
请认真阅读以下内容:
本人应该把能踩过的坑全部都踩了(2days)
我把所有坑和解决方案都记录下来(纯文字)
建议先看完某一个大步骤以及了解踩坑原因再执行对应的命令能够有效避免踩坑
本文包括:
(1)官方编译好的动态库(x86,x64)以及我编译好的动态库(arm64)
(2)安装树莓派64位系统
(3)安装bazel(编译tensorflow工具):脚本和编译两个方式
(4)安装tensorflow:编译和直接下载使用两个方式
直接下载(推荐方式):
x86和x64可以直接下载官方编译好的动态链接库,然后跳到安装tensorflow编译完成:
Linux(仅支持 CPU) https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-cpu-linux-x86_64-2.6.0.tar.gz
Linux(支持 GPU) https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-gpu-linux-x86_64-2.6.0.tar.gz
macOS(仅支持 CPU) https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-cpu-darwin-x86_64-2.6.0.tar.gz
Windows(仅支持 CPU) https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-cpu-windows-x86_64-2.6.0.zip
Windows(仅支持 GPU) https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-gpu-windows-x86_64-2.6.0.zip
我编译的树莓派arm64版本:
下载完直接跳到安装步骤
编译安装(不建议方式):
观前提醒(背景):
1.
编译过程十分漫长,你可能需要一天的时间来搞,建议看剧消磨时间
影视推荐:猎魔人,纸牌屋,洛基
2.
如果想要尝试,建议树莓派4B(64位)配置:4G内存+32Gtf卡
编译过程十分耗资源,当然,内存2G应该也行,就是要慢一点(我会有提示,请注意)
我就是4+32,,重装了树莓派64位系统后直接下载编译tensorflow过程中
tf卡占用如下:
Filesystem Size Used Avail Use% Mounted on
/dev/root 29G 14G 15G 49% /
devtmpfs 1.7G 0 1.7G 0% /dev
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 1.9G 492K 1.9G 1% /run
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
/dev/mmcblk0p1 253M 30M 223M 12% /boot
tmpfs 380M 0 380M 0% /run/user/1000
编译时某一时刻内存占用如下:
total used free shared buff/cache available
Mem: 3.7Gi 3.6Gi 34Mi 0.0Ki 104Mi 63Mi
Swap: 4.0Gi 933Mi 3.1Gi
以及
total used free shared buff/cache available
Mem: 3.7Gi 3.5Gi 43Mi 0.0Ki 137Mi 105Mi
Swap: 4.0Gi 1.1Gi 2.9Gi
大部分时候内存占用基本情况(具有一定代表性):
total used free shared buff/cache available
Mem: 3.7Gi 1.9Gi 1.6Gi 0.0Ki 263Mi 1.8Gi
Swap: 4.0Gi 597Mi 3.4Gi
以及
total used free shared buff/cache available
Mem: 3.7Gi 2.7Gi 786Mi 0.0Ki 215Mi 925Mi
Swap: 4.0Gi 420Mi 3.6Gi
3.
我的环境:
- 系统64位,没超频
- 内核:Linux raspberrypi 5.10.63-v8+ #1496 SMP PREEMPT Wed Dec 1 15:59:46 GMT 2021 aarch64 GNU/Linux
- 硬件 :4+32
Original: https://blog.csdn.net/qq_44113911/article/details/122603588
Author: 在退学边缘疯狂试探
Title: arm64/x64/x86/macos安装tensorflow c语言版本
相关阅读1
Title: 机器视觉系列(六)——照明部分
系列文章目录
机器视觉系列(一)——概述
机器视觉系列(二)——机械部分
机器视觉系列(三)——电气部分
机器视觉系列(四)——相机部分
机器视觉系列(五)——镜头部分
文章目录
前言
延续之前的机器视觉系列文章,这里从应用的角度,介绍照明光源部分的相关整理内容。
一、基础概念
照明光源是影响机器视觉系统输入的重要因素,它直接影响输入数据的质量和应用效果。由于没有通用的机器视觉照明设备,所以针对每个特定的应用案例,要选择相应的光源装置,以达到最佳效果。
照明的主要目的为:
① 将待测区域与背景明显区分开;
② 增强待测目标边缘清晰度;
③ 消除阴影;
④ 抵消噪光。
在一定程度上,照明和光源的设计与选择是机器视觉系统成败的关键,其最重要的功能就是使被观察的图像特征与被忽略的图像特征之间产生最大的对比度,从而易于对特征的区分。选择合适的光源不仅能够提高系统的精度和效率,也能降低系统的复杂性和对图像处理算法的需求。
二、光源的分类
光源可分为可见光光源和不可见光光源,最常用的几种可见光光源有LED灯、激光(基本只用于立体视觉);常用的不可见光光源有紫外线UV和红外线IR。
LED光源: 其是目前最常用的光源,主要有以下几个 优点:
① 使用寿命长,大约为10000-30000小时;
②由于LED光源采用多个LED排列而成,故 可以设计成复杂的结构,以实现不同的光源照射角度;
③ 有多种颜色可选,包括红、绿、蓝、白以及红外、紫外;针对不同检查物体的表面特征和材质,可选用不同颜色,即不同波长的光源,从而达到理想效果;
④ 光均匀稳定并且响应速度快,可在10us或更短时间达到最大亮度;
⑤ 可用作闪光灯,响应速度很快,几乎没有老化现象;
⑥由于采用直流供电, 亮度非常容易控制;
⑦工作电压低, 光源功耗小,发热小。
其主要缺点有:
① 其性能与环境温度有关,最大操作温度为60°C。环境温度越高,LED老化越快,寿命越短。
② 白光LED老化会改变颜色坐标(色调和色温)。
推荐的LED光源亮度设置为标称值的50%,这优化了使用寿命,最大限度地减少了老化。
由于LED有如此多的优点,目前在机器视觉中基本都应用LED光源。
激光:相比于普通光源,激光具有以下 优点:
① 方向性好。普通光源(太阳、白炽灯或荧光灯)向四面八方发光,而激光的发光方向可以限制在小于几个毫弧度立体角内,这就使得在照射方向上的照度提高千万倍。激光每200千米扩散直径小于1米,若射到距地球3.8×105km的月球,光束扩散不到2千米,而普通探照灯几千米外就扩散到几十米。
② 亮度高。激光是当代最亮的光源,只有氢弹爆炸瞬间强烈的闪光才能与它相比拟。因此激光的总能量并不一定很大,但由于能量高度集中,很容易在某一微小点处产生高压和几万摄氏度甚至几百万摄氏度的高温。例如,激光打孔、切割、焊接和激光外科手术等实际应用就是利用了这一特性。
③ 单色性好。光的颜色取决于它的波长。普通光源发出的光通常包含着各种波长,是各种颜色光的混合。而某种激光的波长只集中在十分窄的光谱波段或频率范围内。如氦氖激光的波长为632.8纳米,其波长变化范围不到万分之一纳米。例如,激光良好的单色性为精密度仪器测量和激励某些化学反应等科学实验提供了极为有利的手段。
④ 相干性好。干涉是波动现象的一种属性。基于激光具有高方向性和高单色性的特性,它必然会是相干性极好的光。激光的这一特性使全息照相成为现实。
由于激光的这些特性,使得 在超精密测量中,只能使用激光而不能使用普通光源。
基恩士的激光相关产品着重突出其激光光束尖锐技术,其通过独家的光学系统, 将线束直径尖锐到极限(小至25μm),从而实现了以往所无法实现的稳定检测。相应亮点形状对光学系统进行了大幅改良,通过实施最佳化,使以往发生较多的检测不均也转为稳定。

另外,LED光源还可按形状进行分类,主要有:环形光源、背面光源、条形光源、同轴光源、AOI专用光源、球积分光源、线形光源、点光源、组合条形光源、对位光源。
① 环形光源有以下特点:
; 三、光源的主要性能参数
光源的好坏需从以下几个方面衡量:
① 波长范围:其定义为在特征与其周围的区域之间有足够的灰度量区别。好的照明应保证需要检测的特征突出于其他背景。彩色物体反射了一部分光谱,其他部分被吸收。我们可以利用这一特点来增强我们需要的特征,比如使用合适的照明光源使其光谱范围正好是希望看到的波长范围被物体反射,不希望看到的波长范围被物体吸收。例如,如果绿色背景上面的红色被测物需要增强,就可以使用红色照明,这时红色物体会更加明亮,同时绿色物体会变得暗淡。
另外,由于CCD和CMOS传感器对于红外光比较敏感,我们常采用红外光来增强某些特征。增强效果也可通过白光加滤镜得到,然而如果白光这样被过滤,其发光效率将大大降低,所以通常情况下从开始就使用彩色照明。
注意: 由于绿色LED相比红色和蓝色LED具有明显更高的能源转换效率(同样的电流下,绿色LED的光通量是红色LED的近2倍,蓝色LED的近7倍),在被测物没有颜色选择的前提下, 使用绿色LED可以获得更高的亮度和更小的发散角,从而可以使感光较差物体的成像图像获得更大的对比度,提高信噪比,利于进行机器视觉算法的特征提取,所以更具优势。
注意: 红色LED在CCD传感器上产生最大的灰度值,尽管发光强度(人眼)不是最大的。另一方面,最大发光强度为5100mcd的白色LED仅产生中等灰度值。这是由于发光强度值与人眼的V(λ)曲线评估和CCD传感器感知的差异造成的。即使是具有低传感器相关辐射强度的红外LED,由于其较宽的半宽波长,也会产生相当大的灰度值。
白光作为不同波长的混合物不会产生衍射。而单色光容易发生衍射,且衍射发生在光接触的每个材料边缘。所以对于以边缘提取为目标的机器视觉应用,应优先使用白光照明,从而避免产生模糊的边缘。 对于零件颜色经常变化的应用,白光是最好的选择,因为它不会抑制或强调任何颜色。
②亮度:对应的指标是照度。当有两种光源时,应选择更亮的光源。当光源较暗可能出现三种不利于观测的情况:
四、光源的照明方式
机器视觉中照明的目的是使被测物的重要特征显现,而抑制不需要的特征。为达到此目的,我们需要考虑光源与被测物间的相互作用,其中最核心的因素就是光源和被测物的光谱组成,我们可以用单色光照射彩色物体以增强被测物相应特征的对比度,以及照明的角度,其可以用于增强某些特征。物体表面的几何形状和光滑度决定了光在物体表面的反射情况。光在光滑度高的物体表面可能发生高度反射(镜面反射)或者高度漫反射。决定镜面反射还是漫反射的主要因素是物体表面的光滑度。物体表面的形状越复杂,其表面的反射情况也随之而复杂。比如对于一个抛光的镜面表面,光源需要在不同的角度照射,以此来减小光源。这些都需要通过照明角度来进行控制。

光源的入射方向取决于光源的类型和相对于物体放置的位置。一般来说有两种最基本的方式:直射光和漫射光,所有其他的方式都是从这两种方式中延伸出来的。
①直射光:入射光基本上来自一个方向,入射角小,光集中在非常窄的空间范围内,能投射出物体阴影。
②漫射光:入射光来自多个方向,甚至所有的方向,光在各个方向的强度几乎是一样的,不会投射出明显的阴影。
实际应用中有以下几种常见的照明方式:
① 直接照明:其是指光直接射向物体,得到清晰的影像。直接照明适用于得到高对比度的图像。若直接照在光亮或者反射的材料上,则会引起像镜面的反光。其最大好处是便于安装。直接照明一般采用环形光源或点光源。环形光源是一种常用的照明方式,易安装在镜头上,可为漫反射表面提供充足的照明。明场漫射正面照明方式常用于防止产生阴影,并用于减少或防止镜面反射,也可以用于透过被测物体的透明包装,如下图:

明场直接正面照明有两种方法:一种是使用倾斜的环形光,常用于使孔洞或感兴趣区域产生阴影,这种照明方式的缺点是光线分布不均匀;另一种是使用同轴平行光,常用于采集会产生镜面反射的物体图像。如下图:

② 暗场照明:其为物体表面提供低角度照明。使用相机拍摄镜子,使其在相机的视野内,如果在视野内能看见光源,则为亮场照明,反之为暗场照明。因此,光源是亮场照明还是暗场照明取决于光源的位置。典型的暗场照明可以突出被测物的缺口及凸起,可增强像划痕、纹理或雕刻文字等特征,应用于表面部分有突起或有纹理变化的照明。如下图:

③ 背光照明:其是指从物体背面射过来均匀视场的光。背光方式只显示不透明物体的轮廓,常用于被测物体需要的信息可以从其轮廓得到的场合,如测量物体的尺寸和确定物体的方向。背光照明可以产生很强的对比度,通过相机可以看到物面的侧面轮廓。应用背光照明技术时,物体表面特征可能会丢失。例如,可以应用背光照明技术测量硬币的直径,但是却无法判断硬币的正反面。对于透明物体,背光可以用于检测被测物的内部部件,可避免使用正面照明造成的反射。漫射背光对于有一定高度的被测物,其在相机一侧的某些部分也可能会被照亮,因此漫射背光主要用于厚度不大的被测物,平板金属工件和灯泡中的灯丝是常用明场漫射背光照明的两类被测物。如下图:

明场平行光背光照明需要使用远心镜头配合,而且照明与镜头位置需要仔细调整,这种照明会使被测物轮廓非常锐利。此外,由于使用远心镜头,图像也没有透射变形,所以这种照明常用于测量应用。如下图:

④ 连续漫反射照明:其适用于物体表面有反射或者表面角度复杂的情况。连续漫反射照明应用半球形的均匀照明,以减少影子及镜面反射。这种照明方式可用于完全组装的电路板照明,可以达到170°立体角范围的均匀照明。
⑤ 同轴照明:其通过垂直墙壁的发散光,照射到一个使光向下的分光镜上,相机从上方通过分光镜看物体。同轴照明适用于检测高反射率的物体,也适用于受周围环境阴影的影响、检测面积不明显的物体。
⑥ 结构光照明:其可以通过检查具有投影光图案,来测量3D表面信息。不透明表面上的投射光使我们能够使用二维传感器获得三维信息。借助光模式可以:
; 五、照明选型
照明选型过程大致分为:
①了解项目需求,明确要检测或者测量的目标。
②分析目标与背景的区别,找出两者之间的光学现象。
③根据光源与目标之间的配合关系以及物体的材质,初步确定光源的发光类型和光源颜色。
④用实际光源测试,以确定满足要求的照明方式。
即: 外形尺寸→打光方式(角度)→颜色→光照强度。
照明示例:
① 直射光

② 漫射光

③ 平行光


④ 偏振光


⑤ 单色光

⑥ 光的过滤及加强

⑦ 红外光散射率低,透射率高,可透过印刷图像,屏幕玻璃表面,薄膜,液体等。


⑧ 紫外光波长短,主要应用于UV胶水固化及检测,防伪。

⑨ 明场照明

⑩ 暗场照明

光源最好配合专门的光源控制器使用,因为:
①开关电源启动时,电压是不稳定电压,瞬间峰值电压会超过LED灯的耐压值,影响光源的使用寿命。
②在相同的摄像头及镜头参数下,照明光源的光波波长越短,得到的图像的分辨率越高。所以在需要精密尺寸及位置测量的视觉系统中,应尽量采用短波长的单色光作为照明光源,对提高系统精度有很大作用。
六、闪光灯照明
对闪光灯照明的一些要求:
①闪光灯内部的延迟、上升、下降时间短
②闪光灯重复率>所用相机的帧率
③EMC能力
④寿命长
⑤寿命后亮度损失低(无法补偿!)
⑥恒定光能下的可变闪光时间
⑦可变闪光亮度而不改变闪光时间。
使用闪光灯的一些注意事项:
①闪光灯的短光脉冲宽度使其成为需要停止运动的应用(例如高速检查)的绝佳选择。
②闪光灯可用于将生产线上的零件冻结在相机下方进行检查时。触发闪光灯的一致性也是这些应用的主要优势。
③使用闪光灯可以缩短曝光时间(低至1/200 000秒),而不是来自成像传感器的预设(通常为1/30 000~1/60 000秒)。此外,对于没有快门的传感器,可以闪光到标准曝光时间。采用卷帘快门技术的传感器不适合与闪光灯组合使用——为此需要逐行扫描。
④闪光灯(和短曝光时间)适合抑制环境光的影响,但这需要比环境光高几倍的闪光灯光能。
从理论中可以看出,对于入射光和透射光,闪光应用都是可能的。注意测试对象的反射率。许多真实零件的有限反射率使得无法使用入射闪光灯。反射光的量太少了。具有透射光的闪光灯应用通常可靠地工作。
运动模糊是零件在曝光或闪光期间移动的效果。这可能是由以下原因引起的:
①曝光期间部件移动
②曝光期间相机移动(振动)
③曝光时间过长
④照明时间过长(闪光时间)。
注意:通常图像中一个像素的运动模糊是可以用于清晰成像的(可能有例外)。
运动模糊的大小可由下式确定:

其中,MB为图像中的运动模糊;Sexp为曝光时间/闪光时间期间零件的运动;PR为像素分辨率;no.of pixels为像素数,传感器在零件运动方向上使用的像素数;FOV为相机在零件运动方向上的视场长度。
上面的公式说明了更好的像素分辨率使应用程序对运动模糊更加敏感。为了避免这种情况,可以缩短曝光时间和/或闪光时间。
基于对恒定曝光H = Et的需求,如果使用闪光灯照明,则需要在图像中达到相同的亮度以显着增加照明功率(照度E)。为了在图像中生成相同的亮度(恒定的f-stop数),以下示例性关系是有效的:

该示例表明,对这种高照度的需求只能在短时间内满足,并且只能通过闪光灯光源来满足。对足够闪光灯能量的需求通常与对大景深的需求相关联。对于更大的焦深,更强的封闭式光圈将再次增加对更多光线的需求。更大的光圈数意味着需要双倍的光量。
选择闪光灯的一般步骤*:
①找到匹配的照明技术:用静态光检查照明:可能还是不可能?
②确定灯光颜色:注意与零件颜色的相互作用。
③确定照明尺寸
④照明组件可用作脉冲或闪光模型?
⑤时间和亮度考虑(很大程度上取决于设计):带闪光灯的入射光:比1/10 000秒更短的闪光时间大多是有问题的脉冲光入射光:短于1/2000秒的闪光时间大多是有问题的透射光。使用闪光灯:最高可达1/200 000s透射光。使用脉冲光:大约最高可达1/20 000s
⑥可达到的闪光重复率(很大程度上取决于设计)
; 七、实际应用注意事项
机器视觉的工业场景并没有像实验室那样提供理想的照明环境。实验室测试的照明在工厂车间也不能自动工作。最大和不可估量的影响来自环境光和外来光。它可以是静态的(来自工厂大厅的照明)或动态的(通过窗户射入的阳光)。尽量减少环境光影响的第一个条件是选择尽可能强大的照明,称为正确选择的照明技术。目的是计算出的照明功率(在所考虑的光谱带内)比环境光强。如果能保证这一点, 可以尝试通过以下方式尽量减少环境光的影响:
① 选择更短的曝光时间
② 选择更大的光圈数
③ 选择闪光灯
④ 同时选择所有这些措施。
注意:初步检查视觉系统安装位置的环境和外来照明条件。也可以通过视觉系统测量来检查它,而不仅仅是通过你的主观眼睛。感受一下环境光的强度。在选择照明技术、照明组件和软件算法时要考虑到这一点,一些选项会自动被拒绝。
使用单色光或红外光与滤光片相结合来抑制环境光的影响。一种简单但非常有效的方法是用不透明的外壳(内部需通过刷漆等手段,增强吸光性能)封装相机—光学—照明单元。这是一种久经考验的方法,其在各种条件下都有效的对环境/外来光抑制。如果不清楚以后机器安装在哪里,这种方法将是最安全的。
总结
以上就是关于照明光源要讲的内容,欢迎大家对本文章进行补充和指正。
参考资料
《Halcon机器视觉算法原理与编程实战》,北京大学出版社
《海康机器视觉认证工程师官方资料》
《Handbook of Machine and Computer Vision——The Guide for Developers and Users》,Alexander Hornberg,Wiley
《KEYENCE产品综合目录》
Original: https://blog.csdn.net/oruchimaru0420/article/details/125250889
Author: 晓dawn
Title: 机器视觉系列(六)——照明部分
相关阅读2
Title: DeepLearning:windows环境下C++环境实现Tensorflow编译部署
【写在前面】

都说深度学习的这条大船上来了就应该不惧风雨,可是在配置环境这条路上的坑真是刚出旧坑又入新坑,2021年最后一天了。想想rensorflow的源代码在windows 环境下的编译历程,就忍不住想总结一下写一篇文章总结总结如同沙海 求生一般的爬坑之行和大家一起学习...
tensorflow 的c++编译大家一定要有耐心,同样的指导流程,不一样的电脑环境,但坑永远都是五花八门...
先来个定海神针压压惊:编译好的Windows 64bit AVX 指令集下的tensorflow文件(CPU)
链接:https://pan.baidu.com/s/1zYwMDt36OxJuzL5k63H2Nw
初始沙漠图片经过模型处理后的效果如下:
【参考链接】
tensorflow源码地址:
Bazel - 在 Windows 上安装 Bazel:
Bazel官方安装指导:
【软件版本】
环境版本:
系统:Windows10系统64bits
CUDA 10.0
cuDNN 7.6 (cuda+cudnn安装传送门)
(官方地址)
Python3.6.7
tensorflow 1.13.1
为了方便最好电脑网络翻墙,网上教程很多大家自己网罗;
本人安装 原文链接:
https://blog.csdn.net/weixin_42359147/article/details/80622306
https://blog.csdn.net/weixin_44322778/article/details/107359206
【自主编译】
tensorflow的C++编译方式根据其版本不同主要有三种:
①tensorflow版本号
bazel编译实战
软件安装:
①安装vs2017
②安装msys2
③安装Python3.6.7
④安装Bazel
⑤下载tensorflow和编译文件Tensorflow-windows-build-script
⑥编译
⑦模型转换和加载
⑧VS2017调用测试
tensorflow官方文档:
在 Windows 环境中从源代码构建:
版本问题—keras和tensorflow的版本对应关系,
tensorflow CUDA cudnn 版本对应关系:
对应关系在官方文档中有详细说明:
安装Python
Python版本切换参考博文:
https://blog.csdn.net/weixin_44322778/article/details/122195669
安装bazel:
https://blog.csdn.net/darkrabbit/article/details/81262524
安装msys
1:
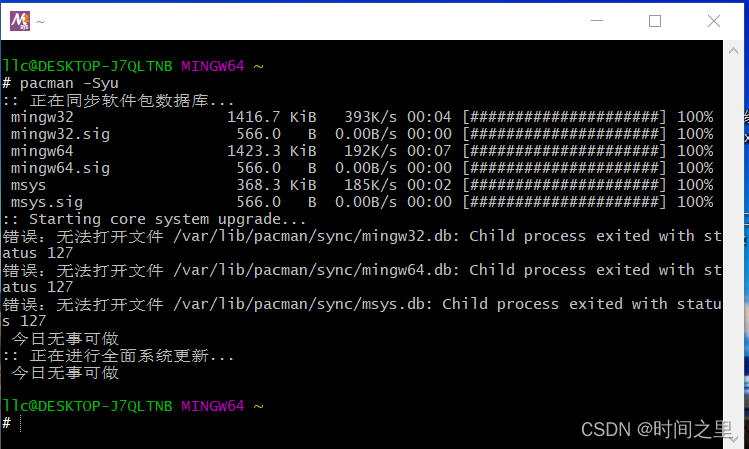
1.安装完msys后报错
解决办法:解决msys2"无法升级 mingw64 (无效或已损坏的数据库 (PGP 签名))"密钥失效问题
【ERROR】
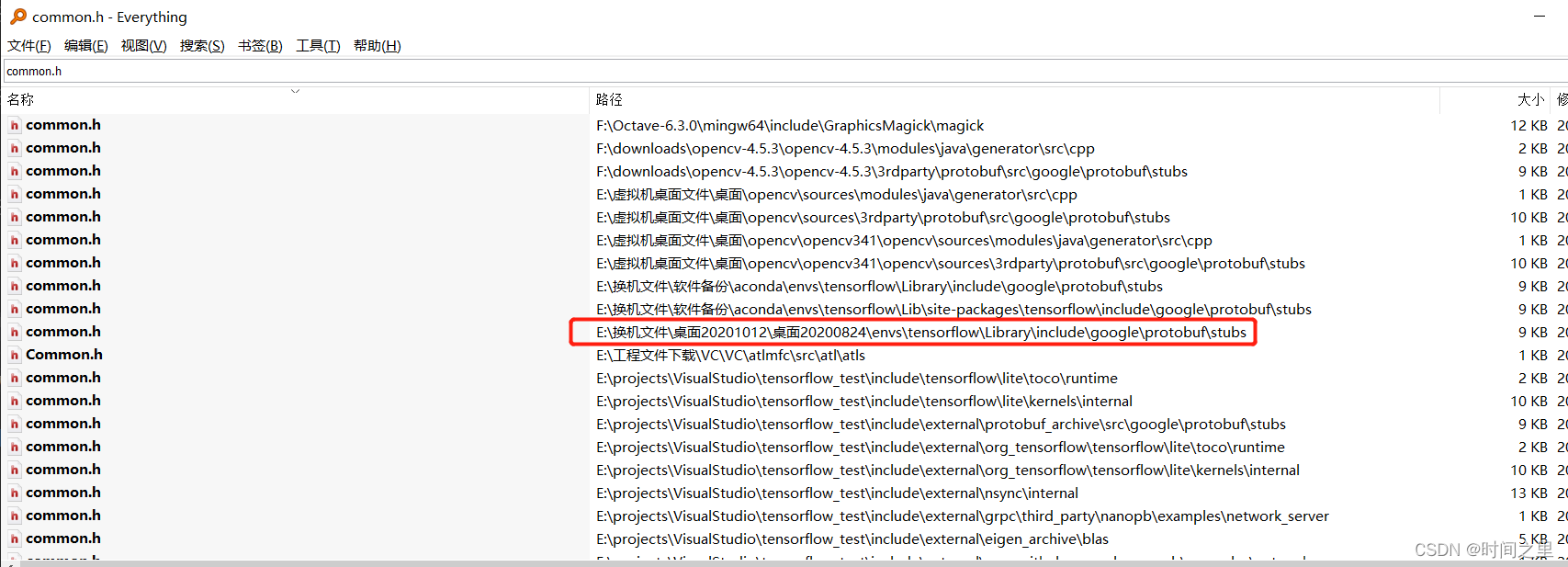
查找:common.h文件位置
发现aconda 虚拟环境中有文件:
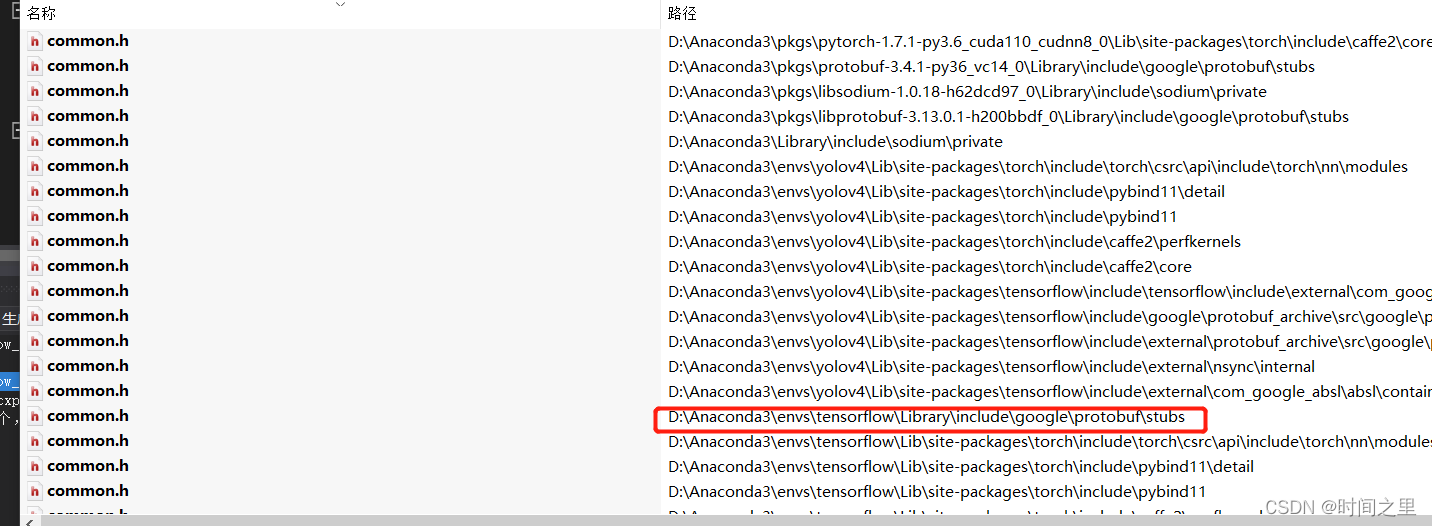
环境配置:
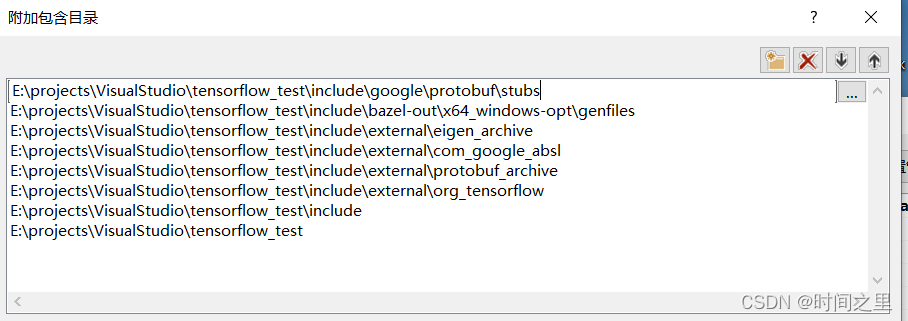
【测试报错】

原因:
模型文件是高版本的tensorflow版本,c++环境中的Tensorflow版本较低,可以直接使用编译好的较高版本的tensorflow
ps:也可以通过c++直接调用py文件实现模型的加载,就是时间效率有点低,需要大家多做改进:参考链接:https://blog.csdn.net/xiaomu_347/article/details/81040855
Original: https://blog.csdn.net/weixin_44322778/article/details/122185123
Author: 时间之里
Title: DeepLearning:windows环境下C++环境实现Tensorflow编译部署
相关阅读3
Title: 机器学习概论 聚类算法实现(实验四)
一、实验目的
1、熟悉使用numpy模块生成二维正态分布;
2、掌握kmeans聚类的代码实现;
3、熟悉numpy的使用;
4、熟悉matplotlib的使用。
二、实验设备
计算机:CPU四核i7 6700处理器;内存8G; SATA硬盘2TB硬盘; Intel芯片主板;集成声卡、千兆网卡、显卡; 20寸液晶显示器。
编译环境:python解释器、Pycharm编辑器
三、实验内容
1、新建项目和文件,并导入numpy和matplotlib
(1)打开Pycharm,新建项目,并在该项目下新建文件kmeans_clustering.py。
(2)导入一些编程中需要的包。
import numpy as np
import matplotlib.pyplot as plt
2、构造一个函数data_producer
(1)定义函数头data_producer,该函数有三个参数,miu,sigma,sample_no分别表示生成二维正态分布的均值,标准差和生成样本点的个数。
(2)调用numpy.random.multivariate_normal生成二维正态分布的数据。
(3)该函数返回生成的数据。```
```java
def data_producer(miu, sigma, sample_no):
data = np.random.multivariate_normal(miu, sigma, sample_no)
return data
``3、编写一个类KmeansClustering
(1)构造一个类KmeansClustering,并定义构造函数,需要数据集和kmeans算法中的k作为输入。
(2)定义类方法cluster,实现kmeans算法,并打印分类后的混淆矩阵,返回分类后的数据。`
```java
class KmeansClustering:
def __init__(self, data, k, maxrenew):
self.data = data
self.k = k
self.Sigma1 = None
self.Sigma2 = None
self.Sigma3 = None
self.renew = 0
self.maxrenew = maxrenew
def cluster(self):
a = []; iter = 0
for i in range(self.k):
x = np.random.randint(0, np.shape(self.data)[0])
a.append(self.data[x])
c = np.array(a)
Old_d = np.copy(c)
while(self.maxrenew 1000):
New_d = np.copy(Old_d)
self.Sigma1 = []
self.Sigma2 = []
self.Sigma3 = []
for j in range(np.shape(self.data)[0]):
if np.argmin(np.sqrt(np.sum((self.data[j, :-1]-New_d[:, :-1])**2, axis=1))) == 0:
self.Sigma1.append(self.data[j])
if np.argmin(np.sqrt(np.sum((self.data[j, :-1]-New_d[:, :-1])**2, axis=1))) == 1:
self.Sigma2.append(self.data[j])
if np.argmin(np.sqrt(np.sum((self.data[j, :-1]-New_d[:, :-1])**2, axis=1))) == 2:
self.Sigma3.append(self.data[j])
self.data=np.vstack((self.Sigma1, self.Sigma2, self.Sigma3))
aa = np.shape(self.Sigma1)[0]
bb = np.shape(self.Sigma2)[0]
cc = np.shape(self.Sigma3)[0]
qq = np.shape(self.data[aa+1:bb+1])
New_d[0] = np.array(np.mean(self.data[:aa+1], axis=0))
New_d[1] = np.array(np.mean(self.data[aa+1:aa+bb+1], axis=0))
New_d[2] = np.array(np.mean(self.data[aa+bb+1:], axis=0))
if np.sum(New_d != Old_d) == 0:
self.renew += 1
print("更新不变的次数", self.renew)
if self.renew >= 3:
return self.Sigma1, self.Sigma2, self.Sigma3
else:
iter += 1
print("迭代次数", iter)
Old_d = New_d
return self.Sigma1, self.Sigma2, self.Sigma3
4、编写if name" main":
(1)构造if name" main":。
(2)在其中设置生成二维正态分布的参数,调用data_producer获取数据。
(3)初始化KmeansClustering类的一个对象my_kmeans,调用cluster方法。
(4)绘制原始数据分布和分类后的数据分布。
if __name__ == "__main__":
Sample_No = 100
Miu1 = [0, 3]
Sigma_1 = np.array([[2, 0], [0, 2]])
Miu2 = [3, 0]
Sigma_2 = np.array([[2, 0], [0, 2]])
Miu3 = [5, 5]
Sigma_3 = np.array([[2, 0], [0, 2]])
Data1 = data_producer(Miu1, Sigma_1, Sample_No)
Data1 = np.hstack((Data1, np.zeros([Sample_No, 1], dtype=np.int8)))
Data2 = data_producer(Miu2, Sigma_2, Sample_No)
Data2 = np.hstack((Data2, np.zeros([Sample_No, 1], dtype=np.int8)))
Data3 = data_producer(Miu3, Sigma_3, Sample_No)
Data3 = np.hstack((Data3, np.zeros([Sample_No, 1], dtype=np.int8)))
Data = np.vstack([Data1, Data2, Data3])
my_kmeans = KmeansClustering(Data, 3, 1000)
Sigma_1, Sigma_2, Sigma_3 = my_kmeans.cluster()
plt.figure()
plt.subplot(121)
plt.plot(Data1[:, 0], Data1[:, 1], 'rs', Data2[:, 1], 'gD', Data3[:, 0], Data3[:, 1], "x")
plt.subplot(122)
plt.plot(np.array(Sigma_1)[:, 0], np.array(Sigma_1)[:, 1], 'rs', np.array(Sigma_2)[:, 1],
'gD', np.array(Sigma_3)[:, 0], np.array(Sigma_3)[:, 1], "x")
plt.show()
实验截图:


五、实验总结
本次实验学习了kmeans聚类的代码实现,一种无监督的聚类算法。在给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。但是从几组数据来看,迭代次数的多样性,对于K值的选取不好把握,如果数据不平衡,则kmeans聚类效果会不佳。
Original: https://blog.csdn.net/le000426/article/details/121864240
Author: 乌卡拉卡乐乐子
Title: 机器学习概论 聚类算法实现(实验四)