
1建立网络
class AgentNet():
def __init__(
self,
name,
n_action,
n_state,
learning_rate=0.001,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=300,
memory_size=50000,
batch_size=32,
e_greedy_increment=None
):
self.n_action = n_action
self.n_state = n_state
self.alpha = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
self.name = name
self.sess = sess
self.build()
self.learn_step_counter = 0
self.memory = []
self.losses = []
'''复制网络'''
t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net')
with tf.variable_scope('hard_replacement'):
self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
def build(self,hidden_dim=64):
with tf.variable_scope(self.name):
self.s = tf.placeholder(tf.float32, [None, self.n_state], name='s')
self.s_ = tf.placeholder(tf.float32, [None, self.n_state], name='s_')
self.r = tf.placeholder(tf.float32, [None, ], name='r')
self.a = tf.placeholder(tf.int32, [None, ], name='a')
with tf.variable_scope("eval_net"):
hidden = tf.layers.dense(self.s,hidden_dim,activation=tf.nn.relu)
hidden = tf.layers.dense(hidden, hidden_dim, activation=tf.nn.relu)
self.q_eval = tf.layers.dense(hidden,self.n_action)
with tf.variable_scope("target_net"):
hidden = tf.layers.dense(self.s_, hidden_dim, activation=tf.nn.relu)
hidden = tf.layers.dense(hidden, hidden_dim, activation=tf.nn.relu)
self.q_next = tf.layers.dense(hidden, self.n_action)
with tf.variable_scope('q_target'):
q_target = self.r + self.gamma * tf.reduce_max(self.q_next, axis=1, name='Qmax_s_')
self.q_target = tf.stop_gradient(q_target)
with tf.variable_scope("q_eval"):
a_indices = tf.stack([tf.range(tf.shape(self.a)[0], dtype=tf.int32), self.a], axis=1)
self.q_eval_wrt_a = tf.gather_nd(params=self.q_eval, indices=a_indices)
with tf.variable_scope("loss"):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval_wrt_a, name='TD_error'))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.alpha).minimize(self.loss)
其含义是:
2 网络的使用
在与环境互动时采用
action = net.choose_action(obs)
选择动作,其中net.choose_action(state)函数是这么定义的:
def choose_action(self,state):
if np.random.random() > self.epsilon:
action_chosen = np.random.randint(0, self.n_action)
else:
state = state[np.newaxis, :]
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: np.array(state)})
action_chosen = np.argmax(actions_value)
return action_chosen
按照贪心策略执行动作,当贪心时根据当前状态s运算得到q_eval,取最大值的动作返回
3 训练网络
Transition = collections.namedtuple("Transition", ["state", "action", "reward", "next_state"])
'''执行eposide次环境'''
if len(net.memory) > net.memory_size:
net.memory.pop(0)
reward = reward if player=="agent_0" else -reward
net.memory.append(Transition(obs, action, reward, next_obs))
if len(net.memory) > net.batch_size * 4:
batch_transition = random.sample(net.memory, net.batch_size)
batch_state, batch_action, batch_reward, batch_next_state = map(np.array, zip(*batch_transition))
loss = net.train(state=batch_state,
reward=batch_reward,
action=batch_action,
state_next=batch_next_state,
)
update_iter += 1
net.losses.append(loss)
首先,在每次执行完成后将{s,a,r,s_} 存入memory中,当积累到一定量之后,按批次提取memory并训练网络,net.train函数定义如下
def train(self,state,reward,action,state_next):
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.target_replace_op)
_,loss = self.sess.run([self._train_op,self.loss],
feed_dict={
self.s:np.array(state),
self.s_:np.array(state_next),
self.a:np.array(action),
self.r:np.array(reward)
})
self.learn_step_counter += 1
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
return loss
其中第一行是每隔多少步将eval_net的网络参数复制给target_net网络,其定义在类的init中.
self.sess.run()将收集到的(s,a,s_,r)传入tensorflow中,运行网络得到loss并更新了网络
。
其实就是建立一个网络,然后在每次执行action时调用网络,收集数据后训练网络,没了。
等我会用github时将函数传上去
Original: https://blog.csdn.net/qq_41751199/article/details/121900149
Author: 剑未佩妥已入江湖
Title: 使用tensorflow快速搭建 DQN环境
相关阅读1
Title: imdb_reviews电影评论数据集的神经网络
文章目录
如何录入信息
文字和图像不同
图像可以将对应的像素点的亮度值或者RGB值转换成张量,然后送入神经网络,但是文字又怎么办呢?
这就需要对文字进行词条化处理,也就是编码,将对应的单词,文字转换成词典中的一个数字,这样一段话,一篇文章就可以使用数字矩阵来表示了
载入数据
tensorflow-datasets中由我们需要的数据
需要pip install tensorflow-datasets
import tensorflow_datasets as tfds
imdb,info = tfds.load('imdb_reviews', with_info=True, as_supervised=True)

imdb_reviews中由训练集核测试集
train_data, test_data = imdb['train'], imdb['test']
training_sentences = []
training_labels = []
testing_sentences = []
testing_labels = []
for s,l in train_data:
training_sentences.append(str(s.numpy()))
training_labels.append(l.numpy())
for s,l in test_data:
testing_sentences.append(str(s.numpy()))
testing_labels.append(l.numpy())

神经网络要求输入向量,这里需要将label转换成向量
training_lable_final = np.array(training_labels)
testing_label_final = np.array(testing_labels)

词条化处理
from tensorflow.keras.preprocessing.text import Tokenizer
num_words = 10000
oov_token = "##"
tokenizer = Tokenizer(num_words=num_words, oov_token=oov_token)
tokenizer.fit_on_texts(training_sentences)
word_dict = tokenizer.word_indx
print(word_dict)

词条序列化
将句子中的单词按照word_dict中的数字转换成一个序列化矩阵
在此之前需要将句子序列化
词条的最大长度维120
默认在不满足长度时,在后面填充0
from tensorflow.keras.preprocessing.sequence import pad_sequences
max_length = 120
train_sequence = tokenizer.texts_to_sequence(training_sentences)
padded_train = pad_sequences(train_sequence, maxlen=max_length,truncate='post')
test_sequence = tokenizer.texts_to_sequence(testing_sentences)
padded_test = pad_sequences(test_sequence, maxlen=max_length, truncate='post')
print(padded_train)
print(padded_test)

搭建神经网络
embedding_dim = 16
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=num_words,
output_dim=embedding_dim,
input_length=max_length,
name='embed-1'),
tf.keras.layers.GlobalAveragePooling1D(name='globalave-1'),
tf.keras.layers.Dense(6, activation='relu', name='fully-1'),
tf.keras.layers.Dense(1, activation='sigmoid', name='sigmoid-1')
])
model.compile(loss=tf.losses.binary_crossentropy, optimizer=tf.optimizers.Adam(), metrics=['accuracy'])
model.summary()
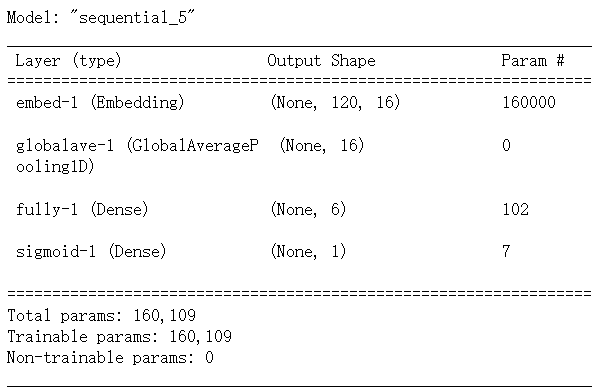
输入数据
model.fit(padded_train,training_lable_final, epochs=10, validation_data=(padded_test, testing_label_final))
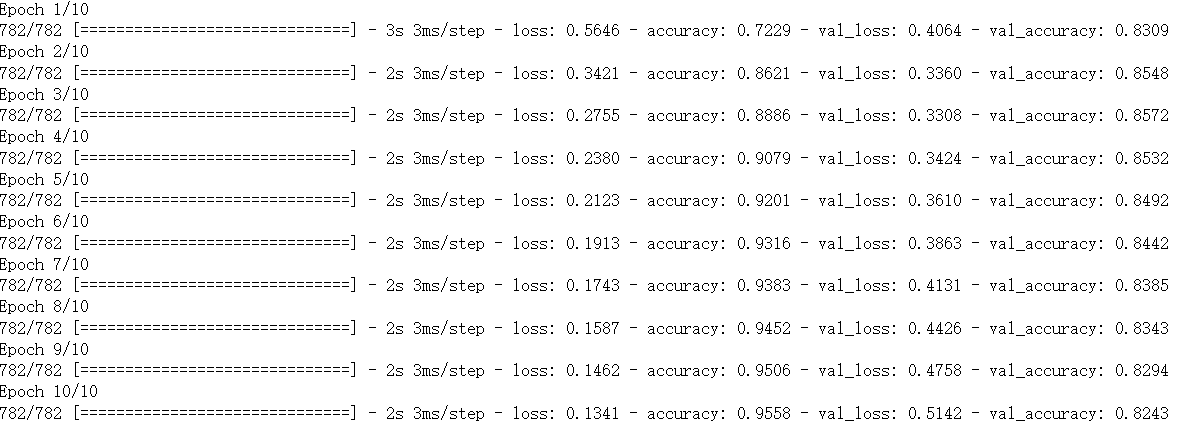
可视化
import io
e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape)
reverse_word_dict = dict([(value, key) for(key, value) in word_dict.items()])
out_v = io.open("E:/datasets/tmp/language-splite/vecs.tsv", 'w', encoding='utf8')
out_m = io.open("E:/datasets/tmp/language-splite/meta.tsv", 'w', encoding='utf8')
for word_num in range(1, vocab_size):
word = reverse_word_dict[word_num]
embeddings = weights[word_num]
out_m.write(word + '\n')
out_v.write('\t'.join([str(x) for x in embeddings]) + '\n')
out_m.close()
out_v.close()
这样访问projector.tensorflow.org然后再上传tsv文件就可以看到相应的词汇的分布了(外国网站,需要科学上网)
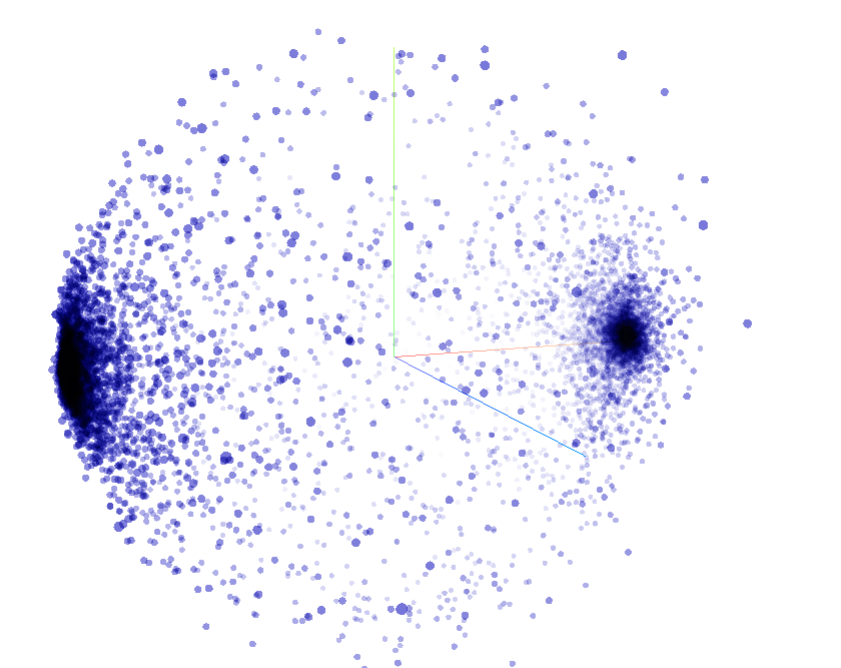
Original: https://blog.csdn.net/m0_56104219/article/details/124543062
Author: 君子以阅川
Title: imdb_reviews电影评论数据集的神经网络
相关阅读2
Title: 激光slam课程学习笔记--第11课:3D激光SLAM介绍
前言:这系列笔记是学习曾书格老师的激光slam课程所得,这里分享只是个人理解,有误之处,望大佬们赐教。这节课主要介绍一些3d slam数学知识,以及典型代表loam。
1. 3d激光SLAM
1.1 介绍

[在地图上,2d的是三个自由度的;3d的是六个自由度的;三维包含微分流形(多次的三个自由度导致的)(个人没理解)]
; 1.2 对比
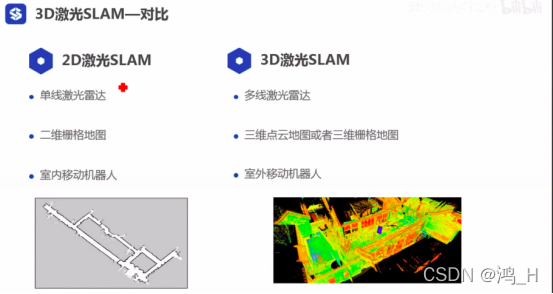
1.3 3d slam的帧间匹配--点到面距离方法
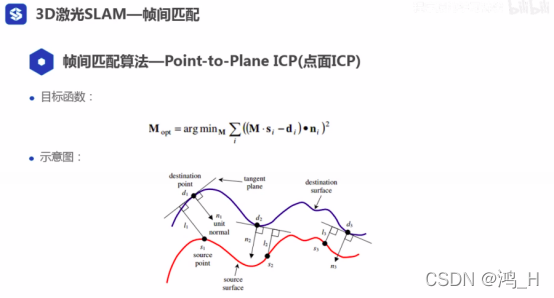
[回环检测,本质也是帧间匹配]
[这里的目标函数表示的是点到面的距离]
; 1.4 帧间匹配算法--基于特征的方法

[由于其采用的多线雷达,匹配时可类似采用图像的方式(基于特征方法)进行帧间匹配]
1.5 NDT方法

[该方法和似然场方法类似][目标函数的每个方格是连续的]
[老师说,在领域中,公式是基础,但是最重要的是奇思妙想,因为公式是大家都是知道的,但是区别别人的,就是个人的奇思妙想]
; 2. LOAM
[介绍基本流程+代码]
[这里的loam方法,只有匹配,没有回环]
2.1 loam
[该方法没有做了回环的]
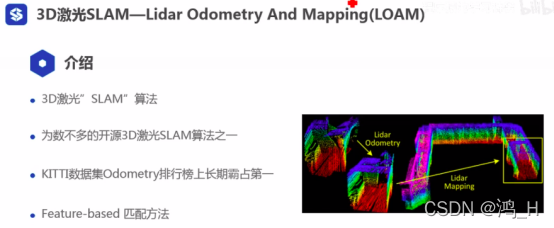
[帧间匹配+单帧局部子图匹配]
[特征匹配方法,提取特征进行匹配;老师建议多种方法使用最好]
; 2.2 框架
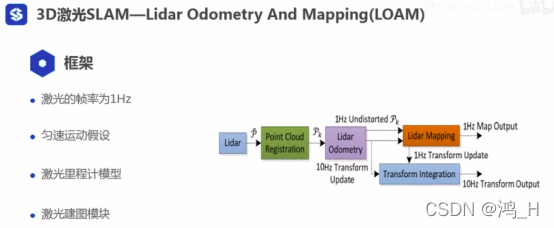
2.3 激光里程计模块

[edge point 指的是两个面的交接处的点;planar point 指的是面上的点(非边界处)][两种点的划分,是根据曲率进行划分的,利用点的附近点进行曲率计算;曲率大的称为edge point,小的称为planar point]
[去除不稳定点,左侧图的b点是跟射线平行的,这种点会被剔除;右侧图的a点从一个角度看是edge point,从另外一个角度看,其又属于planar point,故直接剔除]
; 2.4 特征点匹配
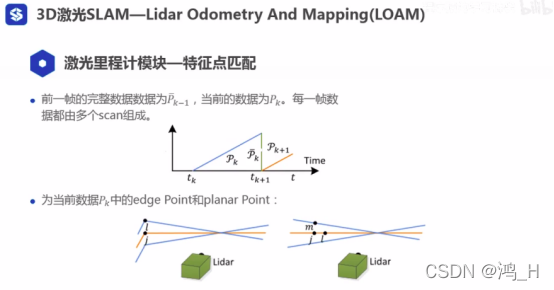
[注意当前的数据pk是不完整的]

[点到线的距离][点到面的距离]
2.5 运动估计

[位姿涉及线性插值]

; 2.6 总结--里程计模块

2.7 总结--激光建图模块

[Qk,是去除畸变的完整sweep]
; 2.8 总结--直线匹配

2.9 例子

[帧间匹配+建图+定位+图优化--->激光slam算法,老师认为这些知识都讲解了,我们应该可以自己编写一个简单的激光slam算法(个人表示还不会,实在惭愧)]
[跑马观花,公式原理都没有理解,代码也没有理解]
该系列课程2022年正月初二晚上22:13结
图片版权归原作者所有
致谢曾老师的付出
不积硅步,无以至千里
好记性不如烂笔头
感觉有点收获的话,麻烦大大们点赞收藏哈
Original: https://blog.csdn.net/qq_45701501/article/details/124368673
Author: 鸿_H
Title: 激光slam课程学习笔记--第11课:3D激光SLAM介绍
相关阅读3
Title: vite2 打包的时候vendor-xxx.js文件过大的解决方法
vite2是一个非常好用的工具,只是随着代码的增多,打包的时候 vendor-xxxxxx.js 文件也越来越大,这就郁闷了。
输出文件名字/static/vendor.9b5698e4.js 806.03kb / brotli: skipped (large chunk)
Some chunks are larger than 500kb after minification. Consider:
- Using dynamic import() to code-split the application
- Use build.rollupOptions.output.manualChunks to improve chunking: rollup.js
- Adjust chunk size limit for this warning via build.chunkSizeWarningLimit.
由于打包时有些依赖包体积过于庞大,提示你进行配置分割;
module.exports = {
build: {
rollupOptions: {
output:{
manualChunks(id) {
if (id.includes('node_modules')) {
return id.toString().split('node_modules/')[1].split('/')[0].toString();
}
}
}
}
}
}
尝试了一下,确实可以分成多个文件,但是问题又来了,分成的文件有大有小,大文件可以接受,但是一堆几k的小文件看着就烦了,于是又想了想,发现可以这样。
build: {
sourcemap: true,
outDir: 'distp', //指定输出路径
assetsDir: 'static/img/', // 指定生成静态资源的存放路径
rollupOptions: {
output: {
manualChunks(id) {
if (id.includes('node_modules')) {
const arr = id.toString().split('node_modules/')[1].split('/')
switch(arr[0]) {
case '@kangc':
case '@naturefw':
case '@popperjs':
case '@vue':
case 'axios':
case 'element-plus':
return '_' + arr[0]
break
default :
return '__vendor'
break
}
}
},
chunkFileNames: 'static/js1/[name]-[hash].js',
entryFileNames: 'static/js2/[name]-[hash].js',
assetFileNames: 'static/[ext]/[name]-[hash].[ext]'
},
brotliSize: false, // 不统计
target: 'esnext',
minify: 'esbuild' // 混淆器,terser构建后文件体积更小
}
},
按照模块分开打包,大模块独立打包,小模块合并打包,这样就不会出现一大堆小文件了。
经过不断尝试发现,@kangc(@kangc/v-md-editor)也就是md的编辑器不能单独打包,会报错。
还有 axios 也不能单独打包,会报错。
if (id.includes('node_modules')) {
const arr = id.toString().split('node_modules/')[1].split('/')
switch(arr[0]) {
case '@naturefw': // 自然框架
case '@popperjs':
case '@vue':
case 'element-plus': // UI 库
case '@element-plus': // 图标
return '_' + arr[0]
break
default :
return '__vendor'
break
}
}
这几个可以分开打包,其他的遇到再说。
Original: https://www.cnblogs.com/jyk/p/16029074.html
Author: 金色海洋(jyk)
Title: vite2 打包的时候vendor-xxx.js文件过大的解决方法