输入样本的聚类中心。没有数字的表示该神经元没有被激活。
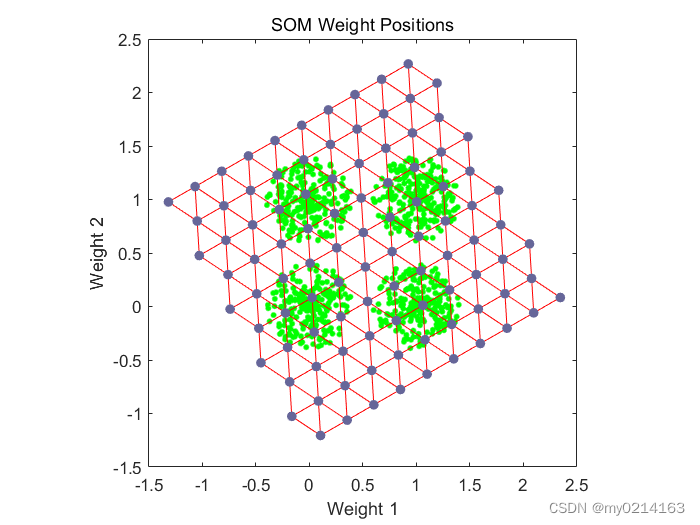
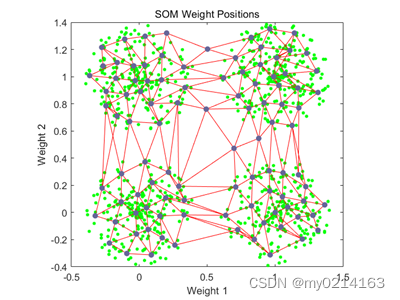
最后点击【SOM Weight Positions】按钮与上述输入plotsompos(net,x);命令结果一致都是显示此例中的二维权值向量的位置。每一个深色的点表示神经元对应权值的位置,红线表示拓扑连接,可以看出,尽管网络的拓扑结构发生了变形,但任然保持一定的规律,即相邻神经元的权值位置也比较接近。
(5)测试网络 网络训练完成后,如果要确定输入向量究竟属于哪一个类别可以输入以下命令:
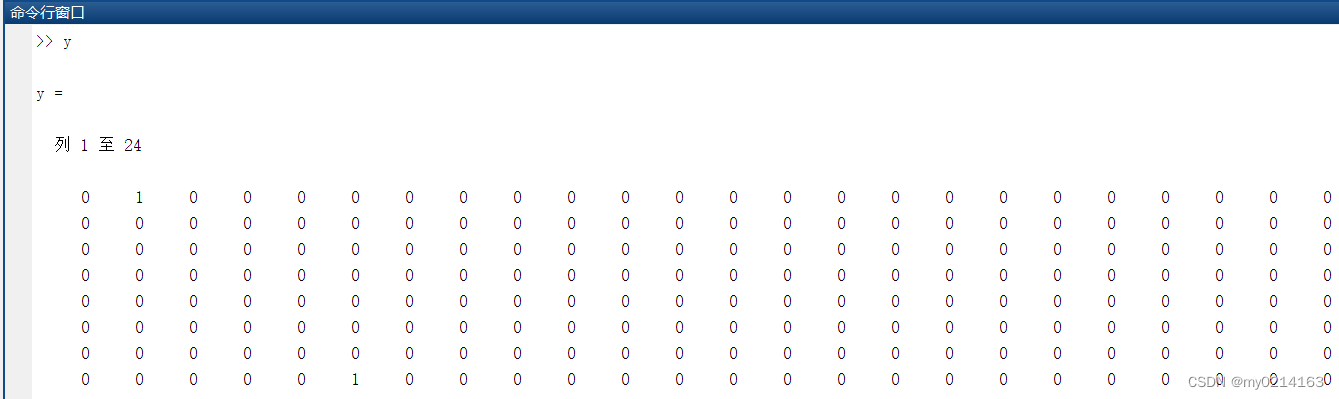
y = net(x);%根据输入x得到网络的输出
y为100×1000的矩阵,列号表示输入向量的编号,如下图所示。行中的1表示该位置的神经元被激活,0表示未被激活。很明显这是一个稀疏矩阵,不易观察,因此使用以下命令:
classes = vec2ind(y);%vec2ind将单值向量组转换成下标向量组
此时这里的classes为1×1000的向量,也就是每个样本激活函数的神经元的编号。如下图所示。

(6)如果对网络性能不满意,可以执行以下操作之一:
①重新训练网络。每次训练都会采用不同网络初始权重和偏置,并且在重新训练后可以产生改进的网络。
②通过增大映射大小来增大神经元的数量。
③使用更大的训练数据集。
还可以评估基于附加测试集的网络性能需要加载附加测试数据来评估网络。
3.实验结果及分析(或实验体会)
本次实验测试了运用SOM网络对数据集进行聚类,自组织映射神经网络, 即Self Organizing Maps (SOM), 可以对数据进行无监督学习聚类。它的思想很简单,本质上是一种只有输入层--隐藏层的神经网络。隐藏层中的一个节点代表一个需要聚成的类。训练时采用"竞争学习"的方式,每个输入的样例在隐藏层中找到一个和它最匹配的节点,称为它的激活节点,也叫"winning neuron"。 紧接着用随机梯度下降法更新激活节点的参数。同时,和激活节点临近的点也根据它们距离激活节点的远近而适当地更新参数。
实验只需要运用简单几个命令即可完成,没有出现错误,但对于用MATLAB绘制SOM网络结构图及训练过程需要完全理掌握。只有理解具体过程才能真正理解SOM网络及运用网络实现各种应用。
Original: https://blog.csdn.net/hanmengyuan2001/article/details/125065207
Author: my0214163
Title: 实验---采用SOM网络进行聚类