
python print输出字符串报错
原创
文章标签 python 字符串 ico 文章分类 Python 后端开发
©著作权归作者所有:来自51CTO博客作者CorwinPC的原创作品,请联系作者获取转载授权,否则将追究法律责任
利用print函数打印字符串报以下错误,原因是因为字符串里面包含Unicode字符。
Traceback (most recent call last):
UnicodeEncodeError: 'gbk' codec can't encode character '\U0001f6d2' in position 130: illegal multibyte sequence
解决办法:
在文件中加入以下代码即可解决
import ioimport syssys.stdout = io.TextIOWrapper(sys.stdout.buffer, errors='replace', line_buffering=True)
- 赞
- 收藏
- 评论
- *举报
Original: https://blog.51cto.com/YangPC/5483135
Author: CorwinPC
Title: python print输出字符串报错
相关阅读1
Title: 不会吧,学过爬虫连这个网站都爬不了?那Python岂不是白学了
本文内容
- 系统分析目标网页
- html标签数据解析方法
- 海量图片数据一键保存
环境介绍
- python 3.8
- pycharm
模块使用
- requests >>> pip install requests
- parsel >>> pip install parsel
- time 时间模块 记录运行时间
通用爬虫
导入模块
import requests # 数据请求模块 第三方模块 pip install requests
import parsel # 数据解析模块 第三方模块 pip install parsel
import re # 正则表达式模块
请求数据
url = f'https://fabiaoqing.com/biaoqing/lists/page/{page}html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
response 对象 200状态码 表示请求成功
解析数据
解析速度 bs4 解析速度会慢一些,如果你想要对于字符串数据内容,直接取值,只能正则表达式
selector = parsel.Selector(response.text) # 把获取下来html字符串数据内容 转成 selector 对象
title_list = selector.css('.ui.image.lazy::attr(title)').getall()
img_list = selector.css('.ui.image.lazy::attr(data-original)').getall()
把获取下来的这两个列表 提取里面元素 一一提取出来
提取列表元素 for循环 遍历
for title, img_url in zip(title_list, img_list):
title = re.sub(r'[\/:*?"<>|\n]', '_', title)
# 名字太长 报错
img_name = img_url.split('.')[-1] # 通过split() 字符串分割的方法 根据列表索引位置取值
img_content = requests.get(url=img_url).content # 获取图片的二进制数据内容
保存数据
with open('img\\' + title + '.' + img_name, mode='wb') as f:
f.write(img_content)
print(title)
共耗时:61秒
; 多线程爬虫
发送求情
def get_response(html_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
return response
获取图片url地址,以及图片名字
def get_img_info(html_url):
response = get_response(html_url)
selector = parsel.Selector(response.text) # 把获取下来html字符串数据内容 转成 selector 对象
title_list = selector.css('.ui.image.lazy::attr(title)').getall()
img_list = selector.css('.ui.image.lazy::attr(data-original)').getall()
zip_data = zip(title_list, img_list)
return zip_data
保存数据
def save(title, img_url):
title = re.sub(r'[\/:*?"<>|\n]', '_', title)
# 名字太长 报错
img_name = img_url.split('.')[-1] # 通过split() 字符串分割的方法 根据列表索引位置取值
img_content = requests.get(url=img_url).content # 获取图片的二进制数据内容
with open('img\\' + title + '.' + img_name, mode='wb') as f:
f.write(img_content)
print(title)
主函数
def main(html_url):
zip_data = get_img_info(html_url)
for title, img_url in zip_data:
save(title, img_url)
入口
if __name__ == '__main__':
start_time = time.time()
exe = concurrent.futures.ThreadPoolExecutor(max_workers=10)
for page in range(1, 11):
url = f'https://fabiaoqing.com/biaoqing/lists/page/{page}html'
exe.submit(main, url)
exe.shutdown()
end_time = time.time()
use_time = int(end_time - start_time)
print('程序耗时: ', use_time)
共耗时:19秒
Original: https://www.cnblogs.com/qshhl/p/15493858.html
Author: 松鼠爱吃饼干
Title: 不会吧,学过爬虫连这个网站都爬不了?那Python岂不是白学了
相关阅读2
Title: python 代码命名规范
1. 常量命名
全部采用全大写,多个单词使用下划线隔开
MAX_NUM = 100
CONNECTION_TIMEOUT = 1000
2. 变量命名
变量名尽量小写, 多个单词用下划线隔开
if __name__ == '__main__':
file_count = 0
file_name = ''
3. 函数命名
- 函数名一律小写,多个单词用下划线隔开
def eat():
pass
def eat_lunch():
pass
- 私有函数前加一个下划线 _
class Person():
def _private_func():
pass
4. 类命名
类名使用驼峰(CamelCase)命名法,看字面意思就能理解,即 使用不同单词的首字母大写命名。(私有类以下划线开头)
class Person():
pass
class MalePerson(Person): # 驼峰命名法
pass
class _PrivateSex(Person):
pass
5. 模块命名
模块尽可能使用小写来命名,单词过多情况推荐使用下划线命名,而单词数量不多情况下尽量少时用下划线。
- 推荐的模块命名
import requests
import expected_conditions
- 不推荐的模块命名
import Beautifulname
补充:如果对于对象命名感到烦恼,可以参见这篇博客 工程实践:给函数取一个"好"的名字
Original: https://blog.51cto.com/coderusher/5510485
Author: Coderusher
Title: python 代码命名规范
相关阅读3
Title: Python+Selenium基础篇之6-元素定位方法
WebDriver 提供了 8 种元素定位方法,在 Python 中,对应的方法如下:
id 定位 → find_element_by_id()
name 定位 → find_element_by_name()
tag 定位 → find_element_by_tag_name()
class 定位 → find_element_by_class_name()
link_text → find_element_by_link_text()
partial link 定位 → find_element_by_partial_link_text()
XPath 定位 → find_element_by_xpath()
CSS_selector 定位 → find_element_by_css_selector()
如果把页面上的元素看作人,那么在现实世界中如何找到某人呢?
首先,可以通过人本身的属性进行查找,例如他的姓名、手机号、身份证号等,这些都是用于区别于他人的属性。在 Web 页面上的元素也有本身的属性,例如,id、name、class name、tag name 等。其次,可以通过位置进行查找,例如,x 国、x 市、x 路、x 号。XPath 和 CSS 可以通过标签层级关系的方式来查找元素。最后,还可以借助相关人的属性来找到某人。例如,我没有小明的联系方式,但是我有他爸爸的手机号,那么通过他爸爸的手机号最终也可以找到小明。XPath 和 CSS 同样提供了相似的定位策略来查找元素。
属性定位
HTML 规定, id 在 HTML 文档中必须是唯一的,这类似于我国公民的身份证号,具有唯一性。WebDriver 提供的 id 定位方法是通过元素的 id 来查找元素的。
HTML 规定,name 用来指定元素的名称,因此它的作用更像是人的姓名。
HTML 规定,class 用来指定元素的类名,其用法与 id、name 类似。
HTML 通过 tag 来定义不同页面的元素。例如, ​<input>​一般用来定义输入框, ​<a>​</a>标签用来定义超链接等。不过,因为一个标签往往用来定义一类功能,所以通过标签识别单个元素的概率很低。例如,我们打开任意一个页面,查看前端代码时都会发现大量的 ​<div>​</div>、 ​<input>​、 ​<a>​</a>等标签。
link 定位与前面介绍的几种定位方法有所不同,它专门用来定位文本链接。百度输入框上面的几个文字链接的代码如下。

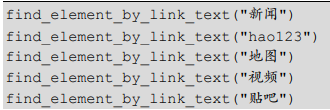
partial link 定位是对 link 定位的一种补充,有些文字链接比较长,这个时候我们可以取文字链接的部分文字进行定位,只要这部分文字可以唯一地标识这个链接即可。
在理想状态下,一个页面当中每个元素都有唯一的 id 值和 name 值,可以通过它们来查找元素。但在实际项目中并非想象得这般美好,有时候一个元素没有 id 值和 name 值,或者页面上有多个元素属性是相同的;又或者 id 值是随机变化的,在这种情况下,如何定位元素呢?
XPath 定位
绝对路径定位
如果把元素看作人,假设这个人没有任何属性特征(手机号、姓名、身份证号),但这个人一定存在于某个地理位置,如 xx 省 xx 市 xx 区 xx 路 xx 号。对于页面上的元素而言,也会有这样一个绝对地址。

利用元素属性定位
除使用绝对路径外,XPath 还可以使用元素的属性值来定位。

//input 表示当前页面某个 input 标签,[@id='kw'] 表示这个元素的 id 值是 kw。如果不想指定标签名,那么可以用星号(*)代替。当然,使用 XPath 不局限于 id、name和 class 这三个属性值,元素的任意属性都可以使用,只要它能唯一标识一个元素。
层级与属性结合
如果一个元素本身没有可以唯一标识这个元素的属性值,那么我们可以查找其上一级元素。如果它的上一级元素有可以唯一标识属性的值,就可以拿来使用。

假如百度输入框没有可利用的属性值,那么可以查找它的上一级属性。例如,小明刚出生的时候没有名字,也没有身份证号,那么亲朋好友来找小明时可以先找到小明的爸爸,因为他爸爸是有很多属性特征的。找到小明的爸爸后,就可以找到小明了。通过 XPath 描述如下: ​find_element_by_xpath("//span[@class='bg s_ipt_wr']/input")​ span[@class='s_ipt_wr'] 通过 class 定位到父元素,后面的/input 表示父元素下面的子元素。如果父元素没有可利用的属性值,那么可以继续向上查找父元素的父元素。
使用逻辑运算符
如果一个属性不能唯一区分一个元素,那么我们可以使用逻辑运算符连接多个属性来查找元素: ​find_element_by_xpath("//input[@id='kw' and @class='s_ipt']")​
使用 contains 方法
contains 方法用于匹配一个属性中包含的字符串。例如,span 标签的 class 属性为"bgs_ipt_wr": ​find_element_by_xpath("//span[contains(@calss,'s_ipt_wr')]/input")​,contains 方法只取了 class 属性中的"s_ipt_wr"部分。
使用 text()方法
text()方法用于匹配显示文本信息。例如,前面通过 link text 定位的文字链接: ​find_element_by_xpath("//a[text(),'新闻')]")​。当然,contains 和 text()也可以配合使用: ​find_element_by_xpath("//a[contains(text(),'一个很长的')]")​。
CSS 定位
CSS 选择器可以较为灵活地选择控件的任意属性,一般情况下,CSS 定位速度比 XPath定位速度快。CSS 选择器的更多用法可以查看 W3CSchool 网站中的 CSS 选择器参考手册(http://www.w3school.com.cn/cssref/css_selectors.asp)。
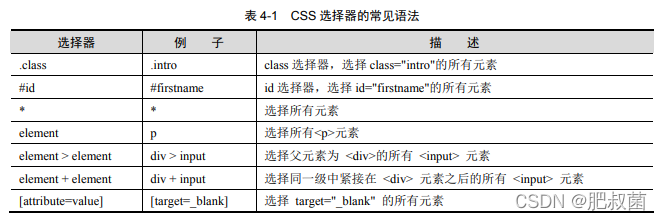
通过 class 定位
find_element_by_css_selector()方法用于在 CSS 中定位元素,点号(.)表示通过 class来定位元素。
find_element_by_css_selector(".s_ipt")find_element_by_css_selector(".s_btn")
通过 id 定位
井号(#)表示通过 id 来定位元素。
find_element_by_css_selector("#kw")find_element_by_css_selector("#su")
通过标签名定位
CSS 中,用标签名定位元素时不需要任何符号标识,直接使用标签名即可: ​find_element_by_css_selector("input")​。
通过标签层级关系定位
​find_element_by_css_selector("span > input")​这种写法表示有父元素,父元素的标签名为 span。查找 span 中所有标签名为 input 的子元素。
通过属性定位
在 CSS 中可以使用元素的任意属性定位,只要这些属性可以唯一标识这个元素。对属性值来说,可以加引号,也可以不加,注意和整个字符串的引号进行区分。
find_element_by_css_selector("[autocomplete=off]")find_element_by_css_selector("[name='kw']")find_element_by_css_selector('[type="submit"]')
组合定位
我们可以把上面的定位策略组合起来使用,这就大大加强了定位元素的唯一性。我们要定位的这个元素标签名为 input,这个元素的 class 属性为 s_ipt;并且它有一个父元素,标签名为 span。它的父元素还有父元素,标签名为 form,class 属性为 fm。我们要找的就是必须满足这些条件的一个元素。
find_element_by_css_selector("form.fm > span > input.s_ipt")find_element_by_css_selector("form#form > span > input#kw")
更多定位用法
查找 class 属性包含"s_ipt_wr"字符串的元素。 ​find_element_by_css_selector("[class*=s_ipt_wr]")​ 查找 class 属性以"bg"字符串开头的元素。 ​find_element_by_css_selector("[class^=bg]")​ 查找 class 属性以"wrap"字符串结尾的元素。 ​find_element_by_css_selector("[class$=wrap]")​ 查找 form 标签下面第 2 个 input 标签的元素。 ​find_element_by_css_selector("form > input:nth-child(2)")​
用 By 定位元素
针对前面介绍的 8 种定位方法,WebDriver 还提供了另外一套写法,即统一调用find_element()方法,通过 By 来声明定位,并且传入对应定位方法的定位参数,具体如下。find_element()方法只用于定位元素,它需要两个参数。第一个参数是定位的类型,由By 提供( ​from selenium.webdriver.common.by import By​);第二个参数是定位的值。

本博客摘抄自《Selenium3自动化测试实战——基于Python语言》,详细内容请购买该书进行学习
Original: https://blog.51cto.com/feishujun/5513653
Author: mb62de8abf75c00
Title: Python+Selenium基础篇之6-元素定位方法