
通过配置模型提供Servable
MindSpore Serving当前仅支持Ascend 310、Ascend 910和Nvidia GPU环境。
MindSpore Serving的Servable提供推理服务,包含两种类型。一种是推理服务来源于单模型,一种是推理服务来源于多模型组合,多模型组合正在开发中。模型需要进行配置以提供Serving推理服务。
本文将说明如何对单模型进行配置以提供Servable,以下所有Servable配置说明针对的是单模型Servable,Serving客户端简称客户端。
以ResNet-50作为样例介绍如何配置模型提供Servable。
相关概念
预处理和后处理
模型提供推理能力,模型的每个输入和输出的数据类型、数据长度、Shape是固定的。
如果客户端发来的数据不能直接满足模型输入要求,需要通过预处理转化为满足模型输入的数据。 如果模型的输出不直接提供给客户端,需要通过后处理转化为所需的输出数据。
以下图是resnet50 Servable数据流程图,描述了图像数据从Serving客户端通过网络传输到Serving,Serving进行预处理、推理和后处理,最后向Serving客户端返回结果:
针对Resnet50推理模型,客户端发来的数据为jpg、png等格式的图片,预期返回图片的分类。Resnet模型输入为经过图片Decode、Resize、Normalize等操作产生的Tensor,输出为每个类别的得分Tensor。需要通过预处理将图片转化为满足模型输入的Tensor,通过后处理返回得分最大的类别名称或者前5类别名称及其得分。
在不同的场景下,如果来自客户端的数据输入组成、结构或类型不同,可以提供不同的预处理。如果对模型的输出也有不同的要求,可以提供不同的后处理。比如上述resnet50 Servable,针对返回得分最大的类别名称还是前5类别名称及其得分这两种场景提供了两个后处理。
上述的resnet Servable提供了classify_top5和classify_top1两个方法(Method)。classify_top5输入为image,输出为label和score,返回前5的分类名称和得分。classify_top1预处理和classify_top5一致,而后处理不同,输入为image,输出为label,返回最大得分的分类名称。
一个Servable可提供一个或多个方法,Servable的名称和方法的名称标记了Serving提供的一个服务,每个方法对客户端提供的数据进行可选的预处理,接着进行模型推理,对模型的推理结果进行可选的后处理,最后将需要的结果返回给客户端。
Servable包含如下内容:
指定可选的预处理和可选的后处理;
定义方法输入、预处理、模型、后处理、方法输出之间的数据流,前者可作为后者的输入。比如方法输出的值可来源于方法输入、预处理、模型或后处理;
指定方法名,使客户端可以通过方法名指定使用的方法;
指定方法的输入和输出名称,使客户端可以通过名称来指定输入、获取输出。
每次请求可包括一个或多个实例,每个实例之间相互独立,结果互不影响。比如一张图片返回一个分类类别,三张独立的图片独立返回三个分类类别
模型配置
以Resnet50模型为例,模型配置文件目录结果如下图所示:
目录resnet50指示Servable的名称。
通过servable_config.py配置Servable,其中包括预处理和后处理定义、模型声明、方法定义。
目录1和2表示版本1和版本2的模型,模型版本为正整数,从1开始,数字越大表示版本越新。
resnet50_1b_cifar10.mindir为模型文件,Servable启动会加载对应版本的模型文件。
预处理和后处理定义
预处理和后处理定义方式例子如下:
代码如下:
import numpy as np
import mindspore.dataset.vision.c_transforms as VC
idx_2_label = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
def preprocess_eager(image):
"""
Define preprocess, input is image numpy, return preprocess result.
Return type can be numpy, str, bytes, int, float, or bool.
Use MindData Eager, this image processing can also use other image processing library,
likes numpy, PIL or cv2 etc.
"""
image_size = 224
mean = [0.4914 * 255, 0.4822 * 255, 0.4465 * 255]
std = [0.2023 * 255, 0.1994 * 255, 0.2010 * 255]
decode = VC.Decode()
resize = VC.Resize([image_size, image_size])
normalize = VC.Normalize(mean=mean, std=std)
hwc2chw = VC.HWC2CHW()
image = decode(image)
image = resize(image)
image = normalize(image)
image = hwc2chw(image)
return image
def postprocess_top1(score):
"""
Define postprocess. This example has one input and one output.
The input is the numpy tensor of the score, and the output is the label str of top one.
"""
max_idx = np.argmax(score)
return idx_2_label[max_idx]
def postprocess_top5(score):
"""
Define postprocess. This example has one input and two outputs.
The input is the numpy tensor of the score. The first output is the str joined by labels of top five,
and the second output is the score tensor of the top five.
"""
idx = np.argsort(score)[::-1][:5] # top 5
ret_label = [idx_2_label[i] for i in idx]
ret_score = score[idx]
return ";".join(ret_label), ret_score
预处理和后处理定义格式相同,入参为每个实例的输入数据。输入数据为文本时,入参为str对象;输入数据为其他数据类型,包括Tensor、Scalar number、Bool、Bytes时,入参为numpy对象。通过return返回实例的处理结果,return返回的每项数据可为numpy、Python的bool、int、float、str、或bytes数据对象。
模型声明
resnet50 Servabale模型声明示例代码如下所示:
代码如下:
from mindspore_serving.server import register
resnet_model = register.declare_model(model_file="resnet50_1b_cifar10.mindir", model_format="MindIR", with_batch_dim=True)
其中declare_model入参model_file指示模型的文件名称;model_format指示模型的模型类别,当前Ascend310环境支持OM和MindIR两种模型类型,Ascend910和GPU环境仅支持MindIR模型类型。
如果模型输入和输出第1维度不是batch维度,需要设置参数with_batch_dim=False,with_batch_dim默认为True。
设置with_batch_dim为True,主要针对处理图片、文本等包含batch维度的模型。假设batch_size=2,当前请求有3个实例,共3张图片,会拆分为2次模型推理,第1次处理2张图片返回2个结果,第2次对剩余的1张图片进行拷贝做一次推理并返回1个结果,最终返回3个结果。
另外,对于一个模型,假设其中一个输入是数据输入,包括batch维度信息,另一个输入为模型配置信息,没有包括batch维度信息,此时在设置with_batch_dim为True基础上,设置额外参数without_batch_dim_inputs指定没有包括batch维度信息的输入信息。 例如:
代码如下
from mindspore_serving.server import register
yolov_model = register.declare_model(model_file="yolov3_darknet53.mindir", model_format="MindIR",
with_batch_dim=True, without_batch_dim_inputs=1)
对于分布式模型,与非分布式单模型配置相比仅声明方法不同,需要使用mindspore_serving.server.distributed.declare_servable,其中入参rank_size表示模型推理使用的device个数,stage_size表示流水线的段数
代码如下:
from mindspore_serving.server import distributed
model = distributed.declare_servable(rank_size=8, stage_size=1, with_batch_dim=False)
方法定义
方法定义的例子如下:
代码如下:
from mindspore_serving.server import register
@register.register_method(output_names=["label"])
def classify_top1(image): # pipeline: preprocess_eager/postprocess_top1, model
"""Define method classify_top1 for servable resnet50.
The input is image and the output is label."""
x = register.add_stage(preprocess_eager, image, outputs_count=1)
x = register.add_stage(resnet_model, x, outputs_count=1)
x = register.add_stage(postprocess_top1, x, outputs_count=1)
return x
@register.register_method(output_names=["label", "score"])
def classify_top5(image):
"""Define method classify_top5 for servable resnet50.
The input is image and the output is label and score. """
x = register.add_stage(preprocess_eager, image, outputs_count=1)
x = register.add_stage(resnet_model, x, outputs_count=1)
label, score = register.add_stage(postprocess_top5, x, outputs_count=2)
return label, score
上述代码在Servable resnet50定义了classify_top1和classify_top5方法,其中方法classify_top1入参为image,出参为label,方法classify_top5入参为image,出参为label和score。即,Servable方法的入参由Python方法的入参指定,Servable方法的出参由register_method的output_names指定。
另外方法定义中:
add_stage指示了使用的预处理、模型和后处理,以及它们的输入。
return指示了方法的返回数据,可以是方法的输入或者add_stage的输出,和register_method的output_names参数对应。
用户在客户端使用Servable某个方法提供的服务时,需要通过入参名称指定对应输入的值,通过出参名称识别各个输出的值。比如客户端访问方法classify_top5:
代码如下:
import os
from mindspore_serving.client import Client
def read_images():
"""Read images for directory test_image"""
image_files = []
images_buffer = []
for path, _, file_list in os.walk("./test_image/"):
for file_name in file_list:
image_file = os.path.join(path, file_name)
image_files.append(image_file)
for image_file in image_files:
with open(image_file, "rb") as fp:
images_buffer.append(fp.read())
return image_files, images_buffer
def run_classify_top5():
"""Client for servable resnet50 and method classify_top5"""
client = Client("localhost:5500", "resnet50", "classify_top5")
instances = []
image_files, images_buffer = read_images()
for image in images_buffer:
instances.append({"image": image}) # input image
result = client.infer(instances)
for file, result_item in zip(image_files, result): # result for every image
label = result_item["label"] # result label
score = result_item["score"] # result score
print("file:", file)
print("label result:", label)
print("score result:", score)
if name == ' main':
run_classify_top5()
Original: https://blog.csdn.net/qq_36893844/article/details/121920187
Author: qq_36893844
Title: 通过配置模型提供Servable
相关阅读1
Title: cuda多版本管理和分类、运行时cuda、驱动cuda
简单的信息查看和调试命令
运行时只会采用虚拟环境里面的cuda运行时版本,所以不用显示切换cuda版本,只要支持即可。
查看cuda版本
ls -l /usr/local | grep cuda
这里是安装的cuda存放的地方和软链接的位置./usr/local/cuda是一个软链接,链接到了/usr/local/cuda-9.0(或者其他版本的目录)
nvidia-smi
它的输出是驱动的版本,并不能就是说torch实际运行时的cuda版本。
GPU的cuda版本分类
- sudo ubuntu-drivers autoinstall 安装驱动,会自带一个cuda,这个cuda是一个版本( 通过 nvidia-smi 查看)
- 从官网上下载,并安装cuda在/usr/local下,此时又是一个cuda版本( 通过 cat /usr/local/cuda/version.txt 查看)
1和2两种安装cuda方法,https://blog.csdn.net/qq_40947610/article/details/114706170
1和2两个cuda版本并存,为何不冲突?https://www.cnblogs.com/marsggbo/p/11838823.html - miniconda安装pytorch或者tensorflow也会安装另一个cuda版本( 在 /miniconda3/pkgs/cudatoolkit*)
2和3的区别,https://blog.csdn.net/qq_40947610/article/details/114707085
其他疑问
如果nvidia-smi命令列出的CUDA版本与nvcc -V列出的版本号不一致,可能是由以下原因之一引起的:
1)安装多版本cuda后,还没有刷新环境变量,刷新即可;
2)CUDA有两种API,分别是运行时API和驱动API,即所谓的Runtime API与Driver API,nvidia-smi的结果除了有GPU驱动版本型号,还有CUDA Driver API的版本号,这里是10.0,而nvcc的结果是对应CUDA Runtime API
补充说明:在安装CUDA 时候会安装3大组件,分别是 NVIDIA 驱动、toolkit和samples。NVIDIA驱动是用来控制GPU硬件,toolkit里面包括nvcc编译器等,samples或者说SDK 里面包括很多样例程序包括查询设备、带宽测试等等。上面说的CUDADriver API是依赖于NVIDIA驱动安装的,而CUDA Runtime API 是通过CUDA toolkit安装的。
多版本问题
其实nvidia-smi的cuda版本并不能唯一限制了pytorch官网能显示的版本。举个例子,pytorch官网显示

我的显卡3090的nvidia-smi输出的cuda版本是11.2。但是官网并没有给出11.2对应的编译的pytorch版本,我仍然可以用上图中的cuda11.3方式去安装。这是因为这种cuda是pytorch的运行时cuda,并不是nividia驱动全部的cuda组件版本。
下图可以看清楚对应的位置,运行时cuda只是其中的一小部分。
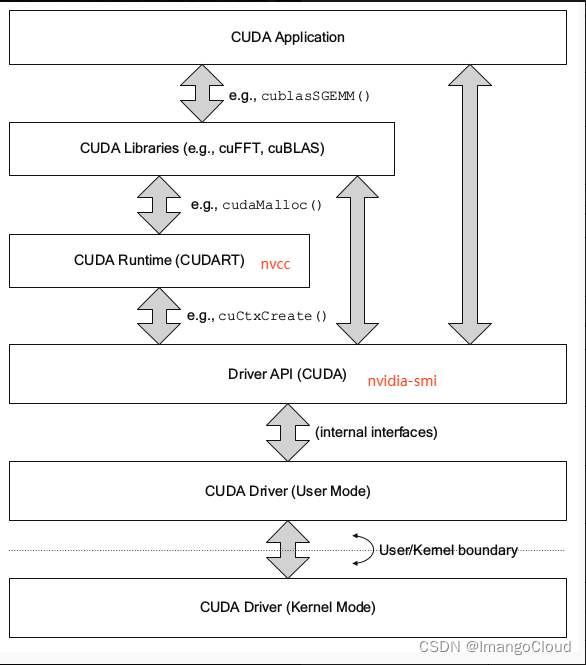
; cuda的查找顺序
- ~/.bashrc下指定的CUDA_HOME
- 默认 cuda 安装目录 /usr/local/cuda
- 如默认目录不存在(例如安装原生 cuda 到其他自定义位置),那么搜索 nvcc 所在的目录
- 如果 nvcc 不存在,那么直接寻找 cudart 库文件目录(此时可能是通过 conda 安装的 cudatoolkit,一般直接用 conda install cudatoolkit,就是在这里搜索到 cuda 库的),库文件目录的上级目录就作为 CUDA_HOME。
- 如果最终未能得到 CUDA_HOME,那么生成的 pytorch 将不使用 CUDA。
多版本cuda的管理
步骤一:/usr/local/cuda软链接设置
cuda版本分类的第2类是通常下载安装的多个不同版本的cuda路径,可以通过修改软链接的方式修改版本。
ln -s /usr/local/cuda-9.1 /usr/local/cuda
步骤二:编辑~/.bashrc文件
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export PATH=$PATH:/usr/local/cuda/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda
猜想(下面是我的猜想,可能不正确)
当在虚拟环境里面安装了指定cuda版本的pytorch之后,是不用再进行cuda版本管理的。因为它依靠的是运行时cuda。
Pytorch查看相关信息
参考链接
linux上的,多种安装方式产生的,多个cuda版本,以及执行顺序问题
conda安装的cudatoolkit, cudnn与在主机上安装的cuda, cudnn有何关系?
参考链接
参考链接2
Original: https://blog.csdn.net/qq_44108731/article/details/122747030
Author: ImangoCloud
Title: cuda多版本管理和分类、运行时cuda、驱动cuda
相关阅读2
Title: 【论文精读】Point-NeRF:Point-based Neural Radiance Fields
CVPR2022 oral的一篇文章,文章还行,代码比较乱,超参非常多且没有注释,代码也有bug
原文链接:https://arxiv.org/abs/2201.08845
代码链接:https://github.com/Xharlie/pointnerf

; Abstract
NeRF对每个场景从头开始重建太过耗费时间,基于学习的multi-view stereo(MVS)可以快速地重建一些场景。该文章把二者结合,使用MVS方法得到3D点云,用以构建辐射场。
1. Introduction & Related work
将真实场景建模并渲染出新的角度下的图片是一个计算机视觉与图形学中的关键问题。NeRF系列的论文在这一方面获得了很好的效果,使用全局的MLP通过ray marching构建radiance fields,但这个过程非常消耗时间,因为针对每个场景拟合本身就很耗时,并且还对很多大片的空旷区域进行了不必要的采样。作者应该是由此想到了使用其他方法获得初始的点云来指导NeRF。Point-NeRF 表现形式包括了一个每个点都有neural feature的点云,每个点编码了3D几何信息和点周围的环境。与以往的NeRF不同,文章将这些神经点视为 3D 中的局部神经基函数,以模拟连续的体积辐射场,从而使用可微分的ray marching实现高质量渲染。初始点云的获得使用了learning-based的MVS。
PixelNeRF和IBRNet在每个ray point添加了多视图2D图像特征用以回归体素特征,而本文利用了(leverage:杠杆作用)场景表面的3D点特征来构建辐射场,这避免了考虑空旷地区的点,从而达到更快的速度和更好的渲染效果。MVSNeRF也可以较快获得结果,但是需要3个small baseline的图片作为输入来重建局部的辐射场,本文方法却可以融合大量数目和视角的图像来更快得到。

; 2. Point-NeRF Representation
2.1 Volume rendering and radiance fields
一个pixel的radiance可以通过投射一条穿过像素的光线来计算,沿着这条光线采M个点,使用体素密度得到的累积radiance是:

其中,τ \tau τ表示volume transmittance,σ j \sigma_{j}σj 和r j r_{j}r j 是在x j x_{j}x j 处的点j的volume density和radiance,Δ t \Delta_{t}Δt 是相邻着色样本之间的距离。一个辐射场表示了任意点的volume density σ \sigma σ和与视角有关的radiance r r r,NeRF提出用MLP来回归这样的辐射场,而文章提出用点云作为替代来计算体素属性。
; 2.2 Point-based radiance field
一个点云P = { ( p i , f i , y i ) ∣ i = 1 , . . . , N } P={(p_{i},f_{i},y_{i})| i =1, ..., N}P ={(p i ,f i ,y i )∣i =1 ,...,N },其中每个点i i i位于p i p_{i}p i 并与含有局部场景信息的神经特征向量f i f_{i}f i 关联,y i y_{i}y i 是一个在[ 0 , 1 ] [0,1][0 ,1 ]之间的置信值,描述了这个点接近真实场景表面的程度。
给定任意一个3D位置x x x,查询半径R R R之内的K K K个邻近的neural points。基于点的神经辐射场可以被抽象为一个神经模块,它在任何位置x x x从其相邻位置回归volume density sigma和与视图相关的radiance r r r,表示为:

文章使用了形如PointNet的网络,用多个sub MLP来做这个回归任务。
2.3 Per-point processing
使用MLP F来处理每个相邻的神经点来为着色位置x x x预测一个新的特征向量:

原始的特征f i f_{i}f i 编码了p i p_{i}p i 周围的局部3D场景信息,这个MLP表示了一个局部3D函数,它输出了x x x处特定的神经场景描述f i , x f_{i,x}f i ,x ,由其局部帧中的神经点建模。相对位置x − p x-p x −p的使用使得网络对于点的平移不变,从而拥有更好的泛化性能。
; 2.4 View-dependent radiance regression
使用标准的inverse distance weighting(反距离加权)来聚合特征f i , x f_{i,x}f i ,x 以得到描述x x x位置场景信息的单个特征f x f_{x}f x :

然后一个多层感知机R从这个特征和一个给定的视图方向d回归视图相关的radiance:

反距离权重w i w_{i}w i 被广泛运用于稀疏数据的插值。文章使用它来聚合神经特征,使得更近的神经点为着色计算贡献更多。此外,使用了每个点的置信度y i y_{i}y i ,这在最后的重建中被sparsity loss优化,这使得网络能够拒绝不必要的点。
Tips: 什么是反距离加权?
假设:彼此距离较近的事物要比彼此距离较远的事物更相似。当为任何未测量的位置预测值时,反距离权重法会采用预测位置周围的测量值与距离预测位置较远的测量值相比,距离预测位置最近的测量值对预测值的影响更大。反距离权重法假定每个测量点都有一种局部影响,而这种影响会随着距离的增大而减小。由于这种方法为距离预测位置最近的点分配的权重较大,而权重却作为距离的函数而减小,因此称之为反距离权重法。
2.5 Density regression
为了计算位置x x x处的volume density σ \sigma σ,先使用多层感知机T来回归σ i \sigma_{i}σi 然后使用反距离权重:

如此一来,每个神经点直接对volume density(体素密度)作出贡献,置信度也显式地与贡献关联,这一点在后续的除点操作中很有用。

; 3. Point-NeRF Reconstruction

3.1 Generating initial point-based radiance fields
给定一组图像I 1 , . . . , I Q I_{1}, ..., I_{Q}I 1 ,...,I Q ,和一个点云,Point-NeRF可以通过优化神经特征和多层感知机重建。现在先想办法快速得到一个初始点云,然后在基于点的辐射场上fine-tune就能快很多了。这一块先介绍了learning-based MVS的流程,Point-NeRF其实可以对接各种获得稠密点云的方法,而不仅仅是MVSNet。
获得点云之后,因为深度置信度描述了点在表面上的可信度,所以为了得到每个点p i p_{i}p i 的置信度y i y_{i}y i ,对MVSNet中的深度置信体进行tri-linearly sample:

G p , y G_{p,y}G p ,y 是基于MVSNet的网络,I q n I_{q_{n}}I q n 和ϕ q n \phi_{q_{n}}ϕq n 是MVS重建过程中使用的图片的邻域帧,在大部分案例中采用2个就够了。
使用2D CNN G f G_{f}G f 来从每个图片I q I_{q}I q 中提取特征图,这些特征图与G p , y G_{p,y}G p ,y 出来的点(深度)预测对齐并被直接用来预测每个点的特征f i f_{i}f i :

G f G_{f}G f 采用了带有3个下采样层的VGG网络。
; 3.2 Optimizing point-based radiance fields
前面的步骤,我们得到了一个可靠的初始point-based radiance field,再通过可微分的ray marching,我们可以进一步优化神经点云(点特征f i f_{i}f i 和点置信度y i y_{i}y i )和MLP来提升辐射场。初始的点云往往有空洞或离群点,这会影响到渲染质量。在对场景的优化中,为了解决这个问题,文章发现直接优化现存点的位置会让训练不稳定并且并不能填补大空洞,于是,文章使用了point pruning和growing来逐步提升几何模型和渲染质量。
Point pruning
Point置信度y i y_{i}y i 描述了神经点是否离表面很近,文章使用这些置信度来修剪不必要的离群点。注意到点置信度与每个点在volume density regression中的贡献直接相关,因此,低置信度反映了一个点局部区域的低体素密度,很有可能这里就是空的。因此,每10000 10000 1 0 0 0 0次迭代就删去y i < 0.1 y_{i}的点。文章在这里也引入了一个loss,在点置信度上引入的loss函数如下:

优化这个loss能强制yi尽量趋近于0或者尽量趋近于1。
; Point growing
文章利用在光线行进中采样的每条光线着色位置x j x_{j}x j 来识别新的候选点。具体来说,确定沿光线不透明度最高的着色位置 x j g x_{j_{g}}x j g :

计算ϵ j g \epsilon_{j_{g}}ϵj g 作为x j g x_{j_{g}}x j g 到最近的神经点的距离。
如果α j g > T o p a c i t y \alpha_{j_{g}}>T_{opacity}αj g >T o p a c i t y 且ϵ j g > T d i s t \epsilon_{j_{g}}>T_{dist}ϵj g >T d i s t ,则生成一个新点 x j g x_{j_{g}}x j g 。这表明这个位置距离表面很近但离其他神经点比较远,通过重复这个步骤,神经场能够被扩大以覆盖初始点云中缺失的区域。这种方法对于较为稀疏的点云尤为有效。
4. Implementation details
Network details
在G f G_{f}G f 里的三个层级多尺度特征提取时,向量是56 ( 8 + 16 + 32 ) 56(8+16+32)5 6 (8 +1 6 +3 2 )通道。最终的每个点的神经特征是59 59 5 9通道的向量。
Training and optimization details
整个pipeline在DTU数据集上训练。先预训练MVSNet深度生成网络,然后训练整个渲染的网络,使用L 2 L2 L 2 rendering loss。文章声称前向传播只需要0.2 s 0.2s 0 .2 s就由3 3 3个视图能生成点云。
在对每个场景优化的阶段,loss函数如下:

; 5. Experiments
在DTU、NeRF Synthetic、Tanks&Temples和ScanNet数据集上实验,并与其他方法进行了对比,效果很好。
此外,还做了一些额外的实验,将COLMAP重建得到的稀疏点云交给网络,迭代150 k 150k 1 5 0 k次后变得很稠密,验证了点云剪枝和生长的有效性。

6. Conclusion
文章将MVS与NeRF结合,更快地得到了初始点云,并引入了点云的修剪与生长算法,加速了重建与渲染速度,提升了质量。
Original: https://blog.csdn.net/YuhsiHu/article/details/123939121
Author: YuhsiHu
Title: 【论文精读】Point-NeRF:Point-based Neural Radiance Fields
相关阅读3
Title: 深度学习与TensorFlow:TensorFlow最佳环境配置
TensorFlow是由Tensor和Flow两个英文单词构成。谷歌公司首款智能芯片命名为Tensor(2021年推出),它可以构建构建适应未来的 AI/ML(人工智能/机器学习)各种应用需求。TensorFlow在2015年由谷歌公司推出,用于各类机器学习算法的编程实现。Tensor芯片推出时间要比TensorFlow晚,谷歌将首款智能芯片命名为Tensor,应该是配合TensorFlow拓展AI/ML应用市场。
Tensor原意是张肌(医学)、张量(化学),对TensorFlow来说,Tensor是张量,张量是一个可用来表示一些矢量、标量和其他张量之间的线性关系的多线性函数。在TensorFlow中,张量是标量、矢量、矩阵、多维数据等数据类型。Flow是流动、持续的意思。由此可见,TensorFlow是标量、矢量、矩阵、多维数组等数据在多个处理节点持续流动和被处理。
TensorFlow是用于开发机器学习应用的计算框架,在基于核心库的基础上,它对外提供了针对不同编程语言的开发接口,支持Python、C++、Java等编程语言开发和训练机器学习模型。TensorFlow对Python的支持最为完善,相关帮助文档和学习教程最为丰富,开发实例容易获取。另外还有比较重要的一点,Python在数值计算、图像视觉处理、数据处理等方面有得天独厚的第三方库优势,这些库都是机器学习必不可少的构件,相对C++、Java语言来说,使用Python学习TensorFlow可以快速提升你的学习曲线。
学习TensorFlow的最佳配置环境如下图所示。
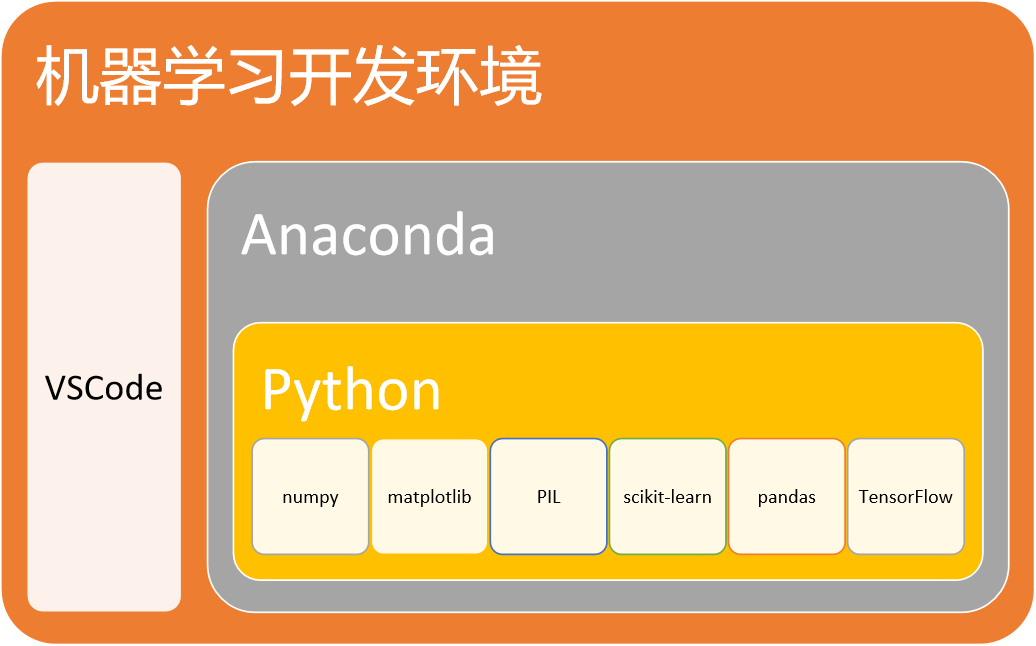
图 1-1学习TensorFlow最佳配置环境
Anaconda可以创建基于Python的虚拟开发环境,它允许在同一机器上创建几个相互独立的Python开发环境,隔离不同项目所需的不同版本的工具包,有效防止版本的冲突。例如:我们可以在同一机器上创建基于TensorFlow-cpu和TensorFlow-gpu两个版本的TensorFlow开发学习环境,观察和研究CPU模式和GPU模式在训练和部署机器学习模型上的差异。
VSCode是一款代码编辑器,编程环境对开发者非常友好,编写代码过程中的语法帮助、代码排版和美化方面做的还是不错的,用VSCode做机器学习的代码编辑器,可以省掉代码优化排版、Python语法错误排查等费时费力的工作。
numpy是数值计算库,多用于矩阵和多维向量的数值计算,同时提供了大量数值计算函数,可以解决机器学习中大量数值计算的问题。
matplotlib是一个数据可视化库,主要用于对机器学习中的数据进行可视化处理,将数据以图表方式展现出来,便于观察和分析数据。
PIL是图片处理库,开发基于图像识别等机器学习程序时,需要使用该库对图片进行切片、过滤、灰度化等图像处理操作。
Pandas是对数据进行处理的工具,机器学习中需要大量的对数据进行处理的操作,通过该工具可以对数据进行快速建模。
scikit-learn也是常用的机器学习库,不同于tensorflow,它不是深度学习。它擅长传统的机器学习方法。那么传统的机器学习和深度学习有什么区别呢?下面给出一个传统的机器学习案例。
建立人口自然增长率预测模型
下表是国民总收入、人均GDP和居民消费价格指数及人口自然增长率部分数据集。
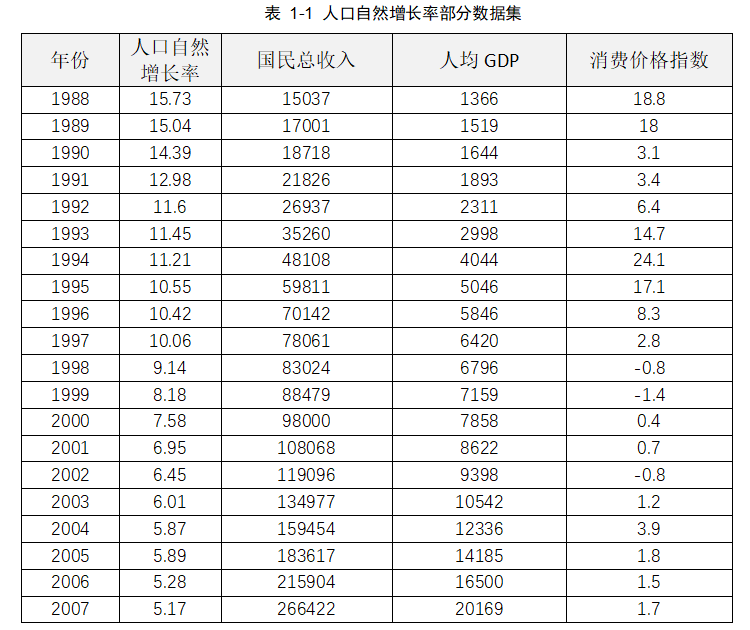
要求编写一个机器学习应用程序,为中国人口自然增长率建立预测模型,该模型根据国民总收入、人均GDP和居民消费价格指数三个因素来预测中国人口自然增长率,这三个因素也称为样本特征。
有了学习数据集,就要考虑设计学习算法了。学习算法是从学习数据集找出数据集变量间的函数关系,即建立预测模型(函数模型)。
在身高预测体重案例中,其数据集有两个变量:身高和体重,体重是因变量,身高是自变量,建立的函数关系是一元一次函数,变量间的关系是线性关系。
在预测人口自然增长率案例的数据集中,有四个变量,其中人口自然增长率是因变量,国民总收入、人均GDP、消费价格指数是自变量,学习算法要建立的函数关系是多元函数,是多元一次函数,还是多元二次函数,......,需要我们通过散点图来发现因变量与多个自变量间的关系。
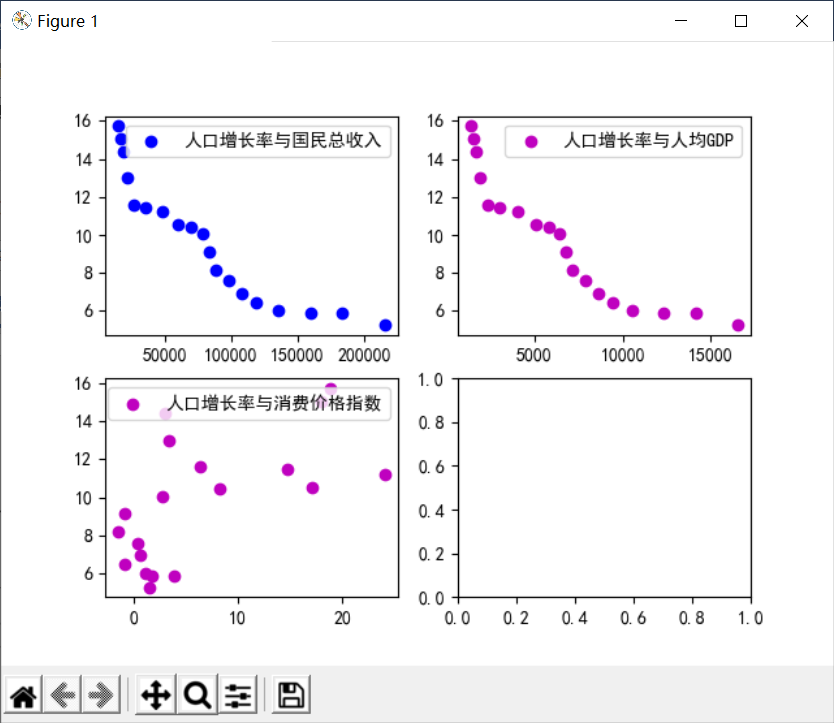
图 1-2 人口自然增长率关系图
从散点图可以看出,人口增长率与国民总收入、人均GDP呈现较好地线性关系,人口增长率与消费价格指数线性关系较弱,在本案例中,可以认为它们具有一定的线性关系。
由此,人口增长率与国民总收入、人均GDP、消费价格指数的线性关系可以假设用下面的多元线性回归模型来表示:
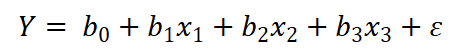
通过学习算法确定回归模型系数值的活就由scikit-learn来做了,可见在传统机器学习中,特征数据和模型的设定一般是由人工来完成的。
在机器学习领域,有很多机器学习任务并不适合从已知数据中提取特征数据,然后将这些特征数据提供给机器学习算法。例如,假设我们要编写一个对服装图像进行分类的程序,使用传统的机器学习方法就会存在问题,因为我们难以准确地根据像素值来描述服装图像数据的特征。解决这个问题的途径之一是使用深度学习技术,深度学习类似于人通过眼睛来识别服装图像并进行分类,深度学习会通过像素值识别出边,再由边识别出角和轮廓,然后进一步识别出图像中的服装,其图像识别过程由简单到复杂,由简单到复杂的识别过程不是一挥而就的,而是分成多个识别层,每个识别层输入的数据是前一层输出的数据,最后的识别层会输出识别出的服装所属的类别。
tensorflow提供了一个对服装图像进行分类的案例,该案例训练一个神经网络模型,对运动鞋和衬衫等服装图像进行分类。
案例提供了训练和测试用的数据集,该数据集包含 10 个类别的 70,000 个灰度图像。这些图像以低分辨率(28x28 像素)展示了单件衣物,如图1-3所示。

图 1-3服装灰度图像
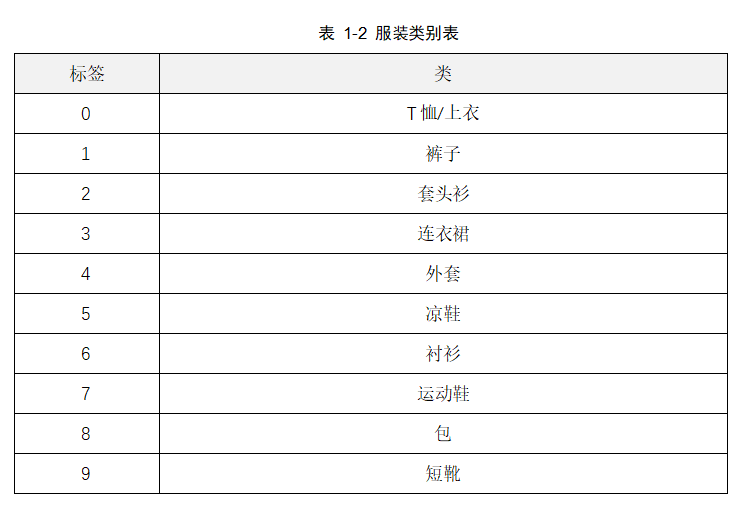
数据集还包括了一个服装类型的标签数组,数组的每个值介于0~9之间,这些标签对应于图像所代表的服装类。如表1-2所示。
训练该神经网络模型需要向模型传送上面的数据集,模型学习将图像和标签关联起来。该模型的基本组成部分是层,层会从向其传送的图像数据中提取表示形式(类似于人的眼睛,从图像数据提取特征数据),该网络的第一层将图像数据从二维数组(28 x 28 像素)转换成一维数组,然后是密集连接或全连接神经层,最后一个层会返回一个数组,该数组存储了当前图像属于各个类别的得分,用来表示当前图像属于 10 个类中的哪一类。
现在我们已经了解了学习和编写深度学习程序最佳的环境配置,马上开始TensorFlow学习与实践之旅。

Original: https://blog.csdn.net/langhonglin/article/details/124448772
Author: langhonglin
Title: 深度学习与TensorFlow:TensorFlow最佳环境配置