
数据介绍
Clifar 10 数据集
5w张 32x32 的图片 训练
1w张 32x32 的图片 测试
输入是分为10个标签,下面的图的左边已经给出了。

; 导入数据集

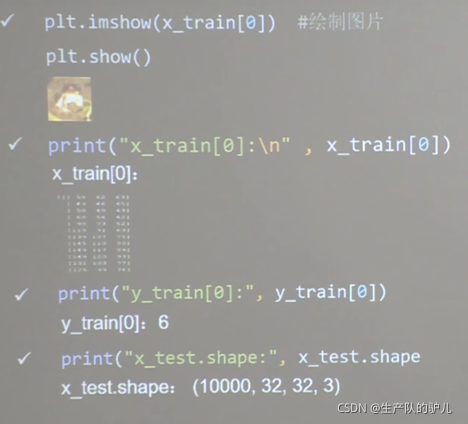
可视化一张图片看看
打印出 x的第一张图片的像素点看看
打印出 x的第一张图片对应的输出分类结果
查看 测试集的整体大小 1000张 32x32像素 3通道的图片集合
搭建卷积神经网络
口诀:CBAPD
一层卷积:5x5卷积核,一共有6个
2x2的卷积池,步长为2
两层全连接
第一次层128个神经元
第二层 10分类问题,输出10神经元的全连接层

下图是详细解释

搭建网络
class Baseline(Model):
def __init__(self):
super(Baseline,self).__init__()
self.c1 = Conv2D(filters = 6, kernel_size =(5,5), padding = "same")
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.p1 = MaxPool2D(pool_size=(2,2),strides=2,padding='same')
self.d1 = Dropout(0.2)
self.flatten = Flatten()
self.f1 = Dense(128,activation='relu')
self.d2 = Dropout(0.2)
self.f2 = Dense(10,activation='softmax')
def call(self,x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.d1(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d2(x)
y = self.f2(x)
return y
model = Baseline()
模型配置参数
model.compile(optimizer=keras.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
指定模型输入
model.build(input_shape=[None, 32, 32, 3])
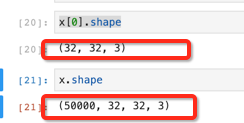
查看一张图片的形状和通道情况
x[0].shape
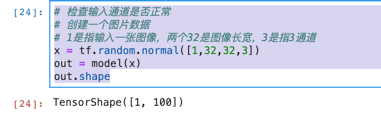
自己创建一个x
看一下通过模型的输出是否符合
x = tf.random.normal([1,32,32,3])
out = model(x)
out.shape
给模型导入数据,进行训练
train_db 是打包了的训练集
validation_data 是打包了的测试集
history = model.fit(train_db,epochs=5,validation_data=test_db)
查看模型结构
model.summary()
查看模型的检验数据
比如 loss 或者 acc
history.history()
绘制 loss 或acc随着迭代次数的变化图
如果有loss的话就绘制loss的变化
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(20,10))
plt.subplot(1,2,1)
plt.plot(loss,label='Trainning loss')
plt.plot(val_loss,label='Validation loss')
plt.legend()
plt.grid()
plt.title('loss')
如果有acc就绘制acc的变化
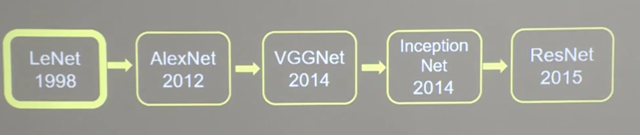
经典卷积网络
Original: https://blog.csdn.net/weixin_46969441/article/details/121463444
Author: 生产队的驴儿
Title: CNN卷积神经网络 入门案例
相关阅读1
Title: TensorFlow、PyTorch各版本对应的CUDA、cuDNN关系
TensorFlow、PyTorch各版本对应的CUDA、cuDNN关系(截止2021年4月7日)
- TensorFow
* - Linux
- - macOS
- - Windows
- - PyTorch
* - CPU
- GPU
- cuDNN与CUDA
- CUDA和NVIDIA显卡驱动关系
因为之前tensorflow、pytorch配环境在cuda上吃过很多亏,主要是版本不匹配造成的,所以自行整理了对应关系,资料均来自官网。
TensorFow
官网:https://www.tensorflow.org/?hl=zh-cn
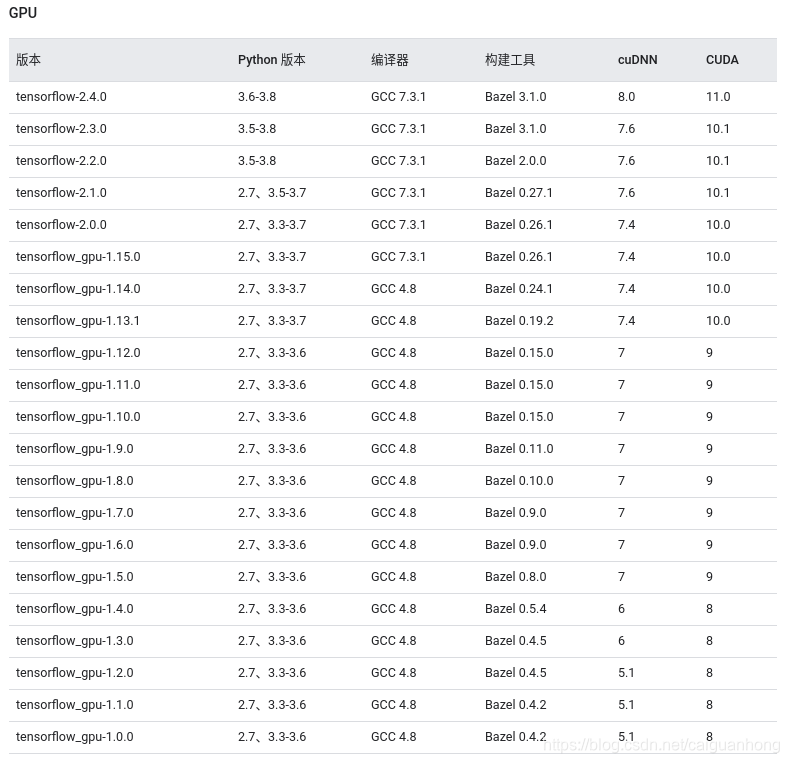
Linux
CPU
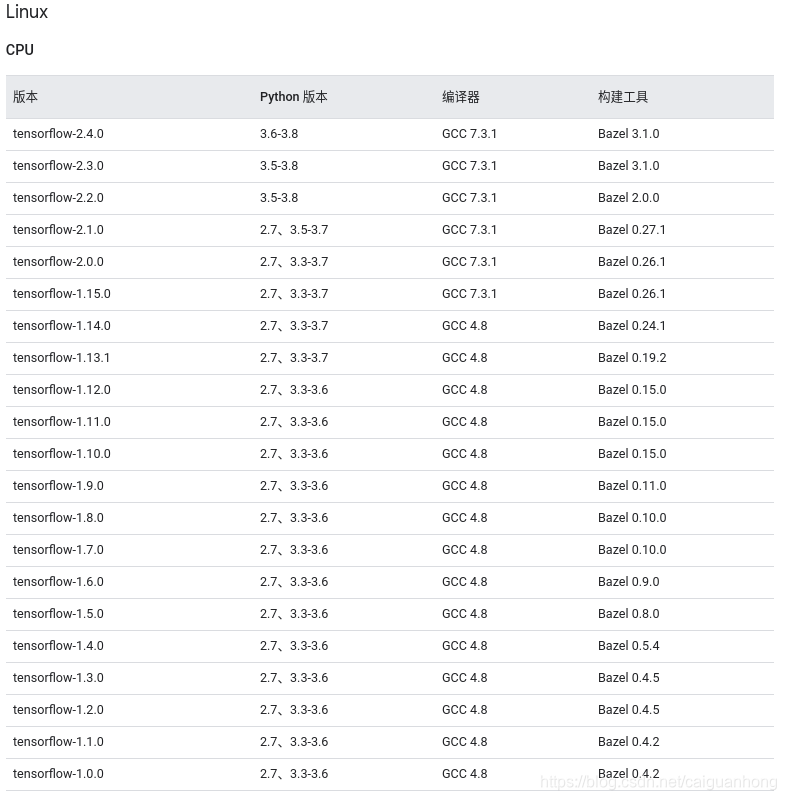
; GPU
macOS
CPU
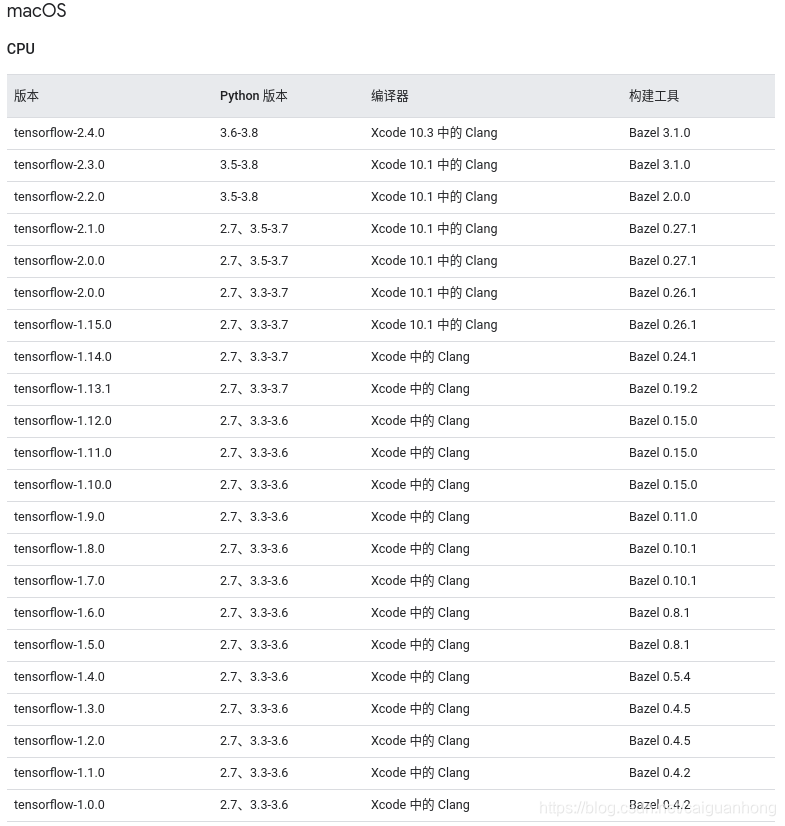
; GPU

Windows
CPU

; GPU
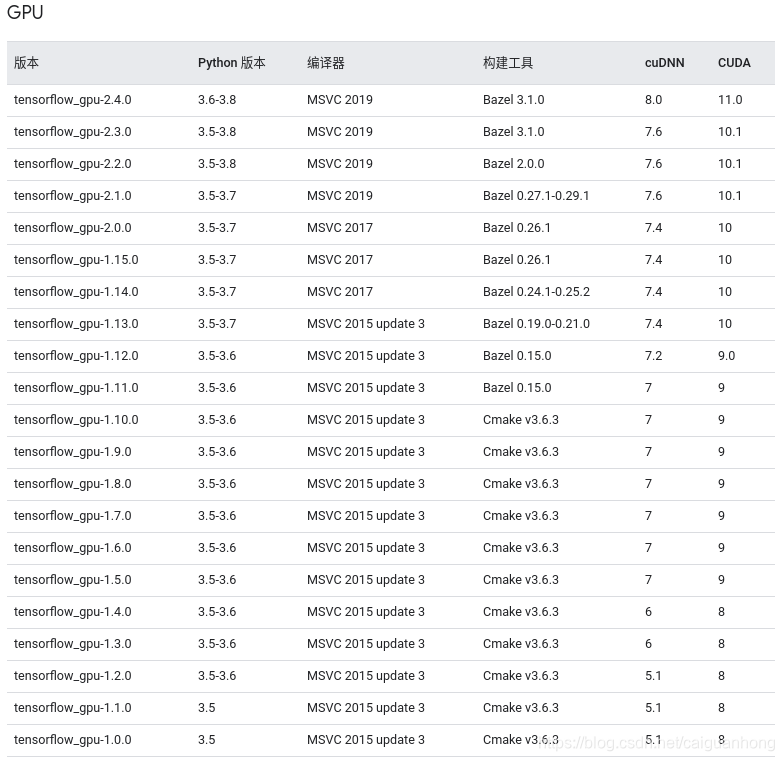
PyTorch
PyTorch官网:https://pytorch.org/
PyTorch历史版本:https://pytorch.org/get-started/previous-versions/
CPU
PyTorchtorchvision1.8.00.9.01.7.10.8.21.7.00.8.01.6.00.7.01.5.10.6.11.5.00.6.01.4.00.5.01.2.00.4.01.1.00.3.01.0.10.2.21.0.00.2.1
GPU
PyTorchCUDAtorchvision1.8.010.2、11.10.9.01.7.19.2、10.1、10.2、11.00.8.21.7.09.2、10.1、10.2、11.00.8.01.6.09.2、10.1、10.20.7.01.5.19.2、10.1、10.20.6.11.5.09.2、10.1、10.20.6.01.4.09.2、10.10.5.01.2.09.2、10.00.4.01.1.09.0、10.00.3.01.0.19.0、10.00.2.21.0.08.0、9.0、10.00.2.1
cuDNN与CUDA
官网:https://developer.nvidia.com/rdp/cudnn-archive
cuDNNCUDA8.1.011.2、11.1、11.0、10.28.0.511.1、11.0、10.2、10.18.0.411.1、11.0、10.2、10.18.0.311.0、10.2、10.18.0.211.0、10.2、10.18.0.111.0、10.27.6.510.2、10.1、10.0、9.2、9.07.6.410.1、10.0、9.2、9.07.6.310.1、10.0、9.2、9.07.6.210.1、10.0、9.2、9.07.6.110.1、10.0、9.2、9.07.6.010.1、10.0、9.2、9.07.5.110.1、10.0、9.2、9.07.5.010.1、10.0、9.2、9.07.4.210.0、9.2、9.07.4.110.0、9.2、9.07.4.010.0、9.2、9.07.3.010.0、9.07.2.19.2
CUDA和NVIDIA显卡驱动关系
官网:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html

Original: https://blog.csdn.net/caiguanhong/article/details/112184290
Author: C_GH
Title: TensorFlow、PyTorch各版本对应的CUDA、cuDNN关系
相关阅读2
Title: 文本处理环境配置
第一步:安装相应软件
根据自己电脑的配置去官网依次安装python、pycharm和anaconda,我自己的是macbook pro,自身没有GPU,但是我也用win,自己对比下来,mac系统在环境配置上比win方便,具体下来就是环境变量.
下面我更多展示的是mac电脑的操作,win版本的我以后会照着做一遍吧.
第二步:配置镜像源
打开终端,依次输入:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
第三步:安装tensorflow
输入命令:conda create -n tensorflow
等出现y/n时选择y,创建完成后,可以根据提⽰使⽤ conda activate 环境名 进⾏环境的激活.
(tensorflow) MacBook-Pro ~ % conda list
我的已经装好了,会显示环境下安装好的包:
packages in environment at /opt/anaconda3:
#
Name Version Build Channel
_ipyw_jlab_nb_ext_conf 0.1.0 py38_0
alabaster 0.7.12 pyhd3eb1b0_0
anaconda 2021.05 py38_0
anaconda-client 1.7.2 py38_0
anaconda-navigator 2.0.3 py38_0
anaconda-project 0.9.1 pyhd3eb1b0_1
anyio 2.2.0 py38hecd8cb5_1
appdirs 1.4.4 py_0
applaunchservices 0.2.1 py_0
由于里面的东西有点多,只显示一部分
第四步:tensorflow安装
使⽤在tensorflow环境下使用 conda install tensorflow=1.14命令
(tensorflow) MacBook-Pro ~ % conda install tensorflow=1.14
稍等后输入y,然后去打麻将......
第五步:pytorch安装
重复上面的步骤
创建环境 conda create -n torch、
激活环境 conda activate torch、
看环境 conda list
第六步:torch安装
注意:torch⽐较特殊,不能安装tensorflow一样,必须进入pytorch官网找命令
pytroch官⽹:https://pytorch.org/get-started/locally/
一般给出的安装代码会有 -c pytorch 后缀,建议去掉,不然不会转入镜像下载,影响速度
根据自己的配置进行安装,
安装完毕后输入conda list看看是否安装成功,
没问题就,结束收工!!!
如果不放心,在bace环境中输入命令conda info --env,会有如下显示:
(base) MacBook-Pro ~ % conda info --env
conda environments:
#
base * /opt/anaconda3
pythonProject /opt/anaconda3/envs/pythonProject
tensorflow /opt/anaconda3/envs/tensorflow
torch /opt/anaconda3/envs/torch
(忽略第二个)那么恭喜你,环境配置完成,可以睡觉了
Original: https://blog.csdn.net/WuGuo12138/article/details/123468414
Author: 理想程
Title: 文本处理环境配置
相关阅读3
Title: CONTINUAL SELF-TRAINING WITH BOOTSTRAPPED REMIXING FOR SPEECH ENHANCEMENT
题目:CONTINUAL SELF-TRAINING WITH BOOTSTRAPPED REMIXING FOR SPEECH ENHANCEMENT
时间:2021.10
作者:Efthymios Tzinis1,∗, Yossi Adi2, Vamsi K. Ithapu3, Buye Xu3, Anurag Kumar3
机构:University of Illinois at Urbana-Champaign, 2Facebook AI Research, 3Facebook Reality Labs Research
摘要:
我们提出了Remix IT,一个简单并创新的语音增强自监督训练方法。此方法基于连续自训练模式,这种模式克服了之前研究中的限制,包括域内噪声分布的假设和可获得的纯净语音目标。具体来说,首先在域外数据集上(OOD)预训练一个分离模型。并把他用于推断每个batch中域内mixture的估计目标信号,然后,通过使用排列的估计的干净和噪声信号生成人工mixture。最后,学生模型使用permuted 估计源作为目标训练模型,同时我们使用最新的学生模型周期性更新老师的权重。实验表明RemixIT在多语音增强任务下超越了之前最新的自监督方法,另外,RemixIT在语音增强任务中,在半监督和无监督之间实现了无缝连接,而且本方法能够应用在任何分离任务和分离模型一起使用。
引言:
神经网络已经被发现可以被高效并且广泛应用于大量语音任务上,包括语音增强,语音增强的目的是提升带噪语音的质量和可懂度。最近,有监督的,实时的,半监督的语音增强方法相继出现。大部分方法都是有监督的,训练这样的模型需要大量大量音频数据,并且期望这些训练数据可以和测试数据的分布相匹配,有限的监督数据虽然可得,使用这些数据训练的有监督模型由于不匹配测试数据的分布,测试时性能下降。
为了解决这些问题,减少对于纯监督数据的依赖,一些语音增强和声源分离方法转向了自监督的方法。在[5]中,训练模型估计带噪语音的SNR,并且为每个带噪片段设置一个置信值。其次,分离模型使用权重重构损失过滤带噪真实语音。最近提出的Mix IT已经能够i实现无监督分离,通过人工混合mixture of mixture,并且使分离模型估计和重新排列源混合物。MixIT提供了鲁棒性的无监督解决方法,语音增强方法中也有follow它的,然而,Mix IT假设能获得域内噪声类型并且能够改变输入数据的SNR分布通过在人工MoMs使用多于一种的噪声类型。
教师-学生模型已经在语音任务上表现出很大提升,包括:学生模型在预训练的MIx IT模型的输出上训练,解决了在训练集和测试集分布上,人工创造的SNR不匹配的问题。使用一个能力阈值减少出现在带噪语音的源数量,而且,此外,学生模型可以适应给定的测试集使用回归预先训练的教师的估计。与我们的工作最接近的自训练框架是一个半监督歌声分离,它使用教师在域外监督数据预训练,用来估计更大的域内带噪数据的源。带有新标签的数据集对低质量的分离源进行过滤,并存储为一个新的学生模型的离线训练,使用人工生成的来自估计的自标记估计源的混合物。之前的大部分方法都是冻结教师模型,在ASR上有一些使用moving mean teacher来更新教师模型表现出很大的提升。
本文章中,我们提出了自训练方法,能够在大的域内带噪数据集上进行自学习,仅仅要求域外预训练教师模型(Mix IT on an OOD dataset),与文献中使用ad-hoc 过滤程序来提高教师模型估计的质量的自我训练方法相比,我们的方法通过执行线上remix教师的估计源,而且,我们不冻结教师,RemixIT将自训练过程看作一个终身学习的过程使用连续,移动平均更新模式,者能够更快收敛,我们的实验证明了对自我监督语音增强的普遍适用性,半监督OOD泛化和zero-shot自适应
方法

我们提出了语音增强的一般情况,其目标是从一个有噪声的语音信号重建干净的语音。
分离模型:fs
输出:M个声源
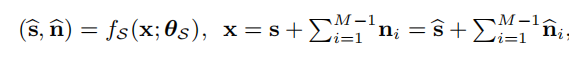
估计的speech,s 纯净语音目标,估计的噪声信号,n:噪声目标
估计的语音加估计的噪声等于纯净语音+噪声使用mixture consistency layer
MixIT:
MixIT已经在不同的自监督增强方法中证明了他的有效性,Mix IT假设训练集是由两部分组成(Dm,Dn),Dm是数据集的一部分,包含了语音和一种噪声的带噪语音,Dn包含了分离的噪声,在训练中,人工合成的MoM:x=s+n1+n2,通过从Dm采样一个batch的带噪语音m,从Dn中采样一个batch的噪声n2,其中m=s+n1,分离模型会估计三个源:s,n1,n2,使用PIT loss最小化第b个输入MoM
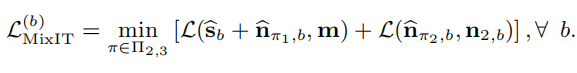
然而,MixIT假设可以获得域内分离的噪声,这种情况在现实中是不现实的,我们不能总是能够使噪声分布与可用的噪声集Dn相匹配,并且可能需要和有点的监督数据一起使用。有数据增强方法提出:从域外噪声集注入一种噪声源到MoM中效果会得到提升,然而,这种方法的性能仍然依赖于在实际噪声分布与Dn之间的分布位移水平。
使用bootstrapped remix连续自训练
RemixIT不假设能够获得域内信息,因此我们仅仅从域内带噪数据集m=s+n描述mixture,域内带噪数据集包含一个单一的噪声源,m,s,n.RemixIT利用学生老师架构,通过排列之前的带噪估计重新混合,并且将他们作为训练目标。
RemixIT的连续自训练框架
我们假设可以使用监督或者自监督方法在域外数据集上预训练教师模型D',第一步是使用教师模型对给定的mixture batch估计新的带噪目标,m=s+n1
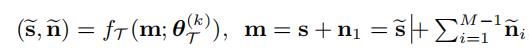
k是优化步骤,如果教师模型通过有监督OOD预训练得到的,(无监督使用MIx IT),会有M=2,M=3个输出,其次,我们使用估计得到的源生成新的noisy mixture,如下:
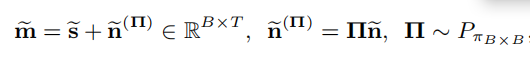
现在,我们使用排列的目标对训练学生模型
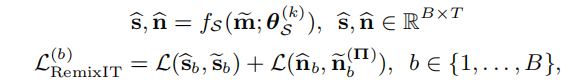
所提方法的损失函数与常规的监督学习中的信号级别的损失函数类似。我们的方法不会人工改变输入SNR的分布(Mixit就是这样做的),取而代之,学生模型使用相同数量的源(bootstrapped mixture),教师模型已经充分训练好。不同于之前的学生-老师模型,他们使用老师估计的相同的声源对作为学生网络的目标,提出的bootstrapped mixture增加了学生输入的多样性,可以更快的训练模型。Remix IT使用终身学习的训练方法,而不是冻结老师模型,使用静态的线下自标注数据集,分开训练学生模型。我们的方法能够与任何线上联合训练的方法一起使用,除了主要的学生模型训练之外连续更新教师模型权重
欧几里得标准下的误差分析
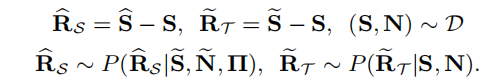
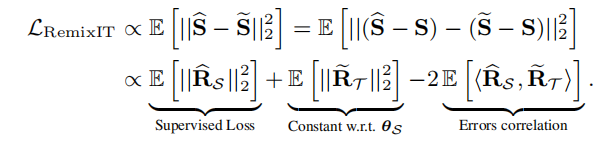
理想情况下,最后一项内积为0,如果教师产生的输出与干净的目标信号中或者上一个公式中的条件误差分布是独立的。直观地说,当我们不断更新教师模型和改进他的输出时,我们最小化了教师误差的范数,另外,这种方法强迫误差更加不相关,因为学生试图重构相同的干净语音信号,类似于他的老师,但是在不同的mixture分布下。学生努力重构s当观察bootstrapped mixture m=s+n~,而教师努力重构s从初始输入mixture m=s+n.
; 实验
数据集:
DNS2020,由64649和150对干净语音和噪声训练和测试,这个数据集用于验证方法的有效性在利用大量带噪语音
LibriFSD50K (LFSD):本研究主要将该数据集用于语音增强模式的OOD无监督或半监督预训练
WHAM!:这个数据集作为一个中等规模的数据集,其中有20,000个训练噪声语音对和3,000个测试mixture
VCTK:使用了他的测试集部分
分离模型
这里重点强调提出的方法可以和任何分离模型一起使用,我们选择了sudo-rm -rf架构,因为它在语音增强质量和时间内存计算要求之间实现了很好的权衡。实验中,我们将新的学生网络的深度增加到16和32。我们为MixIT模型或M=2固定了M=3的输出。
RemixIT 设置
对于无监督RemixIT,我们假设初始的教师模型使用Mix IT在特点的OOD数据集上预训练。对于半监督RemixIT,使用PIT预训练,我们还实验了各种在线教师更新协议,如
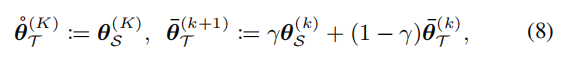
k是训练epoch数,对于顺序更新的老师,每20个epoch用最新的学生替换原来的老师。对于zero-shot域自适应实验,首先将学生和老师的参数设置为一样,然后使用moving average 以0.01更新教师
训练和测试细节
尽管我们能够使用有效的信号级别的loss,我们选择-SI-SDR
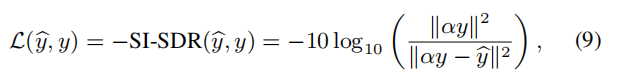
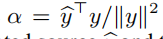
使损失与估计的源y^和目标信号y的尺度不变,
; 结果
教师估计的持续改进
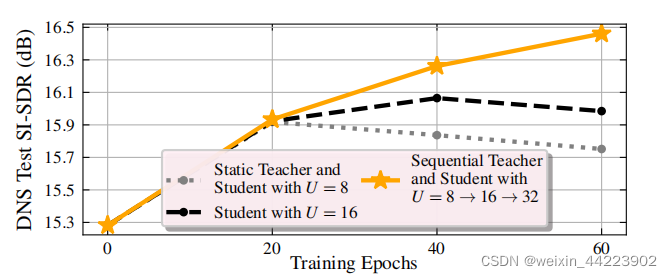
这是使用具有不同的教师更新策略的RemixIT,所有的方法都使用与U=8相同的教师架构,使用WHAM的训练分割,以一种有监督的方式进行预先训练!
连续更新教师模型:每20个epoch用之前的学生模型取代教师,与使用相同的静态教师的方法相比,能够获得显著的改进。在半监督RemixIT设置中,学生模型超越初始的OOD上预训练的教师,在SI-SDR上提升了1DB。
我们的实验结果验证了假设,即语音增强模型可以在教师将与学生并行更新的终身学习过程中更快更有效地训练。顺序更新和冻结的教师方法所获得的语音增强性能如图上所示,在第20个epoch之前,两种策略是一样的,教师是静态的。在20个epoch之后,教师被最新的学生所取代,而下一个学生的深度增加,8→16。结果,连续更新的方法在40个epoch之后表现更好相比于冻结教师。顺序更新的教师规模比其他方法更好,这是我们在所有其他实验中使用的默认策略,除了零镜头适应,我们也表明,运行意味着教师更新方案也是一个有效的选择
自监督和半监督语音增强
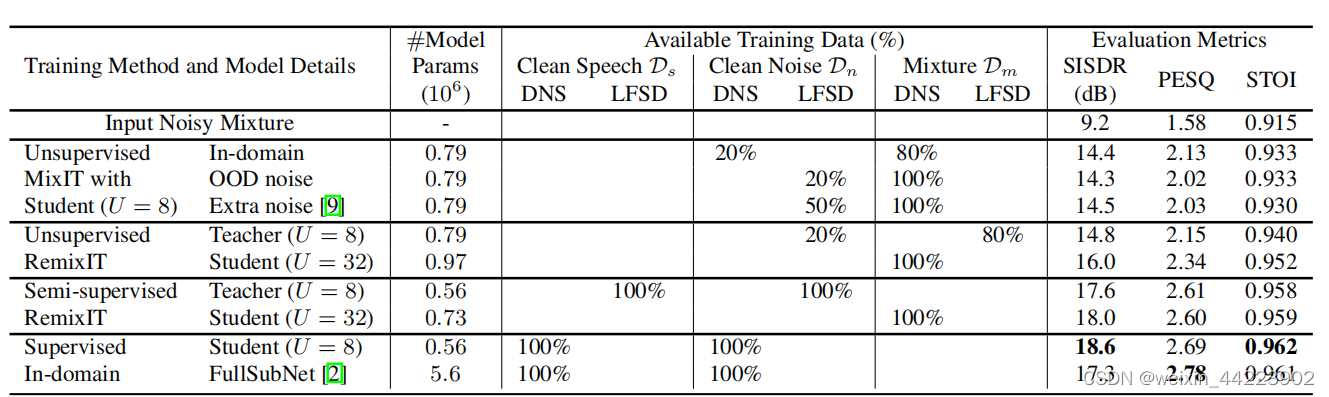
在DNS测试集上的语音增强性能,方法有所提出的RemixIT、无监督MixIT、有监督域内训练,全部使用相同的Sudorm-rf模型(U=8)、和fullsubnet
表中%是指从DNS或者LFSD使用成对的数据。例如:无监督的RemixIT预训练老师模型要求无监督MixIT使用80%的LFSD数据对模拟带噪语音D'm其他20%用于干净OOD噪声Dn,而学生模型利用整个DNS带噪数据集
注意无监督和半监督RemixIT不依赖于干净的域内噪声样本,尽管如此,无监督的学生模型显著优于所有类似于mixit的方法,包括域内训练和最近提出的额外噪声增强方法(MoMs包含3种噪声源),此外,最大的无监督学生(U=32)在所有评估指标上都远远优于其OODMixIT无监督教师,这显示了RemixIT对自我监督设置的有效性。该方法在半监督下也产生了显著的提升,学生模型与使用U=8的默认Sudorm-rf模型和最近的最新模型的域内监督训练表现相当。我们想强调的是,我们的方法可以使用更复杂的教师模型,而不是高效的Sudorm-rf架构,并提供更高质量的语音增强性能。
zero-shot自适应
RemixIT也可以用于低资源的数据集,训练数据有限,但可以访问测试数据集来适应预先训练的模型。在更大的OOD数据集上,用各种有监督和无监督的预训练网络,描述了零镜头语音增强任务的性能改进,RemixIT在SI-SDR上提升了0.8db相比于未经校准的预训练模型当使用有限数量的域内mixture,模型的性能与可用noisy mixture有关,在WHAM(DNS)测试集上看到原因,最大的有3000(只有150)mixture。此外,我们还注意到,在训练数据和自适应集中的混合数据之间有很大的分布转移的情况下,我们有了很大的改进
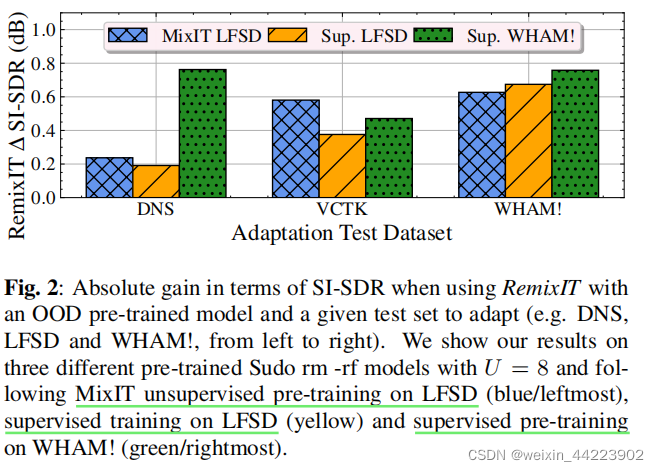
结论
我们提出了一个新的连续自训练降噪方法,在几个现实语音增强任务上表明了他的效果,我们的方法依赖于域内noisy和一个纯使用OOD数据的预训练模型,这种数据可能无法捕捉域内数据的分布,自助再混合过程与连续双向师生自我训练框架的耦合,导致了零射击和自监督语音增强和半监督语音增强以及半监督域自适应的显著改进。在未来,我们的目标是将我们的方法应用于其他领域和去噪任务,并为我们的算法的收敛性提供更强的理论保证。
Original: https://blog.csdn.net/weixin_44223902/article/details/122102009
Author: weixin_44223902
Title: CONTINUAL SELF-TRAINING WITH BOOTSTRAPPED REMIXING FOR SPEECH ENHANCEMENT