
文章目录
🥝🥝向量化
因为 文本不能够直接被模型计算,所以需要将其转化为向量
把文本转化为向量有两种方法:
- 转化为
one-hot编码 - 转化为
word embedding<
Original: https://blog.csdn.net/qq_43940950/article/details/124127858
Author: 炫云云
Title: 1.2 文本表示——Emdedding
相关阅读1
Title: SSD(Single Shot MultiBox Detector)笔记
前言
本文用于记录学习SSD目标检测的过程,并且总结一些精华知识点。
为什么要学习SSD,是因为SSD和YOLO一样,都是 one-stage的经典构架,我们必须对其理解非常深刻才能举一反三设计出更加优秀的框架。SSD这个目标检测网络全称为 Single Shot MultiBox Detector,重点在 MultBox上,这个思想很好地利用了多尺度的优势,全面提升了检测精度,之后的YOLOv2就借鉴了SSD这方面的思路才慢慢发展起来。
强烈建议阅读官方的论文去好好理解一下SSD的原理以及设计思路。这里也提供了相关的pdf:http://www.cs.unc.edu/~wliu/papers/ssd_eccv2016_slide.pdf
当然也有很多好的博客对其进行了介绍,在本文的最下方会有相关链接。本篇文章主要为自己的笔记,其中加了一些自己的思考。
网络构架
SSD的原始网络构架建议还是以论文为准,毕竟平时我们接触到的都是各种 魔改版(也就是所谓的换了backbone,例如最常见的SSD-mobilenetv2),虽然与原版大同小异,不过对于理解来说,会增大我们理解的难度,因此,完全有必要看一遍原始的论文描述。
SSD在论文中是采取的VGG网络作为主干结构,但是去除了VGG中的最后几层(也就是我们经常说的分类层),随后添加了一些新的内容(在原文中叫做auxiliary structure),这些层分别是:
- 额外的特征提取层(Extra Feature Layers),作用就是和原本
backbone的层相结合共同提取出不同尺寸的特征信息,相当于加强了之前的backbone,使其网络更深,提取能力更加强大。 - 分类层(classification headers),对之前网络中的不同位置网络层输出的特征层(不同尺度),进行卷积得出每个特征图中每个坐标对应的分类信息(每个坐标对应着许多default boxes)。
- 坐标位置回归层(regression hearders),结构与分类层相仿,只是输出的通道略有不同,通过对不同尺度的特征图进行卷积,输出的是每个特征图中每个坐标对应的 default boxes的偏移坐标(文章中称为shape offset)。

总体来说,SSD网络结构其实有四部分组成,backbone部分、额外添加的特征提取层、分类层以及坐标位置回归层。注意当初这篇SSD是出于Yolo一代之后二代之前,Yolo二代三代中不同尺度的特征图思想是有借鉴于SSD的。
用于检测的多尺度特征图
多尺度特征图具体表示就是SSD在整个网络的不同位置,取出相应的特征层进行预测,每个特征层因为尺度不一样可以检测的视野以及目标物体的大小也不同。每个特征图可以预测出分类信息和位置信息,如下图中可以看到整个网络使用从前到后使用了6个不同的特征图,从 38x38x512到 1x1x256一共六个不同尺度的特征图。
也就是 使用低层feature map检测小目标,使用高层feature map检测大目标,是SSD的突出贡献。

那么 default box是如何产生?
default box
论文中的原话是这样的:
We associate a set of default bounding boxes with each feature map cell, for multiple feature maps at the top of the network. The default boxes tile the feature map in a convolutional manner, so that the position of each box relative to its corresponding cell is fixed. At each feature map cell, we predict the offsets relative to the default box shapes in the cell, as well as the per-class scores that indicate the presence of a class instance in each of those boxes.
就是对于上述每一个不同尺度的特征图(38x38、19x19、10x10、5x5、3x3、1x1),每一个特征图中的坐标中(cell)产生多个default box。对于每个 default box,SSD预测出与真实标定框的偏移(offsets,一共是4个数值,代表位置信息)以及对应于每个类的概率confidence($c_1 ,c_2, ..., c_p$)。如果一共有c类,每一个坐标产生k个box,那么我们在进行训练的时候,每个cell就会产生(c+4)k个数据,如果特征图大小为mxn,那么总共就是(c+4)kmn,例如3x3的特征图,mxn就是3x3。
注意下,上述的那个offset不仅是相对于 default box,换个角度来说,也是相对于真实标定框的偏移,通俗了说就是 default box加上offsets就是真实标定框的位置。这个offsets是我们在训练学习过程中可以计算出来用于损失函数来进行优化的。
在实际预测中,我们要预测出每个default box的category以及对应的offset。

这部分我看到更好的介绍,所以这里不进行赘述,可以直接看这里:解读SSD中的Default box(Prior Box)。
训练过程
不光要从论文中理解一个网络的细节部分,还需要详细了解一下训练的具体过程:
因为我们要在特征图上生成 default box,那么在训练阶段我们就需要将GT(Ground Truth)与default box相对应才能进行训练,怎么个对应法,SSD中使用了一个IOU阈值来控制实际参与计算的default box的数量, 这一步骤发生在数据准备中:

首先要保证每个GT与和它度量距离最近的(就是iou最大)default box对应,这个很重要,可以保证我们训练的正确性。另外,因为我们有很多狠多的default box,所以不只是iou最大的default box要保留,iou满足一定阈值大小的也要保留下来。
也就是说,训练的过程中就是要判断哪个 default boxes和具体每一张图中的真实标定框对应,但实际中我们在每个特征图的每个cell中已经产生了很多 default boxes,SSD是将所有和真实标定框的IOU(也就是jaccard overlap)大于一定阈值(论文中设定为0.5)的default boxes都保留下来,而不是只保留那个最大IOU值的 default box(为什么要这么做,原论文中说这样有利于神经网络的学习,也就是学习难度会降低一些)。
这样我们就在之前生成的default boxes中,精挑细选出用于训练的 default boxes(为了方便,实际训练中default boxes的数量是不变的,只不过我们直接将那些iou低于一定阈值的 default boxes的label直接置为0也就是背景)。
损失函数
损失函数也是很简单,一共有俩,分别是位置损失以及分类损失:
$$
L(x, c, l, g)=\frac{1}{N}\left(L_{c o n f}(x, c)+\alpha L_{l o c}(x, l, g)\right)
$$
其中$N$为 matched default boxes的数量,这个$N$就是训练过程一开始中精挑细选出来的 default boxes。当$N$为0的时候,此时总体的损失值也为0。而$\alpha$是通过交叉验证最终得到的权重系数,论文中的值为1。
位置损失
其中$x_{i j}^{p}={1,0}$表示当前 defalut box是否与真实的标定框匹配(第$i$个 defalut box与第$j$个真实的标定框,其中类别是$p$),经过前面的match步骤后,有$\sum_{i}x^{p}_{ij}$大于等于1。
$$
L_{l o c}(x, l, g)=\sum_{i \in P \text { os } m \in{c x, c y, w, h}}^{N} \sum_{(c x, c y, w, h}} x_{i j}^{k} \operatorname{smooth} {\mathrm{L1}}\left(l{i}{m}-\hat{g}_{j}{m}\right)
$$
注意,上式中的$\hat{g} {j}^{m}$是进行变化后的 GroundTruth ,变化过程与 default box 有关,也就是我们训练过程中使用的 GroundTruth 值是首先通过 default box 做转换,转化后的值,分别为$\hat{g}{j}^{c x},\hat{g} {j}^{c y},\hat{g}{j}^{w}, \hat{g}_{j}^{h}$,这四个值,分别是真实的标定框 对应 default box的中心坐标$x,y$以及宽度$w$和高度$h$的偏移量。
也就是下面四个转换关系,稍微花一点心思就可以看明白,在训练的时候实际带入损失函数的就是下面这四个转化后的值:
$$
\hat{g} {j}^{c x}=\left(g{j}^{c x}-d_{i}^{c x}\right) / d_{i}^{w} \quad \hat{g} {j}^{c y}=\left(g{j}^{c y}-d_{i}^{c y}\right) / d_{i}^{h}
$$
$$
\hat{g} {j}^{w}=\log \left(\frac{g{j}{w}}{d_{i}{w}}\right) \quad \hat{g} {j}^{h}=\log \left(\frac{g{j}{h}}{d_{i}{h}}\right)
$$
同理,既然我们在训练过程中学习到的是 default box -> GroundTruth Box的偏移量,那么我们在推测的时候自然也要有一个相反的公式给计算回来,将上面的四个公式反转一下即可。
分类损失
分类损失使用交叉熵损失,
$$
L_{c o n f}(x, c)=-\sum_{i \in P o s}^{N} x_{i j}^{p} \log \left(\hat{c} {i}^{p}\right)-\sum{i \in N e g} \log \left(\hat{c} {i}^{0}\right) \quad \text { where } \quad \hat{c}{i}^{p}=\frac{\exp \left(c_{i}^{p}\right)}{\sum_{p} \exp \left(c_{i}^{p}\right)}
$$
需要注意一点就是$x_{i j}^{p}$代表此时的预测box是否与真实标定框匹配,匹配则为1,也就是说分类损失前半部分只考虑与label匹配的,也就是positive boxes。而后半部分$\hat{c} {i}^{0}$则表示背景分类的损失,即negative boxes的损失,想要让$\hat{c}{i}^{0}$越大(背景正确被分为背景),就必须让后半部分的损失越小。
Hard negative mining
这个过程发生在实际训练过程中,因为图像中预测出来的box有很多,而且大部分时negative boxes,所以这里将消除大部分的negative boxes从而使positive与negative的比例达到1:3。首先对之前经过match步骤,精挑细选之后的default boxes计数。这些 default boxes算是positive default boxes,算出此时positive的数量,然后乘以3则是negative boxes的数量。
那么如何去挑选合适数量的negative boxes?SSD中的挑选规则是: 挑选loss最大的boxes,也就是最难学的boxes,根据预测出来的confidence来判断(这段部分的实现可能与论文中会有所不同),那么什么算最难学的,因为我们首先已经根据label(这个label是之前matching过程后的label,label得数量与整张特征图中的boxes数量相同,只不过其中的label已经根据matching步骤进行了调整)得到了positive boxes,这些positive boxes与实际目标都满足一定的条件,而且其中很大概率都有物体。那么最难学的boxes该如何挑选呢?
我们在其余的boxes中,因为其余的这些boxes已经不可能包含目标(因为有目标的在matching中都已经被挑选了,这些是剩下的),所以这些boxes的label理应被预测为 background也就是背景,所以这些boxes关于背景的损失值应该是比较小的,也就是模型较为正确预测了背景。那么我们要选最难识别的boxes,也就是最难识别为背景的boxes,这些叫做negative boxes,首先我们将其余的这些boxes关于背景的loss排序,然后选取前面一定数量(与positive boxes的比值是3:1)的boxes作为negative boxes即可。
这段描述可能有些抽象,配上代码可能更好看一些:
def hard_negative_mining(loss, labels, neg_pos_ratio):
"""
It used to suppress the presence of a large number of negative prediction.
It works on image level not batch level.
For any example/image, it keeps all the positive predictions and
cut the number of negative predictions to make sure the ratio
between the negative examples and positive examples is no more
the given ratio for an image.
Args:
loss (N, num_priors): the loss for each example.
labels (N, num_priors): the labels.
neg_pos_ratio: the ratio between the negative examples and positive examples.
"""
pos_mask = labels > 0
num_pos = pos_mask.long().sum(dim=1, keepdim=True)
num_neg = num_pos * neg_pos_ratio
loss[pos_mask] = -math.inf # put all positive loss to -max
_, indexes = loss.sort(dim=1, descending=True) # sort loss in reverse order (bigger loss ahead)
_, orders = indexes.sort(dim=1)
neg_mask = orders < num_neg
return pos_mask | neg_mask
图像增强
SSD中已经采取了一些比较好的图像增强方法来提升SSD检测 不同大小不同形状的物体,那就是randomly sample,也就是随机在图像片进行crop,提前设定一些比例,然后根据这个比例来对图像进行crop,但是有一点需要注意那就是这个randomly sample中需要考虑到IOU,也就是我们crop出来的图像必须和原始图像中的GT box满足一定的IOU关系,另外crop出来的图像也必须满足一定的比例。
通过randomly sample后的图像其中必定包含原始的GT boxes(不一定全包含),而且crop后的boxes也是正确的。
这部分说起来比较抽象,可以看看这篇文章,我自己懒得进行演示了:
学习率设置
- 官方:优化器使用SGD,初始的学习率为
0.001,momentum为0.9,weight-decay为0.0005,batch-size为32。 - 我个人和官方使用的优化器相同,只不过在学习率上通过
multi-step的方式(具体可以看Pytorch相关实现部分),在80和150个epoch阶段将学习率衰减至之前的1/10。一共训练300个epoch。
训练部分的系数设置仅供参考,不同数据的训练系数略有不同。
预训练权重
个人使用 mobilenetv2-SSD的构架对自己的数据进行了训练,在所有超参数和训练系数不变的情况下,如果采用预训练好的mobilenetv2的权重(在ImageNet上),那么训练速度和最终的训练精度都会高出一截(相同epoch下),所以采用预训练好的权重信息很重要。
总结
SSD是一个优雅的目标检测结构,到现在依然为比较流行的目标检测框架之一,值得我们学习,但是SSD对小目标的检测效果有点差,召回率不是很高,这与SSD的特征图以及semantic语义信息有关,另外SSD中也提到了一些对于提升mAP的原因,其中很大部分是因为图像增强部分,之前提到的random patch可以变相地理解为对图像进行"zoom in"或者"zoom out",也就是方法或者缩小,这样增强了网络监测大目标和小目标的能力(但监测小目标的能力还是稍微差一点)。
对于SSD的更多讨论,我这里也收集了一些其他优秀的文章,这里就不赘述了:
参考链接
https://arleyzhang.github.io/articles/786f1ca3/
https://www.cnblogs.com/sddai/p/10206929.html
撩我吧
- 如果你与我志同道合于此,老潘很愿意与你交流;
- 如果你喜欢老潘的内容,欢迎关注和支持。
- 如果你喜欢我的文章,希望点赞👍 收藏 📁 评论 💬 三连一下~
想知道老潘是如何学习踩坑的,想与我交流问题~请关注公众号「oldpan博客」。
老潘也会整理一些自己的私藏,希望能帮助到大家,点击神秘传送门获取。
Original: https://www.cnblogs.com/bigoldpan/p/14514633.html
Author: 老潘的博客
Title: SSD(Single Shot MultiBox Detector)笔记
相关阅读2
Title: 这5种工作,非常对口人工智能专业,这些技能太硬核了

人工智能听起来很神秘,很遥远,其实它早就应用到我们生活、工作的方方面面。比如手机里的智能语音助手,比如机器人客服,扫地机器人、还有快递机器人等等。
大家就担心机器人会取代人类,但Gartner的一份研究报告称,人工智能是一个新兴领域,将能够创造200多万个工作岗位。 人工智能是一个广泛的术语,包括一般的人工智能、机器学习、专家系统、数据挖掘等。当今世界,人工智能在各行各业都有很高的需求— 游戏、机器人、人脸识别软件、武器、语音识别、视觉识别、专家系统和搜索引擎等。
如果你想在AI领域谋求发展,那么你得先拥有人工智能领域需要的硬技能哦~

顶级人工智能技能
人工智能作为一种职业,需要掌握各种各样的技能并伴随大量培训。比如, 机器学习工程师拥有创建算法的技能,帮助进行机器分析和决策 (需要对不同的编程语言有深入的了解) 。值得注意的是,所有这些领域需要用到大量数学知识,如果你数学功底弱,学习起来可能会比较辛苦。而数学好的同学,则在AI领域如鱼得水。
以下列举一些必备的人工智能技能:
- 编程语言(Python, R, Java是最必要的)
- 线性代数和统计学
- 信号处理技术
- 神经网络架构

1. 机器学习工程师
作为人工智能领域最受欢迎的工作之一,机器学习工程师必须拥有强大的软件技能,能够应用预测模型,利用自然语言处理大量数据集。 此外,机器学习工程师还要了解软件开发方法、敏捷实践,以及从Eclipse和IntelliJ等ide,到持续部署管道的组件等现代软件开发工具的完整范围。
平均薪资:3.15万
任职要求:
- 拥有机器学习证书
- 计算机科学或数学硕士或博士学位
- 具有现代编程语言 (如Python、Java和Scala) 应用知识
- 具有很强的计算机编程技能、专业的数学技能、云应用和计算机语言知识

2. 机器人科学家
机器人可以使工作自动化,但它们需要程序员的幕后操作,确保机器人正常工作。机器人科学应用广泛,从太空探索到医疗保健,安全防护等太多科学领域。其主要功能是制造根据人类命令执行任务的机械设备或机器人。该职位所需的其他技能包括编写和操作计算机程序,与其他专家合作,以及开发技术雏形等。
平均薪资:2万元
任职要求:
- 相关的人工智能学习认证
- 机器人工程/机械工程/机电工程/电气工程学士学位
- 具有高等数学、物理科学、生命科学、计算机科学、计算机辅助设计和绘图(CADD)、物理、流体动力学和材料科学等专业知识背景人员

3. 数据科学家
数据科学家通过机器学习和预测分析来收集、分析和解释大量的数据,从而获得超越统计分析的见解。他们需要精通大数据平台和工具的使用,包括Hadoop、Pig、Hive、Spark和MapReduce。数据科学家还精通语言编程,包括结构化查询语言(SQL)、Python、Scala和Perl,以及统计计算语言。
平均薪资:3.1万
- 硕士或博士学位
- SAS和R, Python编码,Hadoop平台,使用云工具 (如Amazon的S3) 经验,以
- 理解非结构化数据的能力
- 非技术技能要求包括较强的沟通和分析能力、求知欲和商业敏感度

4. 研究科学家
研究科学家是人工智能多个学科的专家,包括机器学习、计算统计和应用数学。这些领域包括深度学习、图形模型、强化学习、计算机感知、自然语言处理和数据表示等。
平均薪资:2.4万
任职条件:
- 计算机科学或相关技术领域的硕士或博士学位
- 拥有并行计算、人工智能、机器学习、算法知识、分布式计算和基准测试等技能。
- 深入理解计算机架构
- 较强的口头和书面沟通技能

5. 商业智能开发人员
对商业智能开发人员的需求量很大。其主要工作是分析复杂的数据,并寻找当前的业务和市场趋势,从而提高组织的盈利能力和效率。他们不仅掌握很强的技术和分析能力,而且还具有良好的沟通和解决问题的能力。他们负责设计、建模、构建和维护复杂、广泛和高度可访问的基于云的数据平台数据。
平均薪资:2.7万
- 计算机科学、工程或相关领域学士学位
- 具有数据仓库设计、数据挖掘、BI技术、SQL查询、SQL Server Reporting Services (SSRS)和SQL Server集成服务(SSIS)知识和流行数据科学证书者优先
随着技术的不断创新,人工智能带来的就业机会越来越多。高德纳咨询公司的专家预测,"人工智能创造的就业机会将超过它消除的就业机会。" 但是想要在AI领域中就业,就需要掌握该领域必备的知识和技能。比如计算机科学学位或编程技能,拥有Python、Java、C/ c++等编程语言背景,并有人工智能、机器学习或自然语言处理经验,不是每一项技能都需要掌握,但需要精通2-3个技能,这样才能够在竞争中拿到高薪。
圣普伦数据人工智能系列课程(机器学习课程+、Keras和TensorFlow的深度学习),通过体系化、精心编排的课程(自然语言处理,语音识别,计算机视觉)帮助大家掌握掌握Deep Learning的概念和使用Keras和TensorFlow框架的模型,学会回归、分类和时间序列建模,该课程由圣普伦与普渡大学合作并与IBM共同开发,通过系统化学习,学员们将能够快速从AI人工智能新手成长为一名优秀的人工智能科学家。
如果你想在人工智能领域谋求一席之地,最好从今天开始行动。获得机器学习和人工智能等领域的证书是一个很好的开始,有了正确的教育,你才能拥有无限的机会。
Original: https://blog.csdn.net/simplilearnCN/article/details/123667987
Author: simplilearn圣普伦
Title: 这5种工作,非常对口人工智能专业,这些技能太硬核了
相关阅读3
Title: Ubuntu 20.04 安装 tensorflow-gpu
1. 安装Anaconda3
1.1 下载安装包
wget -P /tmp https://repo.anaconda.com/archive/Anaconda3-2020.02-Linux-x86_64.sh
1.2 安装
bash /tmp/Anaconda3-2020.02-Linux-x86_64.sh
1.3 激活 Anaconda
source ~/.bashrc
1.4 升级 Anaconda
conda update --all
1.5 Anaconda换源
清华源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/simpleitk
中科大源:
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/bioconda/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/menpo/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/pytorch/
2. 安装tensorflow
2.1 安装NVIDIA显卡驱动
lshw -c video
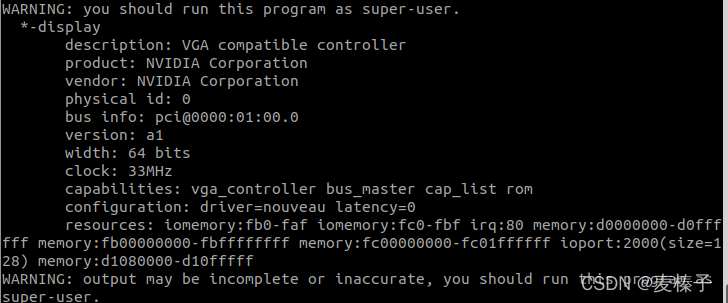
可以看到你的显卡信息,比如我的就是product: NVIDIA Corporation
环境搭建01——Ubuntu如何查看显卡信息及安装NVDIA显卡驱动_命名无能的博客-CSDN博客_ubuntu查看显卡驱动

ubuntu-drivers devices
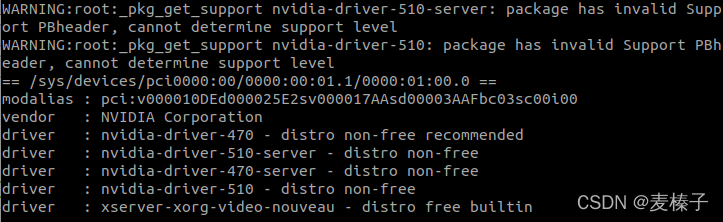
结果显示和搜索到的驱动版本一样,推荐也是510,那我们可以安心安装510.60.02版本。
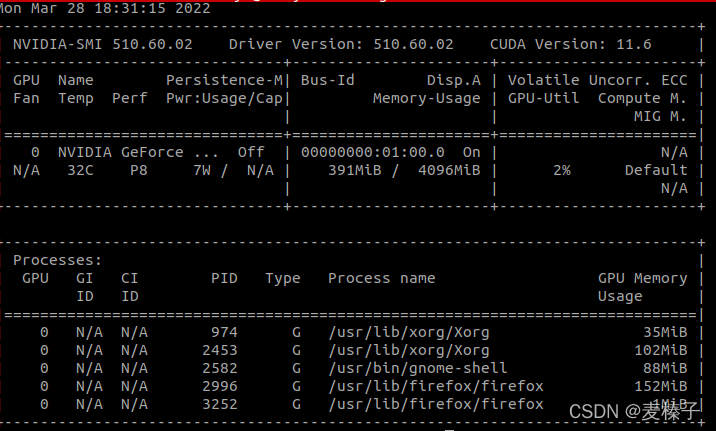
2.2 安装CUDA
CUDA Toolkit 11.2 Downloads | NVIDIA Developer
wget https://developer.download.nvidia.com/compute/cuda/11.2.0/local_installers/cuda_11.2.0_460.27.04_linux.run
sudo sh cuda_11.2.0_460.27.04_linux.run
按上图最下方两行代码安装。
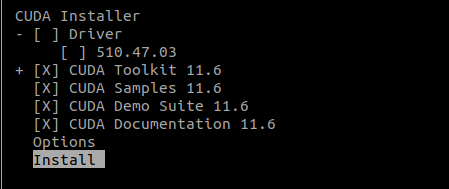
由于双系统win11装过CUDA了,所以取消勾选Driver,否则会报错
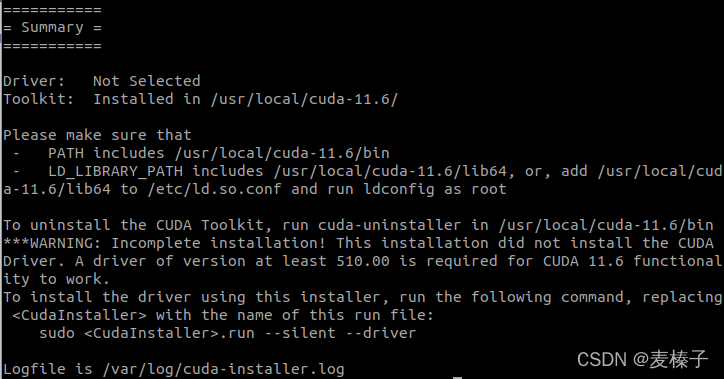
查看CUDA是否安装成功:

2.3 安装cuDNN
首先到官网下载cuDNN( NVIDIA cuDNN | NVIDIA Developer ),需要注册为开发者才能下载。
参考大佬的文章:
环境搭建02——Ubuntu安装cuda和cudnn_命名无能的博客-CSDN博客 成功解决--查看cudnn版本无反应的问题_石头儿啊的博客-CSDN博客_查看cudnn版本没反应
2.4 安装tensorflow
conda create -n tensorflow python=3.6
conda activate tensorflow
Win11 下通过Anaconda安装tensorflow_麦榛子的博客-CSDN博客
测试:
python
import tensorflow as tf
tf.compat.v1.disable_eager_execution() #保证sess.run()能够正常运行
hello = tf.constant('hello,tensorflow')
sess= tf.compat.v1.Session()#版本2.0的函数
print(sess.run(hello))
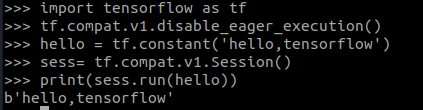
安装完毕!
PS:
打开VS code,点击右下角python切换虚拟环境,终端输入conda activate tensorflow.
Original: https://blog.csdn.net/weixin_44709392/article/details/123800999
Author: 麦榛子
Title: Ubuntu 20.04 安装 tensorflow-gpu