
下载和安装Anaconda
这是大佬整理的Python和Anaconda对应版本的参照表,不建议下载最新版的,因为好多库都不兼容,而且会在后续过程中会出现很多难以解决的问题https://blog.csdn.net/yuejisuo1948/article/details/81043823
- 安装注意问题
一个很关键的问题就是安装路径,这里建议新手和小白直接安装到C盘,这可以避免后续的很多小问题,但是尽管这样我也没有尝试过把它装入C盘
特别要注意的是,自己创建的路径,不要有空格和中文字符!!!
其中有一步是要选择系统环境变量,不要选!不要选!不要选!这里是自动添加环境变量,自己手动添加即可(当然,你如果能解决无法定位到动态链接库的问题,直接略过这里)
4. 配置Anaconda环境
在系统变量中添加
\AnacondaPython需要\Anaconda\Scriptsconda自带脚本\Anaconda\Library\mingw-w64\bin使用C with python的时候\Anaconda\Library\binjupyter notebook动态库\Anaconda\Library\usr\bin如果安装过程中勾选的all user
检验是否安装成功
在cmd中输入python,检查是否有Python环境
在cmd中输入conda --version,查看是否有conda环境(检验安装成功的标志)
增加Anaconda中国镜像
在Anaconda prompt中操作:
conda config --add channels mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels
当显示这些的时候,说明你的通道已经修改成功
安装TensorFlow-GPU
看了好多博主大佬们,都是要配置环境,下载各种包之类的,运气好的话也要几个小时才能搞定,不过我在偶然间发现可以直接使用Anaconda Navigator 进行安装
- 创建环境
如果曾经创建过项目,直接调到步骤3
如果没有的话在首页选择environments后再点create

- 定义环境名,选择对应python版本

这里python版本不建议使用太高版本,name不要出现中文汉字等且不能与location中目录名相同,包括大小写 - 安装TensorFlow

GPU版的话只选择这个就可以,如果不使用GPU就选择上面不带-gpu的第三方库
版本的话建议安装1.14以下,2.0以上的话在后期写代码的过程中会出现各种各样的问题,而且搜尽了csdn也有一部分问题处理不了 - pycharm中环境配置
file->settings->project->project interpreter
选择add local python interpreter
添加刚才创建的环境
- 验证
低于TensorFlow2.0的使用
import tensorflow as tf
hello = tf.constant('hello,tf')
sess = tf.Session()
print(sess.run(hello))
高于2.0的使用
import os
import tensorflow as tf
config = tf.compat.v1.ConfigProto(gpu_options=tf.compat.v1.GPUOptions(allow_growth=True))
sess = tf.compat.v1.Session(config=config)
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
Original: https://blog.csdn.net/qq_39235581/article/details/123803007
Author: 孑影安然
Title: Anaconda+TensorFlow安装血泪史
相关阅读1
Title: 创建DataFrame的两个途径
https://www.shiyanlou.com/courses/536/labs/1818/document
方法一 由反射机制推断出模式:
Step 1:引用必要的类。
Step 2:创建RDD。
Step 3:定义 case class 。
Step 4:将 RDD 转换为含有 case 对象的 RDD 。
Step 5:隐式转换会将含有 case 对象的 RDD 转换为 DataFrame ,将 DataFrame 的一些操作和函数应用于这个 DataFrame 中。
方法二 通过编程方式构建模式:
这种方式适用于列和类型在运行时不可知的情况,我们就需要手动地去构建 DataFrame 的模式。通常 DataFrame 的模式在动态变化时才会使用这种方式。
注意:该方式在 case class 在不能被提前定义时,或者使用 Scala 语言的项目中 case class 超过22个字段时,才会用到。
Step 2:由原始 RDD 创建一个 Row RDD 。
Step 3:使用 StructType 和 StructField 分别创建模式。其中, StructType 对应于 table (表),StructField 对应于 field (字段)。
Step 4:使用 SQLContext 提供的方法,将模式应用于 Row RDD 上,以创建 DataFrame。
现有的大数据应用通常需要搜集和分析来自不同的数据源的数据。而 DataFrame 支持 JSON 文件、 Parquet 文件、 Hive 表等数据格式。它能从本地文件系统、分布式文件系统(HDFS)、云存储(Amazon S3)和外部的关系数据库系统(通过JDBC,在Spark 1.4版本起开始支持)等地方读取数据。另外,通过 Spark SQL 的外部数据源 API ,DataFrame 能够被扩展,以支持第三方的数据格式或数据源。
csv:
主要是 com.databricks_spark-csv_2.11-1.1.0 这个库,用于支持 CSV 格式文件的读取和操作。
step 1:
在终端中输入命令: wget http://labfile.oss.aliyuncs.com/courses/610/spark_csv.tar.gz 下载相关的 jar 包。
将该压缩文件解压至 /home/shiyanlou/.ivy2/jars/ 目录中,确保该目录含有如图所示的以下三个 jar 包。
step 2 导入包:
step 3 直接将 CSV 文件读入为 DataFrame :
step 4 根据需要修改字段类型:
json:
扩展阅读:
由于数据格式和数据源众多,这里暂不一一展开讲解。在实际应用中,如果需要使用某种格式的数据或者某个数据源,应查询其官方文档。通常官方文档(特别是 API 手册)都提供了详细的集成方法和指导。
在 Spark 中,默认的数据源被设定为 Parquet ,所以通用的加载方式为:
如果是其他格式,则需要手动地指定格式:
下面给出了其他的加载指定数据源的方法:
sqlContext.jdbc:从数据库表中加载 DataFramesqlContext.jsonFile:从 JSON 文件中加载 DataFramesqlContext.jsonRDD:从包含 JSON 对象的 RDD 中加载 DataFramesqlContext.parquetFile:从 parquet 文件中加载 DataFrame
需要注意的是,在 Spark 1.4 及之后的版本中,加载数据源的方法为:
Original: https://www.cnblogs.com/libin2015/p/6782667.html
Author: 粒子先生
Title: 创建DataFrame的两个途径
相关阅读2
Title: 激光雷达和IMU标定
激光雷达和IMU标定
激光雷达简介
激光雷达,即LiDAR(Light Detection and Ranging),是激光探测及测距系统的简称,另外也称Laser Radar或LADAR(Laser Detection and Ranging)。激光雷达可以探测目标位置获取反射强度,有些也可以监测移动速度。激光光束可以准确测量视场中物体轮廓边沿与设备间的相对距离这些轮廓信息组成点云并绘制出3D环境地图,精度可达到厘米级别,从而提高测量精度。激光雷达按照有无机械旋转部分,可分为机械式激光雷达和固态激光雷达,目前普遍应用的为机械式的。固态激光雷达按实现方式不同可分为微机电系统(MEMS)、面阵闪光(Flash)和光学相控阵(OPA),其中OPA为近年来热点,具有无惯性器件、精确稳定、方向可任意控制等优点。
相比于摄像头,激光雷达的最大优势在于使用环境限制较小,因为使用激光主动探测,不依赖于外界光照条件或目标本身的辐射特性,所以不管在白天还是夜晚都能正常识别。激光雷达类似于雷达,但是分辨率更高,因为激光的波长是微米的量级,可以探测非常小的目标。它可以区分真实移动中的行人和人物海报、在三维立体的空间中建模、检测静态物体、精确测距。同时,LiDAR具有抗干扰性强的特点,激光波长短,可发射发散角非常小(μrad量级)的激光束,多路径效应小(不会形成定向发射,与微波或者毫米波产生多路径效应),可探测低空/超低空目标。所以,在自动驾驶汽车中,激光雷达在感知和定位模块中发挥着非常重要的作用。但是激光雷达最大的缺点是容易受到大气条件以及工作环境的烟尘的影响,而且价格昂贵,未来要在量产车上应用,必须大幅降价。
IMU简介
IMU全称Inertial Measurement Unit,即惯性测量单元,它由三个单轴的加速度计和三个单轴陀螺仪组成。加速度计检测物体在载体坐标系系统独立三轴的加速度信号,而陀螺仪检测载体相对于导航坐标系的角速度信号,对这些信号进行处理之后,便可解出物体的姿态。IMU大多用在需要进行运动控制的设备,如汽车和机器人上,以及需要用姿态进行精密位移推算的场合,如潜艇、飞机、导弹和航天器的惯性导航设备上。IMU提供的是相对的定位信息,它的作用是测量相对于起点物体所运动的路线,不能提供具体位置的信息,因此常常和GNSS一起使用。在一些GPS信号微弱的地方,IMU可让汽车继续获得绝对位置的信息和物体的姿态。
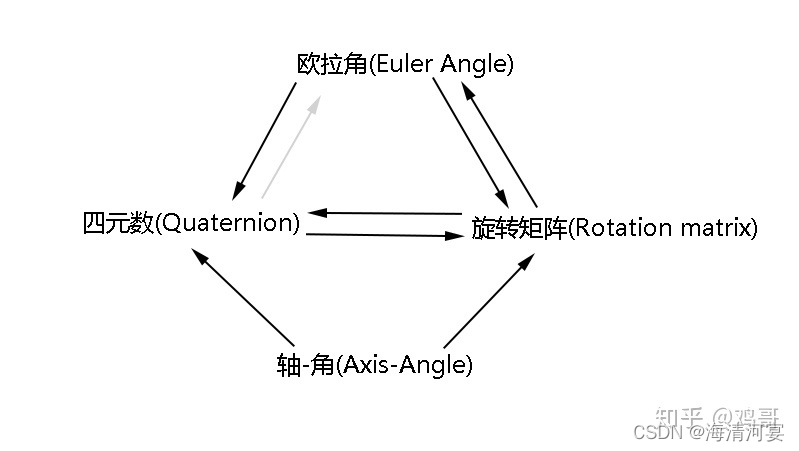
算法的数学原理
四元数
四元数是简单的超复数,是由实数加上三个虚数单位 i、j、k 组成,而且它们有如下的关系: i 2 = j 2 = k 2 = − 1 , i 0 = j 0 = k 0 = 1 i^2 = j^2 = k^2 = -1, i^0 = j^0 = k^0 = 1 i 2 =j 2 =k 2 =−1 ,i 0 =j 0 =k 0 =1每个四元数都是 1、i、j 和 k 的线性组合,即是四元数一般可表示为a + bi+ cj + dk,其中a、b、c 、d是实数。
对于i、j、k本身的几何意义可以理解为一种旋转,其中i旋转代表X轴与Y轴相交平面中X轴正向向Y轴正向的旋转,j旋转代表Z轴与X轴相交平面中Z轴正向向X轴正向的旋转,k旋转代表Y轴与Z轴相交平面中Y轴正向向Z轴正向的旋转,-i、-j、-k分别代表i、j、k旋转的反向旋转。
四元数是复数的不可交换延伸,如把四元数的集合考虑成多维实数空间的话,四元数就代表着一个四维空间,相对于复数为二维空间。四元数的优点是:非奇异表达(和例如欧拉角之类的表示相比)、比矩阵更紧凑(更快速)、单位四元数的对可以表示四维空间中的一个转动。
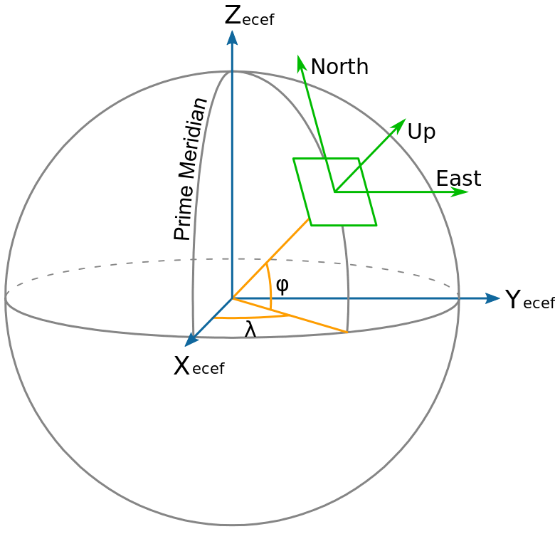
; ENU坐标系
地理坐标系,也称当地垂线坐标系,圆点位于运载体所在点,z轴沿当地地理垂线的方向,x,y轴在当地水平面内沿当地经线和纬线的切向方向可选为"东北天(ENU)"、"东北地(END)"、"北西天(NWU)"等右手直角坐标系。ENU坐标系为x指向东,y轴指向北,z轴垂直于当地水平面,沿当地垂线向上。
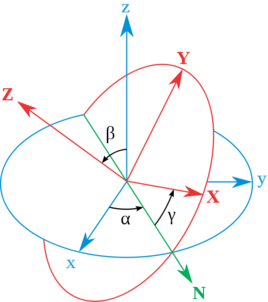
三维旋转
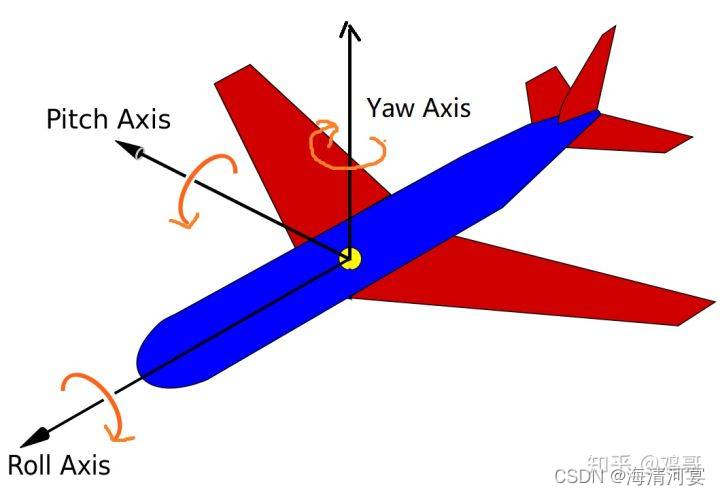
; 欧拉角(Euler Angle)与旋转矩阵(Rotation Matrix)
欧拉角旋转如按照ZXY顺归,分别对应着Z-Roll,X-Pitch,Y-Yaw,如下图:
欧拉角构造旋转矩阵可直接把三个Elemental Rotation Matrix乘在一起:

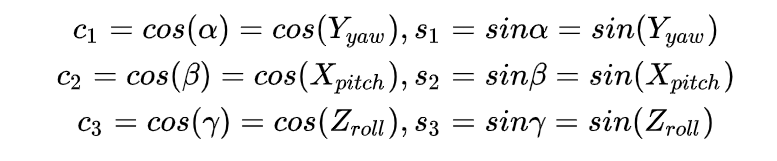
四元数(Quaternion)与旋转矩阵
欧拉旋转是有万向节死锁(Gimbal Lock)的问题的,而四元数(Quaternion)这种数学工具可以避免这个情况。一般来说,我们都会用单位四元数q = w+xi+yj+zk来表示旋转,其中∣ ∣ q ∣ ∣ = x 2 + y 2 + z 2 + w 2 = 1 ||q|| = x^2+y^2+z^2+w^2 = 1 ∣∣q ∣∣=x 2 +y 2 +z 2 +w 2 =1。那么给定一个单位四元数,可以构造旋转矩阵:
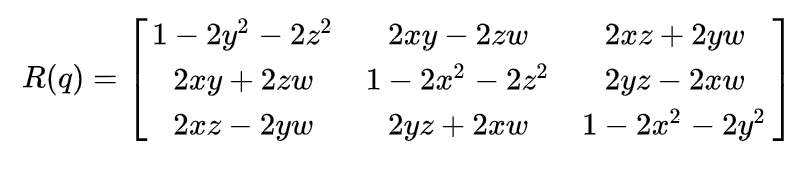
而也能通过运算,从旋转矩阵转换到四元数:
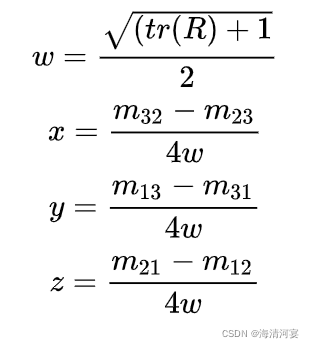
其中,m为R中的元素,例如m 32 m_{32}m 3 2 为第三行第二列元素。
; 四元数与欧拉角
给定一个欧拉旋转(X, Y, Z)(即分别绕x轴、y轴和z轴旋转X、Y、Z度),则对应的四元数为q = (x, y, x, w):
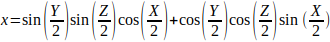
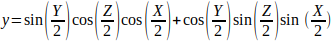
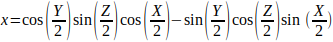
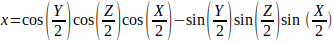
三维空间的位姿描述和齐次变换
首先规定一个坐标系,相对于该坐标系,点的位置可以用3维列向量表示;刚体的方位可用3×3的旋转矩阵来表示。而4×4的齐次变换矩阵则可将刚体位置和姿态(位姿)的描述统一起来,它具有以下优点:
(1) 它可描述刚体的位姿,描述坐标系的相对位姿(描述)。
(2) 它可表示点从一个坐标系的描述转换到另一坐标系的描述(映射)。
(3)它可表示刚体运动前、后位姿描述的变换(算子)。
位置矢量

旋转矩阵
经常用到的旋转变换矩阵是绕x轴、绕y轴或绕z轴按顺序各转角度:
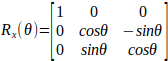
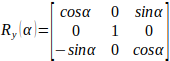
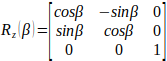
3x3旋转矩阵:
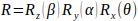
向量a经过一次旋转R和一个平移T后,得到a':
非齐次表述
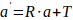
齐次表述(M为4x4 变换矩阵)
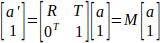
; 优化器
标定算法中采用的NLopt是一个非线性优化库,包括了多种优化算法,可进行大量参数的优化,包含全局和局部优化算法。在LiDAR和IMU/GNSS标定算法中,采用了全局优化算法GN_DIRECT_L,和局部优化算法LN_BOBYQA。
NLopt库中GN_DIRECT_L是DIRECT_L从零开始的再实现,是无梯度全局优化算法。DIRECT是全局优化的矩形分割算法(Dividing RECTangles algorithm),DIRECT-L是它"局部偏向"的变体。这些是基于将查找域系统性分割成更小的超矩形的决定性查找算法。DIRECT-L算法"更偏向于局部查找",所以对于没有很多局部最小值的方程更有效率。DIRECT_L将边界约束再划分成超立方,在搜索过程中给所有维度相同的权重。上述算法对于非约束性问题不适用,也不能处理任意非线性约束。
LN_BOBYQA是无梯度边界约束局部优化算法基于迭代建立的二次最优化不断优化目标函数。它接受不同参数的不相等的初始步长,这当参数之间有非常大尺度差别时很重要。
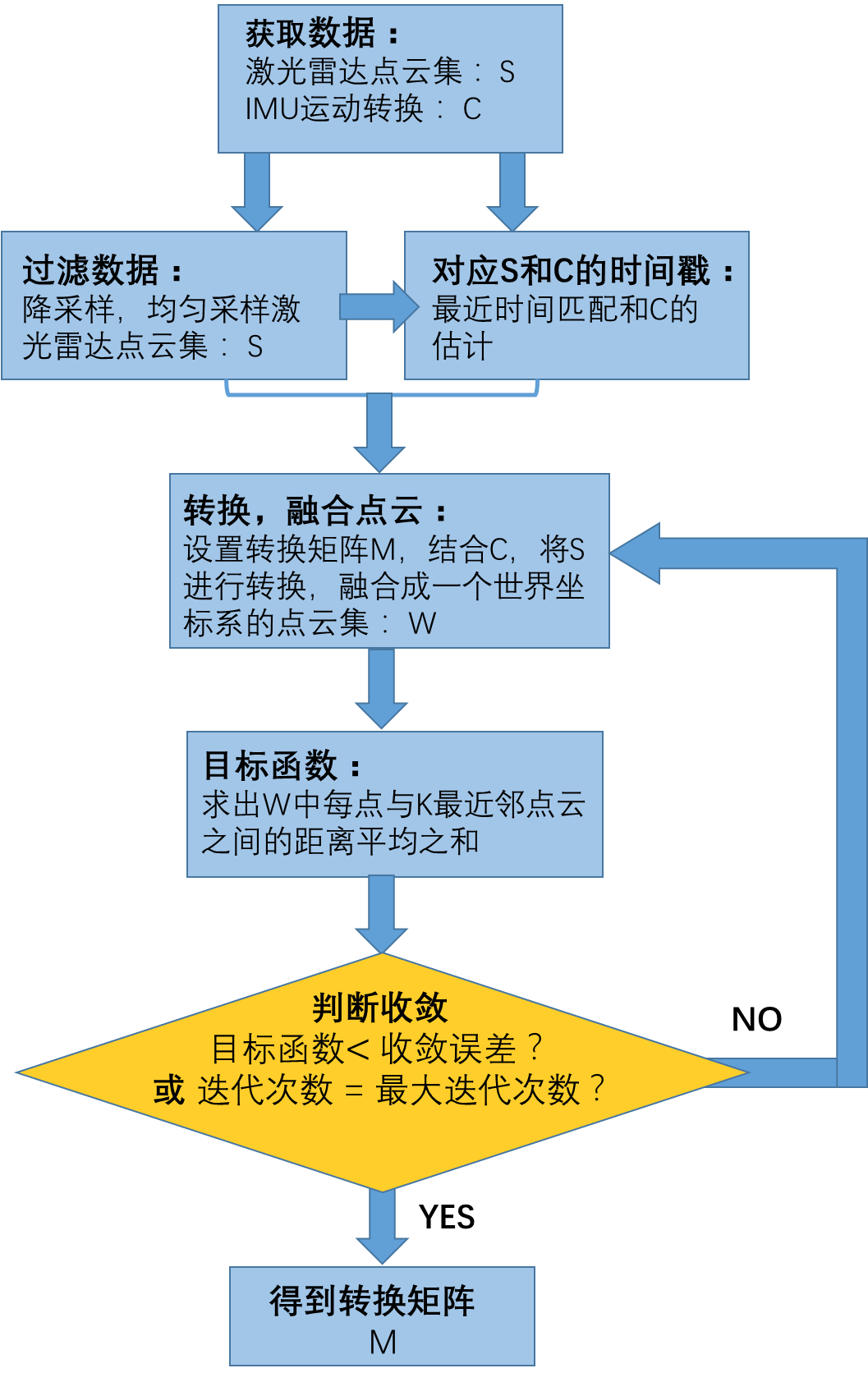
标定方法
现有的方法利用了来自激光雷达的点云在校准正确时看起来更"清晰"的特性进行激光雷达和IMU的标定,具体方法如下:
1)设置激光雷达与IMU之间的转换矩阵;
2)将点云相对坐标、IMU运动变换与上述转换相结合,将所有激光雷达点融合成一个点云;
3)求出每一点与其最近邻点云之间的距离之和;
这个过程在一个优化过程中重复,不断迭代找到最小化这个距离的转换矩阵。
IMU或者GNSS里程计输入的是类似geometry_msgs::TransformStamped的消息类型,也就是我们关注的是积分后的平移量和旋转量。
最终的标定质量与转换源的质量和观测到的运动范围密切相关。为了确保准确的校准,数据集应该包含大量的旋转和平移。近似规划器的运动(例如,一辆汽车沿着街道行驶)不会在垂直于平面的方向上提供关于系统的任何信息,这将导致优化器在这个方向上给出不正确的估计,比如在Z轴上的平移量就标定不准确。
优化过程包含了粗略角度的全局优化和局部6自由度优化。标定结果包含平移和旋转变换参数。
标定流程图
Original: https://blog.csdn.net/lpj822/article/details/122451778
Author: 海清河宴
Title: 激光雷达和IMU标定
相关阅读3
Title: 调用百度aip实现短语音翻译(附代码)
我的本意是想在Xilinx PYNQ上实现语音翻译,做一个类似翻译宝的应用,由于百度智能云目前仅支持安卓和IOS上的语音翻译,所以想要在嵌入式设备上实现该功能,就需要顺序调用短语音识别API和通用翻译API,下面记录使用方法。
1.进入百度智能云网站注册账号并登录:百度智能云-智能时代基础设施 (baidu.com)
登录界面:
2.登录之后在上面一堆选项栏里选择产品 —> 人工智能 —> 短语音识别
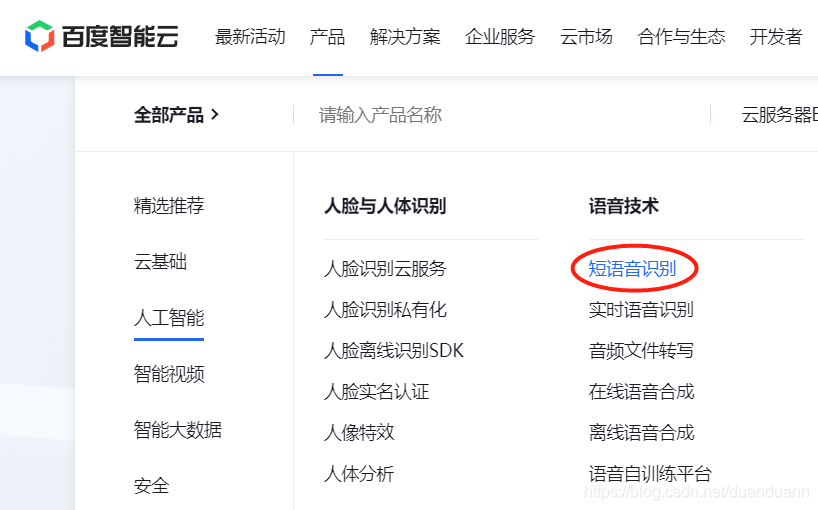
如果让注册开发者那就注册一下(需要身份证号认证)再点这个短语音识别选项。
3.点立即使用,如下图

4.点领取免费资源,能领的都领上,如下图
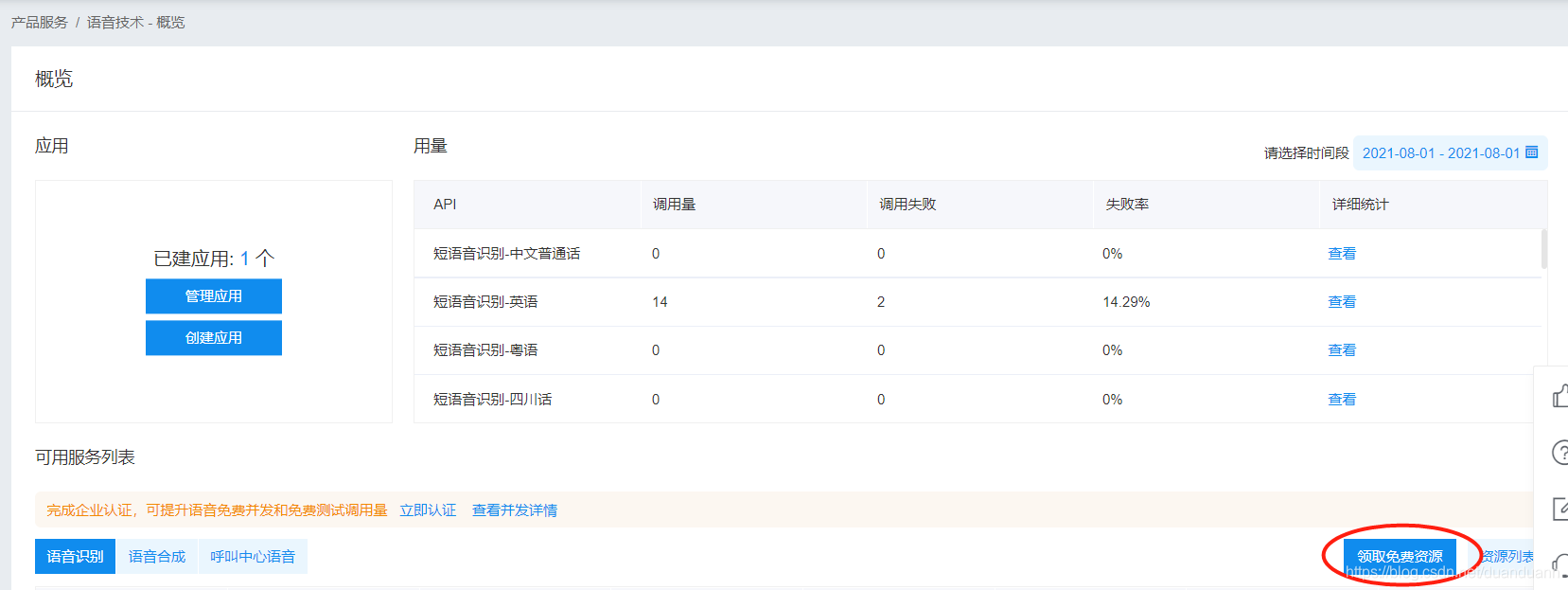
5.领完之后回到页面,点创建应用
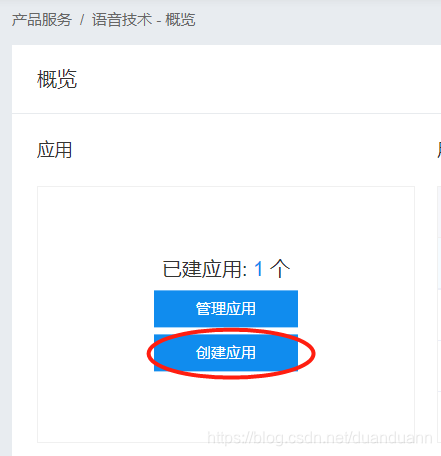
按照指引填就行了
6.填完回来再点管理应用,这里就显示了调用API要用到的三个关键字符串:AppID、API Key 和 Secret Key,如图点击左侧的技术文档选项。
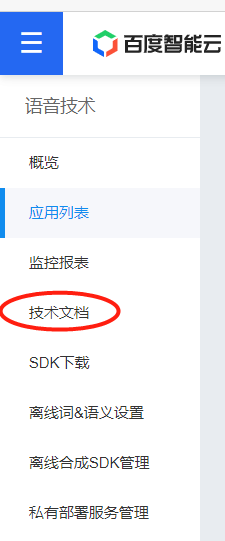
7.如图,在这里就能找到API的使用方法
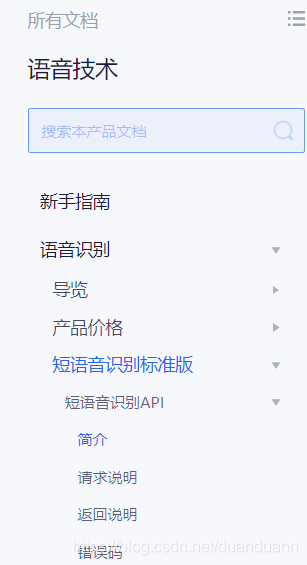
这里贴两个我的代码供参考:
from aip import AipSpeech
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
result = client.asr(get_file_content('mic1.wav'), 'wav', 16000, {
'dev_pid': 1737,
})
import audioop
from aip import AipSpeech
from soundfile import SoundFile
cap_cnt = 44100 #采样频率
file = SoundFile('recong.wav')
temp_data = bytes(cap_cnt * 50)
file.buffer_read_into(temp_data, dtype='int16');
data = audioop.ratecv(temp_data, 2, 1, 44100, 16000, None) # 转换采样频率到16000
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
result = client.asr(data[0], 'wav', 16000, {
'dev_pid': 1737,
})
result里返回一个字典包括很多数据,用 result['result'][0] 返回识别结果。
8.下面是将识别到的结果送到百度翻译
点击网址:百度AI开放平台-全球领先的人工智能服务平台 (baidu.com)
在上面选择开发能力选项,点击通用文本翻译选项,如下图所示
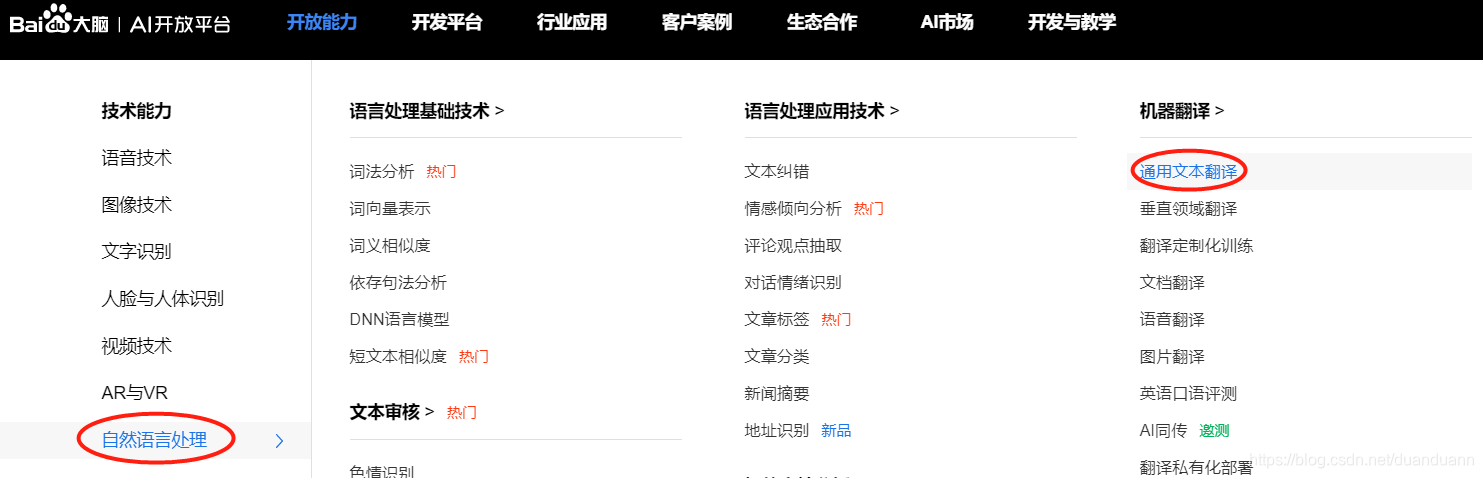
如果需要登录的话,用语音识别的账号就行,点立即使用
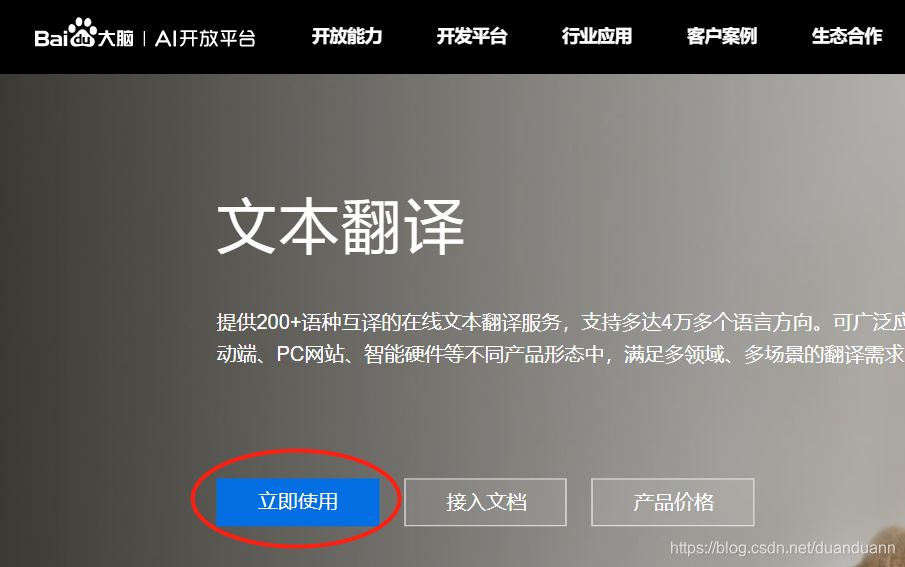
创建应用,按照指引填写就行了

点管理应用,点技术文档
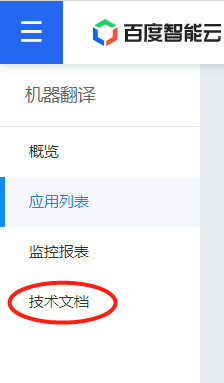
9.这里需要说明的是,文本翻译功能使用的是HTTP的方式进行调用,所以要先根据技术文档获取access_token,文档里有教:

import requests
client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官网获取的AK】&client_secret=【官网获取的SK】'
response = requests.get(host)
if response:
print(response.json())

10.获取到access_token后,就能使用翻译功能了:
import requests
url = 'https://aip.baidubce.com/rpc/2.0/mt/texttrans/v1?access_token=【刚刚获取的access_token】'
headers = {"Content-Type":"json;charset=utf-8"}
params = {"q":"hello","from":"auto","to":"zh"}
r = requests.post(url=url,params=params,headers=headers)
a = r.json()
print(a['result']['trans_result'])
把语音识别的输出送到文本翻译的输入,就可以实现语音翻译了
Original: https://blog.csdn.net/duanduann/article/details/119300775
Author: DUANDAUNNN
Title: 调用百度aip实现短语音翻译(附代码)