
QT实现语音识别功能的相关步骤如下(附程序代码):
1.阿里云注册账号,登录智能语音交互平台:创建新项目,此时或获得AppKey,进入智能语音交互总览一页,右上方会看见一个Access Token,然后点击头像进入accessKey管理页面,你会看到accessKeyID和accessKey secret.记住这四个参数,后面会用的到的
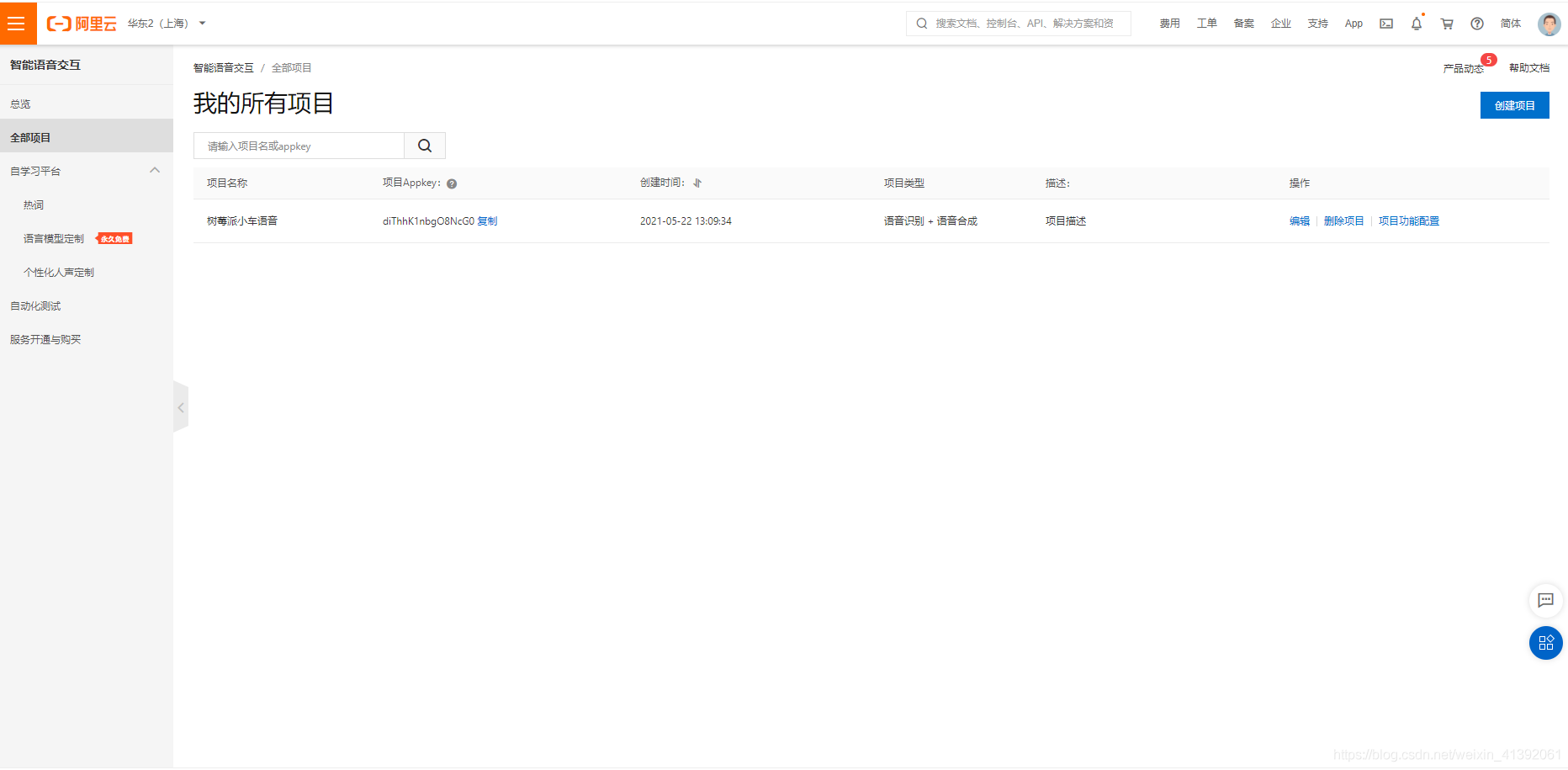
2.找到帮助文档中一句话识别下的下载C++SDK的文件,下载下来

3.往下翻找到编译环境的搭建步骤:
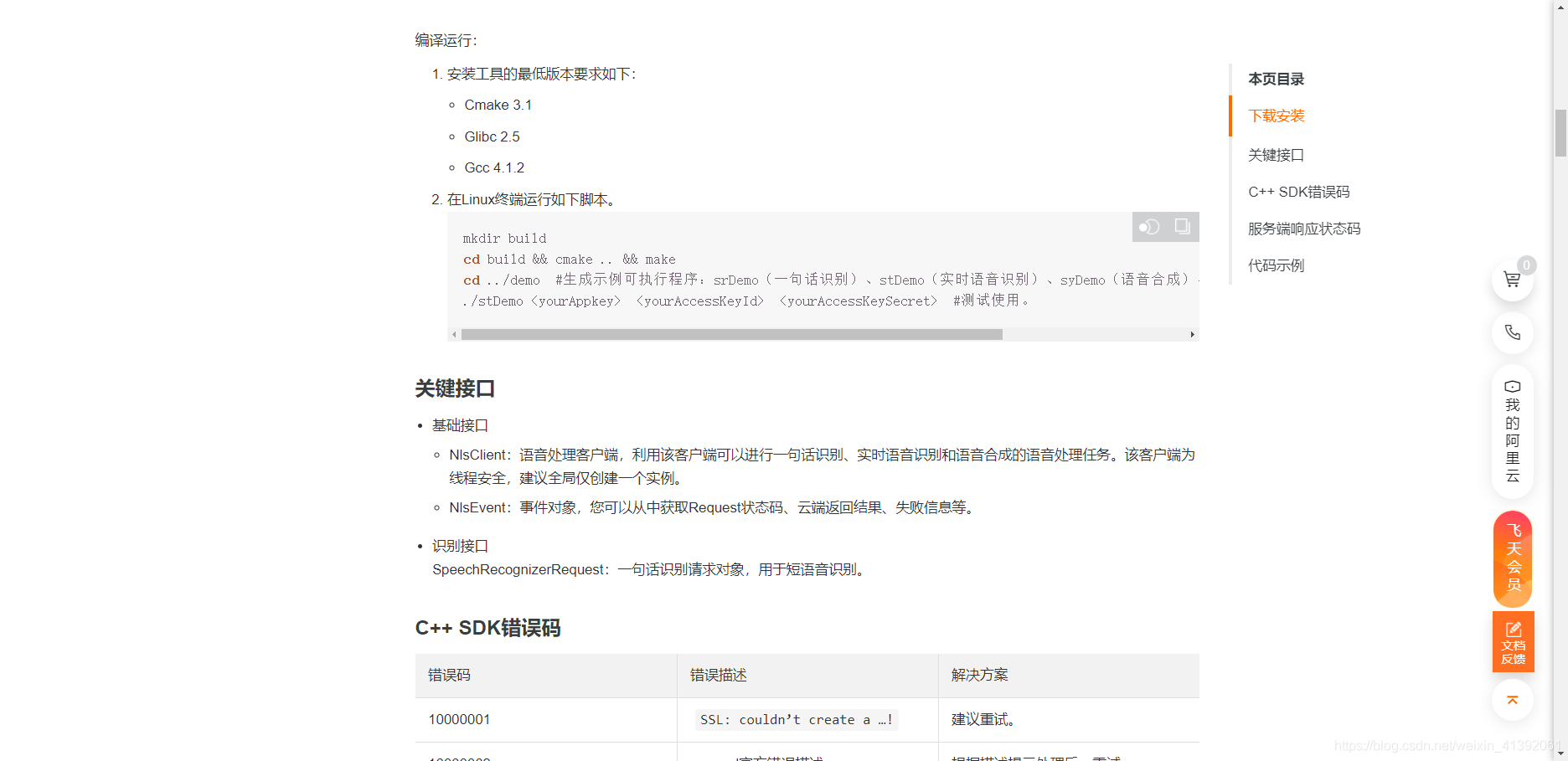
环境配置好之后就可以开始进行编程了
4.附上详细的代码(具体步骤自己看程序理解)
详细代码附上,压缩文件格式的,亲测可行:
5.
QT += core gui multimedia
INCLUDEPATH += /home/wangzhen/IOTEK/Qt/NlsSdkCpp3.X/include
LIBS += -L/home/wangzhen/IOTEK/Qt/NlsSdkCpp3.X/lib -lalibabacloud-idst-common -lalibabacloud-idst-speech
6.myrecord.h
#ifndef MYRECORD_H
#define MYRECORD_H
#include <qwidget>
#include<qaudioinput>//实现录音功能
#include<qaudioformat>//设置录音格式
#include<qaudiodeviceinfo>//设置录音设备信息
#include<qfile>
namespace Ui {
class MyRecord;
}
struct WAVHEARD
{
//RIFF头
char RiffName[4];
unsigned int nRiffLength;
//数据类型标识符
char WavName[4];
//格式块中的块头
char FmtName[4];
unsigned int nFmtLength;
//格式具体数据
unsigned short nAudioFormat;
unsigned short nChannleNumber;
unsigned int nSampleRate;
unsigned int nBytesPerSecond;
unsigned short nBytesPerSample;
unsigned short nBitsPerSample;
//音频数据信息
char DataName[4];
unsigned int nDataLength;
};
class MyRecord : public QWidget
{
Q_OBJECT
public:
explicit MyRecord(QWidget *parent = nullptr);
~MyRecord();
void initAudio();
void rawTowav();
void loadConfig();
public slots:
void recvMsg(QString msg);
private slots:
void on_start_pb_clicked();
void on_stop_pb_clicked();
private:
Ui::MyRecord *ui;
QAudioInput *m_pAudioInput;
QFile m_rawFile;
QFile m_wavFile;
QString m_strAppkey;
QString m_strAKID;
QString m_strAKSecret;
QString m_strToken;
};
#endif // MYRECORD_H
</qfile></qaudiodeviceinfo></qaudioformat></qaudioinput></qwidget>
7.result.h
#ifndef RESULT_H
#define RESULT_H
#include <qwidget>
class Result : public QWidget
{
Q_OBJECT
public:
explicit Result(QWidget *parent = nullptr);
void send(std::string msg);
static Result& getInstance();
signals:
void sendMsg(QString msg);
public slots:
};
#endif // RESULT_H
</qwidget>
8.speechRecognizerDemo.h
#ifndef SPEECH_H
#define SPEECH_H
/*
* Copyright 2015 Alibaba Group Holding Limited
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the Licenise for the specific language governing permissions and
* limitations under the License.
*/
#include <string.h>
#include <unistd.h>
#include <pthread.h>
#include <stdlib.h>
#include <ctime>
#include <string>
#include <iostream>
#include <vector>
#include <fstream>
#include <sys time.h>
#include "nlsClient.h"
#include "nlsEvent.h"
#include "speechRecognizerRequest.h"
#include "nlsCommonSdk/Token.h"
#define FRAME_SIZE 3200
#define SAMPLE_RATE 16000
using namespace AlibabaNlsCommon;
using AlibabaNls::NlsClient;
using AlibabaNls::NlsEvent;
using AlibabaNls::LogDebug;
using AlibabaNls::LogInfo;
using AlibabaNls::LogError;
using AlibabaNls::SpeechRecognizerRequest;
// 自定义线程参数
struct ParamStruct {
std::string fileName;
std::string appkey;
std::string token;
};
// 自定义事件回调参数
struct ParamCallBack {
int userId;
char userInfo[8];
};
//全局维护一个服务鉴权token和其对应的有效期时间戳,
//每次调用服务之前,首先判断token是否已经过期,
//如果已经过期,则根据AccessKey ID和AccessKey Secret重新生成一个token,并更新这个全局的token和其有效期时间戳。
//注意:不要每次调用服务之前都重新生成新token,只需在token即将过期时重新生成即可。所有的服务并发可共用一个token。
#if 0
// 根据AccessKey ID和AccessKey Secret重新生成一个token,并获取其有效期时间戳
// token使用规则:在有效期到期前可以一直使用,且可以多个进程/多个线程/多个应用使用均可,建议在有效期快到期时提起申请新的token
int generateToken(std::string akId, std::string akSecret, std::string* token, long* expireTime) {
NlsToken nlsTokenRequest;
nlsTokenRequest.setAccessKeyId(akId);
nlsTokenRequest.setKeySecret(akSecret);
if (-1 == nlsTokenRequest.applyNlsToken()) {
// 获取失败原因
printf("generateToken Failed: %s\n", nlsTokenRequest.getErrorMsg());
return -1;
}
*token = nlsTokenRequest.getToken();
*expireTime = nlsTokenRequest.getExpireTime();
return 0;
}
#endif
//@brief 获取sendAudio发送延时时间
//@param dataSize 待发送数据大小
//@param sampleRate 采样率 16k/8K
//@param compressRate 数据压缩率,例如压缩比为10:1的16k opus编码,此时为10;非压缩数据则为1
//@return 返回sendAudio之后需要sleep的时间
//@note 对于8k pcm 编码数据, 16位采样,建议每发送1600字节 sleep 100 ms.
// 对于16k pcm 编码数据, 16位采样,建议每发送3200字节 sleep 100 ms.
// 对于其它编码格式的数据, 用户根据压缩比, 自行估算, 比如压缩比为10:1的 16k opus,
// 需要每发送3200/10=320 sleep 100ms.
unsigned int getSendAudioSleepTime(int dataSize, int sampleRate, int compressRate);
//@brief 调用start(), 成功与云端建立连接, sdk内部线程上报started事件
//@param cbEvent 回调事件结构, 详见nlsEvent.h
//@param cbParam 回调自定义参数,默认为NULL, 可以根据需求自定义参数
void OnRecognitionStarted(NlsEvent* cbEvent, void* cbParam);
//@brief 设置允许返回中间结果参数, sdk在接收到云端返回到中间结果时, sdk内部线程上报ResultChanged事件
//@param cbEvent 回调事件结构, 详见nlsEvent.h
//@param cbParam 回调自定义参数,默认为NULL, 可以根据需求自定义参数
void OnRecognitionResultChanged(NlsEvent* cbEvent, void* cbParam);
//@brief sdk在接收到云端返回识别结束消息时, sdk内部线程上报Completed事件
//@note 上报Completed事件之后, SDK内部会关闭识别连接通道. 此时调用sendAudio会返回-1, 请停止发送.
//@param cbEvent 回调事件结构, 详见nlsEvent.h
//@param cbParam 回调自定义参数,默认为NULL, 可以根据需求自定义参数
void OnRecognitionCompleted(NlsEvent* cbEvent, void* cbParam);
void OnRecognitionTaskFailed(NlsEvent* cbEvent, void* cbParam);
void* pthreadFunction(void* arg);
//线程循环识别
//需要调整count值和每次要识别的文件,Demo中默认每次识别一个文件
void* multiRecognize(void* arg);
// 识别单个音频数据
int speechRecognizerFile();
//识别多个音频数据;
//sdk多线程指一个音频数据源对应一个线程, 非一个音频数据对应多个线程.
//示例代码为同时开启2个线程识别2个文件;
//免费用户并发连接不能超过2个;
#define AUDIO_FILE_NUMS 2
#define AUDIO_FILE_NAME_LENGTH 32
int speechRecognizerMultFile(const char* appkey);
#endif
</sys></fstream></vector></iostream></string></ctime></stdlib.h></pthread.h></unistd.h></string.h>
9.main.cpp
#include "myrecord.h"
#include <qapplication>
int main(int argc, char *argv[])
{
QApplication a(argc, argv);
MyRecord w;
w.show();
return a.exec();
}
</qapplication>
10.myrecord.cpp
#include "myrecord.h"
#include "ui_myrecord.h"
#include"speechRecognizerDemo.h"
#include<qdebug>
#include"result.h"
extern std::string g_appkey;
extern std::string g_akId;
extern std::string g_akSecret;
extern std::string g_token;
MyRecord::MyRecord(QWidget *parent) :
QWidget(parent),
ui(new Ui::MyRecord)
{
ui->setupUi(this);
initAudio();
loadConfig();
connect(&(Result::getInstance()),SIGNAL(sendMsg(QString)),
this,SLOT(recvMsg(QString)));
// 根据需要设置SDK输出日志, 可选. 此处表示SDK日志输出至log-recognizer.txt, LogDebug表示输出所有级别日志,支持LogInfo、LogWarning、LogError, 400表示单个文件400MB
int ret = NlsClient::getInstance()->setLogConfig("log-recognizer", LogDebug, 400);
if (-1 == ret) {
printf("set log failed.\n");
}
//启动工作线程
NlsClient::getInstance()->startWorkThread(4);
}
MyRecord::~MyRecord()
{
delete ui;
}
void MyRecord::initAudio()
{
QAudioFormat format;
format.setSampleRate(16000);//设置采样频率为16KHZ
format.setChannelCount(1);//设置为单声道
format.setSampleSize(16);//采样字节大小
format.setCodec("audio/pcm");
format.setByteOrder(QAudioFormat::LittleEndian);//设置采用存放音频数据是大端字节序还是小端字节序
format.setSampleType(QAudioFormat::SignedInt);
QAudioDeviceInfo defInfo = QAudioDeviceInfo::defaultInputDevice();
if(!defInfo.isFormatSupported(format)){
format = defInfo.nearestFormat(format);
}
m_pAudioInput = new QAudioInput(format,this);
}
void MyRecord::rawTowav()
{
m_rawFile.open(QIODevice::ReadOnly);
m_wavFile.setFileName("test.wav");
m_wavFile.open(QIODevice::WriteOnly|QIODevice::Truncate);
static WAVHEARD wavHeard;
qstrcpy(wavHeard.RiffName,"RIFF");
qstrcpy(wavHeard.WavName,"WAVE");
qstrcpy(wavHeard.FmtName,"fmt");
qstrcpy(wavHeard.DataName,"data");
wavHeard.nFmtLength =16;
wavHeard.nAudioFormat =1;
wavHeard.nBitsPerSample = 16;
wavHeard.nChannleNumber =1;
wavHeard.nBytesPerSample = 2;
wavHeard.nSampleRate = 16;
wavHeard.nBytesPerSecond = 32000;
wavHeard.nRiffLength = m_rawFile.size()-8+sizeof(WAVHEARD);
wavHeard.nDataLength = m_rawFile.size();
m_wavFile.write(reinterpret_cast<char*>(&wavHeard),sizeof(WAVHEARD));
m_wavFile.write(m_rawFile.readAll());
m_rawFile.close();
m_wavFile.close();
}
void MyRecord::loadConfig()
{
QFile file(":/speech.config");
file.open(QIODevice::ReadOnly);
QByteArray data = file.readLine();
m_strAppkey = data.data();
m_strAppkey.remove("\n");
data = file.readLine();
m_strAKID = data.data();
m_strAKID.remove("\n");
data = file.readLine();
m_strAKSecret = data.data();
m_strAKSecret.remove("\n");
data = file.readLine();
m_strToken = data.data();
m_strToken.remove("\n");
file.close();
g_appkey = m_strAppkey.toStdString();
g_akId = m_strAKID.toStdString();
g_akSecret = m_strAKSecret.toStdString();
g_token = m_strToken.toStdString();
}
void MyRecord::recvMsg(QString msg)
{
ui->showResult->append(msg);
}
void MyRecord::on_start_pb_clicked()
{
m_rawFile.setFileName("test.raw");
m_rawFile.open(QIODevice::WriteOnly|QIODevice::Truncate);
m_pAudioInput->start(&m_rawFile);
}
void MyRecord::on_stop_pb_clicked()
{
m_pAudioInput->stop();
m_rawFile.close();
rawTowav();
speechRecognizerFile();
}
</char*></qdebug>
11.result.cpp
#include "result.h"
Result::Result(QWidget *parent) : QWidget(parent)
{
}
void Result::send(std::string msg)
{
emit sendMsg(msg.c_str());
}
Result &Result::getInstance()
{
static Result instance;
return instance;
}
12.speechRecognizerDemo.cpp
#include"speechRecognizerDemo.h"
#include"result.h"
//全局维护一个服务鉴权token和其对应的有效期时间戳,
//每次调用服务之前,首先判断token是否已经过期,
//如果已经过期,则根据AccessKey ID和AccessKey Secret重新生成一个token,并更新这个全局的token和其有效期时间戳。
//注意:不要每次调用服务之前都重
std::string g_appkey="";
std::string g_akId = "";
std::string g_akSecret = "";
std::string g_token = "";
std::string g_result = "";
long g_expireTime = -1;
struct timeval tv;
struct timeval tv1;
#if 0
// 根据AccessKey ID和AccessKey Secret重新生成一个token,并获取其有效期时间戳
// token使用规则:在有效期到期前可以一直使用,且可以多个进程/多个线程/多个应用使用均可,建议在有效期快到期时提起申请新的token
int generateToken(std::string akId, std::string akSecret, std::string* token, long* expireTime) {
NlsToken nlsTokenRequest;
nlsTokenRequest.setAcc
}essKeyId(akId);
nlsTokenRequest.setKeySecret(akSecret);
if (-1 == nlsTokenRequest.applyNlsToken()) {
// 获取失败原因
printf("generateToken Failed: %s\n", nlsTokenRequest.getErrorMsg());
return -1;
}
*token = nlsTokenRequest.getToken();
*expireTime = nlsTokenRequest.getExpireTime();
return 0;
}
#endif
//@brief 获取sendAudio发送延时时间
//@param dataSize 待发送数据大小
//@param sampleRate 采样率 16k/8K
//@param compressRate 数据压缩率,例如压缩比为10:1的16k opus编码,此时为10;非压缩数据则为1
//@return 返回sendAudio之后需要sleep的时间
//@note 对于8k pcm 编码数据, 16位采样,建议每发送1600字节 sleep 100 ms.
// 对于16k pcm 编码数据, 16位采样,建议每发送3200字节 sleep 100 ms.
// 对于其它编码格式的数据, 用户根据压缩比, 自行估算, 比如压缩比为10:1的 16k opus,
// 需要每发送3200/10=320 sleep 100ms.
unsigned int getSendAudioSleepTime(int dataSize, int sampleRate, int compressRate) {
// 仅支持16位采样
const int sampleBytes = 16;
// 仅支持单通道
const int soundChannel = 1;
// 当前采样率,采样位数下每秒采样数据的大小
int bytes = (sampleRate * sampleBytes * soundChannel) / 8;
// 当前采样率,采样位数下每毫秒采样数据的大小
int bytesMs = bytes / 1000;
// 待发送数据大小除以每毫秒采样数据大小,以获取sleep时间
int sleepMs = (dataSize * compressRate) / bytesMs;
return sleepMs;
}
//@brief 调用start(), 成功与云端建立连接, sdk内部线程上报started事件
//@param cbEvent 回调事件结构, 详见nlsEvent.h
//@param cbParam 回调自定义参数,默认为NULL, 可以根据需求自定义参数
void OnRecognitionStarted(NlsEvent* cbEvent, void* cbParam) {
ParamCallBack* tmpParam = (ParamCallBack*)cbParam;
// 演示如何打印/使用用户自定义参数示例
printf("OnRecognitionStarted: %d, %s\n", tmpParam->userId, tmpParam->userInfo);
// 获取消息的状态码,成功为0或者20000000,失败时对应失败的错误码
// 当前任务的task id,方便定位问题,建议输出,特别提醒该taskid非常重要,是和服务端交互的唯一标识,因此建议在实际使用时建议输出该taskid
printf("OnRecognitionStarted: status code=%d, task id=%s\n", cbEvent->getStatusCode(), cbEvent->getTaskId());
// 获取服务端返回的全部信息
//printf("OnRecognitionStarted: all response=%s\n", cbEvent->getAllResponse());
}
//@brief 设置允许返回中间结果参数, sdk在接收到云端返回到中间结果时, sdk内部线程上报ResultChanged事件
//@param cbEvent 回调事件结构, 详见nlsEvent.h
//@param cbParam 回调自定义参数,默认为NULL, 可以根据需求自定义参数
void OnRecognitionResultChanged(NlsEvent* cbEvent, void* cbParam) {
ParamCallBack* tmpParam = (ParamCallBack*)cbParam;
// 演示如何打印/使用用户自定义参数示例
printf("OnRecognitionResultChanged: %d, %s\n", tmpParam->userId, tmpParam->userInfo);
// 当前任务的task id,方便定位问题,建议输出,特别提醒该taskid非常重要,是和服务端交互的唯一标识,因此建议在实际使用时建议输出该taskid
printf("OnRecognitionResultChanged: status code=%d, task id=%s, result=%s\n", cbEvent->getStatusCode(), cbEvent->getTaskId(), cbEvent->getResult());
// 获取服务端返回的全部信息
//printf("OnRecognitionResultChanged: response=%s\n", cbEvent->getAllResponse());
}
//@brief sdk在接收到云端返回识别结束消息时, sdk内部线程上报Completed事件
//@note 上报Completed事件之后, SDK内部会关闭识别连接通道. 此时调用sendAudio会返回-1, 请停止发送.
//@param cbEvent 回调事件结构, 详见nlsEvent.h
//@param cbParam 回调自定义参数,默认为NULL, 可以根据需求自定义参数
void OnRecognitionCompleted(NlsEvent* cbEvent, void* cbParam) {
ParamCallBack* tmpParam = (ParamCallBack*)cbParam;
// 演示如何打印/使用用户自定义参数示例
printf("OnRecognitionCompleted: %d, %s\n", tmpParam->userId, tmpParam->userInfo);
// 当前任务的task id,方便定位问题,建议输出,特别提醒该taskid非常重要,是和服务端交互的唯一标识,因此建议在实际使用时建议输出该taskid
printf("OnRecognitionCompleted: status code=%d, task id=%s, result=%s\n", cbEvent->getStatusCode(), cbEvent->getTaskId(), cbEvent->getResult());
g_result = cbEvent->getResult();
Result::getInstance().send(g_result);
// 获取服务端返回的全部信息
//printf("OnRecognitionCompleted: response=%s\n", cbEvent->getAllResponse());
}
//@brief 识别过程发生异常时, sdk内部线程上报TaskFailed事件
//@note 上报TaskFailed事件之后, SDK内部会关闭识别连接通道. 此时调用sendAudio会返回-1, 请停止发送.
//@param cbEvent 回调事件结构, 详见nlsEvent.h
//@param cbParam 回调自定义参数,默认为NULL, 可以根据需求自定义参数
//@return
void OnRecognitionTaskFailed(NlsEvent* cbEvent, void* cbParam) {
ParamCallBack* tmpParam = (ParamCallBack*)cbParam;
// 演示如何打印/使用用户自定义参数示例
printf("OnRecognitionTaskFailed: %d, %s\n", tmpParam->userId, tmpParam->userInfo);
// 当前任务的task id,方便定位问题,建议输出,特别提醒该taskid非常重要,是和服务端交互的唯一标识,因此建议在实际使用时建议输出该taskid
printf("OnRecognitionTaskFailed: status code=%d, task id=%s, error message=%s\n", cbEvent->getStatusCode(), cbEvent->getTaskId(), cbEvent->getErrorMessage());
// 获取服务端返回的全部信息
//printf("OnRecognitionTaskFailed: response=%s\n", cbEvent->getAllResponse());
}
//@brief 识别结束或发生异常时,会关闭连接通道, sdk内部线程上报ChannelCloseed事件
//@param cbEvent 回调事件结构, 详见nlsEvent.h
//@param cbParam 回调自定义参数,默认为NULL, 可以根据需求自定义参数
void OnRecognitionChannelClosed(NlsEvent* cbEvent, void* cbParam) {
ParamCallBack* tmpParam = (ParamCallBack*)cbParam;
// 演示如何打印/使用用户自定义参数示例
printf("OnRecognitionChannelClosed: %d, %s\n", tmpParam->userId, tmpParam->userInfo);
// 获取服务端 qDebug()<< m_strAppkey << m_strAKID;返回的全部信息
printf("OnRecognitionChannelClosed: response=%s\n", cbEvent->getAllResponse());
delete tmpParam; //识别流程结束,释放回调参数
}
void* pthreadFunction(void* arg) {
int sleepMs = 0;
ParamCallBack *cbParam = nullptr;
//初始化自定义回调参数, 以下两变量仅作为示例表示参数传递, 在demo中不起任何作用
//回调参数在堆中分配之后, SDK在销毁requesr对象时会一并销毁, 外界无需在释放
cbParam = new ParamCallBack;
cbParam->userId = rand() % 100;
strcpy(cbParam->userInfo, "User.");
// 0: 从自定义线程参数中获取token, 配置文件等参数.
ParamStruct *tst = (ParamStruct *) arg;
if (tst == nullptr) {
printf("arg is not valid\n");
return nullptr;
}
// 打开音频文件, 获取数据
std::ifstream fs;
fs.open(tst->fileName.c_str(), std::ios::binary | std::ios::in);
if (!fs) {
printf("%s isn't exist..\n", tst->fileName.c_str());
return nullptr;
}
//1: 创建一句话识别SpeechRecognizerRequest对象
SpeechRecognizerRequest *request = NlsClient::getInstance()->createRecognizerRequest();
if (request == nullptr) {
printf("createRecognizerRequest failed\n");
return nullptr;
}
request->setOnRecognitionStarted(OnRecognitionStarted, cbParam); // 设置start()成功回调函数
request->setOnTaskFailed(OnRecognitionTaskFailed, cbParam); // 设置异常识别回调函数
request->setOnChannelClosed(OnRecognitionChannelClosed, cbParam); // 设置识别通道关闭回调函数
request->setOnRecognitionResultChanged(OnRecognitionResultChanged, cbParam); // 设置中间结果回调函数
request->setOnRecognitionCompleted(OnRecognitionCompleted, cbParam); // 设置识别结束回调函数
request->setAppKey(tst->appkey.c_str()); // 设置AppKey, 必填参数, 请参照官网申请
request->setFormat("pcm"); // 设置音频数据编码格式, 可选参数, 目前支持pcm, opus. 默认是pcm
request->setSampleRate(SAMPLE_RATE); // 设置音频数据采样率, 可选参数, 目前支持16000, 8000. 默认是16000
request->setIntermediateResult(true); // 设置是否返回中间识别结果, 可选参数. 默认false
request->setPunctuationPrediction(true); // 设置是否在后处理中添加标点, 可选参数. 默认false
request->setInverseTextNormalization(true); // 设置是否在后处理中执行ITN, 可选参数. 默认false
//request->setEnableVoiceDetection(true); //是否启动语音检测, 可选, 默认是False
//允许的最大开始静音, 可选, 单位是毫秒, 超出后服务端将会发送RecognitionCompleted事件, 结束本次识别. 注意: 需要先设置enable_voice_detection为true
//request->setMaxStartSilence(5000);
//允许的最大结束静音, 可选, 单位是毫秒, 超出后服务端将会发送RecognitionCompleted事件, 结束本次识别. 注意: 需要先设置enable_voice_detection为true
//request->setMaxEndSilence(800);
//request->setCustomizationId("TestId_123"); //定制语言模型id, 可选.
//request->setVocabularyId("TestId_456"); //定制泛热词id, 可选.
// 用于传递某些定制化、高级参数设置,参数格式为json格式: {"key": "value"}
//request->setPayloadParam("{\"vad_model\": \"farfield\"}");
request->setToken(tst->token.c_str()); // 设置账号校验token, 必填参数
// 2: start()为异步操作。成功返回started事件。失败返回TaskFailed事件。
if (request->start() < 0) {
printf("start() failed. may be can not connect server. please check network or firewalld\n");
NlsClient::getInstance()->releaseRecognizerRequest(request); // start()失败,释放request对象
return nullptr;
}
while (!fs.eof()) {
uint8_t data[FRAME_SIZE] = {0};
fs.read((char *) data, sizeof(uint8_t) * FRAME_SIZE);
size_t nlen = fs.gcount();
if (nlen <= 0) { continue; } 3: 发送音频数据. sendaudio为异步操作, 返回-1表示发送失败, 需要停止发送. int ret="request-">sendAudio(data, nlen);
if (ret < 0) {
// 发送失败, 退出循环数据发送
printf("send data fail.\n");
break;
}
// 语音数据发送控制:
// 语音数据是实时的, 不用sleep控制速率, 直接发送即可.
// 语音数据来自文件(也即本示例代码模拟的语音流发送机制), 发送时需要控制速率, 使单位时间内发送的数据大小接近单位时间原始语音数据存储的大小.
sleepMs = getSendAudioSleepTime(nlen, SAMPLE_RATE, 1); // 根据 发送数据大小,采样率,数据压缩比 来获取sleep时间
// 4: 语音数据发送延时控制
usleep(sleepMs * 1000);
}
printf("sendAudio done.\n");
//5: 关闭音频文件
fs.close();
//6: 通知云端数据发送结束.
//stop()为异步操作.失败返回TaskFailed事件。
request->stop();
//7: 通知SDK释放request.
NlsClient::getInstance()->releaseRecognizerRequest(request);
return nullptr;
}
//线程循环识别
//需要调整count值和每次要识别的文件,Demo中默认每次识别一个文件
void* multiRecognize(void* arg) {
int count = 2;
while (count > 0) {
pthreadFunction(arg);
count--;
}
return nullptr;
}
// 识别单个音频数据
int speechRecognizerFile() {
//获取当前系统时间戳,判断token是否过期
// std::time_t curTime = std::time(0);
// if (g_expireTime - curTime < 10) {
// printf("the token will be expired, please generate new token by AccessKey-ID and AccessKey-Secret.\n");
// if (-1 == generateToken(g_akId, g_akSecret, &g_token, &g_expireTime)) {
// return -1;
// }
// }
ParamStruct pa;
pa.token = g_token;
pa.appkey =g_appkey;
pa.fileName = "test.wav";
pthread_t pthreadId;
// 启动一个工作线程, 用于单次识别
pthread_create(&pthreadId, nullptr, &pthreadFunction, (void *)&pa);
// 启动一个工作线程, 用于循环识别
// pthread_create(&pthreadId, NULL, &multiRecognize, (void *)&pa);
pthread_join(pthreadId, nullptr);
return 0;
}
//识别多个音频数据;
//sdk多线程指一个音频数据源对应一个线程, 非一个音频数据对应多个线程.
//示例代码为同时开启2个线程识别2个文件;
//免费用户并发连接不能超过2个;
#define AUDIO_FILE_NUMS 2
#define AUDIO_FILE_NAME_LENGTH 32
int speechRecognizerMultFile(const char* appkey) {
//获取当前系统时间戳,判断token是否过期
// std::time_t curTime = std::time(0);
// if (g_expireTime - curTime < 10) {
// printf("the token will be expired, please generate new token by AccessKey-ID and AccessKey-Secret.\n");
// if (-1 == generateToken(g_akId, g_akSecret, &g_token, &g_expireTime)) {
// return -1;
// }
// }
char audioFileNames[AUDIO_FILE_NUMS][AUDIO_FILE_NAME_LENGTH] = {"test0.wav", "test1.wav"};
ParamStruct pa[AUDIO_FILE_NUMS];
for (int i = 0; i < AUDIO_FILE_NUMS; i ++) {
pa[i].token = g_token;
pa[i].appkey = appkey;
pa[i].fileName = audioFileNames[i];
}
std::vector<pthread_t> pthreadId(AUDIO_FILE_NUMS);
// 启动AUDIO_FILE_NUMS个工作线程, 同时识别AUDIO_FILE_NUMS个音频文件
for (int j = 0; j < AUDIO_FILE_NUMS; j++) {
pthread_create(&pthreadId[j], nullptr, &pthreadFunction, (void *)&(pa[j]));
}
for (int j = 0; j < AUDIO_FILE_NUMS; j++) {
pthread_join(pthreadId[j], nullptr);
}
return 0;
}
#if 0
int main(int arc, char* argv[]) {
if (arc < 4) {
printf("params is not valid. Usage: ./demo <your appkey> <your accesskey id> <your accesskey secret>\n");
return -1;
}
std::string appkey = argv[1];
g_akId = argv[2];
g_akSecret = argv[3];
// 根据需要设置SDK输出日志, 可选. 此处表示SDK日志输出至log-recognizer.txt, LogDebug表示输出所有级别日志,支持LogInfo、LogWarning、LogError, 400表示单个文件400MB
int ret = NlsClient::getInstance()->setLogConfig("log-recognizer", LogDebug, 400);
if (-1 == ret) {
printf("set log failed.\n");
return -1;
}
//启动工作线程
NlsClient::getInstance()->startWorkThread(4);
// 识别单个音频数据
speechRecognizerFile(appkey.c_str());
// 并发识别多个音频数据
//speechRecognizerMultFile(appkey.c_str());
// 所有工作完成,进程退出前,释放nlsClient. 请注意, releaseInstance()非线程安全.
NlsClient::releaseInstance();
return 0;
}
#endif
</your></your></your></pthread_t></=>
13.config
diThhK1nbgO8NcG0
LTAI5tAhmUo4aKLdVuu1oKTK
tAjf2qsmsrAoq5fTqkwFYJzbh7uNqS
f1c642a7436349849823997d469e6841
Original: https://blog.csdn.net/weixin_41392061/article/details/117431550
Author: weixin_41392061
Title: QT实现语音识别功能
相关阅读1
Title: 常用的图像增强方法
大规模数据集是成功应用深度神经网络的前提。例如,我们可以对图像进行不同方式的裁剪,使感兴趣的物体出现在不同位置,从而减轻模型对物体出现位置的依赖性。我们也可以调整亮度、色彩等因素来降低模型对色彩的敏感度。可以说,在当年AlexNet的成功中,图像增强技术功不可没
1.常用的图像增强方法
图像增强(image augmentation)指通过剪切、旋转/反射/翻转变换、缩放变换、平移变换、尺度变换、对比度变换、噪声扰动、颜色变换等一种或多种组合数据增强变换的方式来增加数据集的大小。图像增强的意义是通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模,而且随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力。
常见的图像增强方式可以分为两类:几何变换类和颜色变换类
-
几何变换类,主要是对图像进行几何变换操作,包括翻转,旋转,裁剪,变形,缩放等。
-
颜色变换类,指通过模糊、颜色变换、擦除、填充等方式对图像进行处理
实现图像增强可以通过tf.image来完成,也可以通过tf.keras.imageGenerator来完成。
2.tf.image进行图像增强
导入所需的工具包并读取要处理的图像:
导入工具包
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
读取图像并显示
cat = plt.imread('./cat.jpg')
plt.imshow(cat)
左右翻转图像是最早也是最广泛使用的一种图像增广方法。可以通过 tf.image.random_flip_left_right来实现图像左右翻转。
左右翻转并显示
cat1 = tf.image.random_flip_left_right(cat)
plt.imshow(cat1)
创建 tf.image.random_flip_up_down实例来实现图像的上下翻转,上下翻转使用的较少。
上下翻转
cat2 = tf.image.random_flip_up_down(cat)
plt.imshow(cat2)
随机裁剪
cat3 = tf.image.random_crop(cat,(200,200,3))
plt.imshow(cat3)
另一类增广方法是颜色变换。我们可以从4个方面改变图像的颜色:亮度、对比度、饱和度和色调。接下来将图像的亮度随机变化为原图亮度的50%50%(即1−0.51−0.5)∼150%∼150%(即1+0.51+0.5)。
cat4=tf.image.random_brightness(cat,0.5)
plt.imshow(cat4)
类似地,我们也可以随机变化图像的色调
cat5 = tf.image.random_hue(cat,0.5)
plt.imshow(cat5)
3 使用ImageDataGenerator()进行图像增强
ImageDataGenerator()是keras.preprocessing.image模块中的图片生成器,可以在batch中对数据进行增强,扩充数据集大小,增强模型的泛化能力。比如旋转,变形等,如下所示:
keras.preprocessing.image.ImageDataGenerator(
rotation_range=0, #整数。随机旋转的度数范围。
width_shift_range=0.0, #浮点数、宽度平移
height_shift_range=0.0, #浮点数、高度平移
brightness_range=None, # 亮度调整
shear_range=0.0, # 裁剪
zoom_range=0.0, #浮点数 或 [lower, upper]。随机缩放范围
horizontal_flip=False, # 左右翻转
vertical_flip=False, # 垂直翻转
rescale=None # 尺度调整
)
来看下水平翻转的结果:
获取数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
将数据转换为4维的形式
x_train = X_train.reshape(X_train.shape[0],28,28,1)
x_test = X_test.reshape(X_test.shape[0],28,28,1)
设置图像增强方式:水平翻转
datagen = ImageDataGenerator(horizontal_flip=True)
查看增强后的结果
for X_batch,y_batch in datagen.flow(x_train,y_train,batch_size=9):
plt.figure(figsize=(8,8)) # 设定每个图像显示的大小
# 产生一个3*3网格的图像
for i in range(0,9):
plt.subplot(330+1+i)
plt.title(y_batch[i])
plt.axis('off')
plt.imshow(X_batch[i].reshape(28,28),cmap='gray')
plt.show()
break
Original: https://blog.csdn.net/weixin_46556352/article/details/124167804
Author: AI耽误的大厨
Title: 常用的图像增强方法
相关阅读2
Title: 【平头哥RVB2601开发板试用体验】基于 HTTPClient 的云语音识别 2
作者 | 哈猪猪
在文章1中我们计划用 HTTPClient 组件帮助我们与服务器通信,上传录音文件并接收识别结果,最终实现云语音识别。经过测试后没有问题,因此接下来我们需要理解该组件提供的功能,并实现文件对服务器的上传。
首先,根据 HTTPClient 组件的示例程序 http_examples.c,我们得知了一个完整的 HTTP 请求需要调用的接口流程,大致如下。以 POST 请求为例,并直接设置 url 而非 host&path:
http_client_config_t config = {
.url = "http://httpbin.org/get",
.event_handler = _http_event_handler,
};
http_client_handle_t client = http_client_init(&config);
​
const char *post_data = "field1=value1&field2=value2";
http_client_set_method(client, HTTP_METHOD_POST);
http_client_set_post_field(client, post_data, strlen(post_data));
err = http_client_perform(client);
if (err == HTTP_CLI_OK) {
LOGI(TAG, "HTTP POST Status = %d, content_length = %d \r\n",
http_client_get_status_code(client),
http_client_get_content_length(client));
} else {
LOGE(TAG, "HTTP POST request failed: 0x%x @#@@@@@@", (err));
e_count ++;
}
整个流程主要涉及到以下几个函数:
http_client_init() 主要是基于 config 对 client 结构的各种变量赋初值,包括在请求中会用的到的各种缓存空间,以及 header 中的基本信息。其中 config 未设置的会赋缺省值。也可以用库提供的各种 set_xxx 函数来对变量赋值。
http_client_set_post_field():对于有请求体的 POST,我们需要调用这个函数将发送数据的指针以及长度赋予 client:
web_err_t http_client_set_post_field(http_client_handle_t client, const char *data, int len)
{
web_err_t err = WEB_OK;
client->post_data = (char *)data; // 待发送数据指针
client->post_len = len; // 待发送数据长度
LOGD(TAG, "set post file length = %d", len);
// 如果此前没有设置 Content-Type,则设置为 application/x-www-form-urlencoded
if (client->post_data)
{
char *value = NULL;
if ((err = http_client_get_header(client, "Content-Type", &value)) != WEB_OK)
{
return err;
}
if (value == NULL)
{
err = http_client_set_header(client, "Content-Type", "application/x-www-form-urlencoded");
}
}
else
{
client->post_len = 0;
err = http_client_set_header(client, "Content-Type", NULL);
}
return err;
}
阅读源码可见,库默认支持"Content-Type"为"application/x-www-form-urlencoded"的 POST 请求,而我们要上传音频文件是"multipart/form-data"类型的。然而浏览了整个 HTTPClient 组件发现它就支持这一种类型......POST 的具体实现也只支持这一种。我们接着往下看就知道了......
http_client_perform():无论是什么 HTTP 请求,在设置完 client 之后最后都是经由这一个函数来具体实现。该函数将根据当前所处的 HTTP 请求流程,调用对应的函数,而这些函数最终会调用 transport 组件即在传输层上读写,最终实现整个 HTTP 请求。http_client_perform() 依次主要调用了以下几个函数:
http_client_prepare();
http_client_connect();
http_client_request_send();
http_client_send_post_data();
http_client_fetch_headers();
http_check_response();
http_client_get_data();
http_client_close();
实现的功能与其函数名一致,也是我们熟知的 HTTP 请求流程。其中我们最关心的当然是http_client_send_post_data():
static web_err_t http_client_send_post_data(http_client_handle_t client)
{
// 此时请求头应发送完毕
if (client->state != HTTP_STATE_REQ_COMPLETE_HEADER)
{
LOGE(TAG, "Invalid state");
return WEB_ERR_INVALID_STATE;
}
// 没有要发送的 post_data 直接返回(包括其它请求)
if (!(client->post_data && client->post_len))
{
goto success;
}
​
// 发送 post_data
int wret = http_client_write(client, client->post_data + client->data_written_index, client->data_write_left);
if (wret < 0)
{
return wret;
}
// 在 request send 里面 data_write_left 最后被赋值为 post_len
client->data_write_left -= wret;
// 在 request send 里面 data_written_index 最后被赋值为 0
client->data_written_index += wret;
​
// 发送完毕
if (client->data_write_left <= 0) { goto success; } else return err_http_write_data; success: 更新状态 client->state = HTTP_STATE_REQ_COMPLETE_DATA;
return WEB_OK;
}</=>
可见,整个 POST 实现只会发送一次 post_data,它指向我们最初在 http_client_set_post_field() 中填入的待发送数据。然而,我们知道要发送"multipart/form-data"类型的数据,需要按照格式用 boundary 对请求体进行封装,并在请求头中提前告知 boundary。当然,HTTPClient 组件是没有实现这些的......因此如果我们要利用 HTTPClient 发送音频数据,就必须手动实现"multipart/form-data"类型请求体的封装与发送。
当我终于大致理解了 HTTPClient 组件后,我在浏览 YOC 源码时发现了一个就叫"http"的组件,它并没有出现在 YOC 文档里然而它已经实现了"multipart/form-data"类型的 POST......囿于我技术水平有限,源码缺少注释,感觉学习成本过高,遂放弃。
事实上针对本项目要实现的云语音识别,YOC 还有很多更适合的组件:麦克风服务,云音交互(AUI Cloud)......甚至后者本身就是为语音识别等应用构建的。然而由于源码没有注释,只有接口介绍文档,以及其它板子上的相关例程,感觉"移植"组件对自己难度过大,最终都没有使用,选择了基于 HTTPClient 手动实现音频数据的发送。
欢迎关注公众号: 芯片开放社区(ID:OCC_THEAD),查看更多应用实战文章。
Original: https://blog.csdn.net/OCC_THEAD/article/details/123706836
Author: 平头哥芯片开放社区
Title: 【平头哥RVB2601开发板试用体验】基于 HTTPClient 的云语音识别 2
相关阅读3
Title: cuda10.1+cudnn10.1+tensorflow2.2.0+pytorch1.7.1下载安装及配置
一、cuda及cudnn下载
1、查看自己电脑是否支持GPU
方法:鼠标移动到此电脑,点击鼠标右键,依次选择属性、设备管理器、显示适配器有以下图标(NVIDIA)即可安装GPU,我的是MX130的。

2、选择和自己电脑相匹配的cuda版本
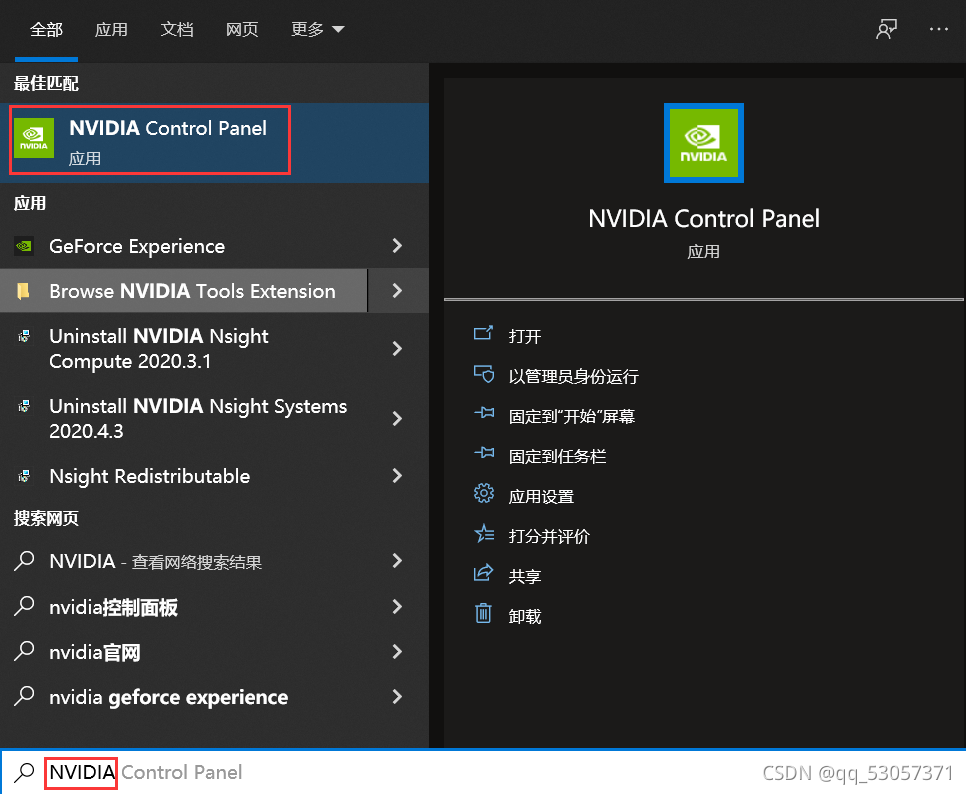
2.1 查看自己电脑cuda版本:点击电脑左下角的搜索图标(放大镜)输入NVIDIA,选择如下应用
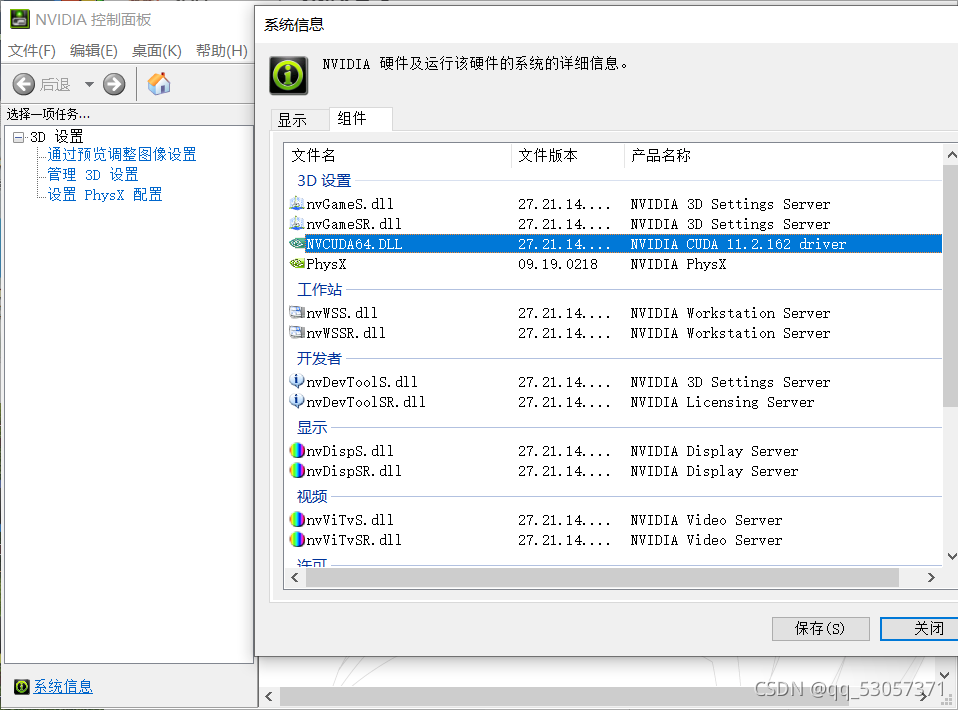
点击帮助、系统信息、组件找到NVCUDA64.DLL查看cuda版本,显示的是最高可安装的cuda版本,并非仅支持,我的是11.2.162版本
3、下载cuda
cuda官网:CUDA Toolkit Archive | NVIDIA Developer
游览器打开相比较于迅雷更慢,下载速度也很慢,建议直接复制网址进入迅雷搜索下载,进入后选择与自己电脑相匹配的版本,选择10.1
下载速度慢的另一个方法是通过像迅雷一样的第三方软件 Internet Download Manager下载(哔哩哔哩看到的,未亲测)
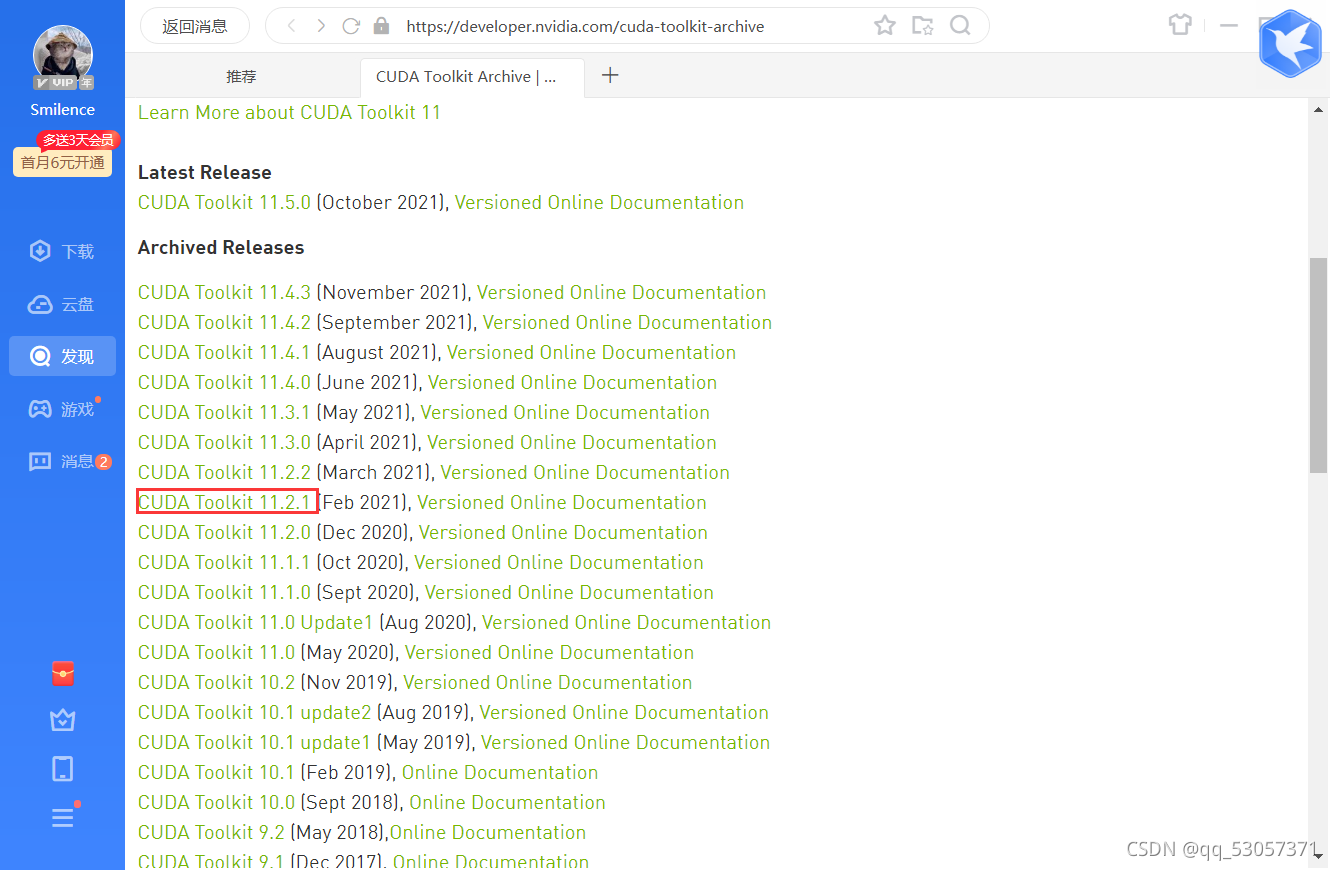
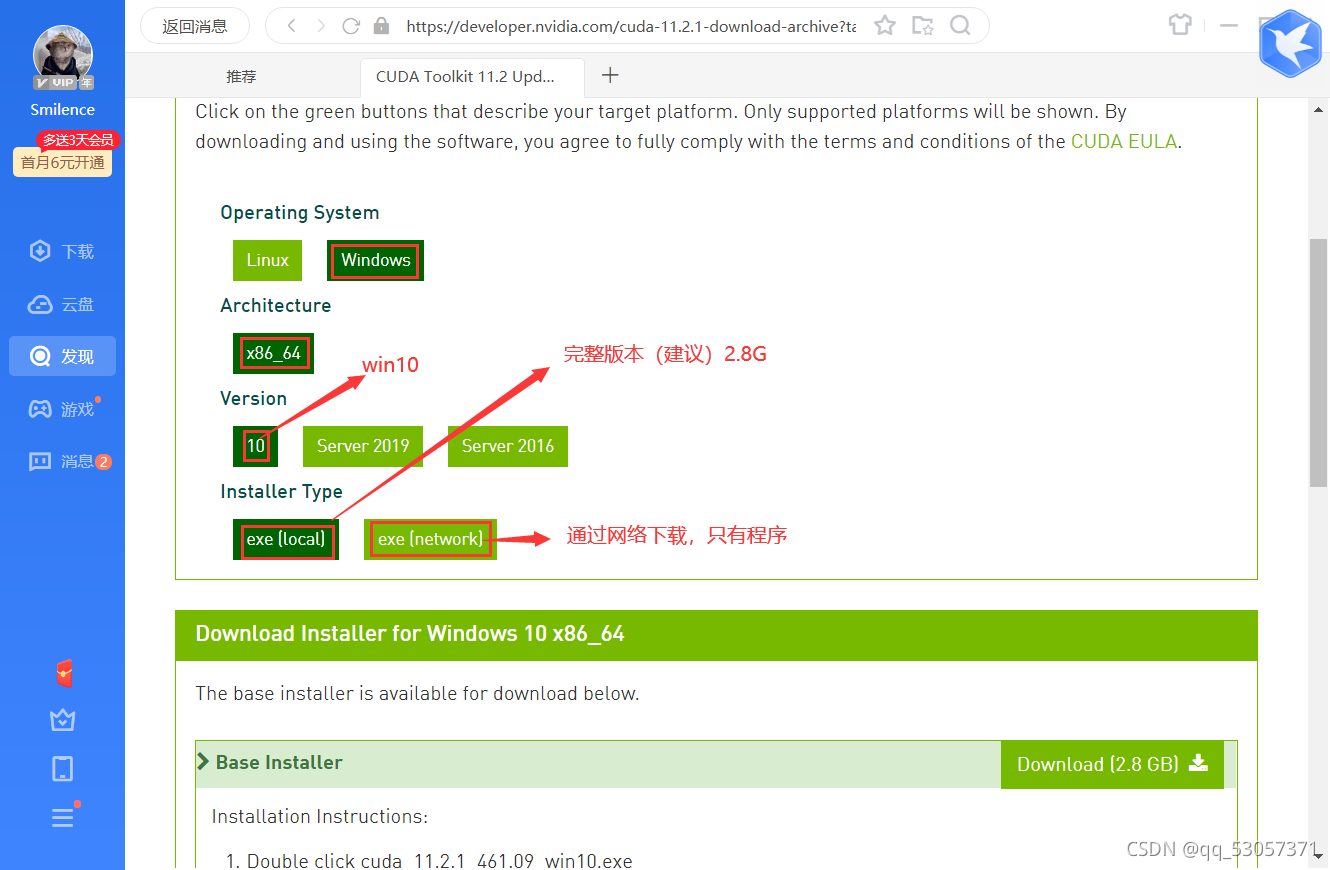
点击进入后,选择自己的系统,我的是WIN10系统(local完整版2.8G,network程序很小59.2MB),建议选择完整版,点击download下载完成即可
4、下载CUDNN 安装包
CUDNN官网:https://developer.nvidia.com/rdp/cudnn-download
方法和下载cuda一样,建议复制链接到迅雷下载
显示需要会员才能下载,点击立即加入,用邮箱注册一个账号,填写一个调查问卷即可下载

注册登陆后,勾选下列图标,进入CUDNN版本选择页

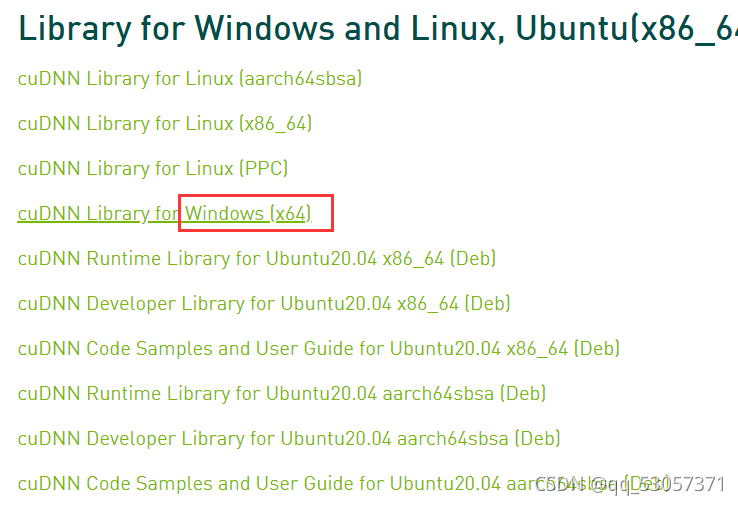
下图所显示的下面的链接表示10.2以前的版本,我的是11.2的,选择上面的版本,如下图
点开链接后选择和自己电脑系统匹配的CUDNN,点击进入,即跳转到下载界面,接着选择自己的下载路径即可
二、cuda安装
1、移动鼠标到cuda安装包上,选择以管理员身份运行,如下图
2、选择安装路径,选择不存在的,能够自己创建(建议选择默认路径,因为后面的安装需要相同的路径)
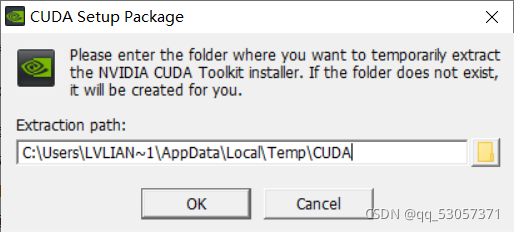
点击OK进入下一步
进入cuda安装环境后不要进行任何操作
返回电脑桌面,滑动鼠标右击此电脑—管理—服务和应用程序—服务
找到Windows Installer点击启动此服
选择自定义安装,下一步
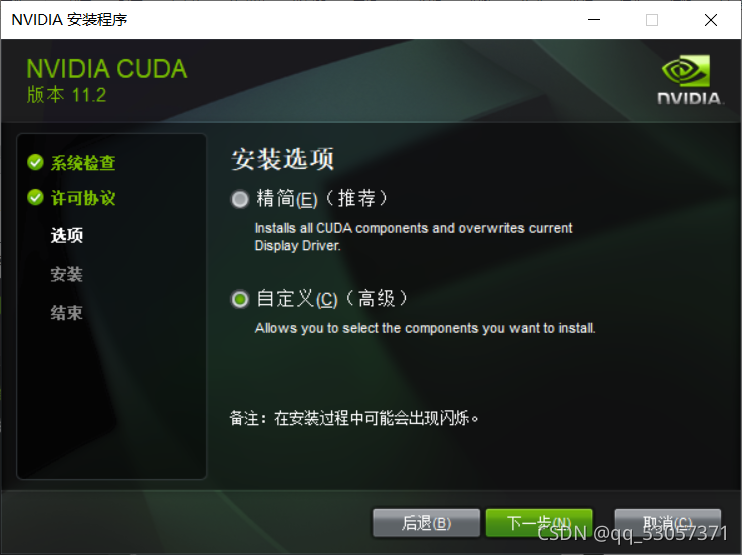
下一步全部选择,电脑有更高的驱动的话,下面三个均可以不选
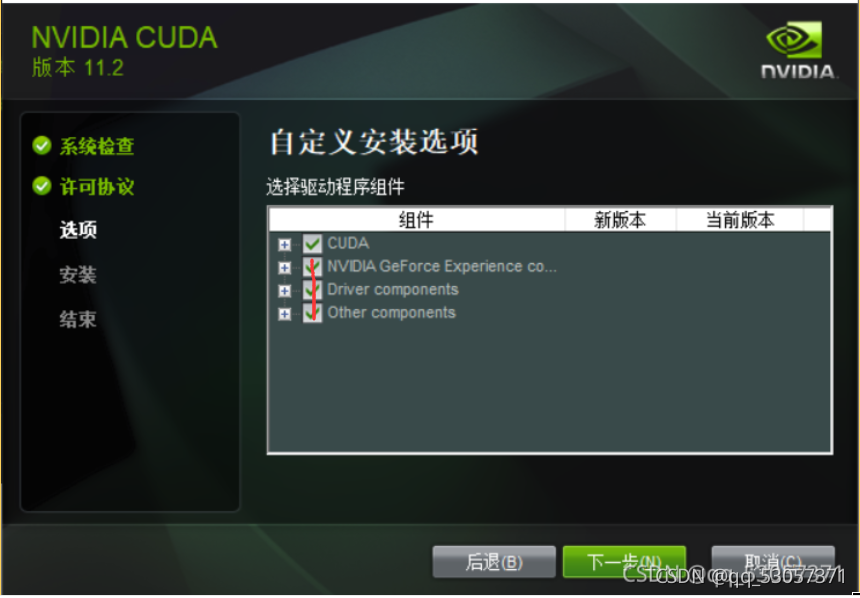
下一步选择安装位置(建议默认)

下一步如果有Visual Studio则勾选以下图标,没有则先安装Visual Studio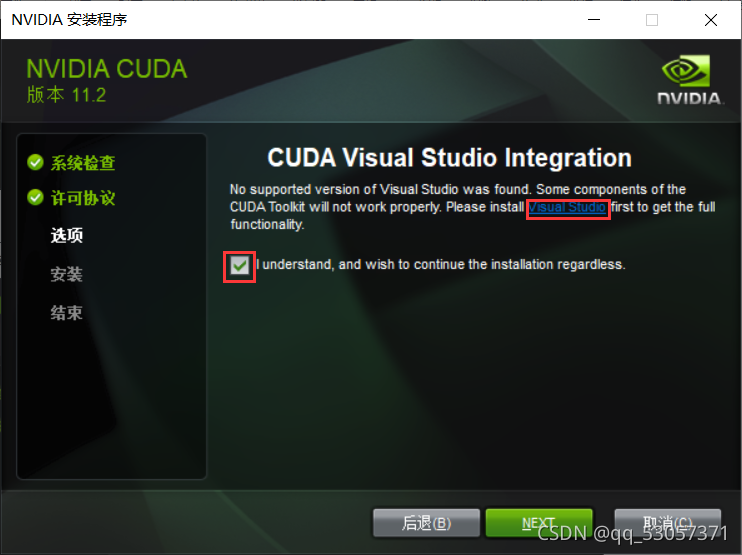 最后,点击next进行安装,接下来就等着安装就可以了
最后,点击next进行安装,接下来就等着安装就可以了
我也是摸索了好几天,下了好几个版本,最终成功了cuda10.1
里面有cuda10.1+cudann,cuda10.0+cudann,cuda11.2+cudnn,有需要的自行下载
提取码:2458
tensorflow,torch详细配置见
torch.cuda.is_available()返回false——解决办法_Nefu_lyh的博客-CSDN博客
Original: https://blog.csdn.net/qq_53057371/article/details/121358408
Author: qq_53057371
Title: cuda10.1+cudnn10.1+tensorflow2.2.0+pytorch1.7.1下载安装及配置