
-------------------
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
def save_model_to_cv_dnn(netmodel, frozen_out_path, frozen_graph_filename):
full_model = tf.function(lambda x: netmodel(x)).get_concrete_function(tf.TensorSpec(netmodel.inputs[0].shape, netmodel.inputs[0].dtype))
# Get frozen ConcreteFunction
frozen_func = convert_variables_to_constants_v2(full_model)
frozen_func.graph.as_graph_def()
layers = [op.name for op in frozen_func.graph.get_operations()]
print("-" * 60)
print("Frozen model layers: ")
for layer in layers:
print(layer)
print("-" * 60)
print("Frozen model inputs: ")
print(frozen_func.inputs) # 模型输入
print("Frozen model outputs: ")
print(frozen_func.outputs) # 模型输出
# 存储PB模型
# Save frozen graph to disk
tf.io.write_graph(graph_or_graph_def=frozen_func.graph,
logdir=frozen_out_path,
name=f"{frozen_graph_filename}.pb",
as_text=False)
# Save its text representation
tf.io.write_graph(graph_or_graph_def=frozen_func.graph,
logdir=frozen_out_path,
name=f"{frozen_graph_filename}.pbtxt",
as_text=True)
path of the directory where you want to save your model
model.save('./data/tf_model_savedmodel', save_format="tf") print('export saved model.') model_loaded = tf.keras.models.load_model('./data/tf_model_savedmodel') yout = model_loaded.predict(x_test) ylab = yout[:, 0] > 0.5 print(ylab.shape) print(y_test.shape) model_loaded.evaluate(x = x_test,y = y_test)
frozen_out_path = './' # 存储模型的路径
name of the .pb file
frozen_graph_filename = "frozen_graph1" # 模型名称
save_model_to_cv_dnn(model,frozen_out_path,frozen_graph_filename)
Original: https://blog.csdn.net/u010795146/article/details/122561465
Author: 这个不开车的老司机
Title: tensorflow2.x保存pb模型,用于opencv3.4.16 dnn模块调用
相关阅读1
Title: TensorFlow模型保存pb或ckpt
Tensorflow的保存分为三种:1. checkpoint模式;2. pb模式;3. saved_model模式。
https://www.zhihu.com/collection/644504409
1 checkpoint模式
checkpoint模式将网络和变量数据分开保存:
|--checkpoint_dir
| |--checkpoint
| |--test-model-550.meta
| |--test-model-550.data-00000-of-00001
| |--test-model-550.index
checkpoint_dir就是保存时候指定的路径,路径下会生成4个文件。其中.meta文件(其实就是pb格式文件)用来保存模型结构,.data和.index文件用来保存模型中的各种变量,而checkpoint文件里面记录了最新的checkpoint文件以及其它checkpoint文件列表,在inference时可以通过修改这个文件,指定使用哪个model。
checkpoint_dir = "./model_ckpt/"
saver = tf.train.Saver(max_to_keep=1)
with tf.Session() as sess:
saver.save(sess, checkpoint_dir + "test-model",global_step=i, write_meta_graph=True)
执行之后就可以在checkpoint_dir下面看到前面提到的4个文件了。(这里的max_to_keep是指本次训练在checkpoint_dir这个路径下最多保存多少个模型文件,新模型会覆盖旧模型以节省空间)。
checkpoint_prefix = os.path.join("output/eval_result", "model")
if not os.path.exists(checkpoint_prefix):
os.makedirs(checkpoint_prefix)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=config.num_checkpoints)
sess.run(tf.global_variables_initializer())
saver.restore(sess, '../data/tv.pretrain.ckpt/pretrain_ckpt_841_765_8800/model-8800')
print('restore ckpt')
current_step = tf.train.global_step(sess, global_step)
if eval_accuracy > min_accuracy:
saver.save(sess, checkpoint_prefix, global_step=current_step)
print("Saved model on {}\n".format(current_step))
加载ckpt并转换成saved_model模式用于上线部署
(1)restore:恢复ckpt
sess_config = tf.ConfigProto()
sess_config.gpu_options.allow_growth = True
sess = tf.Session(config=sess_config)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=config.num_checkpoints)
sess.run(tf.global_variables_initializer())
print('ckpt_path:', ckpt_path)
saver.restore(sess, ckpt_path)
(2)写好feed_dict,然后sess.run
(3)builder.save(),重新保存为saved_model模式
if save_pb:
builder = tf.saved_model.builder.SavedModelBuilder(path+'/model' + str(current_step))
builder.add_meta_graph_and_variables(sess,[tf.saved_model.tag_constants.SERVING])
builder.save()
print("Saved model on {}\n".format(current_step))
2 pb模式:convert_variables_to_constants
https://www.jianshu.com/p/091415b114e2
https://www.tensorflow.org/api_docs/python/tf/compat/v1/graph_util/convert_variables_to_constants
pb模式保存的模型,只有在目标路径pb_dir = "./model_pb/"下孤孤单单的一个文件"test-model.pb",这也是它相比于其他几种方式的优势,简单明了。
pb_dir = "./model_pb/"
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
graph_def = tf.get_default_graph().as_graph_def()
var_list = ["input", "label", "beta", "bias", "output"]
constant_graph = tf.graph_util.convert_variables_to_constants(sess, graph_def, var_list)
with tf.gfile.FastGFile(pb_dir + "test-model.pb", mode='wb') as f:
f.write(constant_graph.SerializeToString())
其实pb模式本质上就是把变量先冻结成常数,然后保存到图结构中。这样就可以直接加载图结构和"参数"了。
if pb_mode:
pb_dir = './only_pb_1223/'
graph_def = tf.get_default_graph().as_graph_def()
var_list = ["audio_input_x", "query_input_x", ..., "output/probability", ...]
constant_graph = tf.graph_util.convert_variables_to_constants(sess, graph_def, var_list)
with tf.gfile.FastGFile(pb_dir + "test-model.pb", mode='wb') as f:
f.write(constant_graph.SerializeToString())
convert_variables_to_constants:把变量转换成常量
参数第一个是当前的session,第二个为graph,第三个是输出节点名(如我的输出层采用了name_scope,所以我们在probability之前需要加上output/)
pb模式的加载旧没那么复杂,因为他的网络结构和数据是存在一起的。
import numpy as np
import tensorflow as tf
pb_dir = "./model_pb/"
with tf.gfile.FastGFile(pb_dir + "test-model.pb", "rb") as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
X, pred = tf.import_graph_def(graph_def, return_elements=["input:0", "output:0"])
现在已经有了X和pred,下面来跑一个pred
feed_X = np.ones((8,size)).astype(np.float32)
feed_y = np.ones((8,1)).astype(np.float32)
with tf.Session() as sess:
print(sess.run(pred, feed_dict={X:feed_X}))
从pb中获取进来的"变量"就可以直接用。为什么我要给变量两个字打上引号呢?
- 因为在pb模型里保存的其实是常量了,取消注释sess.run(tf.global_variables_initializer())后,多次运行的结果还是一样的。此时的"beta:0"和"bias:0"已经不再是variable,而是constant。
- 这带来一个好处:读取模型中的tensor可以在Session外进行。相比之下checkpoint只能在Session内读取模型,对Fine-tune来说就比较麻烦。
with tf.gfile.FastGFile(saved_model_dir + "test-model-noCnnFeatureNoDropout.pb", "rb") as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
audio_input_x, query_input_x, probability
= tf.import_graph_def(graph_def, return_elements=["audio_input_x:0","query_input_x:0", "output/probability:0"])
打印维度
tensor_name_list = [tensor.name for tensor in tf.get_default_graph().as_graph_def().node]
for tensor_name in tensor_name_list:
print(tensor_name, '\n')
Original: https://blog.csdn.net/IOT_victor/article/details/122072516
Author: NLP_victor
Title: TensorFlow模型保存pb或ckpt
相关阅读2
Title: GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis
GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis
Abstract
虽然二维生成对抗网络能够实现高分辨率的图像合成,但它们在很大程度上缺乏对三维世界和图像形成过程的理解。因此,它们不能提供对相机视点或物体姿态的精确控制。为了解决这个问题,最近的几种方法利用基于 中间体素的表示与 可微 渲染相结合。然而,现有的方法要么产生较低的图像分辨率,要么在分离相机和场景属性方面出现不足,例如,物体的身份可能随视点而变化。在本文中,我们提出了一个辐射场的生成模型,该模型最近被证明是成功地用于单个场景的新视图合成。与 基于体素的表示相比,辐射场并不局限于三维空间的粗糙离散化,但允许解开摄像机和场景属性,同时在存在重建模糊性的情况下优雅地退化。通过引入一个 多尺度的基于补丁的鉴别器,我们演示了高分辨率图像的合成,同时仅从未曝光的二维图像训练我们的模型。我们系统地分析了我们的方法在几个具有挑战性的合成和真实世界的数据集。我们的实验表明,辐射场是生成图像合成的一个强大的表示,导致三维一致的模型渲染高保真。
3 Method
我们考虑了 三维感知图像合成的问题, 即 生成高保真图像的任务 ,同时提供 对相机旋转和平移的显式控制。我们主张用它的辐射场来表示一个场景,这样一个连续的表示尺度很好。图像分辨率和内存消耗,同时允许基于物理和无参数的投影映射。在下面,我们首先简要回顾了神经辐射场(NeRF)[36],它构成了所提出的生成辐射场(GRAF)模型的基础。
3.1 Neural Radiance Fields
3.2 Generative Radiance Fields
在这项工作中,我们感兴趣的是 辐射场作为 三维感知图像合成的 表示。与[36]相比,我们不假设单个场景有大量的摆姿势的图像。相反,我们的目标是学习一个 模型,通过对 未曝光图像的训练来合成新的场景。更具体地说,我们利用一个 对抗性框架来训练辐射场的生成模型(GRAF)。

图2显示了对我们的模型的概述。 生成器Gθ以 相机矩阵K、 相机姿态ξ、 二维采样模式ν和 形状/外观代码zs∈Rm/za∈Rn作为输入,并预测 图像补丁P '。 鉴别器Dφ将 合成的补丁P '与从 真实图像i中 提取的补丁P进行比较。在推断时,我们预测每个图像像素的一个颜色值。然而,在训练时,这是太贵了。因此,我们预测一个固定大小的K×K像素的补丁,它被随机缩放和旋转,以为整个辐射场提供梯度。
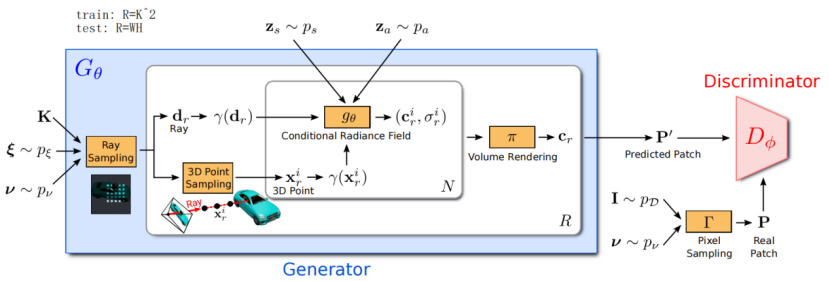
3.2.1 Generator
我们从 姿态分布pξ中采样 相机姿态ξ=[R|t]。在我们的实验中,我们使用在上半球均匀分布的相机位置,相机面向坐标系的原点。根据数据集的不同,我们也会均匀地改变相机到原点的距离。我们选择K,使主点在图像的中心。

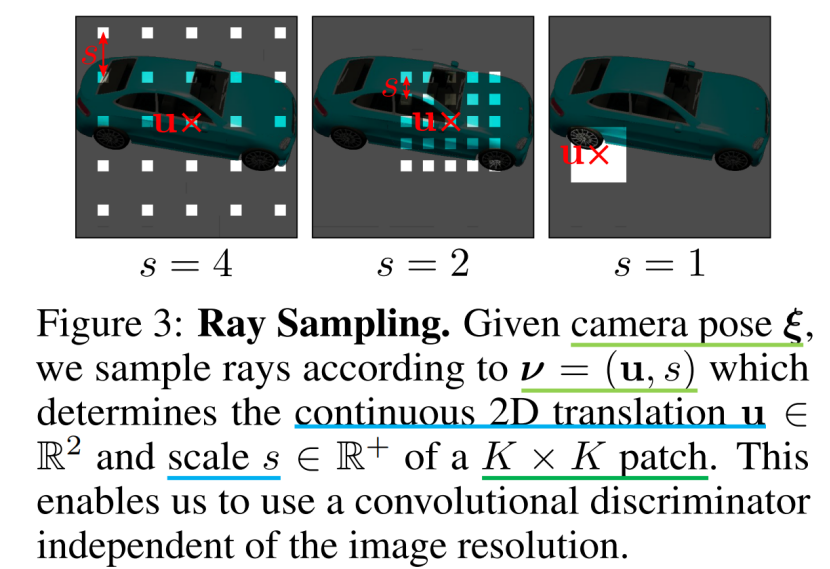
ν=(u,s)决定了我们要生成的虚拟K×K 补丁P(u,s)的 中心 u =(u,v)∈R2和 尺度 s∈R+。这使我们能够使用一个独立于图像分辨率的卷积鉴别器。我们从图像域Ω的均匀分布中随机抽取补丁中心u ∼U(Ω),从均匀分布的s ∼U ([1,S])中随机抽取补丁尺寸s ,其中S=min(W,H)/K,W和H表示目标图像的宽度和高度。此外,我们确保整个补丁都在图像域Ω内。形状和外观变量zs 和za 分别来自形状和外观分布zs ∼ps 和za ∼ps 绘制。在我们的实验中,我们对ps和pa都使用了一个标准的高斯分布。
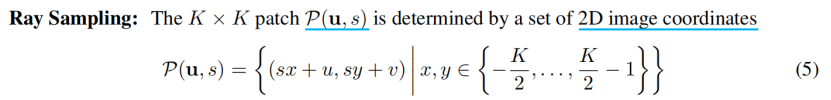
它描述了patch在图像域Ω中的每个像素的位置,如图3所示。请注意,这些坐标是实数,而不是离散的整数,这允许我们连续地计算辐射场。相应的 3D射线由P(u,s)、相机姿态ξ和内在K 唯一确定。我们用r 表示像素/射线索引,用d r 表示归一化的三维射线,射线数用R 表示,其中在训练中R=K2,在推理中R=WH。




条件辐射场gθ的网络结构如图4所示。我们首先从x的位置编码和形状编码zs中计算一个形状编码h。 密度头σθ将该编码转换为体积密度σ。为了预测3D位置x处的颜色c,我们将h与d的位置编码和外观代码za连接起来,并将得到的向量传递给一个 颜色头cθ。我们独立于视点d和外观代码za来计算σ,以鼓励多视图的一致性,同时分离形状和外观。这鼓励网络分别使用潜在代码zs和za来建模形状和外观,并允许在推理过程中分别操作它们。更正式地说,我们有:
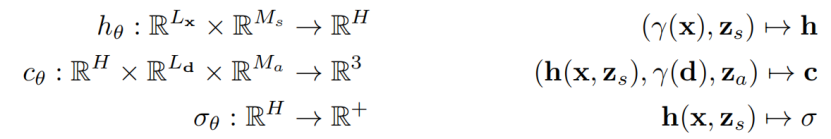
所有的映射(hθ、cθ和σθ)都是使用具有ReLU激活的 全连接网络来实现的。为了避免符号混乱,我们使用相同的符号θ来表示每个网络的参数。

给定沿射线r的所有点的颜色和体积密度{(cir,σir)},我们使用等式(3).中的体积渲染操作符得到射线r对应像素的颜色cr∈R3结合所有R射线的结果,我们将预测的斑片表示为p ',如图2所示。
3.2.2 Discriminator

鉴别器Dφ是实现为一个 卷积神经网络(见附件)将预测的 补丁P '与从数据分布pD中提取的真实图像I中提取的 补丁P进行比较。为了从真实图像I中提取一个K×K补丁,我们首先从我们在上面用于绘制生成器补丁的相同的分布pν中绘制ν=(u,s)。然后,我们通过使用双线性插值法在二维图像坐标P(u,s)处查询I,对真实的patch P进行采样。下面,我们使用Γ(I,ν)来表示这种双线性采样操作。请注意,我们的 鉴别器类似于PatchGAN[21],除了我们允许连续位移u和缩放s,而PatchGAN使用s=1。更重要的是,我们并不是基于s对真实图像I进行降采样,而是在稀疏位置查询I,以保留高频细节,见图3。
在实验中,我们发现一个 具有共享权重的鉴别器对所有的补丁都是足够的,即使这些补丁是在不同尺度的随机位置采样的。请注意,比例尺决定了补丁的接受域。为了便于训练,我们首先从更大的接受域开始,以捕捉全局环境。然后,我们逐步采样具有较小的接受域的补丁,以细化局部细节。
3.2.3 Training and Inference
我们在我们的鉴别器中使用光谱归一化[37]和实例归一化[65],并使用RMSprop[27]训练我们的方法,生成器和鉴别器的学习率分别为0.0005和0.0001。在推理时,我们随机抽取zs、za和ξ,并预测图像中所有像素的颜色值。关于网络架构的详细信息可以在附件中找到。
5 Conclusion
我们引入了生成辐射场(GRAF)用于高分辨率三维感知图像合成。我们证明,与基于体素的方法相比,我们的框架能够生成具有更好的多视图一致性的高分辨率图像。然而,我们的研究结果仅限于具有单个对象的简单场景。我们相信,结合归纳偏差,例如,深度图或对称性,将允许将我们的模型扩展到未来更具挑战性的现实世界场景。
Original: https://blog.csdn.net/qq_43620967/article/details/125577601
Author: ysh9888
Title: GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis
相关阅读3
Title: 微信公众平台开发(121) 微信二维码海报
关键字:微信公众平台 二维码 海报
作者:方倍工作室
原文: http://www.cnblogs.com/txw1958/p/weixin-poster.html
本文介绍微信公众平台下二维码海报的开发过程。
一、微信二维码海报介绍
微信二维码海报是指在海报中嵌入和微信用户关联的参数二维码的海报,用户分享推广之后,新用户可以被统计为被推广人员数,从而达到增加粉丝的传播效果。其使用场景如下:
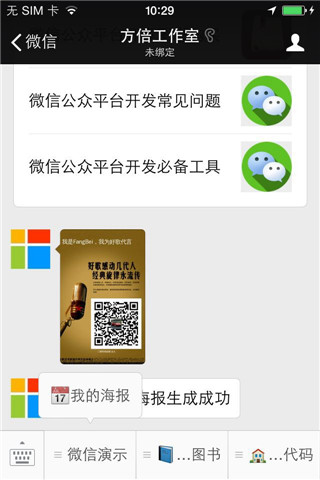

二、开发流程
在微信二维码海报生成中,需要用到以下信息
-
自定义菜单中设置一个菜单项,点击后返回二维码海报给用户
-
接口接收到菜单点击之后,获取用户的头像、ID(可以使用OpenID)
-
生成和用户关联的参数二维码,
-
将参数二维码进行缩放
-
将头像和参数二维码合并成新的参数二维码图片
-
将新参数二维码图片做为水印合成到背景海报中
-
将用户昵称,以及二维码时间戳(类型为临时二维码时)等文字合成到背景海报中
-
将海报上传成临时图片素材
-
将图片素材使用客服接口发送给用户。
三、微信素材准备
海报底图如下

3.1 生成自定义菜单
菜单的生成方法,请参考《微信公众平台开发(58)自定义菜单》以及方倍工作室的书籍《微信公众平台开发最佳实践(第2版)》
本项目中使用的菜单JSON为
3.2 获取用户基本信息
使用方倍工作室SDK获取用户基本信息的方法如下
//获取用户信息
$userinfo = $weixin->get_user_info($openid);
var_dump($userinfo);
//获取用户头像 64像素
$headimgurl = substr($userinfo['headimgurl'],0,strripos($userinfo['headimgurl'], "/"))."/64";
var_dump($headimgurl);
// $headimgurl = "http://wx.qlogo.cn/mmopen/R9V6295VOlibNsicszoREqUF2CiaY8hL5fFt0D8DykUCjJ8ia4rQicbYViax3A2V0am2oUEWvw5awGia0tmwQEbI0tAu4kkCL7Eiaeia7/64";
需要注意的是,用户默认头像是640像素的大图,将其切换成64位像素大小,以便放置在二维码中间。
同样的,用户基本信息的获取方法,请参考《微信公众平台开发(76) 获取用户基本信息 》以及方倍工作室的书籍《微信公众平台开发最佳实践(第2版)》
用户头像信息如下所示

3.3 生成参数二维码
使用方倍工作室SDK获取用户基本信息的方法如下
//创建永久二维码,参数为用户openid
$qrcodeinfo = $weixin->create_qrcode("QR_LIMIT_STR_SCENE", $openid);
var_dump($qrcodeinfo);
$qrcodeurl = "https://mp.weixin.qq.com/cgi-bin/showqrcode?ticket=".urlencode($qrcodeinfo["ticket"]);
var_dump($qrcodeurl);
// $qrcodeurl = "https://mp.weixin.qq.com/cgi-bin/showqrcode?ticket=gQHf7zoAAAAAAAAAASxodHRwOi8vd2VpeGluLnFxLmNvbS9xL05rUGlyTXJsd2hxN3BCUnFNbTlNAAIEu1X8VwMEAAAAAA%3D%3D";
参数二维码可以考虑使用永久字符串的,也可以考虑使用临时数字,临时数字优点没有上限限制,缺点是有有效期。永久的则相反。
同样的,参数二维码的获取方法,请参考《微信公众平台开发(83) 生成带参数二维码》以及方倍工作室的书籍《微信公众平台开发最佳实践(第2版)》
参数二维码如下所示

四、微信二维码海报生成
4.1 二维码缩放
微信二维码默认是430像素,将其缩放成300像素,核心代码如下
imagecopyresampled($qrcode_thumb, $qrcode_source, 0, 0, 0, 0, 300, 300, 430, 430);
4.2 头像合成到二维码图片上
核心代码如下
imagecopy($qrcode_thumb, $head_source, 118, 118, 0, 0, 64, 64);
合成后,效果如下

4.3 二维码合成到海报中
核心代码如下
//加水印
imagecopy($dst_qr, $qrcode_thumb, 212, 410, 0, 0, 300, 300); //水印位置
4.4 文字合成到海报中
核心代码如下
imagettftext($dst_qr, 30, 0, 40, 85, $textcolor, $font, $text);
合成后效果如下
五、素材上传与发送
5.1 上传临时图片素材
使用方倍工作室SDK上传图片素材的方法如下
//将图片上传临时图文素材
$material = $weixin->upload_temporary_material("image", $filename); //logo.jpg须放于类同目录,注意路径
var_dump($material);
$mediaid = $material["media_id"];
// array(3) { ["type"]=> string(5) "image" ["media_id"]=> string(64) "21Lz-eMFoSsA_R5gLOUJOqxbGw6YEEPRQq-UjHVbU6q64VyUBUqt7B8252ySPKdt" ["created_at"]=> int(1487213817) }
上传后,获得图片的media_id
5.2 使用客服接口发送图片
使用方倍工作室SDK发送图片的方法如下
//客服接口发送临时图片素材
$send_result = $weixin->send_custom_message($openid, "image", array('media_id'=>$mediaid));
var_dump($send_result);
六、演示
关注方倍工作室微信公众账号,点击菜单"我的海报"

六、源码
联系QQ 1354386063
Original: https://www.cnblogs.com/lanzhi/p/6467357.html
Author: 岚之山
Title: 微信公众平台开发(121) 微信二维码海报