
Original: https://www.cnblogs.com/pythonQqun200160592/p/15528441.html
Author: python可乐编程
Title: Python爬虫全网搜索并下载音乐
相关阅读1
Title: Django cors跨域问题
Django cors跨域问题
前后端分离项目中的跨域问题 即同源策略
同源策略:同源策略/SOP(Same origin policy)是一种约定,由 Netscape 公司 1995 年引入浏览器,它是浏览器最核心也最基本的安全功能,现在所有支持 JavaScript 的浏览器都会使用这个策略。如果缺少了同源策略,浏览器很容易受到 XSS、 CSFR 等攻击。
同源是指"协议+域名+端口"三者相同,即便两个不同的域名指向同一个 ip 地址,也非同源。
源就是协议、域名和端口号。
协议:http,https
跨域:前端请求URL的协议、域名、端口与前端页面URL不同就是跨域
在Django中解决跨域问题
一、
# 1、安装第三方库 django-cors-headers
# 2、在settings.py中添加'corsheaders.middleware.CorsMiddleware',在SessionMiddleware和CommonMiddleware的中间
# 3、在INSTALLED_APPS里添加"corsheaders"
INSTALLED_APPS = [
'search.apps.SearchConfig',
'record_data.apps.RecordDataConfig',
'deleted_data.apps.DeletedDataConfig',
'rest_framework',
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'corsheaders', # 新增
]
# 4、在中间件中添加corsheaders.middleware.CorsMiddleware,django.middleware.common.CommonMiddleware
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'corsheaders.middleware.CorsMiddleware', # 新增/必须在common中间件上面
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'utils.middleware.ExceptionMiddleware',
]
# 5、在项目配置文件底部增加
CORS_ALLOW_CREDENTIALS = True # 允许携带cookie
CORS_ORIGIN_ALLOW_ALL = True # 放行所有
CORS_ORIGIN_WHITELIST = ('*') # 白名单
# CORS_ALLOW_METHODS:字符串列表,允许用哪些HTTP请求方法。
CORS_ALLOW_METHODS = (
'DELETE',
'GET',
'OPTIONS',
'PATCH',
'POST',
'PUT',
'VIEW',
)
# CORS_ALLOW_HEADERS:字符串列表,允许使用哪些非标准HTTP请求头。
CORS_ALLOW_HEADERS = (
'accept',
'accept-encoding',
'authorization',
'content-type',
'dnt',
'origin',
'user-agent',
'x-csrftoken',
'x-requested-with',
)
二、
# 可以自己注册一个中间件,在中间件process_response方法中对response进行封装
def process_response(self, request, response):
response["Content-Type"] = "application/json" # 响应信息的内容格式
response["Access-Control-Allow-Origin"] = "*" # 允许跨域请求的源地址, * 表示:允许所有地址
response["Access-Control-Allow-Methods"] = "POST, GET, OPTIONS" # 允许跨域请求的具体方法
response["Access-Control-Max-Age"] = "1000" # 用来指定本次预检请求的有效期,单位为秒,,在此期间不用发出另一条预检请求。
response["Access-Control-Allow-Headers"] = "*"
return response
- 跨域实现流程为 1、浏览器会第一次先发送options请求询问后端是否允许跨域,后端查询白名单中是否有这两个域名 2、如过域名在白名单中则在响应结果中告知浏览器允许跨域 3、浏览器第二次发送post请求,携带用户登录数据到后端,完成登录验证操作
Original: https://www.cnblogs.com/Free-A/p/16404805.html
Author: Free_A
Title: Django cors跨域问题
相关阅读2
Title: python 爬虫 中的正则表达式
正则表达式虽然不是python语言,但在python爬虫中却有着普遍的应用,可以说没有正则表达式的爬虫是一个没有灵魂的爬虫,话不多说,直接上干货!
首先介绍一个验证正则表达式的在线平台:https://regex101.com/

高亮部分即为提取到的内容。
- 元字符
- \d 匹配所有数字
- \w 匹配所有数字、字母、下划线
- \D 除了数字以外的内容
- \W 除了数字、字母、下划线以外的内容
- \S 匹配所有非空白
- [a,b,c] 匹配a,b,c的内容
- [^a,b,c] 匹配除了a,b,c的内容
- \s 匹配空白
- \b 匹配单个单词边界
- 量词
- 元字符+ 元字符出现1次或多次(等同于{1, })
- 元字符* 前面的元字符出现0次或多次,尽可能多的拿到数据(等同于{0, })
- 元字符? 前面的元字符出现0次或一次
- 匹配字符
- 数字 [0-9]
- 小写字母 [a-z]
- 大写字母 [A-Z]
- 特殊字符 [\特殊字符]
- ^
- 放在区间里表示取反
- [^0-9] 表示匹配非数字
- [^a-z] 表示匹配非小写字母
-
放在区间外面表示匹配字符串开头(^python 表示以python开头的内容)
-
$ 匹配字符串结尾(python$ 表示以python结尾的单词)
- ?
- 可以出现也可以不出现(colou?r 可以同时匹配color、colour)
- 转换为非贪婪模式(\d{8,9}? 默认会匹配8和9位的数字,加上?后,只匹配8位的数字)
- . 除了换行符以外的任意内容
- {数字} 指定匹配次数(\d{9}指匹配9位数的数字)
-
{数字,数字} 指定匹配区间(\d{4, }指匹配4位以上的数字)
-
惰性匹配
- .* 匹配最远的字符
- .*? 匹配最近的字符(惰性匹配)
- 字符串:今天晚上一起吃鸡呀(匹配:晚上.*?吃鸡) 结果:晚上一起吃鸡
-
*分组
-
加括号就可分组(提取号码:0731-8283333的区号和正真的电话号码 结果:\d{4}-\d{7})
- eg:holle (.*?) 不加括号是提取不出来的
- | 或则条件 (.jpg|.gif|.jpeg|.png)表示匹配这几种后缀的图片格式
-
非捕获分组 (?:表达式)
-
*分组的回溯引用
-
提取标签中的文字ge1:破坏标签,将改为
结果: - eg2:编写代码匹配符合ab ba 结果:(\w)(\w)\2\1
- 环视/欲搜索
eg:在 我喜欢你 我喜欢 我喜欢我 喜欢 喜欢你
正向先行断言(?=表达式) 取出喜欢,喜欢的后面必须有"你"

反向先行断言 喜欢(?!你) 即喜欢后面没有"你"
正向后行断言(?

反向后行断言(?

本文均自己整理,时间也比较赶,可能有的地方会存在问题,可以评论留言,看到了就会改。
Original: https://www.cnblogs.com/xiaozebuxiao/p/15863331.html
Author: 小泽不小
Title: python 爬虫 中的正则表达式
相关阅读3
Title: XPath语法和lxml模块
XPath语法和lxml模块
什么是XPath?
xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历。
XPath开发工具
Chrome插件XPath Helper。
安装方法:
- 打开插件伴侣,选择插件
- 选择提取插件内容到桌面,桌面上会多一个文件夹
- 把文件夹放入想要放的路径下
- 打开谷歌浏览器,选择扩展程序,开发者模式打开,选择加载已解压的扩展程序,选择路径打开即可
Firefox插件Try XPath。
XPath节点
在 XPath 中,有七种类型的节点: 元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
XPath语法

使用方式:
使用//获取整个页面当中的元素,然后写标签名,然后在写谓语进行提取,比如:
//title[@lang='en']
//标签[@属性名='属性值']
# 如果想获取html标签下的body标签
html/body
谓语:谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。在下面的表格中,列出了带有谓语的一些路径表达式
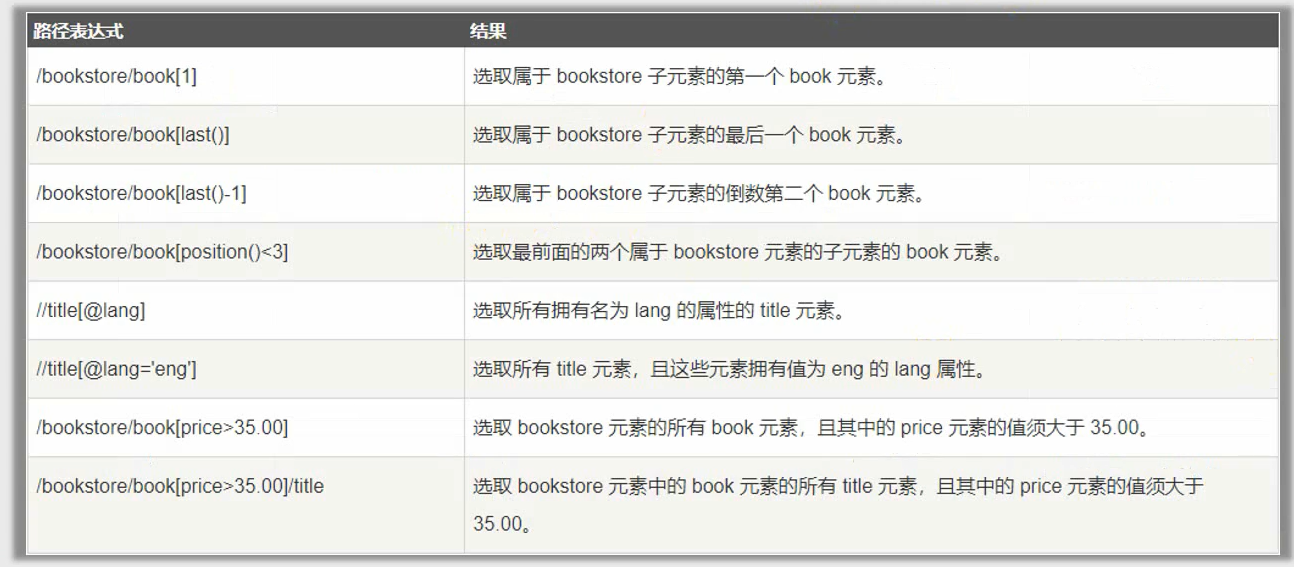
通配符
只要book标签带有属性都可以通过 //book[@*] 匹配到
选取多个路径
通过在路径表达式中使用 | 运算符,可以选取若干个路径
# 选取所有book元素以及book元素下所有的title元素
//bookstore/book|//book/title
运算符
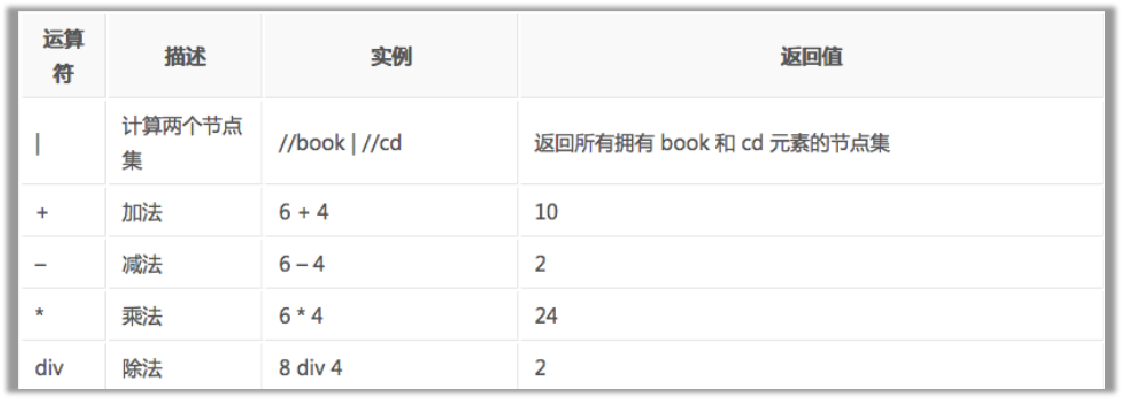
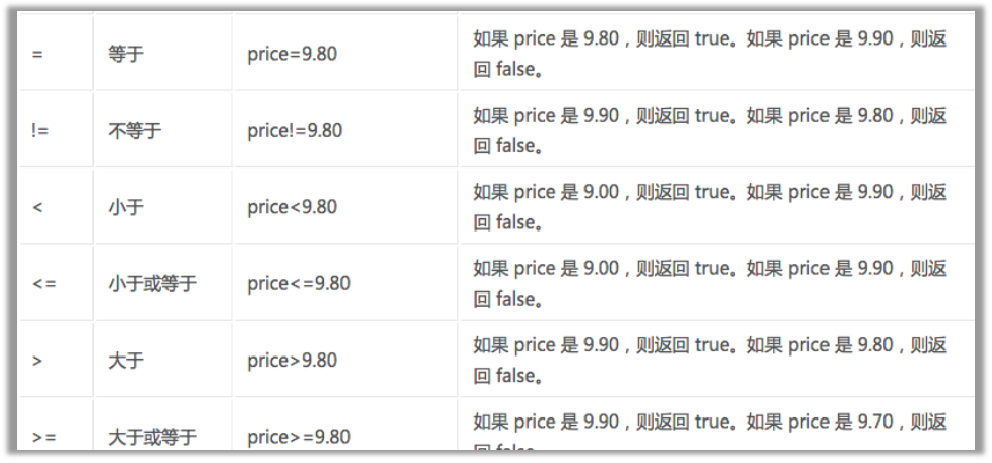

需要注意的知识点:
- /和//的区别:/代表只获取子节点,//获取子孙节点,一般//用的比较多,当然也要视情况而定
- contains:有时候某个属性中包含了多个值,那么可以使用contains函数,示例如下:
//title[contains(@lang,'en')]
- 谓词中下标是从1开始的,不是从0开始的
lxml库
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
👉lxml python 官方文档:http://lxml.de/index.html
👉需要安装C语言库,可使用 pip 安装: pip install lxml
基本使用:
我们可以利用他来解析HTML代码,并且在解析HTML代码的时候,如果HTML代码不规范,他会自动的进行补全
from lxml import etree
text = '''
first item
second item
third item
fourth item
fifth item
'''
# 将字符串解析为html文档
html = etree.HTML(text)
print(html)
# 按字符串序列化html
result = etree.tostring(html).decode('utf-8')
print(result)
从文件中读取html代码:
#读取
html = etree.parse('hello.html')
result = etree.tostring(html).decode('utf-8')
print(result)
在lxml中使用xpath语法
first item
second item
third item
fourth item
fifth item
语法练习
from lxml import etree
html = etree.parse('hello.html')
# 获取所有li标签:
# result = html.xpath('//li')
# print(result)
# for i in result:
# print(etree.tostring(i))
# 获取所有li元素下的所有class属性的值:
# result = html.xpath('//li/@class')
# print(result)
# 获取li标签下href为www.baidu.com的a标签:
# result = html.xpath('//li/a[@href="www.baidu.com"]')
# print(result)
# 获取li标签下所有span标签:
# result = html.xpath('//li//span')
# print(result)
# 获取li标签下的a标签里的所有class:
# result = html.xpath('//li/a//@class')
# print(result)
# 获取最后一个li的a的href属性对应的值:
# result = html.xpath('//li[last()]/a/@href')
# print(result)
# 获取倒数第二个li元素的内容:
# result = html.xpath('//li[last()-1]/a')
# print(result)
# print(result[0].text)
# 获取倒数第二个li元素的内容的第二种方式:
result = html.xpath('//li[last()-1]/a/text()')
print(result)
Original: https://www.cnblogs.com/48xz/p/16227487.html
Author: HammerZe
Title: XPath语法和lxml模块