
【注意】!!!!这个代码基于tf1,但是笔者装的tf2框架,实在改不动了,1.1和1.2还能勉强跑通,1.3怎么改都报错,所以1.3放的是原始tf1的代码
卷积神经网络: 应用
*
- 【注意】!!!!这个代码基于tf1,但是笔者装的tf2框架,实在改不动了,1.1和1.2还能勉强跑通,1.3怎么改都报错,所以1.3放的是原始tf1的代码
* 1.0 - TensorFlow模型
*
- 1.1 - 创建占位符
- 1.2 - 初始化参数
- 1.3 - 前向传播
- 1.4 - 计算成本
- 1.5 - 模型
欢迎来到课程4的第二份作业!在这此次作业里,你可以:
- 实现在实现TensorFlow模型时使用的帮助函数
- 使用TensorFlow实现一个功能完整的ConvNet
完成这个任务后,你将能够:
- 在TensorFlow中构建和训练一个卷积神经网络来解决一个分类问题
我们假设你已经熟悉TensorFlow。如果你还没有,请参考课程2第三周的TensorFlow教程(" 改进深度神经网络")。
1.0 - TensorFlow模型
在之前的作业中,您使用numpy构建了帮助函数,以理解卷积神经网络背后的机制。目前大多数实际的深度学习应用程序都是使用编程框架构建的,这些框架有许多可以简单调用的内置函数。
和往常一样,我们将从导入库开始。
import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
import scipy
from PIL import Image
from scipy import ndimage
"""
注意我用的是tf2,如果想禁掉tf2,只用tf1的功能就这么写
但是我这次写作业的时候,不知道为啥这样写,用jupyter禁不掉tf2,用pycharm可,麻了....
所以我后面的代码都会加tf.compat.v1,如果能禁成功,直接tf.就行
"""
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
from tensorflow.python.framework import ops
from cnn_utils import *
%matplotlib inline
np.random.seed(1)
【注意】:如果显示没有scipy,在anaconda prompt里面输入 conda install scipy即可,名字输错了找了半天错,麻了...
运行下一个单元格来加载将要使用的"SIGNS"数据集。
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
提醒一下,SIGNS数据集是6个符号的集合,表示从0到5的数字。

下一个单元格将向您展示数据集中带有标签的图像的示例。请随意更改下面index的值,并重新运行以查看不同的示例。
index = 6
plt.imshow(X_train_orig[index])
print ("y = " + str(np.squeeze(Y_train_orig[:, index])))
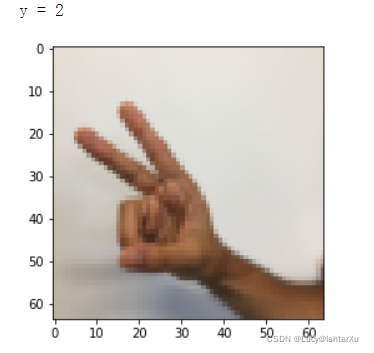
在课程2中,您已经为这个数据集构建了一个全连接网络。但由于这是一个图像数据集,因此更自然的做法是将ConvNet应用于它。
首先,让我们检查一下数据的形状。
X_train = X_train_orig/255.
X_test = X_test_orig/255.
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).T
print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
conv_layers = {}
输出结果为
number of training examples = 1080
number of test examples = 120
X_train shape: (1080, 64, 64, 3)
Y_train shape: (1080, 6)
X_test shape: (120, 64, 64, 3)
Y_test shape: (120, 6
1.1 - 创建占位符
TensorFlow要求您为将在运行会话时输入到模型中的输入数据创建占位符。
【 练习】:实现下面的函数,为输入图像X X X和输出图像Y Y Y创建占位符。目前不应该定义训练示例的数量。为此,您可以使用 “None”作为批处理大小,它将为您提供以后选择它的灵活性。因此X的维度应该是 [None, n_H0, n_W0, n_C0], Y的维度应该是 [None, n_y]。提示
def create_placeholders(n_H0, n_W0, n_C0, n_y):
"""
Creates the placeholders for the tensorflow session.
Arguments:
n_H0 -- scalar, height of an input image
n_W0 -- scalar, width of an input image
n_C0 -- scalar, number of channels of the input
n_y -- scalar, number of classes
Returns:
X -- placeholder for the data input, of shape [None, n_H0, n_W0, n_C0] and dtype "float"
Y -- placeholder for the input labels, of shape [None, n_y] and dtype "float"
"""
"""
如果这里是tf1的,直接写
X = tf.placeholder(shape=[None, n_H0, n_W0, n_C0], dtype = "float")
Y = tf.placeholder(shape=[None, n_y], dtype = "float")
"""
X = tf.compat.v1.placeholder(shape=[None, n_H0, n_W0, n_C0], dtype = "float")
Y = tf.compat.v1.placeholder(shape=[None, n_y], dtype = "float")
return X, Y
X, Y = create_placeholders(64, 64, 3, 6)
print ("X = " + str(X))
print ("Y = " + str(Y))
输出结果为
X = Tensor("Placeholder:0", shape=(?, 64, 64, 3), dtype=float32)
Y = Tensor("Placeholder_1:0", shape=(?, 6), dtype=float32)
1.2 - 初始化参数
你将使用 tf.contrib.layers.xavier_initializer(seed = 0)初始化weights/filter 𝑊 1 𝑊1 W 1和𝑊 2 𝑊2 W 2。你不需要担心偏差变量,因为你很快就会看到TensorFlow函数处理偏差。还请注意,您将只初始化 conv2d函数的权重/过滤器。TensorFlow自动初始化全连接部分的层。我们在以后的作业中会详细讨论。
【注意】:tf2把上面那个函数取消了,经测试, tf.initializers.GlorotUniform()和上面函数效果一致
练习:实现 initialize_parameters()。下面提供了每组过滤器的尺寸。提示:初始化Tensorflow中shape[1,2,3,4]的参数𝑊 𝑊W,使用:
W = tf.get_variable("W", [1,2,3,4], initializer = ...)
def initialize_parameters():
"""
Initializes weight parameters to build a neural network with tensorflow. The shapes are:
W1 : [4, 4, 3, 8]
W2 : [2, 2, 8, 16]
Returns:
parameters -- a dictionary of tensors containing W1, W2
如果可以把tf2禁了,不需要我这么麻烦
"""
tf.compat.v1.set_random_seed(1)
W1 = tf.compat.v1.get_variable("W1",[4, 4, 3, 8], initializer = tf.initializers.GlorotUniform())
W2 = tf.compat.v1.get_variable("W2",[2, 2, 8, 16], initializer =tf.initializers.GlorotUniform())
parameters = {"W1": W1,
"W2": W2}
return parameters
tf.compat.v1.reset_default_graph()
with tf.compat.v1.Session() as sess_test:
parameters = initialize_parameters()
init = tf.compat.v1.global_variables_initializer()
sess_test.run(init)
print("W1 = " + str(parameters["W1"].eval()[1,1,1]))
print("W2 = " + str(parameters["W2"].eval()[1,1,1]))
输出结果
和官方不一样...找到错误再说吧
W1 = [ 0.00131723 0.1417614 -0.04434952 0.09197326 0.14984085 -0.03514394
-0.06847463 0.05245192]
W2 = [ 0.19037306 0.05684656 0.1125446 -0.23109215 -0.22926426 0.04337913
-0.12032002 -0.01428771 0.04773349 0.1976018 0.0700236 0.24014717
-0.2141701 0.09505171 -0.19955802 0.19850826]
1.3 - 前向传播
在TensorFlow中,有一些内置函数可以帮你完成卷积的步骤。
tf.nn.conv2d(X,W1, strides = [1,s,s,1], padding = 'SAME'):给定一个输入𝑋 𝑋X和一组过滤器𝑊1,该函数对𝑊1的过滤器X X X进行卷积。第三个输入([1,f,f,1])表示输入(m, n_H_prev, n_W_prev, n_C_prev)的每个维度的strides。你可以在这里阅读完整的文档tf.nn.max_pool(A, ksize = [1,f,f,1], strides = [1,s,s,1], padding = 'SAME'):给定一个输入A,这个函数使用一个大小为(f, f)的窗口和大小为(s, s)的strides来对每个窗口执行max pooling。你可以在这里阅读完整的文档tf.nn.relu(Z1):计算Z1的elementwise ReLU(可以是任何形状)。你可以在这里阅读完整的文档。tf.contrib.layers.flatten(P):给定一个输入P,该函数将每个样本扁平化为一个1D向量,同时保持批处理大小。它返回一个扁平的张量,形状为[batch_size, k]。你可以在这里阅读完整的文档。tf.contrib.layers.fully_connected(F, num_outputs):
给定一个扁平的输入F,它返回使用全连接层计算得到的输出。你可以在这里阅读完整的文档。
在上面的最后一个函数 tf.contrib.layers.fully_connected(F, num_outputs):中,全连接层 自动初始化图中的权值,并在训练模型时继续训练它们。因此,在初始化参数时,不需要初始化这些权重。
练习:
实现下面的 forward_propagation函数,构建如下模型: CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> fullconnected。您应该使用上面的函数。
在细节中,我们将使用以下参数的所有步骤:
Conv2D:步长=1,填充"SAME"
ReLU - Max pool:使用一个8x8过滤器的大小和一个8×8步长,填充"SAME" Conv2D:步长=1,填充"SAME"
ReLU
Max pooling:使用一个4×4过滤器的大小和一个4×4步长,填充"SAME"
展平之前的输出
FC (full - connected)层:全连接层,无非线性激活功能。
不要在这里调用softmax。这将导致输出层中有6个神经元,然后这些神经元随后被传递到softmax。 在TensorFlow中,softmax和cost函数被合并到一个单独的函数中,当计算cost时,你会调用一个不同的函数。
def forward_propagation(X, parameters):
"""
Implements the forward propagation for the model:
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
Arguments:
X -- input dataset placeholder, of shape (input size, number of examples)
parameters -- python dictionary containing your parameters "W1", "W2"
the shapes are given in initialize_parameters
Returns:
Z3 -- the output of the last LINEAR unit
以下都是tf1的代码,不改了。。。我用tf2疯狂报错,改不动了- -
"""
W1 = parameters['W1']
W2 = parameters['W2']
Z1 = tf.nn.conv2d(X,W1, strides = [1,1,1,1], padding = 'SAME')
A1 = tf.nn.relu(Z1)
P1 = tf.nn.max_pool(A1, ksize = [1,8,8,1], strides = [1,8,8,1], padding = 'SAME')
Z2 = tf.nn.conv2d(P1,W2, strides = [1,1,1,1], padding = 'SAME')
A2 = tf.nn.relu(Z2)
P2 = tf.nn.max_pool(A2, ksize = [1,4,4,1], strides = [1,4,4,1], padding = 'SAME')
P2 = tf.contrib.layers.flatten(P2)
Z3 = tf.contrib.layers.fully_connected(P2, num_outputs = 6, activation_fn=None)
return Z3
tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
X, Y = create_placeholders(64, 64, 3, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
init = tf.global_variables_initializer()
sess.run(init)
a = sess.run(Z3, {X: np.random.randn(2,64,64,3), Y: np.random.randn(2,6)})
print("Z3 = " + str(a))
输出结果为
Z3 = [[-0.44670227 -1.57208765 -1.53049231 -2.31013036 -1.29104376 0.46852064]
[-0.17601591 -1.57972014 -1.4737016 -2.61672091 -1.00810647 0.5747785 ]]
1.4 - 计算成本
实现下面的计算成本函数。你可能会发现这两个函数很有用:
tf.nn.softmax_cross_entropy_with_logits(logits = Z3, labels =Y):计算softmax熵损失。这个函数既计算softmax激活函数,也计算由此产生的损失。你可以在这里查看完整的文档。tf.reduce_mean:计算张量各个维度元素的平均值。用这个公式把所有例子的损失加起来,得到总成本。你可以在这里查看完整的文档。
练习:使用上面的函数计算下面的成本。
def compute_cost(Z3, Y):
"""
Computes the cost
Arguments:
Z3 -- output of forward propagation (output of the last LINEAR unit), of shape (6, number of examples)
Y -- "true" labels vector placeholder, same shape as Z3
Returns:
cost - Tensor of the cost function
"""
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=Z3, labels=Y))
return cost
tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
X, Y = create_placeholders(64, 64, 3, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
init = tf.global_variables_initializer()
sess.run(init)
a = sess.run(cost, {X: np.random.randn(4,64,64,3), Y: np.random.randn(4,6)})
print("cost = " + str(a))
输出
cost = 2.91034
1.5 - 模型
最后,您将合并上面实现的helper函数来构建模型。您将在SIGNS数据集上训练它。
你已经在课程2实现了 random_mini_batches()。记住,这个函数返回一个小批量的列表。
练习:完成下列功能。
以下模型应该:
- 创建占位符
- 初始化参数
- 向前传播
- 计算出成本
- 创建一个优化器
最后,您将 创建一个会话并 为num_epochs运行一个for循环,获取小批量,然后为每个小批量优化函数。
def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.009,
num_epochs = 100, minibatch_size = 64, print_cost = True):
"""
Implements a three-layer ConvNet in Tensorflow:
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
Arguments:
X_train -- training set, of shape (None, 64, 64, 3)
Y_train -- test set, of shape (None, n_y = 6)
X_test -- training set, of shape (None, 64, 64, 3)
Y_test -- test set, of shape (None, n_y = 6)
learning_rate -- learning rate of the optimization
num_epochs -- number of epochs of the optimization loop
minibatch_size -- size of a minibatch
print_cost -- True to print the cost every 100 epochs
Returns:
train_accuracy -- real number, accuracy on the train set (X_train)
test_accuracy -- real number, testing accuracy on the test set (X_test)
parameters -- parameters learnt by the model. They can then be used to predict.
"""
ops.reset_default_graph()
tf.set_random_seed(1)
seed = 3
(m, n_H0, n_W0, n_C0) = X_train.shape
n_y = Y_train.shape[1]
costs = []
X, Y = create_placeholders(n_H0, n_W0, n_C0, n_y)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(num_epochs):
minibatch_cost = 0.
num_minibatches = int(m / minibatch_size)
seed = seed + 1
minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)
for minibatch in minibatches:
(minibatch_X, minibatch_Y) = minibatch
_ , temp_cost = sess.run([optimizer, cost], feed_dict={X:minibatch_X, Y:minibatch_Y})
minibatch_cost += temp_cost / num_minibatches
if print_cost == True and epoch % 5 == 0:
print ("Cost after epoch %i: %f" % (epoch, minibatch_cost))
if print_cost == True and epoch % 1 == 0:
costs.append(minibatch_cost)
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
predict_op = tf.argmax(Z3, 1)
correct_prediction = tf.equal(predict_op, tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print(accuracy)
train_accuracy = accuracy.eval({X: X_train, Y: Y_train})
test_accuracy = accuracy.eval({X: X_test, Y: Y_test})
print("Train Accuracy:", train_accuracy)
print("Test Accuracy:", test_accuracy)
return train_accuracy, test_accuracy, parameters
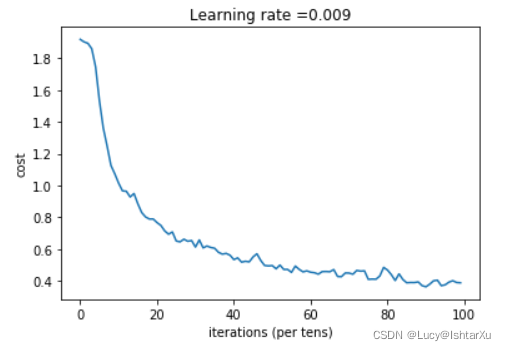
_, _, parameters = model(X_train, Y_train, X_test, Y_test)
输出结果为
Cost after epoch 0: 1.917920
Cost after epoch 5: 1.532475
Cost after epoch 10: 1.014804
Cost after epoch 15: 0.885137
Cost after epoch 20: 0.766963
Cost after epoch 25: 0.651208
Cost after epoch 30: 0.613356
Cost after epoch 35: 0.605931
Cost after epoch 40: 0.534713
Cost after epoch 45: 0.551402
Cost after epoch 50: 0.496976
Cost after epoch 55: 0.454438
Cost after epoch 60: 0.455496
Cost after epoch 65: 0.458359
Cost after epoch 70: 0.450040
Cost after epoch 75: 0.410687
Cost after epoch 80: 0.469005
Cost after epoch 85: 0.389253
Cost after epoch 90: 0.363808
Cost after epoch 95: 0.376132
Tensor("Mean_1:0", shape=(), dtype=float32)
恭喜你!您已经完成了作业,并建立了一个模型,识别手语的准确性接近80%的测试集。如果您愿意,可以自由地进一步使用这个数据集。实际上,您可以通过花更多的时间调整超参数或使用正则化(因为该模型显然具有很高的方差)来提高其准确性。
再一次,为你的工作竖起大拇指!
fname = "images/thumbs_up.jpg"
image = np.array(ndimage.imread(fname, flatten=False))
my_image = scipy.misc.imresize(image, size=(64,64))
plt.imshow(my_image)
Original: https://blog.csdn.net/FelicityXu/article/details/122549527
Author: Lucy@IshtarXu
Title: 吴恩达深度学习课程-Course 4 卷积神经网络 第一周 卷积神经网络编程作业(第二部分)
相关阅读1
Title: NLP学习概况
自然语言处理(NLP)是一门集合了语言学、数学、计算机科学交叉的学科.
目标在于:
1.更好的人机交互,辅助生活和工作.
2.进行非结构化数据的分析/挖掘:舆情分析、文本分类、知识抽取、智能问答和辅助决策
非结构化数据的特点:具有稀疏性和高维性,且文本中含有停用词、低频词和标点符号,这都使得词边界带有模糊性
常见的困难:
1.难以划分语义的边界——过几天天天天气不好
2.同义、同音字的区分(消歧问题)——朝阳机场的飞机迎着朝阳起飞
3.全局特征与局部特征的取舍问题——单身的原因有两个,一是谁都看不上,二是谁都看不上.
有人说过:"如果真的有不止一种理解文本的方式,那么所有解释就不可能是相同的.",所以NLP任务对人、对机器而言都是十分困难的.
主要任务:
1.序列标注任务
2.文本分类任务
3.文本匹配
4.关系抽取任务
5.文本增强任务
6.seq2seq任务
7.知识图谱构建
NLP常用工具
1.tensorflow:无需多说
2.pytorch:反正很强就对了
3.Sklearn:大量机器学习算法
4.Numpy:各种向量矩阵操作(文本向量化后主力工具)
Python数据处理常用库
1.Jieba:分词,词性标注
2.Pandas:数据处理,可以读取excel,csv格式的文件
3.Re:正则表达式
4.Json:读取json格式数据
5.Matplotlib:可视化工具
NLP推荐数据库(个人倾向)
1.MySQL
2.Neo4j
NLP常用步骤
1.数据获取
2.数据预处理
3.文本向量化
4.算法选择:常见(Transformer、LSTM、BERT、CNN、RNN、DNN、GNN等)
5.算法调优
6.模型评价(准确率、召回率、F1值)
内容会不断更新,如果哪里有错误也欢迎指出,共同交流进步!!!!!!!
Original: https://blog.csdn.net/WuGuo12138/article/details/123473779
Author: 理想程
Title: NLP学习概况
相关阅读2
Title: 你怎么记笔记?
B站、YouTube 等 UGC 网站有很多优质的 UP,比如半佛、老蒋、小 Lin。他们会基于自己的认知对某一个领域给出见解,如财经、 互联网等。
除了视频网站,最近老逛也注意到了一些声音内容的产品,比如小宇宙博客,你可以在这里收听到很多互联网领域内容创作者的修复。
老逛经常去这些地方去逛逛,有时候会得到很多不同的认知,于是想把这些优质的内容记录下来。
在最近一段时间的摸索,找到了一些开源项目,能大大提高自己学习和记笔记的效率,推荐给大家。
01
一键下载高质量视频
大多数视频网站没有提供下载的功能,如果你想下载 B站、优酷、YouTube、腾讯视频等网站上的优质视频,这个 GitHub 项目可完美解决下载问题,一行命令下载全网视频。
开源地址:https://github.com/soimort/you-get
支持的国内网站:
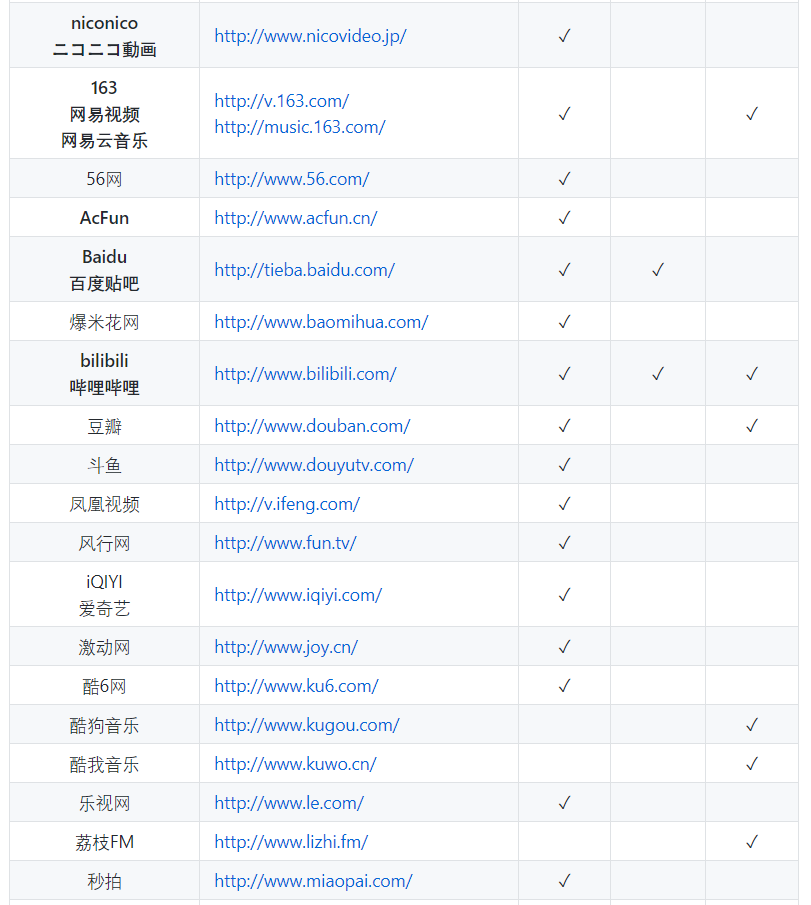
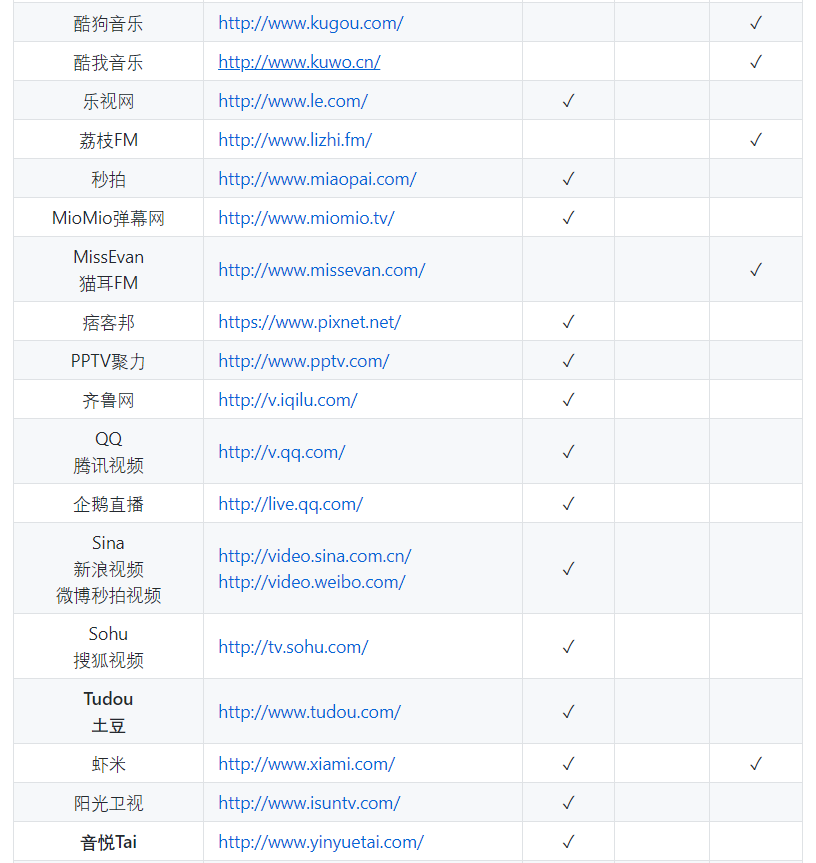
这个开源项目能帮你缓存一些高质量的视频,推荐这个项目的原因是:
-
高质量的内容值得保存,因为某些视频可能因为某些原因被下掉。
-
下载下来的视频可以一键提取字幕,这样就能做成笔记了。
02
提取视频中的字幕
这个开源项目是提取视频中字幕的开源项目,提取视频中的关键帧,检测视频帧中文本的所在位置,识别视频帧中文本的内容。
不知道大家有没有做笔记的习惯,这个开源项目就很方便的把你一个视频中的字幕提取出来,方便记录关键内容。
开源地址:https://github.com/YaoFANGUK/video-subtitle-extractor
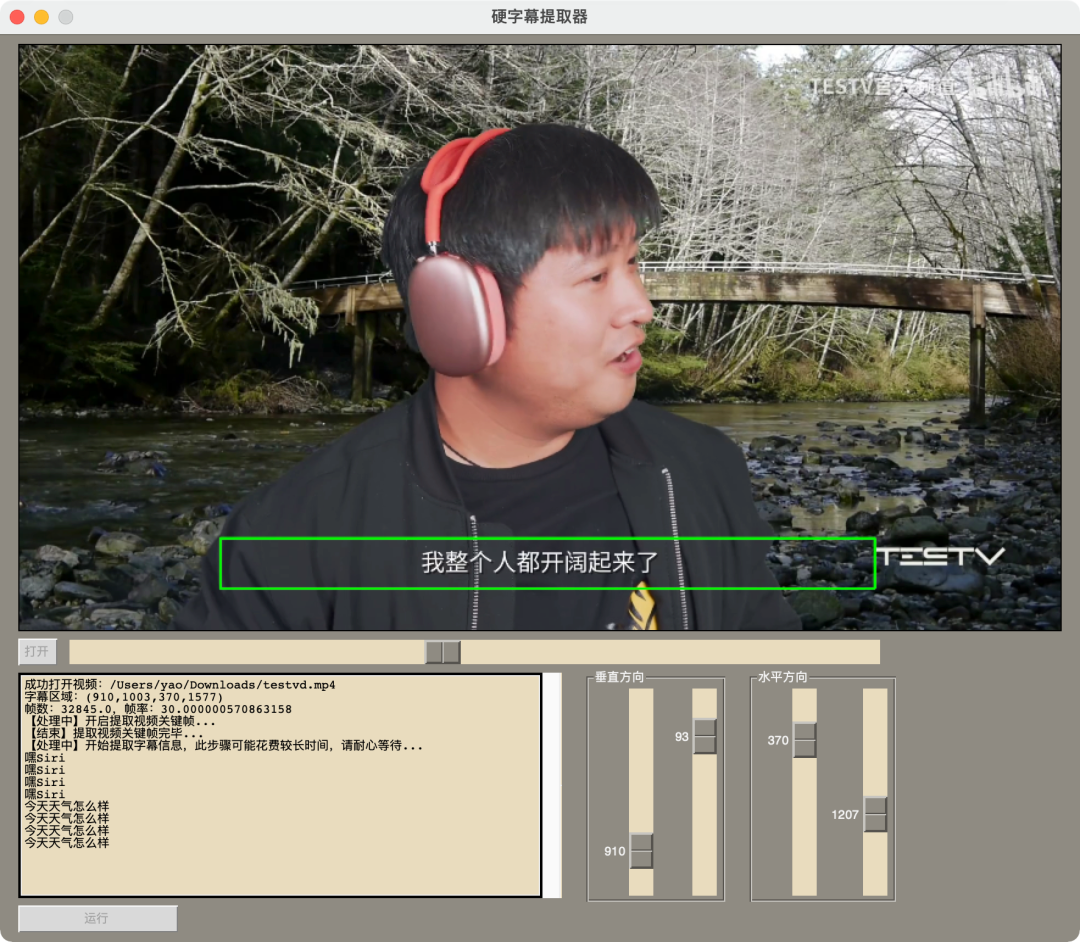
03
提取截屏中的文字
这个开源项目也是关于记录关键信息的场景,如果视频或者某个图片中有你感兴趣的关键信息,你又懒得打字记录下来,这个开源的截屏 OCR 可以帮助你。
只需要对视频中的 PPT 截屏,就能提取出 PPT 中的文字,方便记录下来。不要问为什么不直接保持图片,这个看个人习惯,我更喜欢可编辑的内容。
开源地址:https://github.com/amebalabs/TRex
开源地址:https://github.com/schappim/macOCR
04
语音转成文字
另外一个是语音转文字的仓库,里面包含了很多借助 Google API 进行语音转文字的示例。有时候,我懒得看视频,就一键把语音转成文字,保存下来慢慢看。
开源地址:https://github.com/opensourceteams/google-sdk-speech-to-text
开源地址:https://github.com/PaddlePaddle/PaddleSpeech

05
历史推荐
逛逛 GitHub 每天推荐一个好玩有趣的开源项目。历史推荐的开源项目已经收录到 GitHub 项目,欢迎 Star:
开源项目:https://github.com/Wechat-ggGitHub/Awesome-GitHub-Repo

推荐阅读
1.
2.
3.
4.

Original: https://blog.csdn.net/weixin_47080540/article/details/124464357
Author: 逛逛GitHub
Title: 你怎么记笔记?
相关阅读3
Title: 空间音频 2
13|如何利用HRTF实现听音辨位?
之前介绍了空间音频的基本概念,以及空间音频是如何采集和播放的。已经基本掌握了空间音频的基本原理。其实在游戏、社交、影视等场景中,空间音频被广泛地应用于构建虚拟的空间环境。
在空间音频的应用里最常见的一种就是"听音辨位"。比如在很多射击游戏中,能够通过耳机中目标的脚步、枪声等信息来判断目标的方向。如何利用 HRTF(Head Related Transfer Functions)头相关传递函数来实现"听音辨位"。
HRTF 简介
之前介绍的"双耳效应"实际上就是空间中音源的声波从不同的方向传播到左右耳的路径不同,所以音量、音色、延迟在左右耳会产生不同的变化。
其实这些声波变化的过程就是我们说的声波的空间传递函数,在介绍回声消除的时候就是通过计算回声的空间传递函数来做回声信号估计的。
那么如果预先把空间中不同位置声源的空间传递函数都测量并记录下来,然后利用这个空间传递函数,只需要有一个普通的单声道音频以及这个音源和听音者所在虚拟空间中的位置信息,就可以用预先采集好的空间传递函数来渲染出左右耳的声音,从而实现"听音辨位"的功能了。
而这个和我们头部形状等信息相关的空间传递函数,也就是我们说的 头部相关传递函数(HRTF)。
再想一下:音源的声波是如何传递到双耳的?一部分声音没有受到房间的墙壁、地板或者障碍物的干扰,而是直接通过空气传播到我们的双耳,把这些直接到达我们耳朵的声音叫做直达声。还有一些声波,经过空间障碍物或者界面的多次反射最后传播到你的耳朵里,从而形成了空间中的折射声或者说混响。很显然,直达声和混响相加就是听到的所有的声音了。
如果需要渲染一个真实的空间音频就需要渲染所有的直达声和混响。有没有发现什么问题?
直达声和虚拟环境是没有关系的,而混响则和听音者以及音源所处环境的空间布局有关。比如在一个小房间和荒野大漠中的混响显然是不同的,而且混响还会和音源、听音者以及环境的相对位置有关,比如在房间的墙角和在房间中央的混响信号,经过的路径显然是不同的。因此 直达声和混响通常需要分开来处理。
先来看看 HRTF 中和直达声渲染相关的 HRIR(Head Related Impulse Response),也就是头部相关冲击响应是如何做直达声渲染的。
HRIR 与直达声渲染
HRIR 其实就是预先采集的直达声到达双耳的空间传递函数。为了得到一个线性系统的传递函数,通常会用一个脉冲信号作为系统的输入,然后记录这个系统的输出信号。当做直达声渲染时,只需要将原始音频卷积对应方向位置的双耳冲击响应就可以得到一个直达声的空间立体声了。
那么如何采集 HRIR?
为了排除混响只录制 HRIR,需要在全消实验室录制 HRIR。图 1 就是一个在全消实验室录制 HRIR 的示意图。在图 1 中看到,全消实验室的墙壁上有很多吸音尖劈,这些材料可以有效地吸收声波,所以在全消实验室里墙壁是不会产生混响的。

图1 全消实验室真人录制HRIR
在采集 HRIR 时,真人采集就是让人带上入耳式麦克风,然后让扬声器(白色的一圈)在一个球面的不同位置播放脉冲信号。这样入耳式麦克风采集到的就是空间中各个角度的 HRIR 了。这里的扬声器是一个半弧形阵列,测完一个半弧形后可以改变俯仰角再测一组,直至把所有角度都测完。
当把所有方向的数据都采集完毕后,就可以得到一个球形的数据集。图 2 就是一个球形 HRIR 的坐标示意图。可以看到图 2 中央是人头所在的位置,周围的红点就是 HRIR 采集时音源的方位。
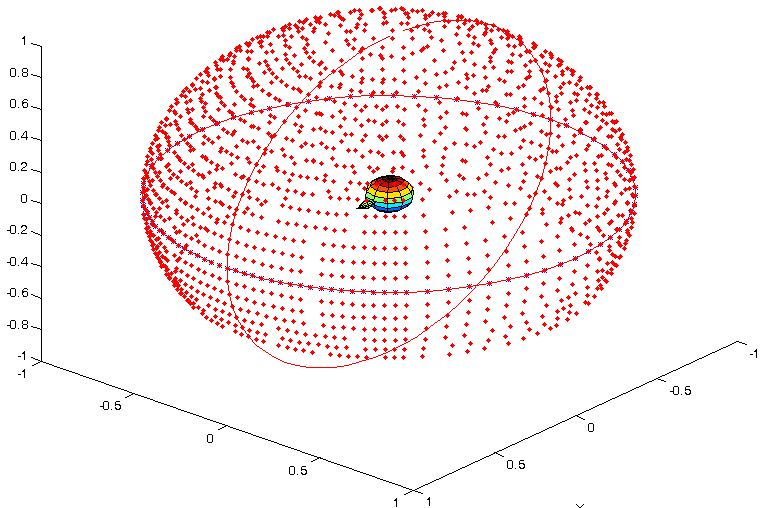
图2 HRIR的采集点的空间分布
当然让一个真人一动不动地测完全套可以得到比较准确的数据,但是这一整套流程下来时间还是很长的。所以为了方便采集,也可以采用同样的方法,使用人工头来采集 HRIR,比如图 3 就是一个利用人工头来采集 HRIR 的例子。人工头上的耳廓可以更换,这样就可以实现可定制耳廓的 HRIR 的采集。

图3 全消实验室人工头录制HRIR
通过采集到的 HRIR,就可以把单通道的音频分别和某个角度的双耳 HRIR 做卷积,从而渲染出特定方向的声音。可能会有疑问,人的耳朵外形轮廓有的不太一样,这会不会影响空间音频的效果呢?
确实每个人的头部形状可能不尽相同,如果用别人的 HRIR 来做空间音频的渲染可能没有你自己平时听得那么自然。从实际使用的结果上来看, 非定制化的 HRIR 渲染出的音频在角度的判断上差异不是很大,但是渲染后的音色可能会有一些细微的不同。但目前定制化的 HRIR 成本还是比较昂贵的,也许在未来人们都进入"元宇宙",这种定制化的增强听感的需求会催生出一些新的更便宜且准确的定制化方案。
现在知道 HRIR 是怎么采集的了,再分享几个开源的 HRIR 的数据集。一个是MIT 的人工头数据集,一个是CIPIC 的真人数据集。
知道了 HRIR 的采集和渲染方法之后,就可以对任意一个单声道的音频进行直达声方位的渲染了。那么剩下的混响要如何去渲染呢?
RIR 与反射声渲染
相较于直达声,反射声或者说混响和空间环境、音源位置、听音者位置都是绑定在一起的。所以如果采用和人工头相似的方法去采集房间冲击响应(RIR),那么理论上一个房间内音源位置和听音位置的组合可以说是无限多的。
并且就算可以用离散的方式采集一个房间内所有音源位置和听音位置的冲击响应,但是在虚拟环境里房间的形状、大小可以说是千变万化的,不可能每个都采用采样混响的方式来渲染。
在实际使用中,其实混响的作用不是提供准确的方位感而是提供空间大小,或者说听音者所处环境的感知。实际上根据镜像原理(如图 4 所示)一个真实声源的声波在经过界面反射后传到听音者的耳中可以等效成一个镜像声源的直达声。
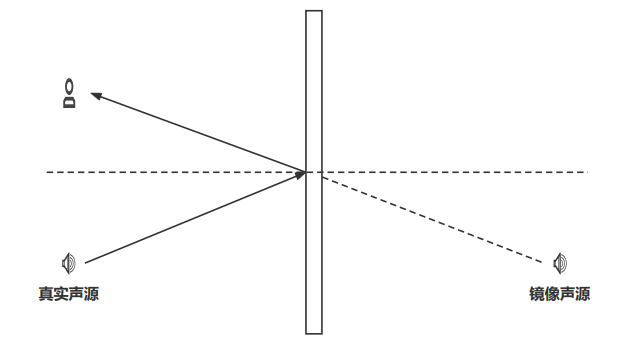
图4 折射声镜像原理
假设在一个长方体的房间里唱歌(如图 5 所示)。那么发出的声音经过 6 个界面的多次反射会形成多个镜像声源。所以其实混响会让对声源位置的判断变得更模糊,但是由于直达声一般来说会比经过反射的混响的音量大一些,所以在一般的房间内不至于让你的听音失去方向感。
这里值得注意的是,反射声大致可以分为前期反射和后期反射。一般把前 50ms 的反射叫做前期反射,超过 50ms 的叫做后期反射。一般来说前期反射对我们语音的可懂度是有提升效果的,而后期反射太多则会让声音变浑浊,从而降低语音的可懂度。
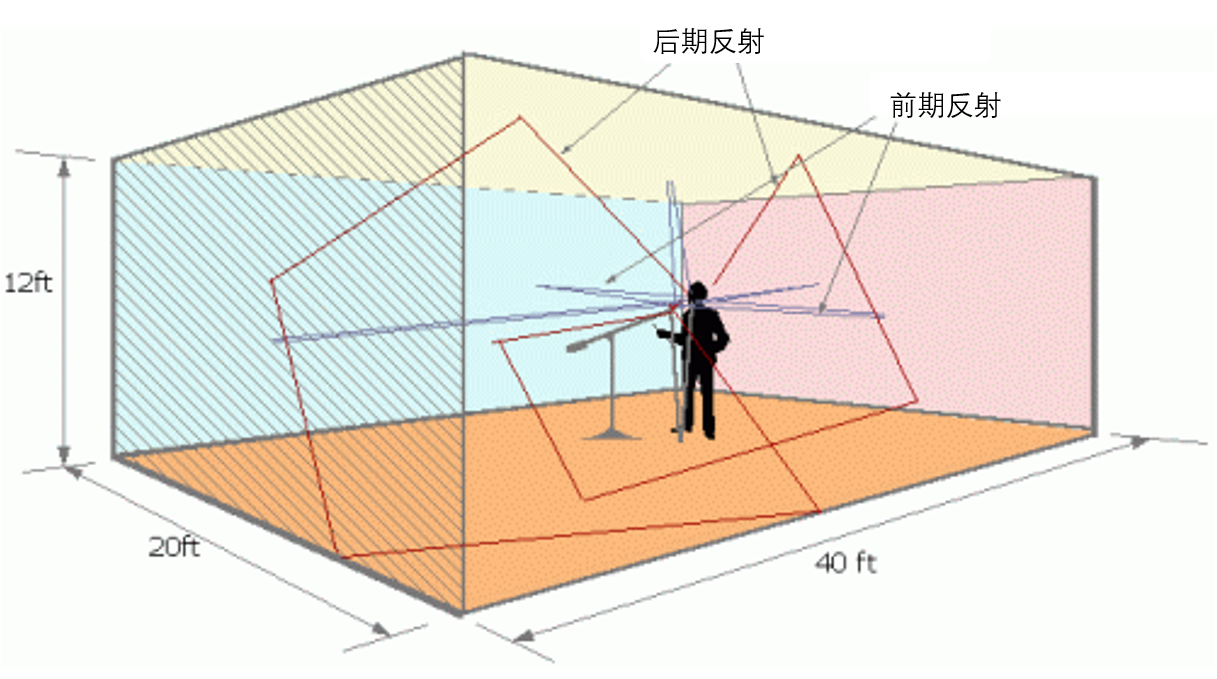
图5 长方体房间内的反射波示意图
这里讲的镜像原理其实也就是生成 RIR 的一种方法。这里分享一个基于镜像法的房间冲击响应的生成器。
其实镜像法的原理就是给定房间界面的大小、界面的反射吸音系数、空气衰减系数,再通过镜像法建模得到房间中任意位置音源和听音者位置组合的房间冲击响应。 用得到的冲击响应和原始音频做卷积就可以做混响的渲染了。
在实际使用空间音频的时候,尤其是实时空间音频的渲染时,还有很多需要注意的地方,这里罗列了几个常见的问题:
-
如果想要用 RIR 给声音增加混响,那么原始的声音得是"干声",也就是原始音频不能有混响。这一点是比较苛刻的。如果是在普通的房间录制的声音,比如客厅或者卧室,其实都已经有 200ms 到 1s 左右的混响了,再卷积一个 RIR 那么得到的混响可能比预期的更为浑浊,混响时间也更长一些。
-
如果音源位置或者听音者位置是移动的,也就是说需要实时生成 RIR 来对混响进行建模,但镜像法生成混响,尤其在混响时间比较长的时候算力是比较大的。有的时候得做出取舍,比如一个房间就使用一个固定的预设 RIR 来避免算力无法实时计算。这也是很多游戏体验中混响在一个房间内都是一样的原因。
-
真实的不一定是好听的,在歌曲制作时经常会使用一些人工混响效果器来代替真实混响,或者采集一些比较好的固定混响的样本,比如用"维也纳金色大厅"的混响 RIR 来进行混响的渲染。
小结
为了实现听音辨位,可以使用 HRTF 对空间音频进行渲染。
直达声可以采用预先采集的 HRIR 和原始音频通过卷积的方式来实现。基本上需要哪个方向的声音就去卷积哪个方向的 HRIR。HRIR 一般需要全消声实验室进行采集,可以使用一些开源库中的 HRIR 来实现。
反射声或者说混响的渲染则是采用卷积房间冲击响应 RIR 的形式来实现。由于 RIR 和房间的大小、材料、听音者和音源的位置都有关系,所以一般采用镜像法模拟的形式来实现。
在实时交互的场景里,空间音频渲染时计算的实时性是很重要的。这里说的卷积和前面回声消除里讲的自适应滤波器一样,都是可以用频域卷积来加速的,比如采样率是 48kHz 的音频。如果需要和超过 64 点以上的卷积核做卷积,那么用频域卷积会快于时域卷积。
Original: https://blog.csdn.net/qq_37756660/article/details/123476510
Author: Rye
Title: 空间音频 2