
代码 参考修改自:
PARL实现DQN,CartPole环境
内容 参考视频:
世界冠军带你从零实践强化学习
【RL】Tensorflow2实现DQN,CartPole环境
代码地址
DQN的两大创新点
- 经验回放(Experience Repaly)
- 固定Q目标(Fixed Q Target)
经验回放(Experience Repaly)
参考:
强化学习-DQN
每个时间步agent与环境交互得到的转移样本存储在 buffer中。
当进行模型参数的更新时,从 buffer中随机抽取 batch_size个数据,构造损失函数,利用梯度下降更新参数。
例子,

经验回放充分利用了 Q-learning中 off-policy的优势。我们可以把 Target policy看作 军师, Behavior policy看作 士兵, Q-table看作 战术, ReplayMemory看作 战斗过程。
士兵根据 战术进行战斗,之后将 战斗过程报告给 军师,(一段时间后) 军师利用 战斗经验来改进 战术。
通过这种方式,
- 去除数据之间的相关性,缓和了数据分布的差异。
- 提高了样本利用率,进而提高了模型学习效率。
为什么要去除数据之间的相关性?
参考:
关于强化学习中经验回放(experience replay)的两个问题?
为什么机器学习中, 要假设我们的数据是独立同分布的?
理解1: 确保数据是 独立同分布的。这样,我们搭建的模型是 简单、易用的。
理解2:
在一般环境中, 智能体得到奖励的情况往往很少。比如在n个格子上,只有1个格子有奖励。智能体在不断地尝试中,大多数情况是没有奖励的。如果没有 Experience Repaly,只是每步都进行更新,模型可能会找不到"正确的道路",陷入 局部最优或 不收敛情况。
; 固定Q目标(Fixed Q Target)
参考:
DQL: Dueling Double DQN, Prioritized Experience Replay, and fixed Q-targets(三下) 【前面一点的内容】
在DQN中,损失函数的定义是,使 Q尽可能地逼近 Q_target。
在实际情况中, Q在变化,作为 "标签" 的 Q_target也在不断地变化。它使得我们的 算法更新不稳定,即输出的 Q在不断变化,训练的损失曲线轨迹是震荡的。
奇怪的追逐路径(训练时的振荡):



DQN引入了 target_net。具体来说,使用 value_net输出 Q值,使用 target_net输出 Q_target值。
target_net与value_net具有相同的网络结构,但不共享参数。
- 在一段时间内,
target_net保持不变,只训练value_net。这样,相当于固定住"标签"Q_target,然后使用预测值Q不断逼近。 - 一段时间过后,将
value_net的权重 复制到target_net上,完成target_net参数的更新。
通过这种方式, 一定程度降低了当前 Q 值和 target_Q 值的相关性,提高了算法稳定性。
Original: https://blog.csdn.net/LittleSeedling/article/details/122824328
Author: LittleSeedling
Title: 【RL】Tensorflow2实现DQN,CartPole环境
相关阅读1
Title: 所学自省
本文是根据在大学的这几年接触的东西写的,给同为软件的,需要的同学参考参考,看看这几年自己在大学学了多少东西。
你学过的东西写了多少笔记?又记得多少?
自己主动去设计一个项目来做的,有多少?
能拿得出手的作品有多少?
(博客园)文末评论和编辑按钮中间有个 MD,点击能看到本文的markdown文本,需要本文markdown文本的可以复制拿去自用。
- H5排版
- 公众号管理
- 公众号自动回复
- 公众号菜单管理
- 公众号推送文章发布流程与注意事项
- 公众号专栏建设
- 公众号第三方管理平台熟悉(选学)
- 图像设计与处理
- Photoshop
- 图片压制
- 音视频制作与处理
- Premiere(至少学会基本剪辑、导入导出)
- Audition(至少要会消音去噪)
- After Effects(至少要会套模板和导出MP4)
- 小丸工具箱/小丸工具箱(熟悉各种视频格式,了解转码压制方法)
- 基于FFmepg API的开发(选修)
- 流媒体技术(选修)
- 办公软件
- Word、PPT、Excel二级水平
-
文档之间的转码操作
-
Java 基础
- C# 基础
- PHP基础
- C语言/C++
-
Python基础
-
HTML5+CSS3
- Bootstrap
- JavaScript
- jQuery
- Vue
- Vue2
- Vue3
- Element-ui(Vue2 UI框架)
- Element-ui plus (Vue3 UI框架)
- Vant (Vue3 移动端框架)
- 响应式开发思想与实现
-
自适应开发思想与实现
-
Java 高级编程
- Javaweb开发
- MVC开发思想
- Maven项目管理工具的使用
- Spring5
- Mybatis
- Spring5+SpringMVC+MyBatis
- MyBatis plus
- Spring Boot
- Spring Cloud
- Django
- Flask
- xml
-
redis
-
OpenCV
- TensorFlow
- PyTorch
- numpy、pandas、matplotlib
-
requests、urllib、bs4
-
Linux
- centOS
- Ubuntu
- UOS
-
kali
-
重装系统
- C盘扩容
-
办公台式机组装
-
MySQL
- PostMan / apifox
- Markdown
- UML
- 阿里云图标库的使用
- 宝塔面板的使用
我相信看到本文的有些同专业同学回想:"算了,一大堆看不懂的东西。"
也有的人看了收藏,然后不管了。
也有人看来,挨个百度,了解是什么东西,然后可能就回去哔哩哔哩找教程,去菜鸟教程网站看教程......
论差距是怎么产生的。
打钩的时候是不是不太自信?查漏补缺。
Original: https://www.cnblogs.com/mllt/p/study.html
Author: 萌狼蓝天
Title: 所学自省
相关阅读2
Title: 《玩态人生》重新学会玩
前方高能警告,在您开始阅读时,请记住,这只是作者小鬼个人的价值观思考。如果看到一半发现严重与您的体系不同,发现不适。请坚决关掉,因为接下来写的内容,可能跟主流的价值观存在很多冲突的地方。
什么是玩态人生,这个词肯定很多人没听过(99%)因为是我刚造的。 对不起大家了,只能造新词,其实跟"游戏人生"这个词的意义很接近,但是"游戏"这个词作为动词的时候跟"玩"比较接近,但是作为名词时太过于广泛,每个人对"游戏"都已经有了一套非常固化、确定的观念,所以我再三考虑,还是造新词了。
以玩的态度去对待人生。
首先我想提出一个问题"玩"究竟是什么?能不能用4-5句话,或者一整篇文章概括性的说,玩是一种什么样的行为?
百科上"通过获得非直接利益来娱乐自身"。
但是这个说法比较窄,获得了直接利益,就不能称之为"玩"么?
玩是一种非常基础的情绪,跟"快乐""悲伤""愤怒"基本上处于一种相同的级别,大多数时候玩会引发快乐,但是也有一些引发"悲伤"的情绪也能称之为玩,比方说仙剑系列,虐你千百遍。
虽然很不好定义"玩"究竟是什么,但是只要说"玩"这个词,所有人就懂了,因为这是人类的天性,就算是一个完全不会说话读写的人,只要能对应上某一种娱乐行为,他也能立即对应起来这个词是什么意思。
这种情绪,这种行为模式本身就是刻画在DNA里的东西。
人可以很容易的界定什么行为是玩,什么行为不是玩,而且也可以很容易的找到玩的方式,实践玩的方法。
给一个圆,可以有100种方法玩。
那么既然是人的本源行为,那么,是否整个生命历程真正有意义的事情就是玩?
这就是这次想造的这个词"玩态人生"。
Linux之父 Linus Torvalds 自传书名叫《Just For Fun》
我想表达类似的观点,用玩的方式去创造也能创造出真正名垂千史的东西。(Linux真的太棒)
刚才有略微提到一点,"玩"可以意会,不可言传。
所以需要从一些侧面去深化一下。
先来描述一个普遍性存在的观点:
"玩就会坏事!"
建议读者在这里停顿一下,想一想"WHY" (给大家留一点空白)
好,回过神来。每个人都肯定不能完全同意小鬼的解释。还是先抛出拙见。
为什么会认为玩既是坏事呢?
从什么时候起的?
大概从1岁起,辛苦的双亲长辈们为了小孩子的安全,在各种各样的情况下,告诫着,这个有危险,那个不能做。
但是小孩子就是喜欢玩,这就是我们的天性,与生俱来的天赋技能。
所以小家伙们为了玩,会捣蛋,会穿马路,会磕磕碰碰,然后大人们一直在禁止。
久而久之,小家伙们越来越不会玩了。
这是错的么?当然不是,这是一个过程,这样的一个吸收人生经验的过程,却很容易过分的抑制人玩的天性。
所以众人认为玩即坏事,其实是一种思维惯性。
玩忽职守当然会坏事,但是职责在人,而不在于方法。
玩也可以玩出花样,玩出一片新天地。
这里举一个写代码的例子,写代码是一件很严肃的事情。多一个逗号,整个功能就挂了。
如果有人告诉我说,要玩着写代码,小鬼可能第一反应是把他从窗外丢出去,再抓回来,再丢一次。
但是以玩写代码有何不可?
请看下图:
(有人写代码的时候用手写的方式拼了一个佛祖出来,期盼无BUG。注释代码,不影响功能)
其实当原本老是以玩坏事的小孩子学会了很多技能之后,他已经知道了所有会出错的地方,绿灯时过马路,怎么拿好一双筷子,怎么做好一道菜。
他已经可以避开所有坏事的选项,但是他也忘了自己其实是会玩的。
再举一个开长途车的例子,也同样是一件非常严肃的事情。
那作为一个老司机,他已经学会了避开了所有会出事故的情况,如果边打游戏边开车,肯定有很大问题。
如果以玩的方式来开车呢?
比方说设定一个游戏规则,一边开车,一边预测下次出现的车辆款式?答对获得1分,答错没分。然后整个旅程就变成了一个3D的猜车游戏。
这样的玩法会坏事么?我们会对来往的车辆更加注意,而且也不会因为疲劳驾驶,也会排解路程的无聊。何乐不为?
当然这里随便举的例子,不一定有多好玩,有的人觉得这个玩法好无聊啊,那就应该自己去创造自己的玩法,只属于自己的不无聊,你已经知道了所有的规则,你不能开出车道,但是你可以在车道内找到属于自己的乐趣。
再举一个例子,踢石子的游戏肯定很多人小时候都玩过,就是放学回家路上踢一块小石头,一路踢回去。为什么现在没法玩了?
一方面是因为玩过了,一方面是因为觉得傻,或者是自己认为别人认为自己傻,另外一方面,也有安全问题的考虑,不小心踢坏一些东西怎么办?(老实讲,被一块小石头击中能有多大危害,又不是全力踢)
有时候人这种生物会被群体束缚,群体认为对的事情,个人的反对一点作用也没有。有时候也有假想中的群体束缚个人。
傻笨就是玩的表象,疯狂就是玩的动力。
这就是玩态人生的核心观点,重新学会玩。
重新去理解玩的含义,重新去创造玩的办法。重新去玩一玩你的人生。
除了玩,人生没什么要紧事。
那么我讲完可行性,现在讲一下这样做有什么价值?
第一,玩是人乐趣的根源,是源动力。
很多时候人遵循了一定的社会规则,社会习惯,但是永远的忘了一开始走上这条路的原因是什么
就像编程一样,一开始其实是觉得做Hack大神很酷,很屌。但是后来一直都是在写相关业务代码,做架构,做外包,接需求做实现。走的越远,越忘了来时的目的。
第二,玩是更容易实现的办法。
以前大家一直在讲,你要坚持你要坚持,比如说学习,学习就是一长段的折磨之后,每日作业,每天听课,晚间学习,周末复习。然后考试时拿到高分的喜悦。
这就是很大程度的锻炼人的延迟享乐机制,有研究表明,越早的学会延迟享乐的人,以后的成就会越高。
这是对的么?当然是对的,但是这确实很难。这是会成功的么?当然会成功,也能看到确实有人成功了。
但是这里面有一个大大前提,要求你是一个大毅力的人,所有人都尊崇那些大毅力的人,也都对他们的事迹如数家珍,但是成功的人确实很少。
因为这些方法只是对而已。但是却不太具有可复制性,与可实践性。大家都是9年义务教育,如果没把你锻炼成这样的人,我建议放下这些不切实际的幻想。真正的落地下来做一些可以做得到的方式。
比如说,坚持运动。
每天都坚持运动,当然身体会很健康,但是为什么还是会胖?还是坚持不了几天就忘了。
因为每天都很痛苦,每天都在考验你的毅力,每天都在放弃的边缘徘徊。这种方法当然有毅力的人坚持下来了,成功减肥了。
但是大多数人还都是肥宅专业户(类似我)。
那么切实有效的办法是什么?以前早就实践过了,却忘了。就是打篮球,对我个人而言,就是找人一起去打篮球。因为打篮球这种运动对我来说实在太有意思了。
以前在学校几乎天天打,工作之后反而找不到人去打,放下了,然后也胖了。
这就是玩的力量。每天都很累,但是每天都很快乐。减肥于无形。
玩的热情与平常坚持的热情简直是两码事,如果拿这种热情去做事,你可以成为达芬奇。
第三,玩可以极具创造力。
玩一种玩法多了,你会很快发现,腻味了。因为玩就是这样,容不得你机械式重复,乏味是最致命的。
当你被动玩时,你无非就是努力去找寻新的游戏,新的旅游地,新的玩伴。
但是玩态人生要求你主动玩,主动去寻找新的玩法,去创造新的玩法,去以极大的热情去创造。去做出这个世界上的唯一的事情。
第四,玩会让你攀登高峰。
乏味是最致命,除了换一种玩法,提高难度也是资深玩家的一剂良方,打通了老手难度,打资深模式。打完资深模式,换一条命模式。一条命也过,就自己设定为无伤通关。相信大家随随便便到哪个直播平台看一下资深玩家玩游戏的方式就知道。
提高难度,这就是资深玩家的玩法,自然而然的,发自内心的提高难度。根本不需要某个人某个组织来规定你。
那么,我们讲了这么多好处跟办法。
玩态人生最大的弊端是什么?
玩说到底是精神需求,如果生存需求得不到保障的情况下,请大家不要考虑这件事。以免分心。
但是生存需求也不要穷奢极欲。保障不会食不果腹,衣不附体即可。
另外一个需要注意的事情是,我们当下讲的所有玩态理念,都是当下这个时代的产物,也只能应用在当下这个时代。
既不能拿战争年代的标准考量,也不能拿未来时代的价值观做考量。
只因为在这种和平年代,这种游戏观下,这件事才能成为可能。
最后,感谢各位阅读。欢迎讨论。还有六一儿童节快乐!
Original: https://www.cnblogs.com/7rhythm/p/9073477.html
Author: 鬼柒
Title: 《玩态人生》重新学会玩
相关阅读3
Title: 机器学习——聚类
1. 分类 vs 聚类
分类:
- 有监督学习(需要标签);
- 依据已知标签的数据,根据一定规则或模式,对新输入数据标记上影响标签(有明确的训练集,有人为给定标签)。
聚类:
- 无监督学习(没有标签);
- 对于给定数据按照其相似性进行划分(没有训练集,没有标签,也不知道确切的类别或簇的数目)。
2. 聚类任务
- 在"无监督学习"任务中研究最多、应用最广;
- 聚类的目标是将数据样本划分为若干个通常不相交的 簇(cluster);
- 既可以作为一个单独过程(用于找寻数据内在的分布结构),也可作为分类等其他学习任务的前驱过程。
聚类:根据某种相似性,把一组数据划分成若干个簇的过程。
- 难点一:相似性很难精准定义! 各种距离,度量学习 !
- 难点二:可能存在的划分太多! 避免穷举,优化算法!
- 难点三:若干个簇 = ? 预先给定,算法自适应!
3. 常见聚类方法:
原型聚类(prototype-based clustering)
- 假设:聚类结构能通过一组原型刻画;
- 过程:先对原型初始化,然后对原型进行迭代更新求解;
- 代表:k均值聚类,学习向量量化(LVQ),高斯混合聚类。
密度聚类(density-based clustering)
- 假设:聚类结构能通过样本分布的紧密程度确定;
- 过程:从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇;
- 代表:DBSCAN, OPTICS,DENCLUE。
层次聚类(hierarchical clustering)
- 假设:能够产生不同粒度的聚类结果;
- 过程:在不同层次对数据集进行划分,从而形成树形的聚类结构;
- 代表:AGNES (自底向上),DIANA(自顶向下)。
4. K-means算法
聚类问题可以通过为每个簇寻找合适的中心来实现。假设每个簇的中心已经找到,可以把所有数据点分配到距离它最近的中心所在的簇。即:j = arg min l d i s t ( x i , μ l ) j=\argmin_ldist(x_i,\mu_l)j =l a r g m i n d i s t (x i ,μl )
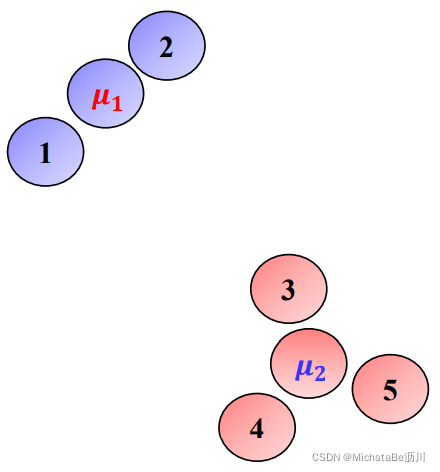
; 4.1 K-means模型
给定数据x x x个簇的个数k k k,K-means模型可以表示为:arg min μ i , C i ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − μ i ∣ ∣ 2 \argmin_{\mu_i,C_i}\sum\limits_{i=1}^k\sum\limits_{x∈C_i}||x-\mu_i||^2 μi ,C i a r g m i n i =1 ∑k x ∈C i ∑∣∣x −μi ∣∣2其中,C i C_i C i 表示第i i i个簇,μ i \mu_i μi 表示第i i i个簇的中心。
目标函数对μ i \mu_i μi 求偏导等于零,得:μ i = 1 ∣ C i ∣ ∑ x ∈ C i x \mu_i=\frac{1}{|C_i|}\sum\limits_{x∈C_i}x μi =∣C i ∣1 x ∈C i ∑x因此,上述模型被称为K-means模型。
K-means模型:arg min C i ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − 1 ∣ C i ∣ ∑ x ∈ C i x ∣ ∣ 2 \argmin_{C_i}\sum\limits_{i=1}^k\sum\limits_{x∈C_i}||x-\frac{1}{|C_i|}\sum_{x∈C_i}x||^2 C i a r g m i n i =1 ∑k x ∈C i ∑∣∣x −∣C i ∣1 x ∈C i ∑x ∣∣2
可能的划分数:S ( n , k ) = 1 k ! ∑ i = 0 k ( − 1 ) i ( k − i ) n S(n,k)=\frac{1}{k!}\sum\limits_{i=0}^k(-1)^i(k-i)^n S (n ,k )=k !1 i =0 ∑k (−1 )i (k −i )n是非凸组合优化问题,NP-难!
4.2 模型求解
采用启发式算法进行求解,主要有以下几种方法:
- Lloyd(Forgy)算法
- Hartigan-Wong算法
- MacQueen算法
下面使用Lloyd算法求解K-means。
- 给定数据x x x和簇的个数k k k;
- 随机选取k k k个簇的中心{ μ i } i = 1 , . . . , k {\mu_i}_{i=1,...,k}{μi }i =1 ,...,k ;
- 重复下述迭代过程直至收敛:
划分步骤:对每个数据点x j x_j x j ,计算其应该属于的簇。arg min i ∣ ∣ x j − μ j ∣ ∣ 2 2 \argmin_i||x_j-\mu_j||2^2 i a r g m i n ∣∣x j −μj ∣∣2 2 更新步骤:重新计算每个簇的中心。μ i = 1 ∣ C i ∣ ∑ x j ∈ C i x j \mu_i=\frac{1}{|C_i|}\sum\limits{x_j∈C_i}x_j μi =∣C i ∣1 x j ∈C i ∑x j
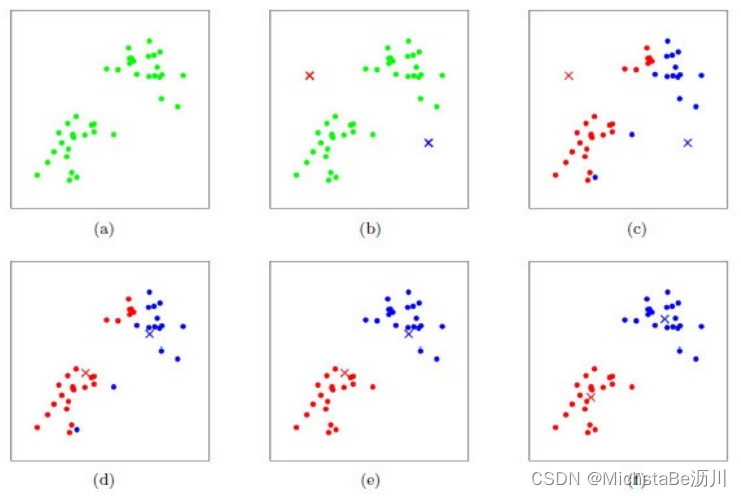
在K-Means聚类时,每个聚类簇的质心是隐含数据。假设K个初始化质心,即EM算法的E步;然后计算得到每个样本最近的质心,并把样本聚类到最近的这个质心,即EM算法的M步。重复这个E步和M步,直到质心不再变化为止,这样就完成了K-Means聚类。
Lloyd算法的优势:
- Lloyd算法属于期望最大化算法(EM算法),可以保证收敛到K-means问题的局部最优解;
- Lloyd算法速度快,计算复杂度为O(nk);
- Lloyd算法思想简单,实现容易,可扩展性强。
Lloyd算法的劣势:
- 簇的个数k k k需要预先给定;
- 聚类结果依赖于初值的选取。
; 4.3 K-means++
K-means++是一种初始化方法,目的是改进K-means算法对初值的影响。流程如下:
- Step 1:随机选取一个簇的中心μ 1 \mu_1 μ1 ;
- Step 2:选择离已有中心最远的数据点作为新的中心;
- Step 3:重复第二步,直至选出k k k个中心;
- Step 4:运行K-means算法。
5. DBSCAN算法
5.1 概念
DBSCAN,即Density-Based Spatial Clustering of Applications with Noise,是一种基于密度的聚类算法。

; 5.2 优劣势分析
优势:
- 不需要指定簇的个数;
- 可以发现任意形状的簇;
- 擅长找到离群点(检测任务);
- 只需要两个参数。
劣势:
- 高维数据比较困难(可以降维);
- 参数难以选择(参数对结果的影响非常大);
- sklearn中效率很低(数据削减策略)。
6. AGNES算法
AGNES,即AGglomerative NESting,是一种凝聚的层次聚类算法。流程如下:
- Step 1:将每个样本点作为一个簇;
- Step 2:合并最近的两个簇;
- Step 3:若所有样本点都存在于一个簇中,则停止;否则转到 Step 2。
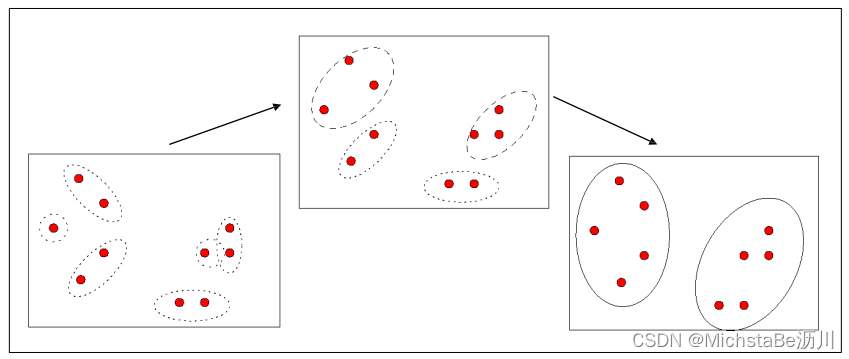
; 7. 聚类性能度量
可参考这篇文章。

Original: https://blog.csdn.net/weixin_47779143/article/details/121879104
Author: MichstaBe沥川
Title: 机器学习——聚类