
基于MATLAB的语音滤波实验
实验目的:
- 在Matlab环境下对语音的频谱进行处理(数字滤波)并试听效果;
- 在Matlab环境下对语音的抽样率进行处理(语音压缩)并试听效果
实验步骤:
一、音频文件的压缩(抽取)。
- 利用windows附件中的录音机功能录制8~10秒的.wav语音文件,并以lei为文件名保存到Matlab/work的文件夹中。
a.打开 开始/程序/附件/娱乐/录音机;
b.用windows media player播放一首音乐并用MIC对着耳机录音或自已说话录音(按
键),到10秒时停止(按
键);
c.将录制的文件加存为C:/Matlab/work中,文件名为leii.wav;
- 打开Matlab并新建一.m文件;
-
在.m文件中用y=wavread('lei.wav')命令读入语音文件。
-
语音压缩:在m命令窗中输入如下命令:
-
运行sample2.m之后会在work文件夹中生成一个名为lei2的.wav文件,如下图:
-
双击lei2音频文件,用耳机试听效果,并跟lei1的效果比较。
- 在sample2.m文件中改变抽取倍率s (必须为正整数),重复4、5、6步,观察在不同抽取倍率s下的音频质量,
(注意:在运行sample2.m之前必须将work中名为lei2的.wav音频文件删除,或在.m文件中wavwrite()中的保存文件名改为其它的名字。)
二、音频信号的时域滤波(音频数据的时域卷积)。
(一)、低通滤波
- 打开Matlab并新建一.m文件,在.m文件中用y=wavread('lei.wav')命令读入语音文件。
-
在m命令窗中输入如下命令,并加存为sample3.m,运行该m文件。
-
双击lei3音频文件,用耳机试听效果,并跟lei1的效果比较。
- 再加一级h(n)的低通滤波,重复2、3步,如下图:
(注意:在运行lei2.m之前必须将work中名为lei3的.wav音频文件删除,或在.m文件中wavwrite()中的保存文件名改为其它的名字。)
- 重复2、3、4步,观察在不同阶数的低通滤波下的音频质量。
(二)、高通滤波
1.打开Matlab并新建一.m文件,在.m文件中用y=wavread('lei.wav')命令读入语音文件。
2.在m命令窗中输入如下命令,并加存为sample4.m,运行该m文件。
- 双击lei4音频文件,用耳机试听效果,并跟lei1的效果比较。
- 再加一级h(n)的低通滤波,重复2、3步,如下图:
(注意:在运行lei2.m之前必须将work中名为lei4的.wav音频文件删除,或在.m文件中wavwrite()中的保存文件名改为其它的名字。)
再加一级高通滤波:
(三)时域低通滤波时频域的频谱变化:
1.打开在第(一)步中创建的sample3.m文件,并在原文件中加入以下命令,另存为sample33.m
频谱如下图:
2.下图为h(n)为31点的三重低通滤波程序和频谱图:
(四)时域高通滤波时频域的频谱变化:
1.打开在第(二)步中创建的sample4.m文件,并在原文件中加入以下命令,另存为sample44.m
频谱如下图:
2.下图为h(n)为3点的三重低通滤波程序和频谱图:
二、音频信号的频域理想滤波处理:
原音频信号的抽样频率:
,
,该式即为模拟域频率f跟频率域(FFT变换)中k的关系
(一)理想低通滤波:
1.设计一截止频率为
对应的数字频率域(FFT)的系统函数的频率特性为:
2.按下图所示输入m文件,另存为lowfilter1.m ,并运行该程序。
2.双击lei5音频文件,用耳机试听效果,并跟lei1的效果比较。
3.将该m文件中的f0=2000分别改为1000、500、300、200、4000、.......后,运行程序试听效果。
4.在该m 文件中加入如下命令,重复第3步,并观察Xw、Hw、Yw的频谱。
(二)理想高通滤波:
1.设计一截止频率为
对应的数字频率域(FFT)的系统函数的频率特性为:
2.按下图所示输入m文件,另存为lowfilter1.m ,并运行该程序。
2.双击lei6音频文件,用耳机试听效果,并跟lei1的效果比较。
3.将该m文件中的f0=1000分别改为800、500、300、200、1500、2000.......后,运行程序试听效果。
4.在该m 文件中加入如下命令,重复第3步,并观察Xw、Hw、Yw的频谱。
(二)理想高通滤波:
1.设计一截止频率为
对应的数字频率域(FFT)的系统函数的频率特性为:
2.按下图所示输入m文件,另存为lowfilter1.m ,并运行该程序。
2.双击lei7音频文件,用耳机试听效果,并跟lei1的效果比较。
3.将该m文件中的fl和fh分别改.后,运行程序试听效果。
4.在该m 文件中加入如下命令,重复第3步,并观察Xw、Hw、Yw的频谱。
基于MATLAB的语音加去噪和延时混响实验
实验说明:
1.本实验提供的beiguo.wav,lei1.wav,music.wav,shao.wav,wang.wav均为原始语音信号.
2.本实验中的jiazao.m为语音加噪实验,xiaozao.m为语音消噪实验,musicadd.m为语音全成实验,musicfilter.m为语音滤波实验,dlaymusic.m为语音混响实验.
实验步骤:
1.将本文件夹中的所有.m文件和所有原始语音信号都复制到MATLAB的work文件夹中。
2.打开MATLAB程序。
一、语音消噪实验
%%%%%%在语音中加噪声%%%%%%%
x1=wavread('lei1.wav');%读取原语音信号,lei1中无噪声.
fs=22050; %原语音信的采样率为22050Hz
fn=1000; %设定噪声的频率为1000Hz
t=1:length(x1); %设置噪声的度度跟原语音信一样长,
x2=2sin(2pifn/fst);%产生幅度为2频率为fn的正弦波作为噪声.
x=x1+x2'; %将原子核语音信号跟噪声相加,x为带有噪声的语音信号.
wavwrite(x,22050,'lei2.wav');%将带有噪声的语音信号转换为声音,lei2中将有噪声
1).在MATLAB中打开名为jiazao.m的程序,运行该程序,将在work中产生一个新的语音文件lei2.wav
2).通过试听对比lei1.wav和lei2.wav语音,看噪声是否加上。
二、语音消噪实验
%%%%%%消除语音中的噪声%%%%%%%
x1=wavread('lei2.wav');%读取原语音信号,lei2中带有噪声.
y=filter(hn,1,x); %将带有噪声的语音信号x经过带阻滤波器进行滤波,以达到消噪目的.
%Bndstop,FIR,Equiripple,Minimum order,Fs=22050,Fpass1=950,Fstop1=980,Fstop2=1020,Fpass2=1050,Apass1=1,Astop=60,Apass2=1
wavwrite(y,22050,'lei3.wav');%将经带阻滤波消噪后的信号转换为语音,lei3中将不再有噪声
1).在MATLAB中打开名为xiaozao.m的程序(暂时不运行)
2).在MATLAB左下角start中打开FDATool界面,按本程序m文件中注释的参数设计带阻滤波器,
并通过File-Export-填hn,将设计的滤波器系数导到工作空间。
3).运行该程序,将在work中产生另一个新的语音文件lei3.wav
4).通过试听对比lei2.wav和lei3.wav语音,看噪声是否消除。
三、语音滤波实验
%%%%%带阻和低通滤波%%%%%%%
x=wavread('shao.wav');%读取名为shao.wav的原语音信号
y=filter(hns,1,x); %带阻滤波,滤波器在FDATool中设计,并导到工空间,因本人的中低音太重,高音不足
%Hpass,FIR,Equiripple,Minmum order,Fs=22050,Fpass1=100,Fstop1=1500,Fstop2=1600,Fpass2=3000,Apass1=1,Astop=30,Apass=1.
yy=filter(hnh,1,y); %高通滤波,滤波器在FDATool中设计,并导到工空间,因本人的低音太重,高音不足
%Hpass,FIR,Equiripple,Minmum order,Fs=22050,Fstop=10,Fpass=4000,Astop=20,Apass=1
wavwrite(yy,22050,'shao2.wav');%将经混响后的信转换为语音,shao2.wav的语音中的中低频分量将有所衰减.
1).在MATLAB中打开名为musicfilter.m的程序(暂时不运行)
2)按本程序m文件中注释的参数分别设计带阻和高通滤波器,并通过File-Export-填hns和hnh,将设计的滤波器系数导到工作空间。
3).运行该程序,将在work中产生另一个新的语音文件lei4.wav
4).通过试听对比shao.wav和shao2.wav语音,看语音有可不同。
四、语音混响实验
%%%%%延时混响%%%%%%%
x=wavread('shao2.wav'); %读入原始声音
n=1200; %设定延迟时间t=n/fs秒,改变该数据可改变混响深度(时间间隔)
N=60; %y设定延迟级数为N级,改变该数据可改变次数
x1=[x;zeros(N*n,1)]; %将x通过补零延长到经N级延时后的长度
for i=1:N %进行N次延时,第一次延时在x前补n 个0,后补(N-1)*n个0
x2=[zeros(in,1);x;zeros((N-i)n,1)]; %第i次延时在x前补in个0,后补(N-i)n个0
x1=x1+1/(2i)x2; %将经延时的信号x1跟x逐次相加
end
wavwrite(x1,22050,'shao3.wav'); %将混响后的数据转换为声音
1).在MATLAB中打开名为dlaymusic.m的程序
2).运行该程序,将在work中产生另一个新的语音文件shao3.wav
3).通过试听对比shao.wav、shao2.wav和shao3.wav语音,看语音有可不同。
4).修改本程序中的n和N,并重复2)和3)的步骤。
五、语音合成实验
%%%%%将两首语音全成一首%%%%%%
m1=wavread('beiguo.wav');%读取一首语音m1
m2=wavread('wang.wav'); %读取另一首语音m2
if length(m1)>length(m2) %比较两首语音的长度,将短的补成跟长的相等
m3=[m2;zeros((length(m1)-length(m2)),1)];
else
m3=[m1;zeros((length(m2)-length(m1)),1)];
end
m=0.6*m1+m3; %将两个语音相加,为分辩明,将其中一个衰减
wavwrite(m,22050,'mu3.wav'); %将合成后的信转为语音
1).在MATLAB中打开名为musicadd.m的程序
2).运行该程序,将在work中产生另一个新的语音文件mu3.wav
3).通过试听对比beiguo.wav、wang.wav和mu3.wav语音,看语音有否不同。
Original: https://blog.csdn.net/m0_59833680/article/details/119908106
Author: MATLAB管家
Title: 基于MATLAB的语音滤波实验
相关阅读1
Title: iToF深度估计原理-带简单数学推导(持续更新)
文章目录
- 什么是iToF?
* - 为什么有相位差,就可以测距?
- 测距原理
* - 正弦调制:4-sampling-bucket 算法(带推导)
- 脉冲调制
- 距离--->深度
- iToF的标定问题
- 双频调制是什么?动机是?
- 挑战问题
* - 多路径问题
- 散射问题
- 环境光/户外问题
- 参考文献
- 附录
* - 怎么理解相位?
什么是iToF?
ToF是Time-of-Flight的缩写,即光飞行时间,其本质上还是一种深度测距相机,目的自然是输出高质量的深度图像,该技术与结构光、双目,构成三种主流的3D视觉技术。
iToF全称为 indirect Time-of-Flight,即间接的ToF,与之相对应的是dToF,即direct Time-of-Flight。iToF相对于dToF来说,有着"smaller maximum range but with a higher lateral resolution."。
本文主要关注iToF的深度估计原理,具体地,iToF向真实的物理场景发射近红外光(调制的红外光信号),由传感器接收反射物体返回的光信号,进行测距工作。其通过测量 相位偏移/延迟来检测测量光的飞行时间,所谓的"相位偏移"即发射信号与接收信号之间的相位差。此外,iToF在输出深度图像的同时,还可以输出幅值图、IR图等作为一些副产品。
为什么有相位差,就可以测距?
其实这个道理很简单,但是考虑到读者可能已经遗忘了一些基础的物理知识,所以还是单拿出一个子标题简单介绍下。其实无非就是距离=时间*速度,相位差主要是用于测量相位延迟的时间,我们已知一个周期的时间是T T T,那么产生这个相位差所需要的时间就是φ / 2 π ∗ T \varphi/2 \pi * T φ/2 π∗T,设光的飞行速度为c c c,那么光到物体一去一回的总距离就是:φ ∗ T 2 π ∗ c \frac{\varphi * T}{2 \pi} * c 2 πφ∗T ∗c,就可以得到物体距离发射端的距离为:
φ ∗ T 4 π ∗ c \frac{\varphi * T}{4 \pi} * c 4 πφ∗T ∗c
测距原理
iToF模组的核心有发射端和接收端。通常来说,发射端为VCSEL(Vertical Cavity Surface Emitting Laser),中文名为垂直共振腔表面放射激光器,主要负责发射特定频率的调制红外光,接收端即为图像传感器,其在 一定积分/曝光时间内接受反射光,经由光电转换及一定处理后交于计算单元对每一个像素计算其对应的相位偏移。
正弦调制:4-sampling-bucket 算法(带推导)
以正弦调制照明光为例。
采样相位延迟为0°,90°,180°,270°的采样信号对相位偏移进行计算,
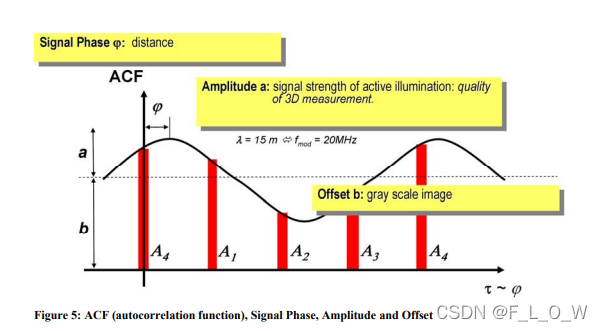
因为是求相位延迟,因此我们不妨以发射段作为相对的相位零点,设相位延迟为φ \varphi φ,那么对于发射端的0°,则对应于接收端的φ \varphi φ,发射端的90°,则对应于接收端的φ + π 2 \varphi + \frac{\pi}{2}φ+2 π,发射端的180°,对应于接收端的φ + π \varphi + \pi φ+π,发射端的270°,对应于接收端的φ + 3 π 2 \varphi + \frac{3\pi}{2}φ+2 3 π。
分别地,对于A 1 A_1 A 1 、A 2 A_2 A 2 、A 3 A_3 A 3 ,A 4 A_4 A 4 ,根据其正弦波的性质,有:
A 1 = a s i n ( φ + 0 ) + b A 2 = a s i n ( φ + π 2 ) + b = a c o s ( φ ) + b A_1 = a sin(\varphi + 0)+b \quad A_2 = a sin(\varphi + \frac{\pi}{2})+b=a cos(\varphi) + b A 1 =a s i n (φ+0 )+b A 2 =a s i n (φ+2 π)+b =a c o s (φ)+b
A 3 = a s i n ( φ + π ) + b = − a s i n ( φ ) + b A 4 = a s i n ( φ + 3 π 2 ) + b = − a c o s ( φ ) + b A_3 = a sin(\varphi + \pi)+b = -a sin(\varphi)+b \quad A_4 = a sin(\varphi + \frac{3\pi}{2})+b = -acos(\varphi)+b A 3 =a s i n (φ+π)+b =−a s i n (φ)+b A 4 =a s i n (φ+2 3 π)+b =−a c o s (φ)+b
自然地,有计算相位偏移的公式为:
φ = arctan ( A 1 − A 3 A 2 − A 4 ) \varphi=\arctan \left(\frac{A_{1}-A_{3}}{A_{2}-A_{4}}\right)φ=arctan (A 2 −A 4 A 1 −A 3 )
幅值a a a的计算方式为:
a = ( A 1 − A 3 ) 2 + ( A 2 − A 4 ) 2 2 a=\frac{\sqrt{\left(A_{1}-A_{3}\right)^{2}+\left(A_{2}-A_{4}\right)^{2}}}{2}a =2 (A 1 −A 3 )2 +(A 2 −A 4 )2
偏移量b b b的计算方式为:
b = A 1 + A 2 + A 3 + A 4 4 b=\frac{A_{1}+A_{2}+A_{3}+A_{4}}{4}b =4 A 1 +A 2 +A 3 +A 4
求取得到相位延迟后,可以通过下式计算得到目标距离:
d = c ⋅ φ 4 π ⋅ f m o d d=\frac{c \cdot \varphi}{4 \pi \cdot f_{\mathrm{mod}}}d =4 π⋅f m o d c ⋅φ
参考文献:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.132.5821&rep=rep1&type=pdf
; 脉冲调制
脉冲工作方式相比起正弦调制,更容易减少环境光的影响。
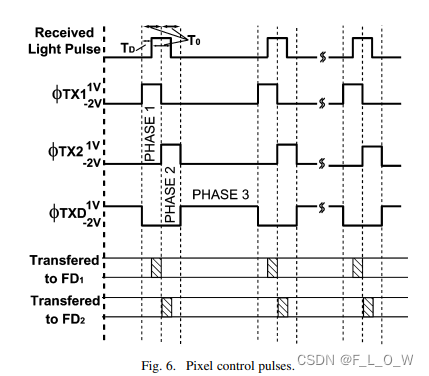
使用ϕ T X 1 \phi_{T X 1}ϕT X 1 以及ϕ T X 2 \phi_{T X 2}ϕT X 2 两个脉冲来去选择将接收到的脉冲转换到node F D 1 FD1 F D 1还是F D 2 FD2 F D 2,而ϕ T X D \phi_{TXD}ϕT X D 则是用于将环境光/背景光引入到charge drains。
主动照明光源的脉冲宽度为T 0 T_0 T 0 ,相位延迟为T D T_D T D 。
已知转移到node FD1以及FD2的电子分别为:
N 1 = I p h q ( T 0 − T D ) N 2 = I p h q T D \begin{gathered} N_{1}=\frac{I_{\mathrm{ph}}}{q}\left(T_{0}-T_{D}\right) \ N_{2}=\frac{I_{\mathrm{ph}}}{q} T_{D} \end{gathered}N 1 =q I p h (T 0 −T D )N 2 =q I p h T D
联合以上二式,可得:
T D = T 0 N 2 ( N 1 + N 2 ) T_{D}=\frac{T_{0} N_{2}}{\left(N_{1}+N_{2}\right)}T D =(N 1 +N 2 )T 0 N 2
有了相位延迟后,则可知距离为:
L = c T 0 N 2 2 ( N 1 + N 2 ) L=\frac{c T_{0} N_{2}}{2\left(N_{1}+N_{2}\right)}L =2 (N 1 +N 2 )c T 0 N 2
如果node的容量是一样的,那么收集到的电子,可以直接等价为电压,即有:
L = c T 0 V 2 2 ( V 1 + V 2 ) L=\frac{c T_{0} V_{2}}{2\left(V_{1}+V_{2}\right)}L =2 (V 1 +V 2 )c T 0 V 2
然而,由下图可见,V o f f s e t V_{offset}V o f f s e t 对距离测量的误差造成了巨大影响,其往往由于物体表面的散射而引起,因此,为了减小该误差,将距离测量的公式改写为:
L = c T 0 ( V 2 − V offset ) 2 ( V 1 + V 2 − 2 V offset ) L=\frac{c T_{0}\left(V_{2}-V_{\text {offset }}\right)}{2\left(V_{1}+V_{2}-2 V_{\text {offset }}\right)}L =2 (V 1 +V 2 −2 V offset )c T 0 (V 2 −V offset )
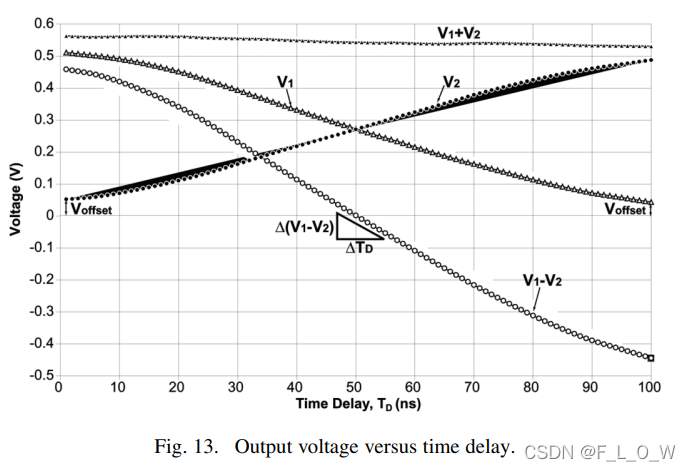
此外,通常来说,脉冲调制去描述频率的时候,更喜欢用脉宽来描述,比如说3ms,这与正弦调制略微有些差别。
参考文献:
https://www.researchgate.net/profile/Shoji-Kawahito/publication/3431993_A_CMOS_Time-of-Flight_Range_Image_Sensor_With_Gates-on-Field-Oxide_Structure/links/0046351ceefe8159b6000000/A-CMOS-Time-of-Flight-Range-Image-Sensor-With-Gates-on-Field-Oxide-Structure.pdf
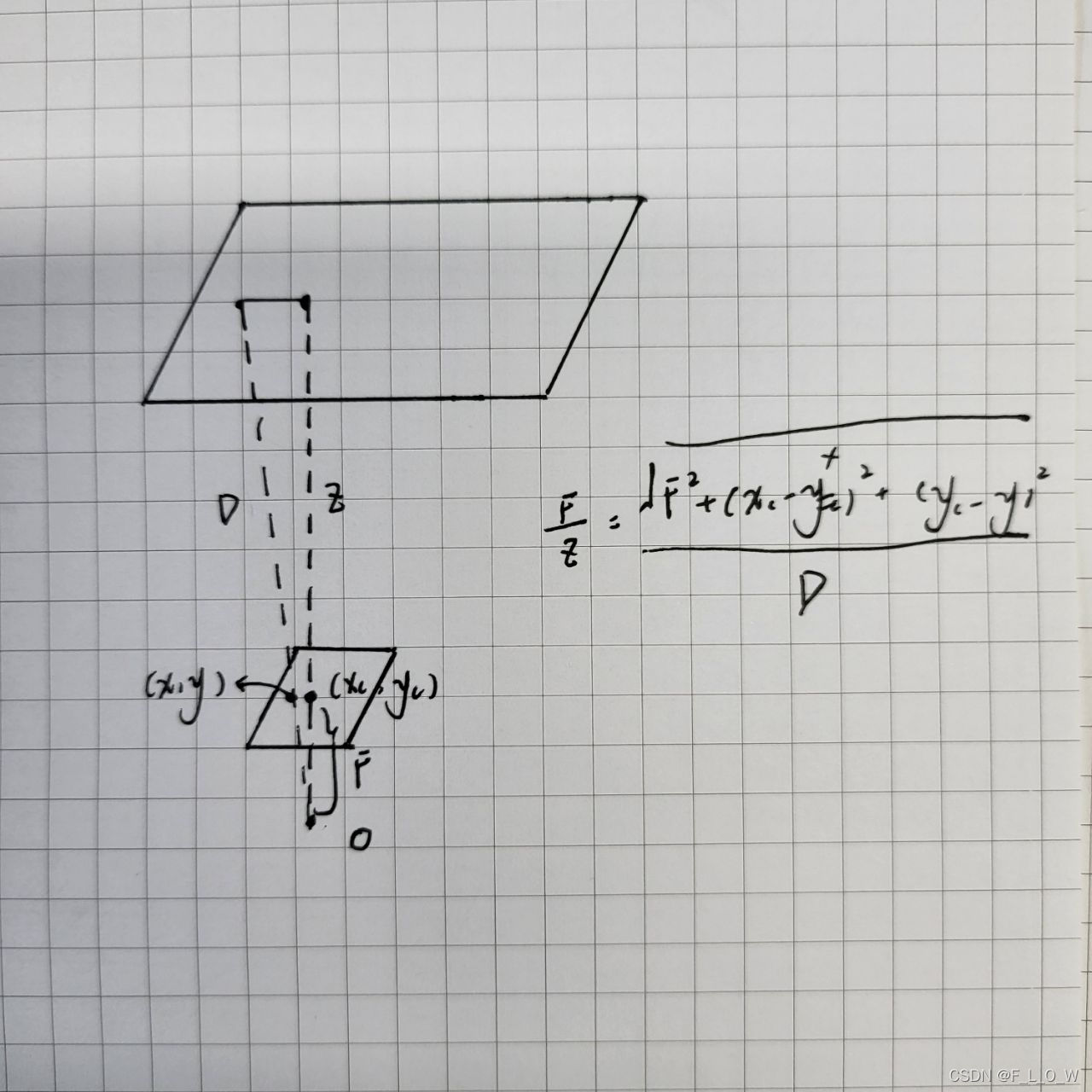
距离—>深度
无论是正弦光调制还是脉冲的方式,以上所介绍与推导的,均是用于求取距离。当需要求取深度时,则可通过简单的三角原理进行解算,在此不做赘述,读者可自行推导,简易手绘的示意图如下:
; iToF的标定问题
所谓的标定,我们可以看作是对iToF系统误差的补偿行为。
而讲到补偿,则主要是对系统误差进行标定,包括相位零漂,温漂误差,wiggling以及FPPN函数。
双频调制是什么?动机是?
我们已知单频调制的最大探测距离的理论公式为:
D m a x = c 2 ∗ f D_{max} = \frac{c}{2*f}D m a x =2 ∗f c
由上式很容易发现,调制频率越低,那么可以探测的距离就越远。然而,鱼和熊掌不可兼得,当探测距离远的时候,探测的精度便相对较差。反之,如果是高频调制,则会取得较好的探测精度,但探测距离又会受限。
自然地,如果我们希望能够兼顾高低频的优势,一种想法便是使得二者进行有机结合,即双频调制。
结合的优势很明显,既拓展了探测距离,也提高了探测精度,然而,万事总不完美,双频调制会拖慢帧率。
双频调制的时候,我们需要确定其距离相交处,难免地,需要计算其频率的最大公约数。而最大公约数可以通过传统的辗转相除法进行计算,python的代码为:
def gcd(a,b):
if a%b == 0:
return b
else :
return gcd(b,a%b)
挑战问题
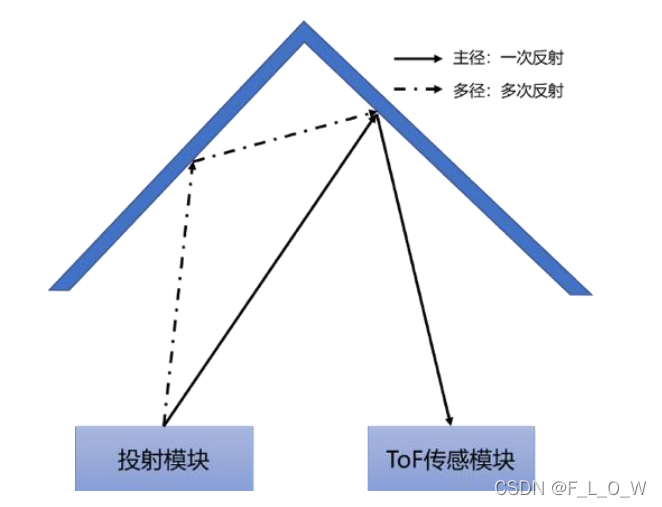
多路径问题
多路径问题会导致ToF接收器接收到多重的深度信息,导致测量错误。
; 散射问题
所谓的散射问题,通常是指内部散射问题,再具体一点,通常是指 高反射率的物体 的能量会在透镜lens和像素平面之间来回的反射,也就是说,其会有一部分的能量被其他的像素接收到,进而,导致了其他像素的深度错误。
环境光/户外问题
参考文献
[1] https://www.163.com/dy/article/FBJHFRM70511BQR8.html
[2] ToF白皮书 : http://www.deptrum.com/uploads/&e5&85&89&e9&89&b4&e5&88&86&e4&ba&ab&e7&99&bd&e7&9a&ae&e4&b9&a6.pdf
[3] https://faster-than-light.net/TOFSystem_C3/
附录
怎么理解相位?
假设简谐运动的物体位于P点,对应于匀速圆周运动的P'点,θ \theta θ角就是相位。
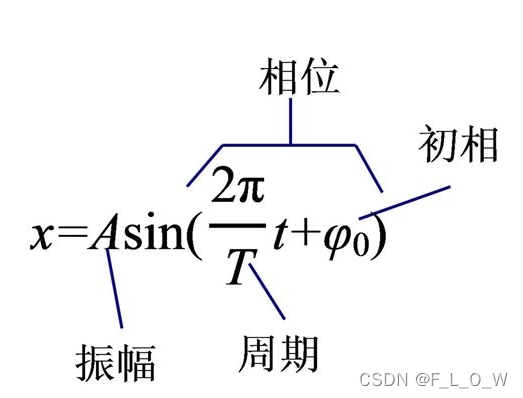
对于公式x = A c o s ( ω t + ϕ ) x = A cos(\omega t+\phi)x =A c o s (ωt +ϕ),有:
参考链接:https://www.zhihu.com/question/31104681
Original: https://blog.csdn.net/flow_specter/article/details/122730446
Author: F_L_O_W
Title: iToF深度估计原理-带简单数学推导(持续更新)
相关阅读2
Title: 语音识别原理与应用 洪青阳 第一章 概论
目录
第一章 语音识别概论
语音识别的基础理论包括 语音的产生和感知过程、语音信号基础知识、语音特征提取等。
关键技术包括高斯混合模型(Gaussian Mixture Model,GMM)、隐马尔科夫模型(Hidden Markov Model,HMM)、深度神经网络(Deep Neural Network,DNN),以及基于这些模型形成的 GMM-HMM、DNN-HMM 和 端到端(End-to-End,E2E)系统。语言模型和 解码器 也非常关键,直接影响语音识别实际应用的效果。
1.1 语音的产生和感知
人的 发音器官包括 肺、气管、声带、喉、咽、鼻腔、口腔、和唇。
肺部产生的气流冲击声带,产生振动。
声带每开启和闭合一次的时间是一个 基音周期(Pitch period)T,其倒数为 基音频率(F0=1/T, 基频),范围在70HZ---450HZ。基频越高,声音越尖细。基频随时间的变化,也反映了声调的变化。
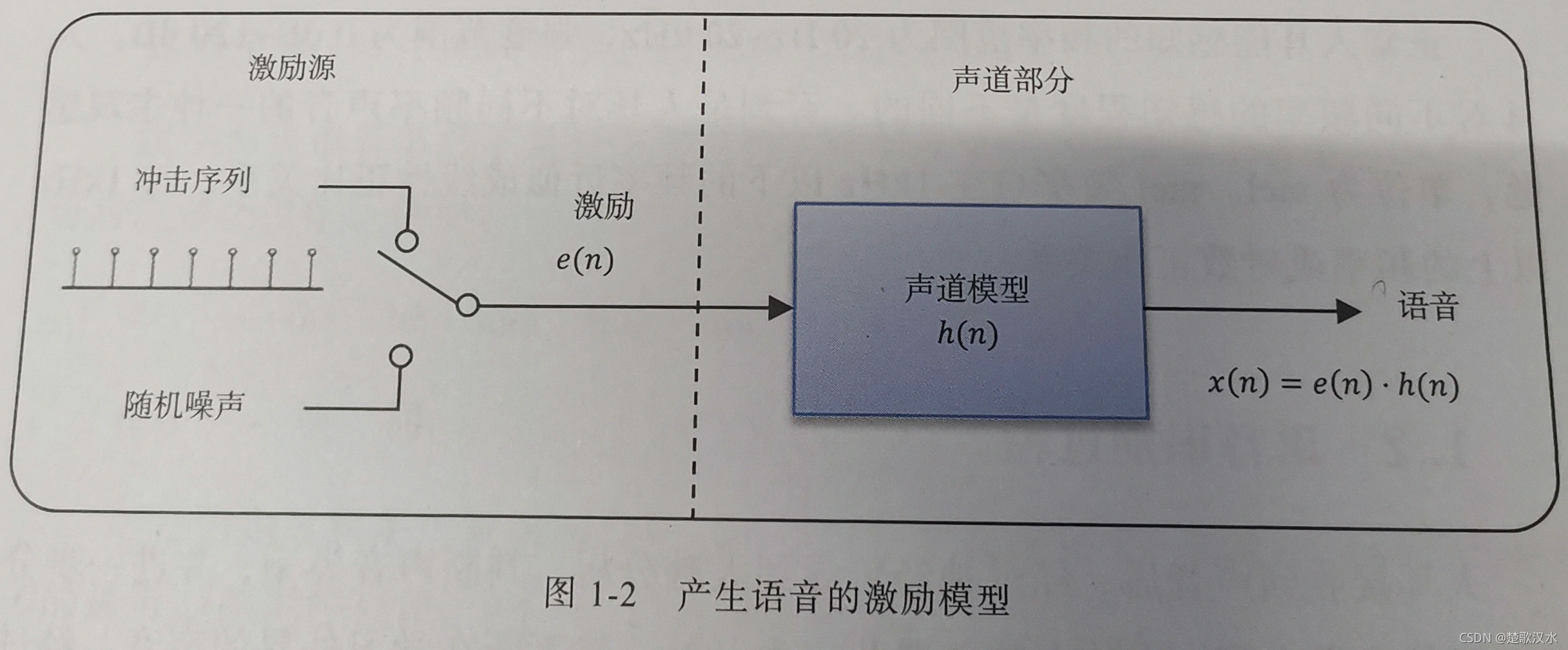
语音的产生过程可进一步抽象成如上图所示的激励的模型。包括 激励源和声道部分。在激励源部分, 冲击序列发生器以基音周期产生周期性信号,经过声带振动, 相当于经过 声门波模型,肺部气流大小相当于振幅; 随机噪声发生器产生非周期性信号。 声道模型模拟口腔、鼻腔等声道器官,最后产生语音信号。我们要发浊音时,声带振动形成准周期的冲击序列。发清音时,声带松弛,相当于发出一个随机噪声。
1.2 语音识别过程
音素(phone)是构成语音的最小单位。英语中有48个音素(20个元音和28个辅音)。
若采用元音和辅音来分类,汉语普通话有32个音素,包括元音10个,辅音22个。 但普通话的韵母多是复韵母,不是简单的元音,因此 拼音一般分为声母(initial)和韵母(final)。
音节(syllable)是听觉能感受到的最自然的语音单位,由一个或多个音素按一定的规律组合而成。英语音节可由一个元音或元音和辅音构成。汉语的音节由声母、韵母和音调构成,其中音调信息包括在韵母中。所以,汉语音节结构可以简化为:声母+韵母。
注:音素(序列)组成音节(序列),从而识别出文字。
汉字与汉语音节并不是一一对应的。一个汉字可以对应多个音节,一个音节可对应多个汉字。
例如:
和 ----- he二声 he四声 huo二声 huo四声 hu二声
tian二声 ----- 填 甜
语音识别过程是个复杂的过程,但其最终任务归结为,找到对应 观测值序列O的最可能的 词序列W'。按贝叶斯准则转化为:
W' = arg max P(W|O) = arg max(P(O|W)P(W))/(P(O))
W' = arg max P(O|W)P(W)
其中,P(O)与P(W)没有关系,可认为是常量,因此P(W|O)的最大值可转换为P(O|W)和P(W)两项乘积的最大值,第一项P(O|W)由声学模型决定,第二项P(W)由语言模型决定。
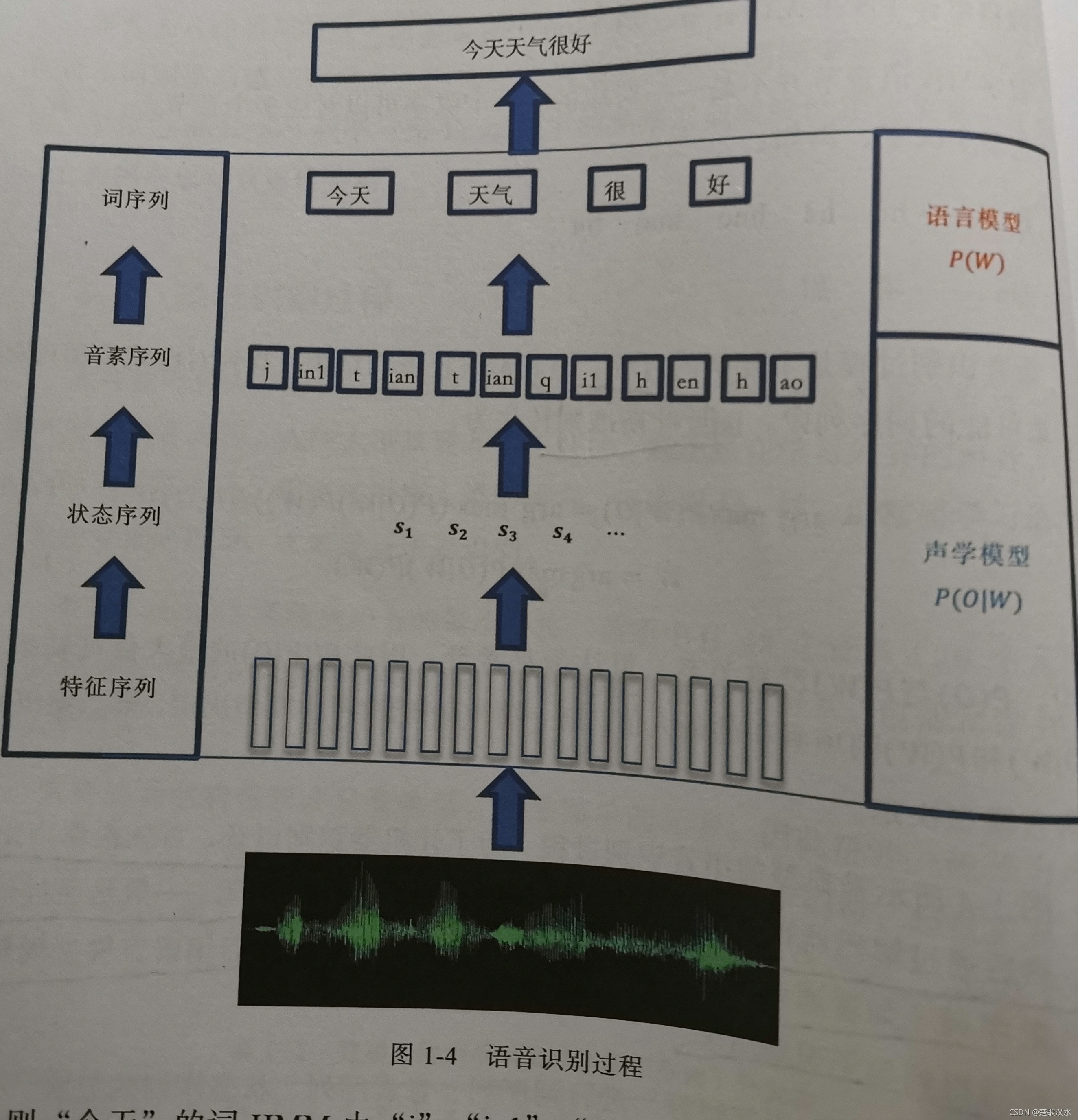
上图是典型的语音识别过程。为了让机器识别语音,首先提取声学特征,然后通过解码器得到状态序列,并转换为对应的识别单元。一般是通过词典将音素序列(如普通话的声母和韵母),转换为词序列,然后用语言模型规整约束,最后得到句子识别结果。

如上图所示,对"今天天气很好"进行词序列、因素序列、状态序列的分解,并和观测值序列对应,其中每个音素对应一个HMM,并且其发射状态(深色)对应多帧观测值。
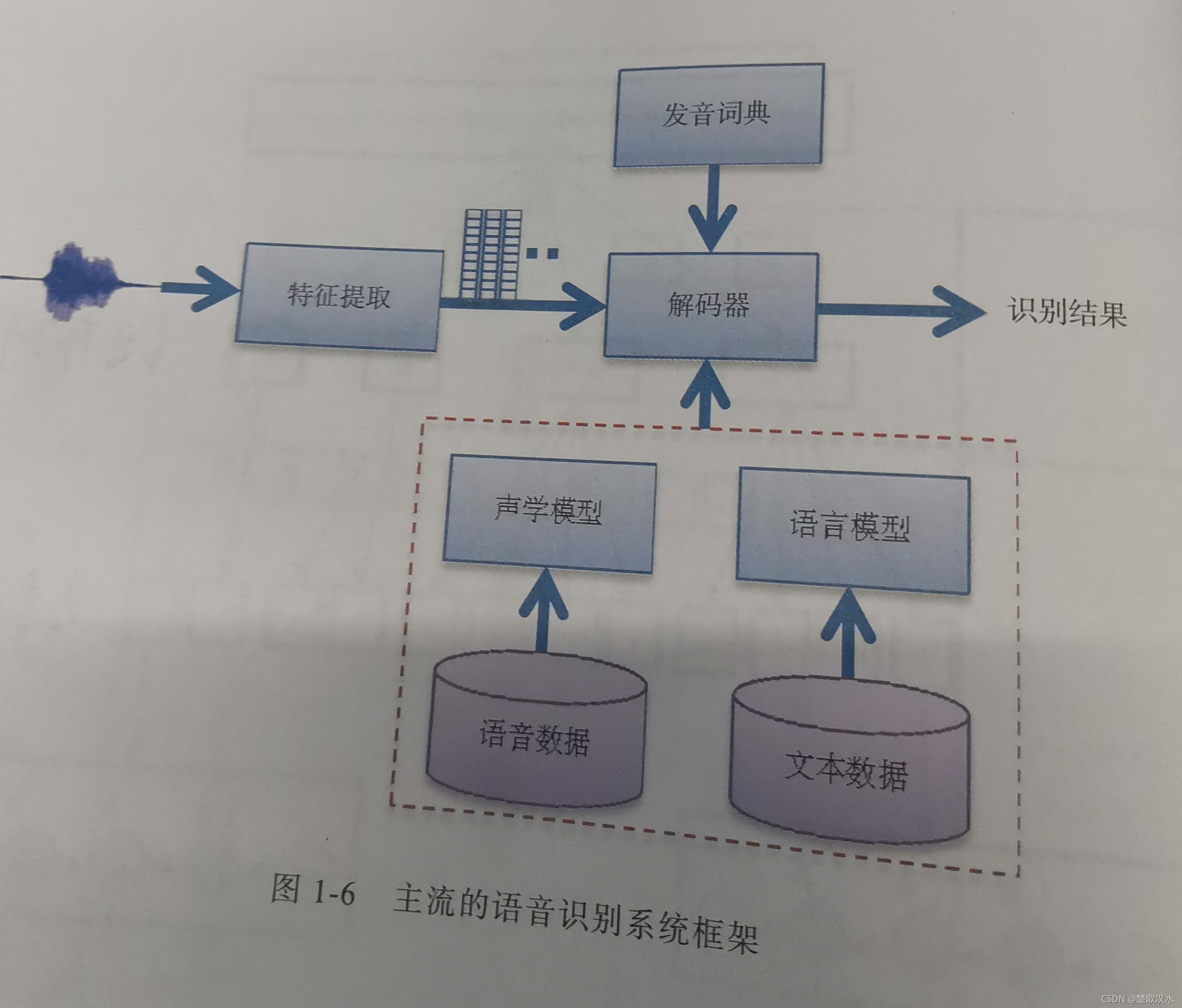
现在工业应用普遍要求 大词汇量连续语音识别(LVCSR)。
1.3语音识别发展历史
解决任务: 孤立词识别 → 大规模连续语音识别 → 复杂场景识别
技术发展: 模板匹配(DTW) → 统计模型(GMM-HMM) → 深度学习(DNN-HMM,E2E)
DTW(Dynamic Time Warping)动态时间规整:使用动态规划算法将两段不同长度的语音在时间轴上进行了对齐。该算法把时间规整和距离的计算有机地结合起来,解决了不同时长语音的匹配问题。在一些要求资源占用率低、识别人比较特定的环境下,DTW是一种很经典很常用的模板匹配算法。
统计模型两项很重要的成果是 声学模型和 语言模型,语言模型以 n元语言模型(n-gram)为代表,声学模型则以 HMM为代表。
GMM-HMM:(1)用HMM对语音状态的转移概率建模;(2)用 高斯混合模型(Gaussian Mixture Model,GMM)对语音状态的观测值概率建模。
HTK(Hidden Markov Tool Kit)是一款开源的基于HMM的语音识别工具包。
Ka1di,是DNN-HMM系统的基石,在工业界得到广泛应用。
大多数主流的语音识别解码器基于 加权有限状态转换器(WFST),把发音词典、声学模型和语言模型编译成静态解码网络,这样可大大加快解码速度,为语音识别的实时应用奠定基础。
RNN可更有效、更充分地利用语音中的上下文信息。引入LSTM或其变体以解决梯度消失的问题。
CNN可通过共享权值来减少计算的复杂度,并且CNN被证明在挖掘语音局部信息的能力上更为突出。
Attention模型的对齐关系没有先后顺序的限制,完全靠数据驱动得到,对齐的盲目性会导致训练和解码时间过长。而CTC的前向后向算法可以引导输出序列和输入序列按时间顺序对齐。
Transformer架构:在 Decoder和Encoder中均采用Attention机制。
Original: https://blog.csdn.net/hnlg311709000526/article/details/120912777
Author: 楚歌汉水
Title: 语音识别原理与应用 洪青阳 第一章 概论
相关阅读3
Title: (Windows,ten2.0)python0-9数字识别系统搭建(MNIST数据集)
一、MNIST数据集介绍:是由0〜9手写数字图片和数字标签所组成的,由60000个训练样本和10000个测试组成。
二、tf2.0.0导入MNIST数据集的方法:
from tensorflow.examples.tutorials.mnist import input_data
我的电脑是tf2.6.0,导入MNIST数据集的方法:
from tensorflow.keras.datasets import mnist
三、代码模块:
代码引用自:https://blog.csdn.net/JulyLi2019/article/details/106248212/
上代码:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 加载mnist数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# print(x_train.shape)
# plt.imshow(x_train[0])
x_train, x_test = x_train / 255.0, x_test / 255.0 # 归一化
y_train_onehot = tf.keras.utils.to_categorical(y_train) # 将标签转换成独热编码
y_test_onehot = tf.keras.utils.to_categorical(y_test)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28))) # 28*28
model.add(tf.keras.layers.Dense(128, activation='relu')) # 中间隐藏层激活函数用relu
model.add(tf.keras.layers.Dense(10, activation='softmax')) # 多分类输出一般用softmax分类器
#loss函数使用交叉熵
# 顺序编码用sparse_categorical_crossentropy
# 独热编码用categorical_crossentropy
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train_onehot, epochs=5)
model.evaluate(x_test, y_test_onehot)
# predict=model.predict(y_test)
#
# predict.shape
运行结果:
当然这里我们可以通过模型保存与载入把训练与测试分开:
训练:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 加载mnist数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# print(x_train.shape)
# plt.imshow(x_train[0])
x_train, x_test = x_train / 255.0, x_test / 255.0 # 归一化
y_train_onehot = tf.keras.utils.to_categorical(y_train) # 将标签转换成独热编码
y_test_onehot = tf.keras.utils.to_categorical(y_test)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28))) # 28*28
model.add(tf.keras.layers.Dense(128, activation='relu')) # 中间隐藏层激活函数用relu
model.add(tf.keras.layers.Dense(10, activation='softmax')) # 多分类输出一般用softmax分类器
#loss函数使用交叉熵
# 顺序编码用sparse_categorical_crossentropy
# 独热编码用categorical_crossentropy
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train_onehot, epochs=5)
model.save('model.h5')
print('saved total model.')
# plt.plot(history.epoch,history.history.get('accuracy'),label='accuracy')
# plt.legend()
# plt.show()
测试:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 加载mnist数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# print(x_train.shape)
# plt.imshow(x_train[0])
x_train, x_test = x_train / 255.0, x_test / 255.0 # 归一化
y_train_onehot = tf.keras.utils.to_categorical(y_train) # 将标签转换成独热编码
y_test_onehot = tf.keras.utils.to_categorical(y_test)
network = tf.keras.models.load_model('model.h5')
network.evaluate(x_test, y_test_onehot)
之后就可以用训练好的模型对手写汉字图片进行预测了!
四、对手写汉字进行预测୧(๑•̀◡•́๑)૭
首先先在电脑某处保存一张手写0-9数字
代码:
import tensorflow as tf
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import pandas as pd
new_model = tf.keras.models.load_model('model.h5')
# 调用模型进行预测识别
im = Image.open(r'C:\Users\12393\Desktop\8.png') # 读取图片路径
im = im.resize((28, 28)) # 调整大小和模型输入大小一致
im = np.array(im)
# 对图片进行灰度化处理
p3 = im.min(axis=-1)
# plt.imshow(p3, cmap='gray')
# 将白底黑字变成黑底白字 由于训练模型是这种格式
for i in range(28):
for j in range(28):
p3[i][j] = 255-p3[i][j]
# 模型输出结果是每个类别的概率,取最大的概率的类别就是预测的结果
ret = new_model.predict((p3 / 255).reshape((1, 28, 28)))
print(ret)
number = np.argmax(ret)
print(number)
我的图片路径为C:\Users\12393\Desktop\8.png。
图片:
运行结果:
注:本人不是计算机视觉处理方向的学生,对计算机视觉处理也是小白一枚,欢迎留言沟通━(`∀´)ノ亻!
Original: https://blog.csdn.net/qidexiaoshijie/article/details/122659371
Author: 爱睡觉的琪
Title: (Windows,ten2.0)python0-9数字识别系统搭建(MNIST数据集)