
基于STM32的有限词条语音识别与对话模块
- 一、模块整体设计思路
- 二、器件选型与方案确定
* - 1、器件选型
- - 2、方案确定
- 三、IO资源分配与模块介绍
* - 1、模块资源分配
- 2、模块介绍
- 四、调试步骤
* - 第一步:初始程序
- 第二部:硬件SPI实现通信
- 第三步:单独对W25Q128进行读写测试
- 第四步:单独对语音合成模块SYN6288进行测试
- 第五步:语音识别与语音合成程序合并测试
- 第六步:单菜单整体调试
- 第七步:实现菜单的切换与返回操作
- 第八步:程序简化
- 第九步:测试发现问题并改进
- 五、总结
* - 1、遗留问题
- - 2、新思路-CI1102(80词条)/CI1103(300词条)附说明文档
- - 参考文献与下载
一、模块整体设计思路

前期设计思路
; 二、器件选型与方案确定
1、器件选型
(1)语音识别模块
语音识别采用LD3320A语音识别芯片, LD3320是一款非特定语音识别芯片,使用前不需要语音识别训练就能够识别不同的群体,能同时识别普通话和方言。LD3320能够准确快速识别不同实验对象发出的相同的语音命令,使其的适用范围更加广泛。
LD3320具有可动态编辑的关键词语列表,只要在程序初始化时将需要识别的内容以拼音的形式写入LD3320,即可进行语音的识别 。举一个简单示例:在使用过程中,微处理器把诸如"wang zi"的拼音串按一定格式要求写入LD3320芯片的关键词列表中,当LD3320模块识别的语音内容与该关键词列表中的内容相同时便会输出相应的词条号。
LD3320的关键词列表的容量为50,在某一时刻,LD3320识别的语音内容就与这50条关键词进行对比,将最合适的结果所对应的词条号通过SPI串口通信输出给STM32F103处理器。此外,LD3320没有预置外部存储器的扩展接口,实现了真正的单芯片语音识别,因此大大消减了成本费用 。
(2)词条存储模块
因为LD3320A一次只能进行50条词条的存储,如果要进行大容量语音识别只能采取词条的分级管理,这样就涉及到词条的存储。考虑到词条分级管理所需要的存储空间大小,采用W25Q64作为词条存储设备最为合适。与U盘和SD卡存储相比,W25Q只需要通过SPI口连接至主控芯片即可,不需要类似U盘或SD卡特定的处理芯片,这样大大减少成本。
(3)语音提示模块
语音提示模块采用比较简单的TTS芯片,与廉价的MP3播放芯片相比,TTS芯片不需要去考虑音频文件的存储问题与环境干扰问题。从成本方面去分析,最主要的便是音频文件的存储,经测试1s的音频文件占用29kb大小,这样考虑到词条的三级管理是需要2403条语音提示,这样所需存储空间为66MB,这超过W25Q最大存储容量,所以需要U盘与SD卡参与,这样成本远超普通的TTS语音合成芯片。
TTS语音合成芯片常用的型号有科大讯飞的XFS5152CE、SYN6288、SYN6658等,综合考虑成本与实现该项目所需的功能,最终选型SYN6288。
(4)主控芯片
综合上述模块的选型与整体模块架构,在本项目中MCU需要具备:2个SPI接口,2个USART接口,通过MCU选型软件选择价格低廉的48脚主控芯片STM32F103C8T6作为项目MCU。
2、方案确定

方案定稿
; 三、IO资源分配与模块介绍
1、模块资源分配
引脚号引脚名称功能连接模块连接模块3PC14外部RTC晶振32.768KHz晶振OSC32IN4PC15外部RTC晶振32.768KHz晶振OSC32OUT5OSC_IN外部晶振8M晶振XLAT-IN6OSC_OUT外部晶振8M晶振XLAT-OUT7NRST复位复位电路NRST12PA2USART2_TX语音合成模块SYN6288-RxD13PA3USART2_RX语音合成模块SYN6288-TxD14PA4SPI1_NSSW25Q64的接口座W25Q128-CS-B15PA5SPI1_SCKW25Q64的接口座W25Q128-CLK-B16PA6SPI1_MISOW25Q64的接口座W25Q128-DO-B17PA7SPI1_MOSIW25Q64的接口座W25Q128-DI-B18PB0IO刻字机串口流控制(USART1)IO20PB2BOOT1接地25PB12SPI2_NSSLD3320A模块LD CS26PB13SPI2_SCKLD3320A模块LD SDCK27PB14SPI2_MISOLD3320A模块LD SDO28PB15SPI2_MOSILD3320A模块LD SDI30PA9USART1_TX端口连接刻字机主板OUT-TxD31PA10USART1_RX端口连接刻字机主板OUT-RxD34PA13JTCK_SWDATSWD烧录接口SWIO37PA14JTCK_SWCLKSWD烧录接口SWCLK44BOOT0BOOT0接地45PB8IO接语音模块复位LD IRQ46PB9IO接语音模块中断信号LD RST
2、模块介绍

模块正面效果图

模块反面效果图
; 四、调试步骤
第一步:初始程序
初始程序基于语音模块的毕业设计去考虑,完全从毕业设计的程序出发。初始程序具备了50个词条的指令识别,以及识别之后的串口打印与OLED屏显示识别结果。MCU与语音模块采用了模拟SPI总线通信。
第二部:硬件SPI实现通信
在原始程序的基础上,将模拟SPI通信更改为硬件SPI通信,使用了MCU的SPI2通信接口,在保留原有功能的基础上进行了程序的移植。
第三步:单独对W25Q128进行读写测试
W25Q128与MCU连接采用了硬件SPI通信,使用的时SPI2接口。该程序实现了对W25Q128扇区擦除、数据写入与读出并进行两次数据比对。注意:通过串口1打印显示的时候会发现部分中文汉字数据乱码,这是只要点击十六进制显示并取消按十六进制显示,串口的中文汉字便会显示正常。
第四步:单独对语音合成模块SYN6288进行测试
SYN6288语音模块使用起来比较简单,直接通过串口2发送相关指令与待合成命令即可,SYN6288连接喇叭便会发出待合成语音命令。
第五步:语音识别与语音合成程序合并测试
在硬件SPI完成语音识别的基础上,在每一个识别结果下单独加入语音合成命令取代原有的串口打印与OLED屏显示,完成了一个简单的语音交互功能。
第六步:单菜单整体调试
这一步就是对之前整体功能的调试操作,事先通过单独程序完成对W25Q128数据写入,之后整体程序先读出W25Q128的内容并进行数据处理分类。分成了待识别的拼音数组、待合成的语音数组、待发送的指令数组以及待使用的扇区地址数组。之后便按照W25Q128读出内容进行语音识别与语音的合成操作。
第七步:实现菜单的切换与返回操作
这一步便是实现大量指令识别的基础。由于LD3320A一次只能进行50个词条的识别,要实现大量指令识别只能按菜单分批次写入,这就需要菜单切换与返回操作。
第八步:程序简化
为了实现大量指令的识别以及菜单的分级管理,必须对原有程序的用户处理函数进行简化操作,去掉switch选择并进行数据统一操作(去掉了扇区地址的数组),对这个操作的理解需要先理解用户程序的编写思路。
第九步:测试发现问题并改进
五、总结
1、遗留问题
1、W25Q128词条批量写入问题
前期W25Q128,后期因为用不到16M的容量,最终确定选用8M的W25Q64,程序更改只要更改FlashID即可,W25Q128的FlashID为0xEF4018,W25Q64的FlashID为0xEF4017。
前期W25Q128词条写入一次只写入一个扇区的内容,当然写入的内容要小于扇区容量,一般词条测试是否和要求的。
现在词条写入思路是:设定扇区地址并在相应扇区地址写入相应的内容(必须一一对应,主程序依靠其一一对应实现程序简化去掉了原有扇区地址数组),如果想要对调试菜单的内容进行写入,只需呀将红框标出的FLASH_WriteAddress改为0x001000,并将下面红框中的内容进行替换即可。这样虽然简单,但是总共50组词条写入,就要进行这样操作50次,我们为什么不进行一次操作完成呢?
我的尝试一:直接将50组数据定义在程序(如Order_Buffer[50][4096])中进行操作,这样写完一组只要进行相应标志位的更改便可以继续进行下一组数据写入。想法虽好,但是实际操作中发现程序无法对如此大的数据进行处理(芯片的空间不足)。要么刚换主芯片,选取容量大一点,要么数据内容从外部分批读入然后分批写入。
我的尝试二:将50组数据以txt文档的形式保存在U盘中,这样就可以通过U盘读取数据进而写入到W25Q64中。首先读取U盘的.txt文件并通过串口打印显示查看读取的结果是否正确,当然一组数据显示是没有问题,但是50组数据同时传输过来显示乱码比较严重(由于杜洋开发板U盘读取电路与JTAG电路引脚冲突,无法运行在线调试程序)。于是我该用正点原子407开发板的USB HOST的相关程序进行调试,发现数据完整性无法保持,之后我由于时间关系没有进一步去进行程序改进以及原因查明。
2、主程序对W25Q数据读出后为什么没有直接进行写入,而是要在while(1)的循环中不停写入
2、新思路-CI1102(80词条)/CI1103(300词条)附说明文档
特点:
单芯片集成语音识别与CPU;
说明:
CI1102 是一颗专用于语音处理的人工智能芯片,可广泛应用于家电、家居、照明、音箱、玩具、穿戴设备、汽车等产品领域,实现语音交互及控制。CI1102 内置自主研发的脑神经网络处理器 BNPU,支持本地语音识别,和内置的CPU 核结合可以做各类智能语音方案应用。
CI1102内置高性能低功耗Audio Codec 模块和硬件音频处理模块,可以外接麦克风实现单芯片远场降噪或者回声消除等功能。同时该芯片还集成多路 UART、I2C、SPI、PWM、GPIO等外围控制接口,可以开发低成本的单芯片智 能语音离线识别方案。
芯片单价:
15左右(1个);13左右(100个·)
参考文献与下载
本文 原文 link.
芯片数据资料:
W25Q128 link.
SYN6288 link.
LD3320 link.
原理图及PCB:link.
最终程序:link.
Original: https://blog.csdn.net/m0_48885067/article/details/121175212
Author: 在梦里-119
Title: 基于STM32的有限词条语音识别与对话模块
相关阅读1
Title: 天鹰算法AO
3.1
第一种方法是垂直弯腰的高空翱翔,用于捕猎飞行中的鸟类,在这种情况下,天鹰座上升到地面的高处。一旦探索猎物,鹰隼就会进入一个长而低的角度滑翔,随着翅膀的进一步靠近,速度会提高。为了这种方法的成功,鹰隼需要一个高于猎物的高度特征。在开始前,翅膀和尾巴展开,双脚向前推以抓住猎物,看起来就像一阵雷声
第二种方法是等高线飞行和短滑翔攻击,被阿奎拉认为是最常用的方法,阿奎拉在地面上以较低的高度上升。然后,无论猎物是在奔跑还是在飞翔,都会紧紧地追踪猎物。这种方法有利于捕猎地松鼠、繁殖松鸡或海鸟
第三种方法是低空飞行和慢速下降攻击。在这种情况下,阿奎拉下降到地面上,然后逐渐向猎物发起攻击。鹰隼选择猎物,落在猎物的脖子和背上,试图穿透猎物。这种狩猎方法适用于行动缓慢的猎物,如响尾蛇、刺猬、狐狸和乌龟,或任何没有逃跑反应的猎物
第四种方法是行走和抓取猎物,在这种方法中,鹰隼在陆地上行走并试图拉住猎物。它用于将大型猎物(如鹿或羊)的幼仔拉出覆盖区域
总之,阿奎拉是最聪明、最熟练的猎人之一,可能仅次于人类。提出的AO算法的主要灵感来自上述方法。以下小节描述了如何在AO中对这些过程进行建模。
3.2解决方案初始化
在AO中,它是一种基于群的方法,优化规则从等式(1)中所示的候选解(X)的总体开始,该候选解在给定问题的上界(UB)和下界(LB)之间随机生成。到目前为止,获得的最佳解在每次迭代中被确定为似近最优解。
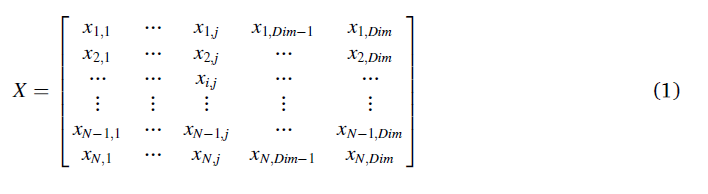
其中X表示通过使用公式(2)随机生成的当前候选解的集合,席表示到第i解的判定值(位置),N是候选解的总数,可以表示问题的维度。
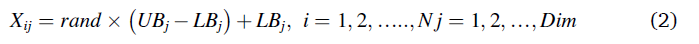
其中rand是一个随机数,LBj表示给定问题的第j个下界,UBj表示给定问题的第j个上界。
3.3 AO的数学模型
所提出的AO算法模拟了Aquila在狩猎过程中的行为,其中显示了狩猎的每个步骤的动作。因此,提出的AO算法的优化过程用四种方法表示;通过垂直弯腰的高空翱翔选择搜索空间,通过短滑翔攻击的等高线飞行在发散搜索空间内探索,通过慢速下降攻击的低空飞行在收敛搜索空间内开拓,以及通过步行和抓取猎物进行俯冲。基于此条件,AO算法可以使用不同的行为从探索步骤转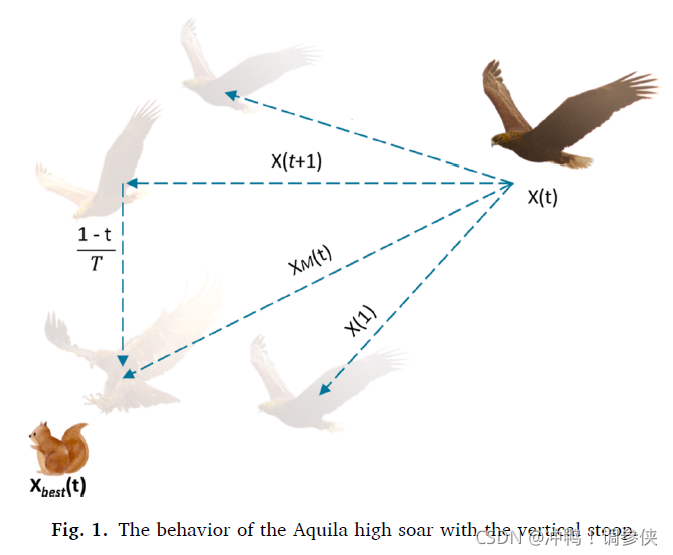
移到开发步骤⩽(23)∗T。探索的步伐将是激动人心的;否则,将很好地执行开发步骤。
我们将Aquila行为建模为一种数学优化范式,并在特定约束条件下确定最佳解决方案。AO的数学模型如下所示。
3.3.1. 步骤1:扩大勘探(X1)
在第一种方法里,阿奎拉识别出猎物区域然后通过垂直弯腰高飞来确认最佳猎物区域。在这个方法中,AO让来自高空的探险家们四处飞翔,以确定猎物所在的搜索空间区域。图1显示了阿奎拉峰垂直俯冲时的行为。这种行为在数学上如式(3)所示。
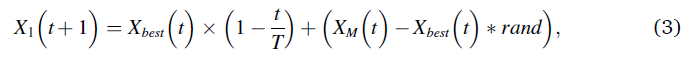
其中,X1(t+1)是由第一搜索方法(X1)生成的t的下一次迭代的解。Xbest(t)是在tth迭代之前获得的最佳解,这反映了猎物的近似位置。该方程用于通过迭代次数控制扩展搜索(探索)。XM(t)表示在第tth次迭代时连接的当前解的平均值,该平均值使用公式(4)计算。rand是介于0和1之间的随机值。t和t分别表示当前迭代和最大迭代次数。
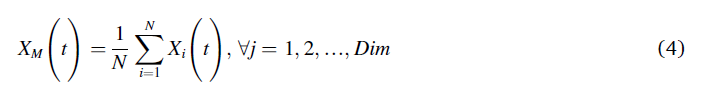
其中,dim是指问题的维度,N是指候选解或者或是群的大小。
3.3.2 狭域勘测
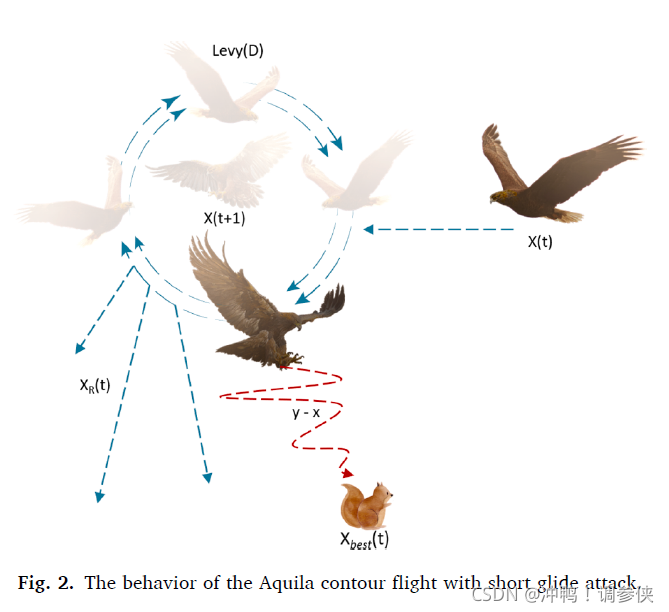
在第二阶段,当猎物被阿拉奎俯瞰发现后,阿拉奎开始围绕猎物进行捕猎,准备好候选区域然后进行攻击。这种方法称为短滑翔攻击的等高线飞行。在这里,AO狭隘地探索目标猎物的选定区域,为攻击做准备。图2显示了短滑翔攻击下阿奎拉等高线飞行的行为。这种行为在数学上如式(5)所示。
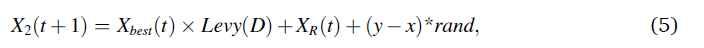
其中X2(t+1)是由第二搜索方法(X2)生成的t的下一次迭代的解。D是维度空间,Levy(D)是Levy飞行分布函数,使用公式(6)计算。XR(t)是在第i次迭代时在[1 N]范围内获得的随机解。

s是一个常量0.01,u和μ是0到1的任意数字,δ是使用(7)式计算的公式。
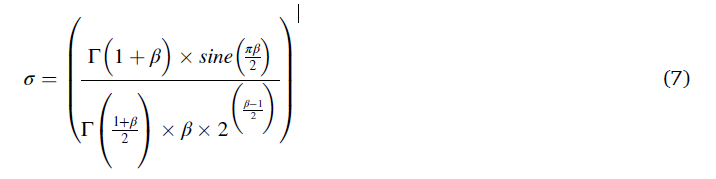
β是常量值1.5,y和x 用来代表搜索的区域形状。计算的过程如下:

r1取1到20之间的值,用于固定的搜索周期数,U是固定为0.00565的小值。D1是从1到搜索空间长度(Dim)的整数,ω是固定为0.005的小值。图3显示了螺旋形AO的行为。
3.3.3. 步骤3:扩展开发(X3)
阿奎拉已经准备好着陆和攻击,阿奎拉垂直下降并进行初步攻击,以发现猎物的反应。这种方法称为低空慢降攻击。在这里,AO利用目标的选定区域接近猎物并进行攻击。图4显示了阿奎拉低空飞行和缓慢下降攻击的行为。这种行为在数学上如式(13)所示。
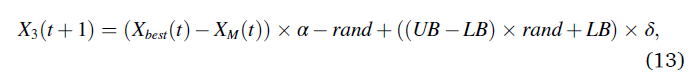 由第三个搜索方法(X3)生成。Xbest(t)表示第i次迭代前猎物的近似位置(获得的最佳解),XM(t)表示第tth次迭代时当前解的平均值,该平均值使用公式(4)计算。rand是介于0和1之间的随机值。α和δ是本文中确定为较小值(0.1)的开采调整参数。LB表示给定问题的下界,UB表示给定问题的上界。
由第三个搜索方法(X3)生成。Xbest(t)表示第i次迭代前猎物的近似位置(获得的最佳解),XM(t)表示第tth次迭代时当前解的平均值,该平均值使用公式(4)计算。rand是介于0和1之间的随机值。α和δ是本文中确定为较小值(0.1)的开采调整参数。LB表示给定问题的下界,UB表示给定问题的上界。
3.3.4缩小范围
在第四种方法(X4)中,当阿奎拉接近猎物时,阿奎拉根据其随机运动在陆地上攻击猎物。这种方法称为"行走并抓住猎物"。最后,AO在最后一个位置攻击猎物。图5显示了阿奎拉行走和抓取猎物的行为。这种行为在数学上表现为
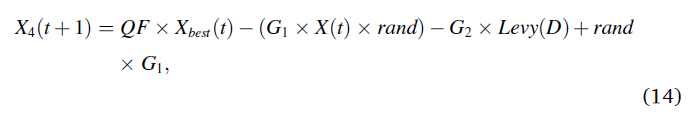
其中X4(t+1)是由第四种搜索方法(X4)生成的t的下一次迭代的解。QF表示用于平衡搜索策略的质量函数,其使用公式(15)计算。G1表示在私奔期间用于跟踪猎物的AO的各种运动,这是使用公式(16)生成的。G2呈现从2到0的递减值,这表示AO的飞行斜率,AO用于在从第一个位置(1)到最后一个位置(t)的私奔过程中跟踪猎物,这是使用公式(17)生成的。X(t)是第tth次迭代的当前解
分别为最大迭代次数。Levy(D)是使用公式(6)计算的Levy飞行分布函数。图6显示了质量函数(QF)、G1和G2对AO行为的影响。
3.4AO算法伪代码
综上所述,在AO中,优化通过生成一组随机预定义的候选解决方案(称为总体)开始改进过程。通过重复轨迹,AO的搜索策略探索接近最优解或最佳解的合理位置。每个解根据AO的优化过程获得的最佳解更新其位置。为了强调AO搜索策略(即勘探和开发)之间的平衡,提供了四种不同的勘探和开发搜索策略(即扩大勘探、缩小勘探、扩大开采和缩小开采)。最后,当满足结束条件时,AO的搜索过程终止。AO的伪代码在算法1中有详细说明。
3.5 AO算法的复杂性
一般而言,AO算法的复杂性依赖于3个原则:解的初始化,适应函数的计算和解的更新。N是解的数量,O(N)是求解初始化的复杂度。计算接的复杂度是O(TN)+O(TNDim),复杂度又寻找最佳位置和更新解组成,整个迭代次数为T,解决问题的维度成为Dim。综上,所提算法的复杂度为O(N(T*D+1))。
4.实验结果及讨论
Original: https://blog.csdn.net/weixin_44738378/article/details/121146321
Author: 冲鸭!调参侠
Title: 天鹰算法AO
相关阅读2
Title: axios的兼容性问题
1、axios在PC端浏览器的兼容性问题
axios支持IE8+,但原理是基于promise之上实现的,因此会存在不兼容IE的问题。
trident内核的浏览器下会报:vuex requires a Promise polyfill in this browser
IE9下 axios 报错问题
解决方案:
(1)、首先安装 babel-polyfill,来解决IE不支持 promise对象的问题
npm install babel-polyfill -s
(2)、安装成功以后需要在 main.js 中引入 babel-polyfill
import 'babel-polyfill'
一般会配置 webpack.base.config.js 中 entry
module.exports = {
context: path.resolve(__dirname, '../'),
entry: {
app: ["babel-polyfill", "./src/main.js"]
// app: './src/main.js'
},
}
2、axios在安卓低版本兼容性处理
在较低版本的安卓手机中发现发现封装的axios请求无效,主要原因还是低版本的安卓手机无法使用promise
注意:安卓4.3以下的手机不支持axios的使用,无法使用promise,加上 polyfill就可以了。
解决方案: (1)、项目中安装 es6-promise
npm install es6-promise -s
(2)、引入 es6-promise
import promise from 'es6-promise'
(3)、注册 es6-promise (一定要在axios之前注册)
// 注意: es6-promise 一定要在 axios 请求 之前注册
promise.polyfill()
或者
require('es6-promise').polyfill();
Browser cdn方式引入qs库使用
普通html页面使用axios post提价数据需要处理提交的数据,一般用到qs库
今天刚好用到,记录下来
原创文章请随便转载。愿和大家分享,并且一起进步。-- 江 coder
Original: https://www.cnblogs.com/jiangxiaobo/p/14108150.html
Author: jiangxiaobo
Title: axios的兼容性问题
相关阅读3
Title: 一句话生成视频(python)
一句话生成视频(python)
最近想运营个抖音号, 但是制作视频是个很麻烦的事情.
所以就想到运营个名言警句和新闻的抖音号.
- 因为名言警句和新闻是可以爬的, 这样自动生成视频.

csdn发不了视频, 大概就是这样的,
1.文字自动生成图片居中,
2.自动把文字读出来生成语音,
3.把图片和文字合成mp4文件;
下面是抖音号, 可以点开url看下视频效果:
url
7.66 jCH:/ 取得成就时坚持不懈,要比遭到失败时顽强不屈更重要。——拉罗什夫科 https://v.douyin.com/FyND8co/ 复制此链接,打开Dou音搜索,直接观看视频!
; 1.生成图片, 文字居中
sum_width = 1125
sum_height = 2436
def create_pic(number, text):
text = handle_text(text)
if len(text) > 0:
im = Image.new('RGB', (sum_width, sum_height), (255, 255, 255))
font = ImageFont.truetype(os.path.join("fonts", "msyh.ttf"), 150)
dr = ImageDraw.Draw(im)
w, h = dr.textsize(text, font)
dr.text(((sum_width - w) / 2, (sum_height - h) / 2), text, font=font, fill='#000000')
im.save('pic/' + number + '.png')
def handle_text(text):
try:
result = ''
array = cut(text, 6)
for v in array:
result = result + v + '\n'
array = result.split('。')
result = array[0] + '。\n' + array[1]
return result
except:
return ''
def cut(obj, sec):
return [obj[i:i+sec] for i in range(0,len(obj),sec)]
2.文字生成语音
使用最niubi最像人的ai合成语音库(azure TTS API)
github
def create_audio(number, text):
cmd = 'python3 -m aspeak -t "{}" -l zh-CN -o audios/{}.mp3 --mp3'.format(text, number)
os.system(cmd)
3.图片+语音合成视频
import cv2
from moviepy.editor import VideoFileClip, AudioFileClip
from mutagen.mp3 import MP3
def create_video(number):
pic_path = ('pic/' + number + '.png')
audio_path = ('audios/' + number + '.mp3')
video_path = ('videos/' + number + '.mp4')
pic_frame = cv2.imread(pic_path)
img_size = (sum_width, sum_height)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
videoWriter = cv2.VideoWriter(video_path, fourcc, 1, img_size)
audio_time_count = get_audio_time_count(number)
print('audio time: ', audio_time_count)
for i in range(audio_time_count):
videoWriter.write(pic_frame)
videoWriter.release()
video = VideoFileClip(video_path)
video_clip = video.set_audio(AudioFileClip(audio_path))
video_clip.write_videofile(video_path)
def get_audio_time_count(number):
audio = MP3('audios/' + number + '.mp3')
time_count = int(audio.info.length)
return time_count
想法是美好的, 实际上上传了十多个视频等了2天并没有带来太多观看😅
下次尝试下其他的视频类型. (比如其他知识类的视频)
如果有流量后期把app自动上传也做了, 没流量就不白费功夫了.
Original: https://blog.csdn.net/pureszgd/article/details/124693925
Author: 清醒思考
Title: 一句话生成视频(python)