
目录
4 Python——uiautomator2库安装
1 蚂蚁森林简介
蚂蚁森林是一项旨在带动公众低碳减排的公益项目,每个人的低碳行为在蚂蚁森林里可计为"绿色能量"。"绿色能量"积累到一定程度,就可以用手机申请在生态亟需修复的地区种下 一棵真树 ,或者在生物多样性亟需保护的地区"认领"保护权益。
蚂蚁森林在各地的生态修复项目,是由蚂蚁集团向公益机构捐赠资金,由公益机构组织种植养护等具体工作,并由当地林业部门进行业务监管,所有项目都有对应的捐赠协议、验收报告。 [23]
2019年9月19日,中国"蚂蚁森林"项目获 联合国 " 地球卫士奖 "
据生态环境部2021年"全国低碳日"主场活动公布的数据:蚂蚁森林从2016年上线5年来,已累计带动超过6.13亿人参与低碳生活,产生"绿色能量"2000多万吨。
为了激励社会公众的低碳生活,5年来蚂蚁森林参与到全国11个省份的生态修复工作,累计种下3.26亿棵树,其中在甘肃、内蒙古均超过1亿棵。 同时,蚂蚁森林还在全国10个省份设立了18个公益保护地,守护野生动植物1500多种。通过在各地的生态环保项目,蚂蚁森林累计创造了种植、养护、巡护等238万人次的绿色就业机会,为当地群众带来劳动增收3.5亿元。
蚂蚁集团公开声明:每年投入蚂蚁森林数亿的费用属于纯公益捐赠。蚂蚁森林种下的树一经捐出,就属于国家、属于社会,未来如果这些树木产生碳汇,将全部用于公益。蚂蚁森林从未参与过碳交易。 如果蚂蚁森林里记录的个人碳减排量未来能交易,产生的所有收益将属于用户个人,不属于蚂蚁森林。
2 逝川长叹
在以前,容易忽略支护宝的我来说,很多能量被好友抢来,然后一直想找一个机会把失去的能量大范围的抢回来,苦于代码能力有限,一直没落实,最近很想弄,不在逝川长叹,也让别人羡慕我。
干货主要有:
① 200 多本 Python 电子书(和经典的书籍)应该有
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且可靠的练手项目及源码)
④ Python基础入门、爬虫、网络开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
Python学习交流Q群101677771
3 结果展示
过几分钟再偷,赚大了,哈哈哈!
4 Python——uiautomator2库安装
UiAutomator是Google提供的用来做安卓自动化测试的一个Java库,可以获取屏幕上任意一个APP的任意一个控件属性,并对其进行任意操作。Uiautomator2是在Uiautomator之上的python的接口封装,简单来说 Uiautomator2可以看到手机当前屏幕上有哪些控件,其坐标是啥,并且还可以模拟点击。
下面我们讲讲安装uiautomator2库的方法(我常用的)。
5 Python代码实现
Original: https://www.cnblogs.com/sn5200/p/15959129.html
Author: Python可乐的呀
Title: 利用Python抢回在蚂蚁森林把逝去的能量
相关阅读1
Title: 利用VAR模型科学管理仓位,提升策略效率

更多精彩内容, 欢迎关注公众号:数量技术宅,也可添加技术宅 个人微信号:sljsz01,与我交流。
期货行情瞬息万变,保证金体系决定了期货交易的杠杆属性。保证金放多了,资金利用率低,放少了,可能在大幅度的行情波动中造成强平的结果,甚至成为最终盈利和亏损的界限。所以,需要有一个衡量标准,为我们的仓位设置提供参考,VaR模型是科学管理仓位,提升策略效率的一个不错的选择。
VaR模型简述
在我们决定仓位的时候,我们其实需要考虑两个重要变量,一个是可能发生的亏损金额,另一个是发生亏损的可能性。用通俗的语言来打个比方,在99%置信区间下,Var值为2w,那么意味着每次交易亏掉2w权益的可能性是1%。具体公式:
VaR风险度 = 一定置信度下的VaR值/权益 * 100%
VaR模型的计算方法
VaR计算方法很多,比如历史模拟法、蒙特卡洛模拟法、核函数法、半参数法、参数法等。
本次我们使用参数法中的Delta-正太模型:
在服从正态分布的假设下,资产Var值为:
式中,$\bar\mu$是资产期望收益,$\bar\sigma$为标准差,$\delta_t$是要计算的时间长度,$Z {1-\alpha}$是从正太分布表中查到的对应于置信度水平$1-\alpha$的Z值,比如$\alpha = 0.01$的$Z{1-\alpha}=2.326$。
在期货市场中,只要我们把保证金控制在Var最大亏损百分比以上,我们就可以认为在这一置信水平下,可以极大程度防范风险。
通过Var模型评估风险
数据选择
选取近两年的期货所有品种的连续合约价格,置信度的选择,我们选取了99%和95%两个。
核心代码模块
if len(data[price].dropna()) != 0:
部分品种VAR结果可视化
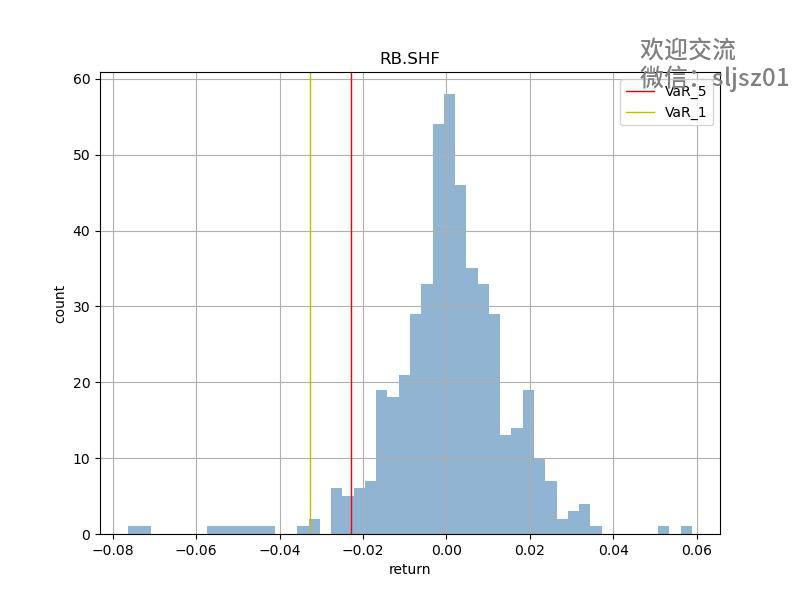
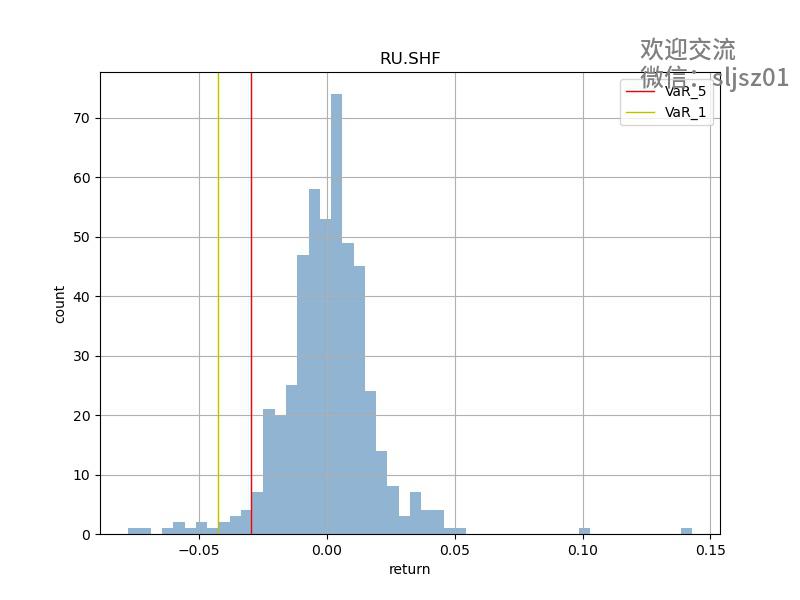
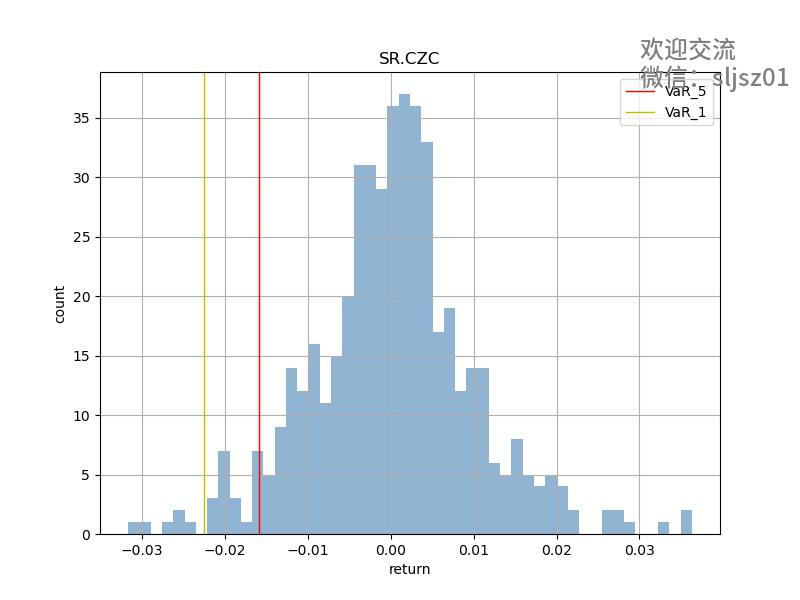
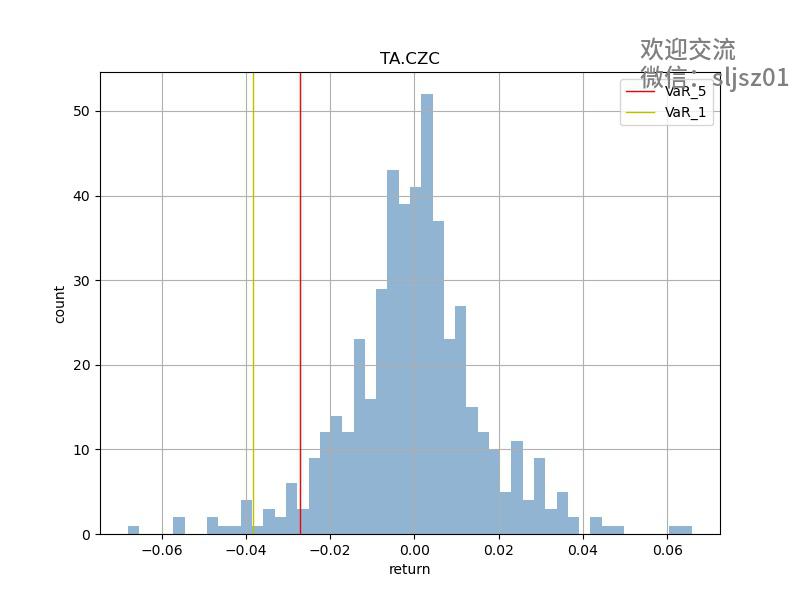
买入持有 + VAR
那么我们算出了var之后,仓位的变化是否能够改善投资组合的整体表现呢?
为了排除策略的影响,我们让所有品种都采用最简单的买入并持有策略,在这个策略下,使用所有品种平均持仓和根据var进行仓位微调之后,整个策略的表现是否会有影响。
由于我们使用了var1和var5,因此我们以var1的权重weight_var1,记为w1,同样还有w5,w0表示初始权重,所有仓位平均分配。
我们的目标是计算w0,w1,w5的夏普率的差别,看看通过权重的变化,夏普率是否有所改善。
核心代码模块:
for code in list['wind_code']: tmp最终我们计算得出:
均值标准差夏普率平均仓位0.00064372690041408 0.01082542031323569 0.08409533179205349 根据var1调仓0.00078209905493337 0.01147973020602057 0.09634852655560597 根据var5调仓0.00078063238309689 0.01148086624921166 0.09615832807729695
可以看到,从夏普率的角度,不论是根据var1调仓还是根据var5调仓,两者数值都有所提高,提高幅度在14.2%。可见,通过VAR模型进行仓位控制,可以在很大程度上,改善投资组合的表现。
VAR仓位管理在量化策略中的表现
我们已经验证了仓位在投资组合当中不可替代的作用,那么在实际的应用表现中,整体仓位比例的变化对于组合的收益率曲线有什么影响。我们以均线策略模型为例,抽取部分策略品种进行体现。从收益率数据的表现看,不管是组合中的品种表现,还是整个组合的表现,var调仓的效果都要比平均仓位的表现要好一些。
部分品种比较曲线,w1代表原始策略表现,w0代表经VAR调整仓位后策略表现:
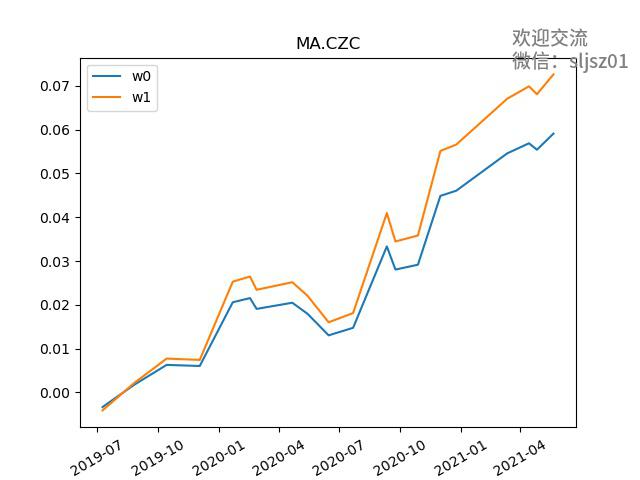
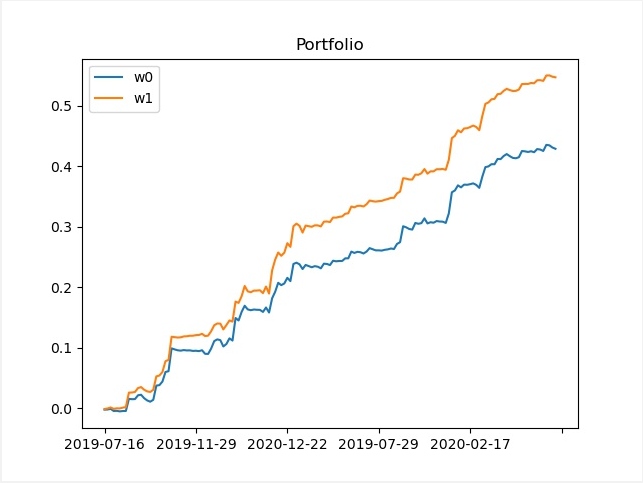
品种汇总曲线,同样的,w1代表原始策略表现,w0代表经VAR调整仓位后策略表现:
想要 获取本次分享的完整代码,或是任何 关于数据分析、量化投资的问题,欢迎添加技术宅微信:sljsz01,一起交流

往期干货分享推荐阅读
Omega System Trading and Development Club内部分享策略Easylanguage源码
【数量技术宅|量化投资策略系列分享】基于指数移动平均的股指期货交易策略
AMA指标原作者Perry Kaufman 100+套交易策略源码分享
【数量技术宅|金融数据系列分享】套利策略的价差序列计算,恐怕没有你想的那么简单
【数量技术宅|量化投资策略系列分享】成熟交易者期货持仓跟随策略
【数量技术宅|金融数据分析系列分享】为什么中证500(IC)是最适合长期做多的指数
商品现货数据不好拿?商品季节性难跟踪?一键解决没烦恼的Python爬虫分享
【数量技术宅|金融数据分析系列分享】如何正确抄底商品期货、大宗商品
【数量技术宅|量化投资策略系列分享】股指期货IF分钟波动率统计策略
【数量技术宅 | Python爬虫系列分享】实时监控股市重大公告的Python爬虫
Original: https://www.cnblogs.com/sljsz/p/15186922.html
Author: 数量技术宅
Title: 利用VAR模型科学管理仓位,提升策略效率
相关阅读2
Title: 【Python数据分析案例】python数据分析老番茄B站数据(pandas常用基础数据分析代码)
- 一、爬取老番茄B站数据
- 二、python数据分析
- 1、读取数据源
- 2、查看数据概况
- 3、查看异常值
- 4.1、查看最大值(max函数)
- 4.2、查看最小值(min函数)
- 5.1、查看TOP3的视频(nlargest函数)
- 5.2、查看倒数3的视频(nsmallest函数)
- 6、查看相关性
- 7.1、可视化分析-plot
- 7.2、可视化分析-pyecharts
- 三、同步讲解视频
一、爬取老番茄B站数据
前几天开发了一个python爬虫脚本,成功爬取了B站李子柒的视频数据,共142个视频,17个字段,含:
视频标题,视频地址,视频上传时间,视频时长,是否合作视频,视频分区,弹幕数,播放量,点赞数,投币量,收藏量,评论数,转发量,实时爬取时间
基于这个Python爬虫程序,我更换了up主的UID,把李子柒的uid换成了老番茄的uid,便成功爬取了老番茄的B站数据。共393个视频,17个字段,字段同上。
这里展示下爬取到的前20个视频数据:

基于爬取的老番茄B站数据,用python做了以下基础数据分析的开发。
二、python数据分析
1、读取数据源
import pandas as pd
df = pd.read_excel('B站视频数据_老番茄.xlsx', parse_dates=['视频上传时间', '实时爬取时间']) # 读取excel数据
2、查看数据概况
df.head(3) # 查看前三行数据
df.shape # 查看形状,几行几列
df.info() # 查看列信息
df.describe() # 数据分析
df['是否合作视频'].value_counts() # 统计:是否合作视频
df['视频分区'].value_counts() # 统计:视频分区
3、查看异常值
df2 = df[['视频标题', '视频地址', '弹幕数', '播放量',
'点赞数', '投币量', '收藏量', '评论数', '转发量', '视频上传时间']] # 去掉不关心的列
df2.loc[df.评论数 == 0] # 评论数是0的数据
df2.isnull().any() # 空值
df2.duplicated().any() # 重复值
4.1、查看最大值(max函数)
df2.loc[df.播放量 == df['播放量'].max()] # 播放量最高的视频
df2.loc[df.弹幕数 == df['弹幕数'].max()] # 弹幕数最高的视频
4.2、查看最小值(min函数)
df2.loc[df.投币量 == df['投币量'].min()] # 投币量最小的视频
df2.loc[df.收藏量 == df['收藏量'].min()] # 收藏量最小的视频
5.1、查看TOP3的视频(nlargest函数)
df2.nlargest(n=3, columns='播放量') # 播放量TOP3的视频
df2.nlargest(n=3, columns='投币量') # 投币量TOP3的视频
5.2、查看倒数3的视频(nsmallest函数)
df2.nsmallest(n=3, columns='评论数') # 评论数倒数3的视频
df2.nsmallest(n=3, columns='转发量') # 转发量倒数3的视频
6、查看相关性
# 查看spearman相关性(得出结论:收藏量&投币量,相关性最大,0.98)
df2.corr(method='spearman')

7.1、可视化分析-plot
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签 # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 可视化效果不好
df2.plot(x='视频上传时间', y=['弹幕数', '播放量', '点赞数', '投币量', '收藏量', '评论数', '转发量'])

7.2、可视化分析-pyecharts
from pyecharts.charts import Line # 折线图所导入的包
from pyecharts import options as opts # 全局设置所导入的包
time_list = df2['视频上传时间'].astype(str).values.tolist()
line = (
Line() # 实例化Line
# 加入X轴数据
.add_xaxis(time_list)
# 加入Y轴数据
.add_yaxis("弹幕数", df2['弹幕数'].values.tolist())
.add_yaxis("播放量", df2['播放量'].values.tolist())
.add_yaxis("点赞数", df2['点赞数'].values.tolist())
.add_yaxis("投币量", df2['投币量'].values.tolist())
.add_yaxis("收藏量", df2['收藏量'].values.tolist())
.add_yaxis("评论数", df2['评论数'].values.tolist())
.add_yaxis("转发量", df2['转发量'].values.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="老番茄B站数据分析"),
legend_opts=opts.LegendOpts(is_show=True),
)
# 全局设置项
)

至此,基础数据分析工作完成了。
三、同步讲解视频
逐行代码视频讲解:
https://www.zhihu.com/zvideo/1455460990275567616
by 马哥python说
Original: https://www.cnblogs.com/mashukui/p/16242980.html
Author: 马哥python说
Title: 【Python数据分析案例】python数据分析老番茄B站数据(pandas常用基础数据分析代码)
相关阅读3
Title: 如何在控制台实现一个数据管理系统(包括MYSQL数据库的增删改查)
为了方便的实现记录数据、修改数据没有精力去做一个完整的系统去管理数据。因此,在python的控制台直接实现一个简易的数据管理系统,包括数据的增删改查等等。只需要在控制台层面调用相应的功能调用查询、修改等功能,这里记录一下实现过程。


创建mysql数据表
使用比较熟悉的数据库客户端来进行操作,这里使用的是navicate客户端来创建好相应的数据表。
创建数据库并指定编码字符集。
CREATE DATABASE `data_boc` CHARACTER SET 'utf8mb4' COLLATE 'utf8mb4_general_ci';
创建数据记录表boc
CREATE TABLE `boc` (
`id_` bigint(255) NOT NULL COMMENT '数据记录编号,ID_作为主键',
`boc_address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`boc_code` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`boc_email` varchar(24) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`boc_name` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
PRIMARY KEY (`id_`) USING BTREE
)
增删改查
import pymysql as mysql # 导入mysql驱动器
from pprint import pprint # 导入美观的数据打印库
确定一下需要实现哪些功能,在控制台打印出功能列表,通过在控制台输入每个功能列表前面的标记来进入后台系统的使用。
def current_menu():
'''
功能目录列表展示
:return:
'''
pprint('---------------- 简易数据管理系统 ----------------')
pprint('系统功能实现:')
pprint('1- 查询数据列表')
pprint('2- 新增数据列表')
pprint('exit- 退出系统')
pprint('更多功能、暂未实现')
编写数据库连接的创建函数,在修改或查询数据时直接调用。
def cteate_connection():
'''
创建数据库连接
:return:
'''
connection = mysql.connect(host='127.0.0.1',
user='root',
password='root',
database='data_boc')
return connection
编写保存数据的函数用于数据列表新增功能实现。
def set_data():
'''
新增数据保存
:return:
'''
pprint('当前进入[2- 新增数据列表]')
id = input('输入数据编号')
id = int(id)
boc_address = str(input('输入详细地址'))
boc_code = str(input('输入具体编码'))
boc_email = str(input('输入正确邮箱'))
boc_name = str(input('输入数据名称'))
pprint('数据输入完成,开始保存...')
'''创建数据库接连'''
connection = cteate_connection()
cursor = connection.cursor()
insert_sql = "insert into boc(id_,boc_address,boc_code,boc_email,boc_name) values('%d','%s','%s',%s,%s)" % (
id, boc_address, boc_code, boc_email, boc_name)
try:
cursor.execute(insert_sql)
connection.commit()
except:
connection.rollback()
print("数据保存出现异常...")
connection.close()
pprint('数据保存完成...')
编写数据列表的查询功能函数。
def get_data():
pprint('当前进入[1- 查询数据列表]')
'''创建数据库连接'''
connection = cteate_connection()
cursor = connection.cursor()
select_sql = "select * from boc"
res_list = []
try:
cursor.execute(select_sql)
res = cursor.fetchall()
for row in res:
id = row[0]
boc_address = row[1]
boc_code = row[2]
boc_email = row[3]
boc_name = row[4]
res_list.append({'数据编号':id,'详细地址':boc_address,'具体编码':boc_code,'邮箱地址':boc_email,'名称':boc_name})
pprint('数据结果:{}'.format(res_list))
connection.commit()
except:
print("数据查询出现异常...")
connection.close()
pprint('数据查询完成...')
启动应用
if __name__ == '__main__':
while True:
current_menu()
chiose_code = input('输入菜单编号:')
if str(chiose_code) == '2':
set_data()
if str(chiose_code) == '1':
get_data()
if str(chiose_code) == 'exit':
break

【往期精选】
自制文档格式转换器,支持 .txt/.xlsx/.csv格式转换...
PyPDF2如何实现按照PDF页码提取后并另存为PDF格式文件?
PyQt5 GUI:百度图片下载器(文末附源码)
浪漫的turtle,送给程序员自己的圣诞树!
PyQt5 GUI && Requests Api 做一个天气查询系统(文末领取完整代码)!
Original: https://www.cnblogs.com/lwsbc/p/15729475.html
Author: Python集中营
Title: 如何在控制台实现一个数据管理系统(包括MYSQL数据库的增删改查)